
如何完善Redis監(jiān)控告警?


本文字?jǐn)?shù):3940字
預(yù)計(jì)閱讀時(shí)間:20分鐘
一、背景 二、監(jiān)控指標(biāo)分類 三、監(jiān)控指標(biāo)說明 四、總結(jié)
一、背景
Redis監(jiān)控告警實(shí)踐是基于開發(fā)CacheCloud云平臺過程中不斷實(shí)踐和總結(jié)出來,隨著Redis實(shí)例規(guī)模不斷變大,會遇到各種各樣的問題,這就需要一套完善的監(jiān)控報(bào)警機(jī)制來幫助我們快速定位問題以及開發(fā)運(yùn)維。
當(dāng)我們在開發(fā)使用Redis的過程中,你是否會遇到這些問題?
問題1:Redis內(nèi)存何時(shí)需要擴(kuò)容? 問題2:Redis客戶端流量和異常如何采集監(jiān)控? 問題3:Redis實(shí)例需要消耗哪些系統(tǒng)資源? 問題4:Redis實(shí)例運(yùn)行狀態(tài)是否正常? 問題5:Redis集群在機(jī)器故障期間是否能保證故障轉(zhuǎn)移成功?
那么將從上面這些問題出發(fā),分享在開發(fā)過程中如何完善Redis的監(jiān)控告警。
二、監(jiān)控指標(biāo)分類
Redis是一種基于key-value的Nosql數(shù)據(jù)庫,會將所有數(shù)據(jù)都存放在內(nèi)存中,所以想全面監(jiān)控Redis指標(biāo)需要考慮到影響它的內(nèi)外因素,比如像客戶端連接數(shù)、OPS、是否有熱點(diǎn)key或bigkey、CPU競爭、宿主環(huán)境磁盤IO壓力、集群實(shí)例分布等等。那么先從上面幾個(gè)問題入手,來分析Redis監(jiān)控指標(biāo)的幾個(gè)方面:
1).Redis內(nèi)部指標(biāo) 2).客戶端采集指標(biāo) 3).宿主/容器環(huán)境指標(biāo) 4).實(shí)例運(yùn)行狀態(tài)指標(biāo) 5).集群拓?fù)渲笜?biāo)
問題1:Redis內(nèi)存何時(shí)需要擴(kuò)容?
這里首先需要了解Redis內(nèi)部指標(biāo)有哪些,通過info all可以獲取到關(guān)于實(shí)例客戶端、內(nèi)存使用、運(yùn)行數(shù)據(jù)統(tǒng)計(jì)、持久化信息、命令統(tǒng)計(jì)、集群信息統(tǒng)計(jì)等,下圖只展示了部分模塊的指標(biāo),詳細(xì)指標(biāo)說明參見3.1 Redis info指標(biāo)。
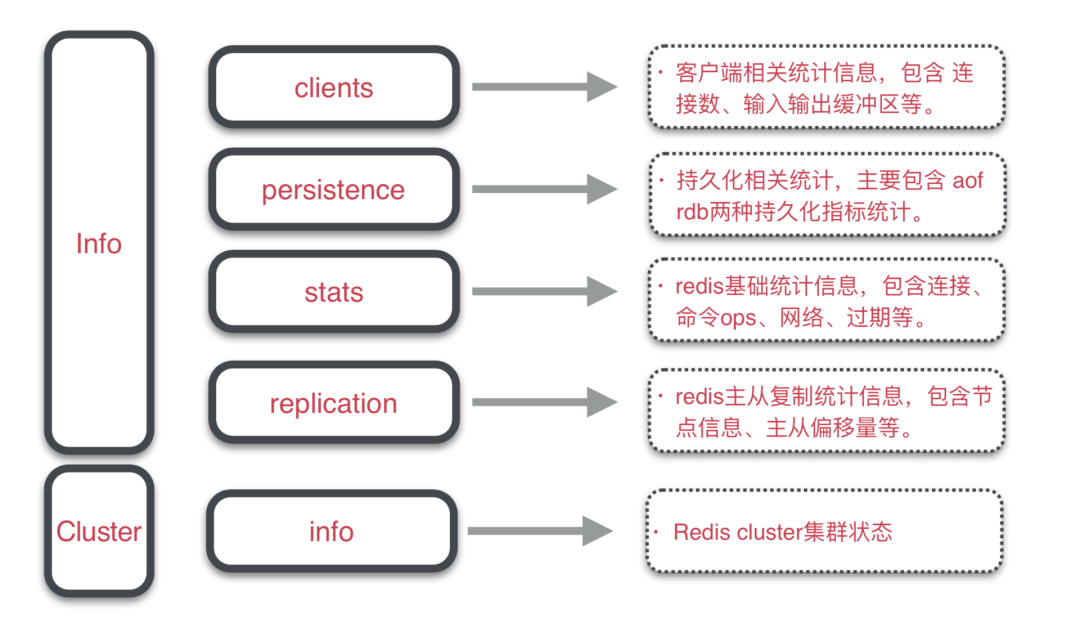
其中當(dāng)前對Redis內(nèi)部指標(biāo)重點(diǎn)監(jiān)控指標(biāo)有:
| 序號 | 配置名 | 配置說明 | 關(guān)系 | 閾值 |
|---|---|---|---|---|
| 1 | aof_current_size | aof當(dāng)前尺寸(單位:MB) | 大于 | 6000 |
| 2 | aof_delayed_fsync | 分鐘aof阻塞個(gè)數(shù) | 大于 | 3 |
| 3 | client_biggest_input _buf | 輸入緩沖區(qū)最大buffer大小(單位:MB) | 大于 | 10 |
| 4 | client_longest_output_list | 輸出緩沖區(qū)最大隊(duì)列長度 | 大于 | 50000 |
