
深入理解 glibc malloc:內(nèi)存分配器實(shí)現(xiàn)原理
譯者:貓科龍
鏈接:https://blog.csdn.net/maokelong95/article/details/51989081

前言
堆內(nèi)存(Heap Memory)是一個(gè)很有意思的領(lǐng)域。你可能和我一樣,也困惑于下述問(wèn)題很久了:
如何從內(nèi)核申請(qǐng)堆內(nèi)存? 誰(shuí)管理它??jī)?nèi)核、庫(kù)函數(shù),還是應(yīng)用本身? 內(nèi)存管理效率怎么這么高?! 堆內(nèi)存的管理效率可以進(jìn)一步提高嗎?
最近,我終于有時(shí)間去深入了解這些問(wèn)題。下面就讓我來(lái)談?wù)勎业恼{(diào)研成果。
開源社區(qū)公開了很多現(xiàn)成的內(nèi)存分配器(Memory Allocators,以下簡(jiǎn)稱為分配器):
dlmalloc – 第一個(gè)被廣泛使用的通用動(dòng)態(tài)內(nèi)存分配器; ptmalloc2 – glibc 內(nèi)置分配器的原型; jemalloc – FreeBSD & Firefox 所用分配器; tcmalloc – Google 貢獻(xiàn)的分配器; libumem – Solaris 所用分配器; …
每一種分配器都宣稱自己快(fast)、可拓展(scalable)、效率高(memory efficient)!但是并非所有的分配器都適用于我們的應(yīng)用。內(nèi)存吞吐量大(memory hungry)的應(yīng)用程序,其性能很大程度上取決于分配器的性能。
在這篇文章中,我只談「glibc malloc」分配器。為了方便大家理解「glibc malloc」,我會(huì)聯(lián)系最新的源代碼。
歷史:ptmalloc2 基于 dlmalloc 開發(fā),其引入了多線程支持,于 2006 年發(fā)布。發(fā)布之后,ptmalloc2 整合進(jìn)了 glibc 源碼,此后其所有修改都直接提交到了 glibc malloc 里。因此,ptmalloc2 的源碼和 glibc malloc 的源碼有很多不一致的地方。(譯者注:1996 年出現(xiàn)的 dlmalloc 只有一個(gè)主分配區(qū),該分配區(qū)為所有線程所爭(zhēng)用,1997 年發(fā)布的 ptmalloc 在 dlmalloc 的基礎(chǔ)上引入了非主分配區(qū)的概念。)
1. 申請(qǐng)堆的系統(tǒng)調(diào)用
我在之前的文章中提到過(guò),malloc內(nèi)部通過(guò)brk或mmap系統(tǒng)調(diào)用向內(nèi)核申請(qǐng)堆區(qū)。
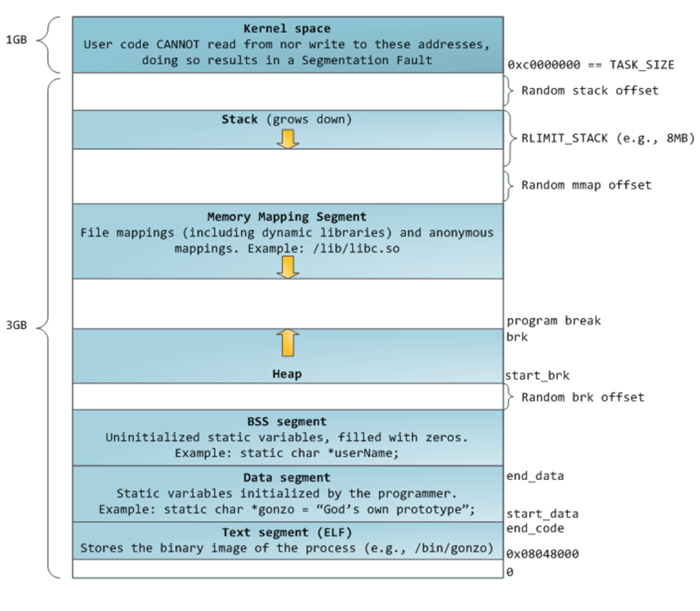
譯者注:在內(nèi)存管理領(lǐng)域,我們一般用「堆」指代用于分配動(dòng)態(tài)內(nèi)存的虛擬地址空間,而用「棧」指代用于分配靜態(tài)內(nèi)存的虛擬地址空間。具體到虛擬內(nèi)存布局(Memory Layout),堆維護(hù)在通過(guò)
brk系統(tǒng)調(diào)用申請(qǐng)的「Heap」及通過(guò)mmap系統(tǒng)調(diào)用申請(qǐng)的「Memory Mapping Segment」中;而棧維護(hù)在通過(guò)匯編棧指令動(dòng)態(tài)調(diào)整的「Stack」中。在 Glibc 里,「Heap」用于分配較小的內(nèi)存及主線程使用的內(nèi)存。下圖為 Linux 內(nèi)核 v2.6.7 之后,32 位模式下的虛擬內(nèi)存布局方式。
2. 多線程支持
Linux 的早期版本采用 dlmalloc 作為它的默認(rèn)分配器,但是因?yàn)?ptmalloc2 提供了多線程支持,所以 后來(lái) Linux 就轉(zhuǎn)而采用 ptmalloc2 了。多線程支持可以提升分配器的性能,進(jìn)而間接提升應(yīng)用的性能。
在 dlmalloc 中,當(dāng)兩個(gè)線程同時(shí)malloc時(shí),只有一個(gè)線程能夠訪問(wèn)臨界區(qū)(critical section)——這是因?yàn)樗芯€程共享用以緩存已釋放內(nèi)存的「空閑列表數(shù)據(jù)結(jié)構(gòu)」(freelist data structure),所以使用 dlmalloc 的多線程應(yīng)用會(huì)在malloc上耗費(fèi)過(guò)多時(shí)間,從而導(dǎo)致整個(gè)應(yīng)用性能的下降。
