
Kudu 實踐 | Apache Kudu 在網(wǎng)易的實踐
本次的分享內(nèi)容分成四個部分:
1.系統(tǒng)概述:認識kudu,理解Kudu的系統(tǒng)設計與定位
2.生產(chǎn)實踐:分享網(wǎng)易內(nèi)部的典型使用場景
3.遇到的問題:實際使用過程中遇到的問題和問題的排障過程
4.功能展望:對Kudu功能特性的展望
Kudu定位與架構(gòu)
Kudu是一個存儲引擎,可以接入Impala、Presto、Spark等Olap計算引擎進行數(shù)據(jù)分析,容易融入Hadoop社區(qū)。Kudu整合了隨機讀寫和大數(shù)據(jù)分析能力,具有低延遲的隨機讀寫能力和高吞吐量的批量查詢能力。
與HBase、Casandra不同,Kudu要求聲明Schema。Schema可以為上層計算引擎提供更多元數(shù)據(jù),進行計算優(yōu)化。Kudu的每個字段有主鍵、列名和列類型。拿到列類型信息后能夠?qū)Σ煌羞M行編碼和壓縮,優(yōu)化存儲空間,減少磁盤開銷。Kudu支持bitshuffle、運行長度編碼、字典編碼等列編碼方式,這些編碼會根據(jù)列的類型不同做不同設計。比如對于重復值多、重復值變化不大的數(shù)據(jù)的壓縮率很好。
Kudu使用列式存儲給Kudu帶來了如下特性:
1. 存儲上可以節(jié)約空間
2. 可以對查詢做更多優(yōu)化,如將過濾條件下推到kudu執(zhí)行,節(jié)約計算資源
3. 支持向量化操作
Kudu的Schema和列存
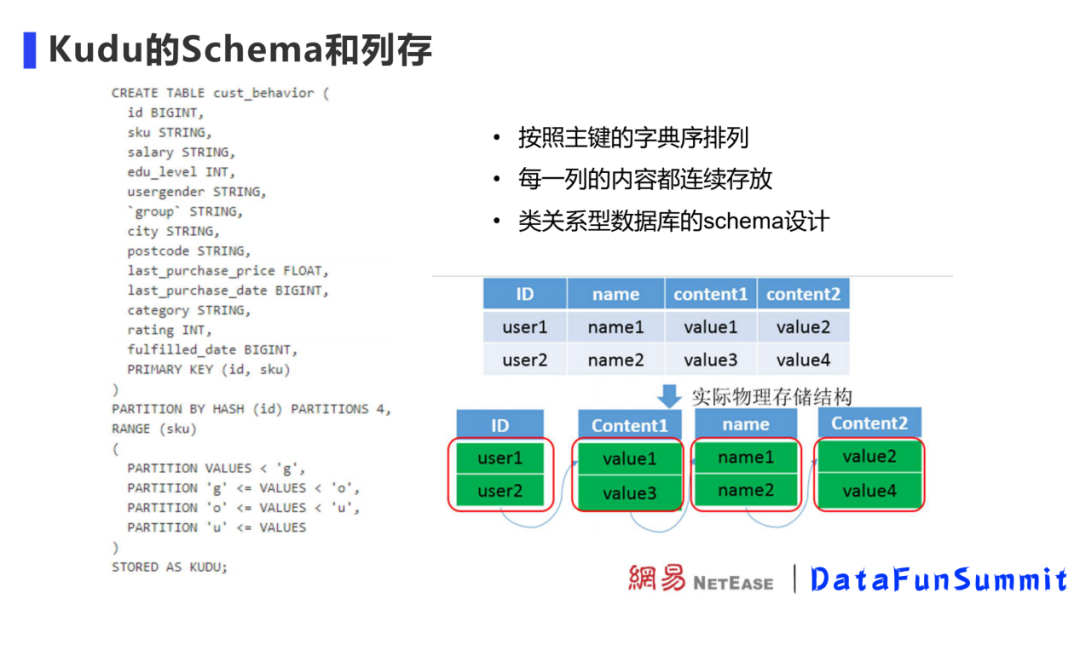
