
淺談NVIDIA H100白皮書(shū)
【GiantPandaCV導(dǎo)語(yǔ)】忙完手頭工作,就趕緊來(lái)過(guò)了一遍 H100 白皮書(shū)。下面我就以框架開(kāi)發(fā)和煉丹師的角度談?wù)?H100 的一些新特性,如有說(shuō)錯(cuò)的地方還望指正。
硬件層級(jí)
相較于A100的108個(gè)SM,H100 提升到了132個(gè)SM,每個(gè)SM里一共有 128個(gè)FP32 CUDA Core,并配備了第四代 TensorCore。每個(gè) GPU 一共有16896個(gè) FP32 CUDA Core,528個(gè)Tensor Core。

我還留意了下其他文章所提及的,這次 FP32 CUDA Core是獨(dú)立的,而在安培架構(gòu),是有復(fù)用 INT32 部分。相較A100,這次是在沒(méi)復(fù)用的情況下把 FP32 CUDA Core數(shù)量翻倍。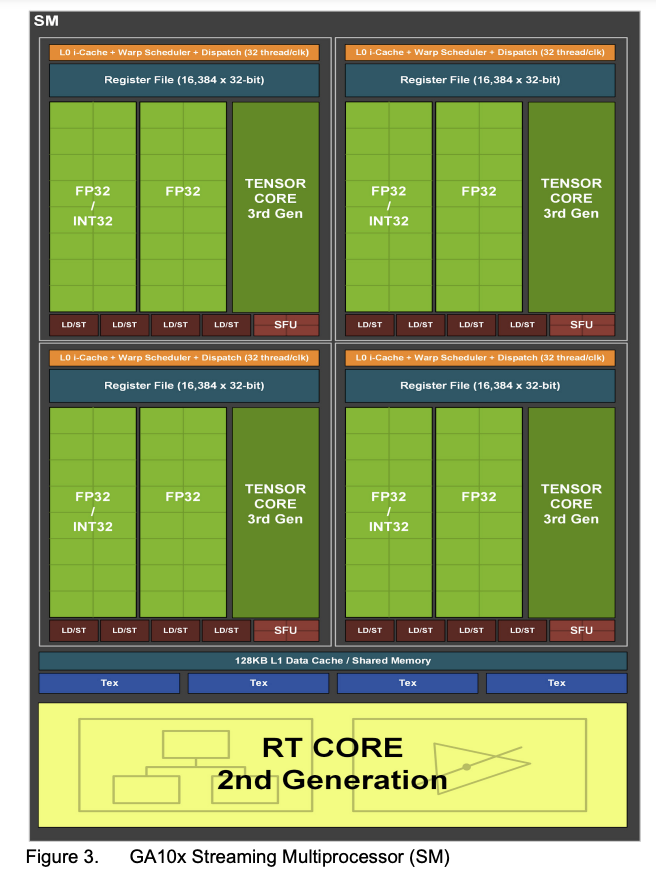
第四代TensorCore
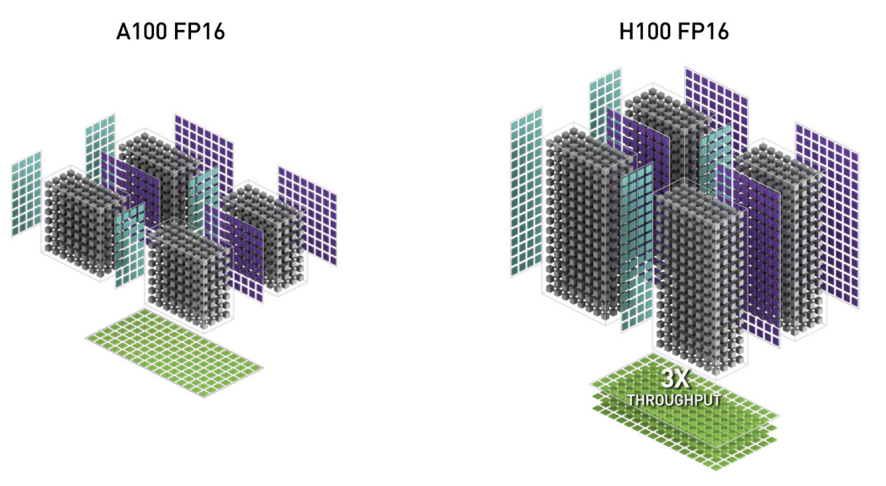