在 ptmalloc2 中,當(dāng)兩個(gè)線程同時(shí)調(diào)用malloc時(shí),內(nèi)存均會(huì)得以立即分配——每個(gè)線程都維護(hù)著單獨(dú)的堆,各個(gè)堆被獨(dú)立的空閑列表數(shù)據(jù)結(jié)構(gòu)管理,因此各個(gè)線程可以并發(fā)地從空閑列表數(shù)據(jù)結(jié)構(gòu)中申請(qǐng)內(nèi)存。這種為每個(gè)線程維護(hù)獨(dú)立堆與空閑列表數(shù)據(jù)結(jié)構(gòu)的行為就「per thread arena」。
2.1. 案例代碼
/*?Per?thread?arena?example.?*/
#include?
#include?
#include?
#include?
#include?
void*?threadFunc(void*?arg)?{
????printf("Before?malloc?in?thread?1\n");
????getchar();
????char*?addr?=?(char*)?malloc(1000);
????printf("After?malloc?and?before?free?in?thread?1\n");
????getchar();
????free(addr);
????printf("After?free?in?thread?1\n");
????getchar();
}
int?main()?{
????pthread_t?t1;
????void*?s;
????int?ret;
????char*?addr;
????printf("Welcome?to?per?thread?arena?example::%d\n",getpid());
????printf("Before?malloc?in?main?thread\n");
????getchar();
????addr?=?(char*)?malloc(1000);
????printf("After?malloc?and?before?free?in?main?thread\n");
????getchar();
????free(addr);
????printf("After?free?in?main?thread\n");
????getchar();
????ret?=?pthread_create(&t1,?NULL,?threadFunc,?NULL);
????if(ret)
????{
????????printf("Thread?creation?error\n");
????????return?-1;
????}
????ret?=?pthread_join(t1,?&s);
????if(ret)
????{
????????printf("Thread?join?error\n");
????????return?-1;
????}?
????return?0;
}
2.2. 案例輸出
2.2.1. 在主線程 malloc 之前
從如下的輸出結(jié)果中我們可以看到,這里還沒(méi)有堆段也沒(méi)有每個(gè)線程的棧,因?yàn)?thread1 還沒(méi)有創(chuàng)建!
sploitfun@sploitfun-VirtualBox:~/ptmalloc.ppt/mthread$?./mthread?
Welcome?to?per?thread?arena?example::6501
Before?malloc?in?main?thread
...
sploitfun@sploitfun-VirtualBox:~/ptmalloc.ppt/mthread$?cat?/proc/6501/maps
08048000-08049000?r-xp?00000000?08:01?539625?????/home/sploitfun/ptmalloc.ppt/mthread/mthread
08049000-0804a000?r--p?00000000?08:01?539625?????/home/sploitfun/ptmalloc.ppt/mthread/mthread
0804a000-0804b000?rw-p?00001000?08:01?539625?????/home/sploitfun/ptmalloc.ppt/mthread/mthread
b7e05000-b7e07000?rw-p?00000000?00:00?0?
