
深入理解 Golang Map
Map 是一種常見(jiàn)的數(shù)據(jù)結(jié)構(gòu),通常用于存儲(chǔ)無(wú)序的鍵值對(duì)。在主流的編程語(yǔ)言中,默認(rèn)就自帶它的實(shí)現(xiàn)。
但是, Map 在編程語(yǔ)言?xún)?nèi)部是如何實(shí)現(xiàn)的呢?
同時(shí)我們可能還有以下一系列疑問(wèn):
如何判斷 Map 中是否包含某個(gè) key ?
Map 是如何實(shí)現(xiàn)增刪改查的?
Map 的擴(kuò)容時(shí)機(jī)是什么?擴(kuò)容策略是什么?
Map 是線程安全的嗎?
Map 概述
我們知道 Map 有以下幾個(gè)基本特點(diǎn):
Map 是一個(gè)無(wú)序的 key/value 集合;
Map 中所有的 key 都是不同的;
通過(guò)給定的 key ,可以在常數(shù)時(shí)間復(fù)雜度內(nèi)查找、更新或刪除相應(yīng)的 value。
哈希算法
處理哈希沖突
擴(kuò)容策略
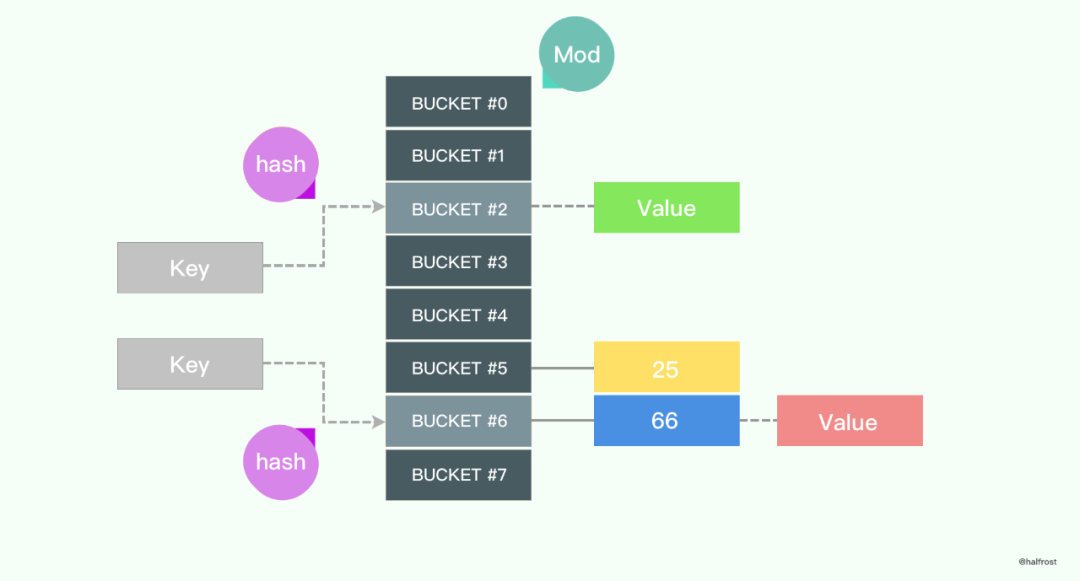
下圖是一個(gè)典型的通過(guò)給定 key 在 Map 中查找 value 的過(guò)程:
對(duì)于給定的 key,先進(jìn)行哈希運(yùn)算得到哈希值,然后按 Map 長(zhǎng)度取模,將 key 映射到指定的位置,最后取得相應(yīng)的 value。
哈希算法
什么是哈希算法?
哈希算法又稱(chēng) Hash 算法/哈希函數(shù)/散列算法,是一種將任意長(zhǎng)度的輸入數(shù)據(jù)轉(zhuǎn)換成較小的、固定長(zhǎng)度的輸出數(shù)據(jù)(哈希值/散列值)的方法。
哈希算法有以下特點(diǎn):
如果兩個(gè)哈希值不同,那么這兩個(gè)哈希值對(duì)應(yīng)的原始輸入肯定不同;
如果兩個(gè)哈希值相同,那么這兩個(gè)哈希值對(duì)應(yīng)的原始輸入可能相同,也可能不同(這種情況稱(chēng)為"哈希沖突/哈希碰撞/散列碰撞")。
Map 中為什么需要哈希算法?
Map 中使用哈希算法是為了實(shí)現(xiàn)快速查找和定位。
常見(jiàn)的哈希算法
下圖列舉了一些常見(jiàn)的哈希算法。
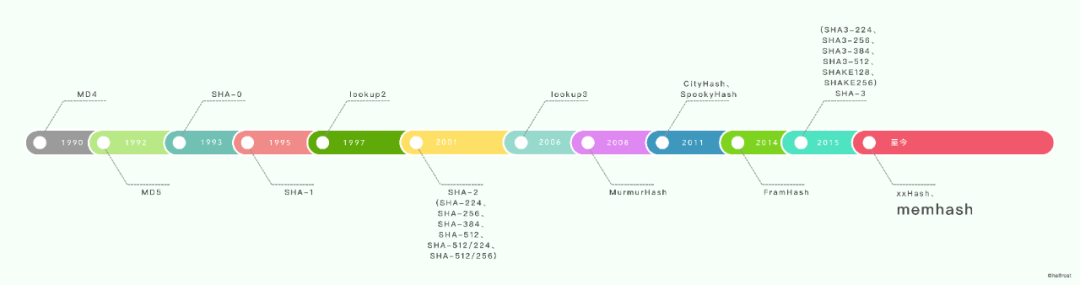
一些經(jīng)典的哈希算法:
MD4(RFC 1320) 是 MIT 的 Ronald L. Rivest 在 1990 年設(shè)計(jì)的。
MD5(RFC 1321) 是 Rivest 于1991年對(duì) MD4 的改進(jìn)版本。MD5 比 MD4 復(fù)雜,速度慢一點(diǎn),但更安全。
SHA-1(RFC 3174) 是由 NSA(美國(guó)國(guó)家安全局) 和 NIST(美國(guó)國(guó)家標(biāo)準(zhǔn)技術(shù)研究所)基于 MD4 的原理設(shè)計(jì)的。
一些現(xiàn)代的哈希算法:
Jenkins hash function 和 SpookyHash
這兩種哈希算法都是由 Bob Jenkins 設(shè)計(jì)的。MurmurHash
MurmurHash 是 Austin Appleby 在2008年發(fā)布的一種非加密型哈希算法。
當(dāng)前的版本是 MurmurHash3,在 Redis、Memcached、Cassandra、HBase、Lucene 等軟件中有著廣泛應(yīng)用。CityHash 和 FramHash
CityHash 是 2011年 Google 發(fā)布的一種非加密型哈希算法。2014 年 Google 又發(fā)布了 FarmHash,它從 CityHash 繼承了許多技巧和技術(shù)。
xxHash
xxHash 是由 Yann Collet 設(shè)計(jì)的非加密哈希算法。它最初用于 LZ4 壓縮算法,用于檢查簽名。它被廣泛使用在 PrestoDB、RocksDB、MySQL、ArangoDB、PGroonga、Spark 等數(shù)據(jù)庫(kù)中,還用在了 Cocos2D、Dolphin、Cxbx-reloaded 等游戲框架中。
下圖是不同哈希算法的性能對(duì)比,測(cè)試環(huán)境是 Open-Source SMHasher program by Austin Appleby ,在 Windows 7 上通過(guò) Visual C 編譯,只有一個(gè)線程,CPU 內(nèi)核是 Core 2 Duo @3.0GHz。
其中,第一欄是哈希算法名稱(chēng),第二欄是速度的對(duì)比,第三欄是哈希質(zhì)量。從表中數(shù)據(jù)看,質(zhì)量最高、速度最快的是 xxHash。

Golang 使用的哈希算法
Golang 選擇哈希算法時(shí),根據(jù) CPU 是否支持 AES 指令集進(jìn)行判斷 ,如果 CPU 支持 AES 指令集,則使用 Aes Hash,否則使用 memhash。
AES Hash
AES 指令集全稱(chēng)是高級(jí)加密標(biāo)準(zhǔn)指令集(或稱(chēng)英特爾高級(jí)加密標(biāo)準(zhǔn)新指令,簡(jiǎn)稱(chēng)AES-NI),是一個(gè) x86指令集架構(gòu)的擴(kuò)展,用于 Intel 和 AMD 處理器。
利用 AES 指令集實(shí)現(xiàn)哈希算法性能很優(yōu)秀,因?yàn)樗芴峁┯布铀佟?/p>
查看 CPU 是否支持 AES 指令集:
$ cat /proc/cpuinfo | grep aes
flags : fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush mmx fxsr sse sse2 ss syscall nx pdpe1gb rdtscp lm constant_tsc rep_good nopl eagerfpu pni pclmulqdq ssse3 fma cx16 pcid sse4_1 sse4_2 x2apic movbe popcnt tsc_deadline_timer aes xsave avx f16c rdrand hypervisor lahf_lm abm 3dnowprefetch fsgsbase bmi1 hle avx2 smep bmi2 erms invpcid rtm rdseed adx smap xsaveopt
相關(guān)代碼:
runtime/alg.go
asm_amd64.s
asm_arm64.s
memhash
網(wǎng)上沒(méi)有找到這個(gè)哈希算法的作者信息,只在 Golang 的源碼中有這幾行注釋?zhuān)f(shuō)它的靈感來(lái)源于 xxhash 和 cityhash。
// Hashing algorithm inspired by
// xxhash: https://code.google.com/p/xxhash/
// cityhash: https://code.google.com/p/cityhash/
相關(guān)代碼:
runtime/hash64.go
