
斯坦福????????????-??-????????????,迭代生成草圖
【新智元導(dǎo)讀】有了????????????-??-????????????,不是藝術(shù)家,也成藝術(shù)家。
只需隨筆一畫,高清畫作就來了。
比如,畫一個中世紀城堡,簡單畫個門,畫條路,一座美麗的城堡出現(xiàn)了。

帶郵箱的霍比特人房子

海洋邊緣的燈塔(PS:有點像海底星空)

來自斯坦福的研究人員提出了????????????-??-????????????,一個能夠?qū)⒉輬D變成畫作的模型。

甚至,????????????-??-????????????可將生成的圖像,轉(zhuǎn)換成完整的草圖,還能為下一步的繪畫提供建議。
那么,它具體是如何工作的呢?
草圖,還能再編輯
現(xiàn)有的草圖控制圖像生成方法包括ControlNet、Sketch-Guided Diffusion,以及DiffSketching。
雖然現(xiàn)有的草圖到圖像方法有著很大優(yōu)勢,但它們有一個關(guān)鍵缺陷:被訓(xùn)練來處理完成的草圖。
然而,典型的草圖工作流程是一個迭代的進行中的工作!
藝術(shù)家逐步添加或刪除線條,有時在深入到更精細的細節(jié)之前構(gòu)建基本結(jié)構(gòu),有時在移動到另一個區(qū)域之前專注于圖像的一個區(qū)域。
因此,我們需要在草圖繪制過程的階段,實現(xiàn)草圖到圖像的功能。
在Sketch-a-Sketch中,研究人員引入了一個ControlNet模型,該模型生成以部分草圖為條件的圖像。
有了ControlNet,Sketch-a-Sketch可以:
1)在草圖過程的各個階段生成與草圖相對應(yīng)的圖像
2)利用這些圖像生成有助于指導(dǎo)藝術(shù)過程的建議草圖

問題:現(xiàn)有方法不適用于部分草圖
以前的研究是在圖像和完成草圖的配對數(shù)據(jù)集上訓(xùn)練的。
在嘗試根據(jù)部分草圖生成圖像時,這些方法會將草圖視為已完成的草圖。
因此草圖其余部分的空白會被視為一個指標,表明圖像不應(yīng)包含通常與輸入草圖中的筆畫相對應(yīng)的內(nèi)容。
例如,給定房子的前幾條線,ControlNet無法在繪制線的區(qū)域之外生成重要的細節(jié):