Kudu數(shù)據(jù)存儲在Table中,Tablet是Kudu的讀寫單元,Table內(nèi)的數(shù)據(jù)會劃分到各個Tablet進行管理。
創(chuàng)建Table時,需要指定Table的分區(qū)方式。Kudu 提供了兩種類型的分區(qū)方式range partitioning ( 范圍分區(qū) ) 、 hash partitioning ( 哈希分區(qū) ),這兩種分區(qū)方式可以組合使用。分區(qū)的目的是把Table內(nèi)的數(shù)據(jù)預先定義好分散到指定的片數(shù)量內(nèi),方便Kudu集群均勻?qū)懭霐?shù)據(jù)和查詢數(shù)據(jù)。范圍分區(qū)支持查詢時快速定位數(shù)據(jù),哈希分區(qū)可以在寫入時避免數(shù)據(jù)熱點,可以適應各個場景下的數(shù)據(jù)。
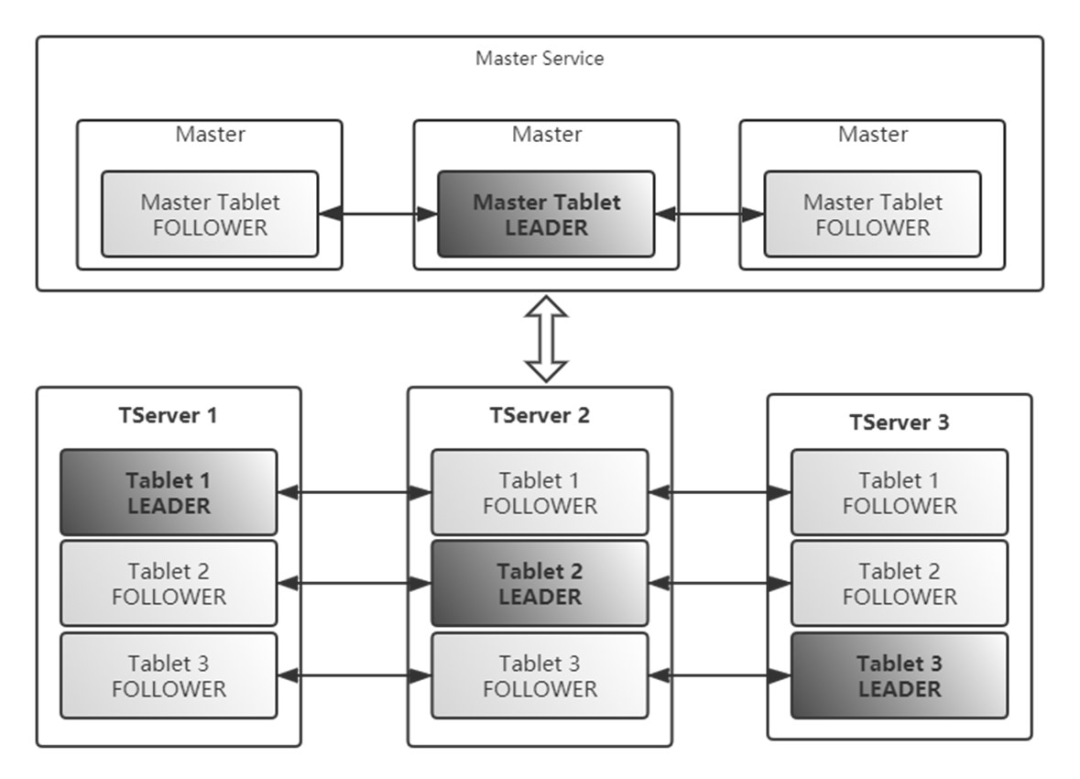
Kudu有管理節(jié)點(Master)和數(shù)據(jù)節(jié)點(Tablet Server)。管理節(jié)點管理元數(shù)據(jù),管理表到分片映射關(guān)系、分片在數(shù)據(jù)節(jié)點內(nèi)的位置的映射關(guān)系,Kudu客戶端最終會直接鏈接數(shù)據(jù)節(jié)點。
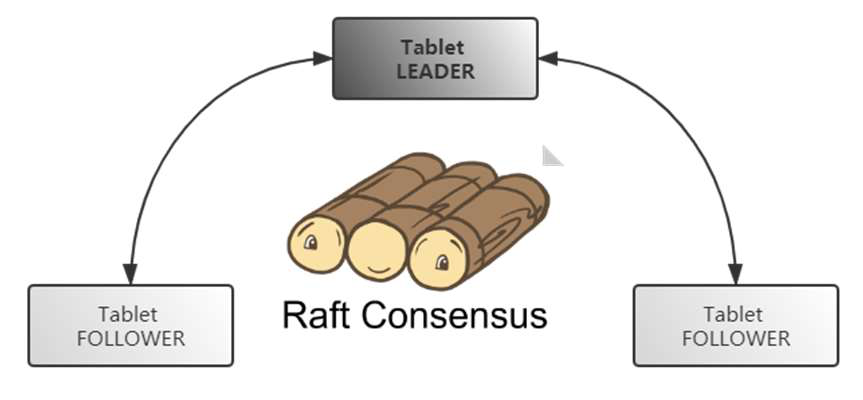
