
Python入門系列24 - 正則表達(dá)式(二)
Python入門系列24

正則表達(dá)式(二)
本篇閱讀時間約為 11分鐘。
1
前言
今天繼續(xù)來介紹一下python的正則表達(dá)式,回顧一下上次介紹的re模塊整篇文章圍繞著re.findall()來進(jìn)行實(shí)例的講解,也就是所謂的查詢操作。為了便于回顧,這里給出鏈接:python入門系列23 - 正則表達(dá)式(一)
2
re模塊的sub函數(shù)
sub:中文有代替的意思。使用re.sub()可以完成我們對原始字符串的替換操作!
先來看下官方函數(shù)的參數(shù)解釋:
re.sub(pattern, repl, string, count=0, flags=0)
pattern : 正則中的模式字符串。
repl : 替換的字符串,也可為一個函數(shù)。
string : 要被查找替換的原始字符串。
count : 模式匹配后替換的最大次數(shù),默認(rèn) 0 表示替換所有的匹配。
flags : 標(biāo)志位,用于控制正則表達(dá)式的匹配方式,如:是否區(qū)分大小寫,多行匹配等等。(如:re.I 使匹配對大小寫不敏感)
一大波實(shí)例來襲,做好準(zhǔn)備喲!
實(shí)例1(替換普通字符):
假設(shè)我數(shù)學(xué)和英文考試都得了60分……然而我并不甘心,上天給了我一次作弊的機(jī)會,可以通過程序來替換分?jǐn)?shù)!如何做呢?
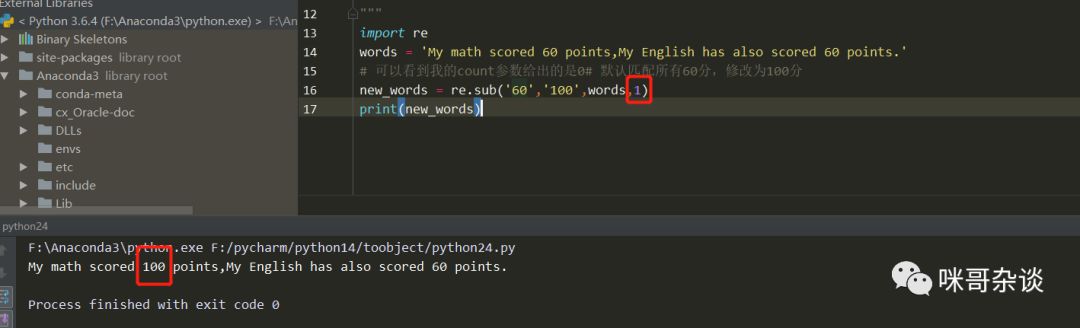
import re
words = 'My math scored 60 points,My English has also scored 60 points.'
# 可以看到我的count參數(shù)給出的是0# 默認(rèn)匹配所有60分,修改為100分
new_words = re.sub('60','100',words,0)
print(new_words)
>>> My math scored 100 points,My English has also scored 100 points.同理,若是只想修改數(shù)學(xué)成績,則將count參數(shù)改為1即可:
實(shí)例2(有邏輯的函數(shù)替換):
假設(shè)我的數(shù)學(xué)成績考了85分!emmm相當(dāng)不錯了,但是我依然想讓它增加5分,我愛數(shù)學(xué)!而英語這次考了100分,因?yàn)樽鞅琢恕瓰榱瞬蛔尷蠋煵煊X,我決定偷偷降低點(diǎn)分?jǐn)?shù)!兩種條件,如何才能使用sub函數(shù)來完成呢?別忘了我們的repl(replace)參數(shù)是可以傳遞函數(shù)的!這也是Python的一個特性,參數(shù)可以傳遞函數(shù),如下:
import re
def modify_score(score):
? ?print(score)
? ?new_socre = score.group() ? ?
? ?if int(new_socre) == 85: ? ? ? ?
? ? ? ?return '90'
? ?if int(new_socre) == 100: ? ? ? ?
