
為什么需要Kafka?

背景
Kafka最早是由LinkedIn公司開發(fā)的,作為其自身業(yè)務(wù)消息處理的基礎(chǔ),后LinkedIn公司將Kafka捐贈給Apache,現(xiàn)在已經(jīng)成為Apache的一個頂級項目了,Kafka作為一個高吞吐的分布式的消息系統(tǒng),目前已經(jīng)被很多公司應(yīng)用在實(shí)際的業(yè)務(wù)中了,并且與許多數(shù)據(jù)處理框架相結(jié)合,比如Hadoop,Spark等。
消息系統(tǒng)
在實(shí)際的業(yè)務(wù)需求中,我們需要處理各種各樣的消息,比如Page View,日志,請求等,那么一個好的消息系統(tǒng)應(yīng)該擁有哪些功能呢?
擁有消息發(fā)布和訂閱的功能,類似于消息隊列或者企業(yè)消息傳送系統(tǒng);
能存儲消息流,并具備容錯性;
能夠?qū)崟r的處理消息;
以上3點(diǎn)是作為一個好的消息系統(tǒng)的最基本的能力。
那么Kafka為什么會誕生呢?
其實(shí)在我們工作中,相信有很多也接觸過消息隊列,甚至自己也寫過簡單的消息系統(tǒng),它最基本應(yīng)該擁有發(fā)布/訂閱的功能,如下圖所示:
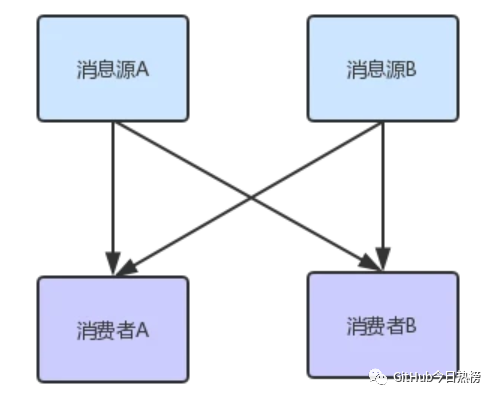
其中消費(fèi)者A與消費(fèi)者B都訂閱了消息源A和消息源B,這種模式很簡單,但是相對來說也有弊端,比如以下兩點(diǎn):
該模式下消費(fèi)者需要實(shí)時去處理消息,因?yàn)檫@里消息源和消費(fèi)者都不會維護(hù)一個消息隊列(維護(hù)代價太大),這將會導(dǎo)致消費(fèi)者若是暫時沒有能力消費(fèi),則消息會丟失,當(dāng)然也就不能獲得歷史的消息;
消息源需要維護(hù)原本不屬于它的工作,比如維護(hù)訂閱者(消費(fèi)者)的信息,向多個消費(fèi)者發(fā)送消息,亦或者有些還需要處理消息反饋,這是原本純粹的消息源就會變得越來越復(fù)雜;
當(dāng)然這些問題都是可以改進(jìn)的,比如我們可以在消息源和消費(fèi)者中間增加一個消息隊列,如下圖所示:
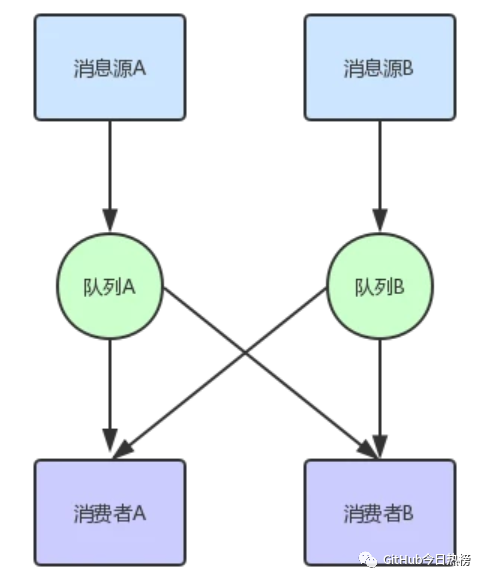
從圖中我們可以看出,現(xiàn)在消息源只需要將消息發(fā)送到消息隊列中就行,至于其他就將給消息隊列去完成,我們可以在消息隊列持久化消息,主動推消息給已經(jīng)訂閱了該消息隊列的消費(fèi)者,那么這種模式還有什么缺點(diǎn)嗎?