Kudu作為分布式系統(tǒng),為了保障數(shù)據(jù)可用性和高可用,支持多副本。Kudu 使用 Raft 協(xié)議來實現(xiàn)分布式環(huán)境下副本之間的數(shù)據(jù)一致性。Raft算法數(shù)據(jù)不依賴其他存儲和文件系統(tǒng),優(yōu)勢在于可以保證服務高可用、服務可用性、一致性的均衡。
Kudu的update設計
Olap中對update的設計會影響到Olap性能。update操作可能引發(fā)數(shù)據(jù)多版本問題和update引發(fā)的數(shù)據(jù)merge問題。
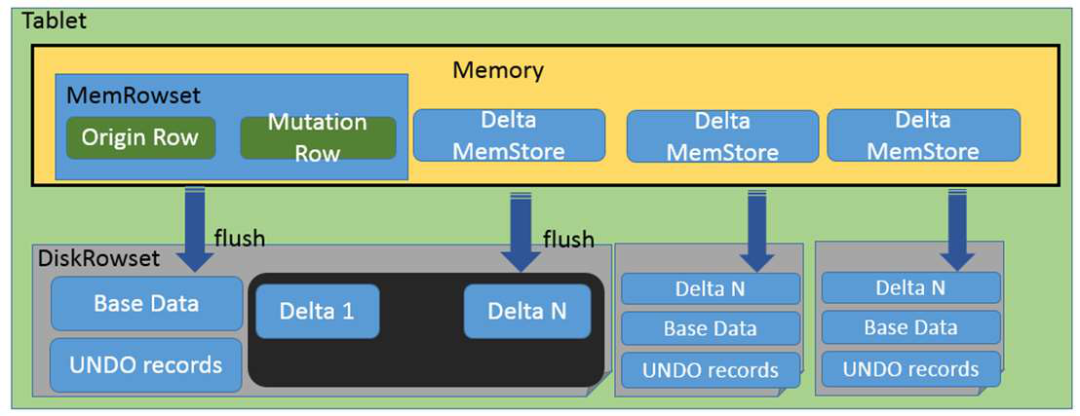
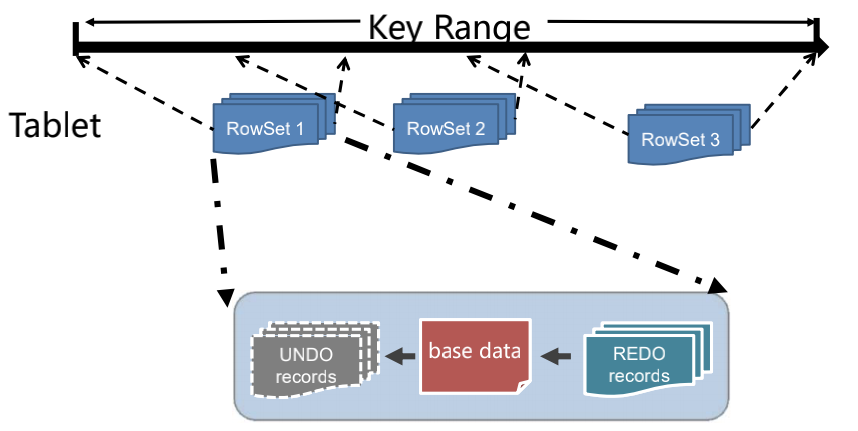
Tablet是Kudu數(shù)據(jù)讀寫單元,Tablet下更細分的數(shù)據(jù)存儲單元是 RowSet。RowSet有兩種, 分別是MemRowSet 和 DiskRowSet,不同RowSet維護了不同組件范圍內(nèi)的數(shù)據(jù)。內(nèi)存中的 MemRowSet 在到達一定大小后會刷盤成為DiskRowSet。

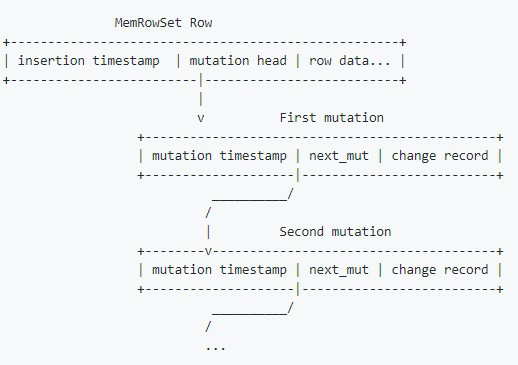
Kudu把更新操作當作一條新操作,而不是寫一條新日志。更新操作是Undo/Redo記錄,這些內(nèi)存中的更新操作會被整合為DeltaMemstore持久化。Base數(shù)據(jù)、Undo數(shù)據(jù)、Redu數(shù)據(jù)寫在同一個RowSet中。這樣的存儲設計優(yōu)點是可以在更新時候快速找到數(shù)據(jù),缺點是查詢時需要確認查詢的主鍵在哪個RowSet位置中。
