
面向?qū)ο蟮乃伎?/h1>

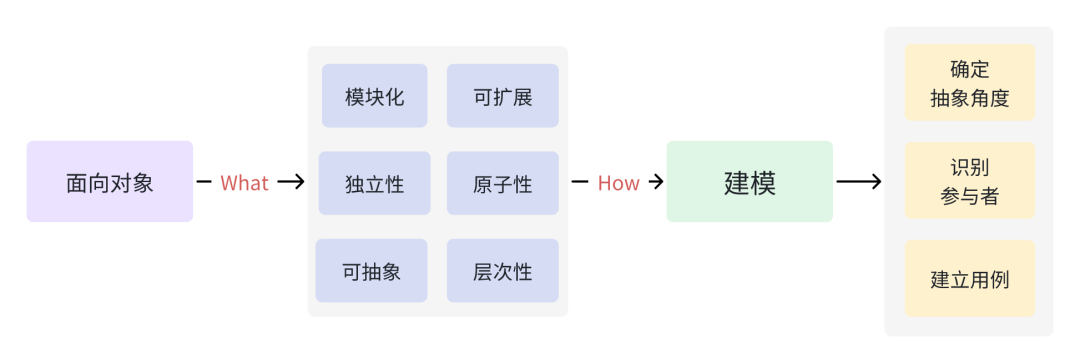
What
面向?qū)ο?/span>
作為一名程序員,代碼編程我們平時伸手就來。日常用到比較多的語言也許是 Java、TypeScript、C++ 等,大家都很清楚,這些都是面向?qū)ο蟮恼Z言。那么問題也隨之而來,是我們需要使用面向?qū)ο蟮奶匦圆胚x擇了這些語言開發(fā),還是人云亦云地選擇了這些語言開發(fā)?
在面向?qū)ο蟮睦砟钪校f物皆對象。面向?qū)ο蟮木柙谟诔橄螅嫦驅(qū)ο蟮睦щy也在于抽象。簡單來說:面向?qū)ο蟮某晒υ谟诔晒Φ某橄螅嫦驅(qū)ο蟮氖≡谟谑〉某橄蟆?/p>
對象與對象之間都是孤立的,好比現(xiàn)實生活的你和我之間。只有在特定的場景下,孤立對象之間進行了某些信息交互才表示出一個場景過程,好比基于這邊文章,你和我之間才建立起了作者和讀者的關系。
面向過程
既然說到面向?qū)ο螅瓦€應該了解到另外一個選項:面向過程。面向過程認為我們的世界是由一個個相互關聯(lián)的消息同組成的,這是一種類似 螺旋式 的結構,每個小系統(tǒng)都有明確的開始和明確的結束,開始和結束之間有著嚴謹?shù)囊蚬P系。在面向過程的設計方法中強調(diào)將問題分解成小的、可重用的模塊,每個模塊負責執(zhí)行特定的任務。
Talk is cheap. Show me the code!我們聯(lián)想下生活中是如何購物的?瀏覽商品 → 加購 → 結算 。轉(zhuǎn)換成對應的偽代碼,應該是這樣的:
這很符合我們平時的代碼風格,但也確實是一種面向過程的標準寫法。感到一絲詫異和矛盾,難道我們平時都在用面向?qū)ο笳Z言來寫面向過程的代碼?事實確實如此。我們平時的方法封裝調(diào)用很大一部分就是面向過程的設計。
這里并非是說 面向過程 的寫法不正確,反而在某些場景下面向過程更加直觀。但面向?qū)ο蟮脑O計為何而來?
哪怕我們平時大部分做的都是 CRUD 的工作,重復性的代碼也會構建出一個龐大的系統(tǒng)。構成一個系統(tǒng)的因素太多,要把所有問題的因素都考慮到,再把所有因素的因果關系都分析清楚,接著把整個過程都用代碼表述出來未免太過于困難,這不僅對創(chuàng)作者來說是一個災難,對后繼者來說更是:talk is cheap, code is shit !
