
解Bug之路-ZooKeeper集群拒絕服務
前言
ZooKeeper作為dubbo的注冊中心,可謂是重中之重,線上ZK的任何風吹草動都會牽動心弦。最近筆者就碰到線上ZK Leader宕機后,選主無法成功導致ZK集群拒絕服務的現(xiàn)象,于是把這個case寫出來分享給大家(基于ZooKeeper 3.4.5)。
Bug現(xiàn)場
一天早上,突然接到電話,說是ZooKeeper物理機宕機了,而剩余幾臺機器狀態(tài)都是
sh zkServer.sh status
it is probably not running
筆者看了下監(jiān)控,物理機宕機的正好是ZK的leader。3節(jié)點的ZK,leader宕了后,其余兩臺一直未能成為leader,把宕機的那臺緊急拉起來之后,依舊無法選主,
導致ZK集群整體拒絕服務!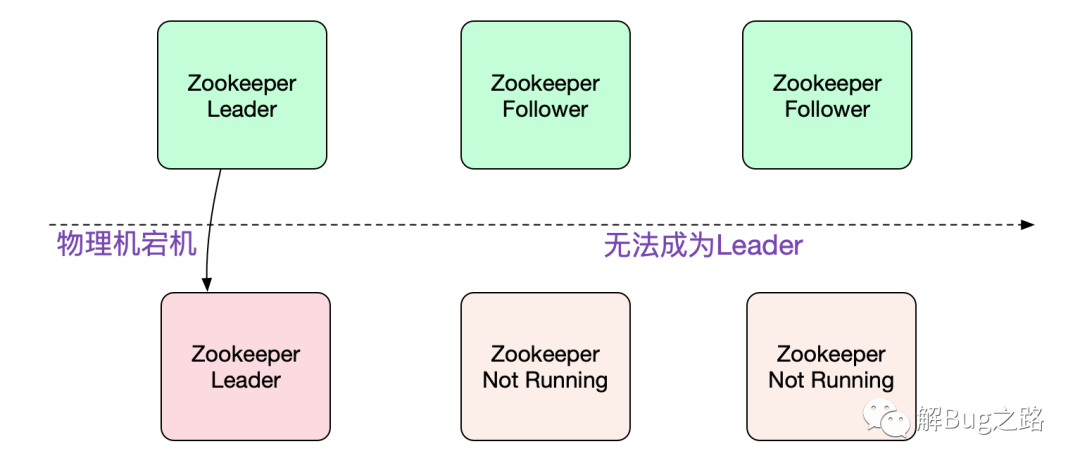
業(yè)務影響
Dubbo如果連接不上ZK,其調用元信息會一直緩存著,所以并不會對請求調用造成實際影響。麻煩的是,如果在ZK拒絕服務期間,應用無法重啟或者發(fā)布,一旦遇到緊急事件而重啟(發(fā)布)不能,就會造成比較重大的影響。
好在我們?yōu)榱烁呖捎茫隽藢Φ葯C房建設,所以非常淡定的將流量切到B機房,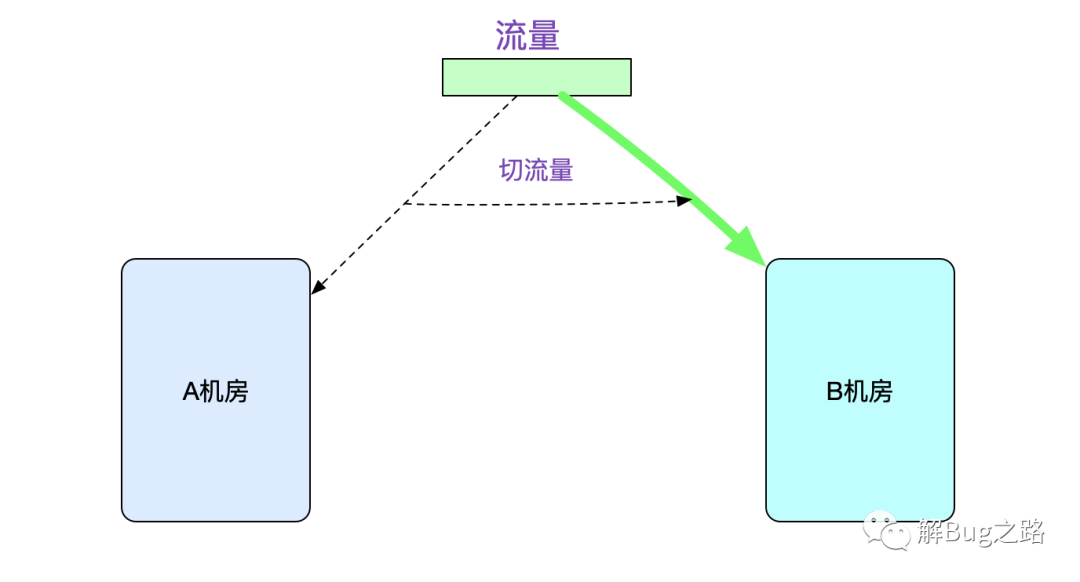
雙機房建設就是好啊,一鍵切換!
