
線程數(shù),512是否合理?
Web-Server有個配置,工作線程數(shù)。
Service一般也有個配置,工作線程數(shù)。
經(jīng)驗豐富的架構(gòu)師,懂得如何配置這些參數(shù),使得系統(tǒng)的性能達(dá)到最優(yōu):有些業(yè)務(wù)設(shè)置為CPU核數(shù)的2倍,有些業(yè)務(wù)設(shè)置為CPU核數(shù)的8倍,有些業(yè)務(wù)設(shè)置為CPU核數(shù)的32倍。
“線程數(shù)”的設(shè)置依據(jù) ,是本文要討論的問題。
工作線程數(shù)是不是設(shè)置的越大越好? 答案顯然是 否定的 : (1)服務(wù)器CPU核數(shù)有限,能夠同時并發(fā)的線程數(shù)有限,單核CPU設(shè)置1000個工作線程沒有意義; (2)線程切換有開銷 ,如果線程切換過于頻繁,反而會使性能降低; ?
調(diào)用sleep()函數(shù)的時候,線程是否一直占用CPU? 不占用 ,休眠時會把CPU讓出來,給其他需要CPU資源的線程使用。
不止sleep, 一些阻塞調(diào)用 ,例如網(wǎng)絡(luò)編程中的: (1)阻塞accept(),等待客戶端連接; (2)阻塞recv(),等待下游回包; 都會讓出CPU資源 。
單核CPU,設(shè)置多線程有意義么? 單核CPU,設(shè)置多線程能否提高并發(fā)性能? 即使是單核,使用多線程也是 有意義 的,大多數(shù)情況也 能提高并發(fā) : (1)多線程編碼可以讓代碼更加清晰 ,例如:IO線程收發(fā)包,Worker線程進(jìn)行任務(wù)處理,Timeout線程進(jìn)行超時檢測; (2)如果有一個任務(wù)一直占用CPU資源在進(jìn)行計算,此時增加線程并不能增加并發(fā),例如以下代碼會一直占用CPU,并使得CPU占用率達(dá)到100%: ?while(1){ i++; } (3)通常來說,Worker線程一般不會一直占用CPU進(jìn)行計算,此時即使CPU是單核,增加Worker線程也能夠提高并發(fā),因為這個線程在休息的時候,其他的線程可以繼續(xù)工作; ?
第一種,IO線程與工作線程通過隊列解耦類模型。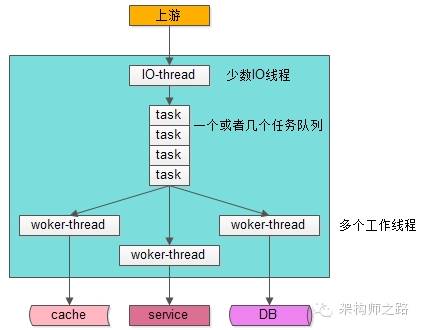
如上圖,大部分Web-Server與服務(wù)框架都是使用這樣的一種“IO線程與Worker線程通過隊列解耦”類線程模型: (1)有少數(shù)幾個IO線程監(jiān)聽上游發(fā)過來的請求,并進(jìn)行收發(fā)包(生產(chǎn)者); (2)有一個或者多個任務(wù)隊列,作為IO線程與Worker線程異步解耦的數(shù)據(jù)傳輸通道(臨界資源); (3)有多個工作線程執(zhí)行真正的任務(wù)(消費(fèi)者);
這個線程模型應(yīng)用很廣,符合大部分場景,這個線程模型的特點(diǎn)是,工作線程內(nèi)部是同步阻塞執(zhí)行任務(wù)的,因此 可以通過增加Worker線程數(shù)來增加并發(fā)能力 ,今天要討論的重點(diǎn)是“該模型Worker線程數(shù)設(shè)置為多少能達(dá)到最大的并發(fā)”。 ? 第二種,純異步線程模型。 沒有阻塞,這種線程模型只需要設(shè)置很少的線程數(shù)就能夠做到很高的吞吐量,該模型的缺點(diǎn)是: (1)如果使用單線程模式,難以利用多CPU多核的優(yōu)勢; (2)程序員更習(xí)慣寫同步代碼,callback的方式對代碼的可讀性有沖擊,對程序員的要求也更高; (3)框架更復(fù)雜,往往需要server端收發(fā)組件,server端隊列,client端收發(fā)組件,client端隊列,上下文管理組件,有限狀態(tài)機(jī)組件,超時管理組件的支持;
