編輯:桃子 好困 袁榭 拉燕
【新智元導(dǎo)讀】2022年2月24日凌晨,在Meta AI實驗室討論會上,小扎親自帶隊公布了多項技術(shù)內(nèi)容:語音生成元宇宙場景的Builder Bot、讓AI趕上人類智慧的「世界模型」、超級AI助手CAIRaoke等等。
「Builder Bot,帶我去海邊轉(zhuǎn)轉(zhuǎn)。」小扎一句話,陽光沙灘,蔚藍(lán)大海,一縷云彩就出現(xiàn)了。要知道,這些都是人工智能生成的(all AI-generated)。Meta的首席執(zhí)行官扎克伯格在今天「用人工智能構(gòu)建元宇宙」的討論會上,首次展示了用人工智能系統(tǒng)Builder Bot創(chuàng)建虛擬空間的過程。只要你一句話,它便可以生成或者導(dǎo)入你想要的虛擬世界。自從2021年11月31日,F(xiàn)acebook改名Meta后,市值被抹去了5000億美元,可見全力奔向元宇宙的代價可不小。第四季度財報公布后,Meta市值一夜蒸發(fā)2000多億美元。不管怎么說,現(xiàn)在Meta市值排名也算是回歸前十。從「帶我們?nèi)ズ_叀归_始,小扎的一系列語言命令,讓AI在其周圍一步步地創(chuàng)建了一個海邊的卡通3D景觀。演示中還創(chuàng)建了公園、海中島嶼、椰子樹、桌子、飲品等等。更炫酷的是,Builder Bot還可以播放熱帶等各種音樂。會上,小扎并沒有具體說明Builder Bot究竟是基于有限人工創(chuàng)建的模型庫,還是AI對任何內(nèi)容能夠?qū)崿F(xiàn)自動生成。作為人工智能項目CAIRaoke的一部分,Builder Bot的研發(fā)最終是為了可以吸引更多的人進(jìn)入Meta的元宇宙社交平臺Horizon。它還可以推進(jìn)創(chuàng)造性人工智能技術(shù)前進(jìn),為機(jī)器生成的藝術(shù)提供動力。目前,許多科技公司的人工智能項目已經(jīng)演示了基于文本描述進(jìn)行圖像生成,包括OpenAI的 DALL-E、英偉達(dá)的GauGAN2和VQGAN+CLIP,以及更易訪問的應(yīng)用程序,如Dream by Wombo。但是,目前這些項目僅能生成2D圖像,而且還不帶附件,而3D對象生成還處于研究階段。正如Meta在演示中所描述的那樣,Builder Bot可以通過使用語音來生成3D對象,而Meta更加雄心勃勃的目標(biāo)是交互。扎克伯格表示,「你將能夠創(chuàng)造微妙的世界,用你的聲音探索并與他人分享經(jīng)驗。」目前,Builder Bot目前還在測試中,暫時還未開放,因為Meta也不知道當(dāng)前系統(tǒng)的局限性在哪。如果用戶要求提供不適當(dāng)?shù)膬?nèi)容,或者人工智能的訓(xùn)練再現(xiàn)了人類對世界的偏見和刻板印象,那么人工智能會帶來許多問題。此外,扎克伯格承認(rèn),「如果用戶想要創(chuàng)建一個理想當(dāng)然的事物,可能還真做不到。復(fù)雜的交互性帶來了重大挑戰(zhàn)。」因此,這次會議上Meta公布了關(guān)于構(gòu)建元宇宙的人工智能計劃,其中就包括通用語言翻譯系統(tǒng)、對話AI系統(tǒng)CAIRaoke,人工智能推薦系統(tǒng)TorchRec等。