
面試必問 | 線程與進程的區(qū)別,Python中如何創(chuàng)建多線程?

進程和線程
為了照顧小白,我們來簡單聊聊進程和線程這兩個概念。這兩個概念屬于操作系統(tǒng),我們經(jīng)常聽說,但是可能很少有人會細究它們的含義。對于工程師而言,兩者的定義和區(qū)別還是很有必要了解清楚的。
首先說進程,進程可以看成是CPU執(zhí)行的具體的任務(wù)。在操作系統(tǒng)當中,由于CPU的運行速度非常快,要比計算機當中的其他設(shè)備要快得多。比如內(nèi)存、磁盤等等,所以如果CPU一次只執(zhí)行一個任務(wù),那么會導致CPU大量時間在等待這些設(shè)備,這樣操作效率很低。為了提升計算機的運行效率,把機器的技能盡可能壓榨出來,CPU是輪詢工作的。也就是說它一次只執(zhí)行一個任務(wù),執(zhí)行一小段碎片時間之后立即切換,去執(zhí)行其他任務(wù)。
所以在早期的單核機器的時候,看起來電腦也是并發(fā)工作的。我們可以一邊聽歌一邊上網(wǎng),也不會覺得卡頓。但實際上,這是CPU輪詢的結(jié)果。在這個例子當中,聽歌的軟件和上網(wǎng)的軟件對于CPU而言都是獨立的進程。我們可以把進程簡單地理解成運行的應用,比如在安卓手機里面,一個app啟動的時候就會對應系統(tǒng)中的一個進程。當然這種說法不完全準確,一個應用也是可以啟動多個進程的。
進程是對應CPU而言的,線程則更多針對的是程序。即使是CPU在執(zhí)行當前進程的時候,程序運行的任務(wù)其實也是有分工的。舉個例子,比如聽歌軟件當中,我們需要顯示歌詞的字幕,需要播放聲音,需要監(jiān)聽用戶的行為,比如是否發(fā)生了切歌、調(diào)節(jié)音量等等。所以,我們需要進一步拆分CPU的工作,讓它在執(zhí)行當前進程的時候,繼續(xù)通過輪詢的方式來同時做多件事情。
進程中的任務(wù)就是線程,所以從這點上來說,進程和線程是包含關(guān)系。一個進程當中可以包含多個線程,對于CPU而言,不能直接執(zhí)行線程,一個線程一定屬于一個進程。所以我們知道,CPU進程切換切換的是執(zhí)行的應用程序或者是軟件,而進程內(nèi)部的線程切換,切換的是軟件當中具體的執(zhí)行任務(wù)。
關(guān)于進程和線程有一個經(jīng)典的模型可以說明它們之間的關(guān)系,假設(shè)CPU是一家工廠,工廠當中有多個車間。不同的車間對應不同的生產(chǎn)任務(wù),有的車間生產(chǎn)汽車輪胎,有的車間生產(chǎn)汽車骨架。但是工廠的電力是有限的,同時只能滿足一個廠房的使用。
為了讓大家的進度協(xié)調(diào),所以工廠需要輪流提供各個車間的供電。這里的車間對應的就是進程。

一個車間雖然只生產(chǎn)一種產(chǎn)品,但是其中的工序卻不止一個。一個車間可能會有好幾條流水線,具體的生產(chǎn)任務(wù)其實是流水線完成的,每一條流水線對應一個具體執(zhí)行的任務(wù)。但是同樣的,車間同一時刻也只能執(zhí)行一條流水線,所以我們需要車間在這些流水線之間切換供電,讓各個流水線生產(chǎn)進度統(tǒng)一。

這里車間里的流水線自然對應的就是線程的概念,這個模型很好地詮釋了CPU、進程和線程之間的關(guān)系。實際的原理也的確如此,不過CPU中的情況要比現(xiàn)實中的車間復雜得多。因為對于進程和CPU來說,它們面臨的局面都是實時變化的。車間當中的流水線是x個,下一刻可能就成了y個。
了解完了線程和進程的概念之后,對于理解電腦的配置也有幫助。比如我們買電腦,經(jīng)常會碰到一個術(shù)語,就是這個電腦的CPU是某某核某某線程的。比如我當年買的第一臺筆記本是4核8線程的,這其實是在說這臺電腦的CPU有4個計算核心,但是使用了超線程技術(shù),使得可以把一個物理核心模擬成兩個邏輯核心。相當于我們可以用4個核心同時執(zhí)行8個線程,相當于8個核心同時執(zhí)行,但其實有4個核心是模擬出來的虛擬核心。