...
sploitfun@sploitfun-VirtualBox:~/ptmalloc.ppt/mthread$
2.2.2. 在主線程 malloc 之后
從如下的輸出結(jié)果中我們可以看到,堆段已經(jīng)產(chǎn)生,并且其地址區(qū)間正好在數(shù)據(jù)段(0x0804b000 - 0x0806c000)上面,這表明堆內(nèi)存是移動(dòng)「Program Break」的位置產(chǎn)生的(也即通過(guò)brk中斷)。此外,請(qǐng)注意,盡管用戶只申請(qǐng)了 1000 字節(jié)的內(nèi)存,但是實(shí)際產(chǎn)生了 132KB 的堆。這個(gè)連續(xù)的堆區(qū)域被稱為「arena」。因?yàn)檫@個(gè) arena 是被主線程建立的,因此其被稱為「main arena」。接下來(lái)的申請(qǐng)會(huì)繼續(xù)分配這個(gè) arena 的 132KB 中剩余的部分。當(dāng)分配完畢時(shí),它可以通過(guò)繼續(xù)移動(dòng) Program Break 的位置擴(kuò)容。擴(kuò)容后,「top chunk」的大小也隨之調(diào)整,以將這塊新增的空間圈進(jìn)去;相應(yīng)地,arena 也可以在 top chunk 過(guò)大時(shí)縮小。
注意:top chunk 是一個(gè) arena 位于最頂層的 chunk。有關(guān) top chunk 的更多信息詳見后續(xù)章節(jié)「top chunk」部分。
sploitfun@sploitfun-VirtualBox:~/ptmalloc.ppt/mthread$?./mthread?
Welcome?to?per?thread?arena?example::6501
Before?malloc?in?main?thread
After?malloc?and?before?free?in?main?thread
...
sploitfun@sploitfun-VirtualBox:~/lsploits/hof/ptmalloc.ppt/mthread$?cat?/proc/6501/maps
08048000-08049000?r-xp?00000000?08:01?539625?????/home/sploitfun/ptmalloc.ppt/mthread/mthread
08049000-0804a000?r--p?00000000?08:01?539625?????/home/sploitfun/ptmalloc.ppt/mthread/mthread
0804a000-0804b000?rw-p?00001000?08:01?539625?????/home/sploitfun/ptmalloc.ppt/mthread/mthread
0804b000-0806c000?rw-p?00000000?00:00?0??????????[heap]
b7e05000-b7e07000?rw-p?00000000?00:00?0?
...
sploitfun@sploitfun-VirtualBox:~/ptmalloc.ppt/mthread$
2.2.3. 在主線程 free 之后
從如下的輸出結(jié)果中我們可以看到,當(dāng)分配的內(nèi)存區(qū)域free掉時(shí),其并不會(huì)立即歸還給操作系統(tǒng),而僅僅是移交給了作為庫(kù)函數(shù)的分配器。這塊free掉的內(nèi)存添加在了「main arenas bin」中(在 glibc malloc 中,空閑列表數(shù)據(jù)結(jié)構(gòu)被稱為「bin」)。隨后當(dāng)用戶請(qǐng)求內(nèi)存時(shí),分配器就不再向內(nèi)核申請(qǐng)新堆了,而是先試著各個(gè)「bin」中查找空閑內(nèi)存。只有當(dāng) bin 中不存在空閑內(nèi)存時(shí),分配器才會(huì)繼續(xù)向內(nèi)核申請(qǐng)內(nèi)存。
sploitfun@sploitfun-VirtualBox:~/ptmalloc.ppt/mthread$?./mthread?
Welcome?to?per?thread?arena?example::6501
Before?malloc?in?main?thread
After?malloc?and?before?free?in?main?thread
After?free?in?main?thread
...
sploitfun@sploitfun-VirtualBox:~/lsploits/hof/ptmalloc.ppt/mthread$?cat?/proc/6501/maps
08048000-08049000?r-xp?00000000?08:01?539625?????/home/sploitfun/ptmalloc.ppt/mthread/mthread
08049000-0804a000?r--p?00000000?08:01?539625?????/home/sploitfun/ptmalloc.ppt/mthread/mthread
0804a000-0804b000?rw-p?00001000?08:01?539625?????/home/sploitfun/ptmalloc.ppt/mthread/mthread
0804b000-0806c000?rw-p?00000000?00:00?0??????????[heap]
b7e05000-b7e07000?rw-p?00000000?00:00?0?
...
sploitfun@sploitfun-VirtualBox:~/ptmalloc.ppt/mthread$
2.2.4. 在 thread1 malloc 之前
從如下的輸出結(jié)果中我們可以看到,此時(shí) thread1 的堆尚不存在,但其棧已產(chǎn)生。
sploitfun@sploitfun-VirtualBox:~/ptmalloc.ppt/mthread$?./mthread?