我們轉(zhuǎn)換下思維,如何利用面向?qū)ο蟮奶匦栽O計以上代碼?利用面向?qū)ο蟮姆椒ㄕ摚f物皆對象。
那么由此可以設計出 商品、購物車 以及 付款 的對象
通過利用這種方式,不論在哪一個層次上,我們都只需要面對有限的復雜度和有限的對象結構,從而可以專心地了解這個層次上的對象是如何工作的。比如在付款的結構上,我們可以只專注付款的擴展,從而可以延伸出 微信付款、支付寶付款、銀聯(lián)付款 等眾多方式。
How
作為開發(fā),我們工作的本質(zhì)就是把一個產(chǎn)品需求轉(zhuǎn)化成一個可以運行的系統(tǒng),中間可能會涉及產(chǎn)品設計、需求建模、架構設計、實現(xiàn)設計、代碼編寫等眾多步驟。
在調(diào)研需求時常常會陷入面向過程的誤區(qū),我們會最先弄清楚有多少業(yè)務流程,接著畫出業(yè)務流程圖,然后順藤摸瓜,找出業(yè)務流程中每個關鍵步驟,弄清楚上下文是如何傳遞的。
事實上,架構設計、實現(xiàn)設計、代碼編寫都是屬于軟件開發(fā)的階段。在設計之前,我們?nèi)绻幸粋€清晰的目標,那后面的行動無疑會變得順利很多。我們面對著成百上千的需求,每個需求可能都存在錯綜復雜的關系,復雜度并非是線性增長的。需求復雜度是否相等于技術復雜度?
 image.png
image.png
面向?qū)ο缶幊桃馕吨帉戓槍?strong style="color:rgb(224,52,93);">建模對象的代碼。這是用于描述復雜系統(tǒng)動作的眾多技術之一。它是通過描述交互對象的數(shù)據(jù)和行為來定義。 那么在編程之間我們就需要進行很關鍵的一步:建模。
ChatGPT:建模是指對客觀事物建立一種抽象的方法用以表征事物并獲得對事物本身的理解,同時把這種理解懷念化,并將這些邏輯概念組織起來,構成一種對所觀察對象內(nèi)部結構和工作原理便于理解的表達。
公式:靜態(tài)的事物(物)+特定的條件(規(guī)則)+特定的動作(參與者的驅(qū)動)=特定的場景(事件)
當我們嘗試為需求背后的場景建模時,首先要決定便是抽象的角度,這一步尤其重要也尤其不易。一旦抽象角度確定,后面的設計就變得順理成章,而不是雜亂無章。
這一步也是與 面向過程 的主要區(qū)別所在:
- 面向過程:希望能夠通盤考慮,把所有問題的因素都考慮到,再將這些因果關系理清,這就會將結構變得很復雜。(把事情復雜化)
- 面向?qū)ο螅合M軌虬褟碗s的事物通過合理的抽象角度分解成小塊,每個小塊之間單獨思考,最后再基于特定的場景將塊與塊之間串聯(lián)。(把事情簡單化)因此面向?qū)ο蟮年P鍵就在于剛開始面對問題領域的時候不要決定去全盤考慮,而是找出問題領域里包含的抽象角度,只要抽象角度找對找全,那么通盤的問題也就層層解決。當然,在抽象的過程中,每個角度之間可能是互不關聯(lián)的。
做需求的時候,首要目標不是要弄清楚業(yè)務是如何一步一步完成的,而是要弄清楚有多少業(yè)務的參與者,以及每個參與者的目標是什么。而這其中參與者的目標便是你需要抽象的角度
抽象角度
抽象的層次越高,具體信息越少,對應的概括能力越強。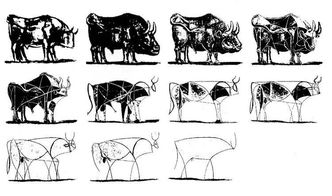 抽象有兩種方式:
抽象有兩種方式:
- 自頂向下: 自頂向下的方法適用于讓人們從頭開始認識一個事物。先宏觀后微觀
- 自底向上:自底向上的方法適用于在實踐中改進和提高認識。先微觀后宏觀
