
CMT:當(dāng)CNN遇到Transformer,“迷途知返”

本文是華為諾亞與悉尼大學(xué)在Transformer+CNN架構(gòu)混合方面的嘗試,提出了一種同時具有Transformer長距離建模與CNN局部特征提取能力的CMT。相比之前的各種Transformer變種,本文更傾向于將Transformer的優(yōu)勢集成到CNN中。整體架構(gòu)采用了ResNet的分階段架構(gòu),Normalization方面采用CNN中常用的BN而非Transformer中的LN,在核心模塊CMTBlock方面,內(nèi)部設(shè)計了具有局部特征提取的LPU,在降低計算量方面對K與V進行了特征分辨率的下降,與此同時將MobileNetV2中的逆殘差思想引入到FFN中得到了IRFFN。總而言之,CMT代表著CV中的Transformer架構(gòu)趨勢又回到了CNN原先研究路線:即CNN為主,其他領(lǐng)域思想為輔。
Abstract
由于其所具有的長距離依賴建模能力,Vision Transformers已被成功應(yīng)用到圖像識別任務(wù)中。然而,其性能與計算量距離優(yōu)秀的CNN仍存在差距。
為解決上述問題,我們設(shè)計了一種新的網(wǎng)絡(luò)CMT,它不僅由于Transformer,同時優(yōu)于高性能CNN。所提CMT是一種混合CNN與Transformer的架構(gòu),它同時利用率Transformer的長距離建模與CNN的局部特征提取能力。具體來說,所提CMT-S取得了83.5%的top1精度,同時比現(xiàn)有的DeiT快14倍,比EfficientNet快2倍。