有一個問題是為什么是4核8線程而不是4核8進程呢?因為CPU并不會直接執(zhí)行進程,而是執(zhí)行的是進程當中的某一個線程。就好像車間并不能直接生產(chǎn)零件,只有流水線才能生產(chǎn)零件。車間負責的更多是資源的調(diào)配,所以教科書里有一句非常經(jīng)典的話來詮釋:進程是資源分配的最小單元,線程是CPU調(diào)度的最小單元。
啟動線程
Python當中為我們提供了完善的threading庫,通過它,我們可以非常方便地創(chuàng)建線程來執(zhí)行多線程。
首先,我們引入threading中的Thread,這是一個線程的類,我們可以通過創(chuàng)建一個線程的實例來執(zhí)行多線程。
from?threading?import?Thread
t?=?Thread(target=func,?name='therad',?args=(x,?y))
t.start()簡單解釋一下它的用法,我們傳入了三個參數(shù),分別是target,name和args,從名字上我們就可以猜測出它們的含義。首先是target,它傳入的是一個方法,也就是我們希望多線程執(zhí)行的方法。name是我們?yōu)檫@個新創(chuàng)建的線程起的名字,這個參數(shù)可以省略,如果省略的話,系統(tǒng)會為它起一個系統(tǒng)名。當我們執(zhí)行Python的時候啟動的線程名叫MainThread,通過線程的名字我們可以做區(qū)分。args是會傳遞給target這個函數(shù)的參數(shù)。
我們來舉個經(jīng)典的例子:
import?time,?threading
#?新線程執(zhí)行的代碼:
def?loop(n):
????print('thread?%s?is?running...'?%?threading.current_thread().name)
????for?i?in?range(n):
????????print('thread?%s?>>>?%s'?%?(threading.current_thread().name,?i))
????????time.sleep(5)
????print('thread?%s?ended.'?%?threading.current_thread().name)
print('thread?%s?is?running...'?%?threading.current_thread().name)
t?=?threading.Thread(target=loop,?name='LoopThread',?args=(10,?))
t.start()
print('thread?%s?ended.'?%?threading.current_thread().name)我們創(chuàng)建了一個非常簡單的loop函數(shù),用來執(zhí)行一個循環(huán)來打印數(shù)字,我們每次打印一個數(shù)字之后這個線程會睡眠5秒鐘,所以我們看到的結(jié)果應該是每過5秒鐘屏幕上多出一行數(shù)字。
我們在Jupyter里執(zhí)行一下:
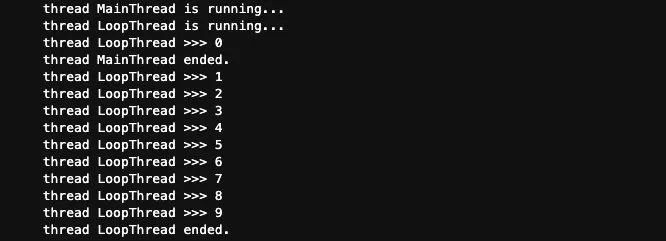
表面上看這個結(jié)果沒毛病,但是其實有一個問題,什么問題呢?輸出的順序不太對,為什么我們在打印了第一個數(shù)字0之后,主線程就結(jié)束了呢?另外一個問題是,既然主線程已經(jīng)結(jié)束了,為什么Python進程沒有結(jié)束, 還在向外打印結(jié)果呢?