? ? ? ?return '80'
words = 'My math scored 85 points,My English scored 100 points.That\'s cool!'
new_words = re.sub('\d{2,3}',modify_score,words,0)
print(new_words)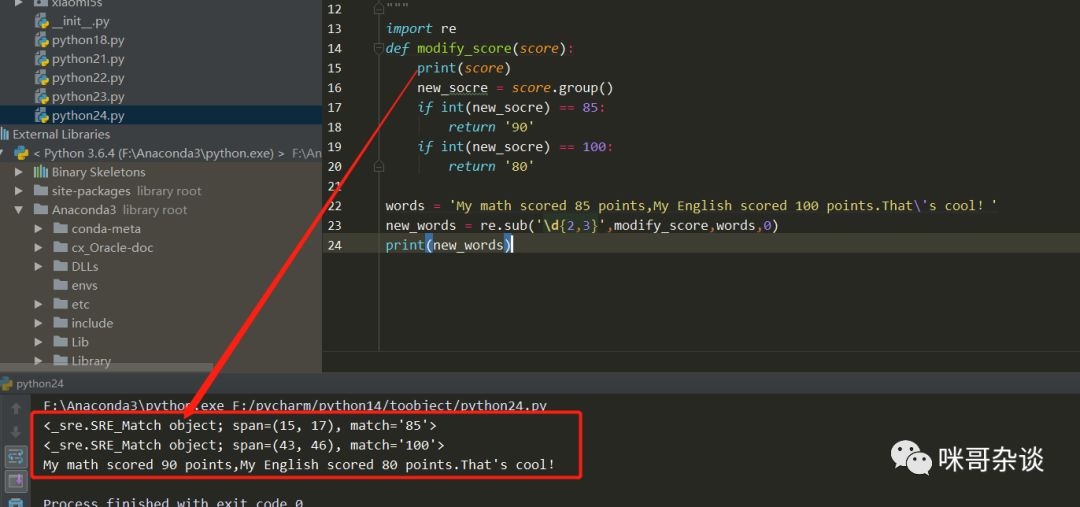
講解一下:在modify_score中,使用傳入score,可以打印輸出看下它的類型,這是一種正則的類型,而非字符串類型。此類型要將其內(nèi)容本身匹配出來,則需要調(diào)用它的group()方法,new_score取出來的便是數(shù)字形式的字符串。下面的邏輯對比,需要將字符串轉(zhuǎn)換為int型,才可以進(jìn)行對比操作,否則會報錯喲。
綜上所述: re.sub()可以輕松的實(shí)現(xiàn)字符串的替換,并且可以用函數(shù)傳遞的方式來對原始字符串進(jìn)行業(yè)務(wù)邏輯的判斷。
3
re模塊其它常用函數(shù)
1. match
依然是用事例來解釋看下:
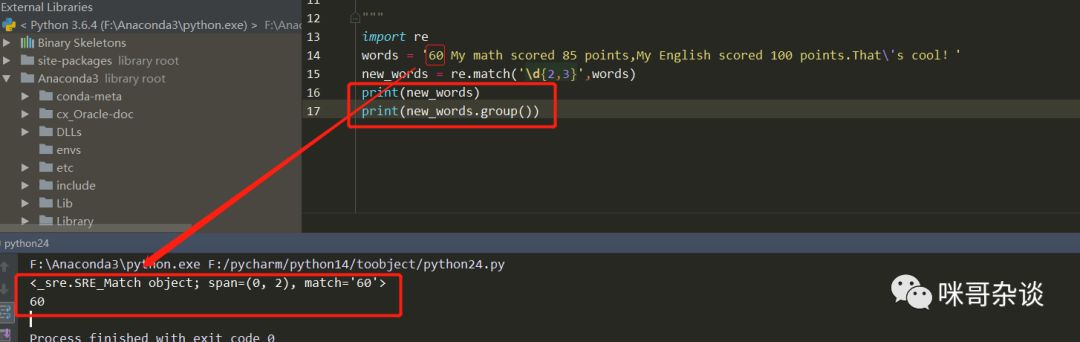
import re
words = 'My math scored 85 points,My English scored 100 points.That\'s cool!'
new_words = re.match('\d{2,3}',words)
print(new_words)
>>> None上述結(jié)果,打印為None,Why???
因?yàn)閙atch函數(shù)在進(jìn)行匹配的時候,是從字符串的起始開始進(jìn)行匹配,若開頭的字符串不符合正則表達(dá)式,則直接返回None,也就是什么都沒匹配到,停止后續(xù)匹配。
所以如果修改words,讓我們的分?jǐn)?shù)在字符串開頭試下:
2. search
使用search的示例如下:
import re
words = 'My math scored 85 points,My English scored 100 points.That\'s cool!'
