
基于 Kubernetes 的云原生 AI 平臺建設
作者:
黃河 極視角科技技術合伙人
霍秉杰 KubeSphere 資深架構師 / KubeSphere 可觀測性及 Serverless 產(chǎn)品負責人 / OpenFunction 發(fā)起人
人工智能與 Kubernetes
在國外眾多知名網(wǎng)站 2021 年對 Kubernetes 的預測中,人工智能技術與 Kubernetes 的更好結合通常都名列其中。Kubernetes 以其良好的擴展和分布式特性,以及強大的調度能力成為運行 DL/ML 工作負載的理想平臺。

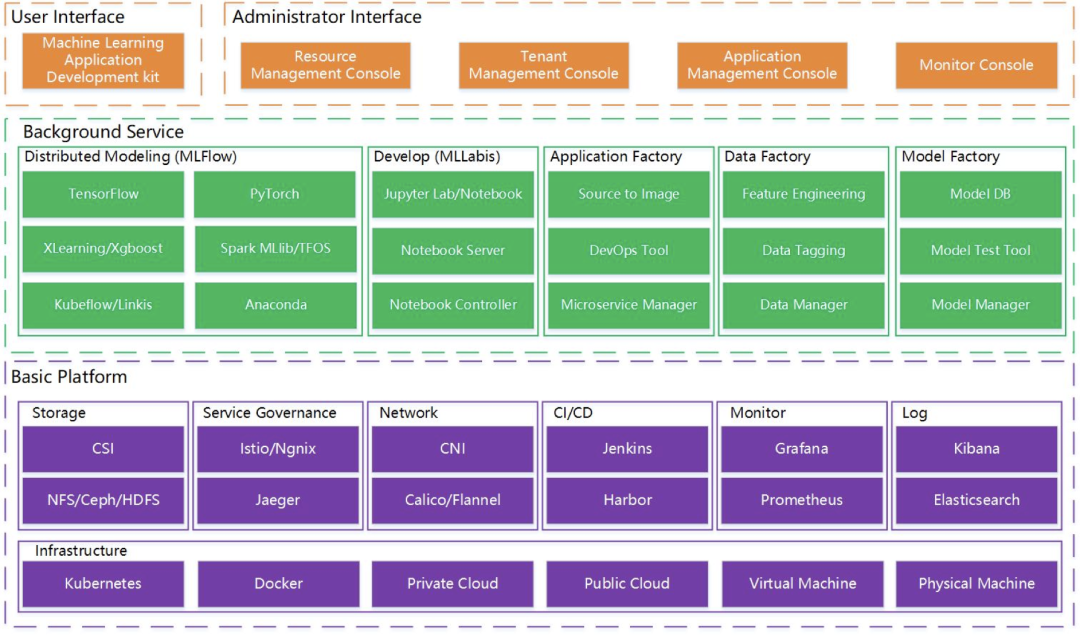
上面是微眾銀行開源的機器學習平臺 Prophecis 的架構圖,我們可以看到綠色的部分是機器學習平臺通常都會有的功能包括訓練、開發(fā)、模型、數(shù)據(jù)和應用的管理等功能。而通常這些機器學習平臺都是運行在 Kubernetes 之上的,如紫色的部分所示:最底層是 Kubernetes,再往上是容器管理平臺 (微眾銀行的開發(fā)者曾在 KubeSphere 2020 Meetup 北京站上提到這里采用的是 KubeSphere),容器管理平臺在 Kubernetes 之上提供了存儲、網(wǎng)絡、服務治理、CI/CD、以及可觀測性方面的能力。
Kubernetes 很強大,但通常在 Kubernetes 上運行 AI 的工作負載還需要更多非 K8s 原生能力的支持比如:
用戶管理: 涉及多租戶權限管理等 多集群管理 圖形化 GPU 工作負載調度 GPU 監(jiān)控 訓練、推理日志管理 Kubernetes 事件與審計 告警與通知
具體來說 Kubernetes 并沒有提供完善的用戶管理能力,而這是一個企業(yè)級機器學習平臺的剛需;同樣原生的 Kubernetes 也并沒有提供多集群管理的能力,而用戶有眾多 K8s 集群需要統(tǒng)一管理;運行 AI 工作負載需要用到 GPU,昂貴的 GPU 需要有更好的監(jiān)控及調度才能提高 GPU 利用率并節(jié)省成本;AI 的訓練需要很長時間才能完成,從幾個小時到幾天不等,通過容器平臺提供的日志系統(tǒng)可以更容易地看到訓練進度;容器平臺事件管理可以幫助開發(fā)者更好地定位問題;容器平臺審計管理可以更容易地獲知誰對哪些資源做了什么操作,讓用戶對整個容器平臺有深入的掌控。
總的來說,K8s 就像 Linux/Unix, 但用戶仍然需要 Ubuntu 或 Mac 。KubeSphere 是企業(yè)級分布式多租戶容器平臺,本質上是一個現(xiàn)代的分布式操作系統(tǒng)。KubeSphere 在 Kubernetes 之上提供了豐富的平臺能力如用戶管理、多集群管理、可觀測性、應用管理、微服務治理、CI/CD等。
如何利用 Kubernetes 和 KubeSphere 構建機器學習平臺