Welcome?to?per?thread?arena?example::6501
Before?malloc?in?main?thread
After?malloc?and?before?free?in?main?thread
After?free?in?main?thread
Before?malloc?in?thread?1
...
sploitfun@sploitfun-VirtualBox:~/ptmalloc.ppt/mthread$?cat?/proc/6501/maps
08048000-08049000?r-xp?00000000?08:01?539625?????/home/sploitfun/ptmalloc.ppt/mthread/mthread
08049000-0804a000?r--p?00000000?08:01?539625?????/home/sploitfun/ptmalloc.ppt/mthread/mthread
0804a000-0804b000?rw-p?00001000?08:01?539625?????/home/sploitfun/ptmalloc.ppt/mthread/mthread
0804b000-0806c000?rw-p?00000000?00:00?0??????????[heap]
b7604000-b7605000?---p?00000000?00:00?0?
b7605000-b7e07000?rw-p?00000000?00:00?0??????????[stack:6594]
...
sploitfun@sploitfun-VirtualBox:~/ptmalloc.ppt/mthread$
2.2.5. 在 thread1 malloc 之后
從如下的輸出結(jié)果中我們可以看到,thread1 的堆段(b7500000 - b7521000,132KB)建立在了內(nèi)存映射段中,這也表明了堆內(nèi)存是使用mmap系統(tǒng)調(diào)用產(chǎn)生的,而非同主線程一樣使用sbrk系統(tǒng)調(diào)用。類似地,盡管用戶只請(qǐng)求了 1000B,但是映射到程地址空間的堆內(nèi)存足有 1MB。這 1MB 中,只有 132KB 被設(shè)置了讀寫權(quán)限,并成為該線程的堆內(nèi)存。這段連續(xù)內(nèi)存(132KB)被稱為「thread arena」。
注意:當(dāng)用戶請(qǐng)求超過(guò) 128KB(比如
malloc(132*1024)) 大小并且此時(shí) arena 中沒(méi)有足夠的空間來(lái)滿足用戶的請(qǐng)求時(shí),內(nèi)存將通過(guò)mmap系統(tǒng)調(diào)用(不再是sbrk)分配,而不論請(qǐng)求是發(fā)自 main arena 還是 thread arena。
ploitfun@sploitfun-VirtualBox:~/ptmalloc.ppt/mthread$?./mthread?
Welcome?to?per?thread?arena?example::6501
Before?malloc?in?main?thread
After?malloc?and?before?free?in?main?thread
After?free?in?main?thread
Before?malloc?in?thread?1
After?malloc?and?before?free?in?thread?1
...
sploitfun@sploitfun-VirtualBox:~/ptmalloc.ppt/mthread$?cat?/proc/6501/maps
08048000-08049000?r-xp?00000000?08:01?539625?????/home/sploitfun/ptmalloc.ppt/mthread/mthread
08049000-0804a000?r--p?00000000?08:01?539625?????/home/sploitfun/ptmalloc.ppt/mthread/mthread
0804a000-0804b000?rw-p?00001000?08:01?539625?????/home/sploitfun/ptmalloc.ppt/mthread/mthread
0804b000-0806c000?rw-p?00000000?00:00?0??????????[heap]
b7500000-b7521000?rw-p?00000000?00:00?0?
b7521000-b7600000?---p?00000000?00:00?0
b7604000-b7605000?---p?00000000?00:00?0
b7605000-b7e07000?rw-p?00000000?00:00?0??????????[stack:6594]
...
sploitfun@sploitfun-VirtualBox:~/ptmalloc.ppt/mthread$
2.2.6. 在 thread1 free 之后
從如下的輸出結(jié)果中我們可以看到,free不會(huì)把內(nèi)存歸還給操作系統(tǒng),而是移交給分配器,然后添加在了「thread arenas bin」中。
sploitfun@sploitfun-VirtualBox:~/ptmalloc.ppt/mthread$?./mthread?
Welcome?to?per?thread?arena?example::6501
Before?malloc?in?main?thread
After?malloc?and?before?free?in?main?thread
After?free?in?main?thread
Before?malloc?in?thread?1
After?malloc?and?before?free?in?thread?1
After?free?in?thread?1
...
sploitfun@sploitfun-VirtualBox:~/ptmalloc.ppt/mthread$?cat?/proc/6501/maps
08048000-08049000?r-xp?00000000?08:01?539625?????/home/sploitfun/ptmalloc.ppt/mthread/mthread
08049000-0804a000?r--p?00000000?08:01?539625?????/home/sploitfun/ptmalloc.ppt/mthread/mthread
0804a000-0804b000?rw-p?00001000?08:01?539625?????/home/sploitfun/ptmalloc.ppt/mthread/mthread
0804b000-0806c000?rw-p?00000000?00:00?0??????????[heap]
b7500000-b7521000?rw-p?00000000?00:00?0?
b7521000-b7600000?---p?00000000?00:00?0?
b7604000-b7605000?---p?00000000?00:00?0?
b7605000-b7e07000?rw-p?00000000?00:00?0??????????[stack:6594]
...
sploitfun@sploitfun-VirtualBox:~/ptmalloc.ppt/mthread$
3. Arena
3.1. Arena 的數(shù)量
在以上的例子中我們可以看到,主線程包含 main arena 而 thread 1 包含它自己的 thread arena。所以線程和 arena 之間是否存在一一映射關(guān)系,而不論線程的數(shù)量有多大?當(dāng)然不是,部分極端的應(yīng)用甚至運(yùn)行比處理器核數(shù)還多的線程,在這種情況下,每個(gè)線程都擁有一個(gè) arena 開銷過(guò)高且意義不大。所以,arena 數(shù)量其實(shí)是限于系統(tǒng)核數(shù)的。
For?32?bit?systems:
Number?of?arena?=?2?*?number?of?cores.
