
Paimon 概覽 | Apache Paimon 流式數(shù)據(jù)湖 V 0.4 與后續(xù)展望
1. 湖存儲上的難點(diǎn) 2. 深入 Apache Paimon 0.4 3. 社會應(yīng)用實(shí)踐 4. 后續(xù)規(guī)劃
Tips: 點(diǎn)擊 「閱讀原文」 免費(fèi)領(lǐng)取 5000CU*小時(shí) Flink 云資源
今年 6 月份 Paimon 0.4 剛剛發(fā)布,它是一個(gè)非常具有競爭力的版本,也是進(jìn)入 Apache 孵化器之后的第一個(gè)版本。
01
湖存儲上的難點(diǎn)
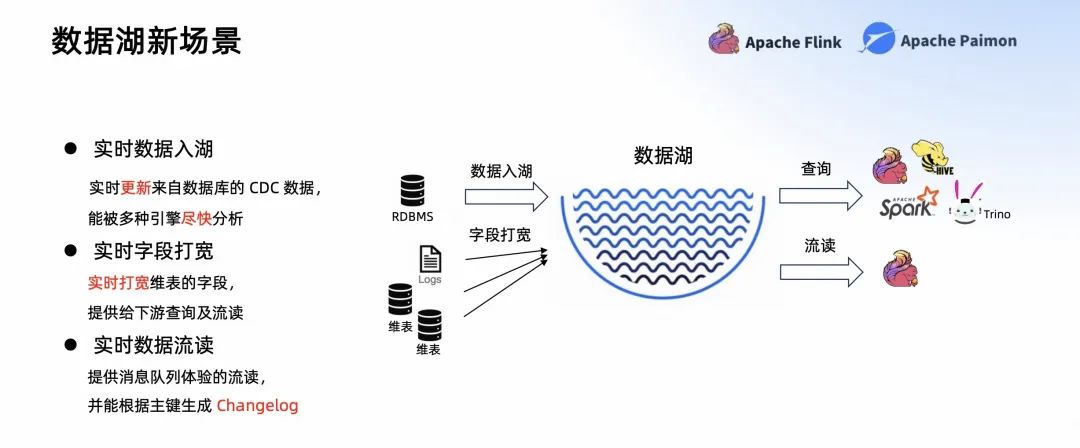
- 第一個(gè)場景,實(shí)時(shí)數(shù)據(jù)入湖。數(shù)據(jù)可以實(shí)時(shí)更新來自數(shù)據(jù)庫的 CDC 數(shù)據(jù),實(shí)時(shí)入湖到數(shù)據(jù)湖中,讓數(shù)據(jù)能被多種引擎盡快分析。
- 第二個(gè)場景,實(shí)時(shí)字段打?qū)挕?shí)時(shí)打?qū)捑S表的字段,提供給下游查詢及流讀。
-
第三個(gè)場景,實(shí)時(shí)數(shù)據(jù)流讀。提供消息隊(duì)列體驗(yàn)的流讀,并能根據(jù)主鍵生成 Changelog。
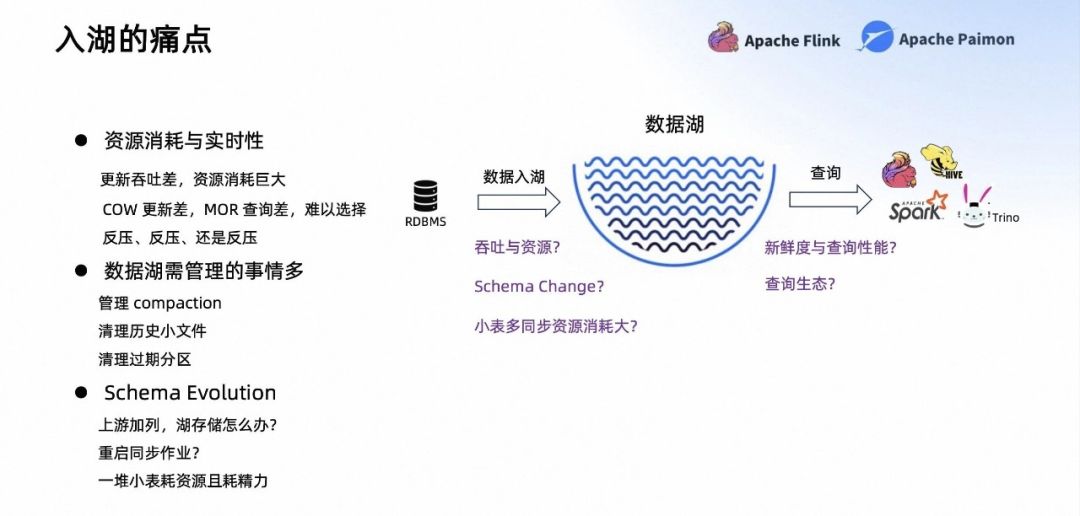
- 資源消耗與實(shí)時(shí)性:更新吞吐差,資源消耗巨大;COW 更新差,MOR 查詢差,難以選擇反壓、反壓、還是反壓。
- 數(shù)據(jù)湖需管理的事情多:管理 Compaction;清理歷史小文件;清理過期分區(qū)。
-
Schema Evolution:上游加列,湖存儲怎么辦?重啟同步作業(yè)?一堆小表耗資源且耗精力。
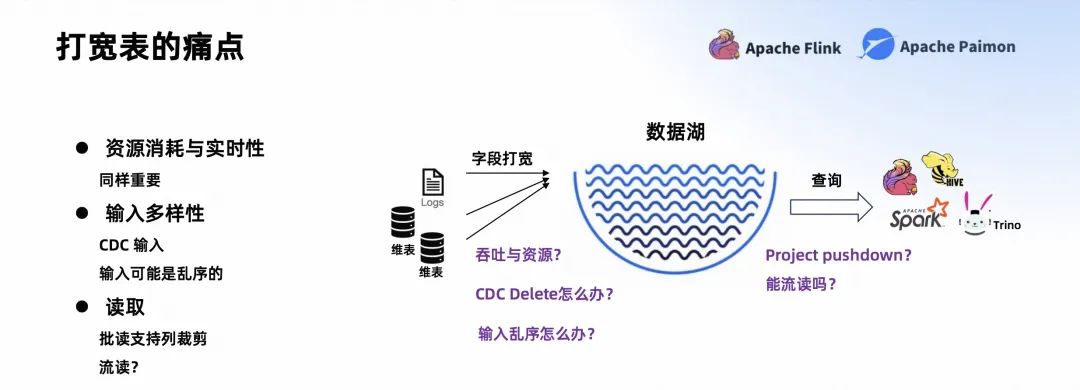
- 資源消耗與實(shí)時(shí)性:吞吐和資源同樣重要。
- 輸入多樣性:CDC 輸入;輸入可能是亂序的。
-
讀取:希望可以足夠高效,有 Project pushdown,且可以流讀。

- 全增量一體流讀:先讀全量再接增量,完整的流,而不是只讀增量。
- Changelog 生成:有些場景要低成本;有些場景要低時(shí)延。
- FileNotFound:數(shù)據(jù)湖文件清理和流讀的矛盾。
-
Lookup Join:支持 Flink 的 Lookup Join。

Apache Paimon 是一個(gè)專門為 CDC 處理、流計(jì)算而生的數(shù)據(jù)湖。希望帶來你舒服、自動的湖上流處理體驗(yàn)。