答案是有,上圖只是兩個消息隊列,我們維護(hù)起來并不困難,但是如果有成百上千個呢?那不得gg,其實(shí)我們可以發(fā)現(xiàn),消息隊列的功能都很類似,無非就是持久化消息,推送消息,給出反饋等功能,結(jié)構(gòu)也非常類似,主要是消息內(nèi)容,當(dāng)然如果要通用化,消息結(jié)構(gòu)也要盡可能通用化,與具體平臺具體語言無關(guān),比如用JSON格式等,所有我們可以演變出以下的消息系統(tǒng):
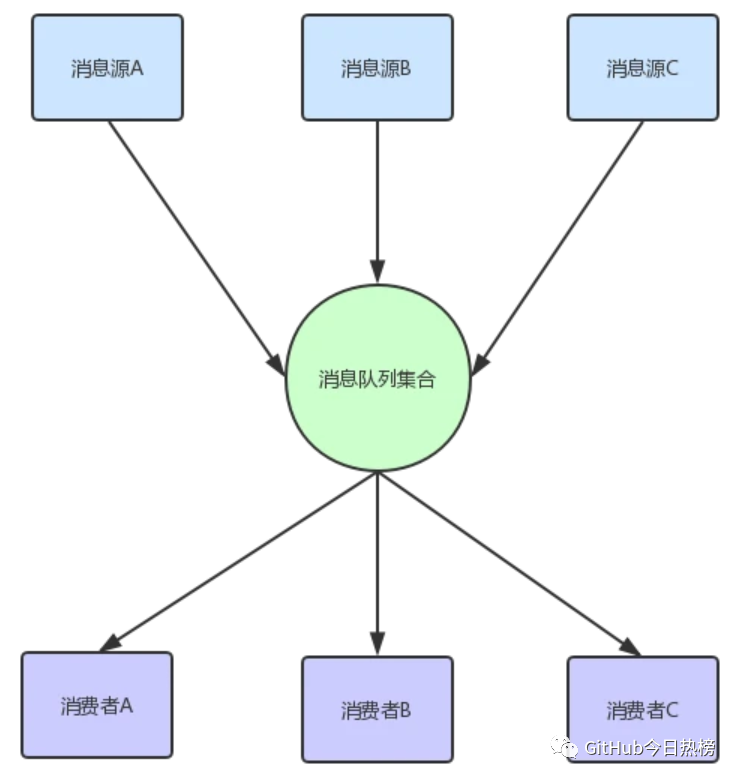
這個方式看起來只是把上面的隊列合并到了一起,其實(shí)并不那么簡單,因?yàn)檫@個消息隊列集合要具備以下幾個功能:
能統(tǒng)一管理所有的消息隊列,不是特殊需求不需要開發(fā)者自己去維護(hù);
高效率的存儲消息;
消費(fèi)者能快速的找到想要消費(fèi)的消息;
當(dāng)然這些只是最基本的功能,還有比如多節(jié)點(diǎn)容錯,數(shù)據(jù)備份等,一個好的消息系統(tǒng)需要處理的東西非常多,很慶幸,Kafka幫我們做到了。
Kafka
在具體了解Kafka的細(xì)節(jié)前,我們先來看一下它的一些基本概念:
Kafka是運(yùn)行在一個集群上,所以它可以擁有一個或多個服務(wù)節(jié)點(diǎn);
Kafka集群將消息存儲在特定的文件中,對外表現(xiàn)為Topics;
每條消息記錄都包含一個key,消息內(nèi)容以及時間戳;
從上面幾點(diǎn)我們大致可以推測Kafka是一個分布式的消息存儲系統(tǒng),那么它就僅僅這么點(diǎn)功能嗎,我們繼續(xù)看下面。
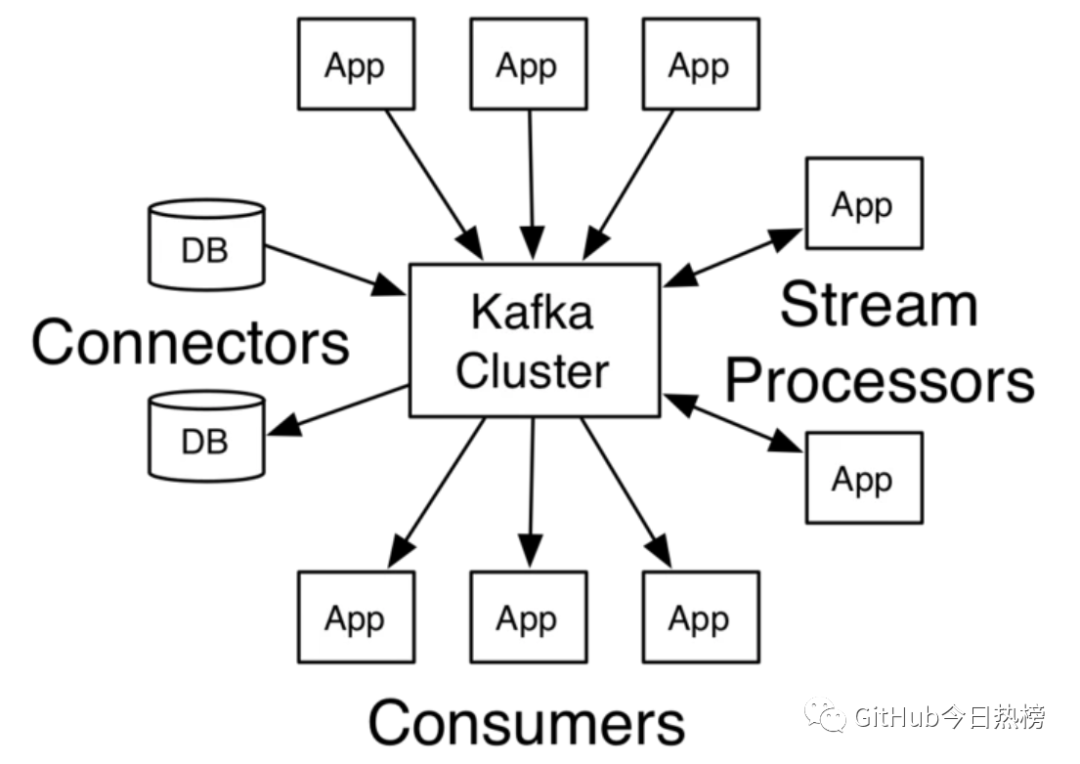
Kafka為了擁有更強(qiáng)大的功能,提供了四大核心接口:
Producer API允許了應(yīng)用可以向Kafka中的topics發(fā)布消息;
Consumer API允許了應(yīng)用可以訂閱Kafka中的topics,并消費(fèi)消息;