Kudu也使用了LSM的結(jié)構(gòu)。Kudu的comopaction有多種:MinorDeltaCompaction、MajorDeltaCompaction、MergingCompaction。
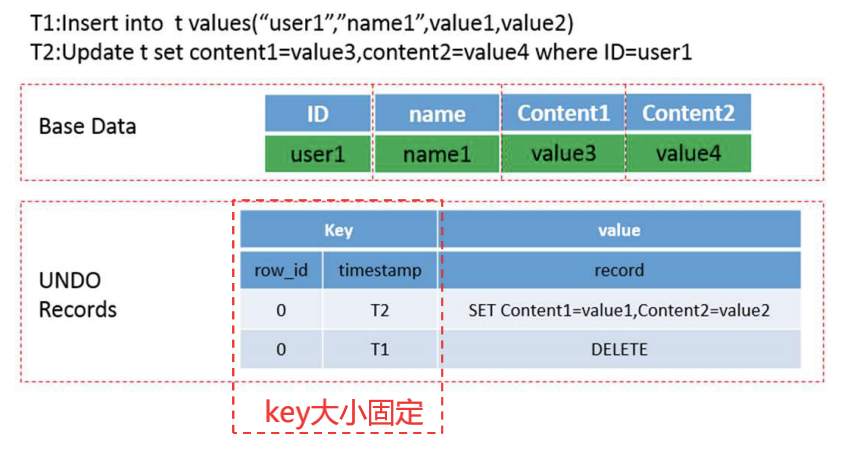
Kudu的update是一個多版本操作,目的是寫入和讀取時互相不干擾、不需要讀時額外加鎖。
小結(jié)
Kudu Update設計特點:
? ** 更新已經(jīng)flush的數(shù)據(jù)和寫入新數(shù)據(jù)走不通的處理邏輯,原始數(shù)據(jù)和更新位于同一個Rowset,不用跨Rowset進行merge**
? **通過base數(shù)據(jù)的RowID和更新時間戳作為REDO/UNDO數(shù)據(jù)的key**,讀取更新高效
? Key大小固定,存儲和比較效率高
? 不需要查詢出主鍵數(shù)據(jù)也能獲取更新數(shù)據(jù)
? 在大多數(shù)使用場景下能夠?qū)崿F(xiàn)更高效的讀取
? 如果返回的結(jié)果不要求順序,直接從RowSet中讀出數(shù)據(jù),不用merge
? 如果更新較少,REDO會快速merge到base數(shù)據(jù),這時在讀取最新數(shù)據(jù)時,可以不進行apply REDO的操作
生產(chǎn)實踐
實時數(shù)據(jù)采集場景
