
深度解析:會用Excel,還有必要學(xué)Python嗎?
在看到知乎上有個問題:
我都會用Excel了,還有必要學(xué)Python嗎?

這個問題大概率可以說明問這個問題的這位同學(xué)目前還沒有遇到非Python不可的場景,之所以產(chǎn)生了學(xué)Python的念頭是因?yàn)檫@兩年P(guān)ython實(shí)在是太火了,如果自己不學(xué)總覺得差點(diǎn)什么。但是學(xué)了一點(diǎn)以后又發(fā)現(xiàn)Python做的那些事情,我Excel也可以做,既然如此,我為什么還要費(fèi)這么大勁去學(xué)Python呢?
為什么要學(xué)Python
大家在學(xué)一個工具或者一項(xiàng)知識的時候,一定不要為了學(xué)而學(xué),這樣不僅學(xué)起來很痛苦,而且很難堅持下去的。
那既然如此,是不是我們就可以不學(xué)Python了?不是的,你想想為什么現(xiàn)在幾乎所有的招聘要求上都會要求掌握Python技能?

原因主要有兩個:
1、有些事情雖然Excel也能做,但是用Python效率會更高
2、有些事情是只有Python可以做,而Excel是做不了的
綜合這兩個原因,就要求你必須掌握Python技能,雖然不一定100%的工作都用Python,但是不得不用Python的時候你得會。
Excel和Python在不同場景下的異同
接下來我們就圍繞一名數(shù)據(jù)從業(yè)者在工作中可能會涉及到的工作內(nèi)容進(jìn)行展開,看看不同工作內(nèi)容下,Excel和Python的異同。主要從以下幾方面進(jìn)行展開:
數(shù)據(jù)處理與運(yùn)算 報表自動化 圖表可視化 統(tǒng)計檢驗(yàn) 機(jī)器學(xué)習(xí)算法
數(shù)據(jù)處理與運(yùn)算
數(shù)據(jù)處理與運(yùn)算這部分工作是我們工作中的大頭,我們先來看下關(guān)于數(shù)據(jù)處理與運(yùn)算中比較高頻的一些內(nèi)容:
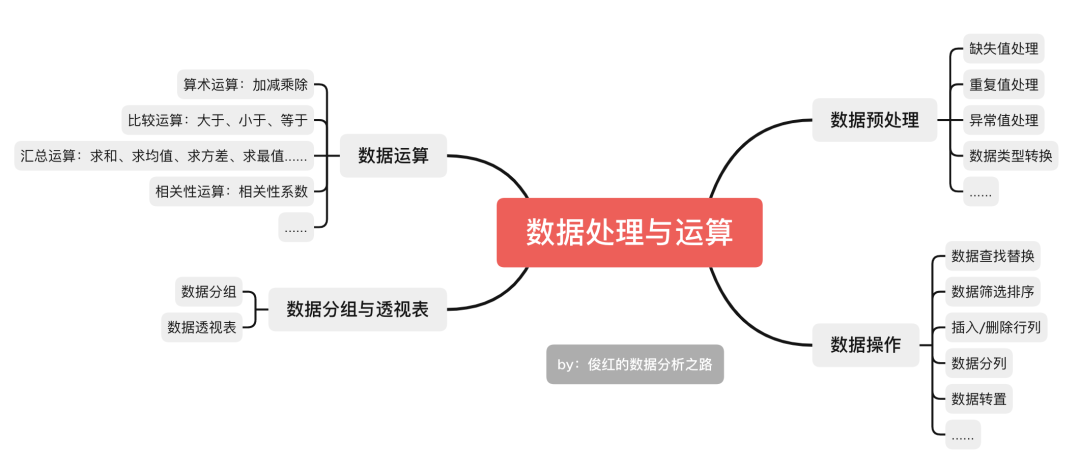
學(xué)過Excel的同學(xué)對這些應(yīng)該都不陌生,這些內(nèi)容在Excel是完全可以實(shí)現(xiàn),在Python中也是可以實(shí)現(xiàn)的,那我們應(yīng)該如何選呢?