For?64?bit?systems:
Number?of?arena?=?8?*?number?of?cores.
3.2. Multiple Arena
舉例而言:讓我們來(lái)看一個(gè)運(yùn)行在單核計(jì)算機(jī)上的 32 位操作系統(tǒng)上的多線程應(yīng)用(4 線程,主線程 + 3 個(gè)線程)的例子。這里線程數(shù)量(4)> 2 * 核心數(shù)(1),所以分配器中可能有 Arena(也即標(biāo)題所稱「multiple arenas」)會(huì)被所有線程共享。那么是如何共享的呢?
當(dāng)主線程第一次調(diào)用
malloc時(shí),已經(jīng)建立的 main arena 會(huì)被沒(méi)有任何競(jìng)爭(zhēng)地使用;當(dāng) thread 1 和 thread 2 第一次調(diào)用
malloc時(shí),一塊新的 arena 將被創(chuàng)建,且將被沒(méi)有任何競(jìng)爭(zhēng)地使用。此時(shí)線程和 arena 之間存在一一映射關(guān)系;當(dāng) thread3 第一次調(diào)用
malloc時(shí),arena 的數(shù)量限制被計(jì)算出來(lái),結(jié)果顯示已超出,因此嘗試復(fù)用已經(jīng)存在的 arena(也即 Main arena 或 Arena 1 或 Arena 2);復(fù)用:
一旦遍歷到可用 arena,就開始自旋申請(qǐng)?jiān)?arena 的鎖; 如果上鎖成功(比如說(shuō) main arena 上鎖成功),就將該 arena 返回用戶; 如果沒(méi)找到可用 arena,thread 3 的 malloc將被阻塞,直到有可用的 arena 為止。當(dāng)thread 3 調(diào)用
malloc時(shí)(第二次了),分配器會(huì)嘗試使用上一次使用的 arena(也即,main arena),從而盡量提高緩存命中率。當(dāng) main arena 可用時(shí)就用,否則 thread 3 就一直阻塞,直至 main arena 空閑。因此現(xiàn)在 main arena 實(shí)際上是被 main thread 和 thread 3 所共享。
3.3. Multiple Heaps