實時數(shù)據(jù)分析中,一些用戶行為數(shù)據(jù)有更新的需求。沒有引入Kudu前,用戶行為數(shù)據(jù)會首先通過流式計算引擎寫入HBase,但HBase不能支撐聚合分析。為了支撐分析和查詢需求,還需要把HBase上的數(shù)據(jù)通過Spark讀取后寫入其他OLAP引擎。使用Kudu后,用戶行為數(shù)據(jù)會通過流式計算引擎寫入Kudu,由Kudu完成數(shù)據(jù)更新操作。Kudu可以支持單點查詢,也可以配合計算引擎做數(shù)據(jù)分析。
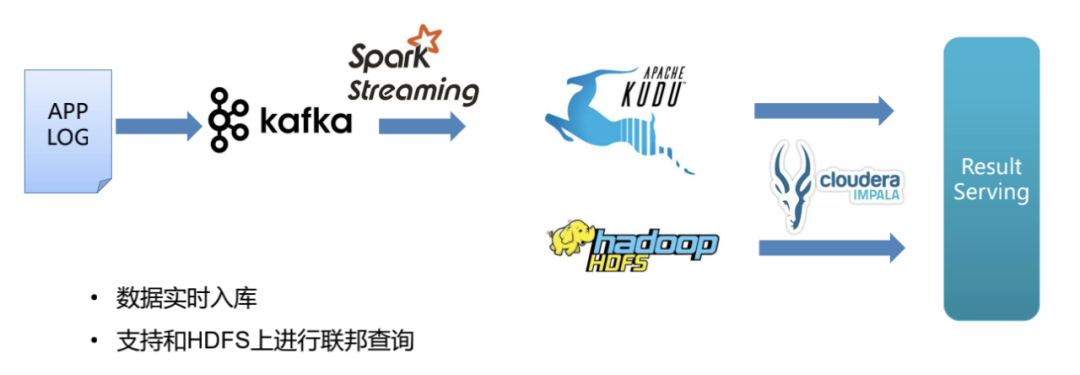
維表數(shù)據(jù)關(guān)聯(lián)應用
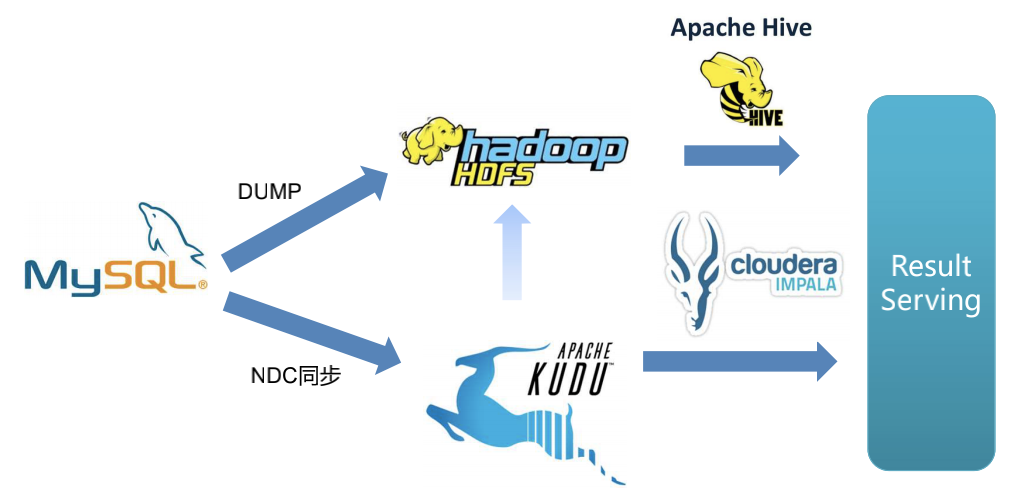
有些場景中,日志的事件表還需要和MySQL內(nèi)維度表做關(guān)聯(lián)后進行查詢。使用Kudu,可以利用NDC同步工具,將MySQL中數(shù)據(jù)實時同步導入Kudu,使Kudu內(nèi)數(shù)據(jù)表和MySQL中的表保持數(shù)據(jù)一致。這時Kudu配合計算引擎就可以直接對外提供結(jié)果數(shù)據(jù),如產(chǎn)生報表和做在線分析等。省去了MySQL中維度表和數(shù)據(jù)合并的一步,大大提升了效率。
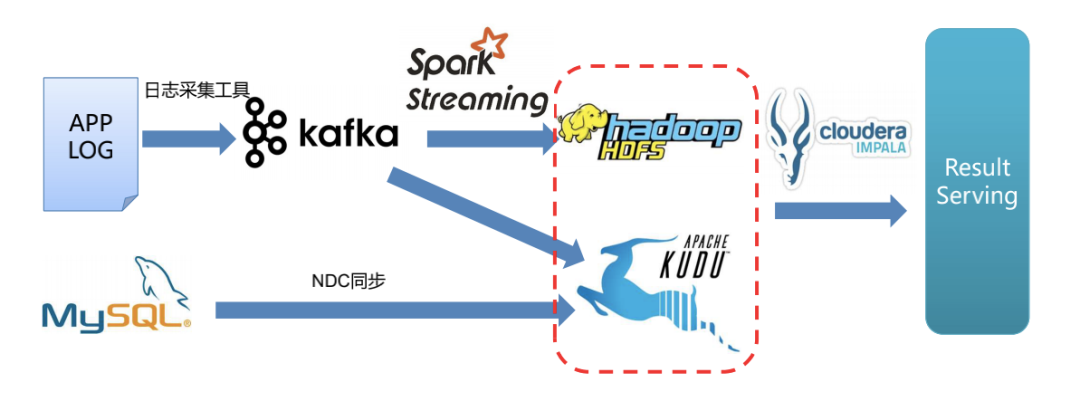
實時數(shù)倉ETL
Kudu作為分布式數(shù)據(jù)存儲引擎,可以和Hadoop生態(tài)更好結(jié)合,因此在生產(chǎn)中我們采用了使用Kudu替換Oracle的做法,提升了擴展性。
ABTEST
