
數(shù)據(jù)同步工具之FlinkCDC/Canal/Debezium對比
點(diǎn)擊上方藍(lán)色字體,選擇“設(shè)為星標(biāo)”
回復(fù)”面試“獲取更多驚喜

前言
數(shù)據(jù)準(zhǔn)實(shí)時(shí)復(fù)制(CDC)是目前行內(nèi)實(shí)時(shí)數(shù)據(jù)需求大量使用的技術(shù),隨著國產(chǎn)化的需求,我們也逐步考慮基于開源產(chǎn)品進(jìn)行準(zhǔn)實(shí)時(shí)數(shù)據(jù)同步工具的相關(guān)開發(fā),逐步實(shí)現(xiàn)對商業(yè)產(chǎn)品的替代。本文把市面上常見的幾種開源產(chǎn)品,Canal、Debezium、Flink CDC 從原理和適用做了對比,供大家參考。
本文首發(fā)微信公眾號《import_bigdata》
Debezium
Debezium is an open source distributed platform for change data capture. Start it up, point it at your databases, and your apps can start responding to all of the inserts, updates, and deletes that other apps commit to your databases. Debezium is durable and fast, so your apps can respond quickly and never miss an event, even when things go wrong.
Debezium是一種CDC(Change Data Capture)工具,工作原理類似大家所熟知的Canal, DataBus, Maxwell等,是通過抽取數(shù)據(jù)庫日志來獲取變更。
Debezium最初設(shè)計(jì)成一個(gè)Kafka Connect 的Source Plugin,目前開發(fā)者雖致力于將其與Kafka Connect解耦,但當(dāng)前的代碼實(shí)現(xiàn)還未變動(dòng)。下圖引自Debeizum官方文檔,可以看到一個(gè)Debezium在一個(gè)完整CDC系統(tǒng)中的位置。
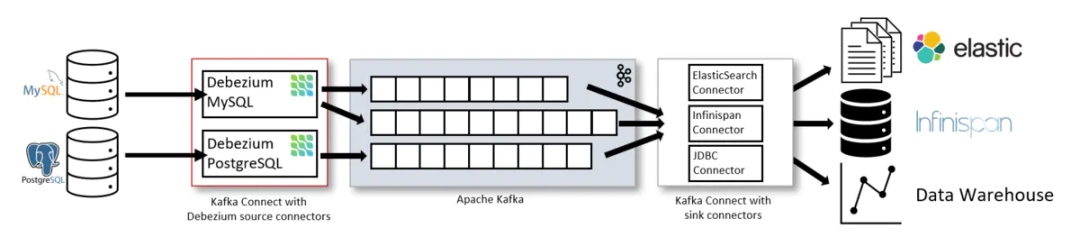
Kafka Connect 為Source Plugin提供了一系列的編程接口,最主要的就是要實(shí)現(xiàn)SourceTask的poll方法,其返回List將會(huì)被以最少一次語義的方式投遞至Kafka。
Debezium MySQL 架構(gòu)
Reader體系構(gòu)成了MySQL模塊中代碼的主線,我們的分析從Reader開始。
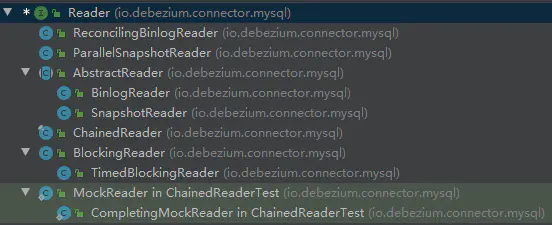
從名字上應(yīng)該可以看出,真正主要的是SnapshotReader和BinlogReader,分別實(shí)現(xiàn)了對MySQL數(shù)據(jù)的全量讀取和增量讀取,他們繼承于AbstractReader,里面封裝了共用邏輯,下圖是AbstractReader的內(nèi)部設(shè)計(jì)。

可以看到,AbstractReader在實(shí)現(xiàn)時(shí),并沒有直接將enqueue喂進(jìn)來的record投遞進(jìn)Kafka,而是通過一個(gè)內(nèi)存阻塞隊(duì)列BlockingQueue進(jìn)行了解耦,這種設(shè)計(jì)有諸多好處:
職責(zé)解耦
如上的圖中,在喂入BlockingQueue之前,要根據(jù)條件判斷是否接受該record;在向Kafka投遞record之前,判斷task的running狀態(tài)。這樣把同類的功能限定在特定的位置。
線程隔離
BlockingQueue是一個(gè)線程安全的阻塞隊(duì)列,通過BlockingQueue實(shí)現(xiàn)的生產(chǎn)者消費(fèi)者模型,是可以跑在不同的線程里的,這樣避免局部的阻塞帶來的整體的干擾。如上圖中的右側(cè),消費(fèi)者會(huì)定期判斷running標(biāo)志位,若running被stop信號置為了false,可以立刻停止整個(gè)task,而不會(huì)因MySQL IO阻塞延遲相應(yīng)。
Single與Batch的互相轉(zhuǎn)化
