
大促壓測,遇到的那些問題
大促,對(duì)于電商公司來說就像家常便飯。那么如何保證大促時(shí)線上系統(tǒng)的穩(wěn)定性呢?答案就是:全鏈路壓測。
全鏈路壓測就是對(duì)業(yè)務(wù)功能的整條鏈路進(jìn)行壓測,并且使用真實(shí)的線上環(huán)境,這樣才能保證壓測結(jié)果跟大促時(shí)的流量應(yīng)對(duì)不會(huì)差太多。但是壓測的時(shí)候需要對(duì)底層存儲(chǔ)進(jìn)行影子庫的配置,所謂影子庫就是復(fù)制一份一樣的業(yè)務(wù)數(shù)據(jù)庫,當(dāng)壓測的流量來臨時(shí)數(shù)據(jù)操作都是走影子庫,這樣才能保證真實(shí)的業(yè)務(wù)數(shù)據(jù)不被污染。
今天分享下壓測過程中遇到的一些問題,也是一些經(jīng)驗(yàn),能夠幫助我們?cè)诤罄m(xù)的工作中對(duì)設(shè)計(jì)方案,編碼的重視。當(dāng)你寫一個(gè)接口,面臨調(diào)用量 100 的QPS和 1000的QPS,所需要考慮的點(diǎn)不止多一星半點(diǎn)。?
Redis大Key問題?
?問題描述
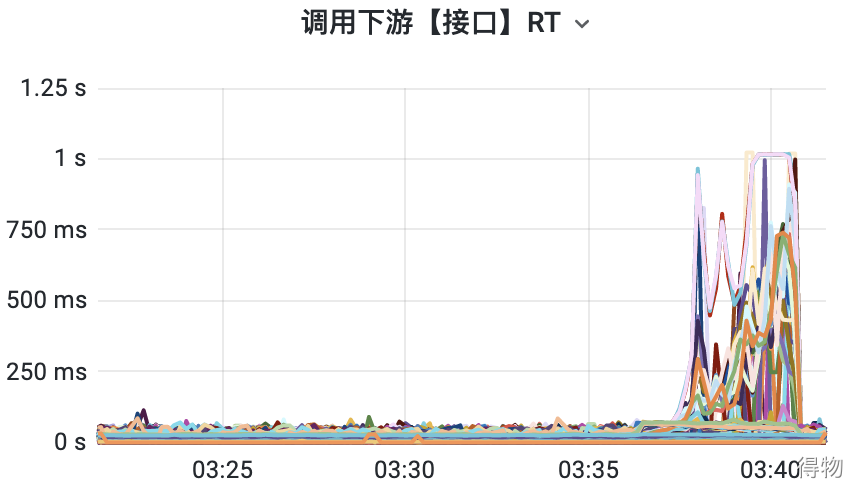
在對(duì)確認(rèn)訂單頁進(jìn)行壓測的時(shí)候,QPS 一直上不去,RT 反而越來越高,慢的 RT 高達(dá)1秒多鐘的時(shí)間。于是馬上查看了下游接口的RT大盤,發(fā)現(xiàn)部分接口的耗時(shí)很高,如下圖:?