因為線程之間是獨立的,對于主線程而言,它在執(zhí)行了t.start()之后,并不會停留,而是會一直往下執(zhí)行一直到結(jié)束。如果我們不希望主線程在這個時候結(jié)束,而是阻塞等待子線程運行結(jié)束之后再繼續(xù)運行,我們可以在代碼當中加上t.join()這一行來實現(xiàn)這點。
t.start()
t.join()
print('thread?%s?ended.'?%?threading.current_thread().name)join操作可以讓主線程在join處掛起等待,直到子線程執(zhí)行結(jié)束之后,再繼續(xù)往下執(zhí)行。我們加上了join之后的運行結(jié)果是這樣的:
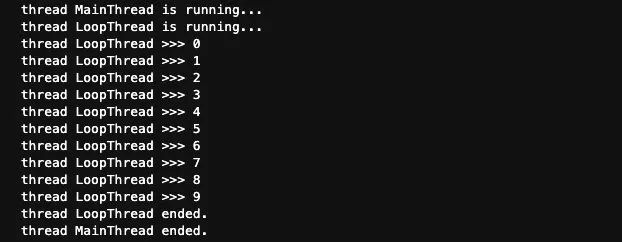
這個就是我們預期的樣子了,等待子線程執(zhí)行結(jié)束之后再繼續(xù)。
我們再來看第二個問題,為什么主線程結(jié)束的時候,子線程還在繼續(xù)運行,Python進程沒有退出呢?這是因為默認情況下我們創(chuàng)建的都是用戶級線程,對于進程而言,會等待所有用戶級線程執(zhí)行結(jié)束之后才退出。這里就有了一個問題,那假如我們創(chuàng)建了一個線程嘗試從一個接口當中獲取數(shù)據(jù),由于接口一直沒有返回,當前進程豈不是會永遠等待下去?
這顯然是不合理的,所以為了解決這個問題,我們可以把創(chuàng)建出來的線程設(shè)置成守護線程。
守護線程
守護線程即daemon線程,它的英文直譯其實是后臺駐留程序,所以我們也可以理解成后臺線程,這樣更方便理解。daemon線程和用戶線程級別不同,進程不會主動等待daemon線程的執(zhí)行,當所有用戶級線程執(zhí)行結(jié)束之后即會退出。進程退出時會kill掉所有守護線程。
我們傳入daemon=True參數(shù)來將創(chuàng)建出來的線程設(shè)置成后臺線程:
t?=?threading.Thread(target=loop,?name='LoopThread',?args=(10,?),?daemon=True)
這樣我們再執(zhí)行看到的結(jié)果就是這樣了:

這里有一點需要注意,如果你在jupyter當中運行是看不到這樣的結(jié)果的。因為jupyter自身是一個進程,對于jupyter當中的cell而言,它一直是有用戶級線程存活的,所以進程不會退出。所以想要看到這樣的效果,只能通過命令行執(zhí)行Python文件。
如果我們想要等待這個子線程結(jié)束,就必須通過join方法。另外,為了預防子線程鎖死一直無法退出的情況, 我們還可以在joih當中設(shè)置timeout,即最長等待時間,當?shù)却龝r間到達之后,將不再等待。
