
日處理200億+調用,單機QPS高峰達到4萬+,喜馬拉雅自研 API 網(wǎng)關架構實踐
點擊上方藍色“小哈學Java”,選擇“設為星標” 回復“資源”獲取獨家整理的學習資料!

網(wǎng)關是一個比較成熟了的產品,基本上各大互聯(lián)網(wǎng)公司都會有網(wǎng)關這個中間件,來解決一些公有業(yè)務的上浮,而且能快速的更新迭代,如果沒有網(wǎng)關,要更新一個公有特性,就要推動所有業(yè)務方都更新和發(fā)布,那是效率極低的事,有網(wǎng)關后,這一切都變得不是問題,喜馬拉雅也是一樣,用戶數(shù)增長達到6億多的級別,Web服務個數(shù)達到500+,目前我們網(wǎng)關日處理200億加次調用,單機QPS高峰達到4w+。
網(wǎng)關除了要實現(xiàn)最基本的功能反向代理外,還有公有特性,比如黑白名單,流控,鑒權,熔斷,API發(fā)布,監(jiān)控和報警等,我們還根據(jù)業(yè)務方的需求實現(xiàn)了流量調度,流量Copy,預發(fā)布,智能化升降級,流量預熱等相關功能,下面就我們網(wǎng)關在這些方便的一些實踐經驗以及發(fā)展歷程,下面是喜馬拉雅網(wǎng)關的演化過程:

第一版 Tomcat nio + AsyncServlet
網(wǎng)關在架構設計時最為關鍵點,就是網(wǎng)關在接收到請求,調用后端服務時不能阻塞Block,否則網(wǎng)關的吞吐量很難上去,因為最耗時的就是調用后端服務這個遠程調用過程,如果這里是阻塞的,那你的tomcat的工作線程都block主了,在等待后端服務響應的過程中,不能去處理其他的請求,這個地方一定要異步
架構圖如下:
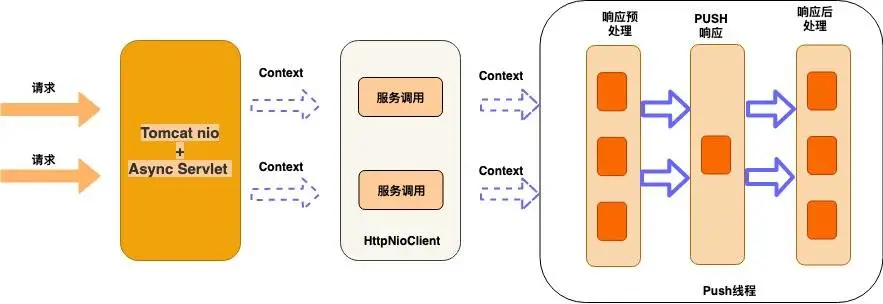
這版我們實現(xiàn)單獨的Push層,作為網(wǎng)關收到響應后,響應客戶端時,通過這層實現(xiàn),和后端服務的通信是HttpNioClient,對業(yè)務的支持黑白名單,流控,鑒權,API發(fā)布等功能,這版只是功能上達到網(wǎng)關的邀請,但是處理能力很快就成了瓶頸,單機qps到5k的時候,就會不停的full gc,后面通過dump 線上的堆分析,發(fā)現(xiàn)全是tomcat緩存了很多http的請求,因為tomcat默認會緩存200個requestProcessor,每個prcessor都關聯(lián)了一個request,還有就是servlet3.0 tomcat的異步實現(xiàn)會出現(xiàn)內存泄漏,后面通過減少這個配置,效果明顯。但性能肯定就下降了,總結了下,基于tomcat做為接入端,有如下幾個問題:
Tomcat自身的問題
緩存太多,tomcat用了很多對象池技術,內存有限的情況下,流量一高很容易觸發(fā)gc。 內存copy,tomcat的默認是用堆內存,所以數(shù)據(jù)需要讀到堆內,而我們后端服務是netty,有堆外內存,需要通過數(shù)次copy。 tomcat 還有個問題是讀body是阻塞的,tomcat 的nio模型和reactor模型不一樣,讀body是block的。
HttpNioClient的問題
獲取和釋放鏈接都需要加鎖,對應網(wǎng)關這樣的代理服務場景,會頻繁的建鏈和關閉鏈接,勢必會影響性能。
基于tomcat的存在的這些問題,我們后面對接入端做改造,用Netty做接入層和服務調用層,也就是我們的第二版,能徹底解決上面的問題,達到理想的性能。
第二版 Netty + 全異步