new_words = re.search('\d{2,3}',words)
print(new_words)
print(new_words.group())
>>> <_sre.SRE_Match object; span=(15, 17), match='85'>
>>> 85上述結(jié)果,打印出了匹配到的對象與值,與match不一樣!但是可以看到,search函數(shù)只匹配到了一次的,后續(xù)分?jǐn)?shù)的100即使符合正則表達(dá)式,也不會被匹配到了。
match和search函數(shù)是當(dāng)今市場上各教程類中,寫爬蟲最常用的兩個方法,而實(shí)際上這兩個函數(shù)是需要對匹配后的結(jié)果進(jìn)行g(shù)roup分組處理,才能取出你想要的結(jié)果。在上節(jié)的小課堂中,全篇講到的findall方法,則不需要進(jìn)行g(shù)roup的調(diào)用,可以直接將結(jié)果以list全面匹配出來,這也是findall和match、search函數(shù)最大的區(qū)別。
4
group分組
既然提到了group分組,那么就來介紹下,group的具體用法,以及在爬蟲中經(jīng)常會以一種什么樣的方式去進(jìn)行你想要的匹配!
此處以search函數(shù)來舉例,場景是醬紫的:我自己說了一句話 ,「我在這次考試中,數(shù)學(xué)分?jǐn)?shù)考了85,英語分?jǐn)?shù)考了100分,這真是太酷了!」。現(xiàn)在需要將「英語分?jǐn)?shù)考了100分」獲取到!代碼如下:
import re
words = 'My math scored 85 points,My English scored 100 points.That\'s cool!'
new_words1 = re.search('points,\wThat',words)
new_words2 = re.search('points,\w*That',words)
new_words3 = re.search('points,.*That',words)
new_words4 = re.search(',(.*)That',words)
print(new_words1.group())
print(new_words2.group())
print(new_words3.group())
print(new_words4.group())仔細(xì)看過代碼的同學(xué),肯定會疑惑為什么寫了這么多行正則匹配的表達(dá)式,莫急莫急,且聽我慢慢道來。在不看我下面的解釋前,你認(rèn)為,下面這四個print()會依次打印出什么樣的結(jié)果呢?