映射到我們的軟件開發(fā)過程中,我們往往會采用自頂向下的方式,先搭建一個框架,用少量粗粒度的概念來覆蓋系統(tǒng)的需求,再逐步細化,降低抽象的層次。同時在細化的過程中,我們也能夠通過細節(jié)間的相同之處,來改進較高層次的抽象范圍。因此這兩種方式應當是相輔相成,而不是兩者擇一的關系。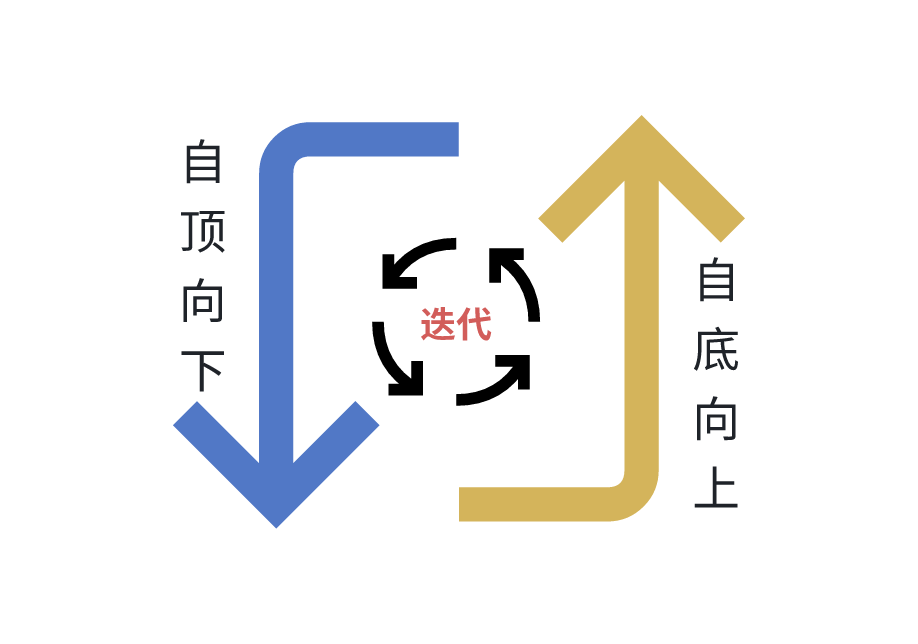
根據(jù)抽象而成的對象理應具備以下特征:
- 對象都具有原子性無論在什么時候,在同一抽象層次上,在分析過程中都應當將對象視為一個不可分割的原子,哪怕這個對象的規(guī)模很大。
- 對象都是可抽象的對象所具有的方面,或者說對象所參與的場景越多,對象越有抽象價值,反之則越?jīng)]有抽象價值
- 對象都有層次性對象是有著抽象層次的。層次越高,其描述越粗略但適應能力越廣;層次越低則描述越精確但適應能力越下降
參與者
參與者的角色在建模過程中是處于核心地位的。他們是處于系統(tǒng)范圍之外,居于業(yè)務范圍之內(nèi)與系統(tǒng)進行交互的。 參與者和系統(tǒng)之間有一個明確的邊界,參與者只可能存在于邊界之外,邊界之內(nèi)(系統(tǒng)之內(nèi))的所有人或事都不是參與者。如果參與者涉及到了系統(tǒng)邊界之內(nèi),那么此時參與者的角色就是可疑的,需要重新定義。因此在業(yè)務設計階段,一定要堅守好這道邊界,參與者過早侵入系統(tǒng)就可能會對系統(tǒng)造成損害。
參與者和系統(tǒng)之間有一個明確的邊界,參與者只可能存在于邊界之外,邊界之內(nèi)(系統(tǒng)之內(nèi))的所有人或事都不是參與者。如果參與者涉及到了系統(tǒng)邊界之內(nèi),那么此時參與者的角色就是可疑的,需要重新定義。因此在業(yè)務設計階段,一定要堅守好這道邊界,參與者過早侵入系統(tǒng)就可能會對系統(tǒng)造成損害。
什么是參與者?簡單定義如下:
- 誰將使用此功能
- 誰對某個特定功能感興趣
- 誰負責支持和維護系統(tǒng)參與者一定是直接并且主動地向系統(tǒng)發(fā)出動作并獲得反饋的,否則就不是參與者
在實際業(yè)務分析階段,我們需要區(qū)分 業(yè)務范圍 和 系統(tǒng)范圍
- 業(yè)務范圍:是指項目所涉及的全部客戶業(yè)務領域,不論是否涉及開發(fā)系統(tǒng)的參與,這些業(yè)務都是客觀存在的
- 系統(tǒng)范圍:是指軟件系統(tǒng)將要實現(xiàn)的那一部分功能,這些功能是從業(yè)務范圍中提取,是業(yè)務范圍的一個子集
如果在業(yè)務分析階段就預設了計算機系統(tǒng)的存在,那么將會混淆現(xiàn)有業(yè)務和將來實際開發(fā)的業(yè)務,將用戶代入到計算機系統(tǒng)中,可能會造成現(xiàn)有業(yè)務屬性的削弱,而忽略了實際業(yè)務背后的含義。
當然,這也是開發(fā)人員對接業(yè)務需求的一大誤區(qū)之一。喜歡從計算機系統(tǒng)的角度來思考問題,在向客戶收集需求的時候總是在第一時間想到計算機將如何實現(xiàn)它,常常津津樂道于跟客戶討論背后的系統(tǒng)將如何實現(xiàn)客戶的需求,并且指望客戶能夠用這種方式來確認需求。帶來的危害:
- 客戶不能理解將來的落地實現(xiàn)是什么樣子的,但是出于信任開發(fā)人員,就會將信將疑地做出肯定