Enqueue record是單條的投遞record,drain_to是批量的消費(fèi)records。這個(gè)用法也可以反過來,實(shí)現(xiàn)batch到single的轉(zhuǎn)化。
可能你還知道阿里開源的另一個(gè)MySQL CDC工具canal,他只負(fù)責(zé)stream過程,并沒有處理snapshot過程,這也是debezium相較于canal的一個(gè)優(yōu)勢。
對于Debezium來說,基本沿用了官方搭建從庫的這一思路,讓我們看下官方文檔描述的詳細(xì)步驟。
MySQL連接器每次獲取快照的時(shí)候會(huì)執(zhí)行以下的步驟:
獲取一個(gè)全局讀鎖,從而阻塞住其他數(shù)據(jù)庫客戶端的寫操作。 開啟一個(gè)可重復(fù)讀語義的事務(wù),來保證后續(xù)的在同一個(gè)事務(wù)內(nèi)讀操作都是在一個(gè)一致性快照中完成的。 讀取binlog的當(dāng)前位置。 讀取連接器中配置的數(shù)據(jù)庫和表的模式(schema)信息。 釋放全局讀鎖,允許其他的數(shù)據(jù)庫客戶端對數(shù)據(jù)庫進(jìn)行寫操作。 (可選)把DDL改變事件寫入模式改變topic(schema change topic),包括所有的必要的DROP和CREATEDDL語句。 掃描所有數(shù)據(jù)庫的表,并且為每一個(gè)表產(chǎn)生一個(gè)和特定表相關(guān)的kafka topic創(chuàng)建事件(即為每一個(gè)表創(chuàng)建一個(gè)kafka topic)。 提交事務(wù)。 記錄連接器成功完成快照任務(wù)時(shí)的連接器偏移量。
部署
基于 Kafka Connect
最常見的架構(gòu)是通過 Apache Kafka Connect 部署 Debezium。Kafka Connect 為在 Kafka 和外部存儲(chǔ)系統(tǒng)之間系統(tǒng)數(shù)據(jù)提供了一種可靠且可伸縮性的方式。它為 Connector 插件提供了一組 API 和一個(gè)運(yùn)行時(shí):Connect 負(fù)責(zé)運(yùn)行這些插件,它們則負(fù)責(zé)移動(dòng)數(shù)據(jù)。通過 Kafka Connect 可以快速實(shí)現(xiàn) Source Connector 和 Sink Connector 進(jìn)行交互構(gòu)造一個(gè)低延遲的數(shù)據(jù) Pipeline:
Source Connector(例如,Debezium):將記錄發(fā)送到 Kafka Sink Connector:將 Kafka Topic 中的記錄發(fā)送到其他系統(tǒng)
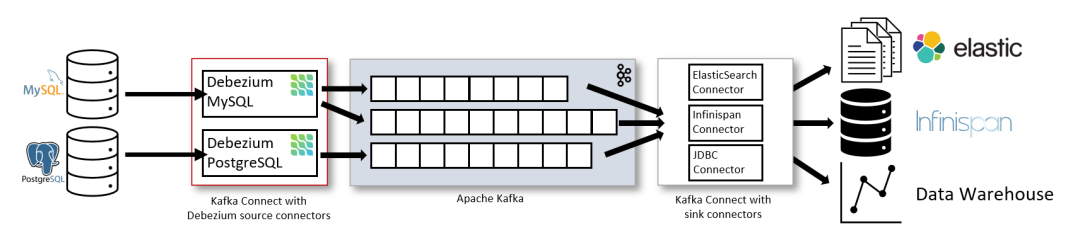
如上圖所示,部署了 MySQL 和 PostgresSQL 的 Debezium Connector 以捕獲這兩種類型數(shù)據(jù)庫的變更。每個(gè) Debezium Connector 都會(huì)與其源數(shù)據(jù)庫建立連接:
MySQL Connector 使用客戶端庫來訪問 binlog。 PostgreSQL Connector 從邏輯副本流中讀取數(shù)據(jù)。
除了 Kafka Broker 之外,Kafka Connect 也作為一個(gè)單獨(dú)的服務(wù)運(yùn)行。默認(rèn)情況下,數(shù)據(jù)庫表的變更會(huì)寫入名稱與表名稱對應(yīng)的 Kafka Topic 中。如果需要,您可以通過配置 Debezium 的 Topic 路由轉(zhuǎn)換來調(diào)整目標(biāo) Topic 名稱。例如,您可以:
將記錄路由到名稱與表名不同的 Topic 中 將多個(gè)表的變更事件記錄流式傳輸?shù)揭粋€(gè) Topic 中
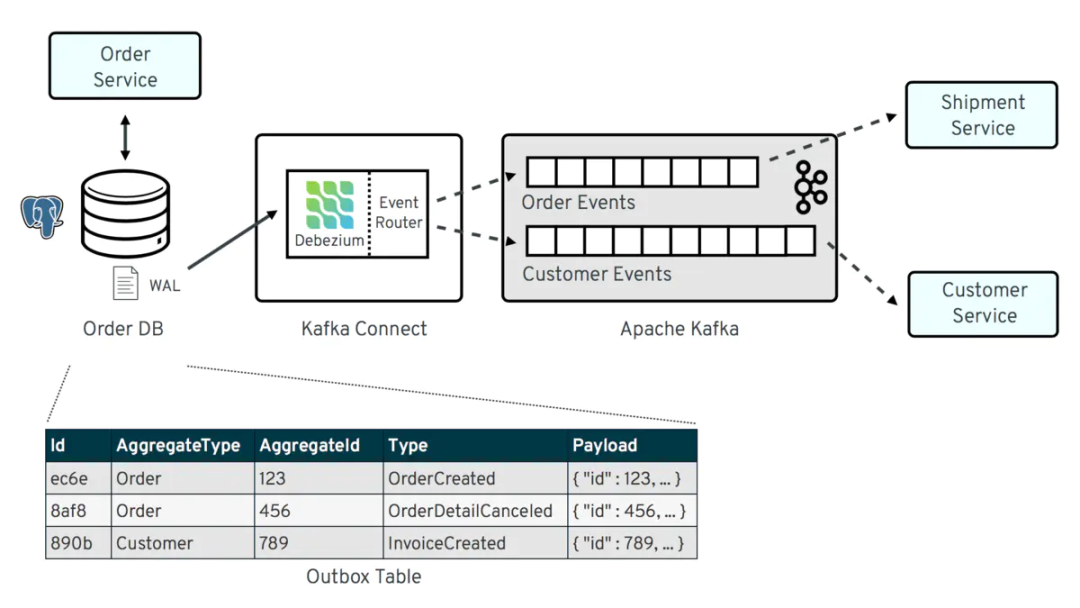
變更事件記錄在 Apache Kafka 中后,Kafka Connect 生態(tài)系統(tǒng)中的不同 Sink Connector 可以將記錄流式傳輸?shù)狡渌到y(tǒng)、數(shù)據(jù)庫,例如 Elasticsearch、數(shù)據(jù)倉庫、分析系統(tǒng)或者緩存(例如 Infinispan)。
Debezium Server