原則就是哪個方便用哪個,如果你現(xiàn)在只有100行數(shù)據(jù),你現(xiàn)在要對這100行數(shù)據(jù)進(jìn)行降序排列,這個時候肯定用Excel效率更高,你用Python的話還需要先把數(shù)據(jù)導(dǎo)入到Python中以后再做處理,相對來說更麻煩一些。
但如果你的數(shù)據(jù)條數(shù)超過10萬行,你試著用Excel執(zhí)行一下刪除重復(fù)值的操作,幾乎會瞬間無響應(yīng),然后Excel就閃退了,很多人又沒有及時保存文件的習(xí)慣,閃退會導(dǎo)致之前做的工作白做了。如果你用Python的話,首先Python處理幾十萬條數(shù)據(jù)的時候,速度還是可以的,即使速度慢一點(diǎn),大多數(shù)時候是不會出現(xiàn)軟件閃退的,而且即使閃退了,之前的代碼是有的,只需要把之前的代碼重新運(yùn)行一遍就好了,不需要重頭再做。
如果你的數(shù)據(jù)超過100萬行,那么就只能用Python了,因?yàn)镋xcel的最大行數(shù)為1048576行。
需要聲明的是,不管是Excel還是Python,數(shù)據(jù)處理速度會跟電腦自身的性能有很大關(guān)系。
綜上,如果你平常接觸的數(shù)據(jù)都是10萬以內(nèi)的小數(shù)量級,那么其實(shí)是可以不學(xué)Python的,但如果需要經(jīng)常處理大數(shù)量級的數(shù)據(jù),還是有必要學(xué)一學(xué)Python的。
報表自動化
報表是作為一個數(shù)據(jù)從業(yè)者不得不做的一件事,常見的報表就是日報、周報、月報這些,這些報表有一個好處就是格式比較固定,只有固定的內(nèi)容我們就可以進(jìn)行自動化。而所謂的自動化就是讓機(jī)器代替人工做事情的過程。
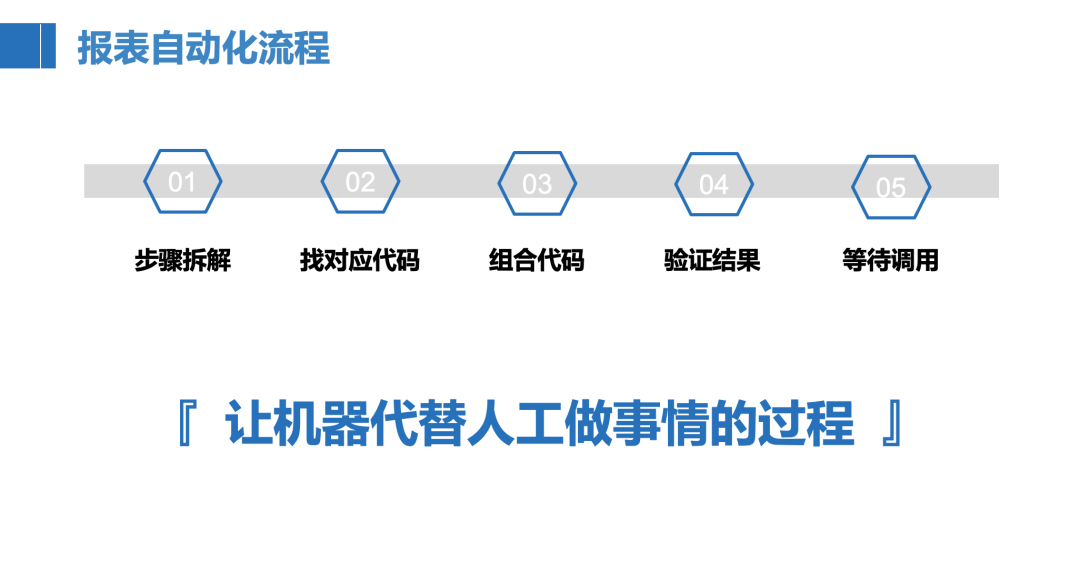
下圖是我列的常規(guī)報表自動化的流程,主要分為5個步驟,核心在于前兩個步驟,先對整個報表制作流程進(jìn)行拆解,拆解成若干個小的步驟,然后再找每個步驟對應(yīng)的代碼是什么,最后把小步驟的代碼合并起來就是整個報表制作的代碼,我們每次只需要把寫好的代碼運(yùn)行一遍,結(jié)果就自動出來了,也就達(dá)到了報表自動化的目的。