- 開發(fā)人員在一開始就加入了自己的主觀判斷,假設了業(yè)務在計算機系統(tǒng)里的實現(xiàn)方式,而沒有真正地去理解客戶的實際業(yè)務
用例
用例是一種描述系統(tǒng)如何與外部用戶或其他系統(tǒng)進行交互的技術工具。它描述了系統(tǒng)的功能和行為,并以用戶的角度來描述系統(tǒng)的需求和使用場景。簡言之:用例是用來捕捉功能性需求
在軟件開發(fā)階段,我們會以用例作為最小指導單元進行設計,標準的用例應當具備以下特征:
- 用例是相對獨立的
- 用例的執(zhí)行結果對參與者來說是可觀測的和有意義的用例的粒度大小不是從用例包含的步驟的多少來判斷的,而是每一個用例能盡量能夠說明一件完整的事情
用例的獲取并非來源于開發(fā)人員,換言之,開發(fā)人員是用例的翻譯者。用例的定義是參與者驅(qū)動的,這也對應了用例的特征之一:用例的執(zhí)行結果對參與者來說是可觀測的和有意義的。因此用例的來源就是參與者對系統(tǒng)的期望。所以發(fā)現(xiàn)用例的前提條件就是發(fā)現(xiàn)參與者,確定參與者的同時就確定了系統(tǒng)邊界。
Code without understanding the business is like playing the rogue結合業(yè)務,與參與者聊需求的時候經(jīng)常感覺需求飄渺不定,每個點都感覺是需求的核心部分。那么是否有認真想過:參與者想做和要做的事情不一定是他真實的目標,也許只是他做事情的一個步驟
- 一個明確有效的目標才是一個用例的來源
- 一個真實的目標應當完備地表達參與者的期望
- 一個有效的目標應當在系統(tǒng)邊界內(nèi),由參與者發(fā)動,并具有明確的后果
在軟件開發(fā)需要耗時最久是哪個階段?應該是需求分析和設計階段。為了縮短開發(fā)周期,很容易想到便是縮減需求分析和設計階段的時間,當你真的這么做了,你可能就會離真正的用例愈偏愈遠!要平衡時間和質(zhì)量,就需要充分理解用戶需求,當訪談不順利的時候應當重新調(diào)整策略,調(diào)整系統(tǒng)邊界的規(guī)模或者更換訪談的參與者都是不錯的選擇。
用例不是功能點在大多數(shù)開發(fā)者看來 用例是一個功能點。然而實際情況并非如此。功能的生命周期:輸入->計算->輸出,功能是脫離使用者的愿望而存在的,本身是孤立的。
類似一個判斷用戶是否有操作權限的方法,這個方法本身是脫離業(yè)務的,它的用例場景可能是用戶在提交某個模塊下的變更記錄,才需要校驗權限,而校驗權限只是其中的一個功能。
在實際情況下,更應當從使用者的觀點去描述,一個用例是一個參與者如何使用系統(tǒng),獲得什么結果的一個集合,那么此時用例可以解釋為一系列完成一個特定目標的功能的組合,針對不同的應用場景,這些功能可以以不同的組合方式構建出新的用例。
步驟不是目標一個用例是參與者對目標的一個期望。在完成這個目標之前需要經(jīng)由很多步驟,但每個步驟并不能完整地反映出參與者的目標,因此作為一個用例是有所缺陷的。錯誤地使用步驟作為用例,將無法準確地描述參與者如何使用系統(tǒng),整體系統(tǒng)的操作流程以及交互細節(jié)會發(fā)生偏差,脫離預期。
目標和步驟很容易造成混淆,在弄清楚目標與步驟之前,我們就需要設置一些實際場景來解釋,通過場景中涉及到的問題來測試出什么才是參與者真正的目的。
可能在此之前參與者也不清楚自己想要的到底是什么!