所提CMT-S同樣具有非常好的泛化性能,比如CIFAR10取得了99.2%,CIFAR100上取得了91.7%,F(xiàn)lowers上取得了98.7%,COCO上取得了44.3%mAP。
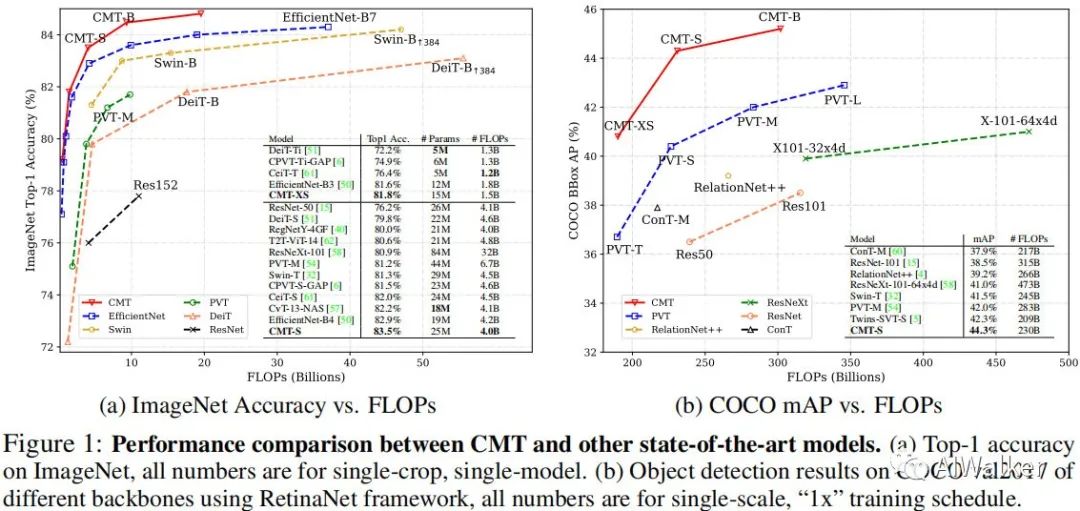
Method
本文的初衷是構(gòu)建一種混合網(wǎng)絡(luò),它同時利用CNN與Transformer的優(yōu)勢。下圖給出了ResNet50、DeiT以及所提CMT的網(wǎng)絡(luò)架構(gòu)示意圖。
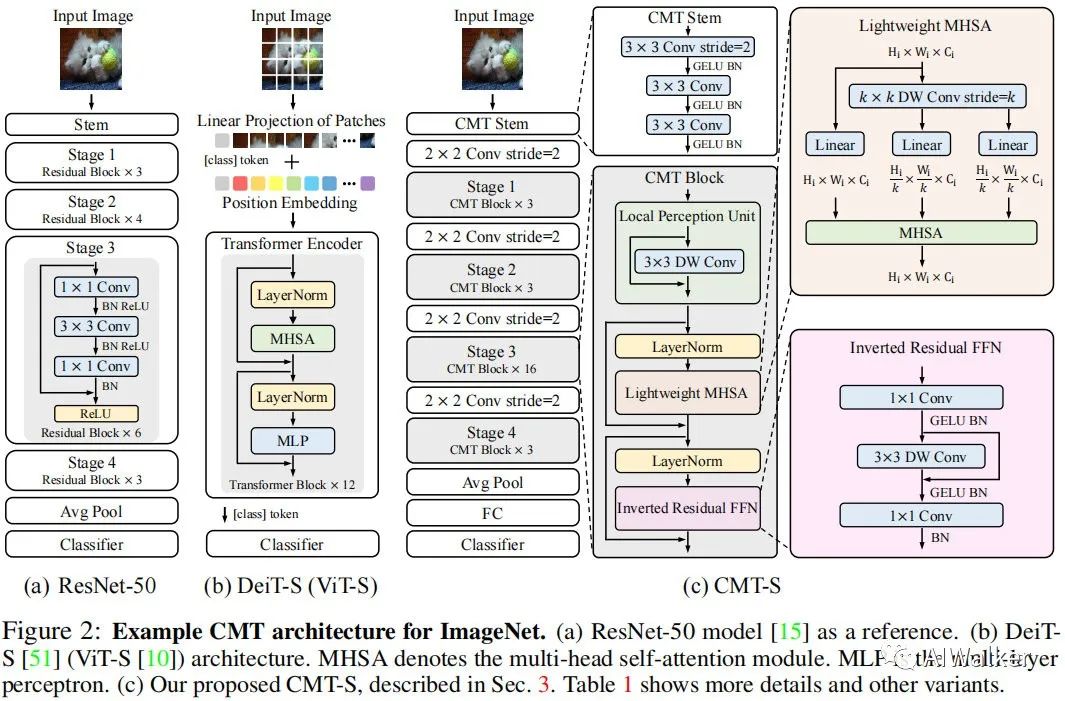
如上圖所示,DeiT直接將輸入圖像拆分為非重疊圖像塊,圖像塊的結(jié)構(gòu)信息則通過線性投影方式弱建模。為克服該局限性,我們采用類似ResNet的stem架構(gòu),它由三個 卷積構(gòu)成,但激活函數(shù)采用了GELU,而非ResNet的ReLU。
類似經(jīng)典CNN(如ResNet)架構(gòu)設(shè)計,所提CMT包含四個階段以生成多尺度特征(這對于稠密預(yù)測任務(wù)非常重要)。為生成分層表達,在每個階段開始之前采用 卷積降低特征分辨率并提升通道維度。在每個階段,堆疊多個CMT模塊進行特征變換同時保持特征分辨率不變,每個CMT模塊可以同時捕獲局部與長距離依賴關(guān)系。在模型的尾部,我們采用GAP+FC方式進行分類。