在這些草圖中,與線條相對應(yīng)的特征出現(xiàn)在生成的圖像中:支撐屋頂?shù)闹印跅U的頂部、門廊的底部等。
然而,在草圖僅包含空白的區(qū)域,也存在大量主要的圖像特征。
訓(xùn)練數(shù)據(jù):通過隨機刪除線條制作部分草圖
Photo-Sketch 是現(xiàn)有的最大數(shù)據(jù)集,其中包含文本描述圖像,與部分完成階段的草圖配對的數(shù)據(jù)集。
然而,該數(shù)據(jù)集存在以下不足:
1)僅限于 1000 張圖片的草圖;
2)所有圖片均為室外場景(缺乏多樣性,無法生成一般的文本條件);
3)通過對現(xiàn)有圖片進行描摹來構(gòu)建(強加了筆畫順序,可能與許多藝術(shù)家的畫圖過程不符)。
因此,我們以編程方式構(gòu)建了自己的數(shù)據(jù)集,其中包含與部分草圖配對的帶描述圖像。
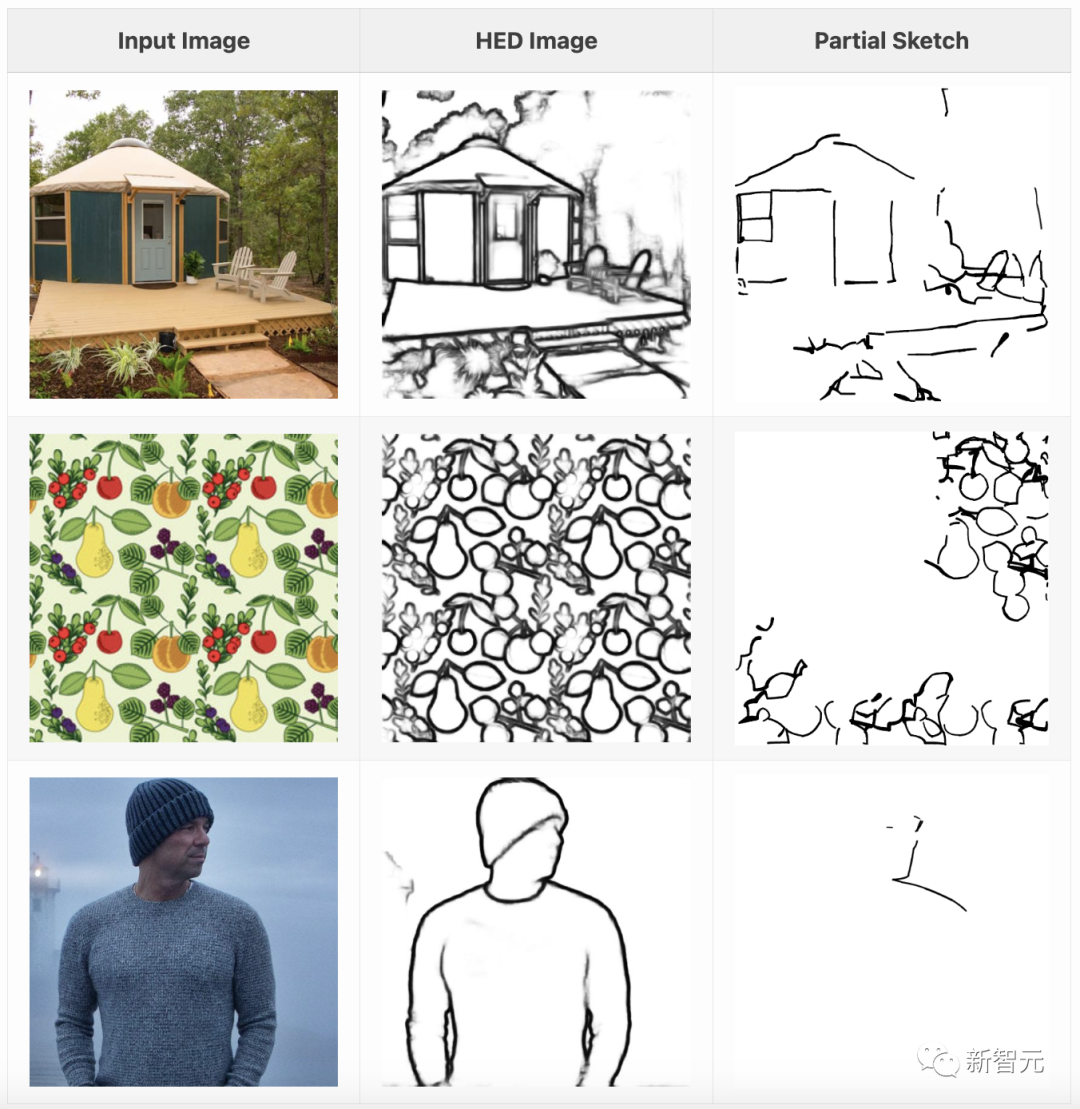
斯坦福研究人員的方法是:1)使用HED將圖像轉(zhuǎn)換為光柵化邊緣圖;2)將邊緣圖矢量化為筆畫集合;3)隨機刪除部分筆畫。
通過以任意順序刪除筆畫,我們還能以任意順序繪制的筆畫為條件生成圖像,從而適應(yīng)各種草圖風(fēng)格。
研究人員使用來自LAION Art的45000張圖片構(gòu)建了配對數(shù)據(jù)集,并對ControlNet模型進行了訓(xùn)練,以便在圖片-草圖配對上調(diào)節(jié)Stable Diffusion 1.5。