另一種部署 Debezium 的方法是使用 Debezium Server。Debezium Server 是一個(gè)可配置的、隨時(shí)可用的應(yīng)用程序,可以將變更事件從源數(shù)據(jù)庫流式傳輸?shù)礁鞣N消息中間件上。
下圖展示了基于 Debezium Server 的變更數(shù)據(jù)捕獲 Pipeline 架構(gòu):
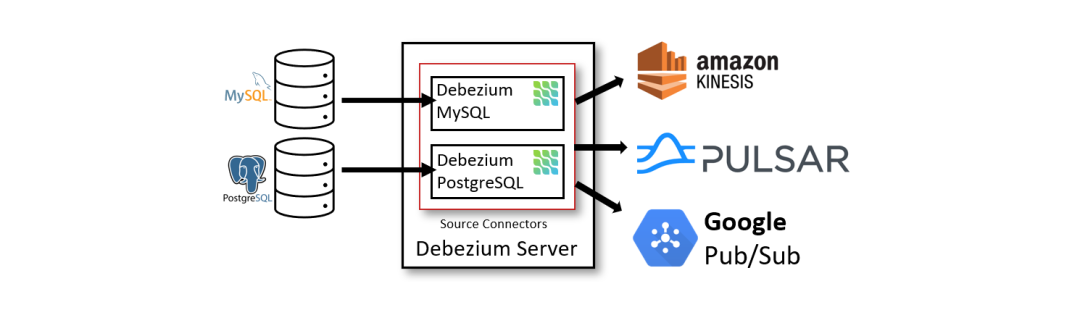
Debezium Server 配置使用 Debezium Source Connector 來捕獲源數(shù)據(jù)庫中的變更。變更事件可以序列化為不同的格式,例如 JSON 或 Apache Avro,然后發(fā)送到各種消息中間件,例如 Amazon Kinesis、Google Cloud Pub/Sub 或 Apache Pulsar。
嵌入式引擎
使用 Debezium Connector 的另一種方法是嵌入式引擎。在這種情況下,Debezium 不會(huì)通過 Kafka Connect 運(yùn)行,而是作為嵌入到您自定義 Java 應(yīng)用程序中的庫運(yùn)行。這對于在您的應(yīng)用程序本身內(nèi)獲取變更事件非常有幫助,無需部署完整的 Kafka 和 Kafka Connect 集群,也不用將變更流式傳輸?shù)?Amazon Kinesis 等消息中間件上。
特性
Debezium 是一組用于 Apache Kafka Connect 的 Source Connector。每個(gè) Connector 都通過使用該數(shù)據(jù)庫的變更數(shù)據(jù)捕獲 (CDC) 功能從不同的數(shù)據(jù)庫中獲取變更。與其他方法(例如輪詢或雙重寫入)不同,Debezium 的實(shí)現(xiàn)基于日志的 CDC:
確保捕獲所有的數(shù)據(jù)變更。 以極低的延遲生成變更事件,同時(shí)避免因?yàn)轭l繁輪詢導(dǎo)致 CPU 使用率增加。例如,對于 MySQL 或 PostgreSQL,延遲在毫秒范圍內(nèi)。 不需要更改您的數(shù)據(jù)模型,例如 ‘Last Updated’ 列。 可以捕獲刪除操作。 可以捕獲舊記錄狀態(tài)以及其他元數(shù)據(jù),例如,事務(wù) ID,具體取決于數(shù)據(jù)庫的功能和配置。
Flink CDC
2020 年 7 月提交了第一個(gè) commit,這是基于個(gè)人興趣孵化的項(xiàng)目; 2020 年 7 中旬支持了 MySQL-CDC; 2020 年 7 月末支持了 Postgres-CDC;
一年的時(shí)間,該項(xiàng)目在 GitHub 上的 star 數(shù)已經(jīng)超過 800。

Flink CDC 發(fā)展
Flink CDC 底層封裝了 Debezium, Debezium 同步一張表分為兩個(gè)階段:
全量階段:查詢當(dāng)前表中所有記錄; 增量階段:從 binlog 消費(fèi)變更數(shù)據(jù)。
大部分用戶使用的場景都是全量 + 增量同步,加鎖是發(fā)生在全量階段,目的是為了確定全量階段的初始位點(diǎn),保證增量 + 全量實(shí)現(xiàn)一條不多,一條不少,從而保證數(shù)據(jù)一致性。從下圖中我們可以分析全局鎖和表鎖的一些加鎖流程,左邊紅色線條是鎖的生命周期,右邊是 MySQL 開啟可重復(fù)讀事務(wù)的生命周期。
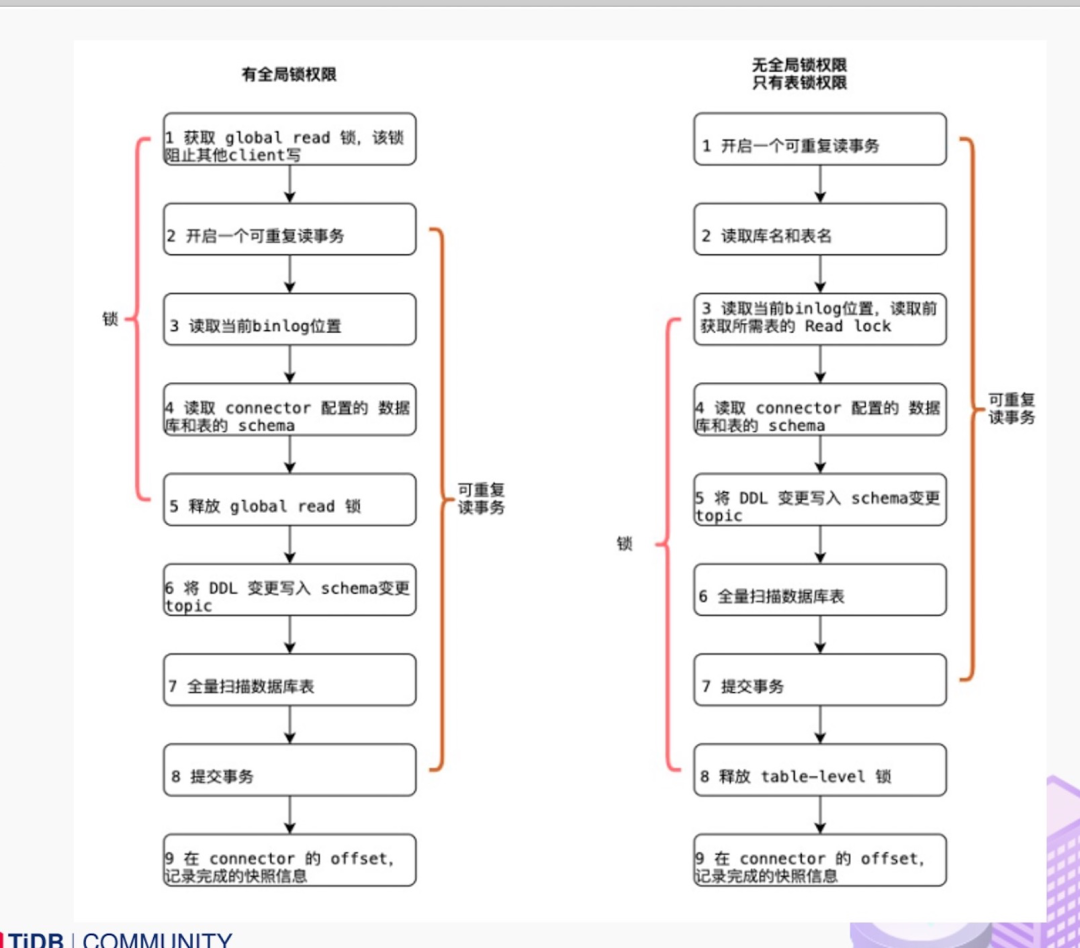
以全局鎖為例,首先是獲取一個(gè)鎖,然后再去開啟可重復(fù)讀的事務(wù)。這里鎖住操作是讀取 binlog 的起始位置和當(dāng)前表的 schema。這樣做的目的是保證 binlog 的起始位置和讀取到的當(dāng)前 schema 是可以對應(yīng)上的,因?yàn)楸淼?schema 是會(huì)改變的,比如如刪除列或者增加列。在讀取這兩個(gè)信息后,SnapshotReader 會(huì)在可重復(fù)讀事務(wù)里讀取全量數(shù)據(jù),在全量數(shù)據(jù)讀取完成后,會(huì)啟動(dòng) BinlogReader 從讀取的 binlog 起始位置開始增量讀取,從而保證全量數(shù)據(jù) + 增量數(shù)據(jù)的無縫銜接。
表鎖是全局鎖的退化版,因?yàn)槿宙i的權(quán)限會(huì)比較高,因此在某些場景,用戶只有表鎖。表鎖鎖的時(shí)間會(huì)更長,因?yàn)楸礞i有個(gè)特征:鎖提前釋放了可重復(fù)讀的事務(wù)默認(rèn)會(huì)提交,所以鎖需要等到全量數(shù)據(jù)讀完后才能釋放。