解釋:其實(shí)new_words1~4是一段非常有邏輯的演變過程。
① 先來看new_word1,如果想要匹配我英語分?jǐn)?shù)考了100分這段英文字符,需要先使用普通字符串進(jìn)行邊界的限定,還記得嗎?(上節(jié)小課堂有說過哦!忘了的話回到文章首處點(diǎn)擊鏈接進(jìn)行回顧。) 所以使用"ponit, "和"That"進(jìn)行邊界限定,一旦邊界限定后,便可以使用元字符來進(jìn)行內(nèi)容的匹配,而\w代表的含義是匹配包括下劃線的任何單詞字符。于是調(diào)用如下圖:
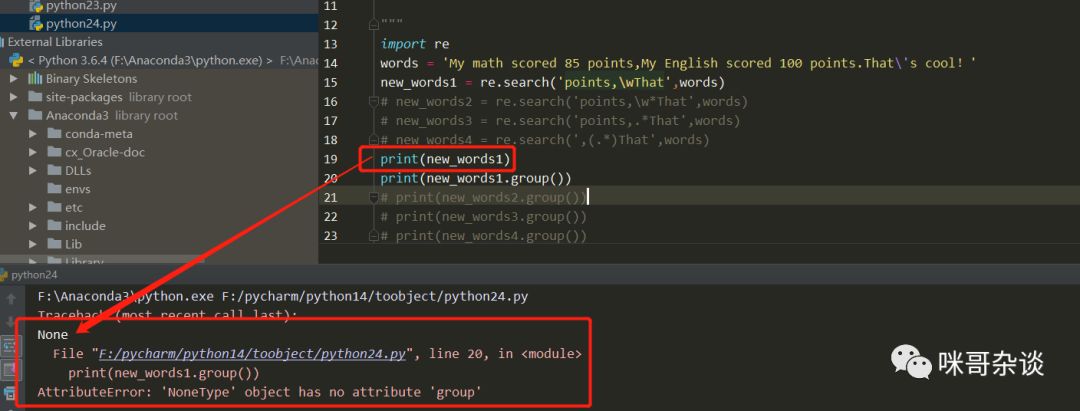
可以看到報錯啦,錯誤說的是None類型沒有g(shù)roup方法,因?yàn)?中的正則是錯誤的,沒有正確進(jìn)行匹配,所以最終得到的值是None。理由很簡單,因?yàn)?/span>\w這樣的寫法只進(jìn)行了單字符匹配,故然是不行的。如何進(jìn)行多字符匹配呢?于是有了new_word2。
②?來看new_word2,普通字符的邊界限定寫法是不變的,在原來的基礎(chǔ)上,在\w后面新增*。*的元字符代表的含義是匹配前一個字符0次或n次以上。然后有了下圖:
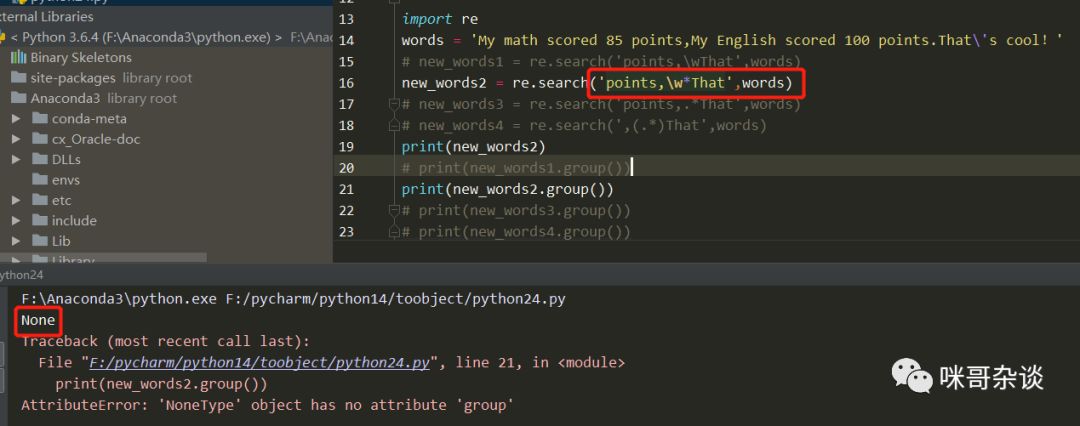
為毛還是報錯?然后在反思下,發(fā)現(xiàn)。。。哦原來是想匹配的字符串中是包含空格的,而\w是不能匹配到空格字符的,所以這個正則表達(dá)式的寫法依然不對!再繼續(xù),什么元字符可以進(jìn)行空格和字母的匹配呢?于是有了new_words3。
③?new_words3中使用的是.來進(jìn)行空格和字母的匹配,點(diǎn)的后面還是使用*來匹配。如下圖:
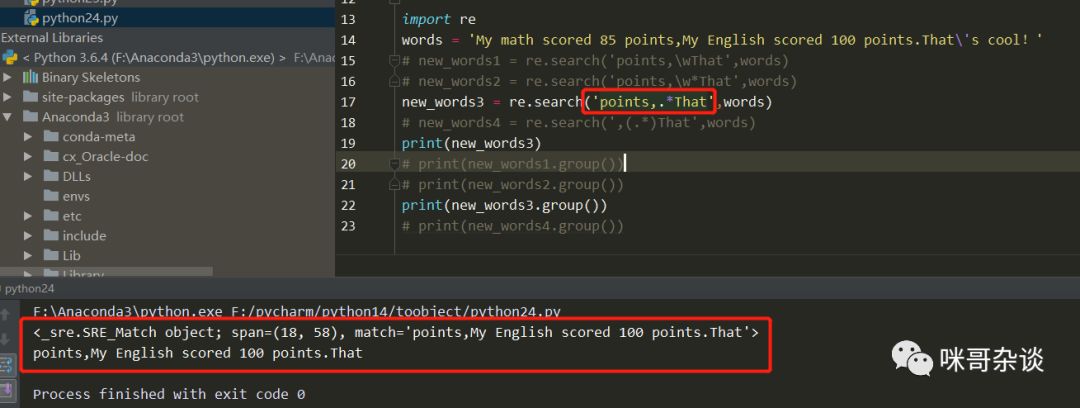
可以看到正確的結(jié)果了,終于沒有報錯了!但是呢,但是呢,但是呢。。。會發(fā)現(xiàn),匹配到的結(jié)果卻不是我想要的最終結(jié)果,它把整個正則表達(dá)式的限定邊界也匹配到了...于是再次改進(jìn),就有了最后的new_words4。
④ new_words4是在③的基礎(chǔ)上,除去了邊界字符的限定,將.*用小括號擴(kuò)了起來,此處就是在上節(jié)小課堂中提到的分組!而一旦分好組之后,我們便可以通過group將自己定義好的分組提取出來,清理下以上注釋掉的代碼:
import re
words = 'My math scored 85 points,My English scored 100 points.That\'s cool!'