從官網(wǎng)上也可以看到,Apache Paimon 支持高速的數(shù)據(jù)寫入,Changelog 的生成以及高效的實(shí)時(shí)查詢。
02
深入 Apache Paimon 0.4
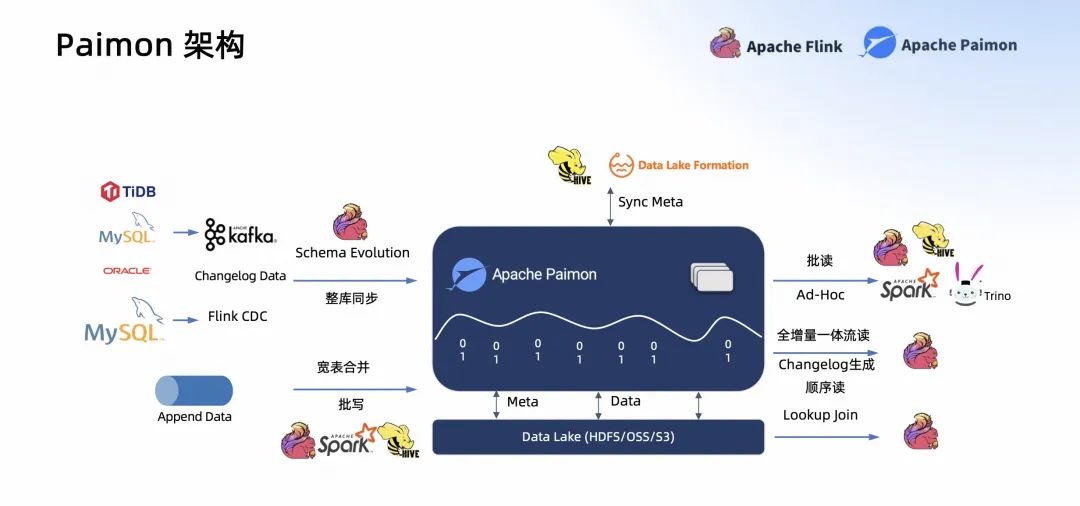
Paimon 的整體架構(gòu)是一個(gè)數(shù)據(jù)湖 build 在 Data Lake (HDFS/OSS/S3),它的所有 Meta 和數(shù)據(jù)都存儲在這些數(shù)據(jù)湖上,它是一個(gè)數(shù)據(jù)湖格式。這個(gè)數(shù)據(jù)湖的 Meta 也可以同步到 Hive Metastore 和阿里云的 Data Lake Formation 上,做一個(gè)統(tǒng)一的、數(shù)據(jù)的、表格式的管理。然后數(shù)據(jù)湖通過把 Changelog 同步到入湖中,再同步 Kafka。
現(xiàn)在 Paimon 0.4 提供了 Flink CDC 的 Schema Evolution 同步,也提供了 MySQL 的整庫同步,后續(xù) Paimon 0.5 會支持 Kafka 的 CDC 數(shù)據(jù)同步。此外,我們還可以通過 Flink 將 Append 的 log data 通過批寫的方式寫入 Paimon 中,也可以通過寬表合并的方式寫入 Paimon 中。
在讀端,Paimon 可以支持來自各種引擎的批讀和 Ad-Hoc 查詢,比如 Spark、Trino、StarRocks 等,也可以通過 Flink 來全增量一體的流讀它的 Changelog,而且流讀是可以提供數(shù)據(jù)順序保障的,也可以通過 Flink 來 Lookup Join。
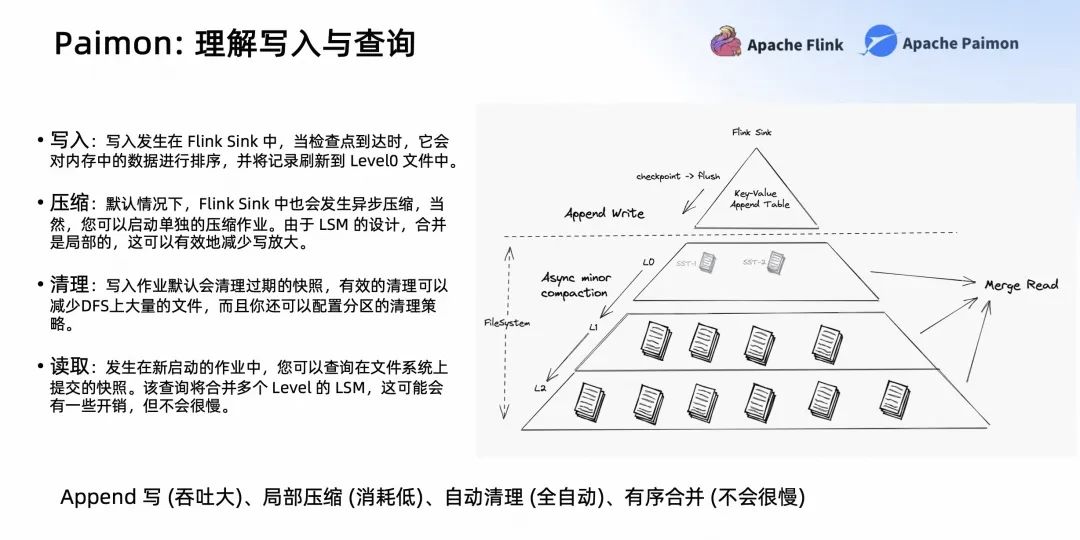
Paimon 是數(shù)據(jù)湖+LSM 的架構(gòu),下面和大家分享一下為什么 Paimon 需要 LSM。
LSM 是一個(gè)面向?qū)懹押玫母袷剑趯懭氲臅r(shí)候可以看到整個(gè)流程,但它不用理解具體的流程,大致的思路是,寫入發(fā)生在 Flink Sink 中,當(dāng)檢查點(diǎn)到達(dá)時(shí),它會對內(nèi)存中的數(shù)據(jù)進(jìn)行排序,并將記錄刷新到 Level0 文件中。
得益于 LSM 這種原生異步的 Minor Compaction,它可以通過異步 Compaction 落到最下層,也可以在上層就發(fā)生一些 Minor 的 Compaction 和 Minor 的合并,這樣壓縮之后它可以保持 LSM 不會有太多的 level。保證了讀取 merge read 的性能,且不會帶來很大的寫放大。