基于Netty的優(yōu)勢,我們實現(xiàn)了全異步,無鎖,分層的架構
先看下我們基于Netty做接入端的架構圖
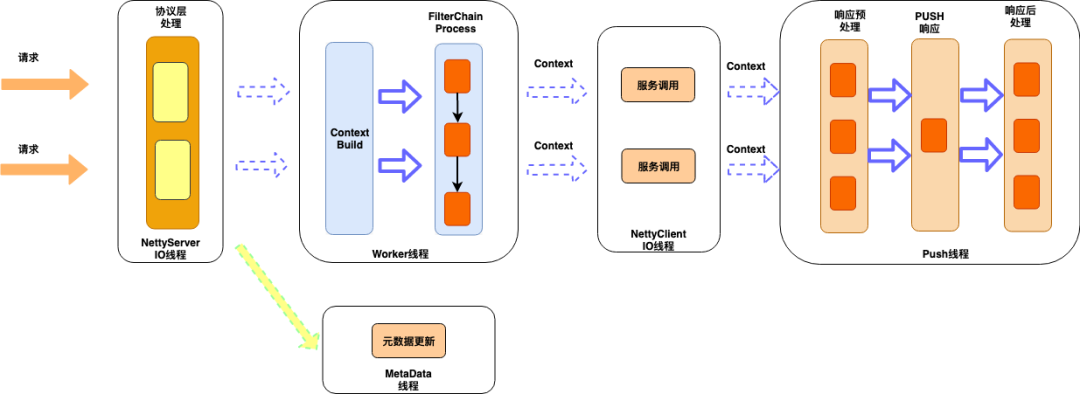
接入層
Netty的io線程,負責http協(xié)議的編解碼工作,同時對協(xié)議層面的異常做監(jiān)控報警
對http協(xié)議的編解碼做了優(yōu)化,對異常,攻擊性請求監(jiān)控可視化,比如我們對http的請求行和請求頭大小是有限制的,tomcat是請求行和請求加在一起,不超過8k,netty是分別有大小限制,假如客戶端發(fā)送了超過閥值的請求,帶cookie的請求很容易超過,正常情況下,netty就直接響應400給客戶端,經過改造后,我們只取正常大小的部分,同時標記協(xié)議解析失敗,到業(yè)務層后,就可以判斷出是那個服務出現(xiàn)這類問題,其他的一些攻擊性的請求,比如只發(fā)請求頭,不發(fā)body/或者發(fā)部分這些都需要監(jiān)控和報警。
業(yè)務邏輯層
負責對API路由,流量調度等一序列的支持業(yè)務的公有邏輯,都在這層實現(xiàn),采樣責任鏈模式,這層不會有io操作。
在業(yè)界和一些大廠的網(wǎng)關設計中,業(yè)務邏輯層基本都是設計成責任鏈模式,公有的業(yè)務邏輯也在這層實現(xiàn),我們在這層也是相同的套路,支持了:
用戶鑒權和登陸校驗 ,支持接口級別配置 黑白明單 ,分全局和應用,以及ip維度,參數(shù)級別 流量控制 ,支持自動和手動,自動是對超大流量自動攔截,通過令牌桶算法實現(xiàn) 智能熔斷 ,在histrix的基礎上做了改進,支持自動升降級,我們是全部自動的,也支持手動配置立即熔斷,就是發(fā)現(xiàn)服務異常比例達到閥值,就自動觸發(fā)熔斷 灰度發(fā)布 ,我對新啟動的機器的流量支持類似tcp的慢啟動機制,給 機器一個預熱的時間窗口 統(tǒng)一降級 ,我們對所有轉發(fā)失敗的請求都會找統(tǒng)一降級的邏輯,只要業(yè)務方配了降級規(guī)則,都會降級,我們對降級規(guī)則是支持到參數(shù)級別的,包含請求頭里的值,是非常細粒度的,另外我們還會和varnish打通,支持varish的優(yōu)雅降級 流量調度 ,支持業(yè)務根據(jù)篩選規(guī)則,對流量篩選到對應的機器,也支持只讓篩選的流量訪問這臺機器,這在查問題/新功能發(fā)布驗證時非常用,可以先通過小部分流量驗證再大面積發(fā)布上線。 流量copy ,我們支持對線上的原始請求根據(jù)規(guī)則copy一份,寫入到mq或者其他的upstream,來做線上跨機房驗證和壓力測試。 請求日志采樣 ,我們對所有的失敗的請求都會采樣落盤,提供業(yè)務方排查問題支持,也支持業(yè)務方根據(jù)規(guī)則進行個性化采樣,我們采樣了整個生命周期的數(shù)據(jù),包含請求和響應相關的所有數(shù)據(jù)。
上面提到的這么多都是對流量的治理,我們每個功能都是一個filter,處理失敗都不影響轉發(fā)流程,而且所有的這些規(guī)則的元數(shù)據(jù)在網(wǎng)關啟動時就會全部初始化好,在執(zhí)行的過程中,不會有IO操作,目前有些設計會對多個filter做并發(fā)執(zhí)行,由于我們的都是內存操作,開銷并不大,所以我們目前并沒有支持并發(fā)執(zhí)行,還有個就是規(guī)則會修改,我們修改規(guī)則時,會通知網(wǎng)關服務,做實時刷新,我們對內部自己的這種元數(shù)據(jù)更新的請求,通過獨立的線程處理,防止io在操作時影響業(yè)務線程。