runtime/hash32.go
處理哈希沖突
通常情況下,哈希算法的輸入范圍一定會(huì)遠(yuǎn)遠(yuǎn)大于輸出范圍,所以當(dāng)輸入的 key 足夠多時(shí)一定會(huì)遇到?jīng)_突,這時(shí)就需要一些方法來(lái)解決哈希沖突問(wèn)題。
最常見(jiàn)的處理哈希沖突方法是鏈地址法和開(kāi)放地址法。Golang 及多數(shù)編程語(yǔ)言都使用鏈地址法處理哈希沖突。
鏈地址法
鏈地址法是處理哈希沖突最常見(jiàn)的方法,它的實(shí)現(xiàn)比開(kāi)放地址法稍微復(fù)雜一些,但平均查找長(zhǎng)度較短,用于存儲(chǔ)節(jié)點(diǎn)的內(nèi)存是動(dòng)態(tài)申請(qǐng)的,可以節(jié)省較多內(nèi)存。
鏈地址法一般使用數(shù)組加上鏈表實(shí)現(xiàn),有些語(yǔ)言會(huì)引入紅黑樹(shù)以?xún)?yōu)化性能。

鏈地址法寫(xiě)入數(shù)據(jù)
如上圖所示,要將一個(gè)鍵值對(duì) (Key6, Value6) 寫(xiě)入哈希表,需要經(jīng)過(guò)兩個(gè)步驟:
鍵值對(duì)中的鍵 Key6 先經(jīng)過(guò) Hash 算法計(jì)算,返回的哈希值定位到一個(gè)桶,選擇桶的方式是對(duì)哈希值取模:
index := hash("Key6") % array.len
選擇了 2 號(hào)桶之后,遍歷當(dāng)前桶中的鏈表,在遍歷鏈表的過(guò)程中會(huì)遇到以下兩種情況:
1. 找到鍵相同的鍵值對(duì),則更新鍵對(duì)應(yīng)的值;
2. 沒(méi)有找到鍵相同的鍵值對(duì),則在鏈表的末尾追加新鍵值對(duì)。
鏈地址法讀取數(shù)據(jù)

如上圖所示,查找 Key11 時(shí),需要經(jīng)過(guò)兩個(gè)步驟:
鍵 Key11 經(jīng)過(guò)哈希算法計(jì)算,返回的哈希值定位到 4 號(hào)桶;
遍歷 4 號(hào)桶中的鏈表,然而遍歷到鏈表末尾也未找到期望的 Key11,所以 Map 中沒(méi)有 Key11 對(duì)應(yīng)的值。
開(kāi)放地址法
開(kāi)放地址方法的核心思想是:對(duì)數(shù)組中的元素依次探測(cè)和比較,以判斷目標(biāo)鍵值對(duì)是否存在于 Map 中。
如果我們使用開(kāi)放地址法來(lái)實(shí)現(xiàn)哈希表,那么支撐 Map 的數(shù)據(jù)結(jié)構(gòu)就是數(shù)組。不過(guò)因?yàn)閿?shù)組的長(zhǎng)度有限,存儲(chǔ) (Key3, Value3) 這個(gè)鍵值對(duì)時(shí)會(huì)從如下的索引開(kāi)始遍歷:
index := hash("Key3") % array.len
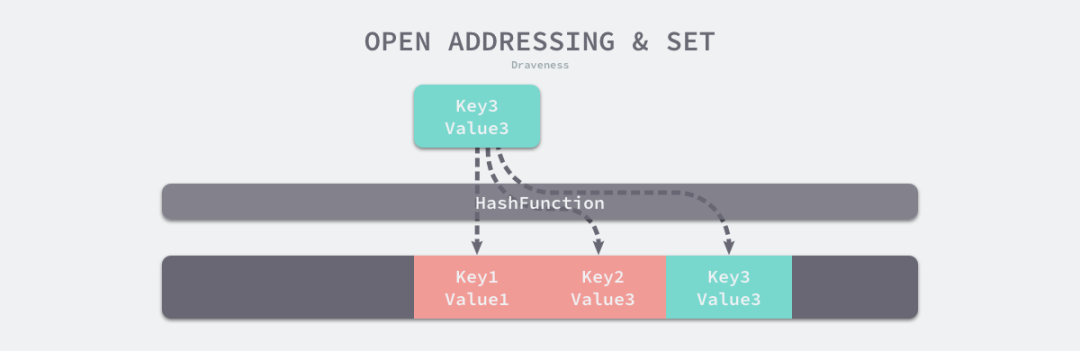
當(dāng)我們向當(dāng)前 Map 寫(xiě)入新數(shù)據(jù)時(shí)發(fā)生了沖突,就將鍵值對(duì)寫(xiě)入到下一個(gè)不為空的位置。
如上圖所示,當(dāng) Key3 的索引與已存在的 Key1 和 Key2 發(fā)生沖突時(shí),Key3 會(huì)被寫(xiě)入 Key2 后面的空閑內(nèi)存中。
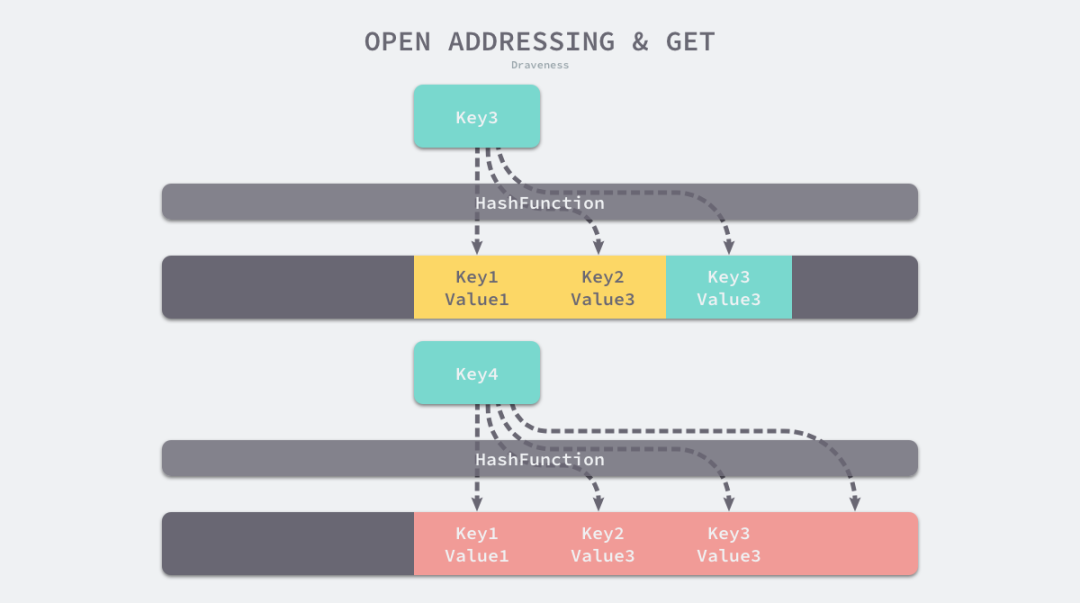
當(dāng)我們讀取 Key3 對(duì)應(yīng)的值時(shí),先對(duì) Key3 進(jìn)行哈希計(jì)算并取模,幫我們找到 Key1,因?yàn)?Key1 與我們期望的鍵 Key3 不匹配,所以會(huì)繼續(xù)查找后面的元素,直到內(nèi)存為空或者找到目標(biāo)元素。
開(kāi)放地址法中對(duì)性能影響最大的是裝載因子,它是數(shù)組中元素的數(shù)量與數(shù)組大小的比值。
隨著裝載因子的增加,線性探測(cè)的平均用時(shí)會(huì)逐漸增加,這會(huì)影響 Map 的讀寫(xiě)性能。當(dāng)裝載率超過(guò) 70% 之后,Map 的性能會(huì)急劇下降。而一旦裝載率達(dá)到 100%,查找任意 Key 都需要遍歷整個(gè) Map,所以在實(shí)現(xiàn) Map 時(shí)要時(shí)刻關(guān)注裝載因子的變化。
擴(kuò)容策略
隨著 Map 中元素的增加,發(fā)生哈希沖突的概率會(huì)增加,Map 的讀寫(xiě)性能也會(huì)下降,所以我們需要更多的桶和更大的內(nèi)存來(lái)保證 Map 的讀寫(xiě)性能。
在實(shí)際應(yīng)用中,當(dāng)裝載因子超過(guò)某個(gè)閾值時(shí),會(huì)動(dòng)態(tài)地增加 Map 長(zhǎng)度,實(shí)現(xiàn)自動(dòng)擴(kuò)容。
每當(dāng) Map 長(zhǎng)度發(fā)生變化后,所有 key 在 Map 中對(duì)應(yīng)的索引需要重新計(jì)算。如果一個(gè)一個(gè)計(jì)算原 Map 中的 key 的索引并插入到新 Map 中,這種一次性擴(kuò)容方式是達(dá)不到生產(chǎn)環(huán)境的要求的,因?yàn)闀r(shí)間復(fù)雜度太高了O(n),在數(shù)據(jù)量大的情況下性能會(huì)很差。
在實(shí)際應(yīng)用中,Map 擴(kuò)容都是分多次、漸進(jìn)式地完成,而不是一性次完成擴(kuò)容。
Golang Map的具體實(shí)現(xiàn)
下面我們來(lái)探索一下 Golang 是如何實(shí)現(xiàn) Map 的。
Golang Map 的具體實(shí)現(xiàn)在 /src/runtime/map.go 文件中。
常量定義
const (
// 一個(gè)桶里最多可以裝載的鍵值對(duì)數(shù)量:8對(duì)
bucketCntBits = 3
bucketCnt = 1 << bucketCntBits
// 觸發(fā)擴(kuò)容操作的裝載因子臨界值是:13 / 2 = 6.5
loadFactorNum = 13
loadFactorDen = 2
// 為保持內(nèi)聯(lián),key 和 value 的最大長(zhǎng)度都是 128 字節(jié),如果超過(guò)了 128 字節(jié),就存儲(chǔ)它的指針
maxKeySize = 128
maxElemSize = 128
// 數(shù)據(jù)偏移
dataOffset = unsafe.Offsetof(struct {
b bmap
v int64
}{}.v)
// tophash 的一些特殊值
emptyRest = 0 // this cell is empty, and there are no more non-empty cells at higher indexes or overflows.
emptyOne = 1 // this cell is empty