運(yùn)行效率:
在代碼這一塊我們既可以用Excel中的VBA,也可以用Python。那我們應(yīng)該如何選呢?首先看效率問題,有個博主專門測試過Python和VBA逐行讀取同一個文件,Python耗時0.639秒,VBA耗時2.855秒,兩者相差4.x多倍。
博文鏈接:
https://www.cnblogs.com/metree/p/3477351.html
書寫效率:
除了執(zhí)行效率方面以外,還有就是代碼書寫效率,下面截圖是從網(wǎng)上找的一個關(guān)于讀取txt文件的VBA代碼:

文檔鏈接:
https://blog.csdn.net/weixin_42578747/article/details/90111536
下面是用Python讀取txt文件時的代碼:
import pandas as pd
pd.read_table('file_name.txt')
是不是明顯Python的代碼要更簡潔,而且更容易理解,read_table就是讀取文件,多直觀。
綜上,如果是平常有大量工作需要自動化的話,也還是有必要學(xué)習(xí)Python的。
圖表可視化
效率方面:
圖表可視化也是我們?nèi)粘9ぷ髦斜容^使用比較高頻一部分,圖表除了傳遞信息以外,還要盡可能的美觀,讓看表的人視覺體驗(yàn)更好。
下圖中左半圖時Excel默認(rèn)的折線圖樣式,右半圖時Python中Seaborn庫中默認(rèn)的折線圖樣式,很明顯右圖要比左圖觀看體驗(yàn)上更好一些。
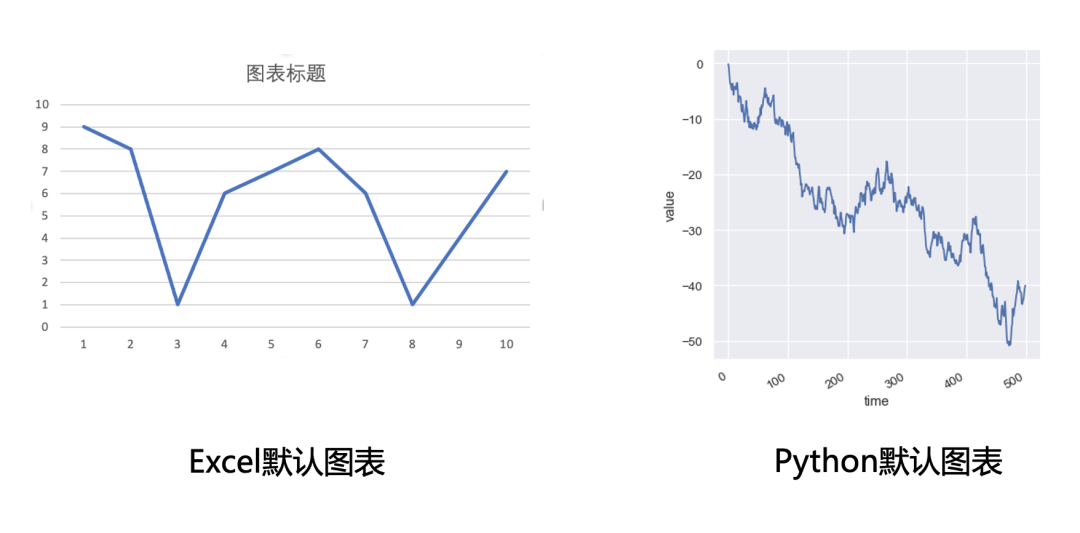
雖然Excel圖表在進(jìn)行專門的樣式設(shè)置以后也能達(dá)到比較好看的效果,但是進(jìn)行樣式設(shè)置很耗費(fèi)時間的,我們還是希望用更少的時間得到稍微不那么丑的圖表。
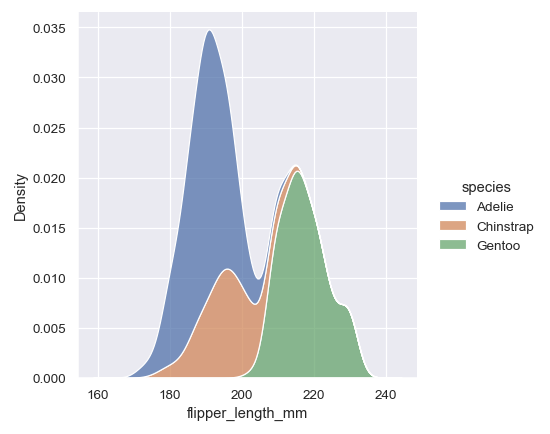
再比如繪制統(tǒng)計學(xué)中的核密度圖,雖然Excel中也可以通過復(fù)雜的操作實(shí)現(xiàn),但是Python中只需要如下一行代碼就可以繪制出比較好看的核密度圖:
sns.displot(penguins, x="flipper_length_mm", hue="species", kind="kde", multiple="stack")