此外,小扎介紹Meta還大力投資自監(jiān)督學(xué)習(xí)(SSL) ,將類人認(rèn)知構(gòu)建到人工智能系統(tǒng)中。并不是說需要喂大量標(biāo)記好的數(shù)據(jù)來訓(xùn)練人工智能,而是輸入原始數(shù)據(jù),然后要求預(yù)測缺失的部分,讓AI學(xué)會如何構(gòu)建抽象表示。在了解這些AI項目之前,不如先聽聽圖靈獎得主Yann LeCun對當(dāng)前人工智能的看法吧。
LeCun的愿景:讓AI像人一樣學(xué)習(xí)和推理
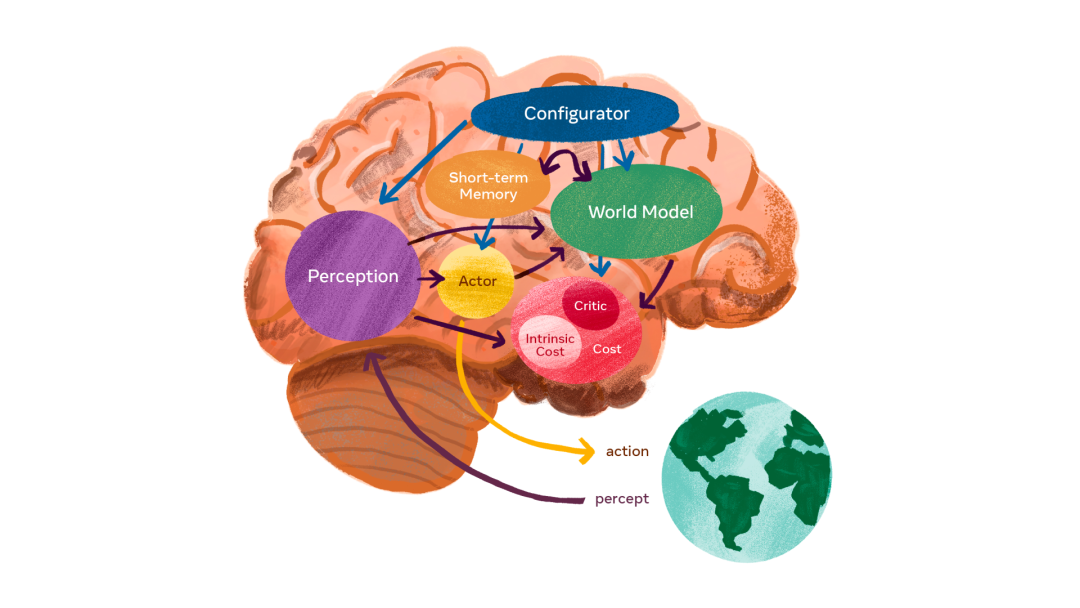
盡管AI研究最近取得了顯著進(jìn)展,但距離創(chuàng)造出能像人類一樣思考和學(xué)習(xí)的機(jī)器,還有很長的路要走。正如Meta AI首席人工智能科學(xué)家Yann LeCun所指出的,一個從未坐在方向盤后的少年可以在大約20小時內(nèi)學(xué)會駕駛,而當(dāng)今最好的智能駕駛系統(tǒng)AI需要數(shù)百萬或數(shù)十億條帶標(biāo)簽的訓(xùn)練數(shù)據(jù)和數(shù)百萬次在虛擬環(huán)境中的強(qiáng)化學(xué)習(xí)試驗。即便如此,它們也達(dá)不到與人類同等可靠的汽車駕駛能力。構(gòu)建接近人類智能的AI需要什么??僅僅堆更多數(shù)據(jù)和更大模型就能搞定嗎?2022年2月24日Meta AI實驗室新聞發(fā)布會中,LeCun為構(gòu)建人類智能級別的AI勾畫出另一種愿景。LeCun提出,AI學(xué)習(xí)「世界模型」(世界如何運(yùn)作的內(nèi)部模型)的能力可能是關(guān)鍵。LeCun提到了人類和動物的學(xué)習(xí)模式:「我常捫心自問,人類和動物使用了哪些我們無法在機(jī)器學(xué)習(xí)中復(fù)制的方法。人類和非人類動物學(xué)習(xí)大量關(guān)于世界如何運(yùn)作的背景知識的方式,是觀察,以及用獨立于任務(wù)、無人監(jiān)督方式進(jìn)行的少量互動。可以假定,這種積累的知識可能構(gòu)成了通常被稱為常識的基礎(chǔ)。」常識可以被視為世界模型的集合,可以指導(dǎo)智能體何種行為可能、何種行為合理、何種行為不可能。這使人類能夠在不熟悉的情況中有效地預(yù)先計劃。例如,一名少年司機(jī)以前可能從未在雪地上駕駛,但他預(yù)知雪地會很滑、如果車開得太猛將會失控打滑。常識性知識讓智能動物不僅可以預(yù)測未來事件的結(jié)果,還可以在時間或空間上填補(bǔ)缺失的信息。當(dāng)司機(jī)聽到附近有金屬撞擊聲時,即使沒有看到撞車現(xiàn)場,他也能立即知道車禍發(fā)生。LeCun稱:「我認(rèn)為機(jī)器學(xué)習(xí)缺失的是人類和動物如何學(xué)習(xí)世界模型,即學(xué)習(xí)世界如何運(yùn)作的能力」。他引述了Bengio提到的首次到英國的人如何學(xué)習(xí)左側(cè)駕駛的例子,「物理法則不會改變」,例如汽車方向盤怎么打,這就是個「世界模型」的例子。