
使用Scrapy網(wǎng)絡(luò)爬蟲框架小試牛刀
回復(fù)“書籍”即可獲贈Python從入門到進(jìn)階共10本電子書
前言
這次咱們來玩一個在Python中很牛叉的爬蟲框架——Scrapy。
scrapy 介紹
標(biāo)準(zhǔn)介紹
Scrapy是一個為了爬取網(wǎng)站數(shù)據(jù),提取結(jié)構(gòu)性數(shù)據(jù)而編寫的應(yīng)用框架,非常出名,非常強(qiáng)悍。所謂的框架就是一個已經(jīng)被集成了各種功能(高性能異步下載,隊(duì)列,分布式,解析,持久化等)的具有很強(qiáng)通用性的項(xiàng)目模板。對于框架的學(xué)習(xí),重點(diǎn)是要學(xué)習(xí)其框架的特性、各個功能的用法即可。
說人話就是
只要是搞爬蟲的,用這個就van事了,因?yàn)槔锩婕闪艘恍┖馨舻墓ぞ?并且爬取性能很高,預(yù)留有很多鉤子方便擴(kuò)展,實(shí)在是居家爬蟲的不二之選。
windows下安裝scrapy
命令
pip install scrapy默認(rèn)情況下,直接pip install scrapy可能會失敗,如果沒有換源,加上臨時源安裝試試,這里使用的是清華源,常見安裝問題可以參考這個文章:Windows下安裝Scrapy方法及常見安裝問題總結(jié)——Scrapy安裝教程。
命令
pip install scrapy -i https://pypi.tuna.tsinghua.edu.cn/simplescrapy創(chuàng)建爬蟲項(xiàng)目
命令
scrapy startproject <項(xiàng)目名稱>示例:創(chuàng)建一個糗事百科的爬蟲項(xiàng)目(記得cd到一個干凈的目錄哈)
scrapy startproject qiushibaike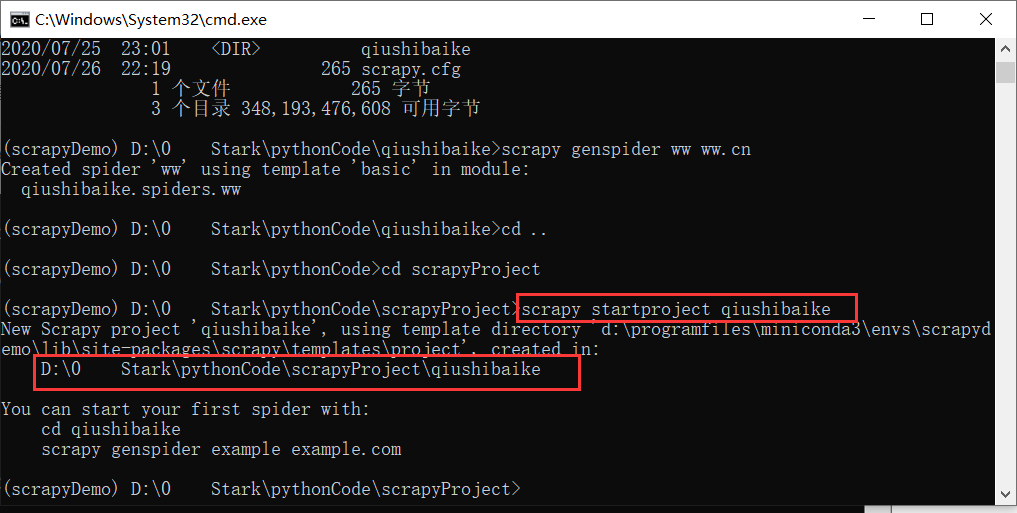
注:此時,我們已經(jīng)創(chuàng)建好了一個爬蟲項(xiàng)目,但是爬蟲項(xiàng)目是一個文件夾
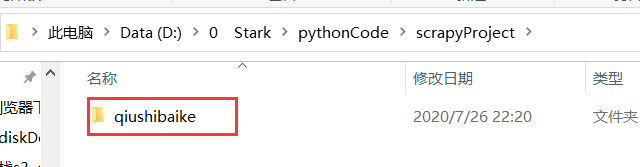
進(jìn)入爬蟲項(xiàng)目
如果想要進(jìn)入這個項(xiàng)目,就要cd進(jìn)這個目錄,如上上圖所示,先cd <項(xiàng)目>,再創(chuàng)建蜘蛛

項(xiàng)目目錄結(jié)構(gòu)解析
此時,我們就已經(jīng)進(jìn)入了項(xiàng)目,結(jié)構(gòu)如下,有一個和項(xiàng)目名同名的文件夾和一個scrapy.cfg文件