| 5 | instantaneous_ops_per_sec | 實(shí)時(shí)ops | 大于 | 60000 |
| 6 | latest_fork_usec | 上次fork所用時(shí)間(單位:微秒) | 大于 | 400000 |
| 7 | mem_fragmentation_ratio | 內(nèi)存碎片率(檢測大于500MB) | 大于 | 1.5 |
| 8 | rdb_last_bgsave_status | 上一次bgsave狀態(tài) | 不等于 | ok |
| 9 | total_net_output_bytes | 分鐘網(wǎng)絡(luò)輸出流量(單位:MB) | 大于 | 5000 |
| 10 | total_net_input_bytes | 分鐘網(wǎng)絡(luò)輸入流量(單位:MB) | 大于 | 1200 |
| 11 | sync_partial_err | 分鐘部分復(fù)制失敗次數(shù) | 大于 | 0 |
| 12 | sync_partial_ok | 分鐘部分復(fù)制成功次數(shù) | 大于 | 0 |
| 13 | sync_full | 分鐘全量復(fù)制執(zhí)行次數(shù) | 大于 | 0 |
| 14 | rejected_connections | 分鐘拒絕連接數(shù) | 大于 | 400000 |
| 15 | master_slave_offset_diff | 主從節(jié)點(diǎn)偏移量差(單位:字節(jié)) | 大于 | 20000000 |
| 16 | cluster_state | 集群狀態(tài) | 不等于 | ok |
| 17 | cluster_slots_ok | 集群成功分配槽個(gè)數(shù) | 不等于 | 16384 |
| 18 | used_memory_precent | 內(nèi)存使用率 | 大于 | 80% |
那么對于Redis內(nèi)存何時(shí)需要擴(kuò)容,需要看那些指標(biāo)呢?
此時(shí)先檢查info memory指標(biāo),其中maxmemory指的是當(dāng)前Redis最大使用內(nèi)存,一旦使用內(nèi)存used_memory>maxmemory限制達(dá)到的時(shí)候,Redis會根據(jù)配置的maxmemory-policy策略來對鍵進(jìn)行回收,如果策略配置不對可能會導(dǎo)致客戶端調(diào)用出現(xiàn)OOM的報(bào)錯(cuò).
因此我們對Redis實(shí)例的內(nèi)存使用率監(jiān)控閾值默認(rèn)設(shè)置在80%,超過閾值則會郵件提醒管理員,以保證提前發(fā)現(xiàn)應(yīng)用對內(nèi)存需求增長的需求。這里展示了線上的某一個(gè)實(shí)例當(dāng)前內(nèi)存使用情況和內(nèi)存回收策略:
1).當(dāng)前實(shí)例內(nèi)存使用情況
127.0.0.1:6470> info memory
# Memory
used_memory:6441145376
used_memory_human:6.00G
used_memory_rss:6622314496
used_memory_rss_human:6.17G
used_memory_peak:6442453200
used_memory_peak_human:6.00G
used_memory_peak_perc:99.98%
maxmemory:6442450944
maxmemory_human:6.00G
...