圖表全面性:
上面是看了Excel和Python的在效率方面的差異,接下來我們看下在圖表全面性方面兩者的差別。
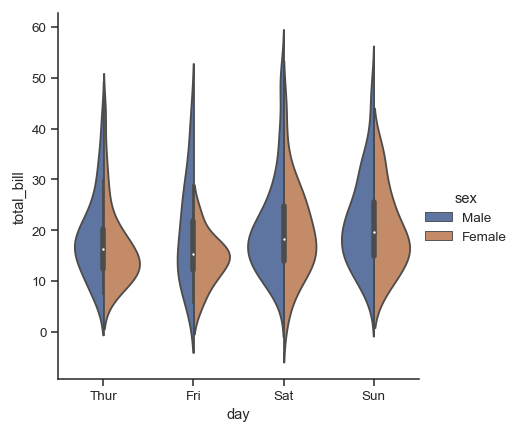
折線圖、柱狀圖是比較常見的一些圖表,除了這些比較常規(guī)的圖表以外,我們有的時候我們還會去繪制一些比較專業(yè)圖表,比如小提琴圖,在Excel里面就不太好去實(shí)現(xiàn),而在Python里面也只需要如下一行代碼就可以輕松實(shí)現(xiàn):
sns.catplot(x="day", y="total_bill", hue="sex",
kind="violin", split=True, data=tips)
在圖表可視化方面,Python中有很多的庫可以供我們使用,下面是一些比較常用的庫的官網(wǎng),我們只需要根據(jù)具體場景選擇適合自己的就好了。
matplotlib官網(wǎng):https://matplotlib.org/
pyecharts官網(wǎng):https://pyecharts.org/#/
seaborn官網(wǎng):https://seaborn.pydata.org/index.html
plotly官網(wǎng):https://chart-studio.plotly.com/feed/#/
Boken官網(wǎng):https://docs.bokeh.org/en/latest/
綜上,如果平常工作中對圖表的視覺體驗(yàn)沒太多要求,而且也涉及到一些高級的統(tǒng)計圖表的話,Excel就用了。如果要是對效率和圖表的全面性都有要求的話,還是有必要學(xué)Python的。
統(tǒng)計學(xué)檢驗(yàn)
我們在平常工作中會做很多AB測試,而AB測試的核心就是背后的統(tǒng)計學(xué)檢驗(yàn),我們看下Excel和Python在統(tǒng)計檢驗(yàn)方面有啥區(qū)別。
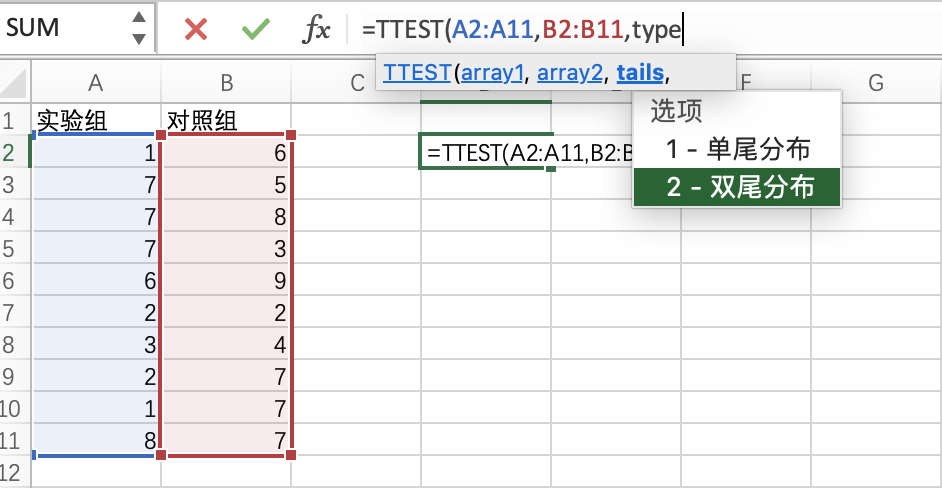
統(tǒng)計檢驗(yàn)中比較基礎(chǔ)的檢驗(yàn)就是T檢驗(yàn)。
