
Flink 優(yōu)化 | Flink_state 的優(yōu)化與 remote_state 的探索
相關(guān)背景
1.1 業(yè)務(wù)概況

業(yè)務(wù)規(guī)模,B 站目前大約是 4000+的 Flink 任務(wù),其中 95%是 SQL 類型。
部署模式,B 站有 80%的部署是 on yarn application 部署,我們的 yarn 集群和離線的 yarn 是分開的,是實時專用的 yarn 集群。剩下的 20%作業(yè),為了響應(yīng)公司降本增效的號召,目前是在線集群混部。這個方案的采用主要是從成本考慮,目前在使用 yarn on docker。
-
state 使用情況,平臺默認(rèn)開啟的全部是 rocksdb statebackend,大概有 50%的任務(wù)都是帶狀態(tài)的,其中有上百個任務(wù)的狀態(tài)超過了 500GB,這種任務(wù)我們稱之為超大狀態(tài)的 state 任務(wù)。
1.2 statebackend 痛點

主要痛點有 3 個:
cpu 抖動大。rocksdb 的原理決定了它一定會有一個 compaction 的操作。目前,在小狀態(tài)下這種操作對任務(wù)本身沒什么影響,但是在大狀態(tài)下,尤其是超過 500GB 左右,compaction 會造成 cpu 抖動大,峰值資源要求高。