另外,F(xiàn)link Sink 會自動清理過期的快照和文件,還可以配置分區(qū)的清理策略。所以整個(gè) Paimon 提供了吞吐大的 Append 寫,消耗低的局部 Compaction,全自動的清理以及有序的合并。所以它的寫吞吐很大,merge read 不會太慢。

- 入湖的資源節(jié)省了 30%-40%。
- 寫入性能提升了 3 倍。
-
部分查詢的性能提升了 7 倍左右。

剛剛分享了 Paimon CDC 數(shù)據(jù)的入湖在吞吐方面的一些能力,下面介紹一下 Paimon 在 CDC 入湖上,給用戶帶來的一些比較方便的入湖工具。
比如在 Paimon 0.4 中,我們提供了 Flink CDC 的入湖。原生集成的 Flink CDC 提供 DataStream 作業(yè),通過 Flink CDC 把 Changelog 的數(shù)據(jù)通過 Schema Evolution 的方式寫入 Paimon。
表同步,它可以自動的管理表結(jié)構(gòu)變更,增加列、刪除列、變更類型、重命名列等等。也可以通過在表同步的定義,新增計(jì)算列、定義分區(qū)列、定義主鍵,以及做分庫分表的同步。
此外,Paimon CDC 入湖還提供了整庫同步,可以讓整個(gè)庫的表全部同步到 Paimon 中,你不用擔(dān)心 OOM 或者容易掛掉。一個(gè)作業(yè)同步過來,可以盡可能減少同步的資源。還支持 INCLUDING、EXCLUDING,還支持表名前后綴,自動跳過失敗表,動態(tài)新增表。
在 Paimon 0.5 中,我們提供了 Kafka 的同步。不僅可以通過 Flink CDC 同步進(jìn)來,Kafka 里面的 CDC 數(shù)據(jù)也可以同步進(jìn)來。你可以把你的數(shù)據(jù)庫,TIDB、MySQL、Oracle 寫到 Kafka 中,然后以 Schema Evolution 的同步,同步到 Paimon 中。
可以看到同步入湖非常簡單,使用 Paimon 的 Flink action 就可以啟動整個(gè)同步的作業(yè)。甚至 Paimon 還提供 CDC 的 DataStream 的 API,你可以直接調(diào)我們已經(jīng)集成好的作業(yè)來同步數(shù)據(jù),也可以通過 CDC 的 DataStream 的 API 編寫自己的 Flink 流的 Schema Evolution 的 Pipeline。
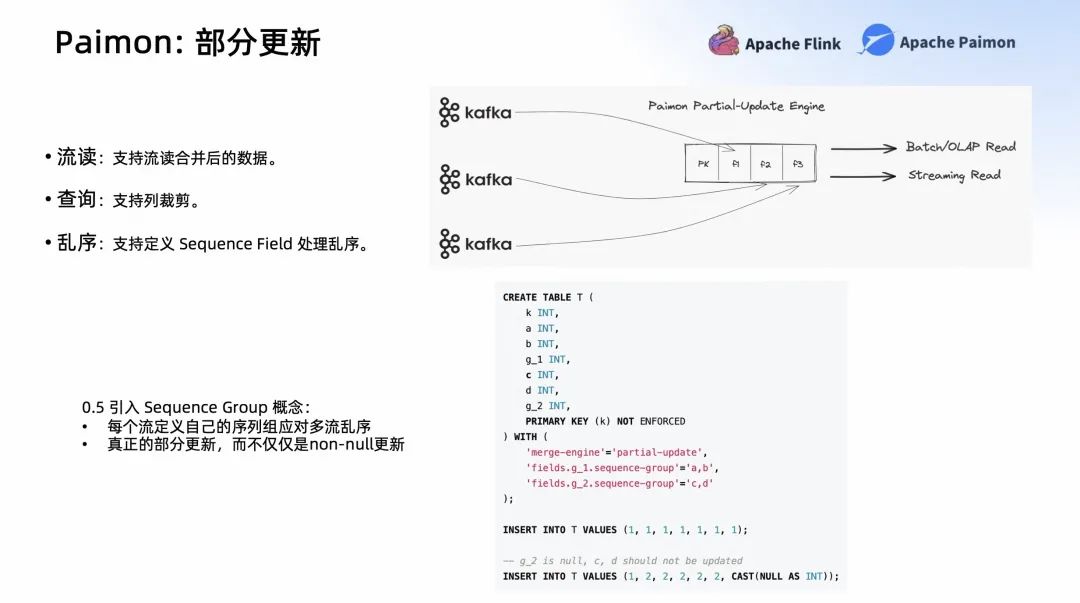
Paimon 支持定義 Partial-update,你可以定義 Partial-update Engine。這樣就可以通過不同的留寫入不同的字段,后面可以批讀,甚至 Paimon 也提供了流讀,只要聲明 Changelog Producer 就可以流讀合并后的數(shù)據(jù),它的查詢也支持列裁剪的高效查詢。