比如我在join當中設(shè)置的timeout等于5時,屏幕上就只會輸出5個數(shù)字。
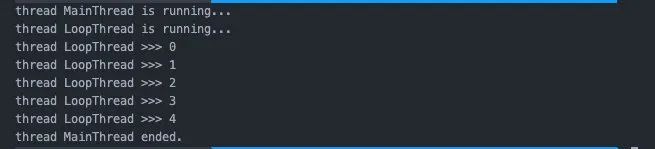
另外,如果沒有設(shè)置成后臺線程的話,設(shè)置timeout雖然也有用,但是進程仍然會等待所有子線程結(jié)束。所以屏幕上的輸出結(jié)果會是這樣的:
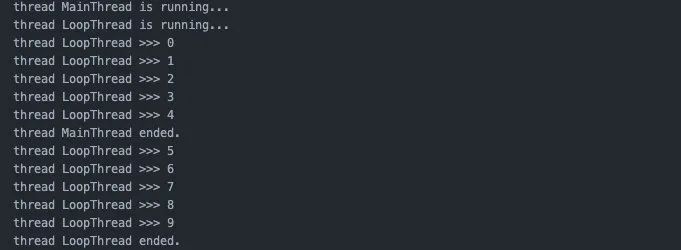
雖然主線程繼續(xù)往下執(zhí)行并且結(jié)束了,但是子線程仍然一直運行,直到子線程也運行結(jié)束。
關(guān)于join設(shè)置timeout這里有一個坑,如果我們只有一個線程要等待還好,如果有多個線程,我們用一個循環(huán)將它們設(shè)置等待的話。那么主線程一共會等待N * timeout的時間,這里的N是線程的數(shù)量。因為每個線程計算是否超時的開始時間是上一個線程超時結(jié)束的時間,它會等待所有線程都超時,才會一起終止它們。
比如我這樣創(chuàng)建3個線程:
ths?=?[]
for?i?in?range(3):
????t?=?threading.Thread(target=loop,?name='LoopThread'?+?str(i),?args=(10,?),?daemon=True)
????ths.append(t)
for?t?in?ths:
????t.start()
for?t?in?ths:
????t.join(2)最后屏幕上輸出的結(jié)果是這樣的:
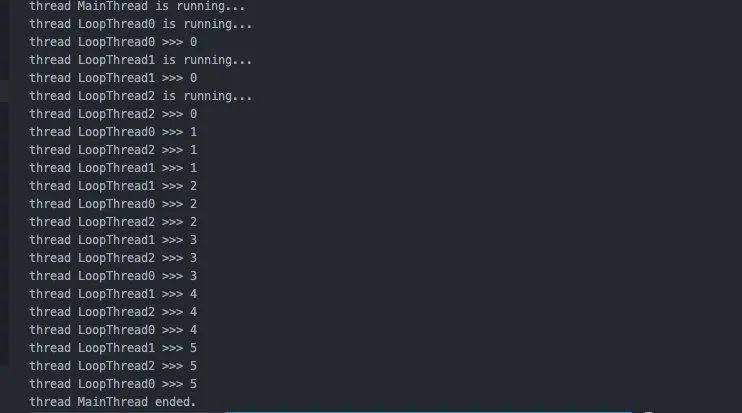
所有線程都存活了6秒,不得不說,這個設(shè)計有點坑,和我們預想的完全不一樣。
總結(jié)
在今天的文章當中,我們一起簡單了解了操作系統(tǒng)當中線程和進程的概念,以及Python當中如何創(chuàng)建一個線程,以及關(guān)于創(chuàng)建線程之后的相關(guān)使用。今天介紹的只是最基礎(chǔ)的使用和概念,關(guān)于線程還有很多高端的用法,我們將在后續(xù)的文章當中和大家分享。
多線程在許多語言當中都是至關(guān)重要的,許多場景下必定會使用到多線程。比如web后端,比如爬蟲,再比如游戲開發(fā)以及其他所有需要涉及開發(fā)ui界面的領(lǐng)域。因為凡是涉及到ui,必然會需要一個線程單獨渲染頁面,另外的線程負責準備數(shù)據(jù)和執(zhí)行邏輯。因此,多線程是專業(yè)程序員繞不開的一個話題,也是一定要掌握的內(nèi)容之一。
今天的文章就到這里,如果喜歡本文,可以點個在看,給我一點鼓勵。