切換過后就可以有充裕的時間來恢復A機房的集群了。在緊張恢復的同時,筆者也開始了分析工作。
日志表現(xiàn)
首先,查看日志,期間有大量的client連接報錯,自然是直接過濾掉,以免干擾。
cat zookeeper.out | grep -v 'client xxx' | > /tmp/1.txt
首先看到的是下面這樣的日志:
ZK-A機器日志
Zk-A機器:
2021-06-16 03:32:35 ... New election. My id=3
2021-06-16 03:32:46 ... QuoeumPeer] LEADING // 注意,這里選主成功
2021-06-16 03:32:46 ... QuoeumPeer] LEADING - LEADER ELECTION TOOK - 7878'
2021-06-16 03:32:48 ... QuoeumPeer] Reading snapshot /xxx/snapshot.xxx
2021-06-16 03:32:54 ... QuoeumPeer] Snahotting xxx to /xxx/snapshot.xxx
2021-06-16 03:33:08 ... Follower sid ZK-B.IP
2021-06-16 03:33:08 ... Unexpected exception causing shutdown while sock still open
java.io.EOFException
at java.io.DataInputStream.readInt
......
at quorum.LearnerHandler.run
2021-06-16 03:33:08 ******* GOODBYE ZK-B.IP *******
2021-06-16 03:33:27 Shutting down
這段日志看上去像選主成功了,但是和其它機器的通信出問題了,導致Shutdown然后重新選舉。
ZK-B機器日志
2021-06-16 03:32:48 New election. My id=2
2021-06-16 03:32:48 QuoeumPeer] FOLLOWING
2021-06-16 03:32:48 QuoeumPeer] FOLLOWING - LEADER ELECTION TOOK - 222
2021-06-16 03:33:08.833 QuoeumPeer] Exception when following the leader
java.net.SocketTimeoutException: Read time out
at java.net.SocketInputStream.socketRead0
......
at org.apache.zookeeper.server.quorum.Follower.followLeader
2021-06-16 03:33:08.380 Shutting down
這段日志也表明選主成功了,而且自己是Following狀態(tài),只不過Leader遲遲不返回,導致超時進而Shutdown
時序圖
筆者將上面的日志畫成時序圖,以便分析: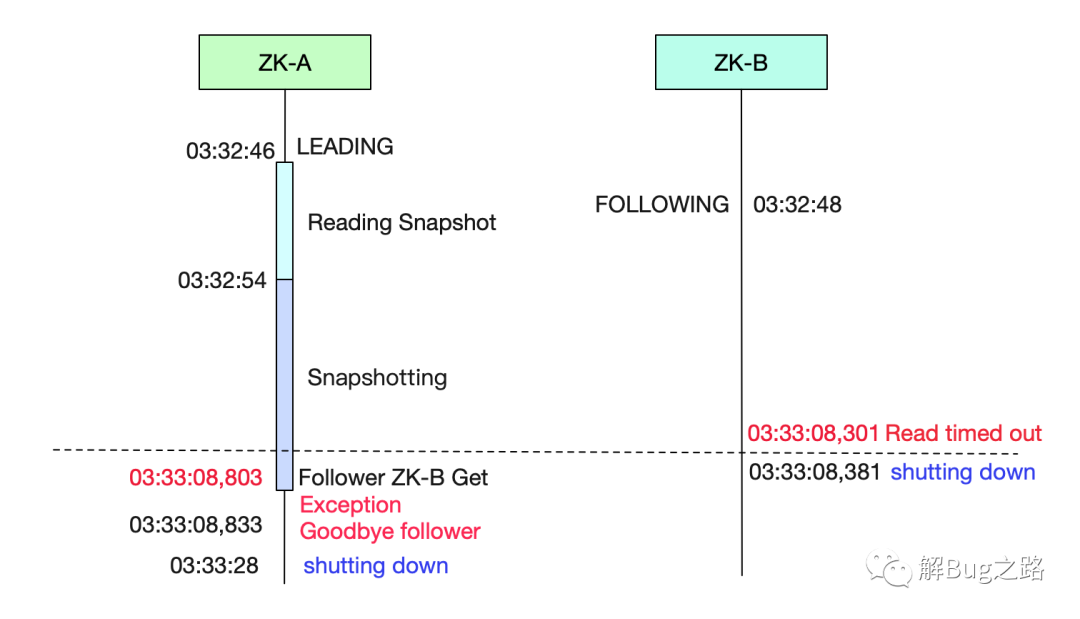
從ZK-B的日志可以看出,其在成為follower之后,一直等待leader,直到Read time out。
從ZK-A的日志可以看出,其在成為LEADING后,在33:08,803才收到Follower也就是ZK-B發(fā)出的包。而這時,ZK-B已經(jīng)在33:08,301的時候Read timed out了。
首先分析follower(ZK-B)的情況
我們知道其在03:32:48成為follower,然后在03:33:08出錯Read time out,其間正好是20s。于是筆者先從Zookeeper源碼中找下其設置Read time out是多長時間。
Learner
protected void connectToLeader(InetSocketAddress addr) {
......