scrapy.cfg # scrapy配置,特殊情況使用此配置qiushibaike # 項(xiàng)目名同名的文件夾items.py # 數(shù)據(jù)存儲模板,定制要保存的字段middlewares.py # 爬蟲中間件pipelines.py # 編寫數(shù)據(jù)持久化代碼settings.py # 配置文件,例如:控制爬取速度,多大并發(fā)量,等__init__.pyspiders # 爬蟲目錄,一個個爬蟲文件,編寫數(shù)據(jù)解析代碼__init__.py
呃,可能此時你并不能懂這么些目錄什么意思,不過不要慌,使用一下可能就懂了,別慌。
創(chuàng)建蜘蛛
通過上述的操作,假設(shè)你已經(jīng)成功的安裝好了scrapy,并且進(jìn)入了創(chuàng)建的項(xiàng)目
那么,我們就創(chuàng)建一個蜘蛛,對糗事百科的段子進(jìn)行爬取。
創(chuàng)建蜘蛛命令
scrapy genspider <蜘蛛名稱> <網(wǎng)頁的起始url>示例:創(chuàng)建糗事百科的段子蜘蛛
scrapy genspider duanzi ww.com
注:網(wǎng)頁的起始url可以隨便寫,可以隨便改,但是必須有
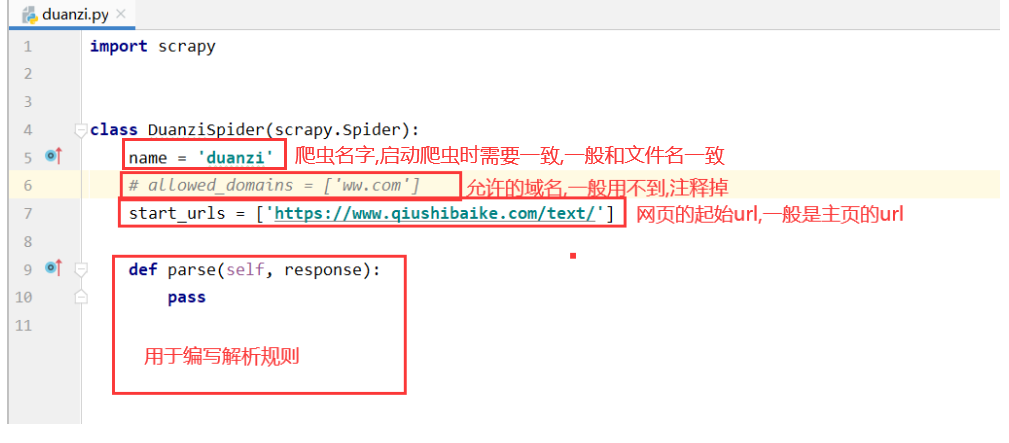
此時在spider文件夾下,會多一個duanzi.py文件
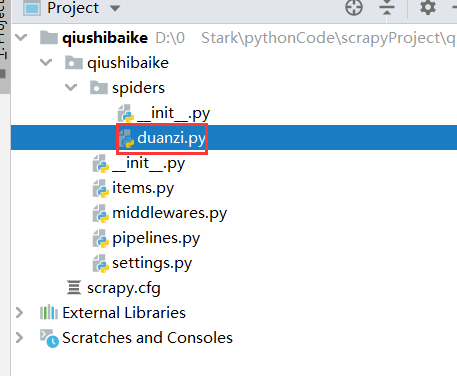
代碼解釋如下
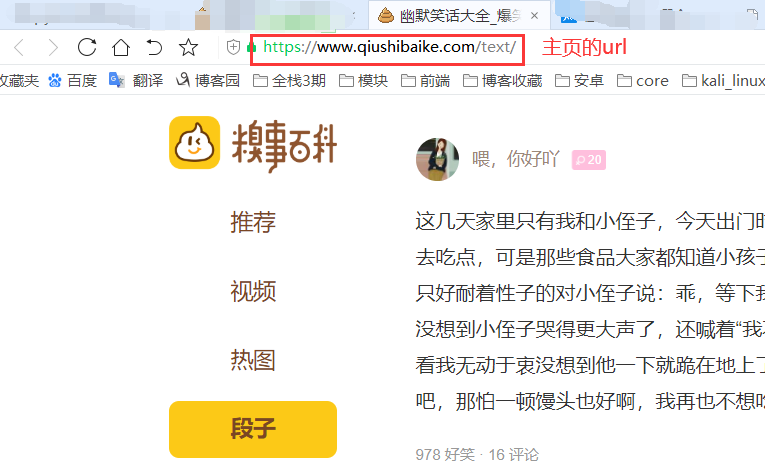
爬取數(shù)據(jù)前準(zhǔn)備
創(chuàng)建好蜘蛛之后,需要在配置一些東西的,不能直接就爬的,默認(rèn)是爬取不了的,需要簡單配置一下
打開settings.py文件,找到ROBOTSTXT_OBEY和USER_AGENT變量
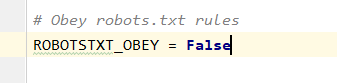
ROBOTSTXT_OBEY配置
等于False不遵守robot協(xié)議,默認(rèn)只有搜索引擎網(wǎng)站才會允許爬取,例如百度,必應(yīng)等,個人爬取需要忽略這個,否則爬取不了
USER_AGENT配置
User-Agent是一個最基本的請求必須帶的參數(shù),如果這個帶的不是正常的,必定爬取不了。
User-Agent
Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36
小試牛刀之獲取糗事百科段子段子鏈接
準(zhǔn)備工作做好了,那就開始吧!!!