however,這個模型不是今天討論的重點(diǎn)。 ?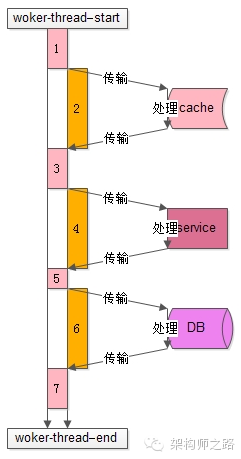
上圖是一個典型的工作線程的處理過程,從開始處理start到結(jié)束處理end,該任務(wù)的處理共有7個步驟: (1)從工作隊列里拿出任務(wù),進(jìn)行一些本地初始化計算,例如http協(xié)議分析、參數(shù)解析、參數(shù)校驗等; (2) 訪問cache 拿一些數(shù)據(jù); (3)拿到cache里的數(shù)據(jù)后,再進(jìn)行一些本地計算,這些計算和業(yè)務(wù)邏輯相關(guān); (4)通過 RPC調(diào)用 下游service再拿一些數(shù)據(jù),或者讓下游service去處理一些相關(guān)的任務(wù); (5)RPC調(diào)用結(jié)束后,再進(jìn)行一些本地計算,怎么計算和業(yè)務(wù)邏輯相關(guān); (6) 訪問DB 進(jìn)行一些數(shù)據(jù)操作; (7)操作完數(shù)據(jù)庫之后做一些收尾工作,同樣這些收尾工作也是本地計算,和業(yè)務(wù)邏輯相關(guān); ? 分析整個處理的時間軸,會發(fā)現(xiàn): (1)其中1,3,5,7步驟中(上圖中粉色時間軸),線程進(jìn)行 本地業(yè)務(wù)邏輯計算 時需要占用CPU; (2)而2,4,6步驟中(上圖中橙色時間軸),訪問cache、service、DB過程中線程處于一個 等待結(jié)果的狀態(tài) ,不需要占用CPU,進(jìn)一步的分解,這個“等待結(jié)果”的時間共分為三部分: 2.1)請求在網(wǎng)絡(luò)上傳輸?shù)较掠蔚腸ache、service、DB; 2.2)下游cache、service、DB進(jìn)行任務(wù)處理; 2.3)cache、service、DB將報文在網(wǎng)絡(luò)上傳回工作線程; ?
通過量化分析,例如打日志進(jìn)行統(tǒng)計,可以統(tǒng)計出整個Worker線程執(zhí)行過程中這兩部分時間的比例,例如: (1)執(zhí)行計算,占用CPU的時間(粉色時間軸)是100ms; (2)等待時間,不占用CPU的時間(橙色時間軸)也是100ms;
得到的結(jié)果是, 這個線程計算和等待的時間是1:1 ,即有50%的時間在計算(占用CPU),50%的時間在等待(不占用CPU): (1)假設(shè)此時是單核,則設(shè)置為2個工作線程就可以把CPU充分利用起來,讓CPU跑到100%; (2)假設(shè)此時是N核,則設(shè)置為2N個工作現(xiàn)場就可以把CPU充分利用起來,讓CPU跑到N*100%; ? 當(dāng)當(dāng)當(dāng)當(dāng)!!!
結(jié)論來了 :
N 核服務(wù)器 ,通過執(zhí)行業(yè)務(wù)的單線程分析出本地計算時間為 x ,等待時間為 y ,則工作線程數(shù)(線程池線程數(shù))設(shè)置為 N*(x+y)/x ,能讓CPU的利用率最大化。
一般來說,非CPU密集型的業(yè)務(wù)(加解密、壓縮解壓縮、搜索排序等業(yè)務(wù)是CPU密集型的業(yè)務(wù)),瓶頸都在后端數(shù)據(jù)庫訪問或者RPC調(diào)用,本地CPU計算的時間很少,所以設(shè)置幾十或者幾百個工作線程是能夠提升吞吐量的。
學(xué)廢了嗎?
架構(gòu)師之路 -分享技術(shù) 思路
相關(guān)文章: 《線上問題排查,這些命令你一定用得到!》 《CPU100%,怎么快速定位?》
《頂尖的人都是怎么想的!(很殘酷)》
思考題 : 貴司線程數(shù)設(shè)置為多少?