sock = new Socket()
// self.tockTime 2000 self.initLimit 10
sock.setSoTimeout(self.tickTime * self.initLimit);
......
}
其Read time out是按照zoo.cfg中的配置項而設置:
tickTime=2000 self.tickTime
initLimit=10 self.initLimit
syncLimit=5
很明顯的,ZK-B在成為follower后,由于某種原因leader在20s后才響應。那么接下來對leader進行分析。
對leader(ZK-A)進行分析
首先我們先看下Leader的初始化邏輯:
quorumPeer
|->打印 LEADING
|->makeLeader
|-> new ServerSocket listen and bind
|->leader.lead()
|->打印 LEADER ELECTION TOOK
|->loadData
|->loadDataBase
|->resore 打印Reading snapshot
|->takeSnapshot
|->save 打印Snapshotting
|->cnxAcceptor 處理請求Accept
可以看到,在我們的ZK啟動監(jiān)聽端口到正式處理請求之間,還有Reading Snapshot和Snapshotting(寫)動作。從日志可以看出一個花了6s多,一個花了14s多。然后就有20s的處理空檔期。如下圖所示: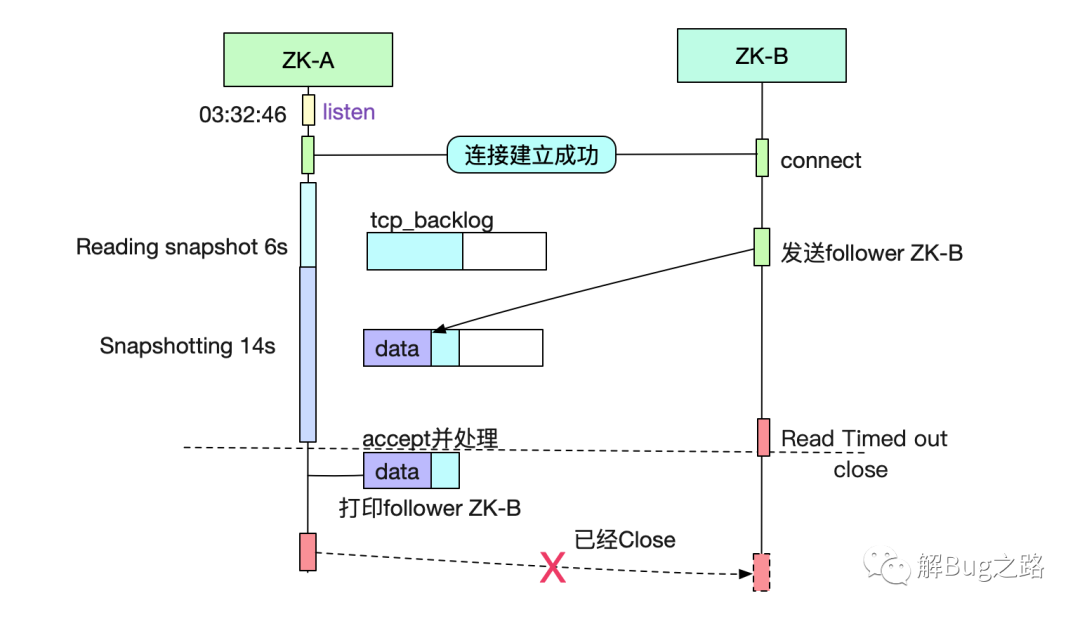
由于在socket listen 20s之后才開始處理數(shù)據(jù),所以ZK-B建立成功的連接實際還放在tcp的內核全連接隊列(backlog)里面,由于在內核看來三次握手是成功的,所以能夠正常接收ZK-B發(fā)送的follower ZK-B數(shù)據(jù)。在20s,ZK-A真正處理后,從buffer里面拿出來20s前ZK-B發(fā)送的數(shù)據(jù),處理完回包的時候,發(fā)現(xiàn)ZK-B連接已經(jīng)斷開。
同樣的,另一臺follower(這時候我們已經(jīng)把宕機的拉起來了,所以是3臺)也是由于此原因gg,而leader遲遲收不到其它機器的響應,認為自己的leader沒有達到1/2的票數(shù),而Shutdown重新選舉。
Snapshot耗時
那么是什么導致Snapshotting讀寫這么耗時呢?筆者查看了下Snapshot文件大小,有將近一個G左右。
調大initLimit
針對這種情況,其實我們只要調大initLimit,應該就可以越過這道坎。
zoo.cfg
tickTime=2000 // 這個不要動,因為和ZK心跳機制有關