此處我們需要有xpath的語法基礎(chǔ),其實(shí)挺簡單的,沒有基礎(chǔ)的記得百度一下,其實(shí)不百度也沒關(guān)系,跟著學(xué),大概能看懂
實(shí)現(xiàn)功能
通過xpath獲取每個段子下的a標(biāo)簽連接
注:審查元素和按住crtl+f搜索內(nèi)容和寫xpath這里不再啰嗦
分析頁面規(guī)則
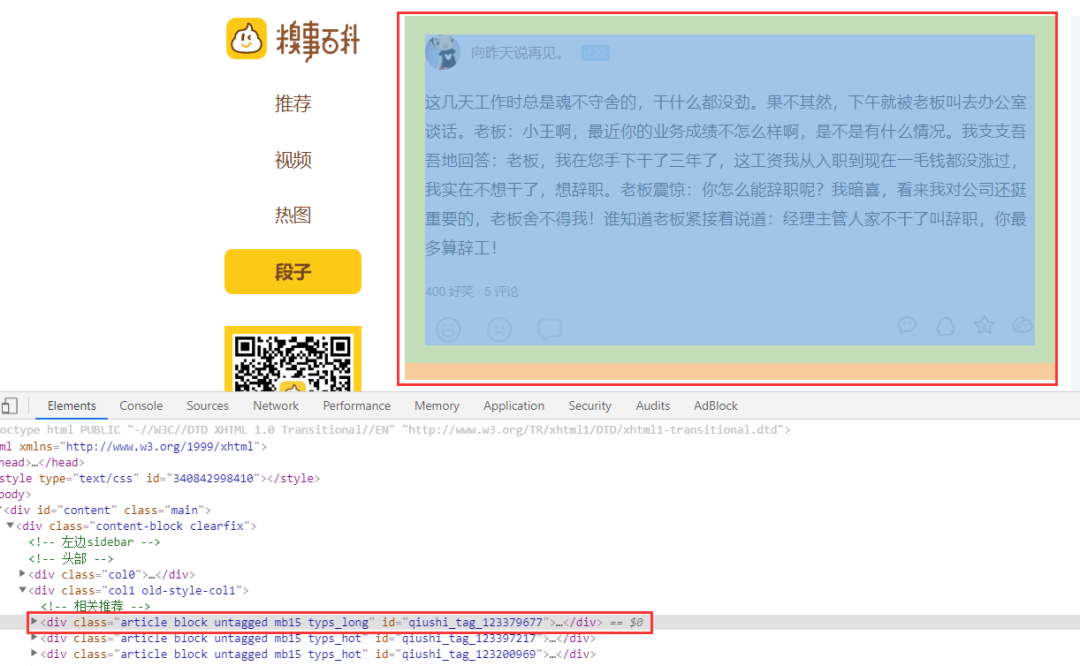
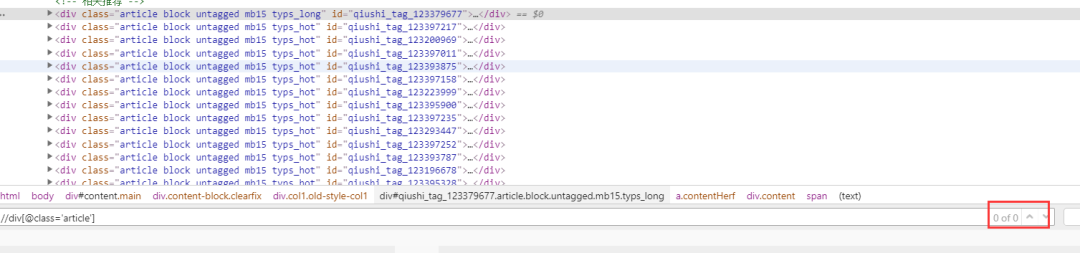
通過審查工具,我們可以看到,class包含article的標(biāo)簽就是一個個的文章,可能你想到xpath可能可以這樣寫
xpath代碼
//div[@class='article']但是你會發(fā)現(xiàn)一個都查不出來,因?yàn)槭前年P(guān)系,所以需要用contains關(guān)鍵字
我們需要這樣寫
xpath代碼
//div[contains(@class,"article")]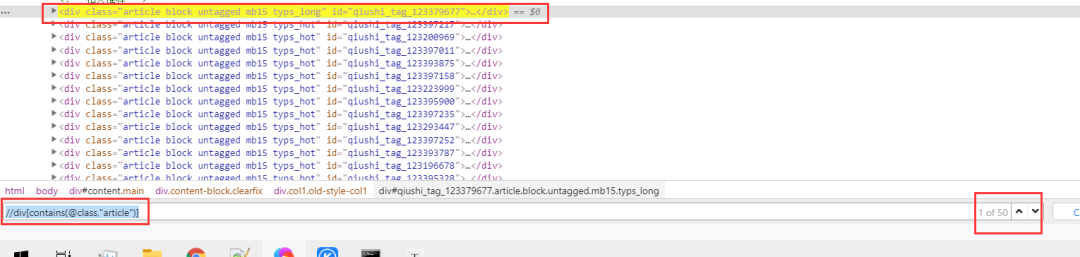
但是會發(fā)現(xiàn),這定位的太多了,并不是每個段子的div,所以我們要多包含幾個,這樣,就是每個段子的div了