此外,Partial-update 的輸入可能是亂序的,所以在 Partial-update 表,也可以定義 Sequence Field 處理亂序的情況。在 Paimon 0.5 中引入了 Sequence Group 的概念,為了解決每個(gè)流不同的亂序。如果它們共用一個(gè)版本字段,某個(gè)流更新之后有可能會導(dǎo)致另外一個(gè)流的最新版本不能更新。
舉個(gè)例子,上游有兩個(gè)表要更新,所以要定義兩個(gè) Sequence Group,這個(gè) Sequence Group 的字段可以是不同的版本字段。這樣不同的流只要更新自己的版本就可以了,不管兩邊多不對齊,它最終的數(shù)據(jù)都能被正確的更新上。
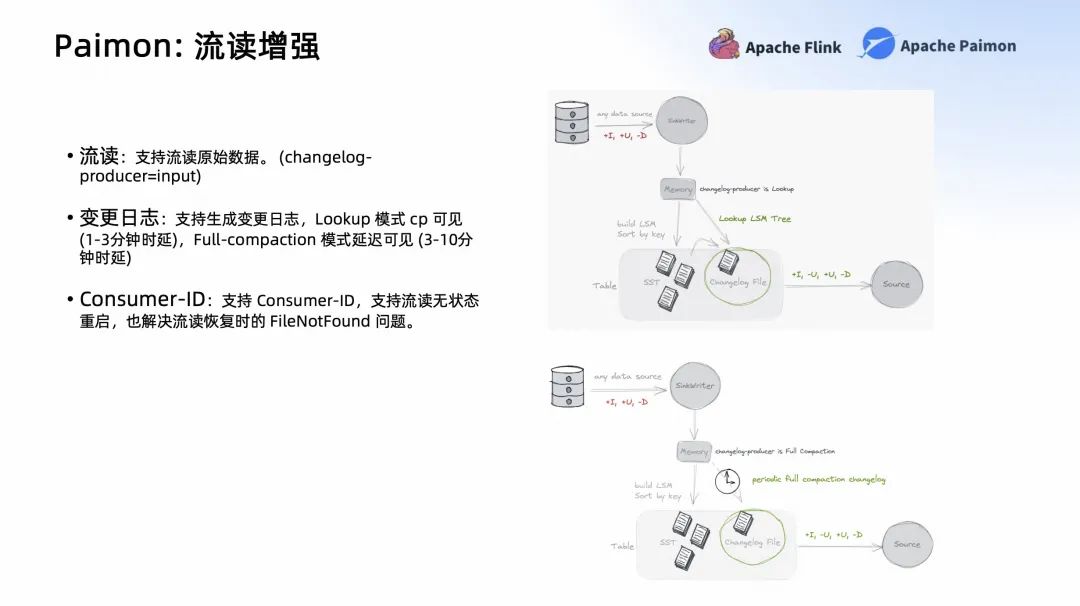
在 Paimon 中,它的流讀是它的核心之一,這也是它區(qū)別其他數(shù)據(jù)湖的一個(gè)關(guān)鍵點(diǎn)所在。Paimon 可以流讀原始數(shù)據(jù),你可以設(shè)置 changelog-producer=input。如果你的數(shù)據(jù)是一個(gè)完整的 CDC,就可以運(yùn)用這種模式,它是最高效,也是消耗資源最少的。
如果你的流不是一個(gè)完整的 CDC,比如 Partial-update 這種輸入。所以就要求下游的流讀要生成一個(gè)變更日志,在 Paimon 這里不僅支持生成變更日志,還有兩種非常靈活的模式,Lookup 模式和 Full-Compaction 模式。
Lookup 模式可以在寫入的時(shí)候就動態(tài) Lookup 高層的文件,查到最新的數(shù)據(jù),合并最新的 Changelog 輸出到下游。這是最快的,也是我們推薦 1-3 分鐘時(shí)延的,但它的成本會高一些。
如果一些作業(yè)成本要求很低,且能接受更大延時(shí),你可以用 Full-Compaction 模式。它在異步的 Full-Compaction 的時(shí)候,才會產(chǎn)生對應(yīng)的 Changelog,可以把 Full-Compaction 的周期調(diào)度時(shí)間設(shè)置的更大,比如 10 分鐘。它的好處是代價(jià)更低,但時(shí)延更高。
剛剛我們提到湖存儲和流讀有一個(gè)矛盾,它就是 FileNotFound。因?yàn)榱鞔鎯σ粩嗲謇?snapshot,這樣它的小文件才會少。但流讀如果依賴一個(gè)很早 snapshot,一旦這個(gè)流作業(yè)掛了,它讀的那個(gè) snapshot 就會被清理,它就完全不能恢復(fù)了。