至此,回想《領域驅(qū)動設計-軟件核心復雜性應對之道》自問世以來,帶來了一個全新的思想:領域驅(qū)動設計。重點傳述的也是通過領域設計來分離業(yè)務復雜度和技術復雜度。復雜度也許永遠不能消除,但我們可以分析復雜度,進而管理復雜度。書中有提到:
每個軟件程序是為了執(zhí)行用戶的某項活動,或是滿足用戶的某種需求。這些用戶應用軟件的問題區(qū)域就是軟件的領域。
回過頭來看上述所講到的面向?qū)ο螅环τ邢嗤帯D撤N程度上,把“領域驅(qū)動設計”改為“模型驅(qū)動設計”也相當貼切。
回收開頭的問題,我認為:需求復雜度 != 技術復雜度,建模理應成為我們管理復雜度的工具!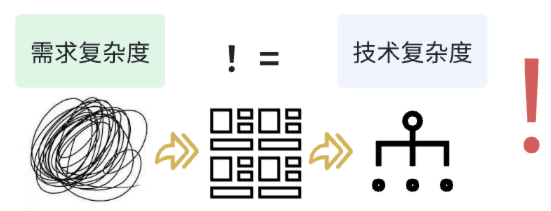
本篇文章的思維路線:
最后以 ChatGPT 來個結尾 面向?qū)ο缶幊淘谂c業(yè)務需求結合時展現(xiàn)出不凡的優(yōu)勢,通過將業(yè)務需求映射為對象和類的組織結構,我們能夠更好地理解和管理復雜的業(yè)務邏輯。
通過面向?qū)ο蟮姆椒ǎ覀兡軌驅(qū)I(yè)務需求轉(zhuǎn)化為具體的對象和類,從而更好地理解和模擬真實世界中的業(yè)務流程和實體。通過封裝數(shù)據(jù)和行為,我們能夠?qū)碗s的業(yè)務邏輯劃分為獨立的對象,每個對象負責特定的功能和責任。這種模塊化的設計使得我們能夠更好地理解和管理業(yè)務需求,同時也為將來的擴展和修改提供了便利。
瀏覽
45
What
面向?qū)ο?/span>
作為一名程序員,代碼編程我們平時伸手就來。日常用到比較多的語言也許是 Java、TypeScript、C++ 等,大家都很清楚,這些都是面向?qū)ο蟮恼Z言。那么問題也隨之而來,是我們需要使用面向?qū)ο蟮奶匦圆胚x擇了這些語言開發(fā),還是人云亦云地選擇了這些語言開發(fā)?
在面向?qū)ο蟮睦砟钪校f物皆對象。面向?qū)ο蟮木柙谟诔橄螅嫦驅(qū)ο蟮睦щy也在于抽象。簡單來說:面向?qū)ο蟮某晒υ谟诔晒Φ某橄螅嫦驅(qū)ο蟮氖≡谟谑〉某橄蟆?/p>
對象與對象之間都是孤立的,好比現(xiàn)實生活的你和我之間。只有在特定的場景下,孤立對象之間進行了某些信息交互才表示出一個場景過程,好比基于這邊文章,你和我之間才建立起了作者和讀者的關系。
面向過程
既然說到面向?qū)ο螅瓦€應該了解到另外一個選項:面向過程。面向過程認為我們的世界是由一個個相互關聯(lián)的消息同組成的,這是一種類似 螺旋式 的結構,每個小系統(tǒng)都有明確的開始和明確的結束,開始和結束之間有著嚴謹?shù)囊蚬P系。在面向過程的設計方法中強調(diào)將問題分解成小的、可重用的模塊,每個模塊負責執(zhí)行特定的任務。
Talk is cheap. Show me the code!我們聯(lián)想下生活中是如何購物的?瀏覽商品 → 加購 → 結算 。轉(zhuǎn)換成對應的偽代碼,應該是這樣的:
這很符合我們平時的代碼風格,但也確實是一種面向過程的標準寫法。感到一絲詫異和矛盾,難道我們平時都在用面向?qū)ο笳Z言來寫面向過程的代碼?事實確實如此。我們平時的方法封裝調(diào)用很大一部分就是面向過程的設計。
這里并非是說 面向過程 的寫法不正確,反而在某些場景下面向過程更加直觀。但面向?qū)ο蟮脑O計為何而來?