極棧平臺是一個面向企業(yè)或機構的機器學習服務平臺,提供從數(shù)據(jù)處理、模型訓練、模型測試到模型推理的 AI 全生命周期管理服務,致力于幫助企業(yè)或機構迅速構建 AI 算法開發(fā)與應用能力。平臺提供低代碼開發(fā)與自動化測試功能,支持任務智能調度與資源智能監(jiān)控,幫助企業(yè)全面提升 AI 算法開發(fā)效率,降低 AI 算法應用與管理成本,快速實現(xiàn)智能化升級。
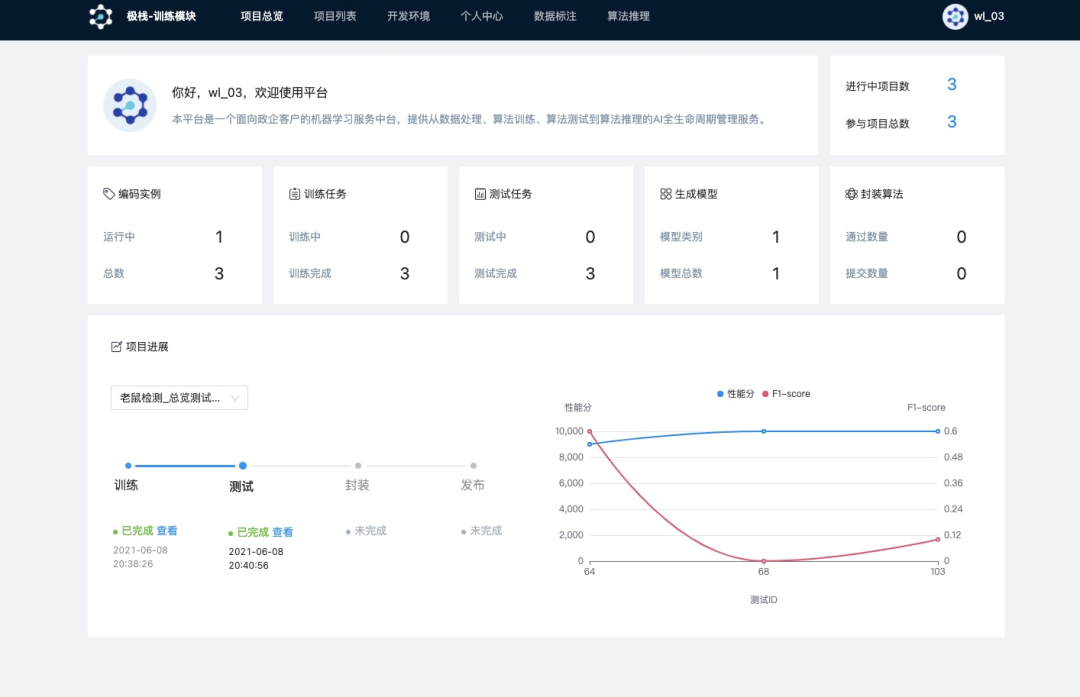
極棧 AI 平臺迭代演變的挑戰(zhàn)
在使用 Kubernetes 之前,平臺使用 Docker 掛載指定 GPU 來分配算力,容器內置 Jupyter 在線 IDE 實現(xiàn)和開發(fā)者交互,開發(fā)者在分配的容器內完成訓練測試代碼編寫、模型訓練,當時存在四個問題需要解決:
算力利用率低:開發(fā)者在編碼時,GPU 僅僅用于代碼調試;同時開發(fā)者需手動開啟或者關閉環(huán)境,如果開發(fā)者訓練結束未關閉環(huán)境,將繼續(xù)占用算力資源。以算法大賽的場景為例,算力利用率平均在 50%,算力資源浪費嚴重。 存儲運維成本高:平臺使用 Ceph 來存儲數(shù)據(jù)集、代碼,比如容器掛載了 Ceph 的塊存儲來持久化存儲開發(fā)環(huán)境,方便再次使用時能在其他node還原。在大量開發(fā)者使用時,出現(xiàn)掛載卷釋放不了、容器無法停止等問題,影響開發(fā)者使用。 數(shù)據(jù)集安全無法保障:商用算法數(shù)據(jù)集往往涉密,需要實現(xiàn)數(shù)據(jù)所有權和使用權分離,比如許多大型政企開發(fā)算法往往外包給專業(yè)的 AI 公司。怎么讓外部 AI 公司的算法工程師在既能完成算法開發(fā),又能不接觸到數(shù)據(jù)集,是政企算法平臺客戶的迫切需求。 算法測試人力成本高:對于算法開發(fā)者提交的算法,要對精度和性能等指標進行評測,達到算法需求方要求的精度和性能指標后方可上線。還是以算法大賽的場景舉例,一般的 AI 平臺會提供訓練數(shù)據(jù)集、測試數(shù)據(jù)集給到用戶,用戶完成算法開發(fā)后,用算法跑測試集,將結果寫入到 CSV 文件里面和算法一起提交。對于獲獎的開發(fā)者,我們要還原開發(fā)者測試環(huán)境,重新用開發(fā)者的算法來跑測試集,并和開發(fā)者提交的 CSV 結果對比,確定 CSV 文件沒有被修改,保證比賽公平,這些都需要大量的測試人員參與,作為定位全棧 AI 開發(fā)的極棧平臺來說,要在平臺上開發(fā)萬千算法,急需降低測試的人工成本。