經(jīng)過上面分析,接下來看看這些鎖到底會(huì)造成怎樣嚴(yán)重的后果:

Flink CDC 1.x 可以不加鎖,能夠滿足大部分場景,但犧牲了一定的數(shù)據(jù)準(zhǔn)確性。Flink CDC 1.x 默認(rèn)加全局鎖,雖然能保證數(shù)據(jù)一致性,但存在上述 hang 住數(shù)據(jù)的風(fēng)險(xiǎn)。
Flink CDC 1.x得到了很多用戶在社區(qū)的反饋,主要?dú)w納為三個(gè):

全量 + 增量讀取的過程需要保證所有數(shù)據(jù)的一致性,因此需要通過加鎖保證,但是加鎖在數(shù)據(jù)庫層面上是一個(gè)十分高危的操作。底層 Debezium 在保證數(shù)據(jù)一致性時(shí),需要對讀取的庫或表加鎖,全局鎖可能導(dǎo)致數(shù)據(jù)庫鎖住,表級鎖會(huì)鎖住表的讀,DBA 一般不給鎖權(quán)限。 不支持水平擴(kuò)展,因?yàn)?Flink CDC 底層是基于 Debezium,起架構(gòu)是單節(jié)點(diǎn),所以Flink CDC 只支持單并發(fā)。在全量階段讀取階段,如果表非常大 (億級別),讀取時(shí)間在小時(shí)甚至天級別,用戶不能通過增加資源去提升作業(yè)速度。 全量讀取階段不支持 checkpoint:CDC 讀取分為兩個(gè)階段,全量讀取和增量讀取,目前全量讀取階段是不支持 checkpoint 的,因此會(huì)存在一個(gè)問題:當(dāng)我們同步全量數(shù)據(jù)時(shí),假設(shè)需要 5 個(gè)小時(shí),當(dāng)我們同步了 4 小時(shí)的時(shí)候作業(yè)失敗,這時(shí)候就需要重新開始,再讀取 5 個(gè)小時(shí)。
通過上面的分析,可以知道 2.0 的設(shè)計(jì)方案,核心要解決上述的三個(gè)問題,即支持無鎖、水平擴(kuò)展、checkpoint。
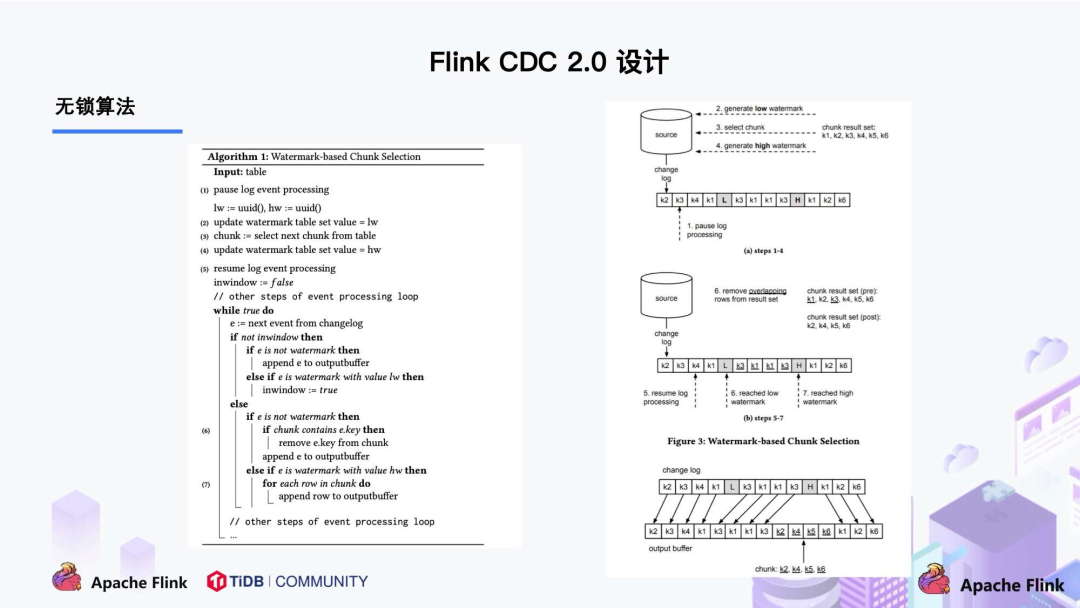
目前,F(xiàn)link CDC 2.0 也已經(jīng)正式發(fā)布,此次的核心改進(jìn)和提升包括:
并發(fā)讀取,全量數(shù)據(jù)的讀取性能可以水平擴(kuò)展; 全程無鎖,不對線上業(yè)務(wù)產(chǎn)生鎖的風(fēng)險(xiǎn); 斷點(diǎn)續(xù)傳,支持全量階段的 checkpoint。
本文發(fā)自微信公眾號《import_bigdata》
Canal
canal [k?'n?l],譯意為水道/管道/溝渠,主要用途是基于 MySQL 數(shù)據(jù)庫增量日志解析,提供增量數(shù)據(jù)訂閱和消費(fèi)。
早期阿里巴巴因?yàn)楹贾莺兔绹p機(jī)房部署,存在跨機(jī)房同步的業(yè)務(wù)需求,實(shí)現(xiàn)方式主要是基于業(yè)務(wù) trigger 獲取增量變更。從 2010 年開始,業(yè)務(wù)逐步嘗試數(shù)據(jù)庫日志解析獲取增量變更進(jìn)行同步,由此衍生出了大量的數(shù)據(jù)庫增量訂閱和消費(fèi)業(yè)務(wù)。
基于日志增量訂閱和消費(fèi)的業(yè)務(wù)包括:
數(shù)據(jù)庫鏡像 數(shù)據(jù)庫實(shí)時(shí)備份 索引構(gòu)建和實(shí)時(shí)維護(hù)(拆分異構(gòu)索引、倒排索引等) 業(yè)務(wù) cache 刷新 帶業(yè)務(wù)邏輯的增量數(shù)據(jù)處理
當(dāng)前的canal支持源端MySQL版本包括 5.1.x , 5.5.x , 5.6.x , 5.7.x , 8.0.x。
工作原理
MySQL主備復(fù)制原理
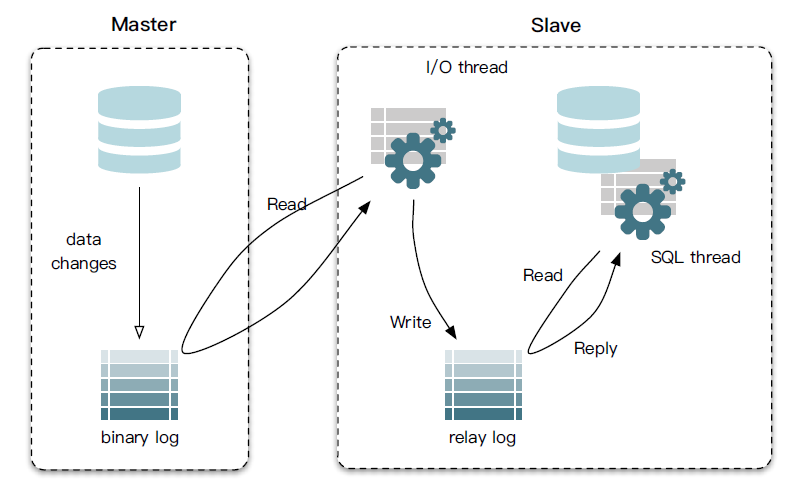
MySQL master 將數(shù)據(jù)變更寫入二進(jìn)制日志( binary log, 其中記錄叫做二進(jìn)制日志事件binary log events,可以通過 show binlog events 進(jìn)行查看) MySQL slave 將 master 的 binary log events 拷貝到它的中繼日志(relay log) MySQL slave 重放 relay log 中事件,將數(shù)據(jù)變更反映它自己的數(shù)據(jù)