evacuatedX = 2 // key/elem is valid. Entry has been evacuated to first half of larger table.
evacuatedY = 3 // same as above, but evacuated to second half of larger table.
evacuatedEmpty = 4 // cell is empty, bucket is evacuated.
minTopHash = 5 // minimum tophash for a normal filled cell.
// 其他標(biāo)記
iterator = 1 // there may be an iterator using buckets
oldIterator = 2 // there may be an iterator using oldbuckets
hashWriting = 4 // a goroutine is writing to the map
sameSizeGrow = 8 // the current map growth is to a new map of the same size
// 迭代檢查桶 id 的哨兵
noCheck = 1<<(8*sys.PtrSize) - 1
)
Golang 觸發(fā)擴(kuò)容操作的裝載因子臨界值 6.5 是怎么得來(lái)的?
這個(gè)值太大會(huì)導(dǎo)致溢出桶(overflow buckets)過(guò)多,查找效率降低,過(guò)小則會(huì)浪費(fèi)存儲(chǔ)空間。
據(jù) Google 開(kāi)發(fā)人員稱(chēng),這個(gè)值是一個(gè)測(cè)試程序測(cè)量出來(lái)的一個(gè)經(jīng)驗(yàn)值。

%overflow :溢出率,平均每個(gè)桶(bucket)有多少鍵值對(duì) key/value 時(shí)會(huì)溢出。
bytes/entry :存儲(chǔ)一個(gè)鍵值對(duì) key/value 時(shí), 所需的額外存儲(chǔ)空間(字節(jié))。
hitprobe :查找一個(gè)存在的 key 時(shí),所需的平均查找次數(shù)。
missprobe :查找一個(gè)不存在的 key 時(shí),所需的平均查找次數(shù)。
經(jīng)過(guò)這幾組測(cè)試數(shù)據(jù),最終選定 6.5 作為臨界的裝載因子。
map header 定義
// A header for a Go map.
type hmap struct {
// Note: the format of the hmap is also encoded in cmd/compile/internal/gc/reflect.go.
// Make sure this stays in sync with the compiler's definition.
count int // map 長(zhǎng)度
flags uint8
B uint8 // log 以 2 為底,桶個(gè)數(shù)的對(duì)數(shù),即最多能存儲(chǔ) 6.5 * 2^B 個(gè)元素
noverflow uint16 // 溢出桶個(gè)數(shù)的近似數(shù)
hash0 uint32 // 哈希種子
buckets unsafe.Pointer // 有 2^B 個(gè)桶的數(shù)組. count=0 時(shí),這個(gè)數(shù)組為 nil.
oldbuckets unsafe.Pointer // 舊桶數(shù)組
nevacuate uintptr // 擴(kuò)容遷移過(guò)程的計(jì)數(shù)器
extra *mapextra // 可選字段
}
在 Golang 的 map header 結(jié)構(gòu)中,包含 2 個(gè)指向桶數(shù)組的指針,buckets 指向新的桶數(shù)組,oldbuckets 指向舊的桶數(shù)組。
oldbuckets 在哈希表擴(kuò)容時(shí)用于保存舊桶數(shù)據(jù),它的大小是當(dāng)前 buckets 的一半。
hmap 的最后一個(gè)字段是一個(gè)指向 mapextra 結(jié)構(gòu)的指針,它的定義如下:
// mapextra holds fields that are not present on all maps.
type mapextra struct {
// If both key and elem do not contain pointers and are inline, then we mark bucket
// type as containing no pointers. This avoids scanning such maps.
// However, bmap.overflow is a pointer. In order to keep overflow buckets
// alive, we store pointers to all overflow buckets in hmap.extra.overflow and hmap.extra.oldoverflow.
// overflow and oldoverflow are only used if key and elem do not contain pointers.
// overflow contains overflow buckets for hmap.buckets.
// oldoverflow contains overflow buckets for hmap.oldbuckets.
// The indirection allows to store a pointer to the slice in hiter.
overflow *[]*bmap
oldoverflow *[]*bmap
// nextOverflow holds a pointer to a free overflow bucket.
nextOverflow *bmap
}

如上圖所示 Map 里的桶就是 bmap,每一個(gè) bmap 能存儲(chǔ) 8 個(gè)鍵值對(duì)。
當(dāng) Map 中存儲(chǔ)的數(shù)據(jù)過(guò)多,單個(gè)桶裝滿(mǎn)時(shí)就會(huì)使用 extra.overflow 中的桶存儲(chǔ)溢出的數(shù)據(jù)。上圖中黃色的 bmap 是正常桶,綠色的 bmap 是溢出桶。
桶的結(jié)構(gòu)體 bmap 定義
// A bucket for a Go map.
type bmap struct {
// tophash generally contains the top byte of the hash value
// for each key in this bucket. If tophash[0] < minTopHash,
// tophash[0] is a bucket evacuation state instead.
tophash [bucketCnt]uint8
// Followed by bucketCnt keys and then bucketCnt elems.