服務調用層
服務調用對于代理網(wǎng)關服務是關鍵的地方,一定需要異步,我們通過netty實現(xiàn),同時也很好的利用了netty提供的鏈接池,做到了獲取和釋放都是無鎖操作
異步Push
網(wǎng)關在發(fā)起服務調用后,讓工作線程繼續(xù)處理其他的請求,而不需要等待服務端返回,這里的設計是我們?yōu)槊總€請求都會創(chuàng)建一個上下文,我們在發(fā)完請求后,把該請求的context 綁定到對應的鏈接上,等netty收到服務端響應時,就會在給鏈接上執(zhí)行read操作,解碼完后,再從給鏈接上獲取對應的context,通過context可以獲取到接入端的session,這樣push就通過session把響應寫回客戶端了,這樣設計也是基于http的鏈接是獨占的,即鏈接可以和請求上下文綁定。
鏈接池
鏈接池的原理如下圖:
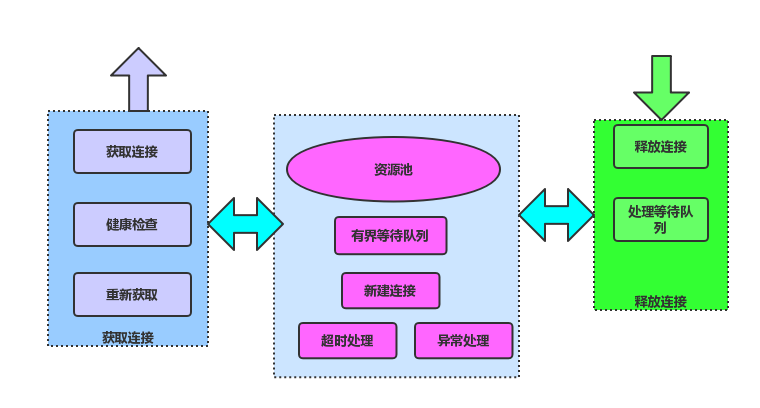
服務調用層除了異步發(fā)起遠程調用外,還需要對后端服務的鏈接進行管理,http不同于rpc,http的鏈接是獨占的,所以在釋放的時候要特別小心,一定要等服務端響應完了才能釋放,還有就是鏈接關閉的處理也要小心,總結如下幾點:
Connection:close 空閑超時,關閉鏈接 讀超時關閉鏈接 寫超時,關閉鏈接 Fin,Reset
上面幾種需要關閉鏈接的場景,下面主要說下Connection:close和空閑寫超時兩種,其他的應該是比較常見的比如讀超時,鏈接空閑超時,收到fin,reset碼這幾個。
Connection:close
后端服務是tomcat,tomcat對鏈接重用的次數(shù)是有限制的,默認是100次,當達到100次后,tomcat會通過在響應頭里添加Connection:close,讓客戶端關閉該鏈接,否則如果再用該鏈接發(fā)送的話,會出現(xiàn)400。
還有就是如果端上的請求帶了connection:close,那tomcat就不等這個鏈接重用到100次,即一次就關閉,通過在響應頭里添加Connection:close,即成了短鏈接, 這個在和tomcat保持長鏈接時,需要注意的,如果要利用,就要主動remove掉這個close頭。
寫超時
首先網(wǎng)關什么時候開始計算服務的超時時間,如果從調用writeAndFlush開始就計算,這其實是包含了netty對http的encode時間和從隊列里把請求發(fā)出去即flush的時間,這樣是對后端服務不公平的,所以需要在真正flush成功后開始計時,這樣是和服務端最接近的,當然還包含了網(wǎng)絡往返時間和內核協(xié)議棧處理的時間,這個不可避免,但基本不變。
所以我們是flush成功回調后開始啟動超時任務,這里就有個注意的地方,如果flush不能快速回調,比如來了一個大的post請求,body部分比較大,而netty發(fā)送的時候第一次默認是發(fā)1k的大小,如果還沒有發(fā)完,則增大發(fā)送的大小繼續(xù)發(fā),如果在netty在16次后還沒有發(fā)送完成,則不會再繼續(xù)發(fā)送,而是提交一個flushTask到任務隊列,待下次執(zhí)行到后再發(fā)送,這時flush回調的時間就比較大,導致這樣的請求不能及時關閉,而且后端服務tomcat會一直阻塞在讀body的地方,基于上面的分析,所以我們需要一個寫超時,對大的body請求,通過寫超時來及時關閉。