canal 工作原理
canal 模擬 MySQL slave 的交互協(xié)議,偽裝自己為MySQL slave,向MySQL master發(fā)送dump協(xié)議 MySQL master收到 dump 請求,開始推送 binary log 給 slave (即 canal ) canal 解析 binary log 對象(原始為 byte 流)
Binlog獲取詳解
Binlog發(fā)送接收流程,流程如下圖所示:
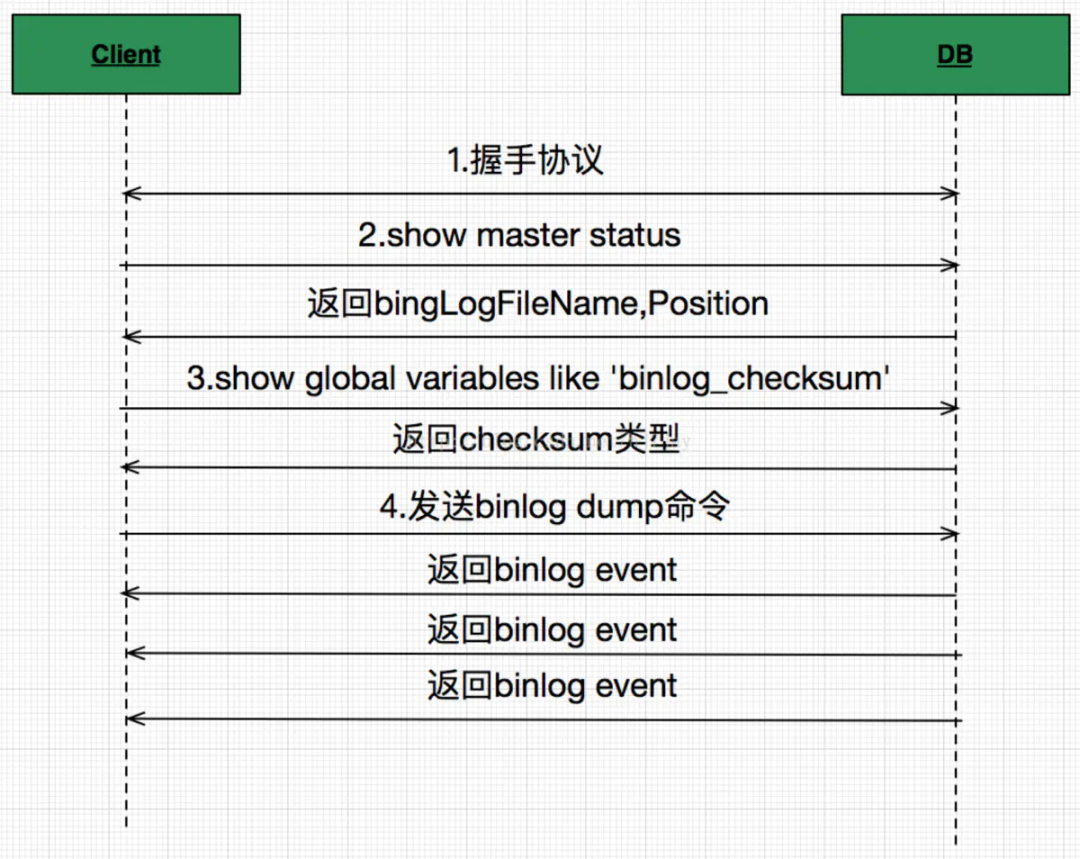
首先,我們需要偽造一個(gè)slave,向master注冊,這樣master才會(huì)發(fā)送binlog event。注冊很簡單,就是向master發(fā)送COM_REGISTER_SLAVE命令,帶上slave相關(guān)信息。這里需要注意,因?yàn)樵贛ySQL的replication topology中,都需要使用一個(gè)唯一的server id來區(qū)別標(biāo)示不同的server實(shí)例,所以這里我們偽造的slave也需要一個(gè)唯一的server id。
接著實(shí)現(xiàn)binlog的dump。MySQL只支持一種binlog dump方式,也就是指定binlog filename + position,向master發(fā)送COM_BINLOG_DUMP命令。在發(fā)送dump命令的時(shí)候,我們可以指定flag為BINLOG_DUMP_NON_BLOCK,這樣master在沒有可發(fā)送的binlog event之后,就會(huì)返回一個(gè)EOF package。不過通常對于slave來說,一直把連接掛著可能更好,這樣能更及時(shí)收到新產(chǎn)生的binlog event。
Dump命令包圖如下所示:

如上圖所示,在報(bào)文中塞入binlogPosition和binlogFileName即可讓master從相應(yīng)的位置發(fā)送binlog event。
canal結(jié)構(gòu)
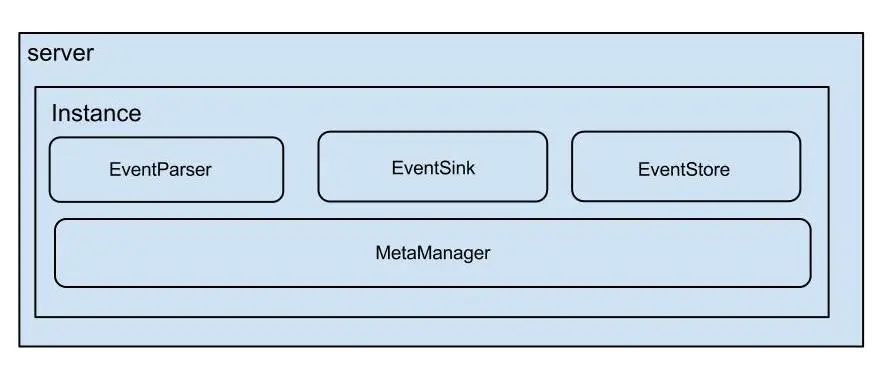
說明:
server代表一個(gè)canal運(yùn)行實(shí)例,對應(yīng)于一個(gè)jvm,也可以理解為一個(gè)進(jìn)程 instance對應(yīng)于一個(gè)數(shù)據(jù)隊(duì)列 (1個(gè)server對應(yīng)1..n個(gè)instance),每一個(gè)數(shù)據(jù)隊(duì)列可以理解為一個(gè)數(shù)據(jù)庫實(shí)例。
Server設(shè)計(jì)
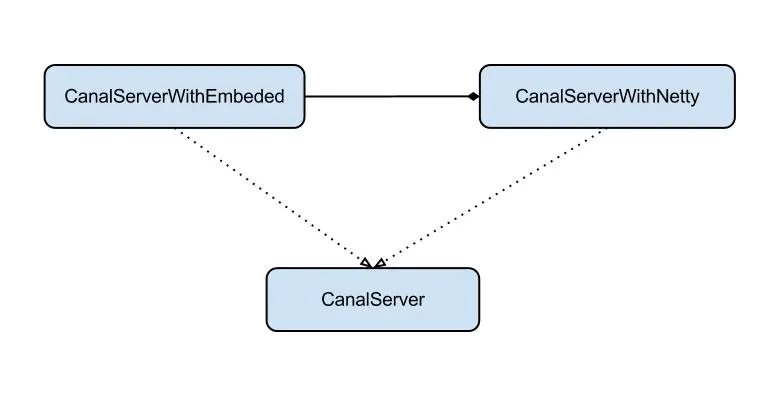
server代表了一個(gè)canal的運(yùn)行實(shí)例,為了方便組件化使用,特意抽象了Embeded(嵌入式) / Netty(網(wǎng)絡(luò)訪問)的兩種實(shí)現(xiàn)
Embeded : 對latency和可用性都有比較高的要求,自己又能hold住分布式的相關(guān)技術(shù)(比如failover) Netty : 基于netty封裝了一層網(wǎng)絡(luò)協(xié)議,由canal server保證其可用性,采用的pull模型,當(dāng)然latency會(huì)稍微打點(diǎn)折扣,不過這個(gè)也視情況而定。(阿里系的notify和metaq,典型的push/pull模型,目前也逐步的在向pull模型靠攏,push在數(shù)據(jù)量大的時(shí)候會(huì)有一些問題)
Instance設(shè)計(jì)
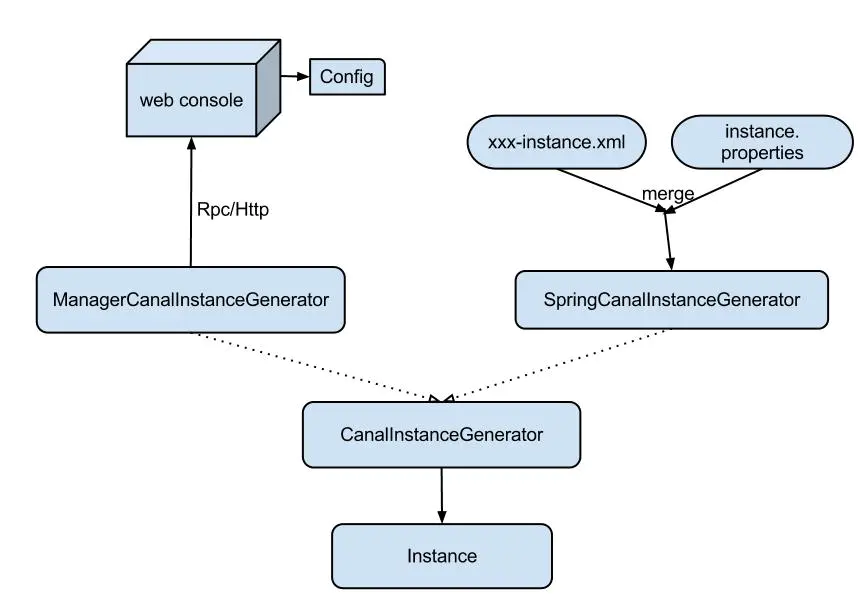
instance代表了一個(gè)實(shí)際運(yùn)行的數(shù)據(jù)隊(duì)列,包括了EventPaser,EventSink,EventStore等組件。
抽象了CanalInstanceGenerator,主要是考慮配置的管理方式:
manager方式:和你自己的內(nèi)部web console/manager系統(tǒng)進(jìn)行對接。(目前主要是公司內(nèi)部使用,Otter采用這種方式) spring方式:基于spring xml + properties進(jìn)行定義,構(gòu)建spring配置.