哪怕我們平時大部分做的都是 CRUD 的工作,重復性的代碼也會構建出一個龐大的系統(tǒng)。構成一個系統(tǒng)的因素太多,要把所有問題的因素都考慮到,再把所有因素的因果關系都分析清楚,接著把整個過程都用代碼表述出來未免太過于困難,這不僅對創(chuàng)作者來說是一個災難,對后繼者來說更是:talk is cheap, code is shit !
我們轉(zhuǎn)換下思維,如何利用面向?qū)ο蟮奶匦栽O計以上代碼?利用面向?qū)ο蟮姆椒ㄕ摚f物皆對象。
那么由此可以設計出 商品、購物車 以及 付款 的對象
通過利用這種方式,不論在哪一個層次上,我們都只需要面對有限的復雜度和有限的對象結構,從而可以專心地了解這個層次上的對象是如何工作的。比如在付款的結構上,我們可以只專注付款的擴展,從而可以延伸出 微信付款、支付寶付款、銀聯(lián)付款 等眾多方式。
How
作為開發(fā),我們工作的本質(zhì)就是把一個產(chǎn)品需求轉(zhuǎn)化成一個可以運行的系統(tǒng),中間可能會涉及產(chǎn)品設計、需求建模、架構設計、實現(xiàn)設計、代碼編寫等眾多步驟。
在調(diào)研需求時常常會陷入面向過程的誤區(qū),我們會最先弄清楚有多少業(yè)務流程,接著畫出業(yè)務流程圖,然后順藤摸瓜,找出業(yè)務流程中每個關鍵步驟,弄清楚上下文是如何傳遞的。
事實上,架構設計、實現(xiàn)設計、代碼編寫都是屬于軟件開發(fā)的階段。在設計之前,我們?nèi)绻幸粋€清晰的目標,那后面的行動無疑會變得順利很多。我們面對著成百上千的需求,每個需求可能都存在錯綜復雜的關系,復雜度并非是線性增長的。需求復雜度是否相等于技術復雜度?
image.png
面向?qū)ο缶幊桃馕吨帉戓槍?strong style="color:rgb(224,52,93);">建模對象的代碼。這是用于描述復雜系統(tǒng)動作的眾多技術之一。它是通過描述交互對象的數(shù)據(jù)和行為來定義。 那么在編程之間我們就需要進行很關鍵的一步:建模。
ChatGPT:建模是指對客觀事物建立一種抽象的方法用以表征事物并獲得對事物本身的理解,同時把這種理解懷念化,并將這些邏輯概念組織起來,構成一種對所觀察對象內(nèi)部結構和工作原理便于理解的表達。
公式:靜態(tài)的事物(物)+特定的條件(規(guī)則)+特定的動作(參與者的驅(qū)動)=特定的場景(事件)
當我們嘗試為需求背后的場景建模時,首先要決定便是抽象的角度,這一步尤其重要也尤其不易。一旦抽象角度確定,后面的設計就變得順理成章,而不是雜亂無章。
這一步也是與 面向過程 的主要區(qū)別所在:
- 面向過程:希望能夠通盤考慮,把所有問題的因素都考慮到,再將這些因果關系理清,這就會將結構變得很復雜。(把事情復雜化)
- 面向?qū)ο螅合M軌虬褟碗s的事物通過合理的抽象角度分解成小塊,每個小塊之間單獨思考,最后再基于特定的場景將塊與塊之間串聯(lián)。(把事情簡單化)因此面向?qū)ο蟮年P鍵就在于剛開始面對問題領域的時候不要決定去全盤考慮,而是找出問題領域里包含的抽象角度,只要抽象角度找對找全,那么通盤的問題也就層層解決。當然,在抽象的過程中,每個角度之間可能是互不關聯(lián)的。
做需求的時候,首要目標不是要弄清楚業(yè)務是如何一步一步完成的,而是要弄清楚有多少業(yè)務的參與者,以及每個參與者的目標是什么。而這其中參與者的目標便是你需要抽象的角度
抽象角度
抽象的層次越高,具體信息越少,對應的概括能力越強。抽象有兩種方式:
- 自頂向下: 自頂向下的方法適用于讓人們從頭開始認識一個事物。先宏觀后微觀
- 自底向上:自底向上的方法適用于在實踐中改進和提高認識。先微觀后宏觀