針對于問題,Paimon 提出了 Consumer-ID,它有點(diǎn)類似于 Kafka 的 Group-ID。它可以保證作業(yè)掛了重啟之后,它讀的那個(gè) snapshot 不會被清理。
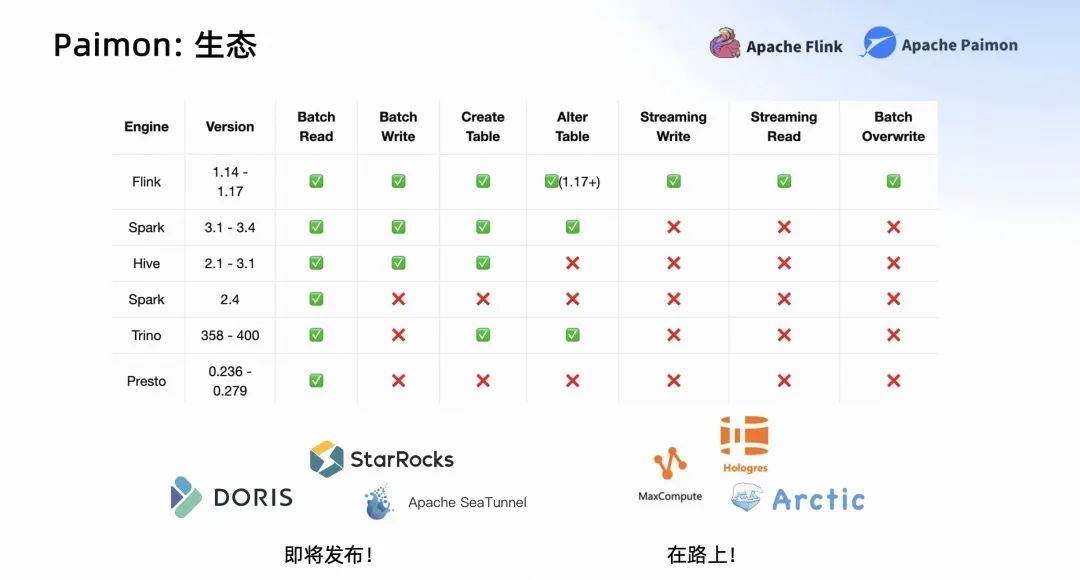
Paimon 0.4 在生態(tài)中也有比較大的進(jìn)步,如上圖所示。
最開始在 Paimon 中只是支持 Flink,它作為 Flink Table Store 支持 Flink 完整的生態(tài)和用法。
在 Paimon 0.4 中支持的更多了。比如在 Spark 中支持了 Batch Read、Batch Write,還可以在 Spark 中 Create Table、Alter Table;在 Hive 中支持了 Batch Reader、Batch Write、Create Table 等等;在 Trino 中支持了 Create Table、Alter Table 等等功能。
我們有兩個(gè)引擎是集成比較完善的,一個(gè)是 Flink,另外一個(gè)是 Spark。我們希望它所有的功能,批讀、批寫、創(chuàng)建表、修改 Meta 等命令,在 Flink 和 Spark 中都支持的比較好。其次,我們希望其他引擎都能支持讀 Paimon,甚至更多的操作,比如 Create Table、Write Table 等等。
除了這些傳統(tǒng)的處理引擎,StarRocks、Doris、Seatunnel 也集成了 Paimon,整體的代碼基本已經(jīng) ready 了,處于即將發(fā)布的狀態(tài)。阿里云上的 MaxCompute、Hologres,網(wǎng)易的 Arctic,也已經(jīng)在研發(fā)的路上了。
03
社會應(yīng)用實(shí)踐

目前開源社區(qū)主要的使用和參與者包括,阿里云、字節(jié)跳動、同程旅行、B 站、中原銀行、米哈游、汽車之家等等企業(yè)。
接下來一起看一下,大家都是怎么用 Paimon 的。
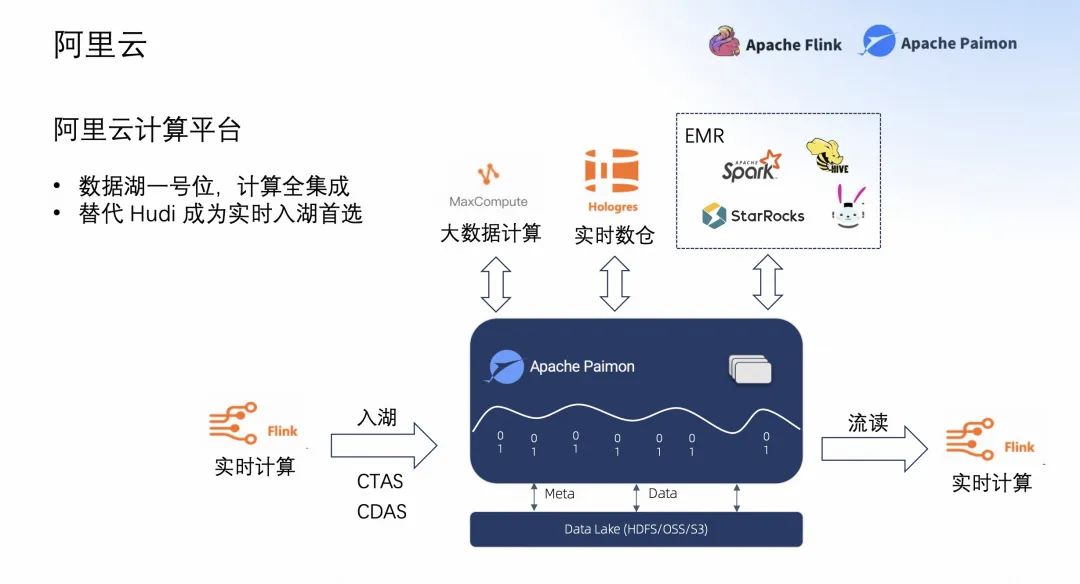
在阿里云計(jì)算平臺,Paimon 是數(shù)據(jù)湖的一號位,希望阿里云計(jì)算平臺的所有計(jì)算全部集成到 Paimon 中,集成 Paimon、讀 Paimon。最好的集成是實(shí)時(shí)計(jì)算 Flink 版平臺,它是 Flink 以及開源大數(shù)據(jù)平臺 E-MapReduce 里面,希望替代 Hudi 成為實(shí)時(shí)入湖的首選。
上圖是 Apache Paimon,可以看到我們通過阿里云的 Flink 實(shí)時(shí)計(jì)算能入湖,能 CTAS 入湖,能通過阿里云實(shí)時(shí)計(jì)算 Flink 流讀。也希望 Paimon 的數(shù)據(jù)能被 MaxCompute、Hologres 查詢,也能在開源大數(shù)據(jù)平臺 E-MapReduce 中融入的更好。