//div[contains(@class,"article") and contains(@class,"block")]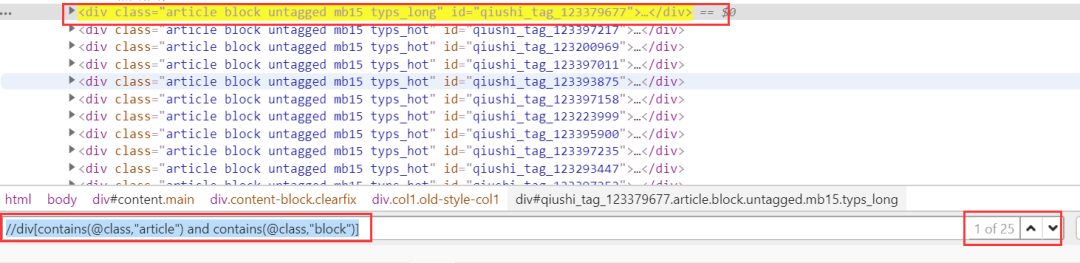
上述已經(jīng)成功定位了一個個的段子,下面在此基礎(chǔ)上,定位到每個段子下的a標(biāo)簽
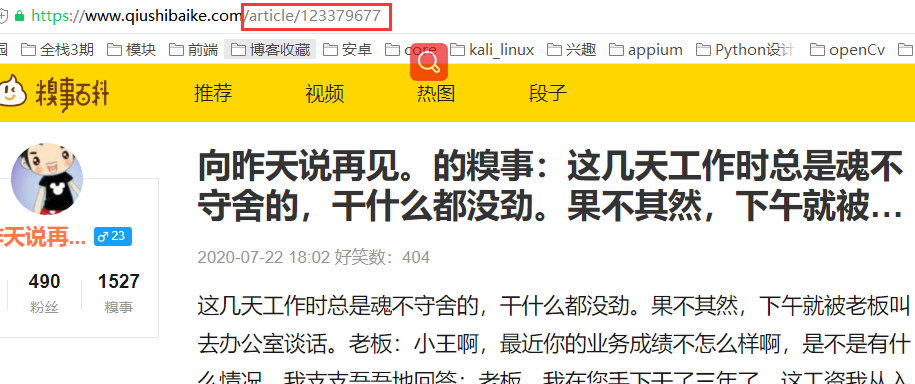
根據(jù)審查元素,發(fā)現(xiàn)每個段子下class="contentHerf"的a標(biāo)簽,就是每個段子的詳情頁
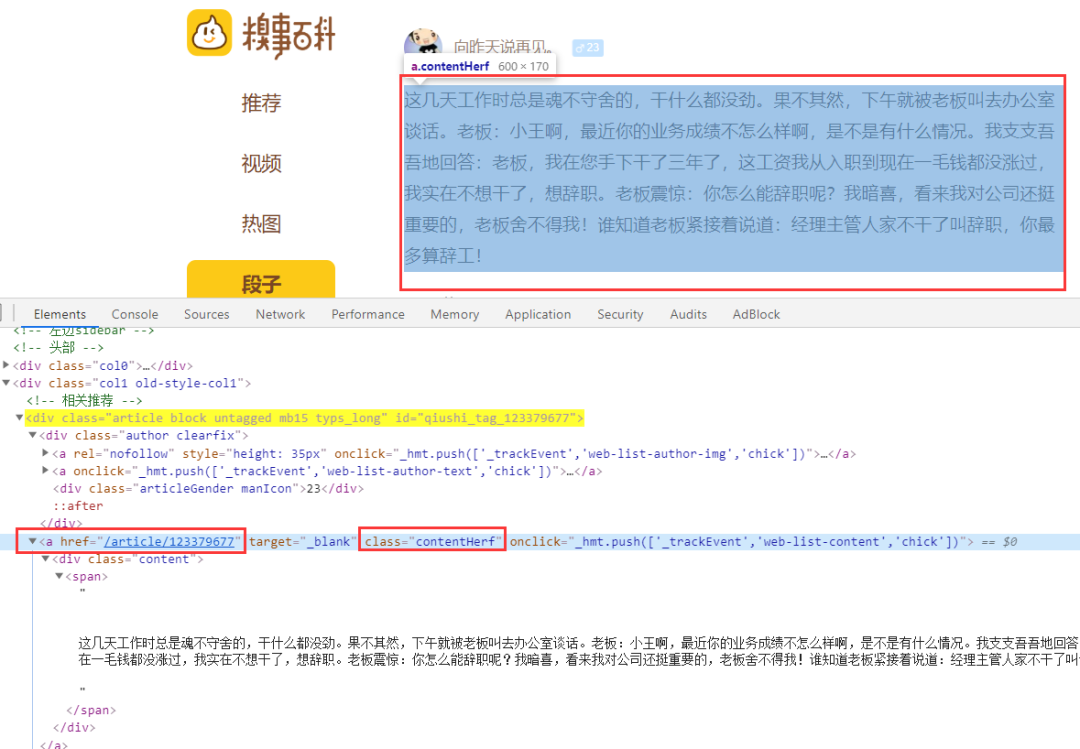
詳情頁,要定位的a標(biāo)簽的href確實(shí)是詳情頁的url
xpath代碼
//div[contains(@class,"article") and contains(@class,"block")]//a[@class="contentHerf"]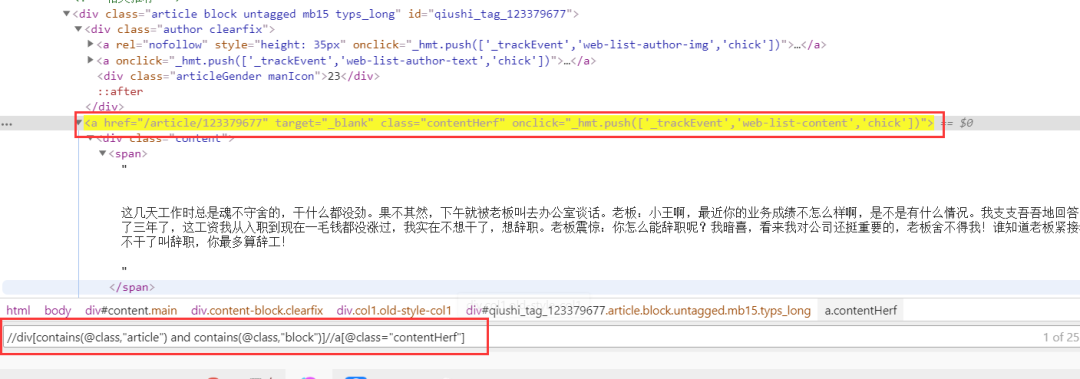
這樣,我們就定位了一個個a標(biāo)簽,只至少在控制臺操作是沒問題的,那么,我們使用Python代碼操作一下吧
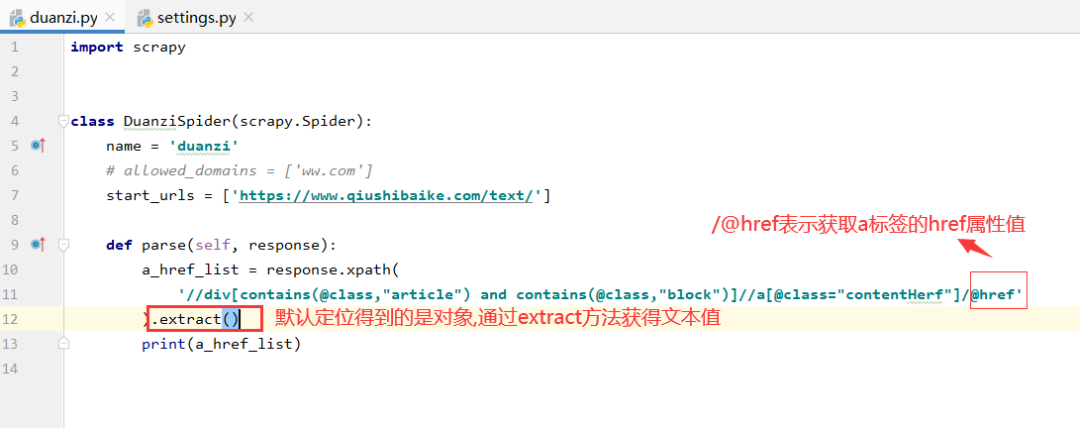