在我們的ABTest業(yè)務中有兩種日志,行為日志和用戶分流日志。
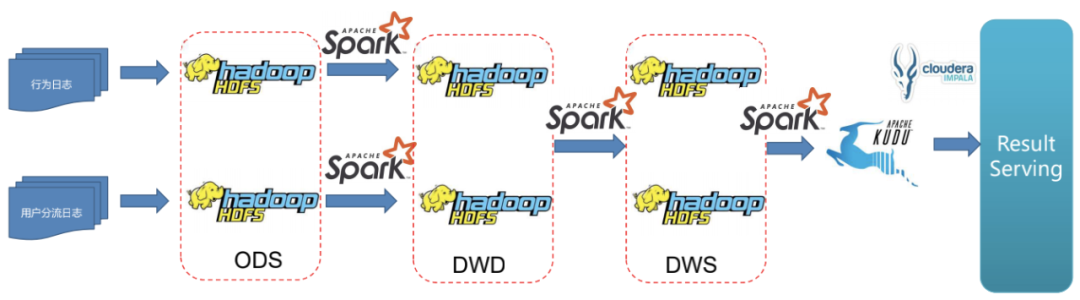
架構(gòu)升級前,我們采用了比較傳統(tǒng)的模式,將用戶行為日志和用戶分流日志分別寫入HDFS作為存儲的ODS層,通過Spark做清洗、轉(zhuǎn)換后導入HDFS作為存儲的DWD層,再通過Spark進行一步清洗、按照時間或其他緯度做簡單聚合后寫入DWS層。
這個架構(gòu)的問題是數(shù)據(jù)產(chǎn)出時間比較長,數(shù)據(jù)延遲在天級別。業(yè)務方需要更及時地拿到ABTest結(jié)果。
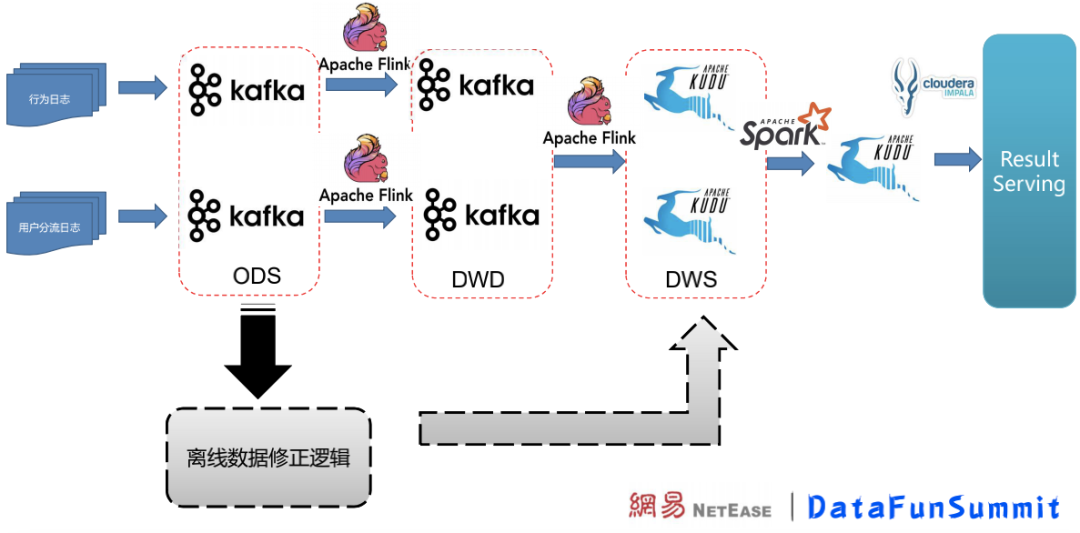
架構(gòu)升級后,使用Kafka作為ODS、DWD層存儲。Flink在ODS層數(shù)據(jù)的基礎上繼續(xù)做一層整理和過濾,寫入DWD形成明細表數(shù)據(jù);DWD層在Flink中做簡單聚合后寫入DWS層,Kudu在DWS層作為數(shù)據(jù)存儲。
Flink開窗口實時修正實驗數(shù)據(jù),這一操作在Kudu完成;超出了Flink時間窗口的數(shù)據(jù)更新則由離線補數(shù)據(jù)的操作在Kudu中完成修正。
架構(gòu)升級后,數(shù)據(jù)延遲大大降低,能夠讓ABTest業(yè)務方更實時地拿到結(jié)果。
我們遇到的問題
問題1: 節(jié)點負載不均衡