initLimit=100 // 直接調成100,200s!
這么巧就20s么?
難道就這么巧,每次選舉流程都剛好卡在20s不過?反復選舉了好多次,應該有一次要<20s成功吧,不然運氣也太差了。如果是每次需要處理Snapshot 30s也就算了,但這個20s太接近極限值了,是否還有其它因素導致選主不成功?
第二種情況
于是筆者翻了下日志,還真有!這次leader這邊處理Snapshot快了,但是follower又拉跨了!日志如下:
leader(ZK-A)第二種情況
2021-06-16 03:38:03 New election. My id= 3
2021-06-16 03:38:22 QuorumPeer] LEADING
2021-06-16 03:38:22 QuorumPeer] LEADING - LEADER ELECTION TOOK 25703
2021-06-16 03:38:22 QuorumPeer] Reading snapshot
2021-06-16 03:38:29 QuorumPeer] Snapshotting
2021-06-16 03:38:42 LearnerHandler] Follower sid 1
2021-06-16 03:38:42 LearnerHandler] Follower sid 3
2021-06-16 03:38:42 LearnerHandler] Sending DIFF
2021-06-16 03:38:42 LearnerHandler] Sending DIFF
2021-06-16 03:38:54 LearnerHandler] Have quorum of supporters
2021-06-16 03:38:55 client attempting to establsh new session 到這開始接收client請求了
......
2021-06-16 03:38:58 Shutdown callsed
java.lang.Exception: shutdown Leader! reason: Only 1 followers,need 1
at org.apache.zookeeper.server.quorum.Leader.shutdown
從日志中我們可以看到選舉是成功了的,畢竟處理Snapshot只處理了13s(可能是pagecache的原因處理變快)。其它兩個follower順利連接,同時給他們發(fā)送DIFF包,但是情況沒好多久,又爆了一個follower不夠的報錯,這里的報錯信息比較迷惑。
我們看下代碼:
Leader.lead
void lead() {
while(true){
Thread.sleep(self.tickTime/2);
......