畫外音:隨手設(shè)了一個200?
經(jīng)驗豐富的架構(gòu)師,懂得如何配置這些參數(shù),使得系統(tǒng)的性能達(dá)到最優(yōu):有些業(yè)務(wù)設(shè)置為CPU核數(shù)的2倍,有些業(yè)務(wù)設(shè)置為CPU核數(shù)的8倍,有些業(yè)務(wù)設(shè)置為CPU核數(shù)的32倍。
“線程數(shù)”的設(shè)置依據(jù) ,是本文要討論的問題。
工作線程數(shù)是不是設(shè)置的越大越好? 答案顯然是 否定的 : (1)服務(wù)器CPU核數(shù)有限,能夠同時并發(fā)的線程數(shù)有限,單核CPU設(shè)置1000個工作線程沒有意義; (2)線程切換有開銷 ,如果線程切換過于頻繁,反而會使性能降低; ?
調(diào)用sleep()函數(shù)的時候,線程是否一直占用CPU? 不占用 ,休眠時會把CPU讓出來,給其他需要CPU資源的線程使用。
不止sleep, 一些阻塞調(diào)用 ,例如網(wǎng)絡(luò)編程中的: (1)阻塞accept(),等待客戶端連接; (2)阻塞recv(),等待下游回包; 都會讓出CPU資源 。
單核CPU,設(shè)置多線程有意義么? 單核CPU,設(shè)置多線程能否提高并發(fā)性能? 即使是單核,使用多線程也是 有意義 的,大多數(shù)情況也 能提高并發(fā) : (1)多線程編碼可以讓代碼更加清晰 ,例如:IO線程收發(fā)包,Worker線程進(jìn)行任務(wù)處理,Timeout線程進(jìn)行超時檢測; (2)如果有一個任務(wù)一直占用CPU資源在進(jìn)行計算,此時增加線程并不能增加并發(fā),例如以下代碼會一直占用CPU,并使得CPU占用率達(dá)到100%: ?while(1){ i++; } (3)通常來說,Worker線程一般不會一直占用CPU進(jìn)行計算,此時即使CPU是單核,增加Worker線程也能夠提高并發(fā),因為這個線程在休息的時候,其他的線程可以繼續(xù)工作; ?
常見服務(wù)線程模型有幾種?
了解常見的服務(wù)線程模型,有助于理解服務(wù)并發(fā)的原理,一般來說互聯(lián)網(wǎng)常見的服務(wù)線程模型有 兩種 : (1)IO線程 與 工作線程 通過 任務(wù)隊列 解耦; (2)純異步;第一種,IO線程與工作線程通過隊列解耦類模型。
如上圖,大部分Web-Server與服務(wù)框架都是使用這樣的一種“IO線程與Worker線程通過隊列解耦”類線程模型: (1)有少數(shù)幾個IO線程監(jiān)聽上游發(fā)過來的請求,并進(jìn)行收發(fā)包(生產(chǎn)者); (2)有一個或者多個任務(wù)隊列,作為IO線程與Worker線程異步解耦的數(shù)據(jù)傳輸通道(臨界資源); (3)有多個工作線程執(zhí)行真正的任務(wù)(消費(fèi)者);
這個線程模型應(yīng)用很廣,符合大部分場景,這個線程模型的特點(diǎn)是,工作線程內(nèi)部是同步阻塞執(zhí)行任務(wù)的,因此 可以通過增加Worker線程數(shù)來增加并發(fā)能力 ,今天要討論的重點(diǎn)是“該模型Worker線程數(shù)設(shè)置為多少能達(dá)到最大的并發(fā)”。 ? 第二種,純異步線程模型。 沒有阻塞,這種線程模型只需要設(shè)置很少的線程數(shù)就能夠做到很高的吞吐量,該模型的缺點(diǎn)是: (1)如果使用單線程模式,難以利用多CPU多核的優(yōu)勢; (2)程序員更習(xí)慣寫同步代碼,callback的方式對代碼的可讀性有沖擊,對程序員的要求也更高; (3)框架更復(fù)雜,往往需要server端收發(fā)組件,server端隊列,client端收發(fā)組件,client端隊列,上下文管理組件,有限狀態(tài)機(jī)組件,超時管理組件的支持;
however,這個模型不是今天討論的重點(diǎn)。 ?