Streams API允許應(yīng)用可以作為消息流的處理者,比如可以從topicA中消費(fèi)消息,處理的結(jié)果發(fā)布到topicB中;
Connector API提供Kafka與現(xiàn)有的應(yīng)用或系統(tǒng)適配功能,比如與數(shù)據(jù)庫連接器可以捕獲表結(jié)構(gòu)的變化;
它們與Kafka集群的關(guān)系可以用下圖表示:
在了解了Kafka的一些基本概念后,我們具體來看看它的一些組成部分。
Topics
顧名思義Topics是一些主題的集合,更通俗的說Topic就像一個消息隊列,生產(chǎn)者可以向其寫入消息,消費(fèi)者可以從中讀取消息,一個Topic支持多個生產(chǎn)者或消費(fèi)者同時訂閱它,所以其擴(kuò)展性很好。Topic又可以由一個或多個partition(分區(qū))組成,比如下圖:
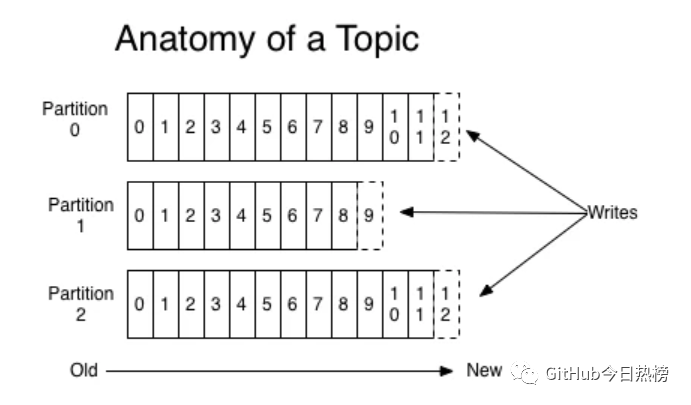
其中每個partition中的消息是有序的,但相互之間的順序就不能保證了,若Topic有多個partition,生產(chǎn)者的消息可以指定或者由系統(tǒng)根據(jù)算法分配到指定分區(qū),若你需要所有消息都是有序的,那么你最好只用一個分區(qū)。另外partition支持消息位移讀取,消息位移有消費(fèi)者自身管理,比如下圖:
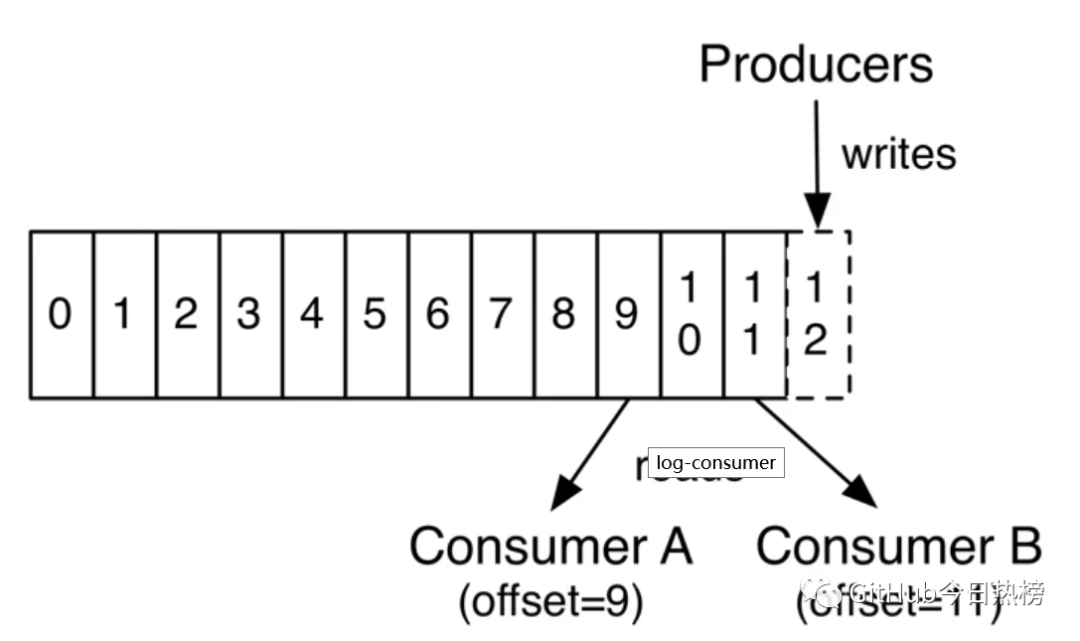
由上圖可以看出,不同消費(fèi)者對同一分區(qū)的消息讀取互不干擾,消費(fèi)者可以通過設(shè)置消息位移(offset)來控制自己想要獲取的數(shù)據(jù),比如可以從頭讀取,最新數(shù)據(jù)讀取,重讀讀取等功能。
關(guān)于Topic的分區(qū)策略以及與消費(fèi)者間平衡后續(xù)文章會繼續(xù)深入講解。
Distribution