syncedSet.add(self.getId())
for(LearnerHandler f:getLearners()){
if(f.synced() && f.getLearnerType()==LearnerType.PARTICIPANT){
syncedSet.add(f.getSid());
}
f.ping();
}
// syncedSet只有1個也就是自身,不符合>1/2的條件,報錯并跳出
if (!tickSkip && !self.getQuorumVerifier().containsQuorum(syncedSet)) {
shutdown("Only" + syncedSet.size() + " followers, need" + (self.getVotingView().size()/2));
return;
}
}
}
報錯的實質就是和leader同步的syncedSet小于固定的1/2集群,所以shutdown了。同時在代碼里面我們又可以看到syncedSet的判定是通過learnerHander.synced()來決定。我們繼續(xù)看下代碼:
LearnerHandler
public boolean synced(){
// 這邊isAlive是線程的isAlive
return isAlive() && tickOfLastAck >= leader.self.tick - leader.self.syncLimit;
}
很明顯的,follower和leader的同步時間超過了leader.self.syncLimit也就是5 * 2 = 10s
zoo.cfg
tickTime = 2000
syncLimit = 5
那么我們的tick是怎么更新的呢,答案是在follower響應UPTODATE包,也就是已經(jīng)和leader同步后,follower每個包過來就更新一次,在此之前并不更新。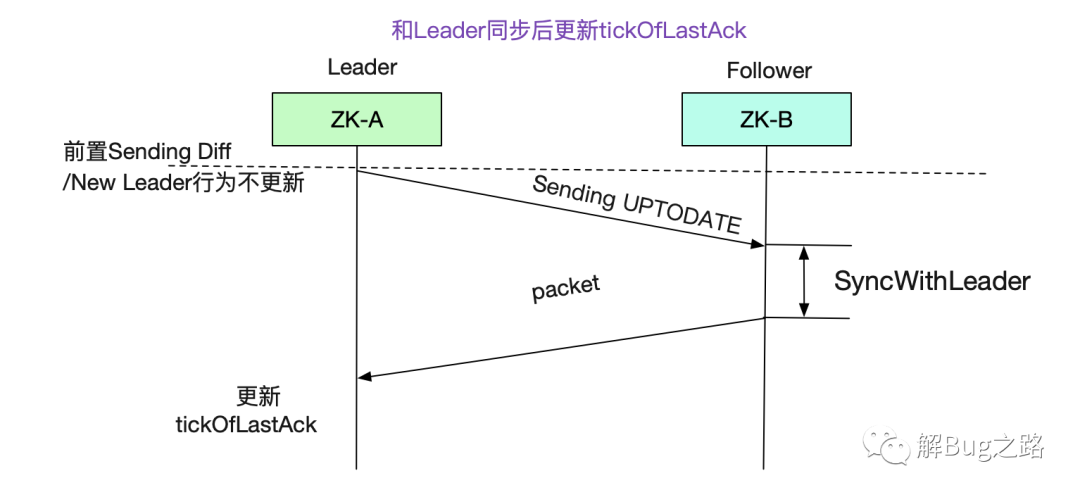
進一步推理,也就是我們的follower處理leader的包超過了10s,導致tick未及時更新,進而syncedSet小于數(shù)量,導致leader shutdown。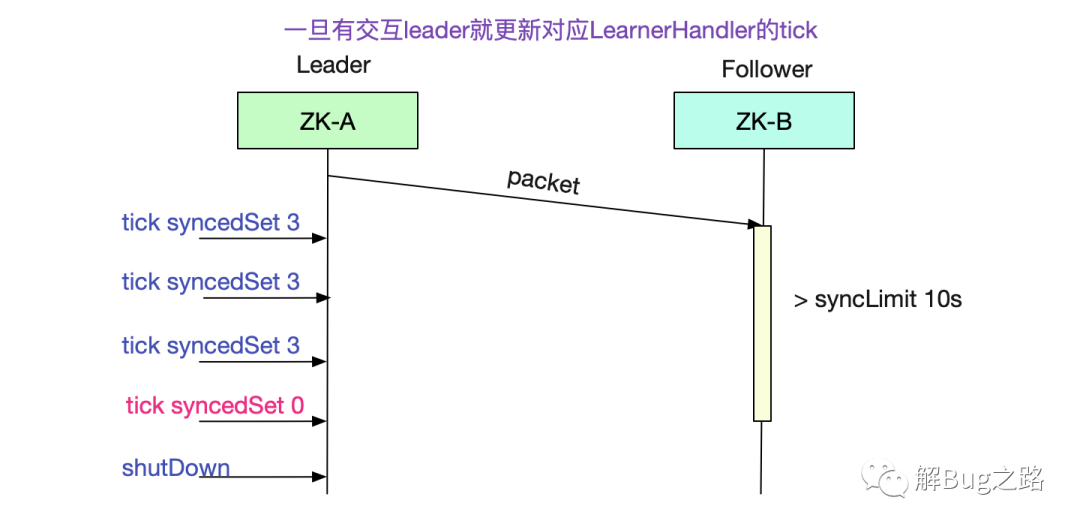
follower(ZK-B)第二種情況
帶著這個結論,筆者去翻了follower(ZK-B)的日志(注:ZK-C也是如此)
2021-06-16 03:38:24 New election. My id = 3
2021-06-16 03:38:24 FOLLOWING
2021-06-16 03:38:24 FOLLOWING - LEADER ELECTION TOOK - 8004
2021-06-16 03:38:42 Getting a diff from the leader
2021-06-16 03:38:42 Snapshotting
2021-06-16 03:38:57 Snapshotting
2021-06-16 03:39:12 Got zxid xxx
2021-06-16 03:39:12 Exception when following the leader
java.net.SocketException: Broken pipe
又是Snapshot,這次我們可以看到每次Snapshot會花15s左右,遠超了syncLimit。
從源碼中我們可以得知,每次Snapshot之后都會立馬writePacket(即響應),但是第一次回包有由于不是處理的UPTODATE包,所以并不會更新Leader端對應的tick:
learner:
proteced void syncWithLeader(...){
outerloop:
while(self.isRunning()){
readPacket(qp);
switch(qp.getType()){
case Leader.UPTODATE
if(!snapshotTaken){
zk.takeSnapshot();
......