一些大表場景下會有負載不均衡問題。Kudu不會把range下的哈希分片當作一張表,而是把整個表的分片當成了平等的表進行處理。而在真實使用場景中,range基本是時間字段;需要讓range的hash分片更均勻地分布在各節(jié)點上,防止數(shù)據(jù)傾斜。下圖是數(shù)據(jù)傾斜的情況展示:
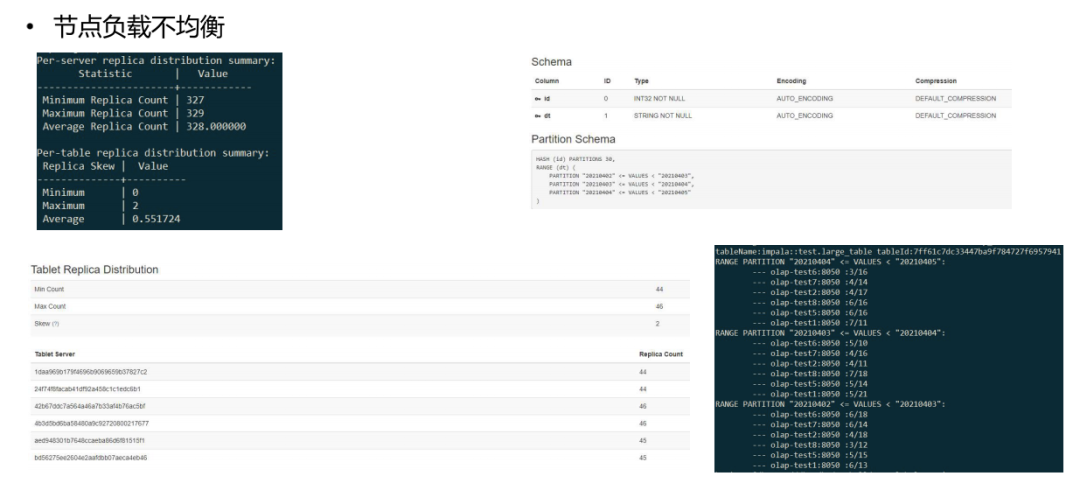
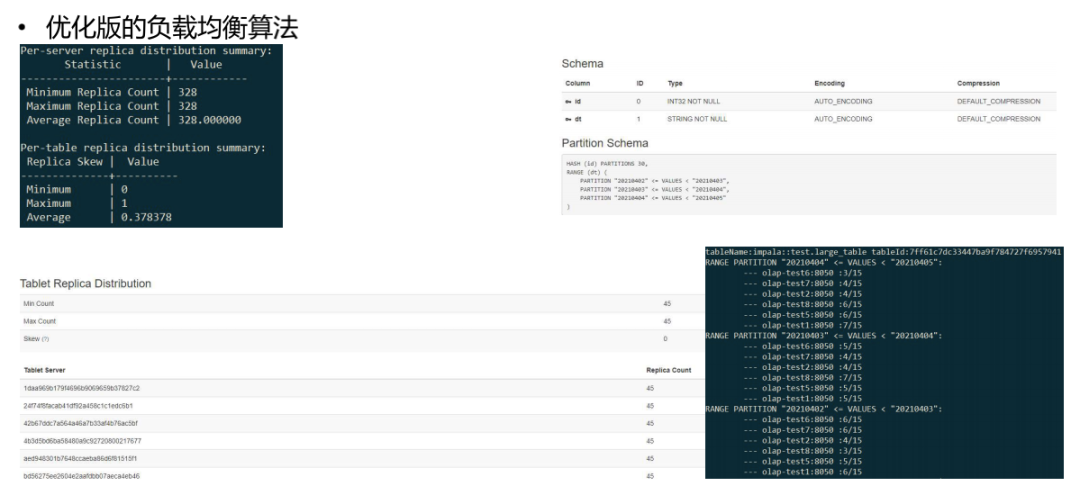
我們的解決方案是實現(xiàn)了一套優(yōu)化版本的負載均衡算法,這個算法能夠把range表當作單獨的表做負載均衡,解決了數(shù)據(jù)傾斜。下圖是優(yōu)化后效果:
問題2: 表結(jié)構(gòu)設計復雜
問題3: 沒有二級索引,只能通過控制主鍵順序和分區(qū)鍵來優(yōu)化某幾種查詢模式
問題4: 創(chuàng)建表時需要根據(jù)業(yè)務場景專門設計表結(jié)構(gòu)
問題2-4,對業(yè)務方要求比較高,經(jīng)常需要專人介入引導業(yè)務方導入數(shù)據(jù)。為了解決問題,我們內(nèi)部設計了二級索引來解決上述問題。二級索引可以滿足查詢性能的要求,同時減少用戶設計表時候的復雜度:
通過支持二級索引來優(yōu)化包含非主鍵列過濾的查詢
支持二級索引能夠降低業(yè)務設計表結(jié)構(gòu)的復雜度
社區(qū)對二級索引的支持進度KUDU-2038:Add b-tree or inverted index on value field
Kudu功能展望
BloomFilter