尤其是在 5、10、15 分鐘這種 checkpoint 的整數(shù)被間隔的情況下,整個 cpu 的起伏會比較高。對于一個任務(wù)來說,它的峰值資源要求會比較高。如果我們的資源滿足不了峰值資源的需求,任務(wù)就會觸發(fā)一陣陣的堆積和消積的情況。
恢復(fù)時間長。因為 rocksdb 是一個嵌入式的 DB 存儲,每次重啟或者任務(wù)的 rescale 狀態(tài)恢復(fù)時間長。因為它要把很大的文件下載下來,然后再在本地進(jìn)行一些重新的 reload,這就需要一些大量的掃描工作,所以會導(dǎo)致整個任務(wù)的狀態(tài)恢復(fù)時間比較長。觀察下來,正常來說大任務(wù)基本需要 5 分鐘左右才能恢復(fù)平穩(wěn)的狀態(tài)。
-
rocksdb 非常依賴本地磁盤。rocksdb 是嵌入式的 DB,所以會非常依賴本地 io 的能力。由于今年公司有降本增效的策略,我們也會在線推薦一些混部,因為 Flink 的帶狀態(tài)任務(wù)有對本地 io 依賴的特點,對于混部來講是沒法用的,這就導(dǎo)致我們使用混部的資源是非常有限的。

主要通過兩個方面解決這些痛點:
第一個是 state 壓縮。出于對如何降低 compaction 開銷的思考,對任務(wù)進(jìn)行了一些 cpu 火焰圖的分析。通過分析發(fā)現(xiàn),整個 cpu 的消耗主要在 2 個方面,一個是 compaction,一個是壓縮數(shù)據(jù)的換進(jìn)換出,這就會帶來大量的壓縮和解壓縮的工作。所以我們在壓縮層做了一些工作。