2).淘汰策略: 在有過期鍵的集合中嘗試回收最少使用的鍵(LRU)
config get maxmemory-policy
1) "maxmemory-policy"
2) "volatile-lru"
3).統(tǒng)計(jì)當(dāng)前實(shí)例過期的key數(shù)量和驅(qū)逐的key的數(shù)量
127.0.0.1:6470> info stats
# Stats
...
expired_keys:19125
evicted_keys:1120問題2:Redis客戶端流量和異常如何采集監(jiān)控?
這里需要定制統(tǒng)一客戶端SDK,通過SDK埋點(diǎn)采集用戶Redis調(diào)用統(tǒng)計(jì)和異常信息,方便從客戶端視角定位問題,形成Redis發(fā)現(xiàn)問題并響應(yīng)解決的持續(xù)運(yùn)維流。
1).從客戶端視角主要指標(biāo)說明如下:
客戶端命令調(diào)用統(tǒng)計(jì): 基礎(chǔ)字段:收集時(shí)間(collectTime)、客戶端IP(client)、應(yīng)用(appId); 命令字段:命令(command)、調(diào)用量(count)、 輸入/輸出流量(input/output)、累計(jì)毫秒耗時(shí)(costtime); 客戶端異常信息統(tǒng)計(jì): 異常分析可參考:3.2 客戶端異常說明 連接事件: 連接失敗次數(shù)(connectFailedCount)、連接失敗毫秒耗時(shí)(connectFiledTime); 命令調(diào)用: 超時(shí)次數(shù)(latencyCount)、超時(shí)毫秒耗時(shí)(latencyTime)、超時(shí)命令明文(latencyCommands);
2).客戶端上報(bào)數(shù)據(jù)采集過程:
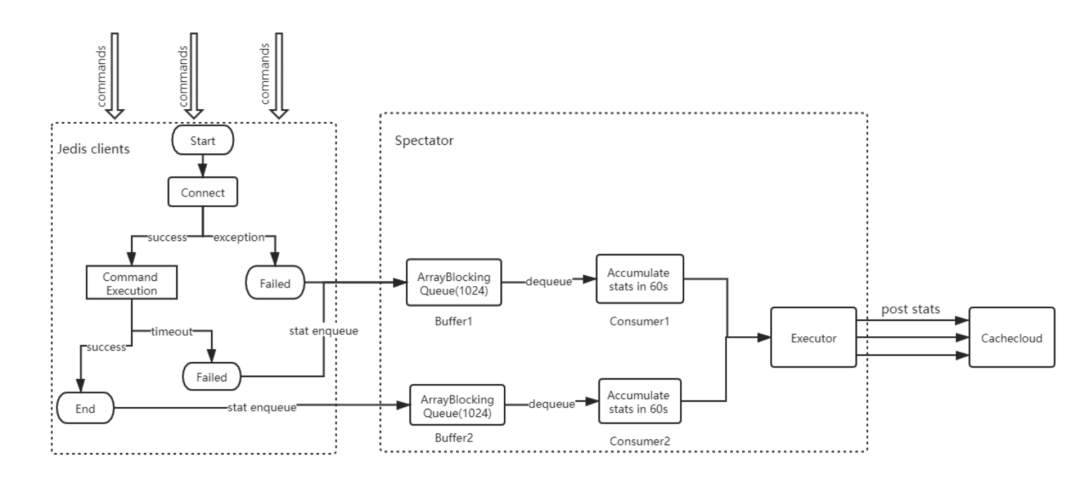
2.1.指標(biāo)采集暫存到隊(duì)列,隊(duì)列大小限制為1024; 2.2.單線程從隊(duì)列取數(shù)據(jù)進(jìn)行消費(fèi),累加一分鐘內(nèi)的指標(biāo); 2.3.單獨(dú)線程池負(fù)責(zé)發(fā)送HTTP請求,上報(bào)指標(biāo)到服務(wù)端; 2.4.通過收集到數(shù)據(jù)繪制實(shí)例圖表曲線和數(shù)據(jù)表格匯總;
如下圖統(tǒng)計(jì)了所有應(yīng)用客戶端指標(biāo)數(shù)據(jù)(按天匯總),這樣就能快速發(fā)現(xiàn)到系統(tǒng)中存在的調(diào)用異常的應(yīng)用,通過收集到數(shù)據(jù)快速發(fā)現(xiàn)問題。
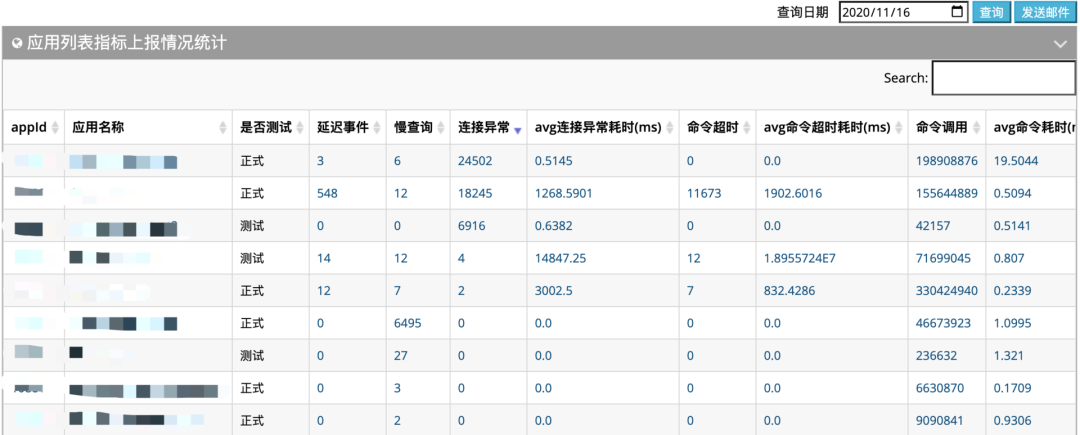
問題3:Redis實(shí)例需要消耗哪些系統(tǒng)資源?