// NOTE: packing all the keys together and then all the elems together makes the
// code a bit more complicated than alternating key/elem/key/elem/... but it allows
// us to eliminate padding which would be needed for, e.g., map[int64]int8.
// Followed by an overflow pointer.
}
bmap 結(jié)構(gòu)體其實(shí)不止包含 tophash 字段,由于 Map 中可能存儲(chǔ)不同類(lèi)型的鍵值對(duì),并且 Golang 不支持泛型,所以鍵值對(duì)占據(jù)的內(nèi)存空間大小只能在編譯時(shí)進(jìn)行推導(dǎo),這些額外字段在運(yùn)行時(shí)都是通過(guò)計(jì)算內(nèi)存地址的方式直接訪問(wèn)的,所以 bmap 的定義中就沒(méi)有包含這些額外的字段。
Golang 會(huì)在編譯期間的 /src/cmd/compile/internal/gc/reflect.go 重建 bmap 的結(jié)構(gòu):
type bmap struct {
topbits [8]uint8
keys [8]keytype
values [8]valuetype
pad uintptr
overflow uintptr
}
編譯期間還會(huì)生成 maptype 結(jié)構(gòu)體, 它定義在 runtime/type.go 文件中:
type maptype struct {
typ _type
key *_type
elem *_type
bucket *_type // internal type representing a hash bucket
// function for hashing keys (ptr to key, seed) -> hash
hasher func(unsafe.Pointer, uintptr) uintptr
keysize uint8 // size of key slot
elemsize uint8 // size of elem slot
bucketsize uint16 // size of bucket
flags uint32
}
下面我們來(lái)看一下整體的 Map 結(jié)構(gòu)圖

bmap 是存放 key/value 的地方,我們把視角拉近,仔細(xì)看看 bmap 的內(nèi)部組成。

上圖是桶的內(nèi)存模型,HOB Hash 指的是 tophash。注意到 key 和 value 是各自放在一起的,并不是 key/value/key/value/... 這樣的形式。
這種形式的好處是在某些情況下可以省略掉 padding 字段,節(jié)省內(nèi)存。
例如,有這樣一個(gè)類(lèi)型的 map:
map[int64]int8
如果按照 key/value/key/value/... 這樣的形式存儲(chǔ),為了內(nèi)存對(duì)齊,在每一對(duì) key/value 后面都要額外 padding 7 個(gè)字節(jié);
而將所有的 key,value 分別綁定到一起,這種形式 key/key/.../value/value/...,則只需要在最后添加 padding。
新建 Map
新建 Map 實(shí)際上底層調(diào)用的是 makemap 函數(shù),主要工作就是分配內(nèi)存并初始化 hmap 結(jié)構(gòu)體的各種字段,例如計(jì)算 B 的大小,設(shè)置哈希種子 hash0 等等。
在 B 不為 0 的情況下,會(huì)調(diào)用 makeBucketArray 函數(shù)初始化桶。
當(dāng) B < 4 的時(shí)候,初始化 hmap 只會(huì)生成 8 個(gè)桶,不生成溢出桶,因?yàn)閿?shù)據(jù)少幾乎不可能用到溢出桶;
當(dāng) B >= 4 的時(shí)候,會(huì)額外創(chuàng)建 2^(B?4) 個(gè)溢出桶。
key 經(jīng)過(guò) Hash 計(jì)算后得到 64 位哈希值(64位機(jī)器);
用哈希值最后 B 個(gè) bit 位計(jì)算它落在哪個(gè)桶;
用哈希值高 8 位計(jì)算它在桶中的索引位置。
還記得前面提到過(guò)的 B 嗎?如果 B = 5,那么桶的總數(shù)是 2^5 = 32。
例如,現(xiàn)在有一個(gè) key 經(jīng)過(guò) Hash 計(jì)算后,得到的哈希值是:
10010111 | 000011110110110010001111001010100010010110010101010 │ 01010
取最后的 5 個(gè) bit 位,也就是 01010,值為 10,定位到第 10 號(hào)桶。這個(gè)操作實(shí)際上就是取余操作,但是取余開(kāi)銷(xiāo)大,所以代碼實(shí)現(xiàn)上用位操作代替。
再用哈希值的高 8 位,找到此 key 在當(dāng)前桶(10號(hào)桶)中的索引位置。如果當(dāng)前桶內(nèi)還沒(méi)有 key,新加入的 key 會(huì)放入第一個(gè)空位。
當(dāng)兩個(gè)不同的 key 落在同一個(gè)桶中,也就發(fā)生了哈希沖突。解決哈希沖突的方式是用鏈地址法:在當(dāng)前桶中從前往后找,直到找到到第一個(gè)空位。
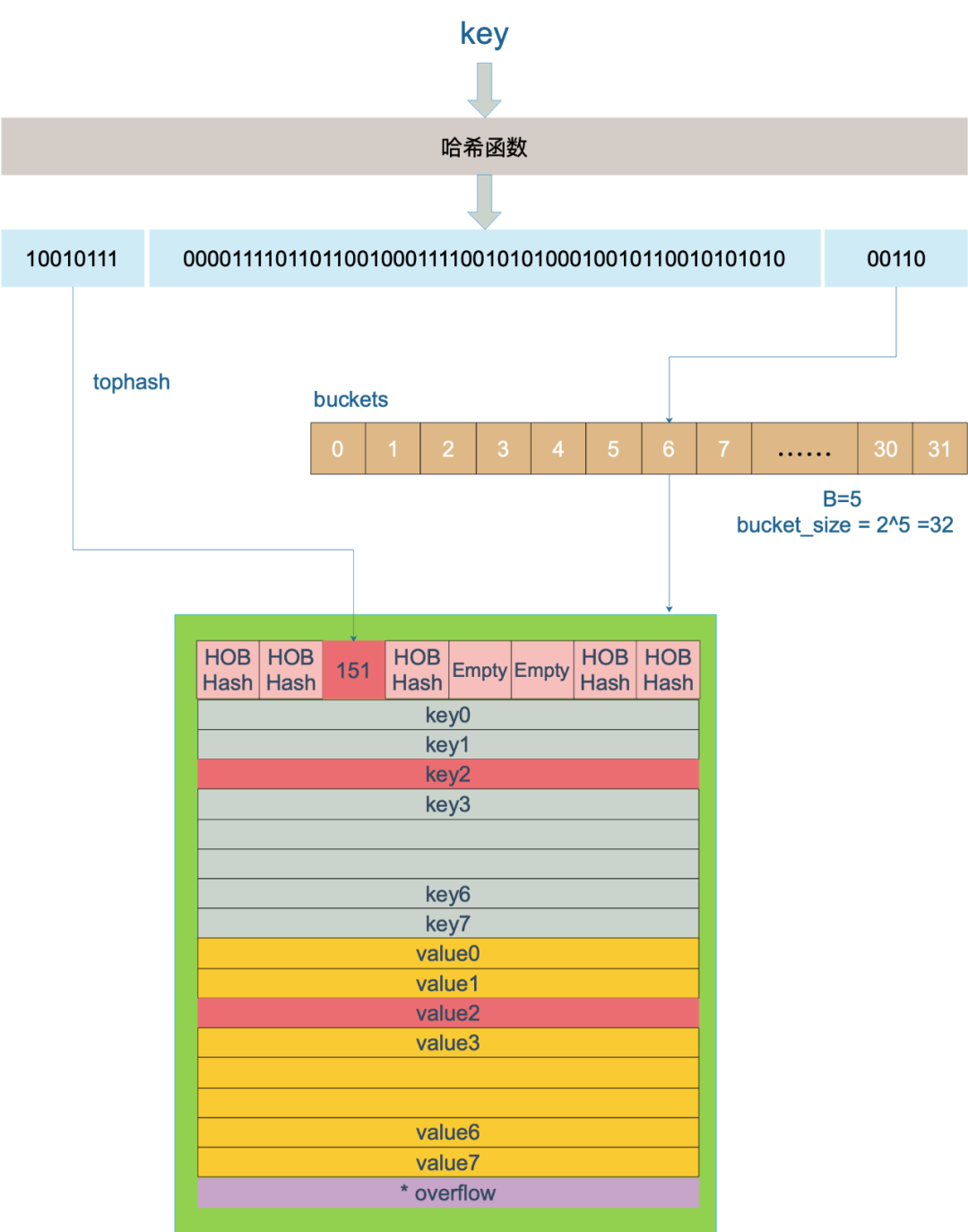
以上圖為例,查找 key 的過(guò)程是:
上圖假定 B = 5,所以桶總數(shù)是 2^5 = 32;
計(jì)算出待查找 key 的哈希值;
使用低 5 位 00110,找到對(duì)應(yīng)的 6 號(hào)桶;
使用高 8 位 10010111(對(duì)應(yīng)十進(jìn)制 151),在 6 號(hào)桶中尋找 tophash 值(HOB hash)為 151 的 key,找到了 2 號(hào)槽位。
如果在當(dāng)前6號(hào)桶中沒(méi)找到 key,并且溢出桶不為空,則還要繼續(xù)去溢出桶中尋找,直到找到 key 或者遍歷完所有槽位。
源碼中查找 key 的函數(shù)是 mapaccess 系列函數(shù),我們看看 mapaccess1 函數(shù)。
func mapaccess1(t *maptype, h *hmap, key unsafe.Pointer) unsafe.Pointer {
if raceenabled && h != nil {
// 獲取 caller 的 程序計(jì)數(shù)器 program counter
callerpc := getcallerpc()
// 獲取 mapaccess1 的程序計(jì)數(shù)器 program counter
pc := funcPC(mapaccess1)
racereadpc(unsafe.Pointer(h), callerpc, pc)
raceReadObjectPC(t.key, key, callerpc, pc)
}
if msanenabled && h != nil {
msanread(key, t.key.size)
}
// h 為空,返回零值
if h == nil || h.count == 0 {
if t.hashMightPanic() {
t.hasher(key, 0) // see issue 23734
}
return unsafe.Pointer(&zeroVal[0])
}
// 多線程讀寫(xiě),直接拋出異常
if h.flags&hashWriting != 0 {
throw("concurrent map read and map write")
}
// 計(jì)算 key 的哈希值
hash := t.hasher(key, uintptr(h.hash0))
// 低位掩碼,hash&m 即可算出 key 在哪個(gè)桶
m := bucketMask(h.B)
// b 就是桶的地址
b := (*bmap)(add(h.buckets, (hash&m)*uintptr(t.bucketsize)))
// oldbuckets 不為 nil,說(shuō)明發(fā)生了擴(kuò)容
if c := h.oldbuckets; c != nil {
// 當(dāng)前擴(kuò)容不是等量擴(kuò)容
if !h.sameSizeGrow() {
// 如果 oldbuckets 未遷移完成 則找找 oldbuckets 中對(duì)應(yīng)的 bucket(低 B-1 位)
// 否則為 buckets 中的 bucket(低 B 位)
// 把 mask 縮小 1 倍