TensorCore對(duì)矩陣乘法有著高度優(yōu)化,這一次發(fā)布了第四代,在FP16矩陣乘法下有3倍的提升
FP8 數(shù)據(jù)格式
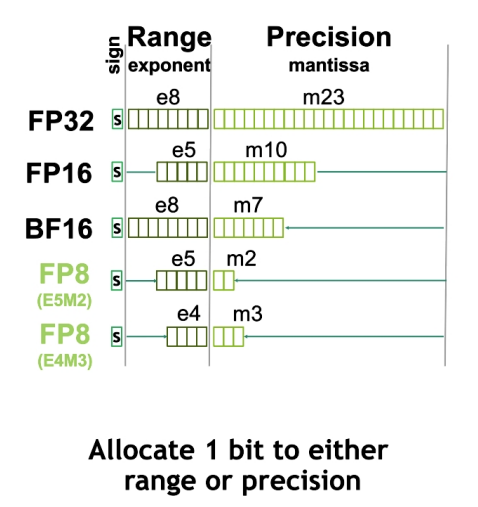
NV也發(fā)布了一款全新的數(shù)據(jù)格式 Float8,具體而言分兩種模式,E5M2是 5個(gè)指數(shù)位,2個(gè)尾數(shù)位,1個(gè)符號(hào)位;另一個(gè) E4M3 是 4個(gè)指數(shù)位置,3個(gè)尾數(shù)位,一個(gè)符號(hào)位。需要比較大的范圍,則用 E5M2,對(duì)精度有一定要求可以使用 E4M3
并且支持多種精度類(lèi)型的累加:
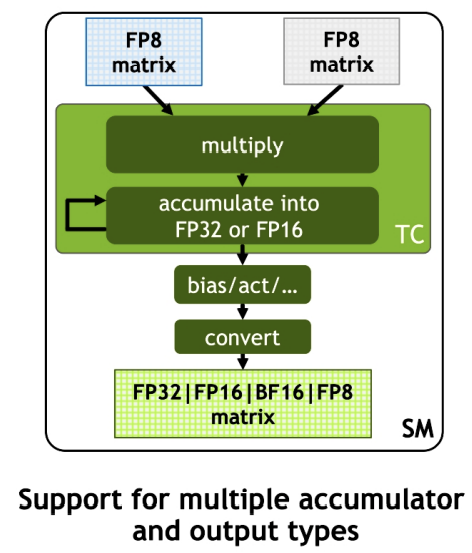
前面 TensorCore 在 FP16 已經(jīng)有3倍提升了,對(duì)應(yīng)的在 FP8 情況則有6倍提升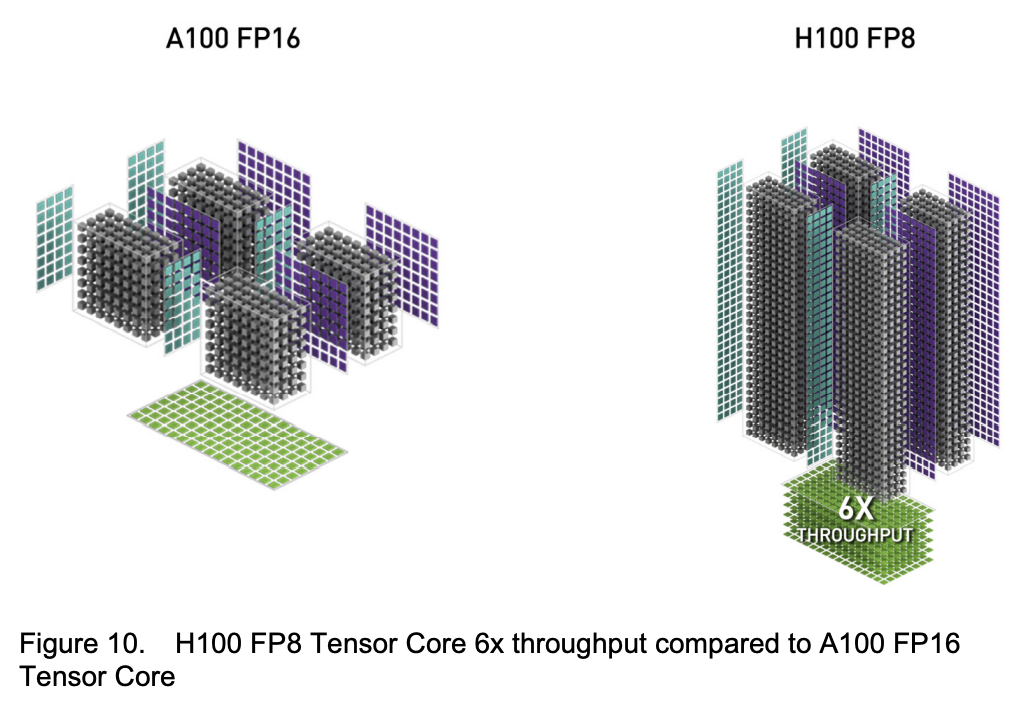
Transformer Engine
一開(kāi)始我以為只是名字恰好取的是Transformer,但看他意思是專(zhuān)為T(mén)ransformer模型而生的一個(gè)組件