在Excel中進(jìn)行T檢驗(yàn)時,使用的TTEST()函數(shù),在該函數(shù)中指明要檢驗(yàn)的兩組數(shù)據(jù)核檢驗(yàn)分布即可,也比較簡單:
在Python中進(jìn)行T檢驗(yàn)時,使用的代碼如下:
stats.ttest_ind(treat_data, control_data)
從簡單的T檢驗(yàn)來看的話,兩者基本沒啥差別。
稍微高級一點(diǎn)的就是多重檢驗(yàn),就是用來檢驗(yàn)多組內(nèi)任意兩組之間的差異情況,此時如果在Excel中需要用到人工進(jìn)行兩兩比較,而在Python中只需要下面一行代碼即可得出兩兩之間的檢驗(yàn)結(jié)果。
MultiComparison(data, groups)
綜上,一些簡單的檢驗(yàn)的話,Excel和Python是沒啥區(qū)別的,而一些稍微復(fù)雜的檢驗(yàn)的話,Python里面都會把復(fù)雜的步驟封裝好,使用起來會更方便。
機(jī)器學(xué)習(xí)算法
作為一名數(shù)據(jù)分析師,雖然日常工作中的主要工作不是做算法,但是還是需要對一些常見算法的原理和實(shí)現(xiàn)是了解的。
機(jī)器學(xué)習(xí)領(lǐng)域比較知名的庫就是Sklearn,用這個庫可以讓你很輕松的就能夠?qū)崿F(xiàn)一個機(jī)器學(xué)習(xí)算法。
算法里面最基礎(chǔ)的就是線性回歸了,運(yùn)行如下代碼就可以求取出線性回歸的各項(xiàng)系數(shù):
from sklearn import linear_model
reg = linear_model.LinearRegression()
reg.fit([[0, 0], [1, 1], [2, 2]], [0, 1, 2])
reg.coef_
Sklearn庫中不僅包含了常見的分類和回歸算法,還包含了特征工程等部分,讓你輕松掌握機(jī)器學(xué)習(xí)。
Sklearn官網(wǎng):https://scikit-learn.org/stable/index.html
而Excel中是沒有這種條件的。
上面從各個方面介紹了在不同場景下Excel和Python的異同,相信大家對于自己到底要不要學(xué)Python應(yīng)該比較清楚了。那如果想學(xué),我們應(yīng)該怎么學(xué)呢?