-
第二個是基于云原生的部署。由于本地沒有 io 能力,我們參考了一些云原生的方案,把整個本地的 rocksdb backend 進(jìn)行了 Remote state 的升級。這相當(dāng)于上面的一個存算分離,然后遠(yuǎn)程進(jìn)行了服務(wù)化的操作。這樣就可以實現(xiàn)即連即用,不需要進(jìn)行 reload 的操作,整個 state 是基于遠(yuǎn)程化進(jìn)行的。
state 壓縮優(yōu)化
2.1 業(yè)務(wù)場景
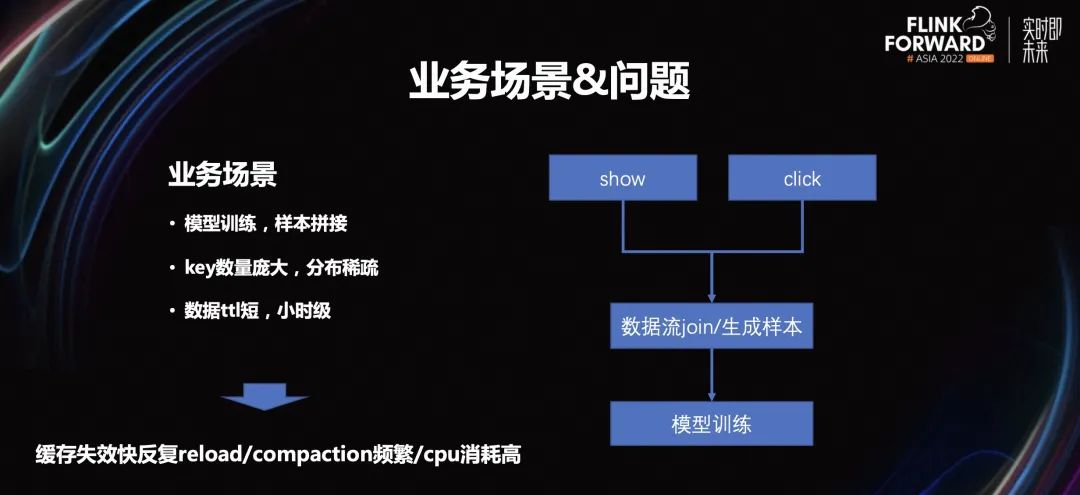
2.2 優(yōu)化思路

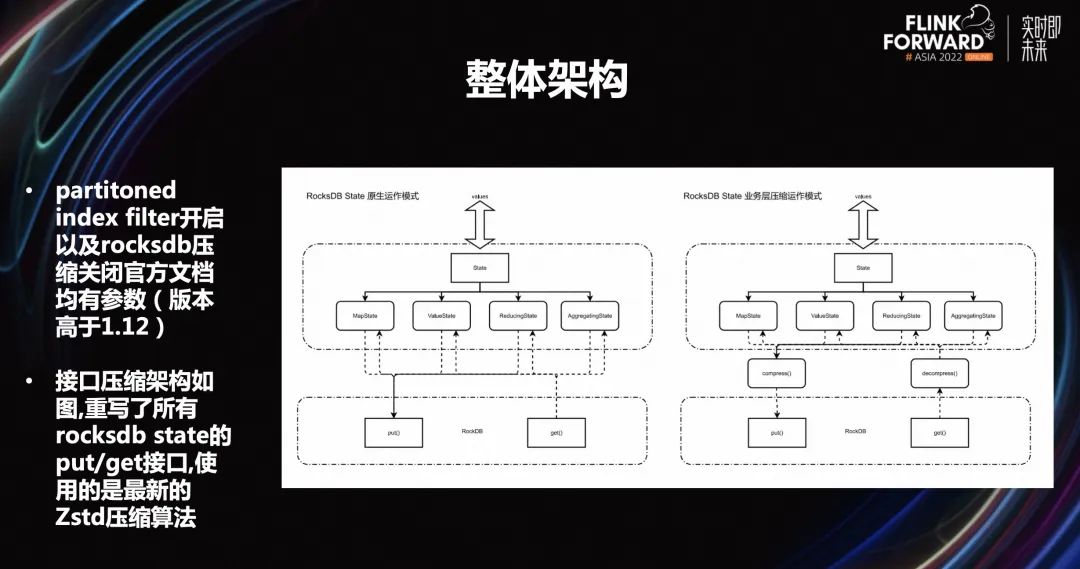
第一個是開啟 partitoned index filter,減少緩存競爭。從火焰圖中可以看到,data block 會不斷地從 block cache 中被換進(jìn)換出,同時產(chǎn)生大量的壓縮和解壓縮工作,大量的 cpu 其實消耗在這里。
第二個是關(guān)閉 rocksdb 壓縮,減少緩存加載 /compaction 時候的 cpu 消耗。從火焰圖中可以看到,整個 SSD 數(shù)據(jù)進(jìn)行底層生成的時候,它會不斷地進(jìn)行整個文件的壓縮和解壓縮。所以我們的思路就是如何去關(guān)閉一些 rocksdb 壓縮,減少整個緩存加載或者 cpu 的消耗。