排查過程
然后馬上通過調(diào)用鏈,抽了幾個(gè)耗時(shí)比較長的Trace進(jìn)行問題排查。
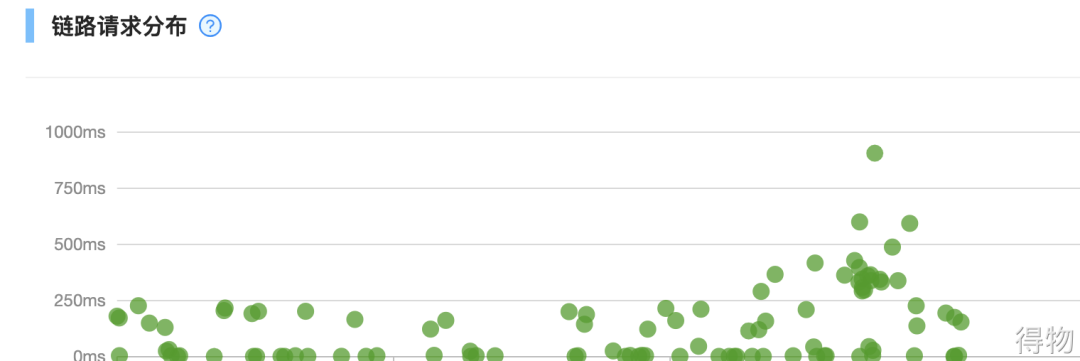
其實(shí)通過下游RT大盤就知道了哪個(gè)接口耗時(shí)較長,不過通過鏈路更方便,也能快速發(fā)現(xiàn)這個(gè)接口內(nèi)部是由于什么邏輯導(dǎo)致響應(yīng)特別慢。
通過鏈路的分析,在這個(gè)接口內(nèi)部有一個(gè)讀取Redis的操作耗時(shí)較長,情況很明了,就是Redis響應(yīng)慢導(dǎo)致整個(gè)接口RT上升。?
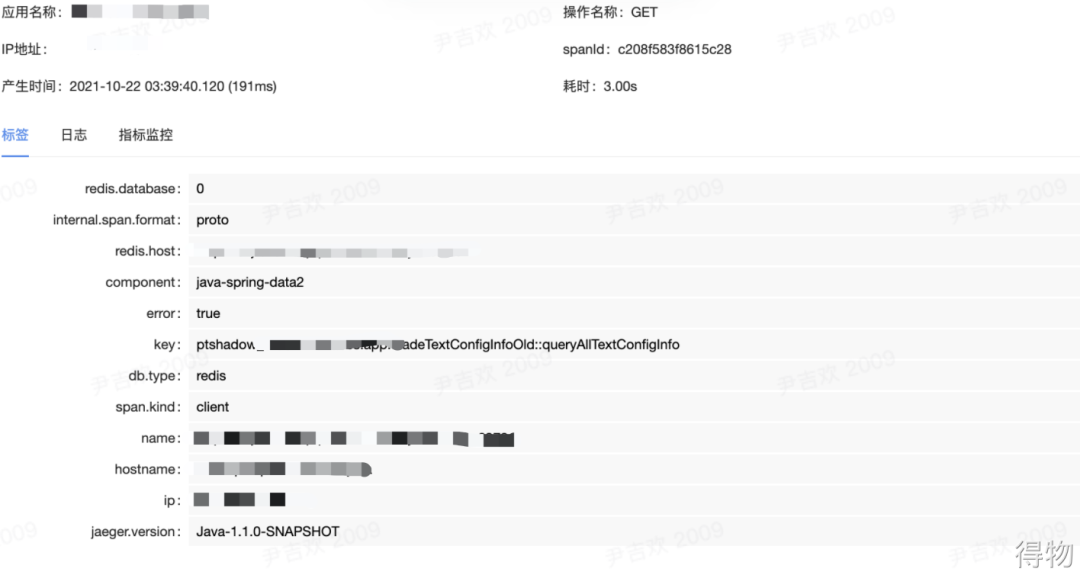
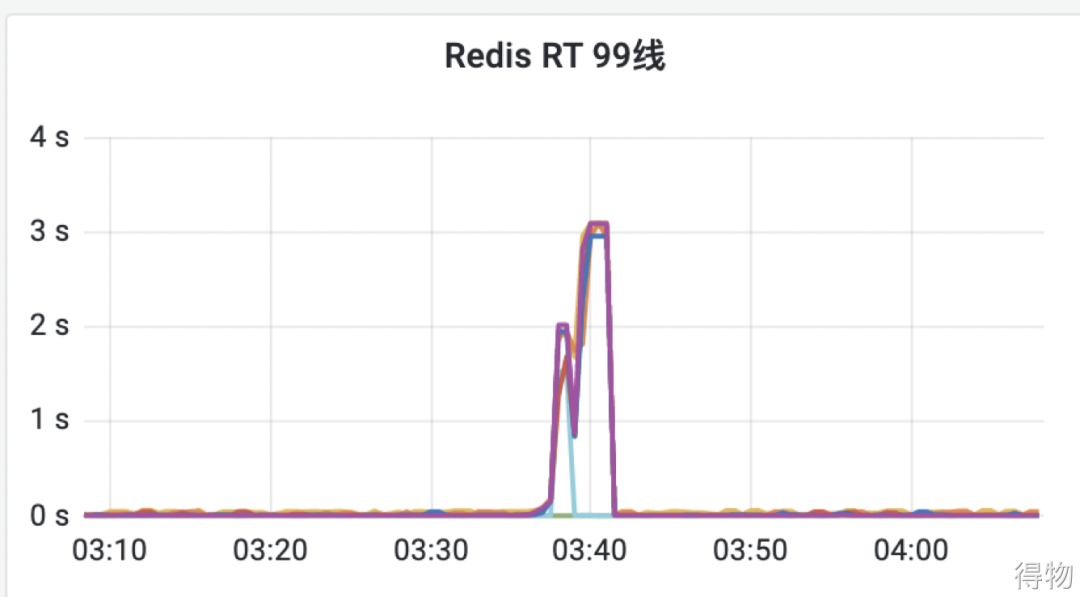
定位到了問題,接下來就是去Redis的管理后臺(tái)查看對(duì)應(yīng)的性能指標(biāo),發(fā)現(xiàn)Redis的CPU很低,也沒有對(duì)應(yīng)慢查詢的記錄。
接著看其他指標(biāo),發(fā)現(xiàn)某個(gè)Redis節(jié)點(diǎn)的帶寬特別高,其他節(jié)點(diǎn)都不高。然后看了這個(gè)Redis集群的配置,直接就發(fā)現(xiàn)了問題的根源所在,帶寬不夠。