隨著 GPT-3 等模型發(fā)展,Transformer類(lèi)的模型越來(lái)越大,訓(xùn)練時(shí)間也越來(lái)越長(zhǎng),以Megatron Turing NLG為例,需要 2048張 A100 訓(xùn)8周。而自動(dòng)混合精度訓(xùn)練逐漸成熟,能夠以更小,更快的數(shù)據(jù)格式(FP16)訓(xùn)練,同時(shí)也能保證模型準(zhǔn)確率,Transformer Engine也應(yīng)運(yùn)而生了。
我理解 NV 這里是通過(guò)硬件+軟件的方式來(lái)實(shí)現(xiàn)了自動(dòng)混合精度訓(xùn)練,我們常說(shuō)的自動(dòng)混合精度訓(xùn)練都是fp16為主,而Transformer Engine支持了 FP8 數(shù)據(jù)格式。Transformer Engine會(huì)對(duì) TensorCore 的計(jì)算結(jié)果進(jìn)行統(tǒng)計(jì)分析,并決定是否要轉(zhuǎn)換精度,并會(huì)搭配scale來(lái)進(jìn)行縮放。
看上去Transformer Engine專(zhuān)門(mén)為T(mén)ransformer模型而生,很好奇后續(xù)應(yīng)該通過(guò)什么專(zhuān)用工具庫(kù)來(lái)調(diào)用Transformer Engine。
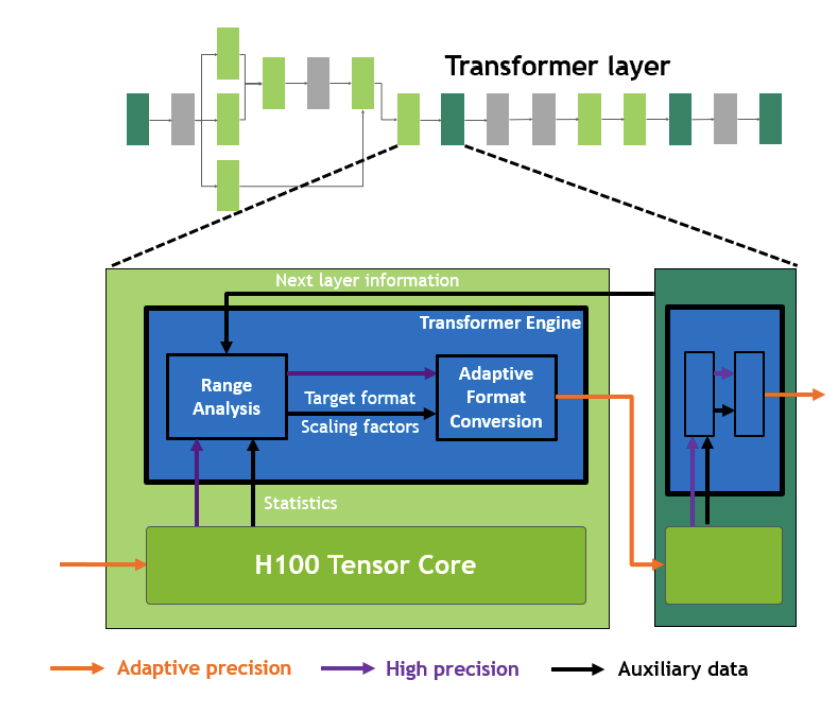
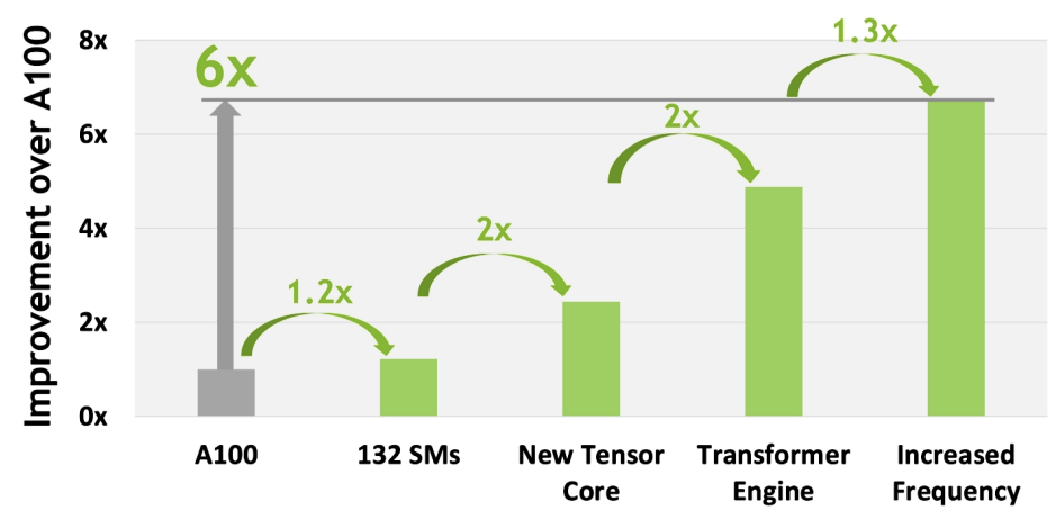
至此:
- SM相較上一代提升了22%
- 第四代TensorCore性能有著兩倍提升
- FP8數(shù)據(jù)類(lèi)型引入+Transformer Engine又有兩倍提升
- 時(shí)鐘頻率提升帶來(lái)了30%提升 這一代相比A100有著6倍的提升
新的線(xiàn)程層次 Thread Block Cluster
在之前CUDA編程里,我們將多個(gè)線(xiàn)程塊組織成一個(gè)Grid,多個(gè)線(xiàn)程組織成一個(gè)線(xiàn)程塊。一個(gè)線(xiàn)程塊被單個(gè)SM調(diào)度,并且塊內(nèi)的線(xiàn)程可以同步,并利用SM上的shared memory來(lái)交換數(shù)據(jù)。線(xiàn)程塊這個(gè)概念作為CUDA編程模型里唯一一個(gè)局部單元,已經(jīng)無(wú)法最大限度拉滿(mǎn)執(zhí)行效率。