Redis實(shí)例是以進(jìn)程為單位運(yùn)行在宿主環(huán)境上,系統(tǒng)資源消耗和實(shí)例的穩(wěn)定運(yùn)行有著重要的聯(lián)系,例如進(jìn)程間存在cpu競爭、磁盤IO壓力大或是網(wǎng)卡阻塞都會影響Redis性能,所以需要對宿主環(huán)境資源做好資源監(jiān)控:
| 序號 | 指標(biāo)類型 | 級別 | 說明 |
|---|---|---|---|
| 1 | cpu限制時(shí)長 | 容器 | 容器cpu限制時(shí)長top10監(jiān)控 |
| 2 | cpu使用率 | 容器 | 容器cpu使用率top10監(jiān)控 |
| 3 | RSS內(nèi)存 | 容器 | 容器內(nèi)存閾值的85%,防止出現(xiàn)oomkiier |
| 4 | 磁盤IO | 宿主機(jī) | 診斷磁盤讀寫壓力 |
| 5 | 網(wǎng)絡(luò)流量 | 宿主機(jī) | 診斷網(wǎng)絡(luò)流量是否異常 |
| 6 | 磁盤空間 | 宿主機(jī) | 診斷磁盤空間否充足 |
| 7 | 宿主機(jī)器運(yùn)行時(shí)間 | 宿主機(jī) | 診斷宿主機(jī)器是否故障 |
下圖通過grafana展示了關(guān)于容器和宿主環(huán)境監(jiān)控指標(biāo)曲線,通過對關(guān)鍵指標(biāo)使用率監(jiān)控能夠快速找到可能發(fā)生問題容器和宿主信息。