-
第三個是支持接口層壓縮,在數(shù)據(jù) state 讀寫前后進(jìn)行解壓縮操作,減少 state 大小。如果關(guān)閉 rocksdb 底層的壓縮,我們觀察到整個磁盤的使用量非常高。這樣的話,壓力就是從壓縮和解壓縮的 cpu 消耗變成磁盤的 io 消耗,磁盤的 io 很容易就被消耗盡了。所以我們就把整個底層的壓縮往上層進(jìn)行了一個牽引,支持接口層的壓縮。
2.3 整體架構(gòu)
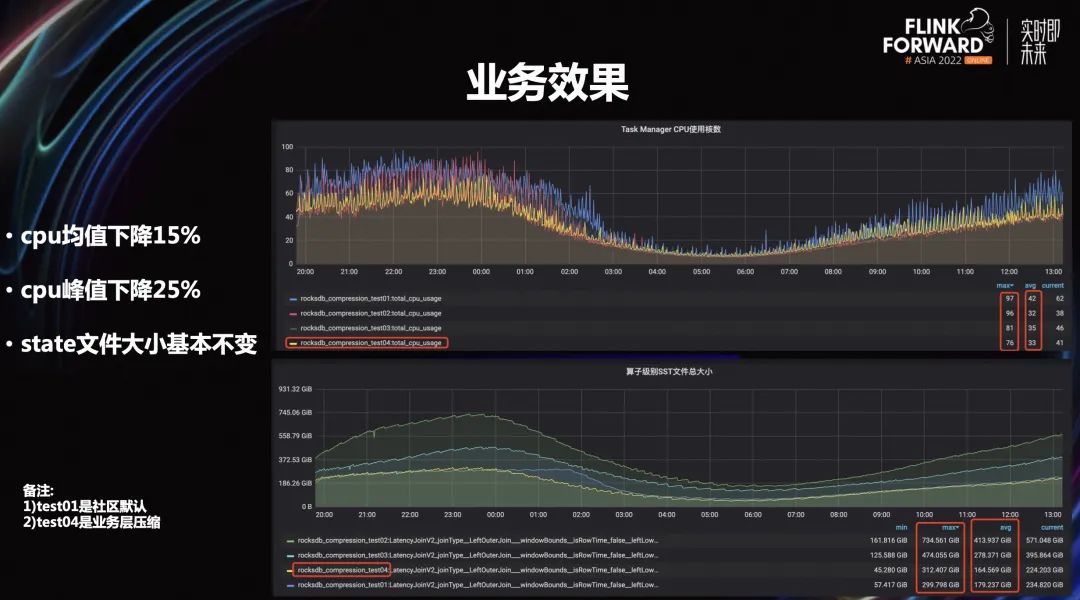
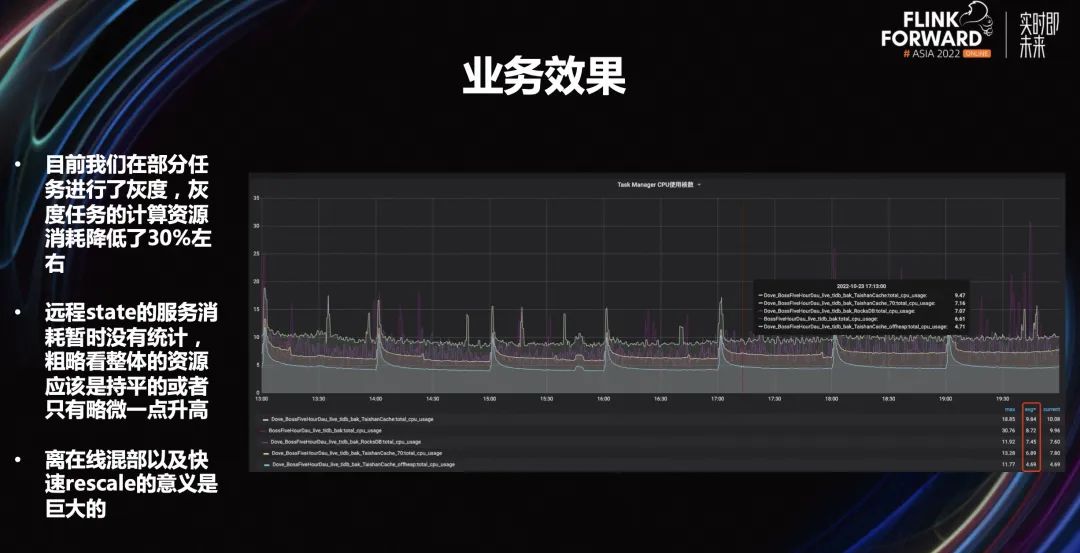
2.4 業(yè)務(wù)效果

Remote state 探索
3.1 業(yè)務(wù)場景和問題
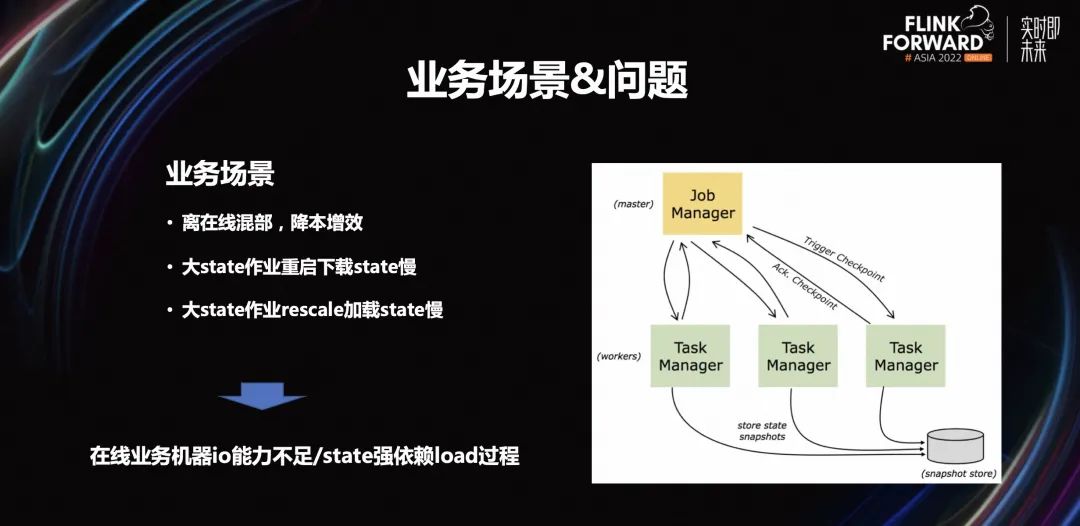
3.2 優(yōu)化思路

3.3 整體架構(gòu)
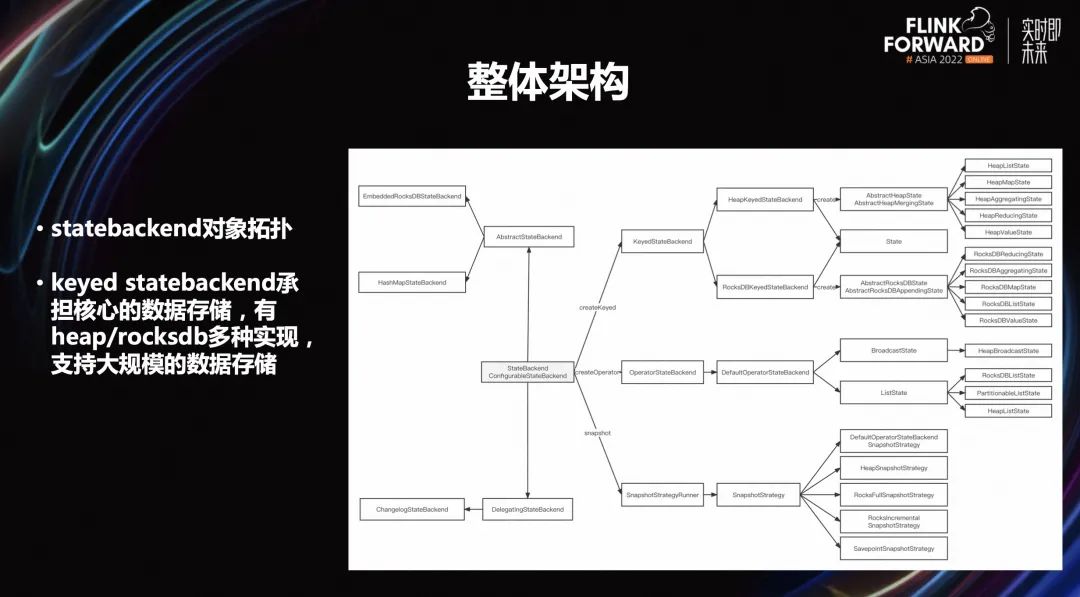

上圖是社區(qū) keyed statebackend 的分配邏輯架構(gòu)。如果想要把 keyed statebackend 做存算分離,需要了解:
Flink 的分片邏輯,它的底層有一個 keyed group 的概念。在所有狀態(tài)在任務(wù)第一次啟動的時候,底層分片就已經(jīng)確定好了。這個分片大小就是 Flink 的最大并發(fā)度的值。這個最大并發(fā)度實際上是在任務(wù)第一次不從 checkpoint 啟動時候算出來的。這中間如果一直從 checkpoint 啟動,那么最大并發(fā)度永遠(yuǎn)不會變。
Flink checkpoint rescale 能力是有限的,本質(zhì)是分片 key-group 在 subtask 之間的移動,分片無法分裂。一旦啟動生成切換之后,這個分片的數(shù)量因為已經(jīng)固定好了,后面不管怎么 rescale,本質(zhì)是分片的移動,其實最大的變動是后面 rescale 不能超過整個分片的數(shù)量,這個數(shù)量對應(yīng)的是分片最大的并發(fā)度。
-
多個 key-group 存儲在相同 rocksdb 的 cf 里面,以 key-group 的 ID 作為 key 的 prefix,依賴 rocksdb 的排序特性,rescale 過程通過 prefix 進(jìn)行定位遍歷提取。
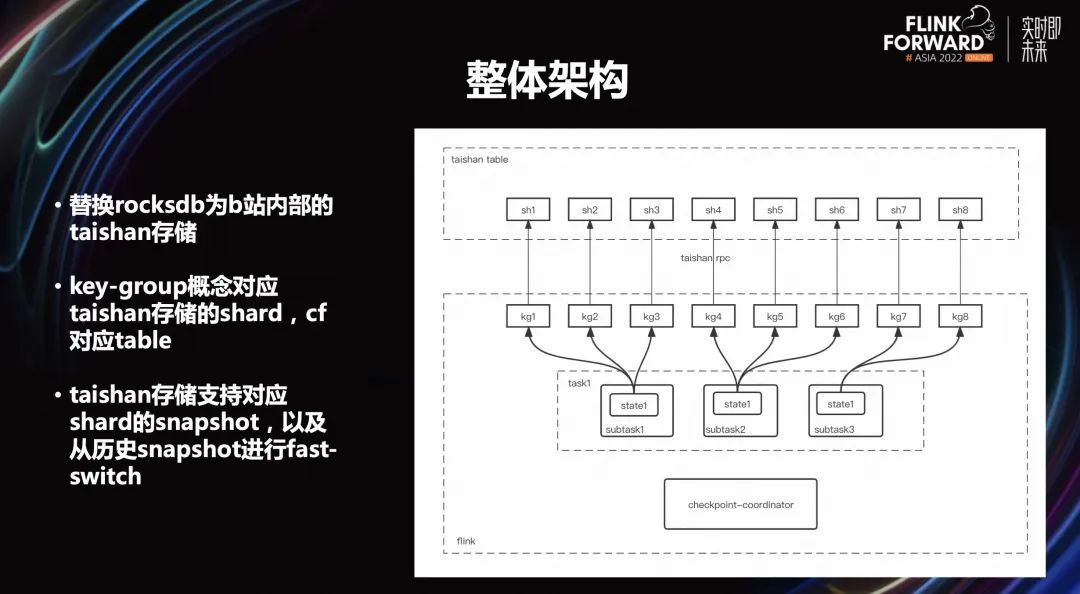
上圖是 Remote state 整體架構(gòu),主要的核心工作有三點:
替換 rocksdb 為 B 站內(nèi)部的 taishan 存儲。Taishan 存儲底層是分布式結(jié)構(gòu),F(xiàn)link 的一些概念是可以對應(yīng)到 taishan 存儲上的。