給定輸入圖像,我們可以得到四個不同分辨率的分層特征,類似于經(jīng)典的CNN(ResNet, EfficientNet)。所得四個不同分辨率的特征對應(yīng)的stride分別為4、8、16、32,因此,CMT所得多尺度特征表達可以輕易應(yīng)用到下游任務(wù)(比如檢測與分割)中。
CMT Block
所提CMT模塊包含一個局部感知單元(Loal Perception Unit, LPU)、一個輕量型多頭自注意力模塊(Lightweight Multi-Head Self-Attention, LMHSA)以及一個逆殘差前饋網(wǎng)絡(luò)(Inverted Residual Feed-Forward Network, IRFFN)。
Local Perception Unit 旋轉(zhuǎn)與平移是視覺任務(wù)中兩種常見數(shù)據(jù)增廣方法,這些操作應(yīng)當(dāng)不能影響模型最終的結(jié)果。然而,Transformer中的絕對位置編碼會破壞該不變性。此外,Transformer忽略了塊內(nèi)的局部相關(guān)性與結(jié)構(gòu)信息。為緩解該限制,我們提出了局部感知單元以提升局部信息,定義如下:
Lightweight Multi-Head Self-Attention 在原始的自注意力模塊中,輸入X線性變換為Q、K以及V,然后通過如下方式執(zhí)行自注意力操作:
為減少計算復(fù)雜度,我們采用 深度卷積降低K與V的空間尺寸,即。此外,類似Swin,我們在自注意力模塊中添加了相對位置偏置B:
Inverted Residual Feed-forward Network 原始的FFN僅包含兩個全連接層+GeLU,第一個FC用于擴展特征維度,第二個FC用于降低特征維度:
本文所提IRFFN采用了類似MobileNetV2的逆殘差模塊,包含一個擴展層、深度卷積以及投影層。具體來說,我們改變了短連接的位置以獲得更好的性能:
注: 這里在推理階段可以進行合并,即跳過連接可以移除掉。它的作用則是利用微小的代價提取局部解雇信息。
基于上述所提到的三個成分,CMT模塊定義如下:
Complexity Analysis
接下來,我們對ViT與CMT的計算量復(fù)雜度進行分析。標(biāo)準(zhǔn)的Transformer模塊包含MHSA與FFN,假設(shè)輸入特征尺寸為 ,那么整體計算復(fù)雜度為:
因此,當(dāng) 時,ViT中的Transformer計算復(fù)雜度表示如下:
采用類似ViT的配置,CMT的計算量復(fù)雜度表示如下:
相比ViT,CMT對計算復(fù)雜度更友好,可以處理更高分辨率的特征。
Scaling Strategy
受啟發(fā)于EfficientNet,我們提出了一種適用于Transformer的復(fù)合縮放策略:它采用復(fù)合系數(shù) 均勻的調(diào)整深度、維度以及輸入分辨率:
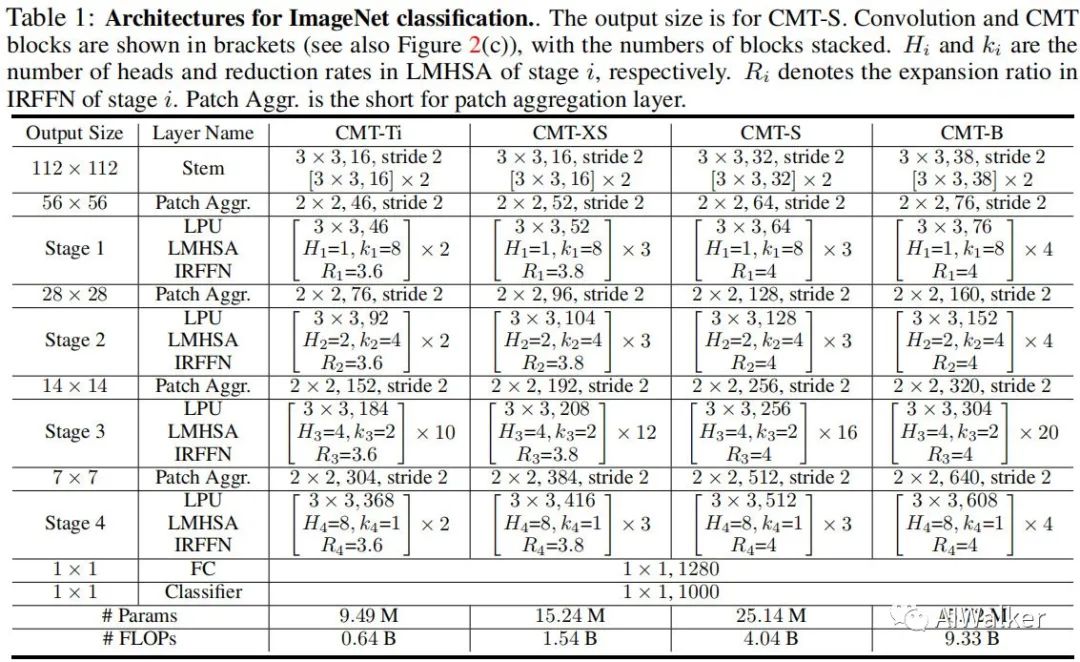
注:在實驗中,我們設(shè)置 。下表給出了不同復(fù)雜度的CMT模型配置信息。
Experiments
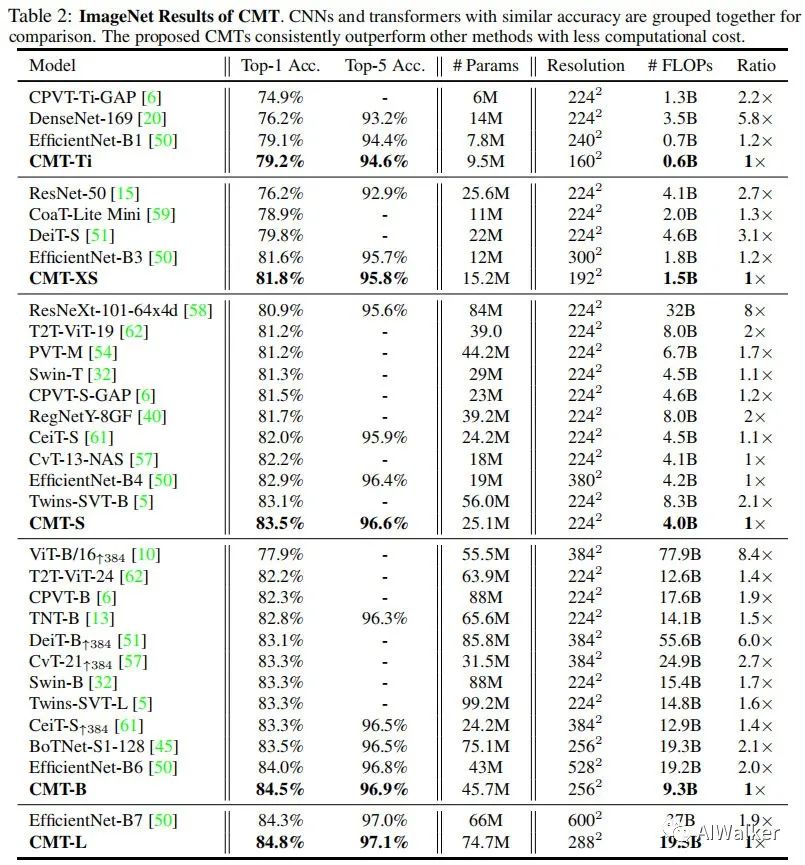
上表給出了所提方法與其他CNN、Transformer的性能對比,從中可以看到:
-
所提CMT取得了更佳的精度,同時具有更少的參數(shù)量、更少的計算復(fù)雜度; -