new_words4 = re.search(',(.*)That',words)
print(new_words4)
print(new_words4.group())
print(new_words4.group(0))
print(new_words4.group(1))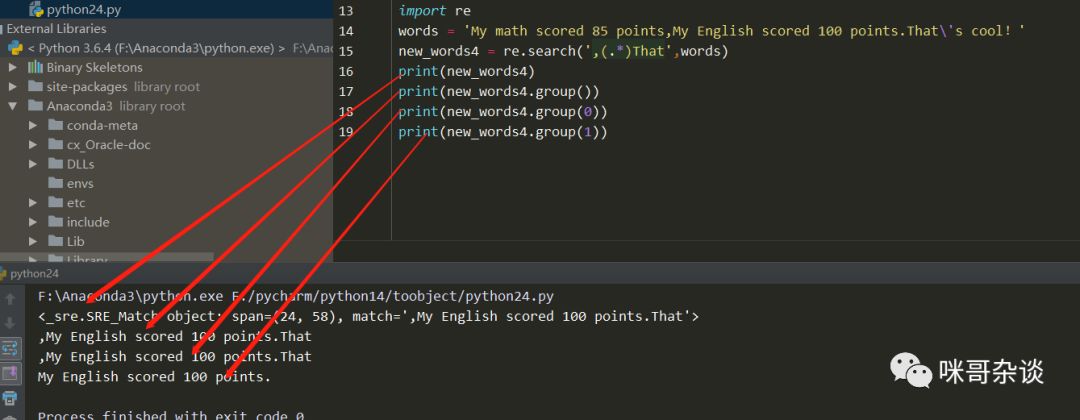
不難發(fā)現(xiàn),其實(shí)group()中是可以傳遞數(shù)字的,默認(rèn)情況下不寫等同于0,可以看到上圖不寫和寫0是一個輸出結(jié)果。這里需要說下,為什么0匹配出來的是整段正則表達(dá)式的字符串,而不是我想要的“My English scored 100 points.”這句話。先來看下兩段代碼:
new_words4 = re.search(',(.*)That',words)new_words5 = re.search('(,(.*)That)',words)實(shí)際上,new_words4是等效于new_words5的,在new_words5中默認(rèn)的正則參數(shù)位置是有一層隱形的小括號,也就是最外面的組,所以當(dāng)我們調(diào)用group(0)或者group()實(shí)則是指這層組的關(guān)系。
若想調(diào)用組中組,需要從左到右,數(shù)字是從1開始進(jìn)行調(diào)用的,和上面的代碼結(jié)果圖的最后一行是對應(yīng)上的!
5
總結(jié)
到這里,關(guān)于Python的正則表達(dá)式常用的幾點(diǎn)也就介紹完了,為什么要講述正則呢?因?yàn)檫@是處理字符串文本必不可少的一個強(qiáng)大工具!只要能得心應(yīng)手的使用它,相信不論是在處理爬蟲想要的信息也好,數(shù)據(jù)清洗時處理也罷,都可以輕松玩轉(zhuǎn)字符串!
用思維導(dǎo)圖來回顧下正表達(dá)式的所有常用知識點(diǎn)吧,所謂一圖勝過千言萬語,畢竟可以來梳理思路:
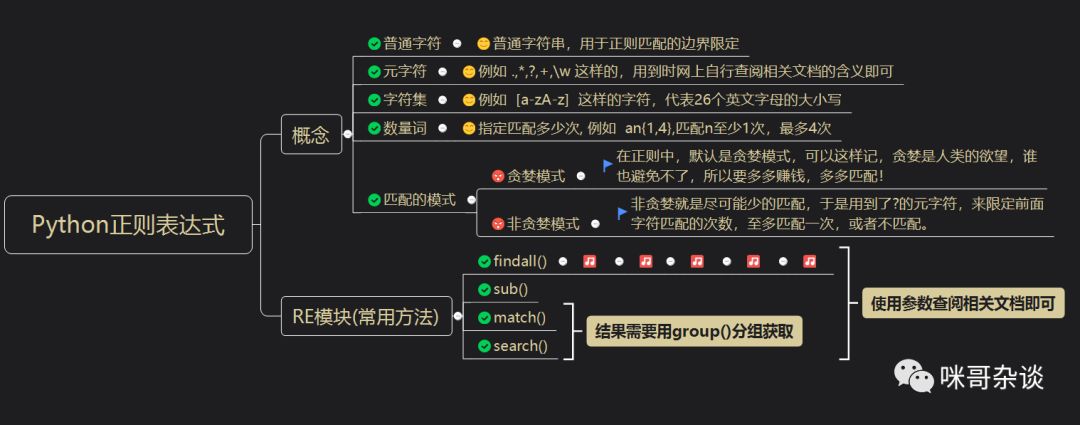
至此完!