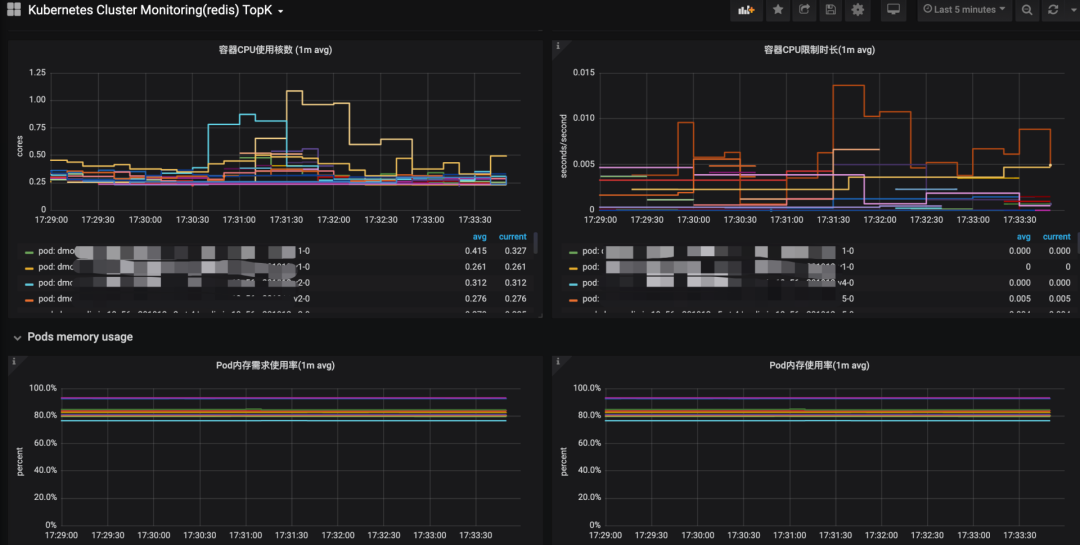
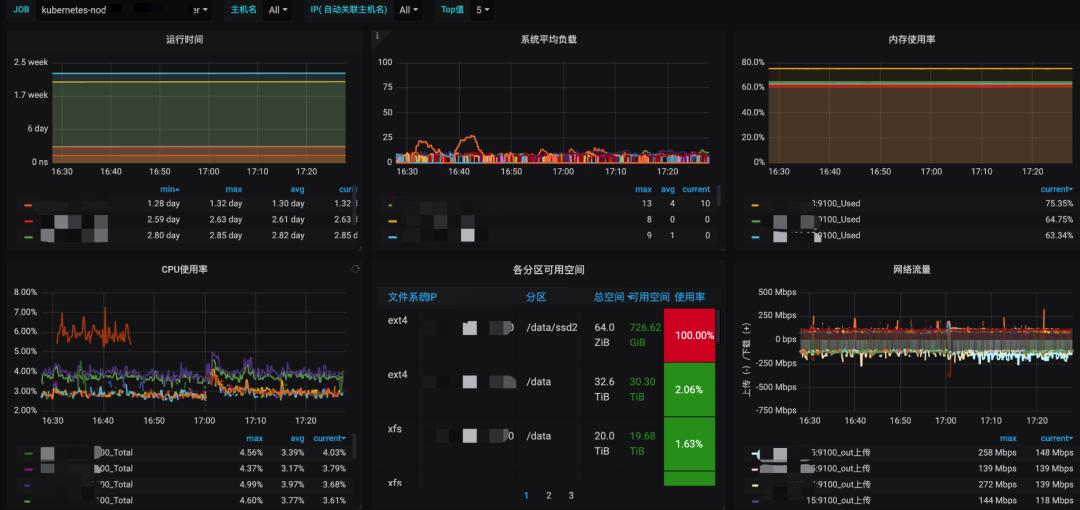
問題4:Redis實(shí)例運(yùn)行狀態(tài)是否正常?
Redis實(shí)例大多是運(yùn)行在容器里的,一旦容器掛起或?qū)嵗L時(shí)間阻塞就會影響服務(wù)調(diào)用,所以需要對容器或?qū)嵗倪\(yùn)行狀態(tài)做好近實(shí)時(shí)監(jiān)控。
| 序號 | 指標(biāo)類型 | 含義 | 監(jiān)控周期 |
|---|---|---|---|
| 1 | Redis實(shí)例狀態(tài) | 0:心跳停止 1:運(yùn)行中 2:下線 3:永久下線 | 每1分鐘 |
| 2 | Pod狀態(tài) | 0:下線 1:上線 | 回調(diào)接口通知 |
Redis實(shí)例狀態(tài): 通過后臺定時(shí)任務(wù)探測所有在線運(yùn)行的實(shí)例,檢測發(fā)現(xiàn)響應(yīng)異常實(shí)例會以郵件形式通知管理員; Pod狀態(tài): 下線:通過回調(diào)接口以郵件形式通知系統(tǒng)哪些Pod不可用; 上線:通過回調(diào)接口以郵件形式通知恢復(fù)&自動拉起實(shí)例列表;
問題5:Redis集群故障期間是否能保證故障轉(zhuǎn)移成功?