// There used to be half as many buckets; mask down one more power of two.
m >>= 1
}
// 計(jì)算 key 在舊桶中的位置
oldb := (*bmap)(add(c, (hash&m)*uintptr(t.bucketsize)))
// 如果沒(méi)有遷移到新桶,那就在舊桶中尋找
if !evacuated(oldb) {
b = oldb
}
}
// 取出 hash 值的高 8 位
top := tophash(hash)
bucketloop:
for ; b != nil; b = b.overflow(t) {
for i := uintptr(0); i < bucketCnt; i++ {
// 如果 hash 的高 8 位和當(dāng)前 key 不同,就找下一個(gè)
// 這樣比較很高效,因?yàn)橹恍枰容^高 8 位,不用比較所有的 hash 值
// 如果高 8 位不同,則 hash 值肯定不同;如果高 8 位相同,則要比較整個(gè) hash 值
if b.tophash[i] != top {
if b.tophash[i] == emptyRest {
break bucketloop
}
continue
}
// tophash 匹配,定位到 key 的位置
k := add(unsafe.Pointer(b), dataOffset+i*uintptr(t.keysize))
if t.indirectkey() {
k = *((*unsafe.Pointer)(k))
}
// key 相等
if t.key.equal(key, k) {
// 定位到 value 的位置
e := add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.keysize)+i*uintptr(t.elemsize))
if t.indirectelem() {
e = *((*unsafe.Pointer)(e))
}
return e
}
}
}
// 返回零值
return unsafe.Pointer(&zeroVal[0])
}
這里說(shuō)一下定位 key 和 value 的方法:
// key 定位公式
k := add(unsafe.Pointer(b), dataOffset+i*uintptr(t.keysize))
// value 定位公式
v := add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.keysize)+i*uintptr(t.valuesize))
b 是 bmap 的地址,這里 bmap 還是源碼里定義的結(jié)構(gòu)體,只包含一個(gè) tophash 數(shù)組。dataOffset 是 key 相對(duì)于 bmap 起始地址的偏移:
dataOffset = unsafe.Offsetof(struct {
b bmap
v int64
}{}.v)
桶里 key 的起始地址是:unsafe.Pointer(b) + dataOffset;
第 i 個(gè) key 的地址就要在此基礎(chǔ)上跨過(guò) i 個(gè) key 的大小;
value 的地址是在所有 key 之后,因此第 i 個(gè) value 的地址還需要加上所有 key 的偏移。
插入 Key
插入 key 的過(guò)程和查找 key 的過(guò)程大體一致。
源碼中插入相關(guān)的是 mapassign 函數(shù)。
// Like mapaccess, but allocates a slot for the key if it is not present in the map.
func mapassign(t *maptype, h *hmap, key unsafe.Pointer) unsafe.Pointer {
if h == nil {
panic(plainError("assignment to entry in nil map"))
}
if raceenabled {
// 獲取 caller 的 程序計(jì)數(shù)器 program counter
callerpc := getcallerpc()
// 獲取 mapassign 的程序計(jì)數(shù)器 program counter
pc := funcPC(mapassign)
racewritepc(unsafe.Pointer(h), callerpc, pc)
raceReadObjectPC(t.key, key, callerpc, pc)
}
if msanenabled {
msanread(key, t.key.size)
}
// 如果多線程讀寫(xiě),直接拋出異常
if h.flags&hashWriting != 0 {
throw("concurrent map writes")
}
// 計(jì)算 key 值的 hash 值
hash := t.hasher(key, uintptr(h.hash0))
// Set hashWriting after calling t.hasher, since t.hasher may panic,
// in which case we have not actually done a write.
h.flags ^= hashWriting
// 如果 hmap 的桶的個(gè)數(shù)為0,那么就新建一個(gè)桶
if h.buckets == nil {
h.buckets = newobject(t.bucket) // newarray(t.bucket, 1)
}
again:
// 計(jì)算 key 所在的桶
bucket := hash & bucketMask(h.B)
// 如果還在擴(kuò)容中,繼續(xù)擴(kuò)容
if h.growing() {
growWork(t, h, bucket)
}
// b 就是 bucket 的地址
b := (*bmap)(unsafe.Pointer(uintptr(h.buckets) + bucket*uintptr(t.bucketsize)))
// hash 值的高 8 位
top := tophash(hash)
var inserti *uint8
var insertk unsafe.Pointer
var elem unsafe.Pointer
bucketloop:
for {
// 遍歷當(dāng)前桶所有鍵值,查找 key 對(duì)應(yīng)的 value
for i := uintptr(0); i < bucketCnt; i++ {
if b.tophash[i] != top {
if isEmpty(b.tophash[i]) && inserti == nil {
// 如果往后找都沒(méi)有找到,這里先記錄一個(gè)標(biāo)記,方便找不到以后插入到這里
inserti = &b.tophash[i]
// 計(jì)算出偏移 i 個(gè) key 值的位置
insertk = add(unsafe.Pointer(b), dataOffset+i*uintptr(t.keysize))
// 計(jì)算 value 所在的位置,當(dāng)前桶的首地址 + 8個(gè) key 值所占的大小 + i 個(gè) value 值所占的大小
elem = add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.keysize)+i*uintptr(t.elemsize))
}
if b.tophash[i] == emptyRest {
break bucketloop
}
continue
}
// 計(jì)算 key 的位置
k := add(unsafe.Pointer(b), dataOffset+i*uintptr(t.keysize))
if t.indirectkey() {
k = *((*unsafe.Pointer)(k))
}
// 比較 key 值是否相等
if !t.key.equal(key, k) {
continue
}
// already have a mapping for key. Update it.
if t.needkeyupdate() {
typedmemmove(t.key, k, key)
}
// 計(jì)算 value 所在的位置
elem = add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.keysize)+i*uintptr(t.elemsize))
goto done
}
ovf := b.overflow(t)
if ovf == nil {
break
}
b = ovf
}
// Did not find mapping for key. Allocate new cell & add entry.