代碼
def parse(self, response):a_href_list = response.xpath('//div[contains(@class,"article") and contains(@class,"block")]//a[@class="contentHerf"]/@href').extract()print(a_href_list)
啟動蜘蛛命令
scrapy crawl <爬蟲名>注:--nolog參數(shù)不加表示一系列日志,一般用于調(diào)試,加此參數(shù)表示只輸入print內(nèi)容
示例:啟動段子命令
scrapy crawl duanzi --nolog
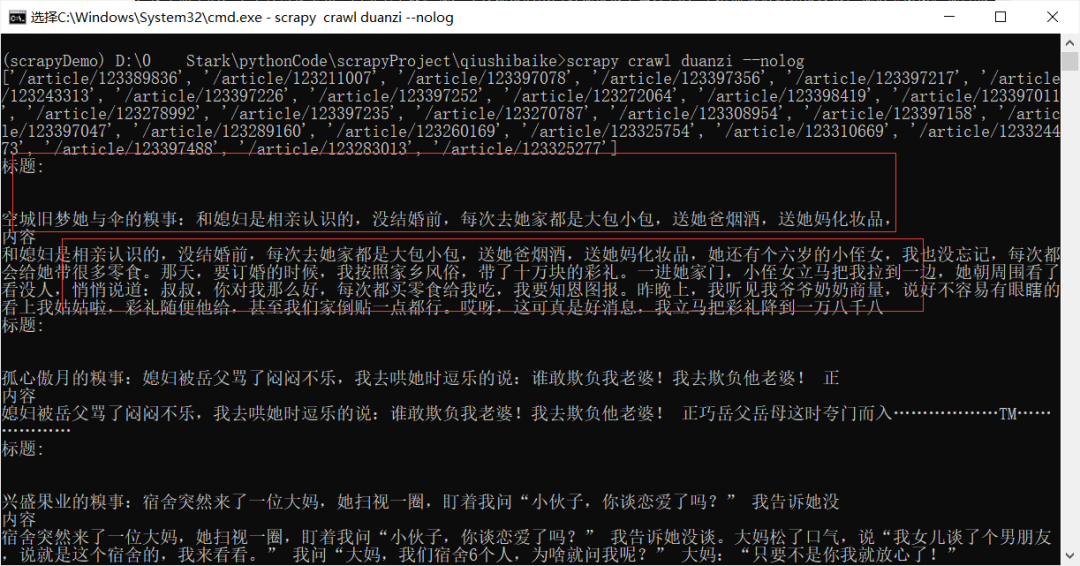
成功拿到每一個鏈接。
獲取詳情頁內(nèi)容
在上述,我們成功的獲取到了每個段子的鏈接,但是會發(fā)現(xiàn)有的段子是不全的,需要進(jìn)入進(jìn)入詳情頁才能看到所以段子內(nèi)容,那我們就使用爬蟲來操作一下吧。
我們定義一下標(biāo)題和內(nèi)容。
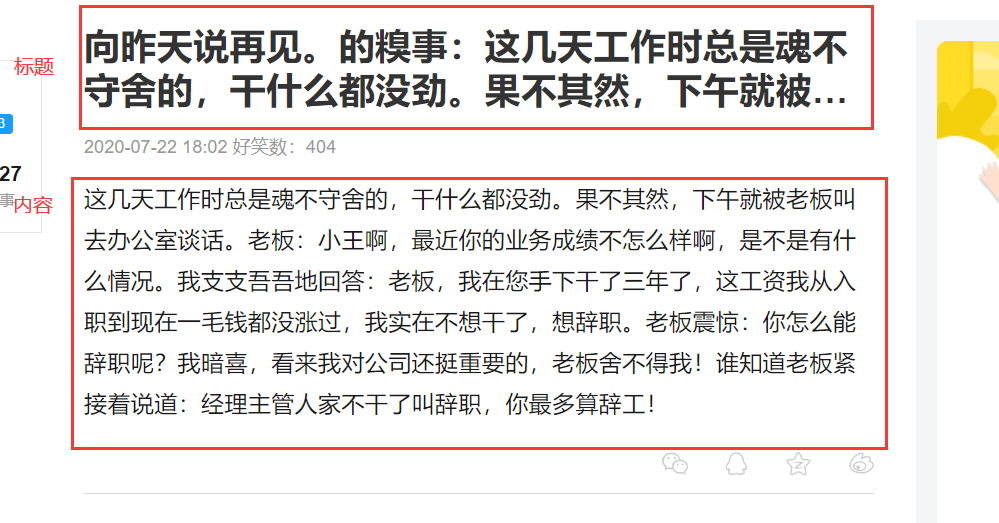
根據(jù)元素審查,標(biāo)題的定位xpath是:
//h1[@class="article-title"]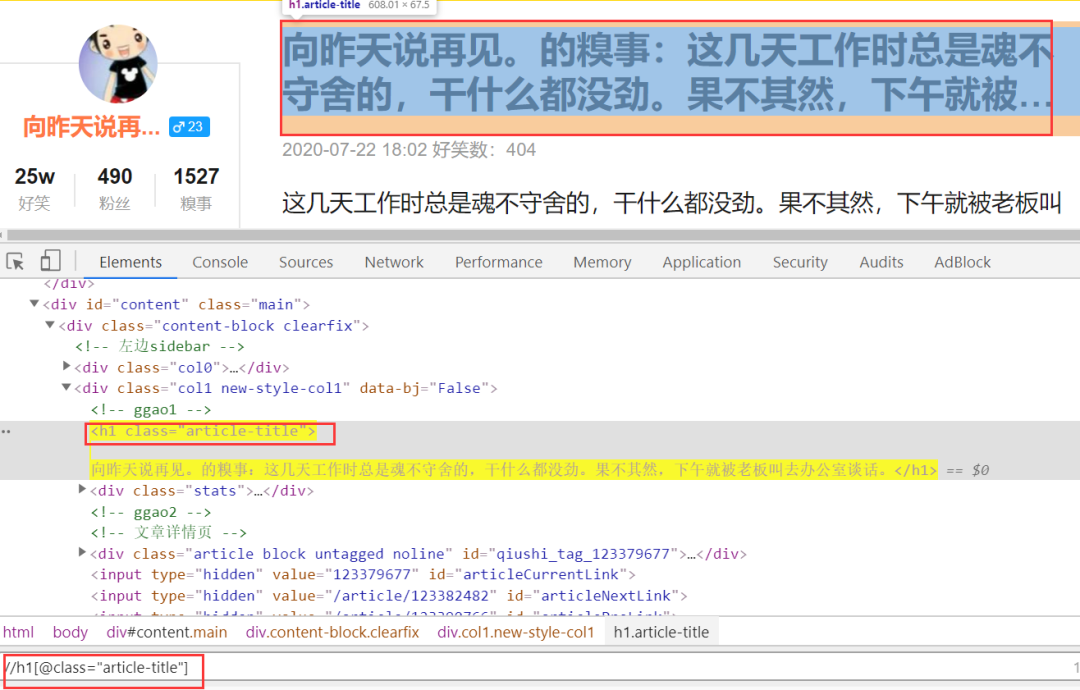
內(nèi)容的xpath是:
//div[@class="content"]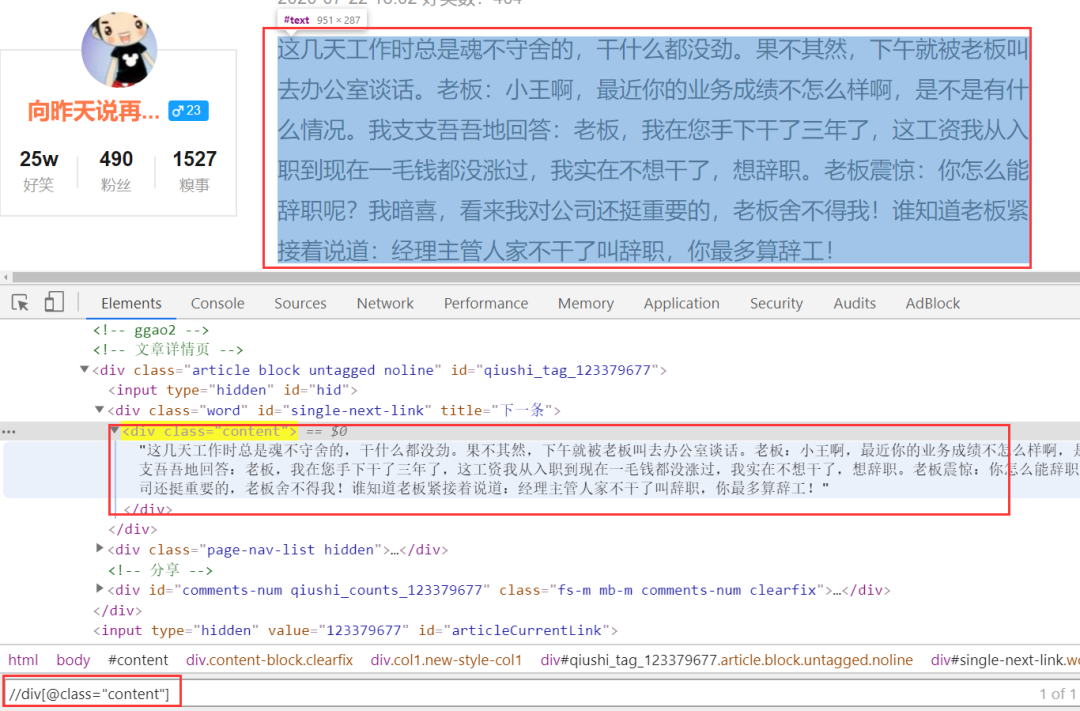
確定標(biāo)題和內(nèi)容的xpath定位之后,我們在python代碼中實(shí)現(xiàn)一下。
注:但是先解決一個問題,詳情頁屬于第二次調(diào)用了,所以我們也需要進(jìn)行調(diào)用第二次,再編寫代碼
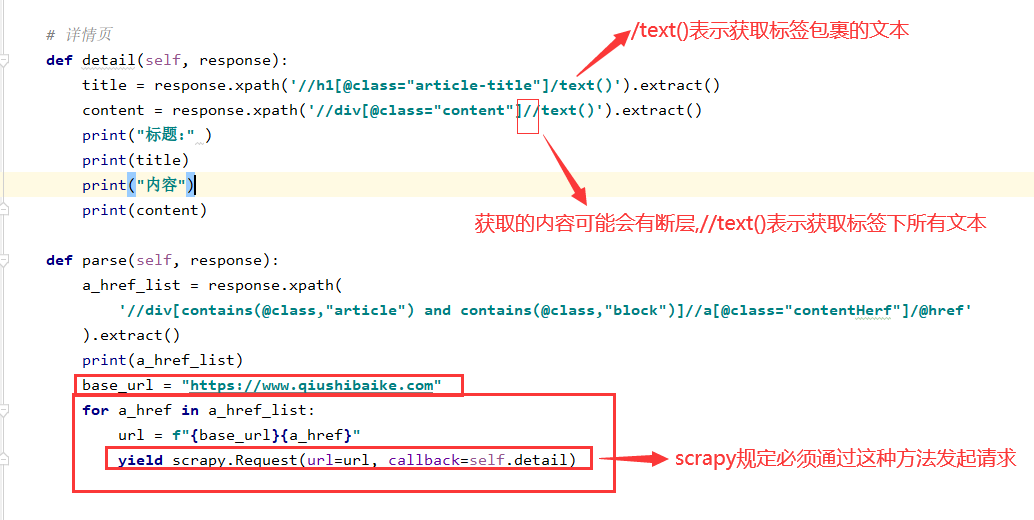
代碼
# 詳情頁def detail(self, response):title = response.xpath('//h1[@class="article-title"]/text()').extract()content = response.xpath('//div[@class="content"]//text()').extract()print("標(biāo)題:" )print(title)print("內(nèi)容")print(content)def parse(self, response):a_href_list = response.xpath('//div[contains(@class,"article") and contains(@class,"block")]//a[@class="contentHerf"]/@href').extract()print(a_href_list)base_url = "https://www.qiushibaike.com"for a_href in a_href_list:url = f"{base_url}{a_href}"yield scrapy.Request(url=url, callback=self.detail)
結(jié)果
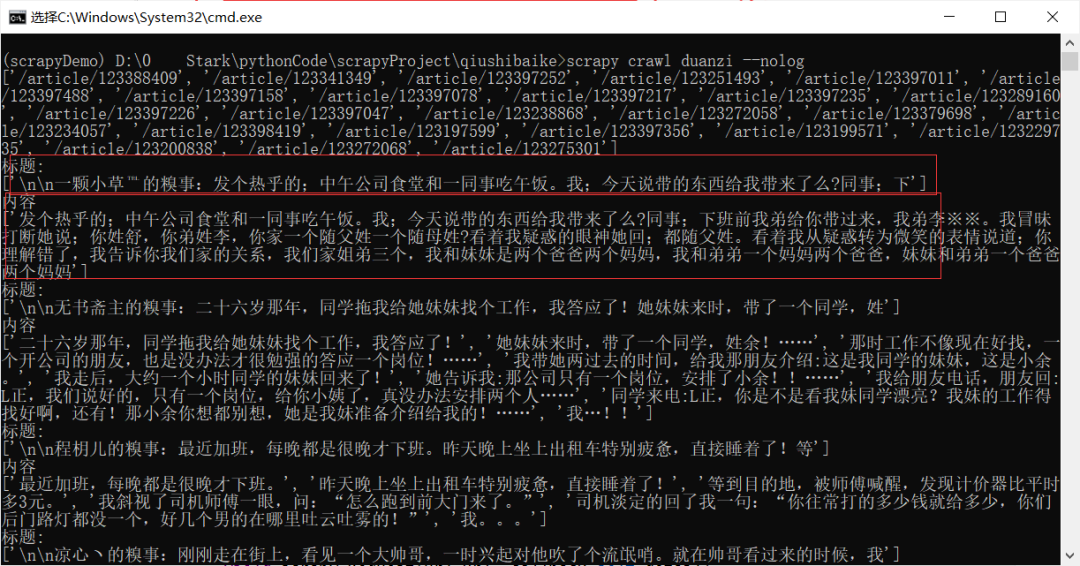
但是會發(fā)現(xiàn)啊,似乎每個都是列表形式,這似乎不太行吶,我們稍微修改一下代碼,這樣我們拿到的就是正常的文本了,如下圖所示:
上述命令總結(jié)
創(chuàng)建爬蟲項(xiàng)目
scrapy startproject <項(xiàng)目名稱> 創(chuàng)建蜘蛛
scrapy genspider <蜘蛛名稱> <網(wǎng)頁的起始url>啟動爬蟲,--nolog參數(shù)不加表示一系列日志,一般用于調(diào)試,加此參數(shù)表示只輸入print內(nèi)容