在平時(shí)使用Redis集群(例如RedisSentinel/RedisCluster)過程中,機(jī)器可能會出現(xiàn)宕機(jī)、重啟等情況,如果集群中部分實(shí)例分布在故障機(jī)器上就會導(dǎo)致實(shí)例無法服務(wù),一旦集群實(shí)例拓?fù)浞植籍惓>蜁?dǎo)致集群故障轉(zhuǎn)移失敗,從而影響整體集群可用性。
| 序號 | 類型 | 含義 |
|---|---|---|
| 1 | Redis Sentinel集群 | 診斷集群拓?fù)涫欠癞惓?/td> |
| 2 | Redis Cluster集群 | 診斷集群拓?fù)涫欠癞惓?/td> |
Redis Sentinel集群拓?fù)湓\斷: sentinel節(jié)點(diǎn)至少分布在3個(gè)及以上物理機(jī); 主從節(jié)點(diǎn)不能分布在同一臺物理機(jī); 主節(jié)點(diǎn)需要有至少一個(gè)從節(jié)點(diǎn); Redis Cluster集群拓?fù)湓\斷: 集群節(jié)點(diǎn)至少分布在3臺物理機(jī)器上; 集群中某一臺容器的宿主機(jī)發(fā)生故障,是否能滿足故障轉(zhuǎn)移; 主節(jié)點(diǎn)需要有從節(jié)點(diǎn);
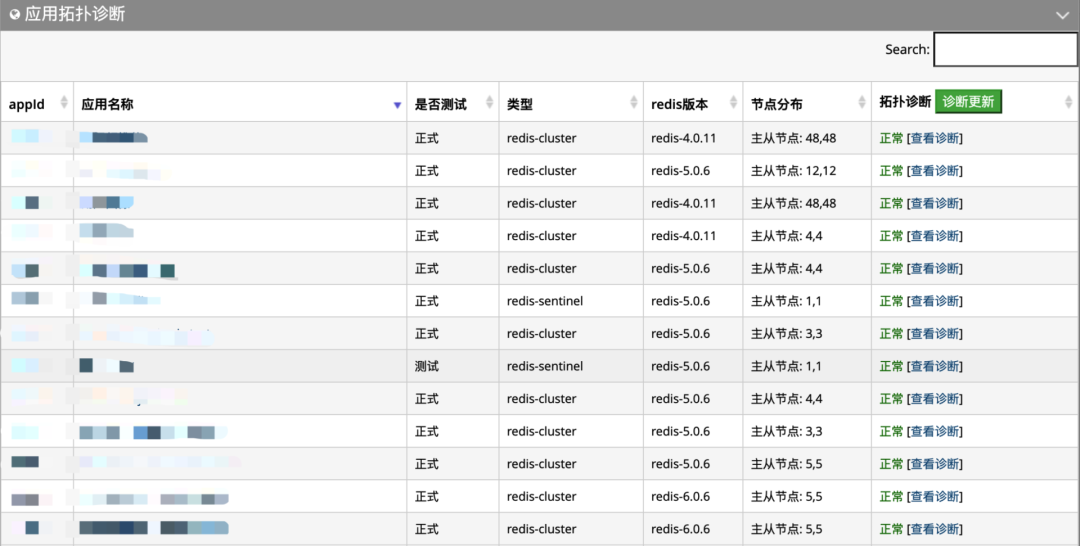
下圖為檢測部分應(yīng)用的拓?fù)湓\斷情況:
三、監(jiān)控指標(biāo)說明
上一節(jié)講述了Redis監(jiān)控指標(biāo)的幾個(gè)方面,下面來詳細(xì)分析指標(biāo)報(bào)警可能產(chǎn)生的原因:
3.1 Redis info指標(biāo)說明
info all命令包含Redis最全的系統(tǒng)狀態(tài)信息,表格列出了涉及到所有模塊,下面分析其中部分模塊的指標(biāo)。
| 序號 | 模塊 | 含義 |
|---|---|---|
| 1 | Clients | 客戶端信息 |
| 2 | Cluster | 集群信息 |
| 3 | Commandstats | 命令統(tǒng)計(jì)信息 |
| 4 | CPU | CPU消耗信息 |
| 5 | Keyspace | 數(shù)據(jù)庫鍵統(tǒng)計(jì)信息 |
| 6 | Memory | 內(nèi)存信息 |
| 7 | Persistence | 持久化信息 |
| 8 | Replication | 復(fù)制信息 |
| 9 | Server | 服務(wù)器信息 |
| 10 | Memory | 統(tǒng)計(jì)信息 |
1).info client模塊:
info client模塊的統(tǒng)計(jì)信息,它包含了連接數(shù)、阻塞命令連接數(shù)、輸入輸出緩沖區(qū)等相關(guān)統(tǒng)計(jì)。
127.0.0.1:6399> info clients
# Clients
connected_clients:300
client_longest_output_list:0
client_biggest_input_buf:0
blocked_clients:0
connected_clients: 統(tǒng)計(jì)當(dāng)前客戶端連接數(shù),報(bào)警閾值>2000個(gè)連接;1).客戶端可能存在連接泄漏問題; 2).客戶端實(shí)例數(shù)增加或客戶端連接池設(shè)置過大; 3).創(chuàng)建集群實(shí)例非單例; client_longest_output_list:當(dāng)前所有輸出緩沖區(qū)中隊(duì)列對象個(gè)數(shù)的最大值,報(bào)警閾值>500;client_biggest_input_buf:輸入緩沖區(qū)最大buffer大小(單位:MB),報(bào)警閾值>10;影響報(bào)警的因素: 1).可能存在bigkey讀寫,阻塞緩沖區(qū); 2).有頻繁批量讀寫操作:hgetall/hkeys、zrange、lrange 、smembers、mget等; 3).開啟monitor直連線上環(huán)境,阻塞服務(wù)端輸入輸出緩沖區(qū);