上文說到過,Kafka是一個分布式的消息系統(tǒng),所以當(dāng)我們配置了多個Kafka Server節(jié)點(diǎn)后,它就擁有分布式的能力,比如容錯等,partition會被分布在各個Server節(jié)點(diǎn)上,同時它們中間又有一個leader,它會處理所有的讀寫請求,其他followers會復(fù)制leader上的數(shù)據(jù)信息,一旦當(dāng)leader因?yàn)槟承┕收隙鵁o法提供服務(wù)后,就會有一個follower被推舉出來成為新的leader來處理這些請求。
Geo-Replication
異地備份是作為主流分布式系統(tǒng)的基礎(chǔ)功能,用于集群中數(shù)據(jù)的備份和恢復(fù),Kafka利用MirrorMaker來實(shí)現(xiàn)這個功能,用戶只需簡單的進(jìn)行相應(yīng)配置即可。
Producers
Producers作為消息的生產(chǎn)者,可以自己指定將消息發(fā)布到訂閱Topic中的指定分區(qū),策略可以自己指定,比如語義或者結(jié)構(gòu)類似的消息發(fā)布在同一分區(qū),當(dāng)然也可以由系統(tǒng)循環(huán)發(fā)布在每一個分區(qū)上。
Consumers
Consumers是一群消費(fèi)者的集合,可以稱之為消費(fèi)者組,是一種更高層次的的抽象,向Topic訂閱消費(fèi)消息的單位是Consumers,當(dāng)然它其中也可以只有一個消費(fèi)者(consumer)。下面是關(guān)于consumer的兩條原則:
假如所有消費(fèi)者都在同一個消費(fèi)者組中,那么它們將協(xié)同消費(fèi)訂閱Topic的部分消息(根據(jù)分區(qū)與消費(fèi)者的數(shù)量分配),保存負(fù)載平衡;
假如所有消費(fèi)者都在不同的消費(fèi)者組中,并且訂閱了同個Topic,那么它們將可以消費(fèi)Topic的所有消息;
下面是一個簡單的例子,幫助大家理解:

上圖中有兩個Server節(jié)點(diǎn),有一個Topic被分為四個分區(qū)(P0-P4)分別被分配在兩個節(jié)點(diǎn)上,另外還有兩個消費(fèi)者組(GA,GB),其中GA有兩個消費(fèi)者實(shí)例,GB有四個消費(fèi)者實(shí)例。