BloomFilter成本較低、效率較高。Join場景下,小表動態(tài)生成BloomFilter下推到存儲層,防止大表在Join層做數(shù)據(jù)過濾。最近的Kudu中已經(jīng)支持了BloomFilter作為過濾條件。
靈活分區(qū)哈希
Kudu每個range的hash bucket數(shù)量是固定的。考慮到時間和業(yè)務增長,在項目實施前期階段要給Kudu哈希桶數(shù)量設置略大,但是數(shù)據(jù)量較小的場景下過大的分片個數(shù)對資源是一種浪費,社區(qū)也不推薦hash bucket設置得比較大。期望后續(xù)Kudu可以更靈活地適配hash bucket數(shù)。
> KUDU-2671:Change hash number for range partitioning
多行事務
Kudu暫時不能支持多行事務。目前更新主鍵需要業(yè)務自己實現(xiàn)邏輯檢測。
> KUDU-2612:Implement multi-row transactions
Flexible Schema
一些業(yè)務場景下業(yè)務沒有唯一主鍵,但只希望利用Kudu的大批量寫入、聚合分析查詢的特性。接入業(yè)務時Kudu對Schema的要求比較高,一些業(yè)務場景無法支持。
> KUDU-1879:Support table without a primary key
嘉賓介紹:
閔濤,網(wǎng)易資深數(shù)據(jù)開發(fā)工程師。擁有多年分布式存儲系統(tǒng)設計和開發(fā)經(jīng)驗,現(xiàn)負責網(wǎng)易大數(shù)據(jù)平臺分布式存儲系統(tǒng)的開發(fā)。
編輯整理:張德通