人類、動物和智能系統(tǒng)使用世界模型的想法,可以追溯到數(shù)十年前的心理學(xué)、機(jī)械控制和機(jī)器人等學(xué)科。LeCun提出,當(dāng)今人工智能最重要的挑戰(zhàn)之一是設(shè)計學(xué)習(xí)范式和架構(gòu),使機(jī)器能夠以自監(jiān)督的方式學(xué)習(xí)世界模型,然后用這些模型進(jìn)行預(yù)測、推理和計劃。他的提議重新組合了認(rèn)知科學(xué)、系統(tǒng)神經(jīng)科學(xué)、最優(yōu)化機(jī)械控制、強(qiáng)化學(xué)習(xí)和「傳統(tǒng)」人工智能等各個學(xué)科中的各種觀點,并將它們與機(jī)器學(xué)習(xí)中的新概念相結(jié)合,如自監(jiān)督學(xué)習(xí)和聯(lián)合-嵌入式架構(gòu)。LeCun提出了一個由六個獨立模塊組成的架構(gòu)。在每個模塊中,都可以很容易地計算目標(biāo)函數(shù)相對于其自身輸入的梯度估計,并將梯度信息傳遞給上游模塊。1. 配置器模塊負(fù)責(zé)控制任務(wù)的執(zhí)行。
?
配置器模塊會為特定的任務(wù)預(yù)先配置感知模塊、世界模型、代價和行為者,并調(diào)節(jié)這些模塊中的參數(shù)。
?
2. 感知模塊負(fù)責(zé)接收來自傳感器的信號并估計世界的當(dāng)前狀態(tài)。
?
對于一個特定任務(wù)來說,系統(tǒng)所感知到的世界狀態(tài)只有一小部分是有用的。而通過與配置器模塊的配合,感知模塊可以提取與當(dāng)前任務(wù)有關(guān)的信息。
?
3. 世界模型模塊的作用有兩點:(1)補(bǔ)全感知模塊沒有提供的信息;(2)預(yù)測合理的未來狀態(tài)。
?
世界模型是一種與當(dāng)前任務(wù)相關(guān)的世界模擬器,也是模型中最復(fù)雜的部分。它不僅可以預(yù)測世界的自然演變,也可以預(yù)測由行為者模塊在一系列動作之后所產(chǎn)生的未來世界狀態(tài)。
由于世界充滿了不確定性,該模型必須能夠涵蓋多種可能的預(yù)測。4. 代價模塊負(fù)責(zé)計算一個單一的標(biāo)量輸出,并預(yù)測智能體的不適程度。
?
代價模塊由兩個子模塊組成:(1)內(nèi)在代價,用于直接計算(如對智能體的損害,違反硬編碼的行為約束等),是不可訓(xùn)練的;(2)評價者,負(fù)責(zé)預(yù)測內(nèi)在代價的未來值,是一個可訓(xùn)練的模塊。
?
智能體的最終目標(biāo)是在長期內(nèi)使內(nèi)在代價最小化。此外,代價的梯度可以通過其他模塊反向傳播,用于規(guī)劃、推理或?qū)W習(xí)。
?
5. 行為者模塊負(fù)責(zé)提供動作序列的建議。
?
行為者可以找到一個使未來代價最小化的最佳動作序列,并執(zhí)行第一個動作,其方式類似于經(jīng)典的最優(yōu)控制。
?
6.短期記憶模塊負(fù)責(zé)跟蹤當(dāng)前和預(yù)測的世界狀態(tài),以及相關(guān)代價。
?
世界模型和自監(jiān)督訓(xùn)練
?