所提CMT-S憑借4.0B FLOPs取得了83.5%的top1精度,這比DeiT-S高3.7%,比CPVT高2.0%; -
所提CMT-S比EfficientNet-B4指標(biāo)高0.6%,同時具有更低的計算復(fù)雜度。
Transfer Learning
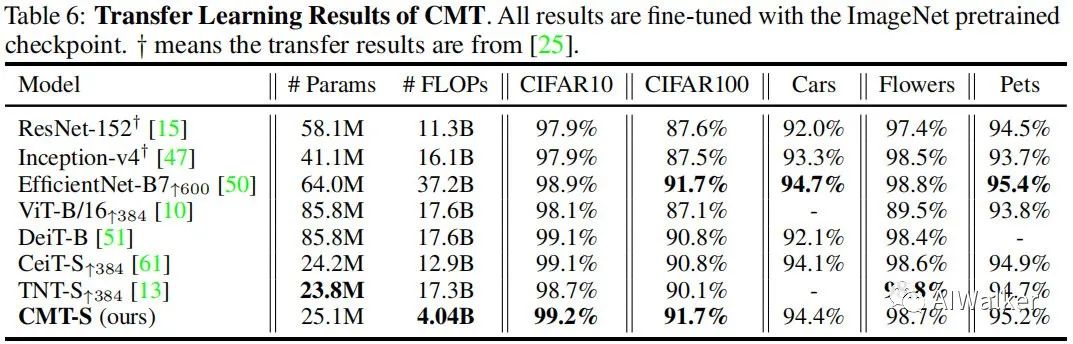
上表對比了所提方法在不同分類數(shù)據(jù)集上的遷移學(xué)習(xí)能力,從中可以看到:
-
在所有數(shù)據(jù)集上,CMT-S均優(yōu)于其他Transformer模型,同時具有更少的FLOPs; -
CMT-S取得了與EfficientNet-B7相當(dāng)?shù)男阅埽瑫r具有少9倍的FLOPs。
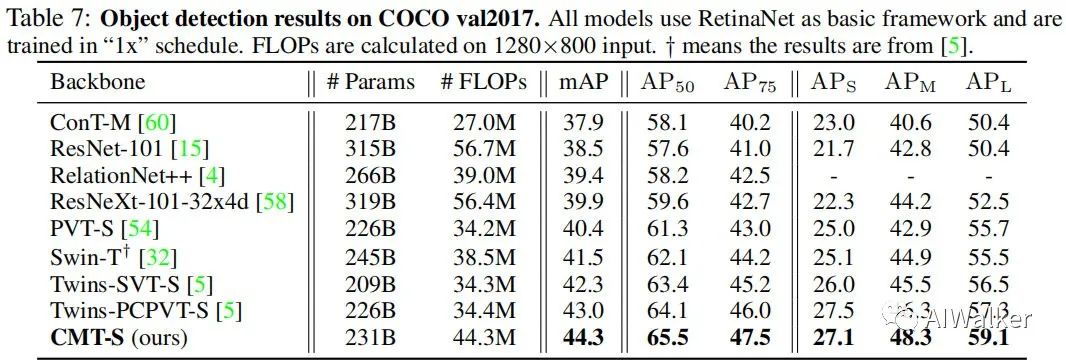
上表給出了所提方法在COCO檢測數(shù)據(jù)集上的遷移學(xué)習(xí)性能對比,從中可以看到:以RetinaNet作為基礎(chǔ)框架,CMT-S取得了比Twins-PCPVT-S高1.3%mAP,比Twins-SVT-S高2.0%mAP的性能。
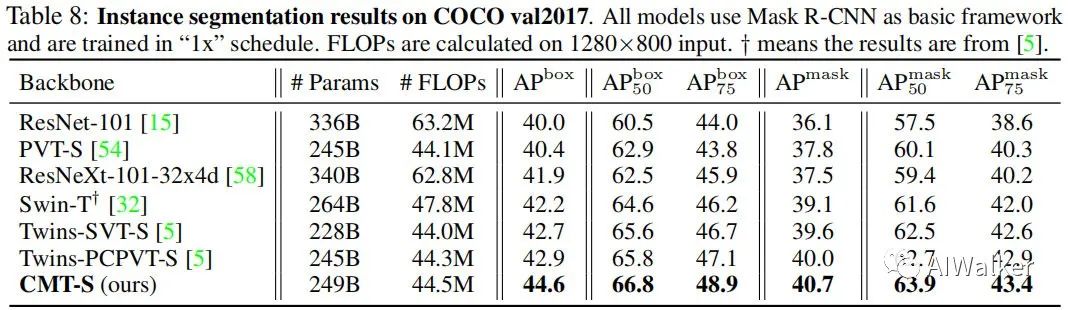
上表給出了所提方法在COCO實例分割任務(wù)上的性能對比,可以看到:以Mask R-CNN為基礎(chǔ)框架,CMT-S取得了比Twins-PCPVT-S高1.7%AP,比Twins-SVT-S高1.9%AP的性能。
Inference Speed
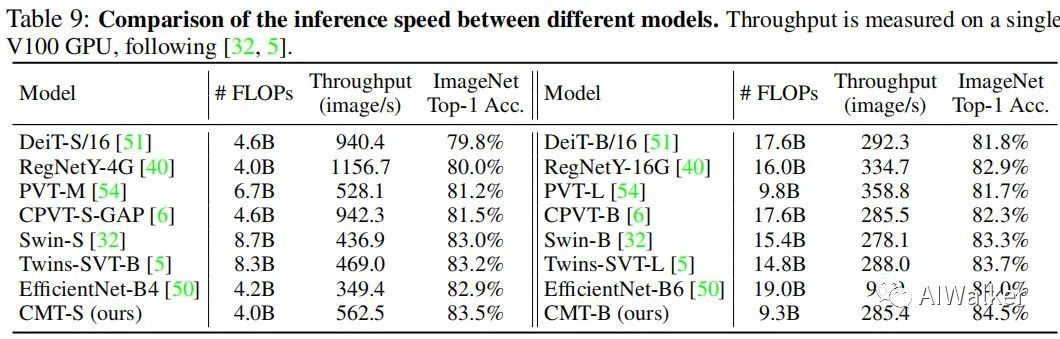