影響報(bào)警的因素:
2).info persistence模塊:
info Persistence模塊的統(tǒng)計(jì)信息,它包含了RDB和AOF兩種持久化的一些統(tǒng)計(jì)。
127.0.0.1:6399> info persistence
# Persistence
loading:0
rdb_changes_since_last_save:589319695
rdb_bgsave_in_progress:0
rdb_last_save_time:1576117607
rdb_last_bgsave_status:ok
rdb_last_bgsave_time_sec:2
rdb_current_bgsave_time_sec:-1
rdb_last_cow_size:2129920
aof_enabled:1
aof_rewrite_in_progress:0
aof_rewrite_scheduled:0
aof_last_rewrite_time_sec:30
aof_current_rewrite_time_sec:-1
aof_last_bgrewrite_status:ok
aof_last_write_status:ok
aof_last_cow_size:20979712
aof_current_size:1654862653
aof_base_size:1584570244
aof_pending_rewrite:0
aof_buffer_length:0
aof_rewrite_buffer_length:0
aof_pending_bio_fsync:0
aof_delayed_fsync:15
aof_current_size:aof當(dāng)前尺寸(單位:MB),報(bào)警閾值>6000MB;aof_delayed_fsync:分鐘aof阻塞個(gè)數(shù),報(bào)警閾值每分鐘阻塞大于3次;影響報(bào)警的因素: 磁盤有壞道或機(jī)器磁盤性能問題,讀寫速度跟不上; 如果是共享容器,需要檢查宿主環(huán)境下其他進(jìn)程的寫盤情況; 宿主環(huán)境上有較密集實(shí)例進(jìn)行AOF/RDB寫盤操作; rdb_last_bgsave_status:上一次bgsave狀態(tài);影響報(bào)警的因素: 可能由于磁盤空間不足導(dǎo)致寫rdb失敗;
3).info stats
info Stats模塊的統(tǒng)計(jì)信息,它是Redis的基礎(chǔ)統(tǒng)計(jì)信息,包含了:連接、命令、網(wǎng)絡(luò)、過期、同步很多統(tǒng)計(jì)。
127.0.0.1:6399> info stats
# Stats
total_connections_received:5261797
total_commands_processed:9448523137
instantaneous_ops_per_sec:1560
total_net_input_bytes:1307208851742
total_net_output_bytes:5338907609106
instantaneous_input_kbps:68.02
instantaneous_output_kbps:137.20
rejected_connections:0
sync_full:3
sync_partial_ok:1
sync_partial_err:3
expired_keys:7984396
expired_stale_perc:0.10
expired_time_cap_reached_count:0
evicted_keys:0
keyspace_hits:3477205762
keyspace_misses:5308763830
pubsub_channels:0
pubsub_patterns:0
latest_fork_usec:114520
migrate_cached_sockets:0
slave_expires_tracked_keys:0
...