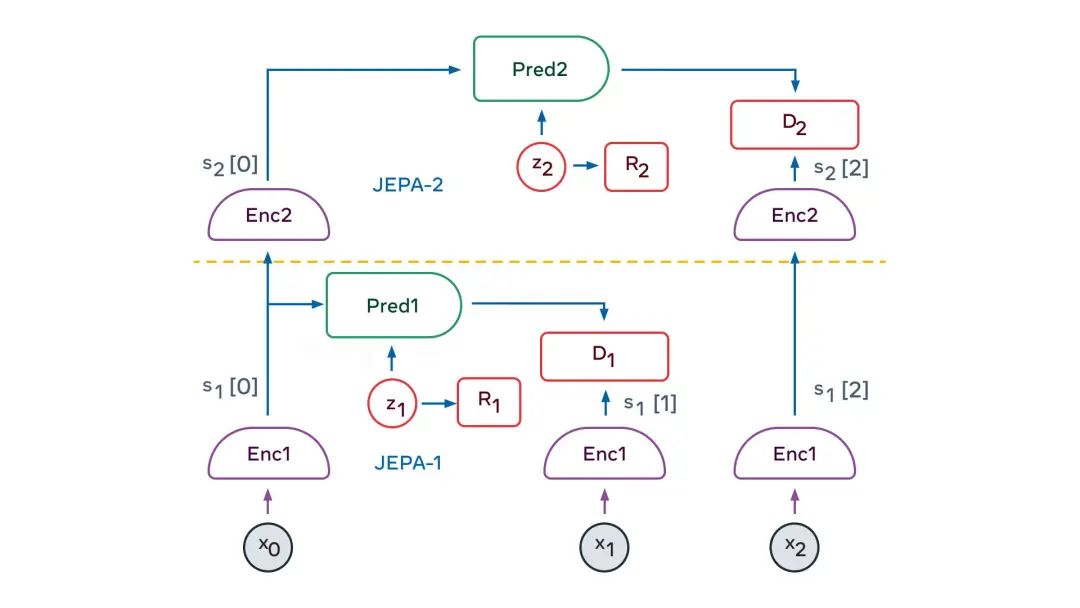
該架構(gòu)的核心是預(yù)測世界模型。而建構(gòu)它的關(guān)鍵挑戰(zhàn),是如何能使其呈現(xiàn)多種可能性的預(yù)測。
現(xiàn)實世界并不是完全可以單一預(yù)測的,特定情況的演變有多種可能途徑,并且狀況的許多細(xì)節(jié)與當(dāng)下任務(wù)無關(guān)。人類司機(jī)可能需要預(yù)測駕駛時自己周圍的汽車會做什么,但不需要預(yù)測道路附近樹木中單個葉子的詳細(xì)位置。世界模型如何學(xué)習(xí)現(xiàn)實世界的抽象表示,從而保留關(guān)鍵細(xì)節(jié)、忽略不相關(guān)細(xì)節(jié),且能在抽象表示的空間中進(jìn)行預(yù)測?解決方案的關(guān)鍵要素是「聯(lián)合嵌入式可預(yù)測架構(gòu)」?(JEPA)。JEPA能捕獲兩個輸入數(shù)據(jù)x和y之間的依賴關(guān)系。例如,x可以是一段視頻,y可以是視頻的下一段。輸入數(shù)據(jù)x和y被饋送到可訓(xùn)練的編碼器,這些編碼器提取它們的抽象表示,即sx和sy。訓(xùn)練預(yù)測器模塊,以從sx預(yù)測sy。預(yù)測器可以使用潛在變量z來表示sy中存在但sx中不存在的信息。JEPA以兩種方式處理預(yù)測中的不確定性:(1)編碼器可能會拋棄關(guān)于y的難以預(yù)測信息,(2)當(dāng)潛在變量z在一個集合上有變化時,將導(dǎo)致在另一個可能性集合上的預(yù)測結(jié)果有變化。JEPA如何訓(xùn)練?直到晚近,唯一的途徑是使用對比方法,即提供足夠多的兼容x和y的示例、兼容x但不兼容y的示例、不兼容x但兼容y的示例。但是當(dāng)抽象表示達(dá)到高維時,此方法不切實際。過去兩年出現(xiàn)了另一種訓(xùn)練策略:正則化方法。當(dāng)應(yīng)用于JEPA時,該方法使用四個準(zhǔn)則:- 使關(guān)于x的表示,最大程度地提供關(guān)于x的信息
- 使關(guān)于y的表示,最大程度地提供關(guān)于y的信息
- 從關(guān)于x的表示中,最大程度地預(yù)測關(guān)于y的呈現(xiàn)
- 使預(yù)測器調(diào)用來自潛在變量的盡可能少的信息,來表示預(yù)測中的不確定性。
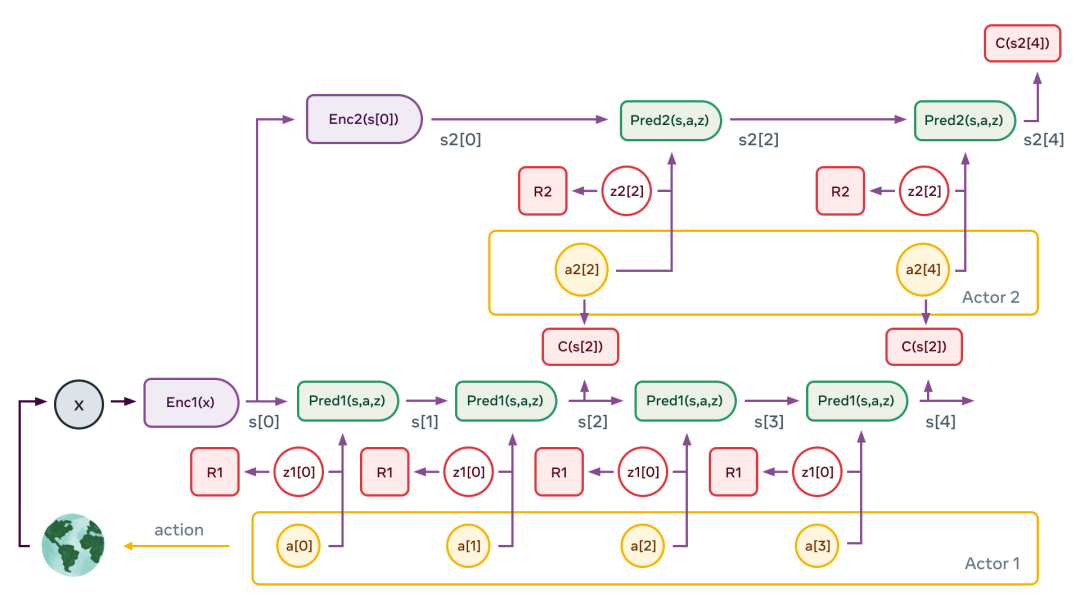