scrapy crawl <爬蟲名>結(jié)尾
經(jīng)過入門級的操作,我相信你大概知道scrapy是怎么玩了。但是你依然可能懵逼,不懂本質(zhì),不過先走起來,才是根本,后續(xù)慢慢聽我繼續(xù)。
下篇正在趕飛機(jī),如果你覺得寫的還不錯,記得點(diǎn)贊留言哈,感謝你的觀看,么么噠。
用微笑告訴別人,今天的我比昨天強(qiáng),今后也一樣。
如果你覺得文章還可以,記得點(diǎn)贊留言支持我們哈。感謝你的閱讀,有問題請記得在下方留言噢~
想學(xué)習(xí)更多關(guān)于Python的知識,可以參考學(xué)習(xí)網(wǎng)址:http://pdcfighting.com/,點(diǎn)擊閱讀原文,可以直達(dá)噢~
------------------- End -------------------
往期精彩文章推薦:

歡迎大家點(diǎn)贊,留言,轉(zhuǎn)發(fā),轉(zhuǎn)載,感謝大家的相伴與支持
想加入Python學(xué)習(xí)群請?jiān)诤笈_回復(fù)【入群】
萬水千山總是情,點(diǎn)個【在看】行不行
/今日留言主題/
隨便說一兩句吧~~