映射到我們的軟件開發(fā)過程中,我們往往會采用自頂向下的方式,先搭建一個框架,用少量粗粒度的概念來覆蓋系統(tǒng)的需求,再逐步細化,降低抽象的層次。同時在細化的過程中,我們也能夠通過細節(jié)間的相同之處,來改進較高層次的抽象范圍。因此這兩種方式應當是相輔相成,而不是兩者擇一的關系。
根據(jù)抽象而成的對象理應具備以下特征:
- 對象都具有原子性無論在什么時候,在同一抽象層次上,在分析過程中都應當將對象視為一個不可分割的原子,哪怕這個對象的規(guī)模很大。
- 對象都是可抽象的對象所具有的方面,或者說對象所參與的場景越多,對象越有抽象價值,反之則越?jīng)]有抽象價值
- 對象都有層次性對象是有著抽象層次的。層次越高,其描述越粗略但適應能力越廣;層次越低則描述越精確但適應能力越下降
參與者
參與者的角色在建模過程中是處于核心地位的。他們是處于系統(tǒng)范圍之外,居于業(yè)務范圍之內(nèi)與系統(tǒng)進行交互的。參與者和系統(tǒng)之間有一個明確的邊界,參與者只可能存在于邊界之外,邊界之內(nèi)(系統(tǒng)之內(nèi))的所有人或事都不是參與者。如果參與者涉及到了系統(tǒng)邊界之內(nèi),那么此時參與者的角色就是可疑的,需要重新定義。因此在業(yè)務設計階段,一定要堅守好這道邊界,參與者過早侵入系統(tǒng)就可能會對系統(tǒng)造成損害。
什么是參與者?簡單定義如下:
- 誰將使用此功能
- 誰對某個特定功能感興趣
- 誰負責支持和維護系統(tǒng)參與者一定是直接并且主動地向系統(tǒng)發(fā)出動作并獲得反饋的,否則就不是參與者
在實際業(yè)務分析階段,我們需要區(qū)分 業(yè)務范圍 和 系統(tǒng)范圍
- 業(yè)務范圍:是指項目所涉及的全部客戶業(yè)務領域,不論是否涉及開發(fā)系統(tǒng)的參與,這些業(yè)務都是客觀存在的
- 系統(tǒng)范圍:是指軟件系統(tǒng)將要實現(xiàn)的那一部分功能,這些功能是從業(yè)務范圍中提取,是業(yè)務范圍的一個子集
如果在業(yè)務分析階段就預設了計算機系統(tǒng)的存在,那么將會混淆現(xiàn)有業(yè)務和將來實際開發(fā)的業(yè)務,將用戶代入到計算機系統(tǒng)中,可能會造成現(xiàn)有業(yè)務屬性的削弱,而忽略了實際業(yè)務背后的含義。
當然,這也是開發(fā)人員對接業(yè)務需求的一大誤區(qū)之一。喜歡從計算機系統(tǒng)的角度來思考問題,在向客戶收集需求的時候總是在第一時間想到計算機將如何實現(xiàn)它,常常津津樂道于跟客戶討論背后的系統(tǒng)將如何實現(xiàn)客戶的需求,并且指望客戶能夠用這種方式來確認需求。帶來的危害:
- 客戶不能理解將來的落地實現(xiàn)是什么樣子的,但是出于信任開發(fā)人員,就會將信將疑地做出肯定
- 開發(fā)人員在一開始就加入了自己的主觀判斷,假設了業(yè)務在計算機系統(tǒng)里的實現(xiàn)方式,而沒有真正地去理解客戶的實際業(yè)務
用例
用例是一種描述系統(tǒng)如何與外部用戶或其他系統(tǒng)進行交互的技術工具。它描述了系統(tǒng)的功能和行為,并以用戶的角度來描述系統(tǒng)的需求和使用場景。簡言之:用例是用來捕捉功能性需求
在軟件開發(fā)階段,我們會以用例作為最小指導單元進行設計,標準的用例應當具備以下特征:
- 用例是相對獨立的
- 用例的執(zhí)行結果對參與者來說是可觀測的和有意義的用例的粒度大小不是從用例包含的步驟的多少來判斷的,而是每一個用例能盡量能夠說明一件完整的事情
用例的獲取并非來源于開發(fā)人員,換言之,開發(fā)人員是用例的翻譯者。用例的定義是參與者驅(qū)動的,這也對應了用例的特征之一:用例的執(zhí)行結果對參與者來說是可觀測的和有意義的。因此用例的來源就是參與者對系統(tǒng)的期望。所以發(fā)現(xiàn)用例的前提條件就是發(fā)現(xiàn)參與者,確定參與者的同時就確定了系統(tǒng)邊界。