在「glibc malloc」中主要有 3 種數(shù)據(jù)結(jié)構(gòu):
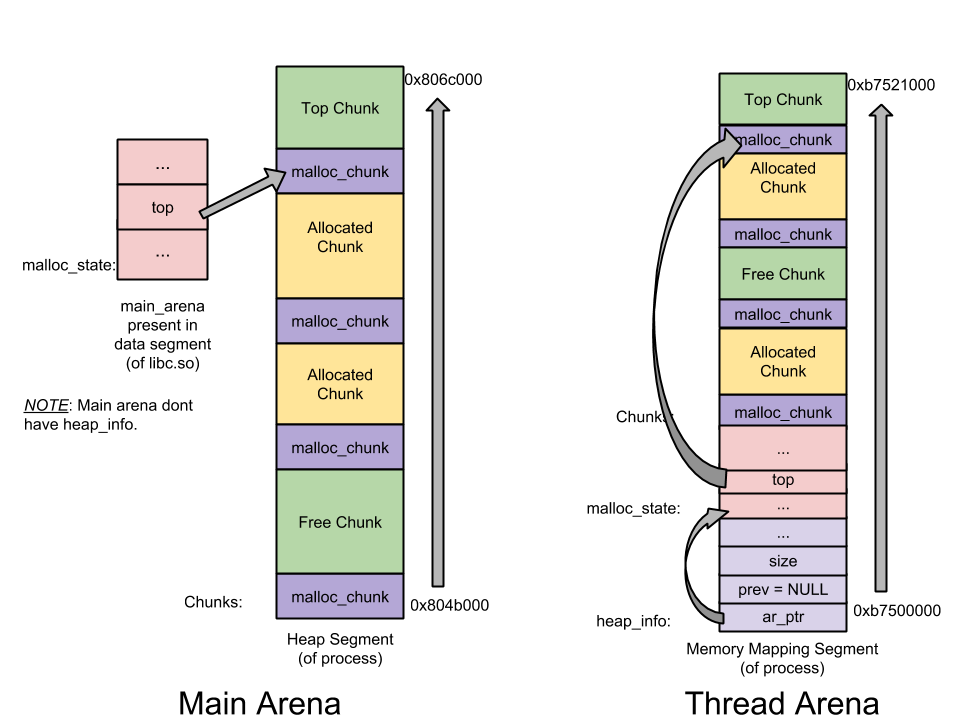
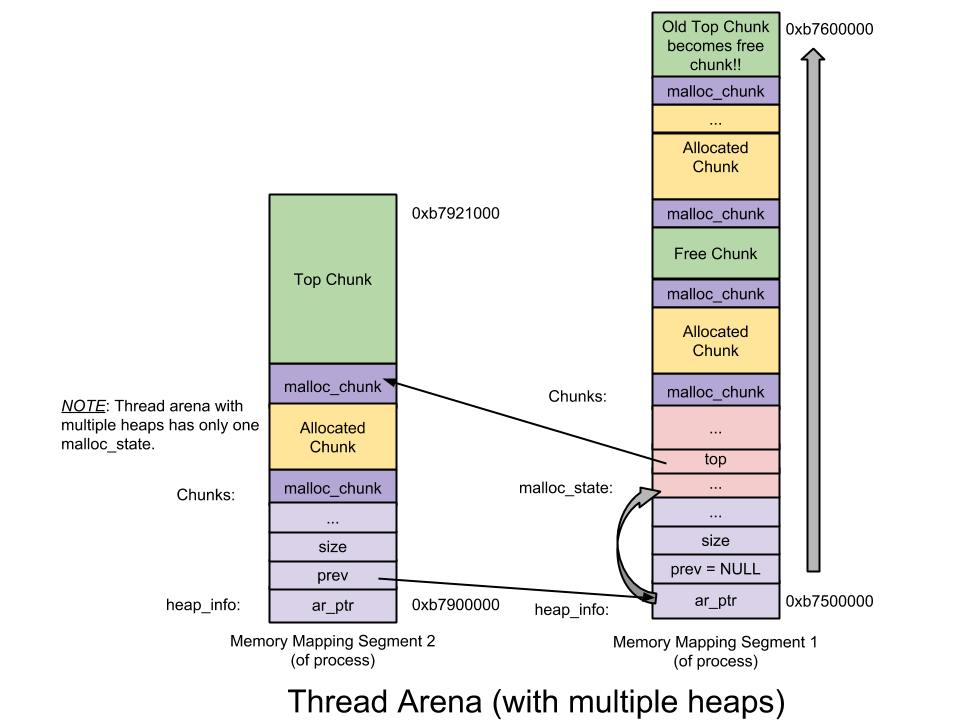
heap_info ——Heap Header—— 一個(gè) thread arena 可以維護(hù)多個(gè)堆。每個(gè)堆都有自己的堆 Header(注:也即頭部元數(shù)據(jù))。什么時(shí)候 Thread Arena 會(huì)維護(hù)多個(gè)堆呢?一般情況下,每個(gè) thread arena 都只維護(hù)一個(gè)堆,但是當(dāng)這個(gè)堆的空間耗盡時(shí),新的堆(而非連續(xù)內(nèi)存區(qū)域)就會(huì)被 mmap到這個(gè) aerna 里;malloc_state ——Arena header—— 一個(gè) thread arena 可以維護(hù)多個(gè)堆,這些堆另外共享同一個(gè) arena header。Arena header 描述的信息包括:bins、top chunk、last remainder chunk 等; malloc_chunk ——Chunk header—— 根據(jù)用戶請(qǐng)求,每個(gè)堆被分為若干 chunk。每個(gè) chunk 都有自己的 chunk header。
注意:
Main arena 無(wú)需維護(hù)多個(gè)堆,因此也無(wú)需 heap_info。當(dāng)空間耗盡時(shí),與 thread arena 不同,main arena 可以通過(guò) sbrk拓展堆段,直至堆段「碰」到內(nèi)存映射段;與 thread arena 不同,main arena 的 arena header 不是保存在通過(guò) sbrk申請(qǐng)的堆段里,而是作為一個(gè)全局變量,可以在 libc.so 的數(shù)據(jù)段中找到。
main arena 和 thread arena 的圖示如下(單堆段):
thread arena 的圖示如下(多堆段):
4. Chunk
堆段中存在的 chunk 類型如下:
Allocated chunk; Free chunk; Top chunk; Last Remainder chunk.