// If we hit the max load factor or we have too many overflow buckets,
// and we're not already in the middle of growing, start growing.
if !h.growing() && (overLoadFactor(h.count+1, h.B) || tooManyOverflowBuckets(h.noverflow, h.B)) {
hashGrow(t, h)
goto again // Growing the table invalidates everything, so try again
}
// 如果找不到一個(gè)空的位置可以插入 key 值
if inserti == nil {
// 意味著當(dāng)前桶已經(jīng)全部滿(mǎn)了,那么就生成一個(gè)新的
// all current buckets are full, allocate a new one.
newb := h.newoverflow(t, b)
inserti = &newb.tophash[0]
insertk = add(unsafe.Pointer(newb), dataOffset)
elem = add(insertk, bucketCnt*uintptr(t.keysize))
}
// store new key/elem at insert position
if t.indirectkey() {
kmem := newobject(t.key)
*(*unsafe.Pointer)(insertk) = kmem
insertk = kmem
}
if t.indirectelem() {
vmem := newobject(t.elem)
*(*unsafe.Pointer)(elem) = vmem
}
typedmemmove(t.key, insertk, key)
*inserti = top
h.count++
done:
if h.flags&hashWriting == 0 {
throw("concurrent map writes")
}
h.flags &^= hashWriting
if t.indirectelem() {
elem = *((*unsafe.Pointer)(elem))
}
return elem
}
插入 key 的過(guò)程和查找 key 有幾點(diǎn)不同:
如果找到了待插入的 key ,則直接更新對(duì)應(yīng)的 value 值;
會(huì)在 oldbucket 中查找 key,但不會(huì)在 oldbucket 中插入 key。
如果在 bmap 中沒(méi)有找到待插入的 key ,這時(shí)分兩種情況:
情況一:bmap 中還有空位,在遍歷 bmap 的時(shí)候預(yù)先標(biāo)記可插入的空位,如果查找結(jié)束也沒(méi)有找到 key,就把 key 放到預(yù)先標(biāo)記的空位上。 情況二:bmap中沒(méi)有空位了,此時(shí)檢查一次是否達(dá)到最大裝載因子。如果達(dá)到了,立即進(jìn)行擴(kuò)容操作。擴(kuò)容以后在新桶里面插入 key。如果沒(méi)有達(dá)到最大裝載因子,則新生成一個(gè) bmap,并且把前一個(gè) bmap 的 overflow 指針指向新的 bmap。
刪除 Key
源碼中刪除相關(guān)的是 mapdelete 函數(shù)。
func mapdelete(t *maptype, h *hmap, key unsafe.Pointer) {
if raceenabled && h != nil {
callerpc := getcallerpc()
pc := funcPC(mapdelete)
racewritepc(unsafe.Pointer(h), callerpc, pc)
raceReadObjectPC(t.key, key, callerpc, pc)
}
if msanenabled && h != nil {
msanread(key, t.key.size)
}
if h == nil || h.count == 0 {
if t.hashMightPanic() {
t.hasher(key, 0) // see issue 23734
}
return
}
// 如果多線程讀寫(xiě),直接拋出異常
if h.flags&hashWriting != 0 {
throw("concurrent map writes")
}
// 計(jì)算 key 的 hash 值
hash := t.hasher(key, uintptr(h.hash0))
// Set hashWriting after calling t.hasher, since t.hasher may panic,
// in which case we have not actually done a write (delete).
h.flags ^= hashWriting
bucket := hash & bucketMask(h.B)
// 如果還在擴(kuò)容中,繼續(xù)擴(kuò)容
if h.growing() {
growWork(t, h, bucket)
}
// 找到桶位置
b := (*bmap)(add(h.buckets, bucket*uintptr(t.bucketsize)))
bOrig := b
top := tophash(hash)
search:
for ; b != nil; b = b.overflow(t) {
// 遍歷當(dāng)前桶
for i := uintptr(0); i < bucketCnt; i++ {
if b.tophash[i] != top {
if b.tophash[i] == emptyRest {
break search
}
continue
}
k := add(unsafe.Pointer(b), dataOffset+i*uintptr(t.keysize))
k2 := k
if t.indirectkey() {
k2 = *((*unsafe.Pointer)(k2))
}
if !t.key.equal(key, k2) {
continue
}
// 找到了 key,開(kāi)始清除 key 和對(duì)應(yīng)的 value
// Only clear key if there are pointers in it.
if t.indirectkey() {
// 如果是指向 key 的指針,把指針置空
*(*unsafe.Pointer)(k) = nil
} else if t.key.ptrdata != 0 {
// 清除 key 的內(nèi)存
memclrHasPointers(k, t.key.size)
}
// 清除 value,根據(jù) value 類(lèi)型置空指針或清除值對(duì)應(yīng)的內(nèi)存
e := add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.keysize)+i*uintptr(t.elemsize))
if t.indirectelem() {
*(*unsafe.Pointer)(e) = nil
} else if t.elem.ptrdata != 0 {
memclrHasPointers(e, t.elem.size)
} else {
memclrNoHeapPointers(e, t.elem.size)
}
// 標(biāo)記當(dāng)前桶的當(dāng)前槽位為空
b.tophash[i] = emptyOne
// If the bucket now ends in a bunch of emptyOne states,
// change those to emptyRest states.
// It would be nice to make this a separate function, but
// for loops are not currently inlineable.
if i == bucketCnt-1 {
if b.overflow(t) != nil && b.overflow(t).tophash[0] != emptyRest {
goto notLast
}
} else {
if b.tophash[i+1] != emptyRest {
goto notLast
}
}
for {
b.tophash[i] = emptyRest
if i == 0 {
if b == bOrig {
break // beginning of initial bucket, we're done.
}
// Find previous bucket, continue at its last entry.
c := b
for b = bOrig; b.overflow(t) != c; b = b.overflow(t) {
}
i = bucketCnt - 1
} else {
i--
}
if b.tophash[i] != emptyOne {
break
}
}
notLast:
h.count--
break search
}
}
if h.flags&hashWriting == 0 {
throw("concurrent map writes")
}
h.flags &^= hashWriting
}
刪除 key 的流程和查找 key 流程也差不多:
找到對(duì)應(yīng)的 key 以后,清除相應(yīng)的 key 和 value 。如果是指針類(lèi)型,就把指針置為 nil;如果是值就清空值對(duì)應(yīng)的內(nèi)存;
清除 tophash 里的值,并做一些標(biāo)記;
最后把 hmap 的計(jì)數(shù)減1;
如果是在擴(kuò)容過(guò)程中,會(huì)在擴(kuò)容完成后在新的 bmap 里面執(zhí)行刪除操作。
擴(kuò)容
為什么要擴(kuò)容?
因?yàn)椋S著 Map 中添加的 key 越來(lái)越多,key 發(fā)生哈希沖突的概率也越來(lái)越大。桶中的 8 個(gè)槽位會(huì)被逐漸塞滿(mǎn),查找、插入、刪除 key 的效率也會(huì)越來(lái)越低,因此需要在 Map 達(dá)到一定裝載率后進(jìn)行擴(kuò)容,保證 Map 的讀寫(xiě)性能。
Golang 衡量裝載率的指標(biāo)是裝載因子,它的計(jì)算方式是:
loadFactor := count / (2^B)
其中:
count 表示 Map 中的元素個(gè)數(shù)
2^B 表示桶數(shù)量
什么時(shí)候擴(kuò)容?
插入 key 時(shí)會(huì)在以下兩種情況觸發(fā)哈希的擴(kuò)容:
裝載因子超過(guò) 6.5,翻倍擴(kuò)容;
使用了太多溢出桶,等量擴(kuò)容;
B < 15 時(shí),溢出桶數(shù)量 >= 2^B
B >= 15 時(shí),溢出桶數(shù)量 >= 2^15
// mapassign 中觸發(fā)擴(kuò)容的時(shí)機(jī)
// If we hit the max load factor or we have too many overflow buckets,
// and we're not already in the middle of growing, start growing.
if !h.growing() && (overLoadFactor(h.count+1, h.B) || tooManyOverflowBuckets(h.noverflow, h.B)) {
hashGrow(t, h)
goto again // Growing the table invalidates everything, so try again
}
// overLoadFactor reports whether count items placed in 1<<B buckets is over loadFactor.
func overLoadFactor(count int, B uint8) bool {
return count > bucketCnt && uintptr(count) > loadFactorNum*(bucketShift(B)/loadFactorDen)
}
// tooManyOverflowBuckets reports whether noverflow buckets is too many for a map with 1<<B buckets.