total_net_output_bytes:分鐘網(wǎng)絡(luò)輸出流量(單位:MB),報(bào)警閾值>2500;total_net_input_bytes:分鐘網(wǎng)絡(luò)輸入流量(單位:MB),報(bào)警閾值>1200;影響報(bào)警的因素: 客戶端整體調(diào)用量OPS較高; 可能存在大對象頻繁的讀寫操作; 實(shí)例可能存在較大流量熱點(diǎn)key; latest_fork_usec:上次fork所用時(shí)間(單位:微秒),報(bào)警閾值>600000;影響報(bào)警的因素: Redis內(nèi)存分片較大,需要控制分片內(nèi)存的大小; 物理內(nèi)存不足導(dǎo)致fork失敗; 宿主環(huán)境thp關(guān)閉,拷貝內(nèi)存頁時(shí)間較長; sync_full:分鐘全量復(fù)制執(zhí)行次數(shù),報(bào)警閾值>0次;sync_partial_ok:分鐘部分復(fù)制成功次數(shù),,報(bào)警閾值>0次;影響報(bào)警的因素: 主動發(fā)起主從failover,從節(jié)點(diǎn)發(fā)起全量復(fù)制(采用psync2協(xié)議可保證增量復(fù)制); 添加從節(jié)點(diǎn)會發(fā)起全量復(fù)制; 網(wǎng)絡(luò)問題導(dǎo)致復(fù)制積壓緩沖區(qū)不足;
4).info replication
info Replication模塊的統(tǒng)計(jì)信息,它包含了Redis主從復(fù)制的一些統(tǒng)計(jì)。
127.0.0.1:6399> info replication
# Replication
role:master
connected_slaves:1
slave0:ip=x.x.x.x,port=6387,state=online,offset=4764522381799,lag=1
master_replid:ac5d8f6938d752f8f6d453a9841b2a4ed261bcfb
master_replid2:82ab36d6a6f7059757b96c83337f4a6132597e1a
master_repl_offset:4764522381799
second_repl_offset:3823758361609
repl_backlog_active:1
repl_backlog_size:10000000
repl_backlog_first_byte_offset:4764512381800
repl_backlog_histlen:10000000
repl_backlog_size:緩沖區(qū)最大長度,報(bào)警閾值>10MB;master_slave_offset_diff:主從節(jié)點(diǎn)偏移量差(單位:字節(jié)),報(bào)警閾值>10MB;影響報(bào)警的因素: 機(jī)器網(wǎng)絡(luò)出現(xiàn)延遲; 主節(jié)點(diǎn)寫操作過于頻繁;
5).info cpu模塊:
127.0.0.1:6399> info cpu
# CPU
used_cpu_sys:156315.03
used_cpu_user:78421.15
used_cpu_sys_children:5608.28
used_cpu_user_children:19055.72
used_cpu_sys:Redis主進(jìn)程在內(nèi)核態(tài)所占用的CPU時(shí)長累加;used_cpu_user:Redis主進(jìn)程在用戶態(tài)所占用的CPU時(shí)長累加;used_cpu_sys_children:子進(jìn)程在內(nèi)核態(tài)所占用的CPU時(shí)長累加;used_cpu_user_children:子進(jìn)程在用戶態(tài)所占用的CPU時(shí)長累加;
如果主進(jìn)程在內(nèi)核態(tài)單位時(shí)間內(nèi)累計(jì)CPU時(shí)長較長,說明主進(jìn)程很繁忙,客戶端就有可能出現(xiàn)阻塞或響應(yīng)慢的情況。
3.2 客戶端異常指標(biāo)說明
目前客戶端的sdk主要用的是Jedis客戶端,這里主要說明關(guān)于Jedis客戶端異常信息:
異常信息1:JedisConnectionException: Could not get a resource from the pool` (1) 連接池存在泄露,直到耗盡連接; (2) 業(yè)務(wù)調(diào)用量增長很快,連接池最大連接數(shù)設(shè)置過小; (3) 有慢查詢或者Redis發(fā)生阻塞; 異常信息2:java.net.SocketTimeoutException: Read timed out (1) 讀寫超時(shí)設(shè)置的過短; (2) 有慢查詢或者Redis發(fā)生阻塞; (3) 網(wǎng)絡(luò)不穩(wěn)定; 異常信息3:JedisDataException: ERR max number of clients reached 客戶端連接數(shù)超過了Redis實(shí)例配置的最大maxclients(默認(rèn)值10000); 異常信息4:JedisDataException: LOADING Redis is loading the dataset in memory 客戶端調(diào)用Redis時(shí),如果Redis正在加載持久化文件,無法進(jìn)行正常的讀寫; 異常信息5:JedisDataException: NOAUTH Authentication required 客戶端調(diào)用Redis時(shí),未傳入密碼;
四、總結(jié)
對于任何服務(wù),系統(tǒng)監(jiān)控告警對服務(wù)質(zhì)量起著至關(guān)重要的作用,關(guān)于Redis監(jiān)控報(bào)警總結(jié)如下:
對于客戶端:
SDK集成和使用簡單; SDK數(shù)據(jù)采集上報(bào)無感知; SDK可用性&穩(wěn)定性保障; 對于服務(wù)端:
內(nèi)部監(jiān)控:Redis內(nèi)部指標(biāo)/客戶端指標(biāo)告警快速定位&解決; 外部監(jiān)控:宿主環(huán)境資源/集群拓?fù)湓\斷快速遷移&修復(fù); 資源使用:合理分配容器實(shí)例數(shù)量以及資源使用率; 故障恢復(fù):能對出現(xiàn)故障的實(shí)例/容器有快速恢復(fù)能力;