這一次在 Block 和 Grid 中間,插入了一個(gè)新的線(xiàn)程層次 Thread Block Cluster。一個(gè) Cluster 是由一組線(xiàn)程塊構(gòu)成,并能被并發(fā)地被一組 SM 調(diào)度。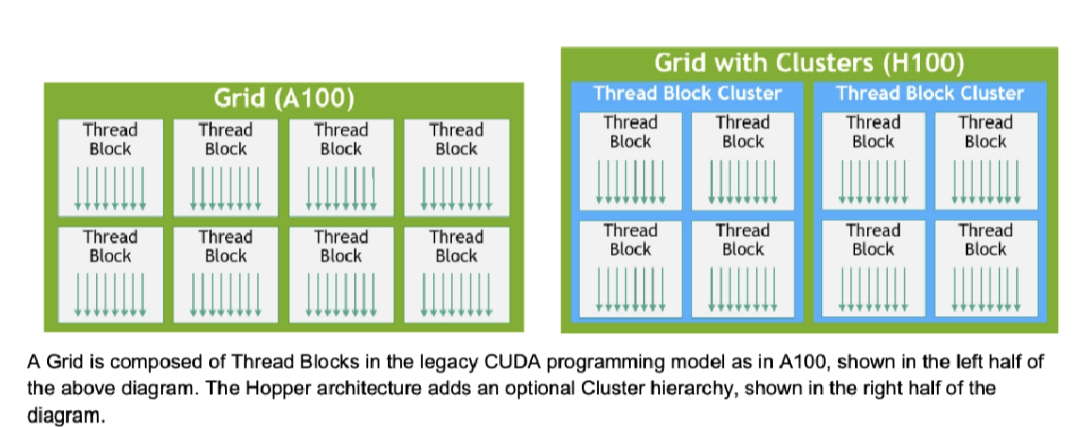
在一個(gè) Cluster 內(nèi),所有線(xiàn)程可以訪(fǎng)問(wèn)其他SM上的Shared Memory進(jìn)行數(shù)據(jù)讀取交換: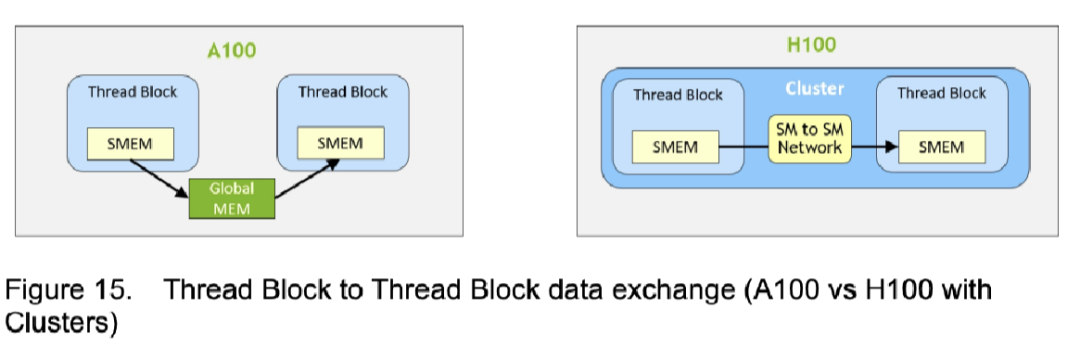
而在A100只能借助Global Memory實(shí)現(xiàn)不同SM上的Shared Memory訪(fǎng)問(wèn)
這種新的數(shù)據(jù)交換方式能夠提升7倍的速度
礙于鄙人的能力,這個(gè)我暫時(shí)只能想到做reduce_sum的時(shí)候,各線(xiàn)程塊的部分和結(jié)果可以直接通過(guò) Cluster 內(nèi)的Distributed Shared Memory相加,而無(wú)需重新啟動(dòng)一個(gè)核函數(shù)或用AtomicAdd實(shí)現(xiàn)最后的求和。