Code without understanding the business is like playing the rogue結合業(yè)務,與參與者聊需求的時候經(jīng)常感覺需求飄渺不定,每個點都感覺是需求的核心部分。那么是否有認真想過:參與者想做和要做的事情不一定是他真實的目標,也許只是他做事情的一個步驟
- 一個明確有效的目標才是一個用例的來源
- 一個真實的目標應當完備地表達參與者的期望
- 一個有效的目標應當在系統(tǒng)邊界內(nèi),由參與者發(fā)動,并具有明確的后果
在軟件開發(fā)需要耗時最久是哪個階段?應該是需求分析和設計階段。為了縮短開發(fā)周期,很容易想到便是縮減需求分析和設計階段的時間,當你真的這么做了,你可能就會離真正的用例愈偏愈遠!要平衡時間和質(zhì)量,就需要充分理解用戶需求,當訪談不順利的時候應當重新調(diào)整策略,調(diào)整系統(tǒng)邊界的規(guī)模或者更換訪談的參與者都是不錯的選擇。
用例不是功能點在大多數(shù)開發(fā)者看來 用例是一個功能點。然而實際情況并非如此。功能的生命周期:輸入->計算->輸出,功能是脫離使用者的愿望而存在的,本身是孤立的。
類似一個判斷用戶是否有操作權限的方法,這個方法本身是脫離業(yè)務的,它的用例場景可能是用戶在提交某個模塊下的變更記錄,才需要校驗權限,而校驗權限只是其中的一個功能。
在實際情況下,更應當從使用者的觀點去描述,一個用例是一個參與者如何使用系統(tǒng),獲得什么結果的一個集合,那么此時用例可以解釋為一系列完成一個特定目標的功能的組合,針對不同的應用場景,這些功能可以以不同的組合方式構建出新的用例。
步驟不是目標一個用例是參與者對目標的一個期望。在完成這個目標之前需要經(jīng)由很多步驟,但每個步驟并不能完整地反映出參與者的目標,因此作為一個用例是有所缺陷的。錯誤地使用步驟作為用例,將無法準確地描述參與者如何使用系統(tǒng),整體系統(tǒng)的操作流程以及交互細節(jié)會發(fā)生偏差,脫離預期。
目標和步驟很容易造成混淆,在弄清楚目標與步驟之前,我們就需要設置一些實際場景來解釋,通過場景中涉及到的問題來測試出什么才是參與者真正的目的。
可能在此之前參與者也不清楚自己想要的到底是什么!
至此,回想《領域驅(qū)動設計-軟件核心復雜性應對之道》自問世以來,帶來了一個全新的思想:領域驅(qū)動設計。重點傳述的也是通過領域設計來分離業(yè)務復雜度和技術復雜度。復雜度也許永遠不能消除,但我們可以分析復雜度,進而管理復雜度。書中有提到:
每個軟件程序是為了執(zhí)行用戶的某項活動,或是滿足用戶的某種需求。這些用戶應用軟件的問題區(qū)域就是軟件的領域。
回過頭來看上述所講到的面向?qū)ο螅环τ邢嗤帯D撤N程度上,把“領域驅(qū)動設計”改為“模型驅(qū)動設計”也相當貼切。
回收開頭的問題,我認為:需求復雜度 != 技術復雜度,建模理應成為我們管理復雜度的工具!
本篇文章的思維路線:
最后以 ChatGPT 來個結尾 面向?qū)ο缶幊淘谂c業(yè)務需求結合時展現(xiàn)出不凡的優(yōu)勢,通過將業(yè)務需求映射為對象和類的組織結構,我們能夠更好地理解和管理復雜的業(yè)務邏輯。
通過面向?qū)ο蟮姆椒ǎ覀兡軌驅(qū)I(yè)務需求轉(zhuǎn)化為具體的對象和類,從而更好地理解和模擬真實世界中的業(yè)務流程和實體。通過封裝數(shù)據(jù)和行為,我們能夠?qū)碗s的業(yè)務邏輯劃分為獨立的對象,每個對象負責特定的功能和責任。這種模塊化的設計使得我們能夠更好地理解和管理業(yè)務需求,同時也為將來的擴展和修改提供了便利。
<b id="afajh"><abbr id="afajh"></abbr></b>