訓(xùn)練好的模型將文字說明和部分草圖作為輸入,并輸出與可能完成的草圖相對應(yīng)的生成圖像。
需要注意的是,通過對許多不同完整程度的隨機部分草圖進行訓(xùn)練,模型學(xué)會了將任何完整程度的草圖轉(zhuǎn)換成最終圖像。
這就意味著,模型并不假定你繪制線條的順序。
你可以按照任何順序繪制線條,????????????-??-????????????仍會根據(jù)草圖的當前狀態(tài)生成圖像。
生成你想要的圖像
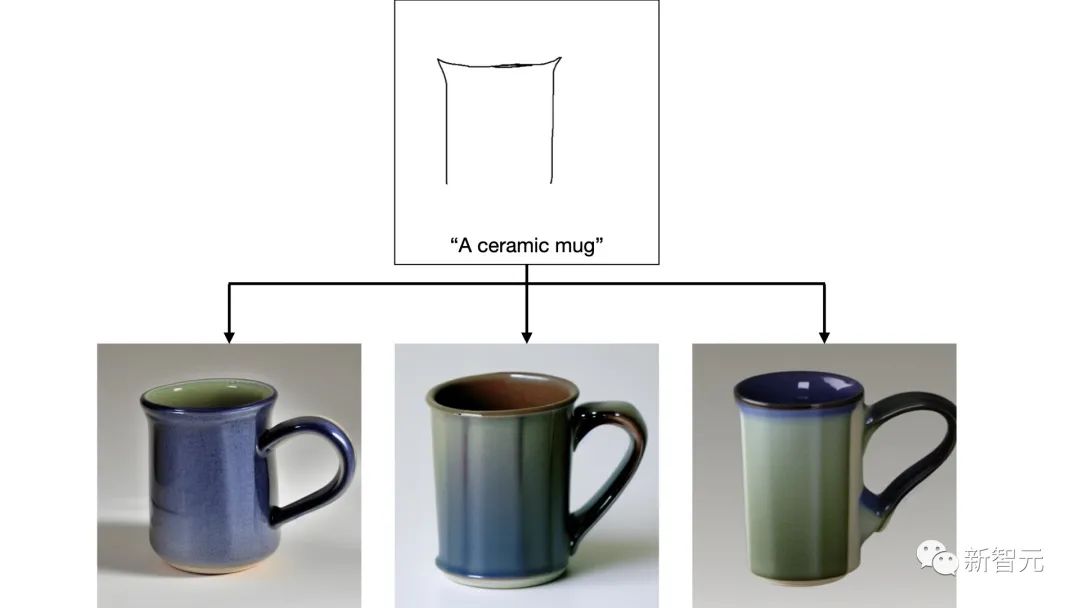
當藝術(shù)家不太確定他們想如何繪制圖像的一部分時,可以根據(jù)繪制的線條生成各種圖像完成。
比如,不太確定他們想如何繪制杯子的把手,所以????????????-??-????????????生成了3張圖像:
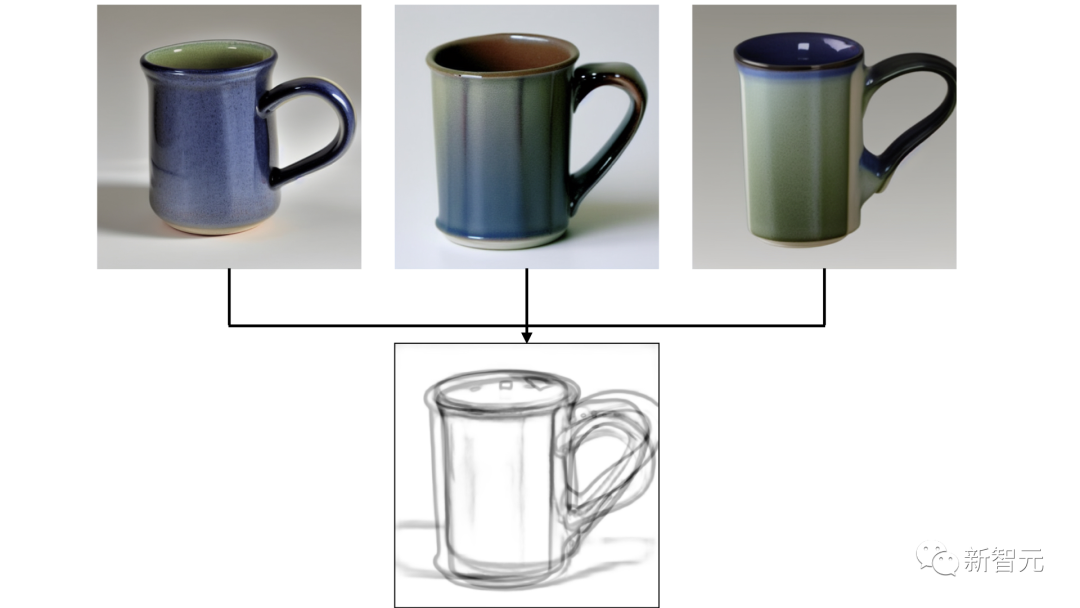
有了這些生成的圖像,Sketch-a-Sketch可以為潛在的繪制線條提供建議。
通過在生成的圖像上運行HED,來生成現(xiàn)有繪圖的潛在補全,然后就可以獲得建議線條的圖像:
風(fēng)格可控
圖像說明和底層擴散骨架會對圖像可視化和建議線條產(chǎn)生重大影響。
與其他文本控制擴散應(yīng)用一樣,????????????-??-????????????可以通過提示來修改生成圖像的風(fēng)格或內(nèi)容。
在下面的圖中,可以通過更改一個單詞來控制一輛跑車的可視化風(fēng)格:
提示:跑車,逼真