全鏈路超時機制
下面是我們在整個鏈路種一個超時處理的機制。

協(xié)議解析超時 等待隊列超時 建鏈超時 等待鏈接超時 寫前檢查是否超時 寫超時 響應超時
監(jiān)控報警
網(wǎng)關業(yè)務方能看到的是監(jiān)控和報警,我們是實現(xiàn)秒級別報警和秒級別的監(jiān)控,監(jiān)控數(shù)據(jù)定時上報給我們的管理系統(tǒng),由管理系統(tǒng)負責聚合統(tǒng)計,落盤到influxdb
我們對http協(xié)議做了全面的監(jiān)控和報警,無論是協(xié)議層的還是服務層的
協(xié)議層
攻擊性請求,只發(fā)頭,不發(fā)/發(fā)部分body,采樣落盤,還原現(xiàn)場,并報警 Line or Head or Body過大的請求,采樣落盤,還原現(xiàn)場,并報警
應用層
耗時監(jiān)控,有慢請求,超時請求,以及tp99,tp999等 qps監(jiān)控和報警 帶寬監(jiān)控和報警,支持對請求和響應的行,頭,body單獨監(jiān)控。 響應碼監(jiān)控,特別是400,和404 鏈接監(jiān)控,我們對接入端的鏈接,以及和后端服務的鏈接,后端服務鏈接上待發(fā)送字節(jié)大小也都做了監(jiān)控 失敗請求監(jiān)控 流量抖動報警,這是非常有必要的,流量抖動要么是出了問題,要么就是出問題的前兆。
總體架構
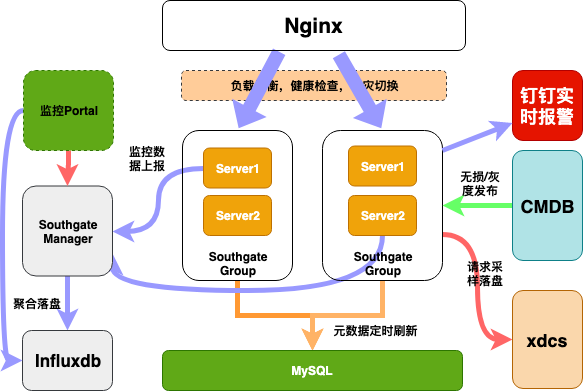
性能優(yōu)化實踐
對象池技術
對于高并發(fā)系統(tǒng),頻繁的創(chuàng)建對象不僅有分配內存的開銷外,還有對gc會造成壓力,我們在實現(xiàn)時會對頻繁使用的比如線程池的任務task,StringBuffer等會做寫重用,減少頻繁的申請內存的開銷。
上下文切換
高并發(fā)系統(tǒng),通常都采用異步設計,異步化后,不得不考慮線程上下文切換的問題,我們的線程模型如下:
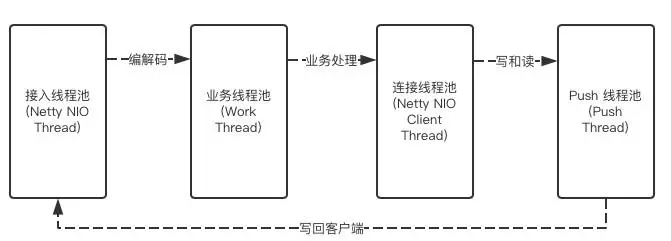
我們整個網(wǎng)關沒有涉及到io操作,但我們在業(yè)務邏輯這塊還是和netty的io編解碼線程異步,是有兩個原因,1是防止開發(fā)寫的代碼有阻塞,2是業(yè)務邏輯打日志可能會比較多,在突發(fā)的情況下,但是我們在push線程時,支持用netty的io線程替代,這里做的工作比較少,這里有異步修改為同步后(通過修改配置調整),cpu的上下文切換減少20%,進而提高了整體的吞吐量,就是不能為了異步而異步,zull2的設計和我們的類似,
GC優(yōu)化
在高并發(fā)系統(tǒng),gc的優(yōu)化不可避免,我們在用了對象池技術和堆外內存時,對象很少進入老年代,另外我們年輕代會設置的比較大,而且SurvivorRatio=2,晉升年齡設置最大15,盡量對象在年輕代就回收掉, 但監(jiān)控發(fā)現(xiàn)老年代的內存還是會緩慢增長,通過dump分析,我們每個后端服務創(chuàng)建一個鏈接,都時有一個socket,socket的AbstractPlainSocketImpl,而AbstractPlainSocketImpl就重寫了Object類的finalize方法,實現(xiàn)如下:
/**
* Cleans up if the user forgets to close it.