這些準(zhǔn)則可以通過各種方式轉(zhuǎn)化為可微的代價函數(shù)。其中一種方式是VICReg方法,它是「方差、不變性、協(xié)方差正則化」(Variance, Invariance, Covariance Regularization)的縮寫。在VICReg中,x和y表示的信息內(nèi)容最大化方式,是將其分量的方差保持在閾值之上,并使這些分量盡可能地相互獨立。同時,此方法試圖讓y的表示可以從x的表示中預(yù)測。此外,潛在變量的信息內(nèi)容,被使其離散、低維、稀疏或噪聲化的方式最小化。JEPA的妙處,在于它自然地產(chǎn)生了關(guān)于輸入信息的抽象表示,這些抽象表示消除了不相關(guān)的細(xì)節(jié),基于其可以執(zhí)行預(yù)測。這使得JEPA可以相互堆疊,用來學(xué)習(xí)具有更高層次的、能藉以執(zhí)行更長期預(yù)測的抽象表示。例如,一個場景可以在高層次上抽象描述為「廚師正在制作法式薄餅」。因此,人類智能可以預(yù)測:廚師會去取面粉、牛奶和雞蛋;混合原料;把面糊舀進(jìn)鍋里;讓面糊油炸;翻轉(zhuǎn)薄餅;重復(fù)以上流程。在低一級的層次上,人類智能可以預(yù)測:舀面糊動作,包括勺子舀面糊、倒進(jìn)鍋里、將面糊鋪在鍋面上。這種層級的攤低可以一直持續(xù)到以毫秒為單位的廚師手部的精確運(yùn)動軌跡。在手部軌跡的低層次上,「世界模型」只能在短期內(nèi)做出準(zhǔn)確的預(yù)測。但在更高的抽象層次上,它可以做出長期的預(yù)測。LeCun稱:「我們應(yīng)該讓機(jī)器通過觀察來學(xué)會現(xiàn)實世界中的最基礎(chǔ)定律,這是讓機(jī)器學(xué)習(xí)世界模型的最主要途徑。」多層JEPA可用于在多個抽象級別和多個時間尺度上執(zhí)行預(yù)測。訓(xùn)練的主要途徑是被動觀察,輔助途徑是與環(huán)境互動。正如嬰兒在出生后頭幾個月,主要通過觀察來了解世界是如何運(yùn)作的。她了解到世界是三維的、有些物體排在其他物體的前面、當(dāng)一個物體被遮擋時它仍然存在。最終,在大約9個月大的時候,嬰兒學(xué)會了直觀的物理學(xué)——例如,不受支撐的物體會因重力而落下。多層JEPA有望通過類似的觀看視頻、與環(huán)境交互等方式,來了解世界是如何運(yùn)作的。通過自訓(xùn)練來預(yù)測視頻中會發(fā)生什么,它將產(chǎn)生世界的分層級表示。通過在現(xiàn)實世界上采取行動并觀察結(jié)果,「世界模型」將學(xué)會預(yù)測其行動的后果,這將使其能夠進(jìn)行推理和計劃。