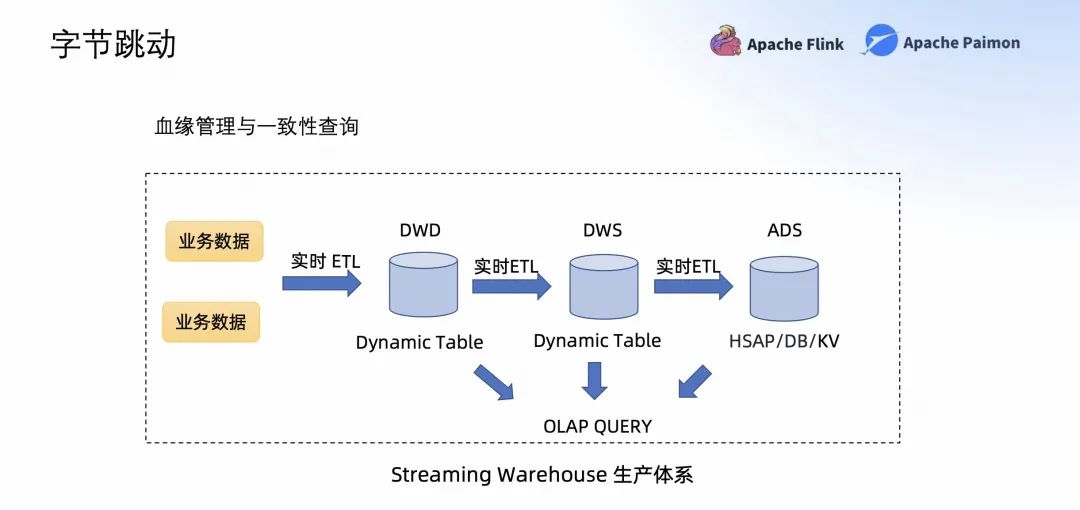
在字節(jié)跳動,工程師們使用 Paimon+Flink 作為血緣管理以及一致性查詢的 Streaming Warehouse 生產(chǎn)體系。如上圖所示,業(yè)務(wù)數(shù)據(jù)通過 Streaming ETL,類似于 Streaming materialize view 類似的概念,落到了 Streaming Warehouse 中。這樣所有的 Paimon 表都能通過一致性的 Query 查詢。

在同程旅行,引入 Paimon 主要優(yōu)化了原有 Hudi 的近實(shí)時(shí)數(shù)倉。
-
在實(shí)時(shí)寫入 ODS 層場景,Paimon 大概有 114+ 的作業(yè);最大 Upsert 日增量 2000 萬+;最大的表總量 90 億+。
-
在局部更新場景,Paimon 有 10+的作業(yè);應(yīng)用了真·局部更新 (Sequence-Group) 的概念。
-
在流讀\增量讀場景,Paimon 有 20+ 流式增量讀的作業(yè);10+ 批處理小時(shí)級增量讀的作業(yè)。

中原銀行在探索流式數(shù)倉;米哈游也在探索流批一體技術(shù);Bilibili 在攻堅(jiān) AI 方向,考慮 Partial-Update 的場景;塵鋒信息在探索 TB 級數(shù)據(jù)入湖,建設(shè)了 Flink 流批一體 + Paimon 的流批一體數(shù)倉等等。
04
后續(xù)規(guī)劃
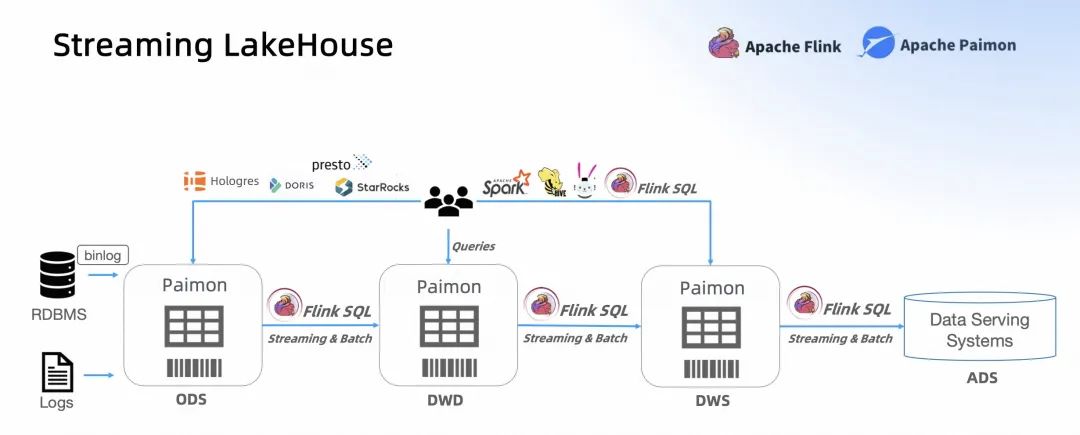
我們希望能達(dá)到這樣一個(gè) Streaming LakeHouse。數(shù)據(jù)通過非常方便的入湖能入到 Paimon 中,也能通過 Paimon 的流讀和批讀建立 Streaming 的 Pipeline。同時(shí),Paimon 也應(yīng)該有一個(gè)非常好的生態(tài),能被各種引擎查詢。這就是 Paimon+Flink 往后走的一個(gè)大方向。

打造一個(gè)易用的、簡單的 Streaming LakeHouse,大致有以下三個(gè)方向。
- 在 CDC 處理中會有更多的 CDC 入湖。比如剛剛提到的 Kafka 的入湖,應(yīng)該是更簡單、更自然、更自動的。