為什么這個(gè)節(jié)點(diǎn)帶寬不夠呢?因?yàn)槌绦蚶镒x取的是固定的一個(gè)Key的緩存,這個(gè)緩存的容量又比較大,達(dá)到了M級(jí)別,所以并發(fā)一上來,帶寬就被打滿了。?
解決方案
方案一:Key拆分
在這個(gè)業(yè)務(wù)場景下,一個(gè)全量的配置信息,全部獲取后再從里面提取業(yè)務(wù)需要的內(nèi)容。也就是可以將這個(gè)配置信息拆成多份,按需求獲取業(yè)務(wù)需要的內(nèi)容。這樣就能避免緩存內(nèi)容太大,將帶寬打滿的問題。
方案二:本地緩存
如果要通過改造業(yè)務(wù)邏輯來解決問題,耗時(shí)有點(diǎn)長,畢竟解決當(dāng)前問題是首要的,所以采用本地緩存的方式快速解決。
將此配置信息緩存一份到本地服務(wù)中,這樣就能避免大量請(qǐng)求去Redis獲取,也就能避免帶寬的問題。但是這種多級(jí)緩存的方式,帶來的問題就是數(shù)據(jù)一致性。如果不能保證數(shù)據(jù)一致性,那么業(yè)務(wù)就有可能出問題。
好在我們內(nèi)部之前有過一套完整的多級(jí)緩存方案,只是復(fù)用即可。會(huì)采用消息通知+定時(shí)更新的方式來保證一致性。?
內(nèi)存泄漏問題?
問題描述?