有了分層JEPA作為世界模型的適當(dāng)訓(xùn)練,智能體就可以對復(fù)雜的動作進(jìn)行分層規(guī)劃,并將復(fù)雜的任務(wù)分解成一系列不那么復(fù)雜和抽象的子任務(wù),一直到效應(yīng)器上的低級動作。首先,感知模塊提取世界狀態(tài)的層次表示,s1[0]=Enc1(x),s2[0]=Enc2(s[0])。接著,多次應(yīng)用第二層的預(yù)測器,以預(yù)測未來的狀態(tài),并給同一層的行為者提出抽象的動作序列。然后,行為者優(yōu)化第二層動作序列,以使總代價最小化,C(s2[4])。這個過程會重復(fù)對第二層的潛變量進(jìn)行多次繪制,從而產(chǎn)生不同的高層方案。不過,由此產(chǎn)生的高層次動作并不構(gòu)成真正的動作,而只是定義了低層次狀態(tài)序列必須滿足的約束條件,進(jìn)而構(gòu)成真正子目標(biāo)。整個過程在低層重復(fù):運(yùn)行低層預(yù)測器,優(yōu)化低層動作序列以最小化來自上層的中間代價,并對低層潛變量的多次繪制。一旦這個過程完成,智能體就把第一個低層次的動作輸出給效應(yīng)器,整個情景也就可以重復(fù)進(jìn)行。如果能成功建立一個這樣的模型,那么所有的模塊都將是可微的。如此一來,整個動作的優(yōu)化過程就可以用基于梯度的方式進(jìn)行。顯然,LeCun的愿景需要更加深入的探索,其中最有趣也最困難的就是實例化世界模型的架構(gòu)和訓(xùn)練程序的細(xì)節(jié)。?
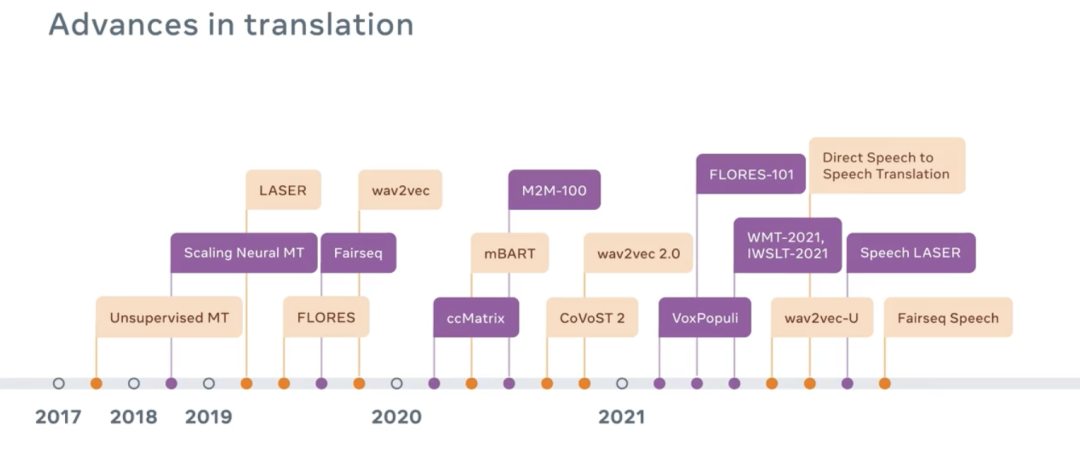
雖然訓(xùn)練世界模型可能會是未來幾十年內(nèi)讓AI實現(xiàn)真正進(jìn)步的主要挑戰(zhàn)。不過,讓全世界所有人都能用自己的語言互相交流,似乎已經(jīng)「勝利在望」了。為了自己的元宇宙大局,Meta推出了一款堪稱「萬能」的翻譯軟件。小扎表示,「能用任何語言和任何人溝通,是所有人一直都有的夢想。現(xiàn)在,AI可以幫我們實現(xiàn)這個夢想。」盡管英語、漢語、西班牙語這類語言目前的翻譯軟件已經(jīng)做得不錯了,但還有差不多20%的世界語言沒有被包括進(jìn)去。這類語言的語料庫一般不太好獲得,或者有時候壓根就沒有標(biāo)準(zhǔn)的書寫系統(tǒng)。Meta將通過新的機(jī)器學(xué)習(xí)技巧來克服這些困難。首先,Meta將會搭建一個可以使用較少訓(xùn)練樣本的AI模型。其次,Meta的這款通用翻譯語音翻譯系統(tǒng)不需要文字作為中介,而是實時進(jìn)行翻譯。大部分翻譯軟件都會利用到文字作為中介。