為解決這些問題,2018 年中決定引入 Kubernetes 對平臺進行重構,但當時團隊沒有精通 Kubernetes 的人員,Kubernetes 的學習成本也不低,重構進展受到一定影響;后來我們發(fā)現(xiàn)了由青云科技開源的容器管理平臺 KubeSphere,它把很多 Kubernetes 底層細節(jié)都屏蔽了,用戶只需要像用公有云一樣,用可視化的方式使用,可以降低使用 Kubernetes 的成本。同時社區(qū)的維護團隊也非常認真負責,最開始把 KubeSphere 部署到我們測試環(huán)境,集群運行一段時間會崩潰,開源社區(qū)的同學手把手幫助我們解決了問題,后來又陸續(xù)引入了 QingStor NeonSAN 來替代 Ceph,極大地提升了平臺穩(wěn)定性。

KubeSphere v3.0.0 支持了多集群管理、自定義監(jiān)控,提供了完善的事件、審計查詢及告警能力;KubeSphere v3.1.x 新增對 KubeEdge 邊緣節(jié)點管理的功能、新增多維度計量計費的能力、重構了告警系統(tǒng),提供了兼容 Prometheus 格式的告警設置、新增了包括企業(yè)微信/釘釘/郵件/Slack/Webhook 等眾多通知渠道、同時對應用商店和 DevOps 也進行了重構;還在開發(fā)當中的 KubeSphere v3.2 將對運行 AI 工作負載提供更好的支持包括 GPU 工作負載調度、GPU 監(jiān)控等;未來 KubeSphere v4.0.0 將升級為可插拔架構,前后端將都會獲得可插拔的能力,基于此可以構建可插拔到 KubeSphere 的機器學習平臺。

云原生 AI 平臺實踐
提高算力資源利用
GPU 虛擬化
首先針對開發(fā)者編碼算力利用率低的情況,我們將編碼和訓練算力集群分開,同時使用 GPU 虛擬化技術來更好利用 GPU 算力,這方面市場上已經(jīng)有成熟的解決方案。在技術調研之后,選擇了騰訊云開源的 GPUManager 作為虛擬化解決方案。
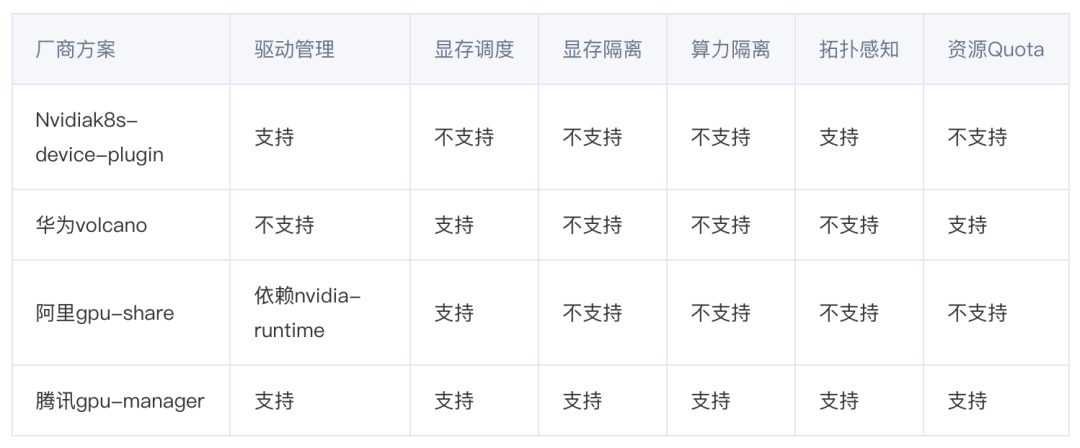
GPUManager 基于 GPU 驅動封裝實現(xiàn),用戶需要對驅動的某些關鍵接口(如顯存分配、cuda thread 創(chuàng)建等)進行封裝劫持,在劫持過程中限制用戶進程對計算資源的使用,整體方案較為輕量化、性能損耗小,自身只有 5% 的性能損耗,支持同一張卡上容器間 GPU 和顯存使用隔離,保證了編碼這種算力利用率不高的場景開發(fā)者可以共享 GPU,同時在同一塊調試時資源不會被搶占。
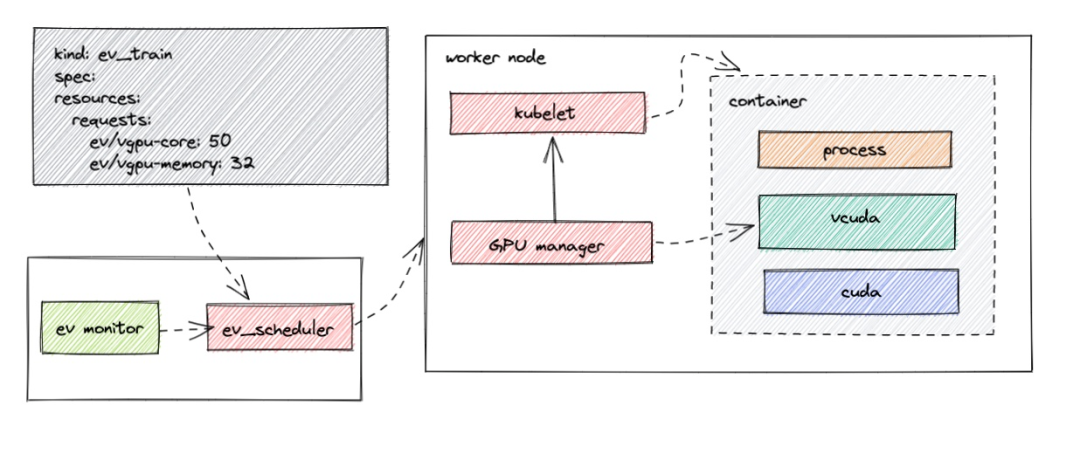
訓練集群算力調度
在 Kubernetes 里面使用 Job 來創(chuàng)建訓練任務,只需要指定需要使用的GPU資源,結合消息隊列,訓練集群算力資源利用率可以達到滿載。
resources:
requests:
nvidia.com/gpu: 2
cpu: 8
memory: 16Gi
limits:
nvidia.com/gpu: 2
cpu: 8
memory: 16Gi
資源監(jiān)控
資源監(jiān)控對集群編碼、訓練優(yōu)化有關鍵指導作用,KubeSphere 不僅能對 CPU 等傳統(tǒng)資源監(jiān)控,通過自定義監(jiān)控面板,簡單幾個步驟配置,便可順利完成可觀察性監(jiān)控,同時極棧平臺也在 Kubernetes 基礎上,按照項目等維度,可以限制每個項目 GPU 總的使用量和每個用戶 GPU 資源分配。