提示:跑車,卡通

提示:跑車,陰影

提示:跑車,生銹

之前已經(jīng)看到過,在一個骨干網(wǎng)(Stable Diffusion 1.5)上訓(xùn)練過的ControlNet在該骨干網(wǎng)的微調(diào)版本上仍然有效。
這一特性同樣適用于部分草圖ControlNet模型,使Sketch-a-Sketch能夠從針對特定領(lǐng)域進行微調(diào)的模型中生成建議。
例如,我們可以使用吉卜力擴散生成吉卜力風(fēng)格的角色:

作者介紹
Vishnu Sarukkai
Vishnu Sarukkai是斯坦福大學(xué)的博士生,導(dǎo)師是Chris Ré和Kayvon Fatahalian。他曾在斯坦福大學(xué)獲得了計算機學(xué)士學(xué)位。
他的研究興趣包括機器學(xué)習(xí)和計算機圖形學(xué),最近的研究主要集中在可控擴散模型上。
Christopher Ré
斯坦福人工智能實驗室(SAIL)、基礎(chǔ)模型研究中心(CRFM)和機器學(xué)習(xí)小組(生物)的副教授。

Kayvon Fatahalian
Kayvon Fatahalian的團隊創(chuàng)建了支持高級計算機圖形和視頻理解應(yīng)用程序的計算系統(tǒng)(通常是高性能和并行的)。最近的研究工作包括,用于「AI訓(xùn)練」的虛擬環(huán)境的高性能模擬。

關(guān)注公眾號【機器學(xué)習(xí)與AI生成創(chuàng)作】,更多精彩等你來讀
臥剿,6萬字!30個方向130篇!CVPR 2023 最全 AIGC 論文!一口氣讀完
深入淺出stable diffusion:AI作畫技術(shù)背后的潛在擴散模型論文解讀
深入淺出ControlNet,一種可控生成的AIGC繪畫生成算法!
 戳我,查看GAN的系列專輯~!
戳我,查看GAN的系列專輯~!
附下載 |《TensorFlow 2.0 深度學(xué)習(xí)算法實戰(zhàn)》
附下載 |《計算機視覺中的數(shù)學(xué)方法》分享
《基于深度神經(jīng)網(wǎng)絡(luò)的少樣本學(xué)習(xí)綜述》
《禮記·學(xué)記》有云:獨學(xué)而無友,則孤陋而寡聞
點擊一杯奶茶,成為AIGC+CV視覺的前沿弄潮兒!,加入 AI生成創(chuàng)作與計算機視覺 知識星球!