從用戶的角度來說,移除語言障礙可以讓幾十億人用想用的語言上網(wǎng),獲得各類信息,還可以徹底改變所有人溝通和交往的方式。從Meta自身來講,這項技術(shù)的問世也可以幫助公司在世界范圍內(nèi)推廣產(chǎn)品,擴(kuò)大在全球范圍內(nèi)的影響力。這項技術(shù)會在未來成為AR和VR的關(guān)鍵技術(shù)。翻譯軟件的底層技術(shù)存在著一些問題——機(jī)器學(xué)習(xí)往往會忽略說話者之前的一些細(xì)微差別。比如性別方面的差異和偏見。另外,還有一些母語是非通用語言的人表示,「會擔(dān)心大公司掌握翻譯軟件會讓他們失去對本土語言和文化的控制」。因此,盡管這款通用翻譯軟件的前景真的很誘人,但Meta要在實現(xiàn)技術(shù)的同時,向人們證明,作為一家有擔(dān)當(dāng)?shù)墓荆梢怨降貞?yīng)用他們的技術(shù)和研究成果。
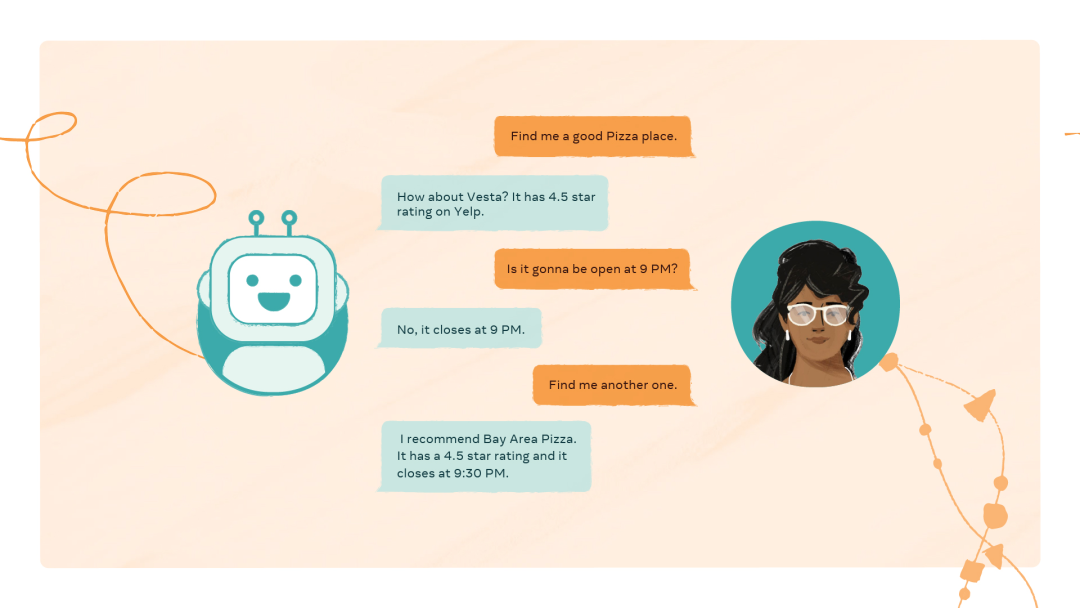
試想一下,如果和AI語音助手交流就像很人說話一樣自如會是什么場景。就像,鋼鐵俠的智能AI助手賈維斯一樣。最近,Meta推出了一款A(yù)I語音助手——CAIRaoke項目。這是一款端對端的神經(jīng)模型,可以支持更加個性化、符合語境的對話,很像人和人之間的日常交流。小扎甚至表示,CAIRaoke項目將是Meta的未來的核心。設(shè)計出更會聊天的AI助手的困難主要集中在以下四個方面。自然語言理解(NLU)、對話狀態(tài)跟蹤(DST)、對話策略管理(DT)以及自然語言生成(NLG)。這些系統(tǒng)必須被連接到一切,這就使得優(yōu)化不那么容易,不能更好地適應(yīng)新的或是不熟悉的任務(wù),還會高度依賴勞動密集型注釋數(shù)據(jù)集。而CAIRRaoke設(shè)計出的模型就可以讓人們更自如的和AI助手對話,可以再次提起之前對話中提到過的內(nèi)容,改變話題,或是說一點需要細(xì)膩把握才能正確理解的內(nèi)容。甚至還可以用手勢或者別的新方式和AI助手進(jìn)行互動。目前,Portal已經(jīng)使用了這項技術(shù),用戶可以輕松設(shè)置一個備忘錄。? : 好的。晚上六點半去買雞蛋的備忘錄已經(jīng)設(shè)置好了~為了提升對話AI的性能,就要全局的了解問題究竟在哪。很多人在看到最近自然語言理解的一些進(jìn)步,比如BART和GPT-3,會覺得AI已經(jīng)可以理解和生成類人的文本了。但其實沒那么容易。為了解釋為什么還不行,首先得能區(qū)分用于理解的AI和用于互動的AI。前者已經(jīng)被充分研究過,得到了充分的發(fā)展。