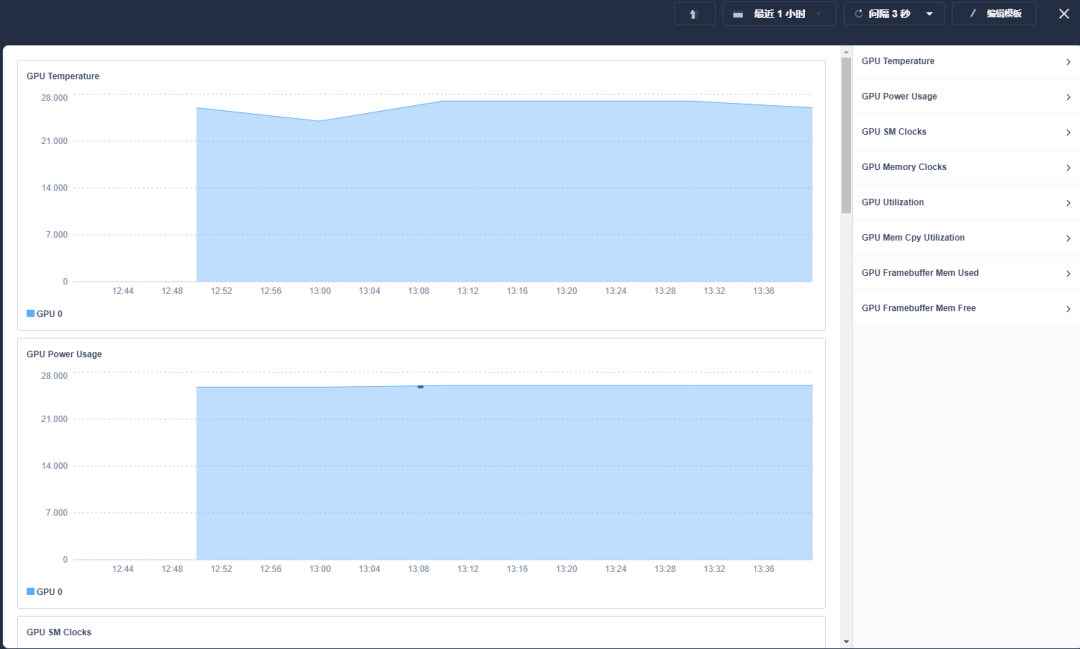
現(xiàn)在,比如算法大賽的場景,我們監(jiān)控到的 GPU 平均使用率在編碼集群達到了 70%,訓練集群達到了 95%。
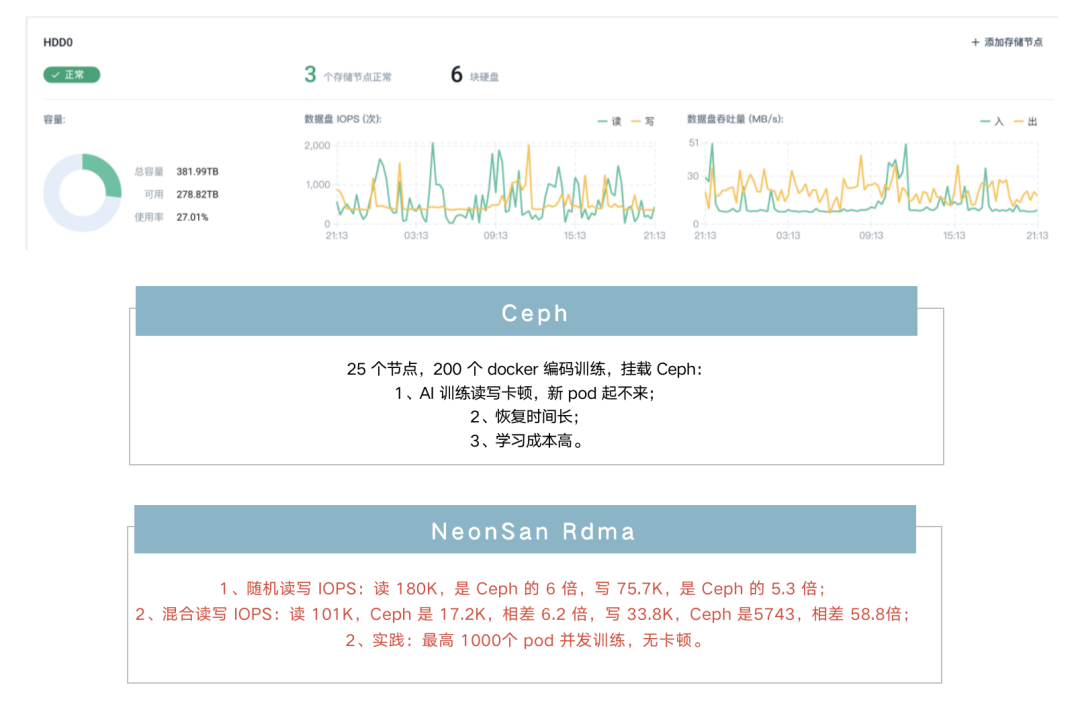
存儲:QingStor NeonSan Rdma
我們采用 NVMe SSD+25GbE(RDMA)的 NeonSAN 來替換開源的 Ceph,NeonSAN 的表現(xiàn)很驚艷:比如隨機讀寫的 IOPS,讀達到了 180K,是 Ceph 的 6 倍,寫也可以達到 75.7K,是Ceph 的 5.3倍,之后 AI 平臺最高 1000 個 Pod 并發(fā)訓練,沒有再出現(xiàn)存儲掛載卷釋放不了引起的卡頓問題。
數(shù)據(jù)集安全
我們做了數(shù)據(jù)安全沙箱來解決數(shù)據(jù)集安全的問題,數(shù)據(jù)安全沙箱實現(xiàn)了在不泄漏數(shù)據(jù)的同時,又能讓算法開發(fā)者基于客戶數(shù)據(jù)訓練模型和評估算法質量。
數(shù)據(jù)安全沙箱要解決兩個問題:
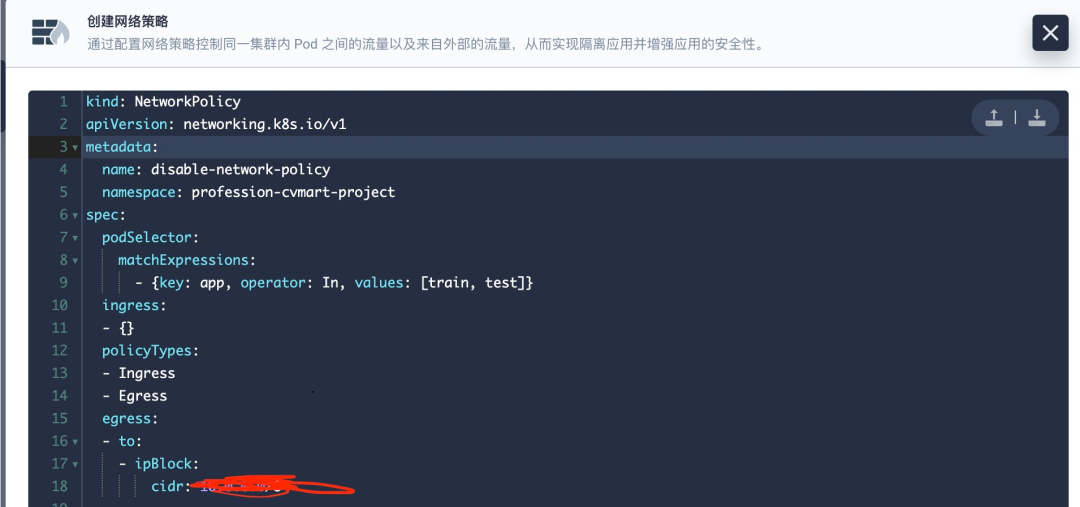
安全隔離問題:對外集群不能連通外網(wǎng),把數(shù)據(jù)傳出去;在平臺內部,可以通過程序把數(shù)據(jù)傳輸?shù)介_發(fā)者能夠訪問的環(huán)境。比如在開發(fā)者可以控制的編碼環(huán)境里面起個 http 服務接收訓練集群傳輸過來的訓練數(shù)據(jù)。KubeSphere 提供了基于租戶的可視化網(wǎng)絡安全策略管理,極大地降低了容器平臺在網(wǎng)絡層面的運維工作壓力。通過網(wǎng)絡策略,可以在同一集群內實現(xiàn)網(wǎng)絡隔離,這意味著可以在 Pod 之間設置防火墻,如果多個策略選擇了一個 Pod, 則該 Pod 受限于這些策略的入站(Ingress)/出站(Egress)規(guī)則的并集,它們不會沖突,所以這里只要設置一個限制訪問外網(wǎng)的策略和禁止訪問編碼 Pod 的策略即可。
訓練體驗問題:隔離之后,開發(fā)者要能夠實時知道訓練和測試狀態(tài),訓練和測試不能是一個黑箱,否則會極大影響模型訓練和算法測試效率,如下圖。
開發(fā)者發(fā)起訓練或者測試,任務在算力集群里面跑了起來,EFK 收集和存儲容器日志,針對不同數(shù)據(jù)集,可以設置不同等級的黑白名單過濾策略,防止圖片數(shù)據(jù)轉碼成日志泄露出來,比如高安全性數(shù)據(jù)集直接設置白名單日志展示。 我們開發(fā)了 EV_toolkit 可視化工具包,來查看訓練的指標如精度、損失函數(shù)(比如交叉熵)等,原理是訓練指標通過 toolkit 的 API 接口寫入到指定位置,再展示到界面上。 訓練監(jiān)控:支持無人值守訓練,錯誤消息通知,訓練進展定制化提醒,訓練結束通知。 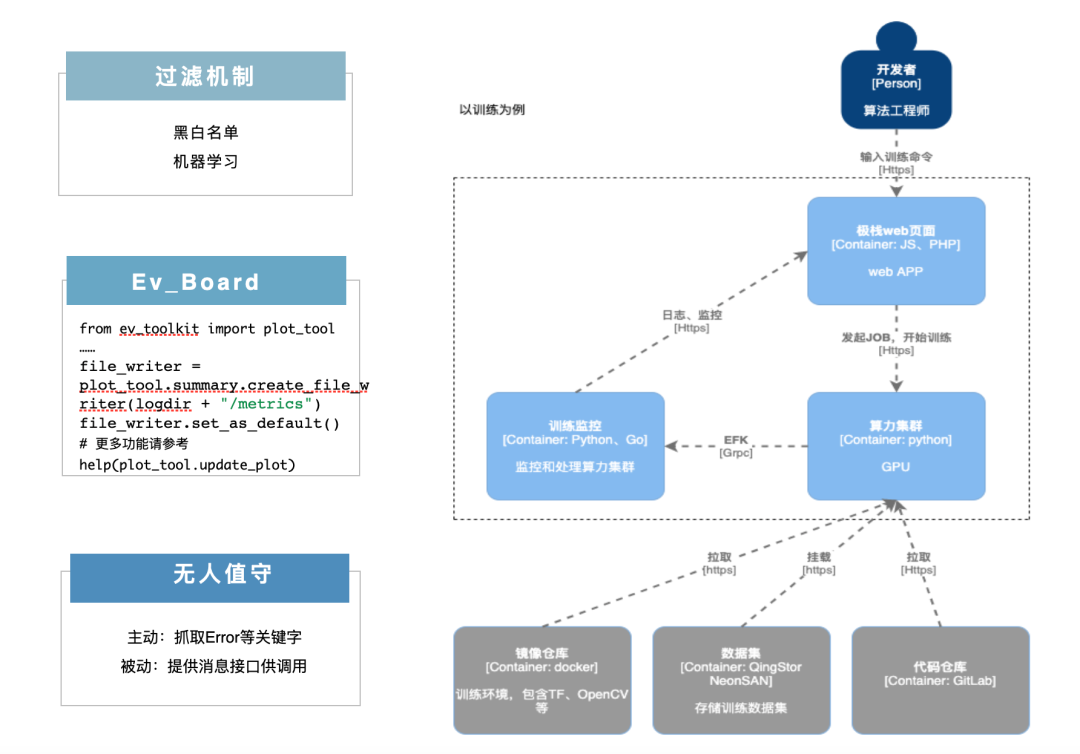
