
3種時間序列混合建模方法的效果對比和代碼實現(xiàn)

來源:DeepHub IMBA 本文約2700字,建議閱讀9分鐘
本文中將討論如何建立一個有效的混合預測器,并對常見混合方式進行對比和分析。
基礎(chǔ)知識
series = trend + seasons + cycles + error首先,學習趨勢并將其從原始序列中減去,得到殘差序列; 其次,從去趨勢的殘差中學習季節(jié)性并減去季節(jié); 最后,學習周期并減去周期。
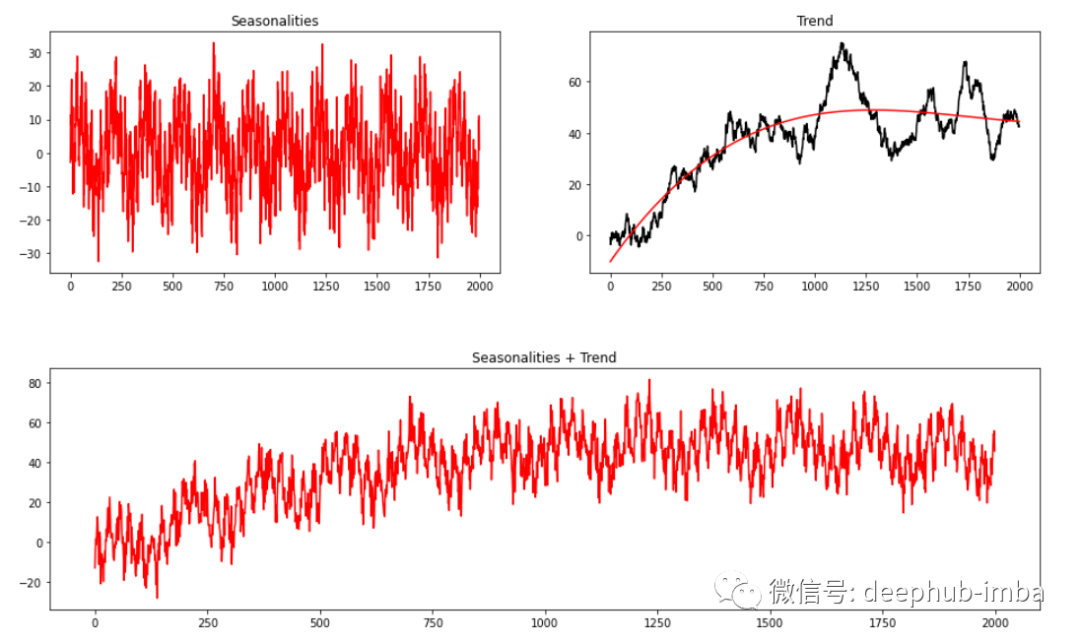
np.random.seed(1234)seas1 = gen_sinusoidal(timesteps=timesteps, amp=10, freq=24, noise=4)seas2 = gen_sinusoidal(timesteps=timesteps, amp=10, freq=24*7, noise=4)rw = gen_randomwalk(timesteps=timesteps, noise=1)X = np.linspace(0,10, timesteps).reshape(-1,1)X = np.power(X, [1,2,3])m = LinearRegression()trend = m.fit(X, rw).predict(X)plt.figure(figsize=(16,4))plt.subplot(121)plt.plot(seas1 + seas2, c='red'); plt.title('Seasonalities')plt.subplot(122)plt.plot(rw, c='black'); plt.plot(trend, c='red'); plt.title('Trend')plt.figure(figsize=(16,4))plt.plot(seas1 + seas2 + trend, c='red'); plt.title('Seasonalities + Trend')
df.plot(legend=False, figsize=(16,6))
實驗方法
擬合一個簡單的線性模型; differencing:使用差分變換,使目標變得穩(wěn)定; hybrid additive:擬合具有最優(yōu)的線性模型推斷趨勢。然后用梯度提升對去趨勢序列進行建模; hybrid inclusive.:擬合梯度提升,包括外推趨勢(獲得擬合具有最優(yōu)線性模型擬合的趨勢)作為特征。
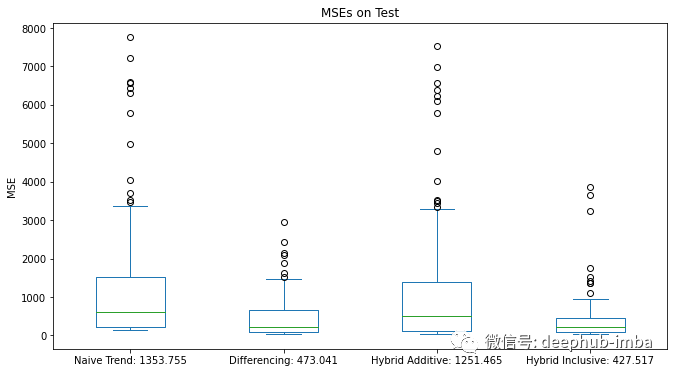
結(jié)果
### 訓練過程略,請查看最后的完整源代碼 ###scores = pd.DataFrame({f'{score_naive}': mse_naive,f'{score_diff}': mse_diff,f'{score_hybrid_add}': mse_hybrid_add,f'{score_hybrid_incl}': mse_hybrid_incl})scores.plot.box(figsize=(11,6), title='MSEs on Test', ylabel='MSE')
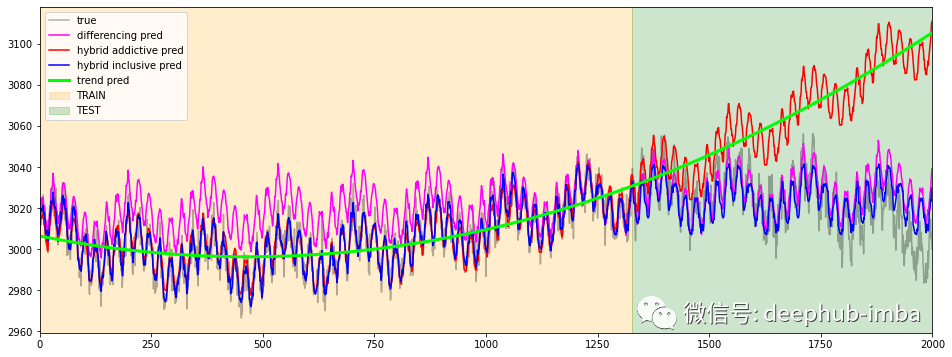
c = 'ts_11'df[c].plot(figsize=(16,6), label='true', alpha=0.3, c='black')df_diff[c].plot(figsize=(16,6), label='differencing pred', c='magenta')df_hybrid_add[c].plot(figsize=(16,6), label='hybrid addictive pred', c='red')df_hybrid_incl[c].plot(figsize=(16,6), label='hybrid