經(jīng)過幾輪壓測后,服務(wù)內(nèi)存一直居高不下,從監(jiān)控看趨勢(shì),是慢慢往上升的。在垃圾回收后,內(nèi)存也沒有降下來,初步判斷是內(nèi)存泄漏了。
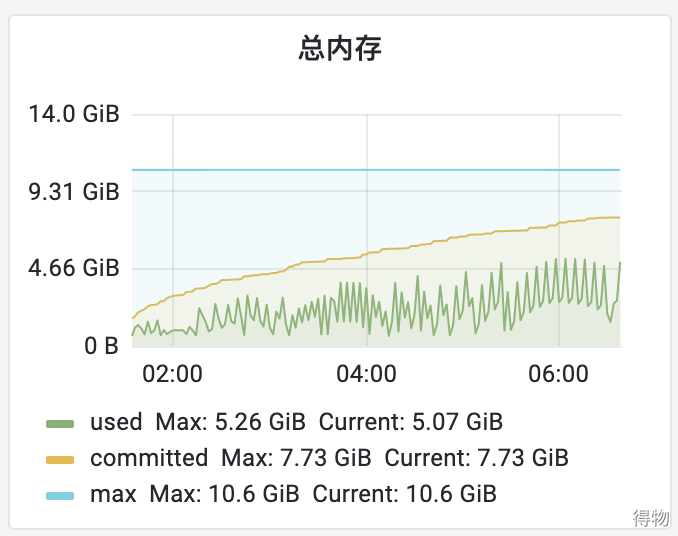
排查過程
解決現(xiàn)有問題排第一,首先將機(jī)器都重啟了一遍,留了一臺(tái)用于分析問題。然后將流量從Nacos上下掉,這樣就不會(huì)影響用戶的請(qǐng)求(非常重要)。
下掉之后讓運(yùn)維大佬幫忙dump下這臺(tái)機(jī)器的內(nèi)存,然后再本地用Mat進(jìn)行分析。最開始本地還沒按照Mat我就用了一個(gè)線上工具分析了下,如下圖:
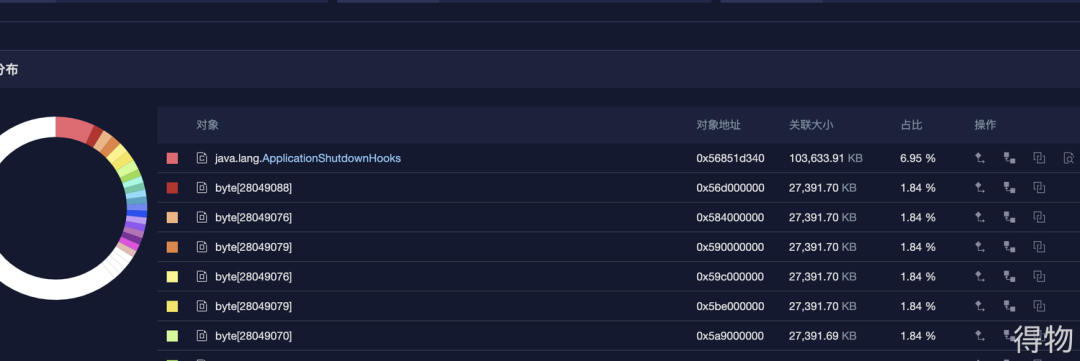
ApplicationShutdownHooks這對(duì)象占比最大,問題就很清晰明了。通過檢查代碼發(fā)下在某個(gè)獲取線程的方法中每次都會(huì)去addShutdownHook,這個(gè)起初是只想加一次就行了的,由于寫法問題導(dǎo)致每訪問一次就加一次,隨著調(diào)用量的增長,這個(gè)對(duì)象也越來越多。
解決方案?
只添加一次Hook即可,改造前代碼如下:?
public static ExecutorService getCartsListExecutor() {shutdownHandle(cartsListForkJoin, "cartsListForkJoin");return cartsListForkJoin;}
改造后代碼如下:?
static {shutdownHandle(cartsListForkJoin, "cartsListForkJoin");shutdownHandle(cartsCacheInitForkJoin, "cartsCacheInitForkJoin");}
機(jī)器內(nèi)存占用過高問題?