自動測試
要完成算法的自動測試需要解決 3 個問題:
各個算法框架開發(fā)出來的模型格式不統(tǒng)一,怎么規(guī)范化統(tǒng)一調用。 所有算法輸入要統(tǒng)一、標準化。 客戶對算法要求越來越高,算法輸出的數(shù)據(jù)結構也越來越復雜,算法輸出怎么跟數(shù)據(jù)標注的正確結果比對。
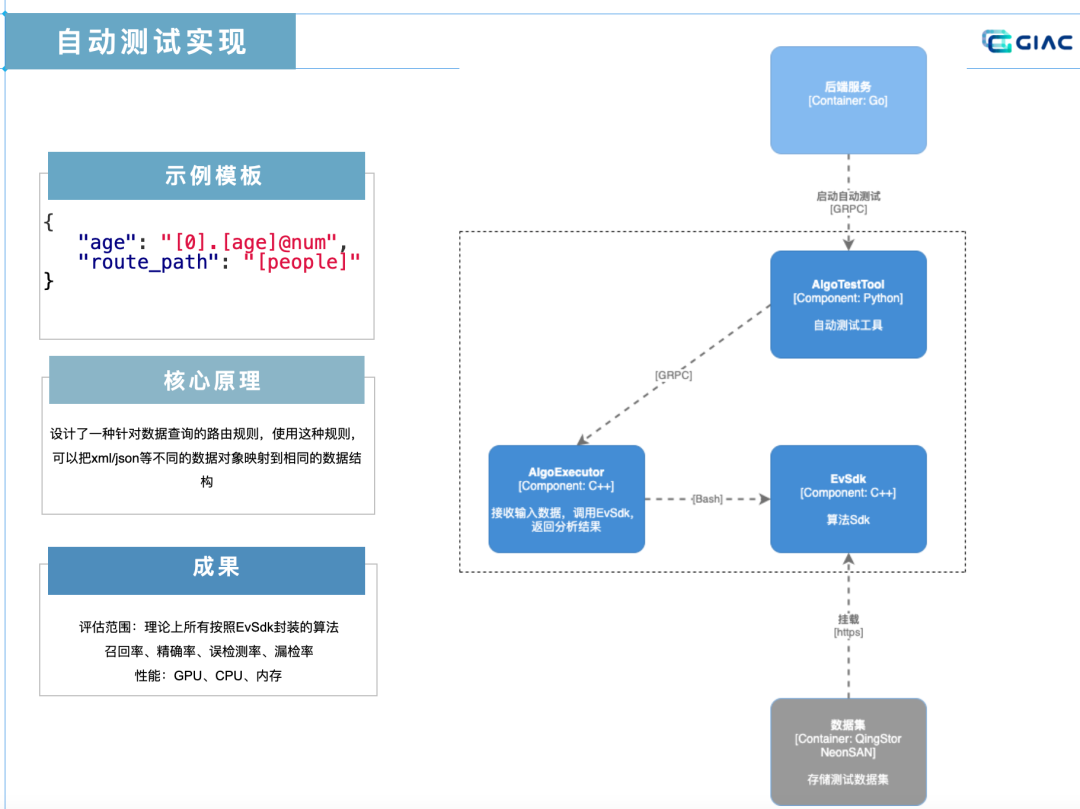
先來看看我們自研的推理框架 EvSdk,它解決了前兩個問題,一是制定了算法統(tǒng)一封裝標準,不同于其他 AI 平臺針對單模型進行評估,極棧自動測試系統(tǒng)針對封裝好的算法進行評估,因為隨著算法越來越復雜,一個算法有多個模型的情況也越來越常見,只是對單模型進行評估并不能評估交付給客戶的成品質量,另外對模型評估還要考慮各種開發(fā)框架模型格式兼容問題;二是 EVSdk 抽象出了算法輸入接口,比如針對視頻分析,第一個參數(shù)是創(chuàng)建的檢測器實例,第二個參數(shù)是輸入的源幀,第三個參數(shù)是可配置的 json,比如 roi、置信度等,通過 EVSdk 制定規(guī)范實現(xiàn)了算法輸入的標準化。除了解決自動測試的兩個問題,EVSdk 還提供工具包,比如算法授權,另外有了統(tǒng)一的推理框架,外面一層的算法工程化工作也可以標準化,由平臺統(tǒng)一提供,以安裝包形式安裝進去,不用開發(fā)者來做了,比如處理視頻流、算法對外提供 GRPC 服務等。
還要解決算法輸出的問題,算法輸出就是要找到輸出 JSON 或者 XML 的節(jié)點里面的算法預測數(shù)據(jù),找到之后和標注的正確數(shù)據(jù)做對比。自動測試系統(tǒng)引入了兩個概念:
模版:定義了算法輸出的數(shù)據(jù)結構,這個數(shù)據(jù)結構中包含若干個變量和如何從原始數(shù)據(jù)中獲取到具體值的路由路徑,根據(jù)模版解析原始數(shù)據(jù)之后,模版中的所有變量將被填充具體的值。 路由路徑:一種針對數(shù)據(jù)查詢的路由規(guī)則,使用這種規(guī)則可以把 xml / json 等不同的數(shù)據(jù)對象映射到相同的數(shù)據(jù)結構。對于不同來源或者不同結構的測試數(shù)據(jù),就可以通過改變配置文件,得到相同數(shù)據(jù)結構的數(shù)據(jù),從而可以對同一類型的任務使用同一個解析器來計算算法指標。