下面是canalServer和instance如何運(yùn)行:
canalServer.setCanalInstanceGenerator(new?CanalInstanceGenerator()?{
????????????public?CanalInstance?generate(String?destination)?{
????????????????Canal?canal?=?canalConfigClient.findCanal(destination);
????????????????//?此處省略部分代碼?大致邏輯是設(shè)置canal一些屬性
????????????????CanalInstanceWithManager?instance?=?new?CanalInstanceWithManager(canal,?filter)?{
????????????????????protected?CanalHAController?initHaController()?{
????????????????????????HAMode?haMode?=?parameters.getHaMode();
????????????????????????if?(haMode.isMedia())?{
????????????????????????????return?new?MediaHAController(parameters.getMediaGroup(),
????????????????????????????????parameters.getDbUsername(),
????????????????????????????????parameters.getDbPassword(),
????????????????????????????????parameters.getDefaultDatabaseName());
????????????????????????}?else?{
????????????????????????????return?super.initHaController();
????????????????????????}
????????????????????}
????????????????????protected?void?startEventParserInternal(CanalEventParser?parser,?boolean?isGroup)?{
????????????????????????//大致邏輯是?設(shè)置支持的類型
????????????????????????//初始化設(shè)置MysqlEventParser的主庫信息,這處抽象不好,目前只支持mysql
????????????????????}
????????????????};
????????????????return?instance;
????????????}
????????});
????????canalServer.start();?//啟動(dòng)canalServer
????????canalServer.start(destination);//啟動(dòng)對應(yīng)instance
????????this.clientIdentity?=?new?ClientIdentity(destination,?pipeline.getParameters().getMainstemClientId(),?filter);
????????canalServer.subscribe(clientIdentity);//?發(fā)起一次訂閱,當(dāng)監(jiān)聽到instance配置時(shí),調(diào)用generate方法注入新的instance
instance模塊:
eventParser (數(shù)據(jù)源接入,模擬slave協(xié)議和master進(jìn)行交互,協(xié)議解析) eventSink (Parser和Store鏈接器,進(jìn)行數(shù)據(jù)過濾,加工,分發(fā)的工作) eventStore (數(shù)據(jù)存儲(chǔ)) metaManager (增量訂閱&消費(fèi)信息管理器)
EventParser設(shè)計(jì)
大致過程:
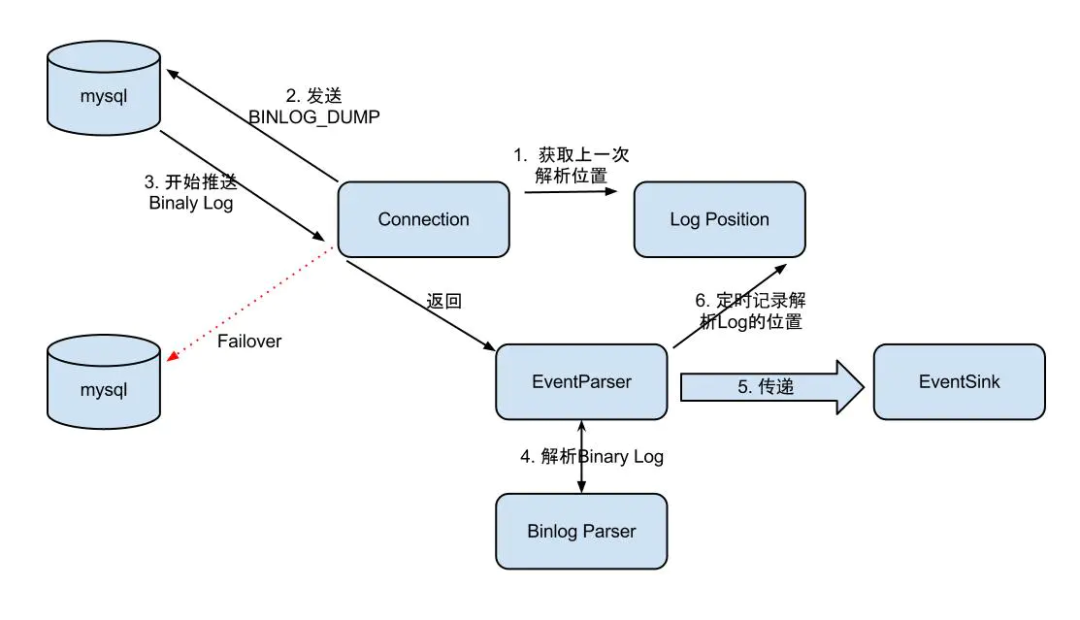
整個(gè)parser過程大致可分為幾步:
Connection獲取上一次解析成功的位置 (如果第一次啟動(dòng),則獲取初始指定的位置或者是當(dāng)前數(shù)據(jù)庫的binlog位點(diǎn)) Connection建立鏈接,發(fā)送BINLOG_DUMP指令
//?0.?write?command?number
//?1.?write?4?bytes?bin-log?position?to?start?at
//?2.?write?2?bytes?bin-log?flags
//?3.?write?4?bytes?server?id?of?the?slave
//?4.?write?bin-log?file?name
Mysql開始推送Binaly Log 接收到的Binaly Log的通過Binlog parser進(jìn)行協(xié)議解析,補(bǔ)充一些特定信息(補(bǔ)充字段名字,字段類型,主鍵信息,unsigned類型處理) 傳遞給EventSink模塊進(jìn)行數(shù)據(jù)存儲(chǔ),是一個(gè)阻塞操作,直到存儲(chǔ)成功 存儲(chǔ)成功后,由CanalLogPositionManager定時(shí)記錄Binaly Log位置