}
break outerloop;
}
case Leader.NEWLEADER:
zk.takeSnapshot();
......
writePacket(......) // leader收到后會更新tick
break;
}
......
writePacket(ack,True); // leader收到后會更新tick
}
注意,ZK-B的日志里面表明會兩次Snapshotting。至于為什么兩次,應該是一個微妙的Bug,(在3.4.5的官方注釋里面做了fix,但看日志依舊打了兩次),筆者并沒有深究。好了,整個時序圖就如下所示:
好了,第二種情況也gg了。這一次時間就不是剛剛好出在邊緣了,得將近30s才能Okay, 而synedSet只有10s(2*5)。ZK集群就在這兩種情況中反復選舉,直到人工介入。
調大syncLimit
針對這種情況,其實我們只要調大syncLimit,應該就可以越過這道坎。
zoo.cfg
tickTime=2000 // 這個不要動,因為和ZK心跳機制有關
syncLimit=50 // 直接調成50,100s!
線下復現(xiàn)
當然了,有了分析還是不夠的。我們還需要通過測試去復現(xiàn)并驗證我們的結論。我們在線下構造了一個1024G Snapshot的ZookKeeper進行測試,在initLimit=10以及syncLimit=5的情況下確實和線上出現(xiàn)一模一樣的那兩種現(xiàn)象。在筆者將參數(shù)調整后:
zoo.cfg
tickTime=2000
initLimit=100 // 200s
syncLimit=50 // 100s
Zookeeper集群終于正常了。
線下用新版本3.4.13嘗試復現(xiàn)
我們在線下還用比較新的版本3.4.13嘗試復現(xiàn),發(fā)現(xiàn)Zookeeper在不調整參數(shù)的情況下,很快的就選主成功并正常提供服務了。筆者翻了翻源碼,發(fā)現(xiàn)其直接在Leader.lead()階段和SyncWithLeader階段(如果是用Diff的話)將takeSnapshot去掉了。這也就避免了處理snapshot時間過長導致無法提供服務的現(xiàn)象。
Zookeeper 3.4.13
ZookeeperServer.java
public void loadData(){
...
// takeSnapshot() 刪掉了最后一行的takeSnapshot
}
learner.java
protected void syncWithLeader(...){
boolean snapshotNeeded=true
if(qp.getType() == Leader.DIFF){
......
snapshotNeeded = false
}
......
if(snapshotNeeded){
zk.takeSnapshot();
}
......
}
還是升級到高版本靠譜呀,這個版本的代碼順帶把那個迷惑性的日志也改了!
為何Dubbo-ZK有那么多的數(shù)據(jù)
最后的問題就是一個dubbo相關的ZK為什么有那么多數(shù)據(jù)了!筆者利用ZK使用的
org.apache.zookeeper.server.SnapshotFormatter
工具dump出來并用shell(awk|unique)聚合了一把,發(fā)現(xiàn)dubbo的數(shù)據(jù)只占了其中的1/4。
有1/2是Solar的Zookeeper(已經(jīng)遷移掉,遺留在上面的)。還有1/4是由于某個系統(tǒng)的分布式鎖Bug不停的寫入進去并且不刪除的(已讓他們修改)。所以將dubbo-zk和其它ZK數(shù)據(jù)分離是多么的重要!隨便濫用就有可能導致重大事件!
總結
Zookeeper作為重要的元數(shù)據(jù)管理系統(tǒng),其無法提供服務有可能會帶來不可估量的影響。感謝雙機房建設讓我們有充足的時間和輕松的心態(tài)處理此問題。另外,雖然ZK選舉雖然復雜,但是只要沉下心來慢慢分析,總歸能夠發(fā)現(xiàn)蛛絲馬跡,進而找到突破口!