下圖示例里面截取了一個模板里面最小單元,但足以說明自動測試原理。自動測試程序要在算法輸出里找到年齡這個值,來和圖片或視頻標注的標簽里面的年齡做對比。route_path 字段告訴系統(tǒng)有個根節(jié)點的 key 是 people,age 這個字段的 value 就是我們要找的路由路徑了,[0] 代表了這是一個數(shù)組,這也很好理解,因為可以有多個人出現(xiàn)在一幀視頻里面,. 代表了下一級,[] 里如果不是 0,比如 age 代表這是個對象,key 名叫做 age,@num 就是他的數(shù)據(jù)類型,至此程序就找到了 age 在算法輸出的位置,找到后拿去和標注的正確數(shù)據(jù)作對比。當然有更復雜的評判標準,例如年齡誤差在 3 歲以內系統(tǒng)認為算法分析結果是正確的。
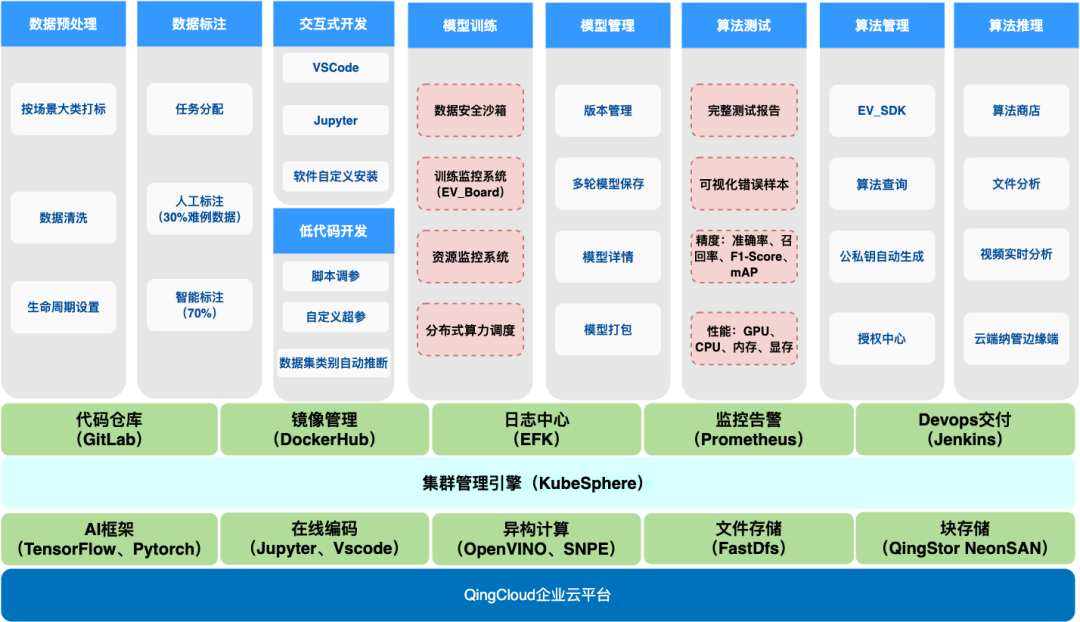
極棧平臺現(xiàn)狀
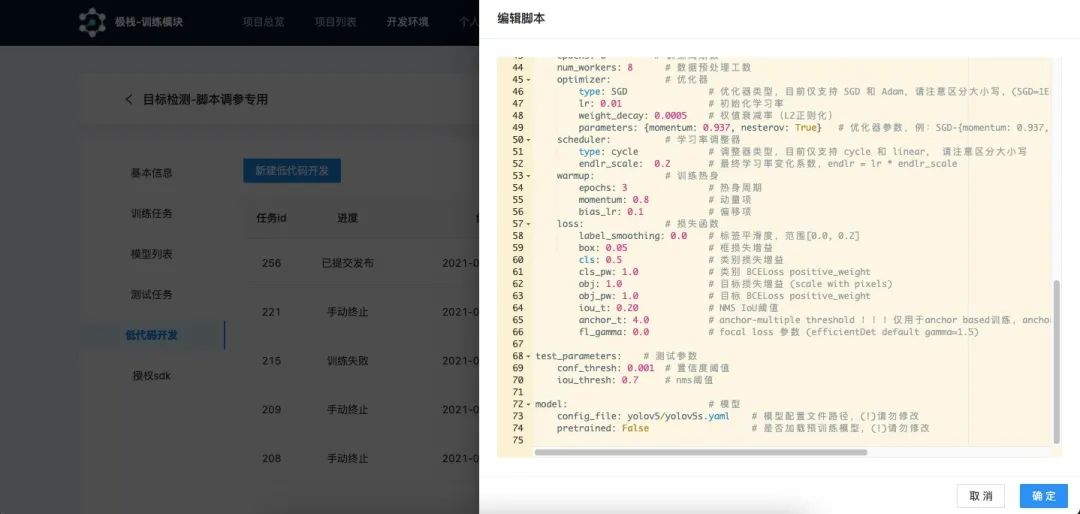
PaaS 層用 KubeSphere 作為底座打造了三個平臺:數(shù)據(jù)平臺,開發(fā)平臺,推理平臺。采集到原始數(shù)據(jù)之后對數(shù)據(jù)大類進行打標,再用算法對數(shù)據(jù)進行去重,以及把低質量數(shù)據(jù)去除掉等初篩工作,人工再進行篩選。因為 AI 訓練數(shù)據(jù)量非常大,我們還支持對數(shù)據(jù)生命周期進行設置,比如根據(jù)數(shù)據(jù)重要性進行保存,然后到數(shù)據(jù)標注,標注是非常占用時間的工作,需要做任務的分配和對標注人員做績效管理,通過再訓練的模型進行自動標注和人工調整標注。數(shù)據(jù)標注好之后流轉到開發(fā)平臺,開發(fā)平臺支持兩種開發(fā)模式,一是交互式開發(fā),二是低代碼的開發(fā)。最后算法生產(chǎn)出來之后上架到推理平臺的算法商店,推理平臺的客戶端可以部署到用戶側,用戶只需要輸入激活碼就可以安裝算法,然后分析本地實時視頻流或圖片。
極棧平臺未來展望
計算機視覺算法和其他軟件不同在哪里呢,比如說 KubeSphere,給我們用的產(chǎn)品和給另外公司用的是一致的。但是對于算法來說,在 A 客戶那里效果很好,到 B 客戶攝像頭距離遠一些、角度不同,或者是檢測物體多了個顏色,效果就不達標了,要重新采集數(shù)據(jù)來訓練模型。算法可復制性不強,難以標準化、產(chǎn)品化。對于解決通用場景的問題,每提高一個百分點識別率需要的算力和數(shù)據(jù)成本要翻倍,所以目前業(yè)界總共花了百億成本才讓人臉識別達到產(chǎn)品化,針對萬千算法,如何大規(guī)模可復用,這是我們要攻克的難題。
既然適配通用場景非常難,回到現(xiàn)實場景中來,我們真的需要不斷去優(yōu)化一個算法適配所有用戶的場景嗎?對于每個用戶來說,他真正關心的是算法在他自己場景下的算法效果。而在實踐中,對于新場景,我們會將新場景數(shù)據(jù)集加入到訓練集里面,對算法進行再訓練來解決。如果系統(tǒng)能夠實現(xiàn)不讓算法工程師介入再訓練過程,而是由客戶通過簡單的操作來完成,就解決了這個問題。