問題描述
前面2.2章節(jié)中介紹了內(nèi)存泄漏的問題,本以為解決后就正常了。沒想到第二輪壓測后,內(nèi)存還是居高不下,占機(jī)器內(nèi)存的70%多,觸發(fā)了告警配置的閥值。
排查過程
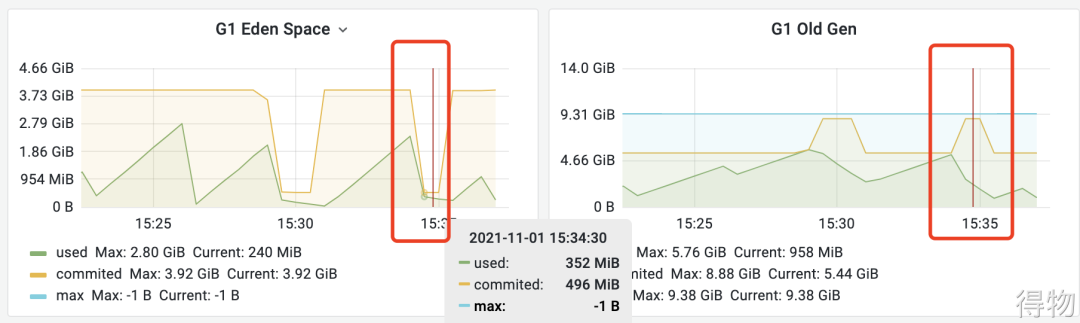
通過JVM的監(jiān)控發(fā)現(xiàn)堆內(nèi)存會(huì)正常回收,但是回收后機(jī)器的內(nèi)存還是降不下來。但是總的使用內(nèi)存其實(shí)不多,多的是黃色線條標(biāo)識(shí)的committed,一直在一條平均線上面,無任何波動(dòng)。?
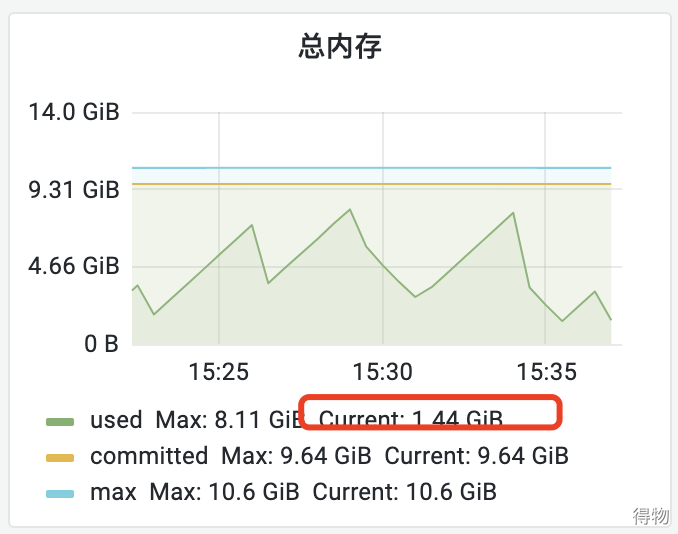
新生代的committed降低后,老年代的又上來了,而總量一直保持在9G多的樣子。由于JVM會(huì)預(yù)先申請(qǐng)內(nèi)存,預(yù)先申請(qǐng)的最大值為Xmx的9600M,一直保持在此值水平線并不會(huì)釋放,所以機(jī)器內(nèi)存占用水位線也一直保持在70%左右,對(duì)應(yīng)用無影響。即使GC后,堆內(nèi)存使用減少,預(yù)先申請(qǐng)的commited內(nèi)存也不會(huì)釋放。
關(guān)于commited內(nèi)存釋放相關(guān)的可以查看下面這些文章:
https://stackoverflow.com/questions/50965967/profiling-jvm-committed-vs-used-vs-free-memory
https://openjdk.java.net/jeps/346
http://www.hilalum.com/2020/12/jvmabout-jvms-committed-memory.html?m=1
https://stackoverflow.com/questions/41468670/difference-in-used-committed-and-max-heap-memory
解決方案
擴(kuò)容機(jī)器內(nèi)存,由16G擴(kuò)到32G,不過目前堆內(nèi)存也夠用,只是觸發(fā)了告警的閥值而已。
限制最大堆內(nèi)存,目前為9600M, 也就是committed最大申請(qǐng)值為9600M,可以調(diào)小點(diǎn),這樣就不會(huì)預(yù)先申請(qǐng)那么多,也不會(huì)觸發(fā)告警。
調(diào)整監(jiān)控閥值比例為80%,目前是70%,經(jīng)過驗(yàn)證內(nèi)存水位一致保持在80%以下,并且堆內(nèi)存也能正常垃圾回收。?

后臺(tái)回復(fù)?學(xué)習(xí)資料?領(lǐng)取學(xué)習(xí)視頻