Tensor Memory Accelerator
TensorCore計(jì)算能力上來(lái)了,那IO也得對(duì)應(yīng)升級(jí)一下。TMA則是針對(duì)數(shù)據(jù)從Global Memory傳輸?shù)絊hared Memory而生。
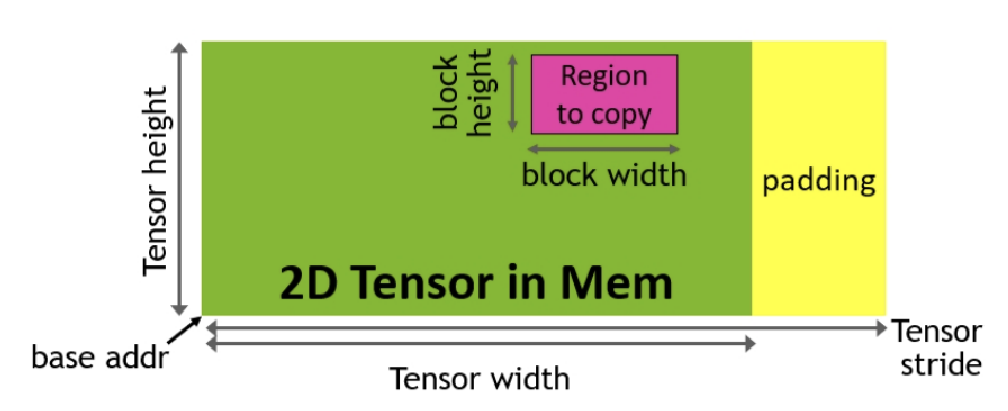
TMA編程模型是單線(xiàn)程的,即一個(gè)線(xiàn)程束內(nèi),會(huì)隨機(jī)選一個(gè)線(xiàn)程用來(lái)異步操作,其他線(xiàn)程則等待數(shù)據(jù)完成傳輸。
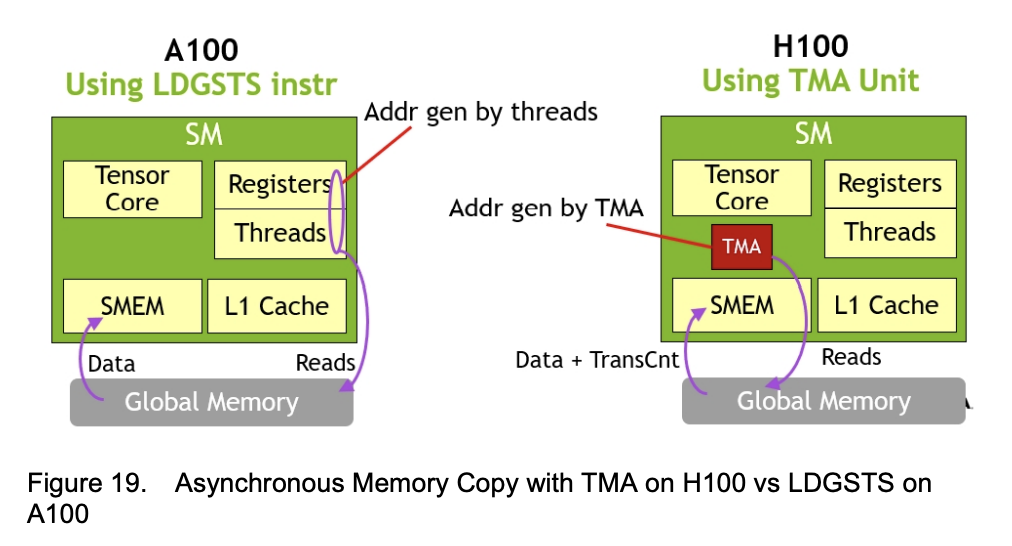
這一硬件也解放了線(xiàn)程,以往地址計(jì)算和數(shù)據(jù)搬運(yùn)是需要線(xiàn)程執(zhí)行,而這一次都由TMA包了:
還有一些特性沒(méi)完全看完,看得出NV已經(jīng)是All in AI,并且押寶在Transformer類(lèi)模型上了,期待后續(xù)的實(shí)際測(cè)試。