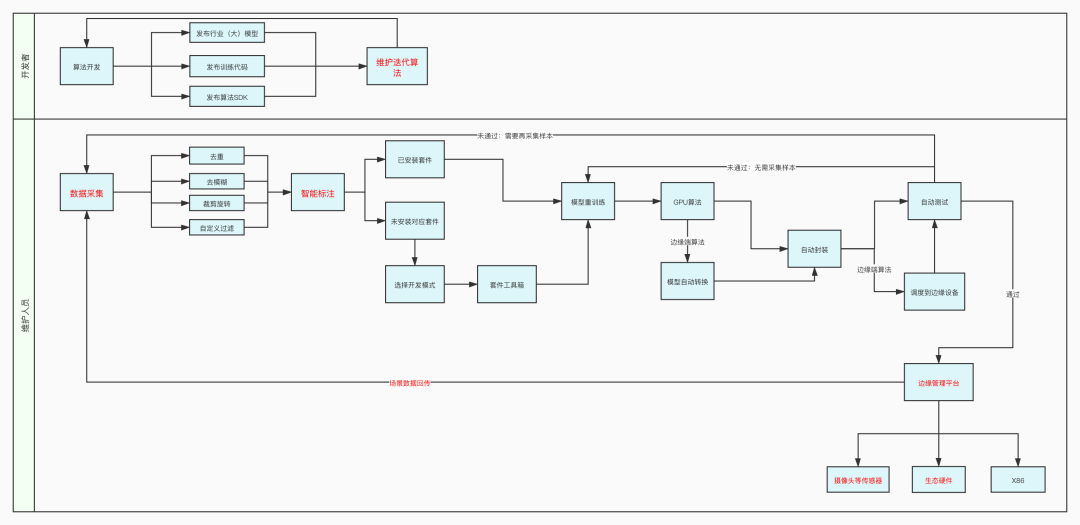
我們下一步會開發(fā)行業(yè)低代碼套件,算法開發(fā)者在平臺內只需開發(fā)算法和維護算法在行業(yè)的領先性,用戶拿自己場景數(shù)據(jù)來標注,訓練模型,適配自己的場景,無需任何編碼工作,就可以完成算法優(yōu)化,優(yōu)化效果不達標的場景,再由開發(fā)者介入。模型優(yōu)化的工作如果無法避免,放到用戶側,算法就相當于用戶喂養(yǎng)的寵物,這其實會重新定義用戶和算法之間的關系,只有這樣走,算法才能產(chǎn)品化,萬千場景才能打開。
Serverless 在 AI 領域的應用
上面詳細闡述了 Kubernetes 在 AI 的應用實踐,其實 AI 也需要 Serverless 技術,具體來說 AI 的數(shù)據(jù)、訓練、推理等都可以同 Serverless 技術相結合而獲得更高的效率并降低成本:
AI 離不開數(shù)據(jù),以 Serverless 的方式處理數(shù)據(jù)成本更低。 可以通過定時或者事件觸發(fā) Serverless 工作負載的方式進行 AI 訓練以及時釋放昂貴的 GPU。 訓練好的模型可以用 Serverless 的方式提供服務。 AI 推理結果可以通過事件的方式觸發(fā) Serverless 函數(shù)進行后續(xù)的處理。
Serverless 是云原生領域不容錯失的賽道,以此為出發(fā)點,青云科技開源了云原生 FaaS 平臺 ——OpenFunction。
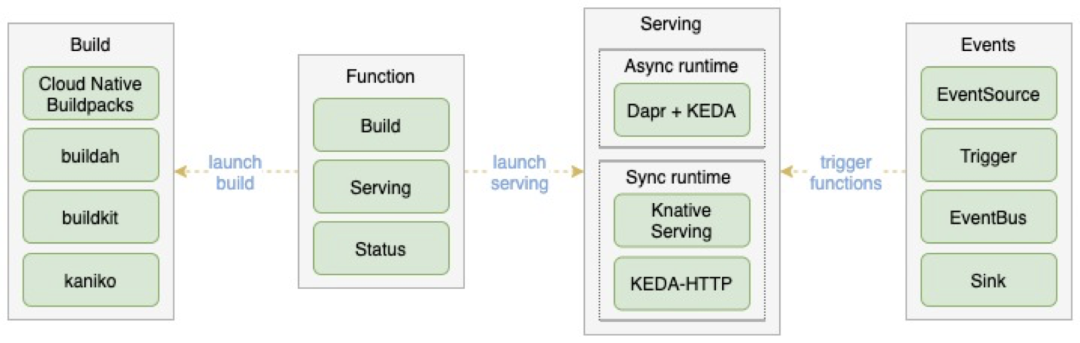
FaaS 平臺主要包含 Build、Serving 及 Events 幾個部分。其中 Build 負責將函數(shù)代碼轉換成函數(shù)鏡像;Serving 部分負責基于生成的函數(shù)鏡像提供可伸縮的函數(shù)服務;Events 部分負責對接外部事件源并驅動函數(shù)運行。
Kubernetes 已經(jīng)啟用 Docker 作為默認的 container runtime,從此不能在 K8s 集群里用 Docker in Docker 的方式 用 docker build 去 build 鏡像,需要有別的選擇。OpenFunction 現(xiàn)在默認支持 Cloud Native Buildpacks ,后面還將陸續(xù)支持 buildah、 buildkit、 kaniko 等。
Dapr 是微軟開源的分布式應用程序運行時,提供了運行分布式應用程序需要的一些通用基礎能力。OpenFunction 也把 Dapr 應用到了 OpenFunction 的 Serving 和 Events 里。
函數(shù)服務最重要的是 0 與 N 副本之間的自動伸縮,對于同步函數(shù),OpenFunction 支持 Knative Serving 作為同步函數(shù)運行時,后面還計劃支持 KEDA-HTTP ; 對于異步函數(shù)來說,OpenFunction 結合 Dapr 與 KEDA 開發(fā)了名為 OpenFunction Async 的異步函數(shù)運行時。