key-group 概念對應(yīng) taishan 存儲的 shard,cf 對應(yīng) table。key-group 的概念就可以對應(yīng)上 taishan 存儲,同時里面 cf 的概念也對應(yīng) taishan 存儲中的一個 table 概念,也支持一個 table 里面可以有多個 key-group。
-
Taishan 存儲支持對應(yīng) shard 的 snapshot,以及從歷史的 snapshot 進(jìn)行快速切換。比如重啟的時候可以從老的 checkpoint 進(jìn)行回復(fù),實際上能夠調(diào)用 taishan 存儲這樣一套接口進(jìn)行快速 snapshot 切換,并可以指定對應(yīng)的 snapshot 并進(jìn)行加載,加載的速度非常快,基本是秒級左右。
3.4 緩存架構(gòu)
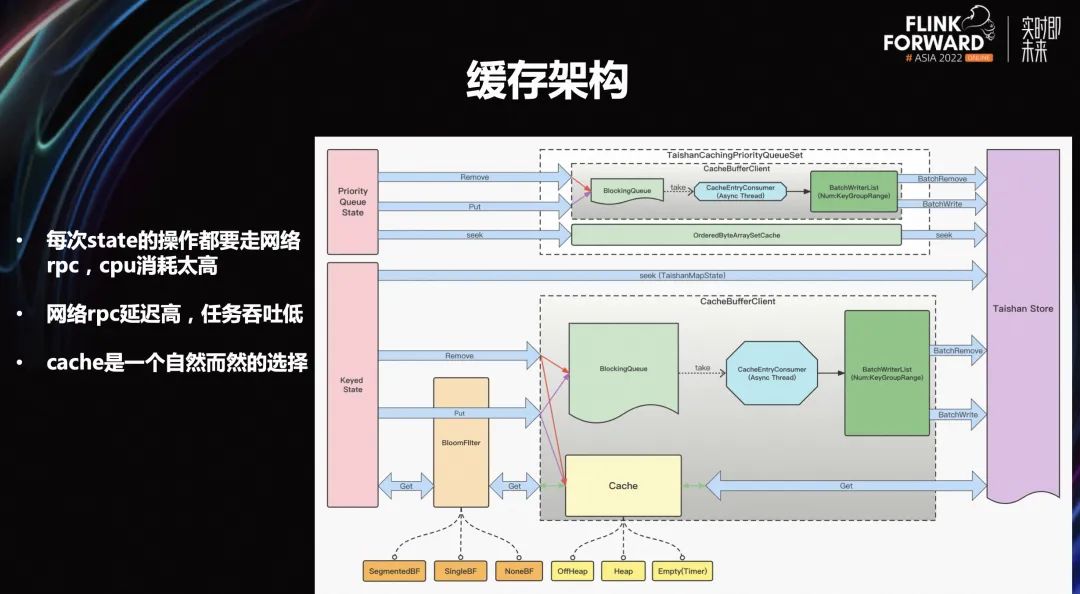
在上文介紹的基礎(chǔ)上可以觀察到,開發(fā)完之后實際上整個功能來說是完全夠用的,但也發(fā)現(xiàn)了一些比較嚴(yán)重的性能問題:
每次 state 操作都需要走網(wǎng)絡(luò) rpc, cpu 的消耗太高
網(wǎng)絡(luò) rpc 的延遲高,任務(wù)吞吐低
-
cache 是一個自然而然的選擇
3.5 緩存難點

讀緩存是比較難的。讀緩存是把場景進(jìn)行拆分來看:
key 比較少的場景效果明顯,命中率極高,效果好,甚至達(dá)到幾百上千倍的效果提升。
稀疏的 key 場景,大量讀 null,緩存命中率低。這個場景是當(dāng)下比較大的難點。
-
周期性業(yè)務(wù)導(dǎo)致緩存定期失效,讀 null,命中率暴跌。周期性業(yè)務(wù)到周期末節(jié)點,就會觸發(fā)一個緩存失效,一旦跨過這個節(jié)點,緩存里就會變成新的數(shù)據(jù)。如果正巧遇上讀 null,命中率就會很低,甚至導(dǎo)致任務(wù)抖動。這也是比較大的難點。
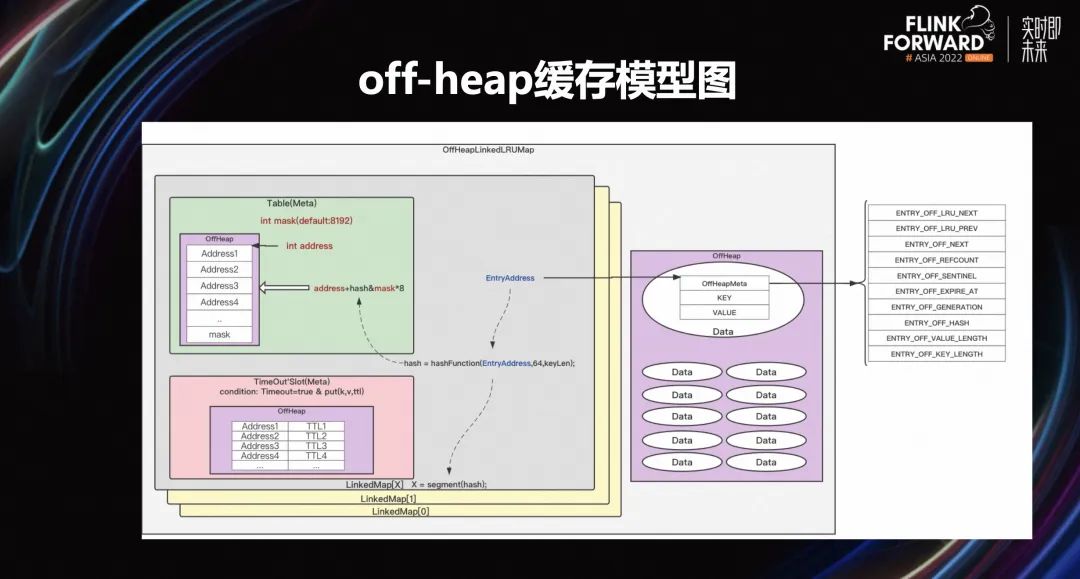
3.6 off-heap 緩存模型圖
未來規(guī)劃

8/26 活動預(yù)告
活動時間:8 月 26 日 13:00
活動地點:北京阿里中心·望京 A 座
線下報名地址:https://developer.aliyun.com/trainingcamp/4bb294cf64b04a2a8b3f8b153e188e9f
線上直播觀看地址:https://gdcop.h5.xeknow.com/sl/1l4Sye

▼ 關(guān)注「Apache Flink」,獲取更多技術(shù)干貨 ▼
 點擊「閱讀原文」,免費領(lǐng)取 5000CU*小時 Flink 云資源
點擊「閱讀原文」,免費領(lǐng)取 5000CU*小時 Flink 云資源