第一類“IO線程與工作線程通過隊列解耦”類線程模型,工作線程的工作模式是怎么樣的?
了解工作線程的工作模式,對量化分析線程數(shù)的設(shè)置非常有幫助:上圖是一個典型的工作線程的處理過程,從開始處理start到結(jié)束處理end,該任務(wù)的處理共有7個步驟: (1)從工作隊列里拿出任務(wù),進(jìn)行一些本地初始化計算,例如http協(xié)議分析、參數(shù)解析、參數(shù)校驗等; (2) 訪問cache 拿一些數(shù)據(jù); (3)拿到cache里的數(shù)據(jù)后,再進(jìn)行一些本地計算,這些計算和業(yè)務(wù)邏輯相關(guān); (4)通過 RPC調(diào)用 下游service再拿一些數(shù)據(jù),或者讓下游service去處理一些相關(guān)的任務(wù); (5)RPC調(diào)用結(jié)束后,再進(jìn)行一些本地計算,怎么計算和業(yè)務(wù)邏輯相關(guān); (6) 訪問DB 進(jìn)行一些數(shù)據(jù)操作; (7)操作完數(shù)據(jù)庫之后做一些收尾工作,同樣這些收尾工作也是本地計算,和業(yè)務(wù)邏輯相關(guān); ? 分析整個處理的時間軸,會發(fā)現(xiàn): (1)其中1,3,5,7步驟中(上圖中粉色時間軸),線程進(jìn)行 本地業(yè)務(wù)邏輯計算 時需要占用CPU; (2)而2,4,6步驟中(上圖中橙色時間軸),訪問cache、service、DB過程中線程處于一個 等待結(jié)果的狀態(tài) ,不需要占用CPU,進(jìn)一步的分解,這個“等待結(jié)果”的時間共分為三部分: 2.1)請求在網(wǎng)絡(luò)上傳輸?shù)较掠蔚腸ache、service、DB; 2.2)下游cache、service、DB進(jìn)行任務(wù)處理; 2.3)cache、service、DB將報文在網(wǎng)絡(luò)上傳回工作線程; ?
如何量化分析,并合理設(shè)置工作線程數(shù)呢?
通過上面的分析,Worker線程在執(zhí)行的過程中: (1)有一部計算時間需要占用CPU; (2)另一部分等待時間不需要占用CPU;通過量化分析,例如打日志進(jìn)行統(tǒng)計,可以統(tǒng)計出整個Worker線程執(zhí)行過程中這兩部分時間的比例,例如: (1)執(zhí)行計算,占用CPU的時間(粉色時間軸)是100ms; (2)等待時間,不占用CPU的時間(橙色時間軸)也是100ms;
得到的結(jié)果是, 這個線程計算和等待的時間是1:1 ,即有50%的時間在計算(占用CPU),50%的時間在等待(不占用CPU): (1)假設(shè)此時是單核,則設(shè)置為2個工作線程就可以把CPU充分利用起來,讓CPU跑到100%; (2)假設(shè)此時是N核,則設(shè)置為2N個工作現(xiàn)場就可以把CPU充分利用起來,讓CPU跑到N*100%; ? 當(dāng)當(dāng)當(dāng)當(dāng)!!!
結(jié)論來了 :
N 核服務(wù)器 ,通過執(zhí)行業(yè)務(wù)的單線程分析出本地計算時間為 x ,等待時間為 y ,則工作線程數(shù)(線程池線程數(shù))設(shè)置為 N*(x+y)/x ,能讓CPU的利用率最大化。
一般來說,非CPU密集型的業(yè)務(wù)(加解密、壓縮解壓縮、搜索排序等業(yè)務(wù)是CPU密集型的業(yè)務(wù)),瓶頸都在后端數(shù)據(jù)庫訪問或者RPC調(diào)用,本地CPU計算的時間很少,所以設(shè)置幾十或者幾百個工作線程是能夠提升吞吐量的。
學(xué)廢了嗎?
架構(gòu)師之路 -分享技術(shù) 思路
相關(guān)文章: 《線上問題排查,這些命令你一定用得到!》 《CPU100%,怎么快速定位?》
《頂尖的人都是怎么想的!(很殘酷)》
思考題 : 貴司線程數(shù)設(shè)置為多少?
畫外音:隨手設(shè)了一個200?
評論
圖片
表情