從圖中我們可以看出,首先訂閱Topic的單位是消費(fèi)者組,另外我們發(fā)現(xiàn)Topic中的消息根據(jù)一定規(guī)則將消息推送給具體消費(fèi)者,主要原則如下:
若消費(fèi)者數(shù)小于partition數(shù),且消費(fèi)者數(shù)為一個,那么它就消費(fèi)所有消息;
若消費(fèi)者數(shù)小于partition數(shù),假設(shè)消費(fèi)者數(shù)為N,partition數(shù)為M,那么每個消費(fèi)者能消費(fèi)的分區(qū)數(shù)為M/N或M/N+1;
若消費(fèi)者數(shù)等于partition數(shù),那么每個消費(fèi)者都會均等分配到一個分區(qū)的消息;
若消費(fèi)者數(shù)大于partition數(shù),則將會出現(xiàn)部分消費(fèi)者得不到消息分區(qū),出現(xiàn)空閑的情況;
總的來說,Kafka會根據(jù)消費(fèi)者組的情況均衡分配消息,比如有消息著實(shí)例宕機(jī),亦或者有新的消費(fèi)者加入等情況。
Guarantees
kafka作為一個高水準(zhǔn)的系統(tǒng),提供了以下的保證:
消息的添加是有序的,生產(chǎn)者越早向訂閱的Topic發(fā)送的消息,會更早的被添加到Topic中,當(dāng)然它們可能被分配到不同的分區(qū);
消費(fèi)者在消費(fèi)Topic分區(qū)中的消息時是有序的;
對于有N個復(fù)制節(jié)點(diǎn)的Topic,系統(tǒng)可以最多容忍N(yùn)-1個節(jié)點(diǎn)發(fā)生故障,而不丟失任何提交給該Topic的消息丟失;
相關(guān)這些點(diǎn)的細(xì)節(jié),我準(zhǔn)備再后續(xù)文章中再慢慢深入。
Kafka as a Messaging System
說了這么多,前面也講了消息系統(tǒng)的演變過程,那么Kafka相比其他的消息系統(tǒng)優(yōu)勢具體在哪里?