- 目前 Paimon 還需要定一個(gè) Bucket 個(gè)數(shù)。太小的 Bucket 性能比較差,數(shù)據(jù)量大了之后,吞吐就下來了。而太大的 Bucket,小文件又很多。雖然一個(gè) Bucket 里是一個(gè) LSM,它已經(jīng)有比較好的吞吐,但你還是要調(diào)優(yōu)。所以在 Paimon 0.5 中會提供一個(gè)動態(tài)的 Bucket,希望達(dá)到的狀態(tài)是全自動的。
-
Create tag,希望 Paimon 實(shí)時(shí)入湖之后,每天能打出一個(gè) tag 給離線生產(chǎn)用。
第二個(gè)方向:Append-Only 處理增強(qiáng)。Paimon 之前的 Append-Only 需要定義 Bucket,這是一個(gè)非常難定義的概念。所以后面 Paimon 應(yīng)該支持真正的離線表,應(yīng)該是沒有 Bucket,且離線表的寫入應(yīng)該也包含小文件合并,并這也符合 Paimon 全自動的概念。
第三個(gè)方向:除了 StarRocks 的生態(tài)的對接,我們希望將 Spark 打造成第二個(gè)像 Paimon 一樣集成非常好的引擎,Spark 讀和寫的能力都應(yīng)該很好,甚至通過 Spark+Paimon,就能組成一個(gè)完整的數(shù)據(jù)湖。
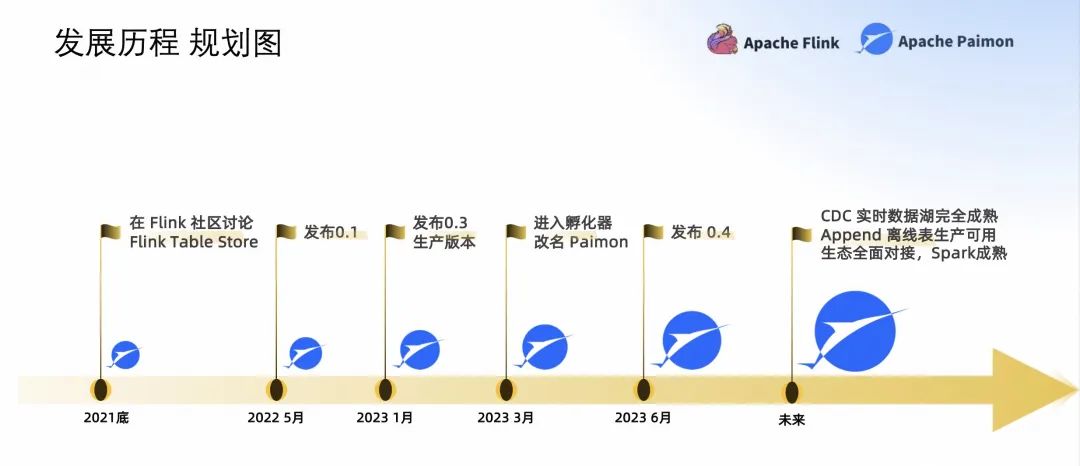
接下來回顧一下 Paimon 的發(fā)展歷程。2021 年在 Flink 社區(qū)討論;2022 年 5 月發(fā)布了 Flink Table Store 的第一個(gè)版本;2023 年 1 月發(fā)布了 0.3,它是 Paimon 的一個(gè)生產(chǎn)可用的版本;3 月進(jìn)入了孵化器,改名 Apache Paimon。2023 年 6 月,發(fā)布了 Paimon 0.4。
未來我們希望 CDC 實(shí)時(shí)數(shù)據(jù)湖完全成熟,Append 離線表生產(chǎn)可用,生態(tài)全面對接,Spark 進(jìn)入成熟狀態(tài)。
Q&A
答:關(guān)鍵還是看性能瓶頸在哪里,是否有內(nèi)存問題,最后看下 Jstack。
問:能不能動態(tài)修改表結(jié)構(gòu)呢?
答:能啊,Spark 或者 Flink 1.17 都可。
問:0.5 大概什么時(shí)候發(fā)布?
答:8 月份左右。
問:請問流讀的延遲怎么樣?
答:最小 checkpoint 延時(shí),也就是 1 分鐘。
問:如何方便的從 Hudi 遷移到 Paimon 上?
答:能,現(xiàn)在推出的 SparkGenericCatalog 也是為了 Hudi 和 Paimon 表共存。
問:可以展開講講 Changelog 的 Lookup 模式嗎?
答:可以看看官網(wǎng)
https://paimon.apache.org/docs/master/concepts/primary-key-table/#lookup