EventSink設(shè)計(jì)
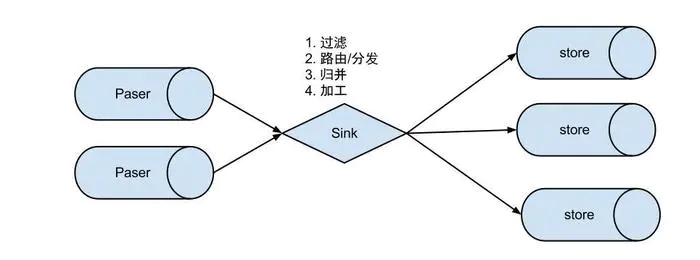
說明:
數(shù)據(jù)過濾:支持通配符的過濾模式,表名,字段內(nèi)容等 數(shù)據(jù)路由/分發(fā):解決1:n (1個(gè)parser對應(yīng)多個(gè)store的模式) 數(shù)據(jù)歸并:解決n:1 (多個(gè)parser對應(yīng)1個(gè)store) 數(shù)據(jù)加工:在進(jìn)入store之前進(jìn)行額外的處理,比如join
數(shù)據(jù)1:n業(yè)務(wù)
為了合理的利用數(shù)據(jù)庫資源, 一般常見的業(yè)務(wù)都是按照schema進(jìn)行隔離,然后在mysql上層或者dao這一層面上,進(jìn)行一個(gè)數(shù)據(jù)源路由,屏蔽數(shù)據(jù)庫物理位置對開發(fā)的影響,阿里系主要是通過cobar/tddl來解決數(shù)據(jù)源路由問題。
所以,一般一個(gè)數(shù)據(jù)庫實(shí)例上,會(huì)部署多個(gè)schema,每個(gè)schema會(huì)有由1個(gè)或者多個(gè)業(yè)務(wù)方關(guān)注。
數(shù)據(jù)n:1業(yè)務(wù)
同樣,當(dāng)一個(gè)業(yè)務(wù)的數(shù)據(jù)規(guī)模達(dá)到一定的量級后,必然會(huì)涉及到水平拆分和垂直拆分的問題,針對這些拆分的數(shù)據(jù)需要處理時(shí),就需要鏈接多個(gè)store進(jìn)行處理,消費(fèi)的位點(diǎn)就會(huì)變成多份,而且數(shù)據(jù)消費(fèi)的進(jìn)度無法得到盡可能有序的保證。
所以,在一定業(yè)務(wù)場景下,需要將拆分后的增量數(shù)據(jù)進(jìn)行歸并處理,比如按照時(shí)間戳/全局id進(jìn)行排序歸并。
EventStore設(shè)計(jì)
目前僅實(shí)現(xiàn)了Memory內(nèi)存模式,后續(xù)計(jì)劃增加本地file存儲(chǔ),mixed混合模式。 借鑒了Disruptor的RingBuffer的實(shí)現(xiàn)思路
RingBuffer設(shè)計(jì):
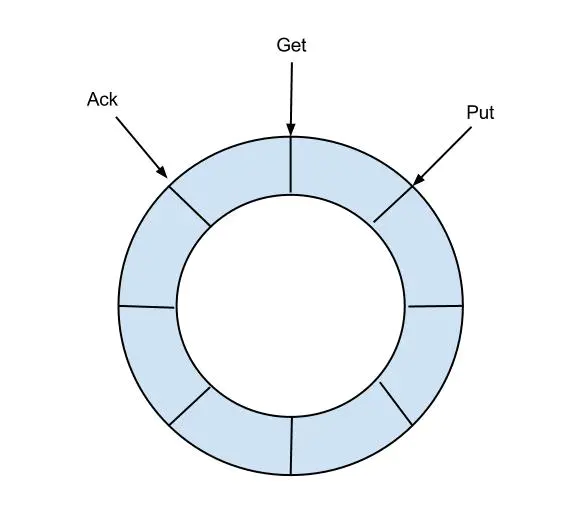
定義了3個(gè)cursor
Put : Sink模塊進(jìn)行數(shù)據(jù)存儲(chǔ)的最后一次寫入位置 Get : 數(shù)據(jù)訂閱獲取的最后一次提取位置 Ack : 數(shù)據(jù)消費(fèi)成功的最后一次消費(fèi)位置
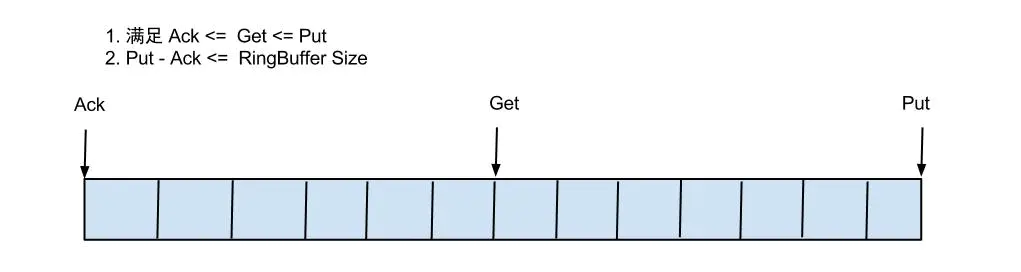
借鑒Disruptor的RingBuffer的實(shí)現(xiàn),將RingBuffer拉直來看:
實(shí)現(xiàn)說明:
Put/Get/Ack cursor用于遞增,采用long型存儲(chǔ)buffer的get操作,通過取余或者與操作。(與操作:cusor & (size - 1) , size需要為2的指數(shù),效率比較高)
HA機(jī)制設(shè)計(jì)
canal的ha分為兩部分,canal server和canal client分別有對應(yīng)的ha實(shí)現(xiàn)
canal server: 為了減少對mysql dump的請求,不同server上的instance要求同一時(shí)間只能有一個(gè)處于running,其他的處于standby狀態(tài). canal client: 為了保證有序性,一份instance同一時(shí)間只能由一個(gè)canal client進(jìn)行g(shù)et/ack/rollback操作,否則客戶端接收無法保證有序。
整個(gè)HA機(jī)制的控制主要是依賴了zookeeper的幾個(gè)特性,watcher和EPHEMERAL節(jié)點(diǎn)(和session生命周期綁定),可以看下我之前zookeeper的相關(guān)文章。
Canal Server:
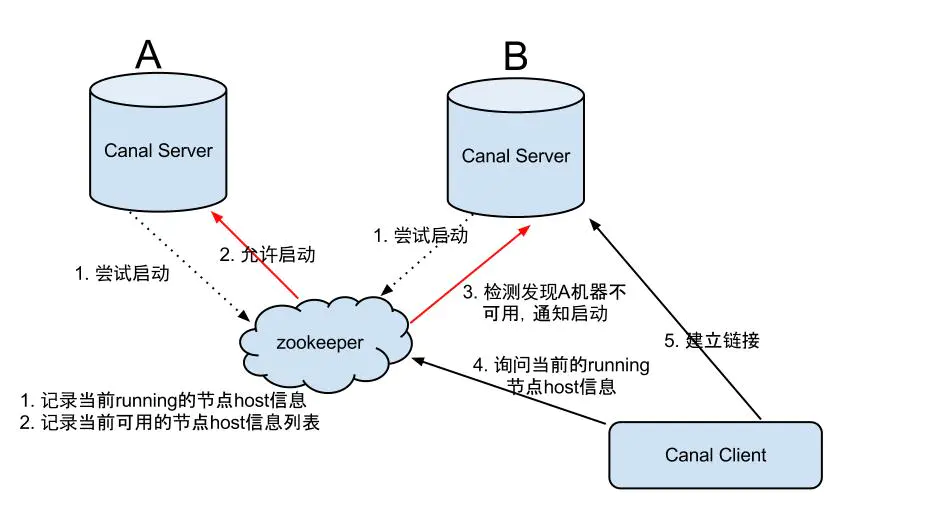
大致步驟:
canal server要啟動(dòng)某個(gè)canal instance時(shí)都先向zookeeper進(jìn)行一次嘗試啟動(dòng)判斷 (實(shí)現(xiàn):創(chuàng)建EPHEMERAL節(jié)點(diǎn),誰創(chuàng)建成功就允許誰啟動(dòng)) 創(chuàng)建zookeeper節(jié)點(diǎn)成功后,對應(yīng)的canal server就啟動(dòng)對應(yīng)的canal instance,沒有創(chuàng)建成功的canal instance就會(huì)處于standby狀態(tài) 一旦zookeeper發(fā)現(xiàn)canal server A創(chuàng)建的節(jié)點(diǎn)消失后,立即通知其他的canal server再次進(jìn)行步驟1的操作,重新選出一個(gè)canal server啟動(dòng)instance canal client每次進(jìn)行connect時(shí),會(huì)首先向zookeeper詢問當(dāng)前是誰啟動(dòng)了canal instance,然后和其建立鏈接,一旦鏈接不可用,會(huì)重新嘗試connect
