服務端壓測指標如何評估?
可能很多QA、RD同學跟我都一樣,對服務端壓測一直沒有系統(tǒng)的認知,印象停留在使用壓測工具如Jmeter對單接口發(fā)壓,調整線程數(shù)和循環(huán)數(shù)來制造不同壓力,最后計算一下TPS和成功率等就完事了?網(wǎng)上雖然有不少壓測相關的文章,但多數(shù)是壓測工具的入門級使用,有的是壓測流程和指標的簡單解釋,或者就是幾個大廠牛逼的全鏈路壓測能力和壓測平臺的介紹。這些文章要不缺少系統(tǒng)性闡述,要不過于抽象不好理解,對沒怎么接觸過壓測的同學看起來還是不太理解,本文就重點從壓測指標如何評估這個角度出發(fā)。
壓測流程
完整的壓測流程一般包含下面幾個步驟:
1、壓測目標的制定
2、壓測鏈路的梳理
3、壓測環(huán)境的準備
4、壓測數(shù)據(jù)的構造
5、發(fā)壓測試
6、瓶頸定位及容量微調
7、壓測總結和報告
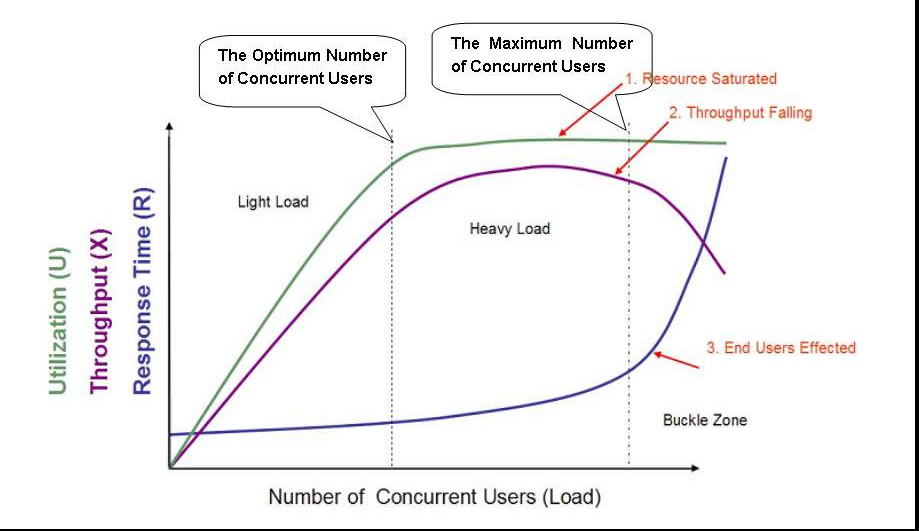
壓測指標
列舉一些常用指標,并不一定都需要關注,根據(jù)業(yè)務考慮指標的細化粒度。
QPS:Query Per Second,每秒處理的請求個數(shù)
TPS:Transactions Per Second,每秒處理的事務數(shù),TPS <= QPS
RT:Response Time,響應時間,等價于Latency
RT分平均延時,Pct延時(Percentile分位數(shù))。平均值不能反映服務真實響應延時,實際壓測中一般參考Pct90,Pct99等指標
CPU使用率:出于節(jié)點宕機后負載均衡的考慮,一般 CPU使用率 < 75% 比較合適
內存使用率:內存占用情況,一般觀察內存是否有尖刺或泄露
Load指標:CPU的負載,不是指CPU的使用率,而是在一段時間內CPU正在處理以及等待CPU處理的進程數(shù)之和的統(tǒng)計信息,表示CPU的負載情況,一般情況下 Load < CPU的核數(shù)*2,更多參考鏈接1和鏈接2
緩存命中率:多少流量能命中緩存層(redis、memcached等)
數(shù)據(jù)庫耗時:數(shù)據(jù)庫就是業(yè)務的生命,很多時候業(yè)務崩掉是因為數(shù)據(jù)庫掛了
網(wǎng)絡帶寬:帶寬是否瓶頸
接口響應錯誤率 or 錯誤日志量
這里要說明一下QPS和TPS的區(qū)別:
QPS一般是指一臺服務器每秒能夠響應的查詢次數(shù),或者抽象理解成每秒能應對多少網(wǎng)絡流量
TPS是指一個完整事務,一個事務可能包含一系列的請求過程。舉個??,訪問一個網(wǎng)頁,這是一個TPS,但是訪問一個網(wǎng)頁可能會對多個服務器發(fā)起多次請求,包括文本、js、圖片等,這些請求會當做多次QPS計算在內,因為它們都是流量性能測試中,平均值的作用是十分有限的,平均值代表前后各有50%的量,對于一個敏感的性能指標,我們取平均值到底意味著什么?是讓50%的用戶對響應時間happy,但是50%的用戶感知到響應延遲?還是說50%的時間系統(tǒng)能保證穩(wěn)定,而50%的時間系統(tǒng)則是一個不可控狀態(tài)?