4.1. Allocated chunk
「Allocated chunck」就是已經(jīng)分配給用戶的 chunk,其圖示如下:
圖中左方三個(gè)箭頭依次表示:
chunk:該 Allocated chunk 的起始地址; mem:該 Allocated chunk 中用戶可用區(qū)域的起始地址( = chunk + sizeof(malloc_chunk));next_chunk:下一個(gè) chunck(無(wú)論類型)的起始地址。
圖中結(jié)構(gòu)體內(nèi)部各字段的含義依次為:
prev_size:若上一個(gè) chunk 可用,則此字段賦值為上一個(gè) chunk 的大小;否則,此字段被用來(lái)存儲(chǔ)上一個(gè) chunk 的用戶數(shù)據(jù);
size:此字段賦值本 chunk 的大小,其最后三位包含標(biāo)志信息:
PREV_INUSE § – 置「1」表示上個(gè) chunk 被分配; IS_MMAPPED (M) – 置「1」表示這個(gè) chunk 是通過(guò) mmap申請(qǐng)的(較大的內(nèi)存);NON_MAIN_ARENA (N) – 置「1」表示這個(gè) chunk 屬于一個(gè) thread arena。
注意:
malloc_chunk 中的其余結(jié)構(gòu)成員,如 fd、 bk,沒(méi)有使用的必要而拿來(lái)存儲(chǔ)用戶數(shù)據(jù); 用戶請(qǐng)求的大小被轉(zhuǎn)換為內(nèi)部實(shí)際大小,因?yàn)樾枰~外空間存儲(chǔ) malloc_chunk,此外還需要考慮對(duì)齊。
4.2. Free chunk
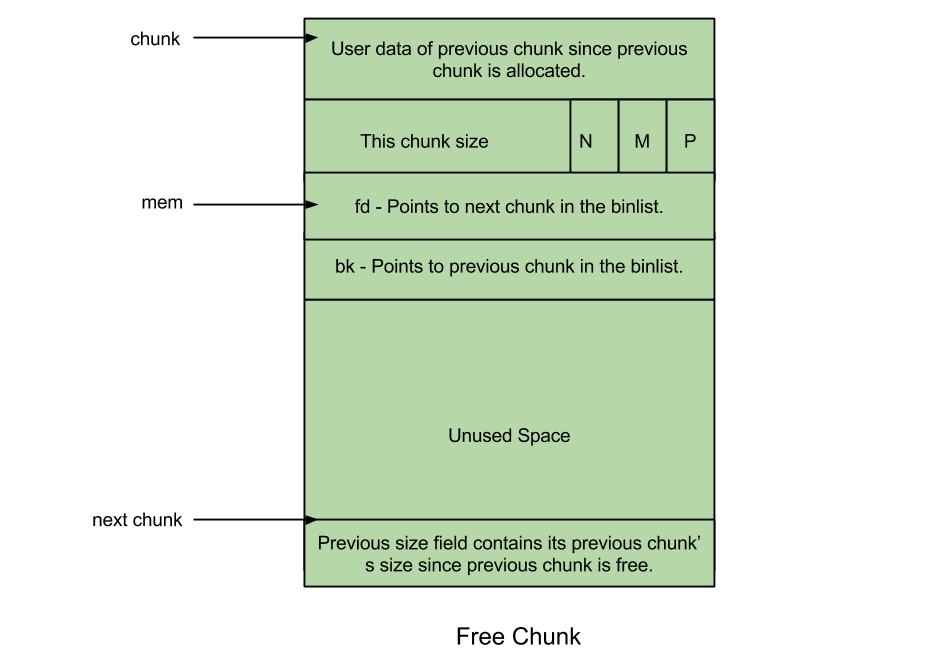
「Free chunck」就是用戶已釋放的 chunk,其圖示如下:
圖中結(jié)構(gòu)體內(nèi)部各字段的含義依次為:
prev_size: 兩個(gè)相鄰 free chunk 會(huì)被合并成一個(gè),因此該字段總是保存前一個(gè) allocated chunk 的用戶數(shù)據(jù); size: 該字段保存本 free chunk 的大小; fd: Forward pointer —— 本字段指向同一 bin 中的下個(gè) free chunk(free chunk 鏈表的前驅(qū)指針); bk: Backward pointer —— 本字段指向同一 bin 中的上個(gè) free chunk(free chunk 鏈表的后繼指針)。
5. Bins
「bins」 就是空閑列表數(shù)據(jù)結(jié)構(gòu)。它們用以保存 free chunks。根據(jù)其中 chunk 的大小,bins 被分為如下幾種類型:
Fast bin; Unsorted bin; Small bin; Large bin.
保存這些 bins 的字段為:
fastbinsY: 這個(gè)數(shù)組用以保存 fast bins;
bins: 這個(gè)數(shù)組用于保存 unsorted bin、small bins 以及 large bins,共計(jì)可容納 126 個(gè),其中:
Bin 1: unsorted bin; Bin 2 - 63: small bins; Bin 64 - 126: large bins.