inclusive pred', c='blue')df_naive[c].plot(figsize=(16,6), label='trend pred', c='lime', linewidth=3)plt.xlim(0, timesteps)plt.axvspan(0, timesteps-test_mask.sum(), alpha=0.2, color='orange', label='TRAIN')plt.axvspan(timesteps-test_mask.sum(), timesteps, alpha=0.2, color='green', label='TEST')plt.legend()
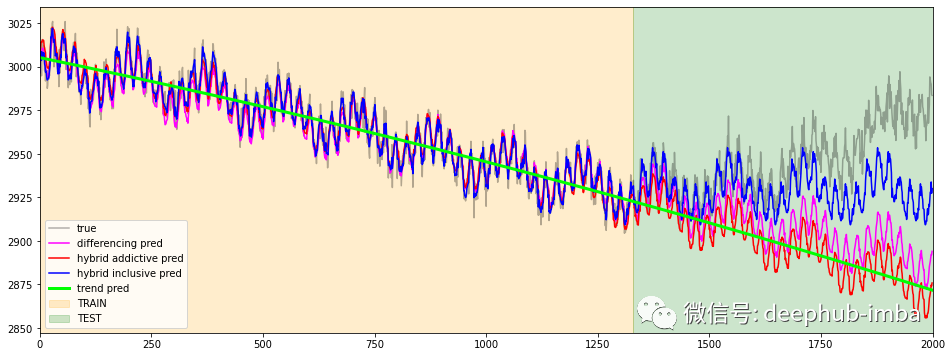
c = 'ts_33'df[c].plot(figsize=(16,6), label='true', alpha=0.3, c='black')df_diff[c].plot(figsize=(16,6), label='differencing pred', c='magenta')df_hybrid_add[c].plot(figsize=(16,6), label='hybrid addictive pred', c='red')df_hybrid_incl[c].plot(figsize=(16,6), label='hybrid inclusive pred', c='blue')df_naive[c].plot(figsize=(16,6), label='trend pred', c='lime', linewidth=3)plt.xlim(0, timesteps)plt.axvspan(0, timesteps-test_mask.sum(), alpha=0.2, color='orange', label='TRAIN')plt.axvspan(timesteps-test_mask.sum(), timesteps, alpha=0.2, color='green', label='TEST')plt.legend()
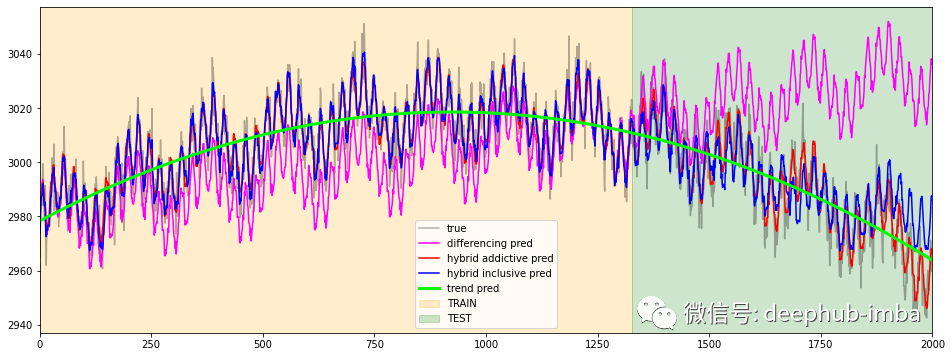
c = 'ts_73'df[c].plot(figsize=(16,6), label='true', alpha=0.3, c='black')df_diff[c].plot(figsize=(16,6), label='differencing pred', c='magenta')df_hybrid_add[c].plot(figsize=(16,6), label='hybrid addictive pred', c='red')df_hybrid_incl[c].plot(figsize=(16,6), label='hybrid inclusive pred', c='blue')df_naive[c].plot(figsize=(16,6), label='trend pred', c='lime', linewidth=3)plt.xlim(0, timesteps)plt.axvspan(0, timesteps-test_mask.sum(), alpha=0.2, color='orange', label='TRAIN')plt.axvspan(timesteps-test_mask.sum(), timesteps, alpha=0.2, color='green', label='TEST')plt.legend()
總結(jié)
最后,本文的完整代碼在這里:
https://github.com/cerlymarco/MEDIUM_NoteBook/tree/master/Hybrid_Trees_Forecasting
作者:Marco Cerliani
評論
圖片
表情