
Hbase與MySQL對比,區(qū)別是什么?

閱讀本文大概需要 2.8 分鐘。
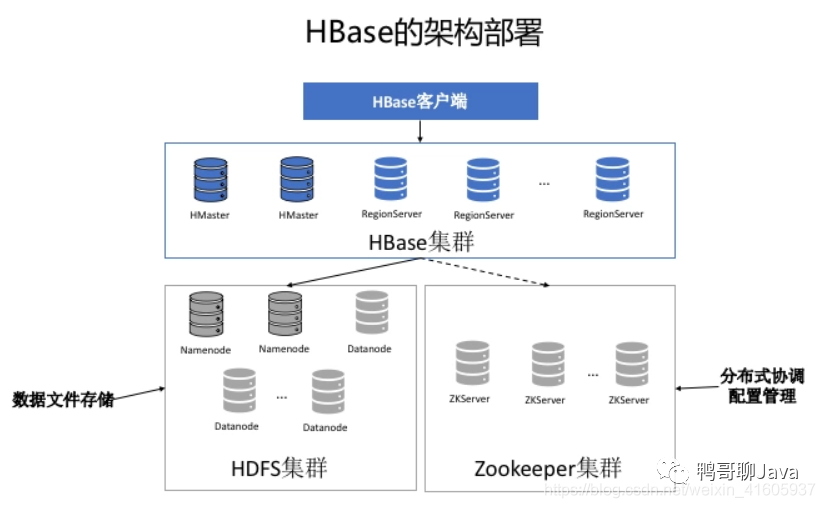
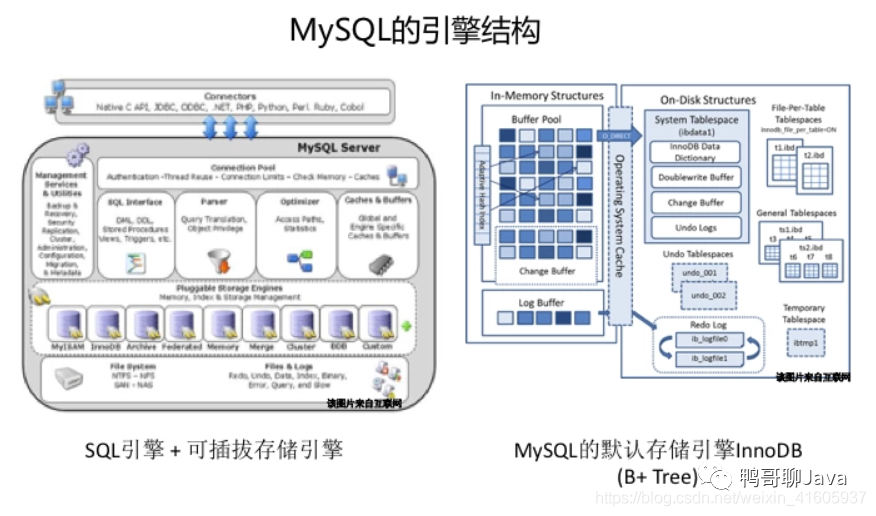
 ?相比MySQL,HBase的內(nèi)部引擎特點(diǎn):
?相比MySQL,HBase的內(nèi)部引擎特點(diǎn):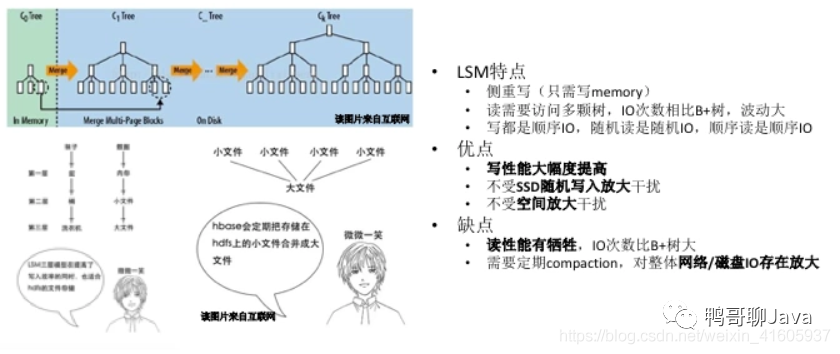
從磁盤讀數(shù)據(jù)是以頁為單位,根據(jù)這個特點(diǎn)使用平衡多路查找樹
B+樹的非葉子節(jié)點(diǎn)存放索引,葉子節(jié)點(diǎn)存放數(shù)據(jù)
非葉子節(jié)點(diǎn)能夠存放更多的索引,樹的高度更低
葉子節(jié)點(diǎn)通過指針相連,有利于區(qū)間查詢
葉子節(jié)點(diǎn)和根節(jié)點(diǎn)的距離基本相同,查找的效率穩(wěn)定
數(shù)據(jù)插入導(dǎo)致葉子節(jié)點(diǎn)分裂,最終導(dǎo)致邏輯連續(xù)的數(shù)據(jù)存放到不同物理磁盤塊位置,導(dǎo)致區(qū)間查詢效率下降
LSM(Log-Structured Merge),LevelDB,RocksDB,HBase,Cassandra等都是基于LSM結(jié)構(gòu)
HDD,SSD順序讀寫的速度都高于隨機(jī)讀寫,寫入日志就是順序?qū)?/span>
WAL,memtable,sstable
有利于寫,不利于讀,先從memtable查找,再到磁盤所有的sstable文件查找
Compaction的目的是減少sstable文件數(shù)量,緩解讀放大的問題,加速查找可以對sstable文件使用布隆過濾器
Compaction策略
STCS(SIze-Tiered Compaction Strategy)空間放大和讀放大問題
LCS(Leveled Compaction Strategy)寫放大問題
Compaction會引入寫放大問題,在Value較大時采用KV分離存儲緩解寫放大
寫操作多于讀操作時,LSM樹有更好的性能,因為隨著insert操作,為了維護(hù)B+樹結(jié)構(gòu),節(jié)點(diǎn)分裂。讀磁盤的隨機(jī)讀寫概率會變大,性能會逐漸減弱。LSM樹相比于B+樹,多次單頁隨機(jī)寫變成一次多頁隨機(jī)寫,復(fù)用了磁盤尋道時間,極大提高寫性能。不過付出代價就是放棄部分讀性能。





推薦閱讀:
頭條三面:toString()、String.valueOf、(String)強(qiáng)轉(zhuǎn),有啥區(qū)別?
最近面試BAT,整理一份面試資料《Java面試BATJ通關(guān)手冊》,覆蓋了Java核心技術(shù)、JVM、Java并發(fā)、SSM、微服務(wù)、數(shù)據(jù)庫、數(shù)據(jù)結(jié)構(gòu)等等。
朕已閱?