上表給出了所提CMT-S與CMT-B在ImageNet上的推理速度對比,從中有看到:所提CMT具有更佳的速度-精度均衡。速度最快的還是愷明大神等人提出的RegNetY。
Ablation Study
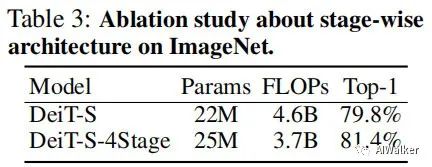
上表對比了分階段架構(gòu)的性能對比,可以看到:當(dāng)為DeiT插上分階段的思想后,其性能取得了1.6%的提升,同時具有更少的FLOPs。
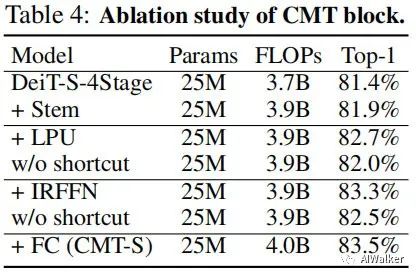
上表對比了所提CMT不同模塊的作用,從中可以看到:
-
引入Stem可以帶來0.5%的性能提升; -
所提LPU與IRFFN可以分別進一步提升0.8%與0.6%; -
LPU與IRFFN中的短連接對于最終的性能同樣非常重要。
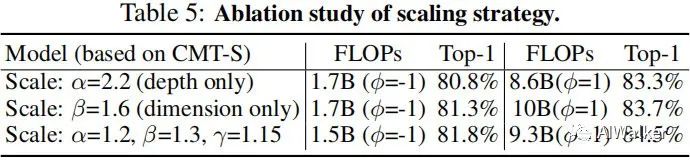
上表對比了不同縮放策略的性能對比,可以看到:單一縮放策略的性能不如符合縮放策略。
推薦閱讀

算法部署 | 萬字長文帶你從C++案例一步一步實操cmake(起飛系列)
CSL-YOLO | 超越Tiny-YOLO V4,全新設(shè)計輕量化YOLO模型實現(xiàn)邊緣實時檢測!!!

詳細解讀 | Google與Waymo教你如何更好的訓(xùn)練目標(biāo)檢測模型!!!(附論文)
長按掃描下方二維碼添加小助手。
可以一起討論遇到的問題
聲明:轉(zhuǎn)載請說明出處
掃描下方二維碼關(guān)注【集智書童】公眾號,獲取更多實踐項目源碼和論文解讀,非常期待你我的相遇,讓我們以夢為馬,砥礪前行!