傳統(tǒng)的消息系統(tǒng)模型主要有兩種:消息隊列和發(fā)布/訂閱。
1.消息隊列
| 特性 | 描述 |
|---|---|
| 表現(xiàn)形式 | 一組消費(fèi)者從消息隊列中獲取消息,消息會被推送給組中的某一個消費(fèi)者 |
| 優(yōu)勢 | 水平擴(kuò)展,可以將消息數(shù)據(jù)分開處理 |
| 劣勢 | 消息隊列不是多用戶的,當(dāng)一條消息記錄被一個進(jìn)程讀取后,消息便會丟失 |
2.發(fā)布/訂閱
| 特性 | 描述 |
|---|---|
| 表現(xiàn)形式 | 消息會廣播發(fā)送給所有消費(fèi)者 |
| 優(yōu)勢 | 可以多進(jìn)程共享消息 |
| 劣勢 | 每個消費(fèi)者都會獲得所有消息,無法通過添加消費(fèi)進(jìn)程提高處理效率 |
從上面兩個表中可以看出兩種傳統(tǒng)的消息系統(tǒng)模型的優(yōu)缺點(diǎn),所以Kafka在前人的肩膀上進(jìn)行了優(yōu)化,吸收他們的優(yōu)點(diǎn),主要體現(xiàn)在以下兩方面:
通過Topic方式來達(dá)到消息隊列的功能
通過消費(fèi)者組這種方式來達(dá)到發(fā)布/訂閱的功能
Kafka通過結(jié)合這兩點(diǎn)(這兩點(diǎn)的具體描述查看上面章節(jié)),完美的解決了它們兩者模式的缺點(diǎn)。
Kafka as a Storage System
存儲消息也是消息系統(tǒng)的一大功能,Kafka相對普通的消息隊列存儲來說,它的表現(xiàn)實(shí)在好的太多,首先Kafka支持寫入確認(rèn),保證消息寫入的正確性和連續(xù)性,同時Kafka還會對寫入磁盤的數(shù)據(jù)進(jìn)行復(fù)制備份,來實(shí)現(xiàn)容錯,另外Kafka對磁盤的使用結(jié)構(gòu)是一致的,就說說不管你的服務(wù)器目前磁盤存儲的消息數(shù)據(jù)有多少,它添加消息數(shù)據(jù)的效率是相同的。
Kafka的存儲機(jī)制很好的支持消費(fèi)者可以隨意控制自身所需要讀取的數(shù)據(jù),在很多時候你也可以將Kafka作為一個高性能,低延遲的分布式文件系統(tǒng)。
Kafka for Stream Processing
Kafka作為一個完美主義代表者,光有普通的讀寫,存儲等功能是不夠的,它還提供了實(shí)時處理消息流的接口。
很多時候原始的數(shù)據(jù)并不是我們想要的,我們想要的是經(jīng)過處理后的數(shù)據(jù)結(jié)果,比如通過一天的搜索數(shù)據(jù)得出當(dāng)天的搜索熱點(diǎn)等,你可以利用Streams API來實(shí)現(xiàn)自己想要的功能,比如從輸入Topic中獲取數(shù)據(jù),然后再發(fā)布到具體的輸出Topic中。
Kafka的流處理可以解決諸如處理無序數(shù)據(jù)、數(shù)據(jù)的復(fù)雜轉(zhuǎn)換等問題。
總結(jié)
消息傳遞、存儲、流處理這么功能單一來看確實(shí)很普通,但如何把它們完美的結(jié)合到一起,就是一種優(yōu)雅的體現(xiàn),Kafka做到了這一點(diǎn)。
相比HDFS分布式文件存儲系統(tǒng),雖然它能支持高效存儲并且批處理數(shù)據(jù),但是它只支持處理過去的歷史數(shù)據(jù)。
相比普通的消息系統(tǒng)來說,雖然能處理現(xiàn)在至未來的數(shù)據(jù),但是它并不沒有存儲歷史的數(shù)據(jù)。
Kafka集眾家之所長,使整個系統(tǒng)能兼顧各方面的需求,可以用一個詞來說:“完美”!
出處:segmentfault.com/a/1190000013834998
關(guān)注GitHub今日熱榜,專注挖掘好用的開發(fā)工具,致力于分享優(yōu)質(zhì)高效的工具、資源、插件等,助力開發(fā)者成長!
點(diǎn)個在看