*/
protected void finalize() throws IOException {
close();
}
是為了我們沒有主動關閉鏈接,做的一個兜底,在gc回收的時候,先把對應的鏈接資源給釋放了,由于finalize的機制是通過jvm的Finalizer線程來處理的,而且Finalizer線程的優(yōu)先級不高,默認是8,需要等到Finalizer線程把ReferenceQueue的對象對于的finalize方法執(zhí)行完,還要等到下次gc時,才能把該對象回收,導致創(chuàng)建鏈接的這些對象在年輕代不能立即回收,從而進入了老年代,這也是為啥老年代會一直緩慢增長的問題。
日志
高并發(fā)下,特別是netty的io線程除了要執(zhí)行該線程上的io讀寫操作,還有執(zhí)行異步任務和定時任務,如果io線程處理不過來隊列里的任務,很有可能導致新進來異步任務出現(xiàn)被拒絕的情況,那什么情況下可能呢,io是異步讀寫的問題不大,就是多耗點cpu,最有可能block住io線程的是我們打的日志,目前l(fā)og4j的ConsoleAppender日志immediateFlush屬性默認為true,即每次打log都是同步寫flush到磁盤的,這個對于內存操作來說,慢了很多,同時AsyncAppender的日志隊列滿了也會block住線程,log4j默認的buffer大小是128,而且是block的,即如果buffer的大小達到128,就阻塞了寫日志的線程,在并發(fā)寫日志量大的的情況下,特別是堆棧很多時,log4j的Dispatcher線程會出現(xiàn)變慢要刷盤,這樣buffer就不能快速消費,很容易寫滿日志事件,導致netty io線程block住,所以我們在打日志時,也要注意精簡。
未來規(guī)劃
現(xiàn)在我們都是基于http1,現(xiàn)在http2相對于http1關鍵實現(xiàn)了在鏈接層面的服務,即一個鏈接上可以發(fā)送多個http請求,即http的鏈接也能和rpc的鏈接一樣,建幾個鏈接就可以了,徹底解決了http1鏈接不能復用導致每次都建鏈和慢啟動的開銷,我們也在基于netty升級到http2,除了技術升級外,我們對監(jiān)控報警也一直在持續(xù)優(yōu)化,怎么提供給業(yè)務方準確無誤的報警,也是一直在努力,還有一個就是降級,作為統(tǒng)一接入網(wǎng)關,和業(yè)務方做好全方位的降級措施,也是一直在完善的點,保證全站任何故障都能通過網(wǎng)關第一時間降級,也是我們的重點。
總結
網(wǎng)關已經是一個互聯(lián)網(wǎng)公司的標配,這里總結實踐過程中的一些心得和體會,希望給大家一些參考以及一些問題的解決思路,我們也還在不斷完善中,同時我們也在做多活的項目,感興趣的同學可以加入我們。
1. JDK 8 Stream 數(shù)據(jù)流效率怎么樣?
2. 又發(fā)現(xiàn)一款牛逼的 API 敏捷開發(fā)工具
3. 發(fā)現(xiàn)一個很奇怪的現(xiàn)象,MyBaits 的 insert方法一直返回"-2147482646"
最近面試BAT,整理一份面試資料《Java面試BATJ通關手冊》,覆蓋了Java核心技術、JVM、Java并發(fā)、SSM、微服務、數(shù)據(jù)庫、數(shù)據(jù)結構等等。
獲取方式:點“在看”,關注公眾號并回復 Java 領取,更多內容陸續(xù)奉上。
文章有幫助的話,在看,轉發(fā)吧。
謝謝支持喲 (*^__^*)