怎么學(xué)
學(xué)習(xí)Python首先要明白兩句核心內(nèi)容,只要真正理解了這兩句話,那你學(xué)起來會很快的:
1、不管Excel還是Python,這些都是實(shí)現(xiàn)工具而已,背后的理論原理是都一樣的;2、常用的功能大概占全部功能的20%,剛開始學(xué),要抓主要矛盾,學(xué)主要內(nèi)容,等把主要內(nèi)容學(xué)會以后,再學(xué)次要內(nèi)容就容易很多了。
對比學(xué)習(xí)法
Excel中的數(shù)據(jù)透視表大家應(yīng)該都比較熟悉,核心就是下面這四個框,只需要把不同的字段拖到對應(yīng)的框里面就行。

如果現(xiàn)在我讓你用Python對一個數(shù)據(jù)表做一個數(shù)據(jù)透視表,你肯定會一臉懵,Excel中都是鼠標(biāo)拖拽的,Python要怎么實(shí)現(xiàn)呢?
其實(shí)也簡單,在Python中做數(shù)據(jù)透視表需要用到pivot_table()函數(shù),該函數(shù)的關(guān)鍵參數(shù)如下:
pd.pivot_table(data,values=None,index=None,columns=None,aggfunc='mean')
看到這里應(yīng)該還不太明白,我們再往下看:

看到這張圖是不是就差不多理解了,不同的參數(shù)其實(shí)就代表Excel中不同的框,在Excel中是用鼠標(biāo)把字段拖到框里面,在Python中是將字段名賦值給相應(yīng)的參數(shù)。
pivot_table()函數(shù)中的data參數(shù)表示要做數(shù)據(jù)透視表的整個表,aggfunc表示對values的進(jìn)行什么樣的運(yùn)算。
數(shù)據(jù)透視表不是Excel所獨(dú)有的,在不同工具里面的實(shí)現(xiàn)邏輯是一樣的,只不過具體的實(shí)現(xiàn)方式會不一樣,但是只要我們把背后的邏輯掌握了,然后借助于我們現(xiàn)有的、比較熟悉的Excel去學(xué)習(xí)和理解Python的實(shí)現(xiàn)方式,這樣學(xué)起來就會輕松很多。

其實(shí)不僅是透視表這個案例,我們所用到的很多知識都是可以按照這種思路去學(xué)習(xí)的,我們把這種學(xué)習(xí)方法稱為對比學(xué)習(xí)法。
我的《對比Excel》系列三本書:《對比Excel,輕松學(xué)習(xí)Python數(shù)據(jù)分析》、《對比Excel,輕松學(xué)習(xí)SQL數(shù)據(jù)分析》、《對比Excel,輕松學(xué)習(xí)Python報表自動化》均是采用了這種思想進(jìn)行寫作的。
先解決主要矛盾
很多Python的書和課程會追求大而全,會講很多又難但又使用頻率不那么高的知識點(diǎn),比如面向?qū)ο缶幊蹋芏鄬W(xué)了幾年的人也沒學(xué)會,新手一學(xué)更是懵逼。這些知識點(diǎn)會把很多新人勸退的,真正的做到了從入門到放棄。

我們在剛開始學(xué)的時候,盡量去學(xué)那些主要的知識點(diǎn),學(xué)完之后馬上逼自己把學(xué)到的應(yīng)用到實(shí)際工作中,當(dāng)你看到學(xué)有所用的時候,大腦會形成正向反饋,越學(xué)越有勁,很快就學(xué)會了。