出色的交互式AI需要穩(wěn)定的理解式AI打基礎(chǔ)。但是很多人覺得交互是一個工程問題,而不是人工智能的問題。然而,正是這種固有觀念,導(dǎo)致對話式AI缺少了靈活性。這也就是為什么現(xiàn)有的AI語音助手并不能讓你很輕松地制定一個假期計劃。由此可知,不僅僅要給AI提供準(zhǔn)確、實時的信息和知識,還要讓AI可以應(yīng)付多模式的、多領(lǐng)域的對話,而不是一套僵硬的對話模板。傳統(tǒng)的方法中,在涉及新領(lǐng)域時,在訓(xùn)練之前需要循序漸進(jìn)地構(gòu)建、調(diào)整每一個模塊。換句話說,只有NLU和DST每天都變化,訓(xùn)練DP才能更有效率。這種互相依賴的特點會拖慢整體的節(jié)奏。不同于上面提到的要使用NLU、DST、DT、NLG的模型,CAIRaoke使用的神經(jīng)網(wǎng)絡(luò)根本不用傳統(tǒng)的對話流。端對端的技術(shù)的應(yīng)用,讓CAIRaoke只需要一套訓(xùn)練數(shù)據(jù)集,就可以把這種依賴性轉(zhuǎn)移到上游的模塊去,使得之后的訓(xùn)練速度、開發(fā)速度大幅提高。技術(shù)人員就可以費(fèi)更少的精力和數(shù)據(jù)量來調(diào)整模型。Meta相信,未來CAIRaoke在應(yīng)用到AR和VR領(lǐng)域以后,它會是一項劃時代的技術(shù),就像鋼鐵俠那樣。此外,Meta 今天還宣布了為開源的PyTorch機(jī)器學(xué)習(xí)框架構(gòu)建最先進(jìn)的推薦系統(tǒng)庫TorchRec。總的來說,創(chuàng)造能夠像人類一樣有效學(xué)習(xí)和理解的機(jī)器是一項長期的科學(xué)努力,而且還不能保證成功。不過,基礎(chǔ)研究最終會讓我們產(chǎn)生對思想和機(jī)器更深入的理解,并帶來有利于每個使用人工智能的人的進(jìn)步。
參考資料:
https://www.facebook.com/watch/live/?ref=watch_permalink&v=1170892023445972
https://ai.facebook.com/blog/teaching-ai-to-translate-100s-of-spoken-and-written-languages-in-real-time
https://ai.facebook.com/blog/project-cairaoke/
https://ai.facebook.com/blog/yann-lecun-advances-in-ai-research/