Canal Client的方式和canal server方式類似,也是利用zookeeper的搶占EPHEMERAL節(jié)點(diǎn)的方式進(jìn)行控制。
本文發(fā)自微信公眾號《import_bigdata》
總結(jié)
CDC 的技術(shù)方案非常多,目前業(yè)界主流的實(shí)現(xiàn)機(jī)制可以分為兩種:
基于查詢的 CDC:
離線調(diào)度查詢作業(yè),批處理。把一張表同步到其他系統(tǒng),每次通過查詢?nèi)カ@取表中最新的數(shù)據(jù); 無法保障數(shù)據(jù)一致性,查的過程中有可能數(shù)據(jù)已經(jīng)發(fā)生了多次變更; 不保障實(shí)時(shí)性,基于離線調(diào)度存在天然的延遲。
基于日志的 CDC:
實(shí)時(shí)消費(fèi)日志,流處理,例如 MySQL 的 binlog 日志完整記錄了數(shù)據(jù)庫中的變更,可以把 binlog 文件當(dāng)作流的數(shù)據(jù)源; 保障數(shù)據(jù)一致性,因?yàn)?binlog 文件包含了所有歷史變更明細(xì); 保障實(shí)時(shí)性,因?yàn)轭愃?binlog 的日志文件是可以流式消費(fèi)的,提供的是實(shí)時(shí)數(shù)據(jù)。
對比常見的開源 CDC 方案,我們可以發(fā)現(xiàn):
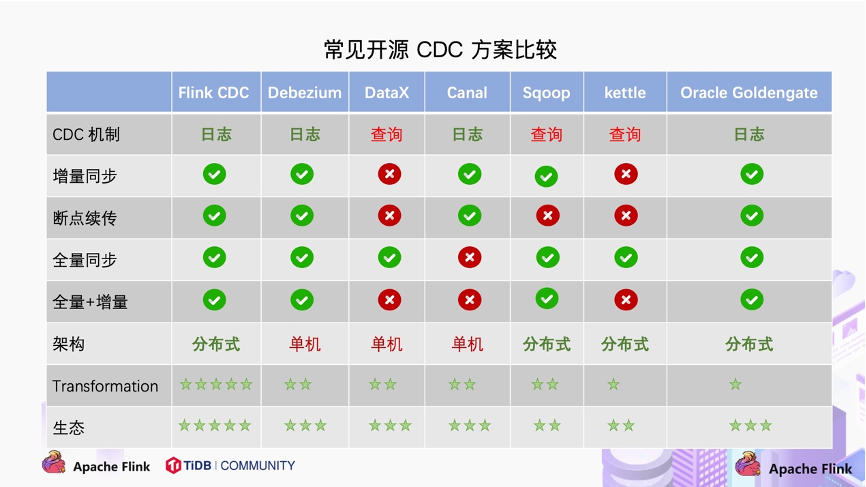
對比增量同步能力:
- 基于日志的方式,可以很好的做到增量同步;
- 而基于查詢的方式是很難做到增量同步的。對比全量同步能力,基于查詢或者日志的 CDC 方案基本都支持,除了 Canal。
而對比全量 + 增量同步的能力,只有 Flink CDC、Debezium、Oracle Goldengate 支持較好。
從架構(gòu)角度去看,該表將架構(gòu)分為單機(jī)和分布式,這里的分布式架構(gòu)不單純體現(xiàn)在數(shù)據(jù)讀取能力的水平擴(kuò)展上,更重要的是在大數(shù)據(jù)場景下分布式系統(tǒng)接入能力。例如 Flink CDC 的數(shù)據(jù)入湖或者入倉的時(shí)候,下游通常是分布式的系統(tǒng),如 Hive、HDFS、Iceberg、Hudi 等,那么從對接入分布式系統(tǒng)能力上看,F(xiàn)link CDC 的架構(gòu)能夠很好地接入此類系統(tǒng)。
在數(shù)據(jù)轉(zhuǎn)換 / 數(shù)據(jù)清洗能力上,當(dāng)數(shù)據(jù)進(jìn)入到 CDC 工具的時(shí)候是否能較方便的對數(shù)據(jù)做一些過濾或者清洗,甚至聚合?
在 Flink CDC 上操作相當(dāng)簡單,可以通過 Flink SQL 去操作這些數(shù)據(jù); 但是像 DataX、Debezium 等則需要通過腳本或者模板去做,所以用戶的使用門檻會(huì)比較高。
另外,在生態(tài)方面,這里指的是下游的一些數(shù)據(jù)庫或者數(shù)據(jù)源的支持。Flink CDC 下游有豐富的 Connector,例如寫入到 TiDB、MySQL、Pg、HBase、Kafka、ClickHouse 等常見的一些系統(tǒng),也支持各種自定義 connector。

八千里路云和月 | 從零到大數(shù)據(jù)專家學(xué)習(xí)路徑指南
我們在學(xué)習(xí)Flink的時(shí)候,到底在學(xué)習(xí)什么?
193篇文章暴揍Flink,這個(gè)合集你需要關(guān)注一下
Flink生產(chǎn)環(huán)境TOP難題與優(yōu)化,阿里巴巴藏經(jīng)閣YYDS
Flink CDC我吃定了耶穌也留不住他!| Flink CDC線上問題小盤點(diǎn)
我們在學(xué)習(xí)Spark的時(shí)候,到底在學(xué)習(xí)什么?
在所有Spark模塊中,我愿稱SparkSQL為最強(qiáng)!
硬剛Hive | 4萬字基礎(chǔ)調(diào)優(yōu)面試小總結(jié)
4萬字長文 | ClickHouse基礎(chǔ)&實(shí)踐&調(diào)優(yōu)全視角解析
【面試&個(gè)人成長】2021年過半,社招和校招的經(jīng)驗(yàn)之談
大數(shù)據(jù)方向另一個(gè)十年開啟 |《硬剛系列》第一版完結(jié)
我寫過的關(guān)于成長/面試/職場進(jìn)階的文章
當(dāng)我們在學(xué)習(xí)Hive的時(shí)候在學(xué)習(xí)什么?「硬剛Hive續(xù)集」
你好,我是王知無,一個(gè)大數(shù)據(jù)領(lǐng)域的硬核原創(chuàng)作者。
做過后端架構(gòu)、數(shù)據(jù)中間件、數(shù)據(jù)平臺(tái)&架構(gòu)、算法工程化。
專注大數(shù)據(jù)領(lǐng)域?qū)崟r(shí)動(dòng)態(tài)&技術(shù)提升&個(gè)人成長&職場進(jìn)階,歡迎關(guān)注。