// Note that most of these overflow buckets must be in sparse use;
// if use was dense, then we'd have already triggered regular map growth.
func tooManyOverflowBuckets(noverflow uint16, B uint8) bool {
// If the threshold is too low, we do extraneous work.
// If the threshold is too high, maps that grow and shrink can hold on to lots of unused memory.
// "too many" means (approximately) as many overflow buckets as regular buckets.
// See incrnoverflow for more details.
if B > 15 {
B = 15
}
// The compiler doesn't see here that B < 16; mask B to generate shorter shift code.
return noverflow >= uint16(1)<<(B&15)
}
什么時(shí)候采用翻倍擴(kuò)容策略?
觸發(fā)擴(kuò)容的第 1 種情況,隨著 Map 中不斷插入新元素,裝載因子不斷升高直至超過(guò) 6.5 ,這時(shí)候就需要翻倍擴(kuò)容。
翻倍擴(kuò)容后,分配的新桶數(shù)量是舊桶的 2 倍。
什么時(shí)候采用等量擴(kuò)容策略?
觸發(fā)擴(kuò)容的第 2 種情況,是在裝載因子較小的情況下, Map 的讀寫(xiě)效率也較低。這種現(xiàn)象是 Map 元素少,但溢出桶數(shù)量很多, 這個(gè)時(shí)候需要等量擴(kuò)容。
可能造成這種情況的原因是:不停地插入元素、刪除元素:
先插入很多元素,導(dǎo)致創(chuàng)建了很多桶,但裝載因子未達(dá)到臨界值,不觸發(fā)擴(kuò)容;
之后,刪除元素降低元素總數(shù)量;
再插入很多元素,導(dǎo)致創(chuàng)建很多溢出桶。
等量擴(kuò)容后,分配的新桶數(shù)量跟舊桶數(shù)量相同,但新桶中存儲(chǔ)的數(shù)據(jù)更加緊密。
擴(kuò)容相關(guān)的方法是 hashGrow(),但是需要注意,它只是分配了新桶,實(shí)際上并沒(méi)有真正地“遷移數(shù)據(jù)”。
func hashGrow(t *maptype, h *hmap) {
// If we've hit the load factor, get bigger.
// Otherwise, there are too many overflow buckets,
// so keep the same number of buckets and "grow" laterally.
bigger := uint8(1)
// 裝載率未超閾值,bigger=0,即采用等量擴(kuò)容策略
if !overLoadFactor(h.count+1, h.B) {
bigger = 0
h.flags |= sameSizeGrow
}
oldbuckets := h.buckets
// 申請(qǐng)新桶
newbuckets, nextOverflow := makeBucketArray(t, h.B+bigger, nil)
flags := h.flags &^ (iterator | oldIterator)
if h.flags&iterator != 0 {
flags |= oldIterator
}
// bigger=1 即采用翻倍擴(kuò)容策略,B+1 相當(dāng)于原來(lái) 2 倍的空間
// commit the grow (atomic wrt gc)
h.B += bigger
h.flags = flags
h.oldbuckets = oldbuckets
h.buckets = newbuckets
// 遷移進(jìn)度為 0
h.nevacuate = 0
h.noverflow = 0
if h.extra != nil && h.extra.overflow != nil {
// Promote current overflow buckets to the old generation.
if h.extra.oldoverflow != nil {
throw("oldoverflow is not nil")
}
h.extra.oldoverflow = h.extra.overflow
h.extra.overflow = nil
}
if nextOverflow != nil {
if h.extra == nil {
h.extra = new(mapextra)
}
h.extra.nextOverflow = nextOverflow
}
// 真正的數(shù)據(jù)遷移工作是由 growWork() 和 evacuate() 這兩個(gè)方法漸進(jìn)式地完成的
// the actual copying of the hash table data is done incrementally
// by growWork() and evacuate().
}
遷移
在擴(kuò)容相關(guān)的 hashGrow() 方法中,最后一段注釋中提到, Map 擴(kuò)容后真正的數(shù)據(jù)遷移工作是由 growWork() 和 evacuate() 這兩個(gè)方法漸進(jìn)式地完成的,而觸發(fā)數(shù)據(jù)遷移的時(shí)機(jī)是插入 Key 和 刪除 Key。
首先,我們來(lái)看看執(zhí)行遷移工作的方法 growWork() 。
func growWork(t *maptype, h *hmap, bucket uintptr) {
// 遷移當(dāng)前正在訪問(wèn)的舊桶
// make sure we evacuate the oldbucket corresponding
// to the bucket we're about to use
evacuate(t, h, bucket&h.oldbucketmask())
// 為加速遷移進(jìn)度,如果當(dāng)前仍在擴(kuò)容中,再遷移一個(gè)桶
// evacuate one more oldbucket to make progress on growing
if h.growing() {
evacuate(t, h, h.nevacuate)
}
}
接下來(lái),我們看看負(fù)責(zé)遷移數(shù)據(jù)的方法 evacuate()。
func evacuate(t *maptype, h *hmap, oldbucket uintptr) {
// 定位舊桶地址
b := (*bmap)(add(h.oldbuckets, oldbucket*uintptr(t.bucketsize)))
newbit := h.noldbuckets()
// 如果舊桶未遷移過(guò)
if !evacuated(b) {
// TODO: reuse overflow buckets instead of using new ones, if there
// is no iterator using the old buckets. (If !oldIterator.)
// xy contains the x and y (low and high) evacuation destinations.
var xy [2]evacDst
x := &xy[0]
x.b = (*bmap)(add(h.buckets, oldbucket*uintptr(t.bucketsize)))
x.k = add(unsafe.Pointer(x.b), dataOffset)
x.e = add(x.k, bucketCnt*uintptr(t.keysize))
// 如果不是等量擴(kuò)容,桶序號(hào)會(huì)變化
if !h.sameSizeGrow() {
// Only calculate y pointers if we're growing bigger.
// Otherwise GC can see bad pointers.
y := &xy[1]
y.b = (*bmap)(add(h.buckets, (oldbucket+newbit)*uintptr(t.bucketsize)))
y.k = add(unsafe.Pointer(y.b), dataOffset)
y.e = add(y.k, bucketCnt*uintptr(t.keysize))
}
// 遍歷所有的桶,包括溢出桶
for ; b != nil; b = b.overflow(t) {
k := add(unsafe.Pointer(b), dataOffset)
e := add(k, bucketCnt*uintptr(t.keysize))
// 遍歷桶中的所有槽位
for i := 0; i < bucketCnt; i, k, e = i+1, add(k, uintptr(t.keysize)), add(e, uintptr(t.elemsize)) {
// 當(dāng)前槽位的 tophash 值
top := b.tophash[i]
// 如果槽位為空,即沒(méi)有 key,就把它標(biāo)記為被"遷移"過(guò)
if isEmpty(top) {
b.tophash[i] = evacuatedEmpty
continue
}
if top < minTopHash {
throw("bad map state")
}
k2 := k
if t.indirectkey() {
k2 = *((*unsafe.Pointer)(k2))
}
var useY uint8
if !h.sameSizeGrow() {
// Compute hash to make our evacuation decision (whether we need
// to send this key/elem to bucket x or bucket y).
hash := t.hasher(k2, uintptr(h.hash0))
if h.flags&iterator != 0 && !t.reflexivekey() && !t.key.equal(k2, k2) {
// If key != key (NaNs), then the hash could be (and probably
// will be) entirely different from the old hash. Moreover,
// it isn't reproducible. Reproducibility is required in the
// presence of iterators, as our evacuation decision must
// match whatever decision the iterator made.
// Fortunately, we have the freedom to send these keys either
// way. Also, tophash is meaningless for these kinds of keys.
// We let the low bit of tophash drive the evacuation decision.