函數(shù)的事件管理我們調研了 Knative Eventing 之后覺得它雖然設計的比較好,但是有點過于復雜,不易學習和使用;Argo Events 架構雖然簡單了許多,但并不是專為 Serverless 而設計,并且要求所有事件都必須發(fā)往它的事件總線 EventBus。基于以上調研,我們自己開發(fā)了函數(shù)事件管理框架 OpenFunction Events。
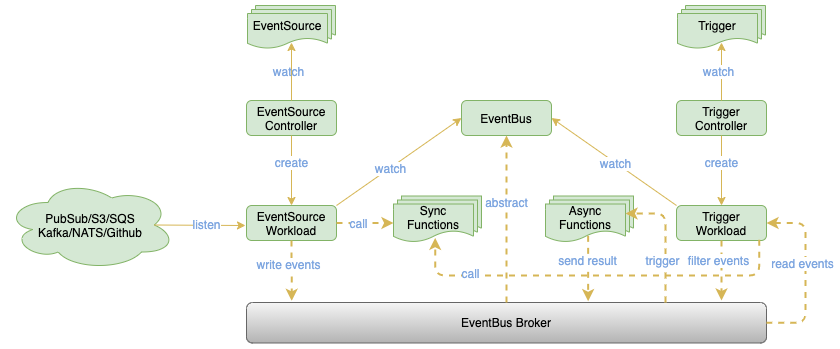
OpenFunction Events 充分利用了 Dapr 的能力去對接眾多事件源、對接更多的 MQ 去作為 EventBus ,包含 EventSource、EventBus 和 Trigger 幾個組件:
EventSource:用于對接眾多外部事件源如 Kafka、NATS、 PubSub、S3、GitHub 等。在獲取到事件之后,EventSource 可以直接調用同步函數(shù)進行處理,也可以將事件發(fā)往 EventBus 進行持久化,進而觸發(fā)同步或者異步函數(shù)。 EventBus:利用 Dapr 能夠以可插拔的方式對接眾多消息隊列如 Kafka、NATS 等。 Trigger:從 EventBus 中獲取事件,進行過濾選出關心的事件后,可以直接觸發(fā)同步函數(shù),也可以將過濾出的事件發(fā)往 EventBus 觸發(fā)異步函數(shù)。
Serverless 除了可以應用到上述 AI 領域之外,還可以應用到諸如 IoT 設備數(shù)據(jù)處理、流式數(shù)據(jù)處理、Web/移動終端后端 API backend (Backend for Frontend) 等領域。
OpenFunction 已經(jīng)在 GitHub 開源,主要倉庫包括:OpenFunction[1],functions-framework[2],builder[3],samples[4]
也歡迎大家到 KubeSphere 和 OpenFunction 社區(qū)的中文 Slack 頻道[5]交流。
腳注
OpenFunction: https://github.com/OpenFunction/OpenFunction
[2]functions-framework: https://github.com/OpenFunction/functions-framework
[3]builder: https://github.com/OpenFunction/builder
[4]samples: https://github.com/OpenFunction/samples
[5]中文 Slack 頻道: https://kubesphere.slack.com/archives/CBJ1A2UCB