問:Bucket 是很重要的參數(shù)嗎,怎么調(diào)優(yōu)?
答:對,根據(jù)數(shù)據(jù)量實(shí)際跑下看看,目前最新也支持了動態(tài) Bucket。
問:存儲一段時(shí)間后,Bucket 可手動調(diào)整么?調(diào)整后之前的數(shù)據(jù)回重分么?
答:詳見官網(wǎng) Rescale Bucket
https://paimon.apache.org/docs/master/maintenance/rescale-bucket/
問:實(shí)時(shí)數(shù)據(jù)亂序的情況下,Paimon 的 Partial-update 怎樣避免舊數(shù)據(jù)覆蓋新數(shù)據(jù)呢,有沒有類似 sequence 列的實(shí)現(xiàn)?
答:有,詳見官網(wǎng) sequence-field
https://paimon.apache.org/docs/master/concepts/primary-key-table/#sequence-field
問:壓縮時(shí),是不是對讀寫的性能影響很大?
答:對寫有影響,是讀寫的一個(gè) tradeoff。
請關(guān)注 Paimon
- 關(guān)注微信公眾號:Apache Paimon,了解行業(yè)實(shí)踐與最新動態(tài)
- 進(jìn)入 Paimon 交流釘釘群:搜索 10880001919,討論技術(shù)并得到實(shí)時(shí)的支持
-
Github https://github.com/apache/incubator-paimon 點(diǎn)贊支持
活動視頻回顧 & PPT 獲取
PC 端
建議前往 Apache Flink 學(xué)習(xí)網(wǎng):
https://flink-learning.org.cn/activity/detail/f7aeb46d723678642e1a96d780d78baa移動端
視頻回顧/PPT 下載 :關(guān)注 Apache Flink 公眾號/ Apache Paimon 公眾號,回復(fù) 0615往期精選





▼ 「 Apache Paimon Meetup 活 動回顧 」掃下方圖片觀看全場直播回放 ▼
 ▼ 關(guān)注「 Apache Flink 」,獲取更多技術(shù)干貨 ▼
▼ 關(guān)注「 Apache Flink 」,獲取更多技術(shù)干貨 ▼

 點(diǎn)擊「閱 讀原文 」,免費(fèi)領(lǐng)取 5000CU*小時(shí) Flink 云資源
點(diǎn)擊「閱 讀原文 」,免費(fèi)領(lǐng)取 5000CU*小時(shí) Flink 云資源