// We recompute a new random tophash for the next level so
// these keys will get evenly distributed across all buckets
// after multiple grows.
useY = top & 1
top = tophash(hash)
} else {
if hash&newbit != 0 {
useY = 1
}
}
}
if evacuatedX+1 != evacuatedY || evacuatedX^1 != evacuatedY {
throw("bad evacuatedN")
}
// 遷移后的 tophash 和新地址
b.tophash[i] = evacuatedX + useY // evacuatedX + 1 == evacuatedY
dst := &xy[useY] // evacuation destination
if dst.i == bucketCnt {
dst.b = h.newoverflow(t, dst.b)
dst.i = 0
dst.k = add(unsafe.Pointer(dst.b), dataOffset)
dst.e = add(dst.k, bucketCnt*uintptr(t.keysize))
}
dst.b.tophash[dst.i&(bucketCnt-1)] = top // mask dst.i as an optimization, to avoid a bounds check
// 復(fù)制舊 key
if t.indirectkey() {
*(*unsafe.Pointer)(dst.k) = k2 // copy pointer
} else {
typedmemmove(t.key, dst.k, k) // copy elem
}
// 復(fù)制舊 value
if t.indirectelem() {
*(*unsafe.Pointer)(dst.e) = *(*unsafe.Pointer)(e)
} else {
typedmemmove(t.elem, dst.e, e)
}
// 定位到下一個(gè)槽位
// 如果是等量擴(kuò)容,會(huì)讓原先分布松散的 key 都集中到一起,變得更加緊湊,提高查找效率
dst.i++
// These updates might push these pointers past the end of the
// key or elem arrays. That's ok, as we have the overflow pointer
// at the end of the bucket to protect against pointing past the
// end of the bucket.
dst.k = add(dst.k, uintptr(t.keysize))
dst.e = add(dst.e, uintptr(t.elemsize))
}
}
// 清除掉多余的溢出桶和 key/value,有助于gc
// Unlink the overflow buckets & clear key/elem to help GC.
if h.flags&oldIterator == 0 && t.bucket.ptrdata != 0 {
b := add(h.oldbuckets, oldbucket*uintptr(t.bucketsize))
// Preserve b.tophash because the evacuation
// state is maintained there.
ptr := add(b, dataOffset)
n := uintptr(t.bucketsize) - dataOffset
memclrHasPointers(ptr, n)
}
}
if oldbucket == h.nevacuate {
advanceEvacuationMark(h, t, newbit)
}
}
對(duì)于翻倍擴(kuò)容,需要重新計(jì)算 key 的哈希值,才能確定它到底落在哪個(gè)桶。例如,原來(lái) B = 5,計(jì)算出 key 的哈希值后,只用看它的低 5 位,就能確定它落在哪個(gè) 桶。擴(kuò)容后,B 變成了 6,因此需要多看一位,它的低 6 位決定了 key 落在哪個(gè)桶,這也被稱(chēng)為 rehash。
因此,某個(gè) key 在遷移前后,所在桶的序號(hào)可能和原來(lái)相同,也可能在原來(lái)基礎(chǔ)上加上 2^B(原來(lái)的 B 值),這取決于哈希值 第 6 bit 位是 0 還是 1。

關(guān)于 Golang Map 的線程安全
Golang 標(biāo)準(zhǔn)包里的 Map 非線程安全, 它支持并發(fā)讀取同一個(gè) Map, 但不支持并發(fā)寫(xiě)同一個(gè) Map,goroutine 并發(fā)寫(xiě)同一個(gè) Map 會(huì)引發(fā)報(bào)錯(cuò):
fatal error: concurrent map writes
為什么不支持?
官方的解釋[1] 是經(jīng)過(guò)長(zhǎng)時(shí)間的討論, 絕大多數(shù) Map 的使用場(chǎng)景并不需要線程安全。在那些極少數(shù)需要 Map 支持線程安全的場(chǎng)景中,Map 被用來(lái)存儲(chǔ)海量共享數(shù)據(jù),這種情況下必須加鎖來(lái)確保數(shù)據(jù)一致,而加鎖顯然會(huì)影響性能和安全性。
如果非要并發(fā)寫(xiě) Map 呢?
方法1:自己在 gorutine 寫(xiě) Map 時(shí)加鎖(sync.RWMutex)
方法2:使用官方的 sync.Map 包
方法3:有人實(shí)現(xiàn)了效率更高(鎖粒度更小)的支持并發(fā)的 concurrent-map[2]
官方的 sync.Map 包:
原理:
sync.Map 里有兩個(gè) Map ,一個(gè)是專(zhuān)門(mén)用于讀的 read map,另一個(gè)是提供讀寫(xiě)的 dirty map;優(yōu)先讀 read map,若不存在則加鎖穿透讀 dirty map,同時(shí)記錄一個(gè)未從 read map 讀到數(shù)據(jù)的計(jì)數(shù),當(dāng)計(jì)數(shù)到達(dá)一定值,就用 dirty map 覆蓋 read map。優(yōu)點(diǎn):
官方出品,通過(guò)空間換時(shí)間,讀寫(xiě)分離;缺點(diǎn):
不適用于大量寫(xiě)的場(chǎng)景,會(huì)導(dǎo)致 read map 讀不到數(shù)據(jù)而進(jìn)一步加鎖讀取,同時(shí) dirty map 也會(huì)一直晉升為 read map,整體性能較差。適用場(chǎng)景:
大量讀,少量寫(xiě)。
哈希算法選用高效的 memhash 算法 和 CPU AES指令集。AES 指令集充分利用 CPU 硬件特性,計(jì)算哈希值的效率高;
key/value 在內(nèi)存中的存儲(chǔ)方式是一組 key 連續(xù)存儲(chǔ),一組 value 連續(xù)存儲(chǔ),而不是key、value成對(duì)存儲(chǔ)。這種形式方便內(nèi)存對(duì)齊,在數(shù)據(jù)量較大時(shí)可節(jié)約因內(nèi)存對(duì)齊造成的浪費(fèi);
key 和 value 超過(guò)128字節(jié)后使用指針存儲(chǔ);
tophash 數(shù)組的設(shè)計(jì)加速了 key 的查找過(guò)程,tophash 也被復(fù)用來(lái)標(biāo)記擴(kuò)容操作時(shí)的狀態(tài);
用位運(yùn)算轉(zhuǎn)換求余操作,m % n ,當(dāng) n = 1 << B 的時(shí)候,可以轉(zhuǎn)換成 m & (1 << B - 1) ;
漸進(jìn)式擴(kuò)容提高效率;
等量擴(kuò)容,緊湊操作。
Golang Map 一些待優(yōu)化的地方
在擴(kuò)容遷移過(guò)程中,不會(huì)重用溢出桶,而是直接申請(qǐng)一個(gè)新桶。這里可優(yōu)化成優(yōu)先重用沒(méi)有指針指向的溢出桶,當(dāng)沒(méi)有可用的溢出桶時(shí),再去申請(qǐng)新桶。關(guān)于這一點(diǎn), Go 作者已經(jīng)寫(xiě)在 TODO[3] 里面了。
當(dāng)前版本中沒(méi)有 shrink 操作,Map 只能增長(zhǎng)而不能收縮。runtime: maps do not shrink after elements removal (delete)[4]
參考資料
如何設(shè)計(jì)并實(shí)現(xiàn)一個(gè)線程安全的 Map[5]
Go 語(yǔ)言設(shè)計(jì)與實(shí)現(xiàn) - 哈希表[6]
深度解密Go語(yǔ)言之map[7]
map 的底層實(shí)現(xiàn)原理是什么.md[8]
[1] 官方的解釋: https://golang.org/doc/faq#atomic_maps
[2] concurrent-map: https://github.com/orcaman/concurrent-map
[3] TODO: https://golang.org/src/runtime/map.go#L1132
[4] https://github.com/golang/go/issues/20135
[5] 如何設(shè)計(jì)并實(shí)現(xiàn)一個(gè)線程安全的 Map: https://halfrost.com/go_map_chapter_one/
[6] Go 語(yǔ)言設(shè)計(jì)與實(shí)現(xiàn) - 哈希表: https://draveness.me/golang/docs/part2-foundation/ch03-datastructure/golang-hashmap/
[7] 深度解密Go語(yǔ)言之map: https://www.cnblogs.com/qcrao-2018/p/10903807.html
[8] map 的底層實(shí)現(xiàn)原理是什么.md: https://github.com/golang-design/Go-Questions/tree/master/content/map
推薦閱讀