平均響應時間這種指標,只有在你每次請求的響應時間都是幾乎一樣的前提下才會有一樣。再來個例子,人均財富這個概念有多沙雕相信大家也明白,19年有個很搞笑的新聞——騰訊員工平均月薪七萬,明白平均值多不靠譜了吧??。下圖是現(xiàn)實世界中一個系統(tǒng)的響應時間柱狀圖,RT在前20%的請求數(shù)較少,但是因為耗時特別短(拉高了均值可能是命中緩存,也可能是請求的快速失敗),而大多數(shù)RT是在均值之下,那才是系統(tǒng)的實際性能情況。
均值并不能反映實際情況,所以說,我們不應看最好的結果,相反地,應該控制最壞的結果,用戶用得爽他不保證會傳播好口碑,但是用戶用到生氣他保證變?yōu)殒I盤俠肆意大罵,這也是為什么平均值無法帶來足夠的參考,因為happy的結果蒙蔽了我們的雙眼,平均值在壓測中丟失太多信息量。
總結一下,較為科學的評估方法應該將指標-成功率-流量三者掛鉤在一起的,比如:99%的響應在500毫秒內返回,其中成功率為99.99%。
根據(jù)這個方針,可以得到一些測試思路:
1、在響應時間的限制下,系統(tǒng)最高的吞吐量(這里不對吞吐量做嚴格定義,當成是QPS或TPS即可)
2、在成功率100%的前提下,不考慮響應時間長短,系統(tǒng)能承受的吞吐量
3、容忍一定的失敗率和慢響應,系統(tǒng)最高能承受的吞吐量(95%成功率,前95%的請求響應時間為xx毫秒時的最大QPS)
4、在上面的場景下還要考慮時間和資源,比如最高吞吐量持續(xù)10分鐘和持續(xù)1小時是不一樣的,不同的時間持續(xù)長度下,機器資源(cpu、內存、負載、句柄、線程數(shù)、IO、帶寬)的占用是否合理
目標預估
壓測開展前是需要有目標的,也就是有期望的性能情況,希望接口或系統(tǒng)能達到的性能預期,沒有目的的壓測是浪費人力,下面給出幾種目標預估的方法。
歷史監(jiān)控數(shù)據(jù)
已經上線并且有歷史監(jiān)控數(shù)據(jù)的接口,可以查看歷史數(shù)據(jù),找出峰值QPS和PCT99。?? 若接口A已經上線并且做了監(jiān)控,在經過某次大活動或者上線時間足夠長后,存量監(jiān)控數(shù)據(jù)就可以使用了。
類比
新接口或者線上未監(jiān)控的接口,不存在歷史數(shù)據(jù),但存在類似功能接口的歷史監(jiān)控數(shù)據(jù),可以通過類比得出壓測的目標。?? 假設上一年淘寶雙十一下訂單接口QPS=x,RT=y,這一年天貓平臺整起來了,雙十一活動與上年淘寶雙十一活動場景類似,也沿用QPS=x,RT=y的目標(例子不嚴謹,理解即可)。
估算
新接口或者線上未監(jiān)控的接口,不存在歷史數(shù)據(jù),且不存在類似功能接口的數(shù)據(jù)可供參數(shù)考,此時需要估算峰值,常用方法有8/2原則——一天內80%的請求會在20%的時間內到達。
top QPS = (總PV * 0.8) / (60 * 60 * 24 * 0.2)
RT如無特殊要求,一般采用默認值:
單服務單表類,RT<100ms
較復雜接口,RT<300ms
大數(shù)據(jù)量或調用鏈較長的接口,RT<1s
??-1:電商秒殺活動,預估同時有1000w人參與,簡單起見假設總QPS是1000w。由于前端不同的秒殺倒計時形式使得請求有2s的打散,再加上nginx等webserver做了20%幾率拒絕請求的策略,所以下單接口總QPS = 1000w / 2 * (1 - 0.2) = 400w/s,最終壓測目標為400w/s的QPS。
??-2:電商全天低價搶購活動,屠龍寶刀,點擊就送,一刀99級,emmmmm跑題了。根據(jù)8/2原則,預估在午休(12-1)和晚上下班后(7-10)共4h是流量高峰,估算接口峰值QPS = 活動全天接口PV / (4*3600s)。
其他
除了前面說到的情況,肯定還有一些我們無法下手的三無接口,無參考、無預估、無歷史數(shù)據(jù),這時候只能一點一點來,慢慢把壓力提上去的同時收集數(shù)據(jù),最終得出接口的最優(yōu)處理能力。