5.1. Fast Bin
大小為 16 ~ 80 字節(jié)的 chunk 被稱為「fast chunk」。在所有的 bins 中,fast bins 路徑享有最快的內(nèi)存分配及釋放速度。
數(shù)量:10
每個(gè) fast bin 都維護(hù)著一條 free chunk 的單鏈表,采用單鏈表是因?yàn)殒湵碇兴?chunk 的大小相等,增刪 chunk 發(fā)生在鏈表頂端即可;—— LIFO
chunk 大小:8 字節(jié)遞增
fast bins 由一系列所維護(hù) chunk 大小以 8 字節(jié)遞增的 bins 組成。也即,
fast bin[0]維護(hù)大小為 16 字節(jié)的 chunk、fast bin[1]維護(hù)大小為 24 字節(jié)的 chunk。依此類推……指定 fast bin 中所有 chunk 大小相同;
在 malloc 初始化過(guò)程中,最大的 fast bin 的大小被設(shè)置為 64 而非 80 字節(jié)。因?yàn)槟J(rèn)情況下只有大小 16 ~ 64 的 chunk 被歸為 fast chunk 。
無(wú)需合并 —— 兩個(gè)相鄰 chunk 不會(huì)被合并。雖然這可能會(huì)加劇內(nèi)存碎片化,但也大大加速了內(nèi)存釋放的速度!
malloc(fast chunk)初始情況下 fast chunck 最大尺寸以及 fast bin 相應(yīng)數(shù)據(jù)結(jié)構(gòu)均未初始化,因此即使用戶請(qǐng)求內(nèi)存大小落在 fast chunk 相應(yīng)區(qū)間,服務(wù)用戶請(qǐng)求的也將是 small bin 路徑而非 fast bin 路徑;
初始化后,將在計(jì)算 fast bin 索引后檢索相應(yīng) bin;
相應(yīng) bin 中被檢索的第一個(gè) chunk 將被摘除并返回給用戶。
free(fast chunk)計(jì)算 fast bin 索引以索引相應(yīng) bin; free掉的 chunk 將被添加到上述 bin 的頂端。
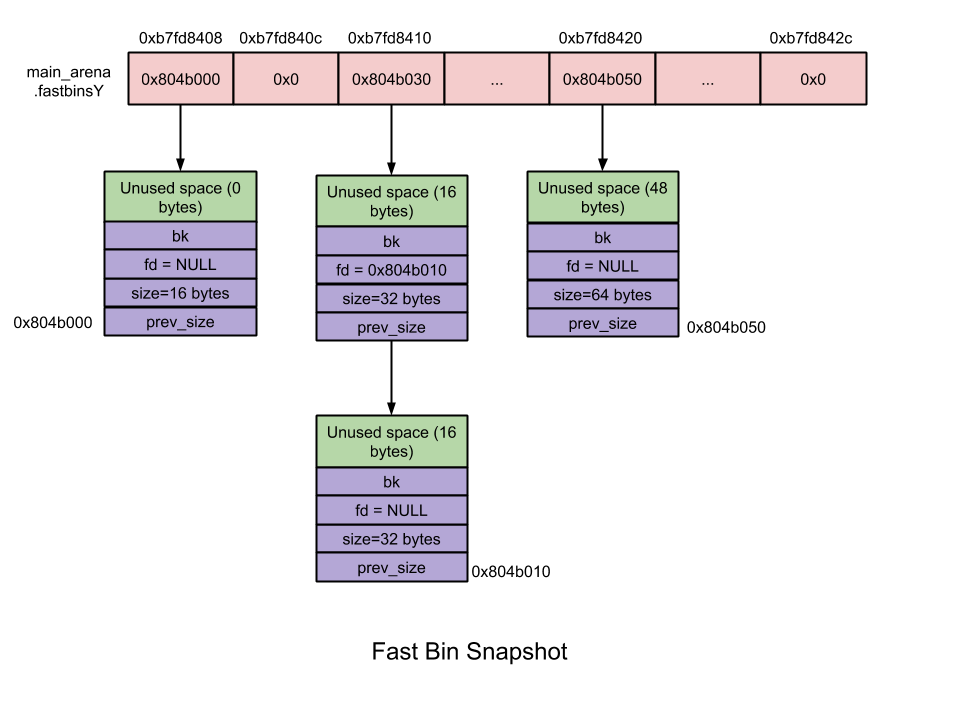
5.2. Unsorted Bin
當(dāng) small chunk 和 large chunk 被free掉時(shí),它們并非被添加到各自的 bin 中,而是被添加在 「unsorted bin」 中。這使得分配器可以重新使用最近free掉的 chunk,從而消除了尋找合適 bin 的時(shí)間開銷,進(jìn)而加速了內(nèi)存分配及釋放的效率。
譯者注:經(jīng) @kwdecsdn 提醒,這里應(yīng)補(bǔ)充說(shuō)明「Unsorted Bin 中的 chunks 何時(shí)移至 small/large chunk 中」。在內(nèi)存分配的時(shí)候,在前后檢索 fast/small bins 未果之后,在特定條件下,會(huì)將 unsorted bin 中的 chunks 轉(zhuǎn)移到合適的 bin 中去,small/large。
數(shù)量:1 unsorted bin 包括一個(gè)用于保存 free chunk 的雙向循環(huán)鏈表(又名 binlist); chunk 大小:無(wú)限制,任何大小的 chunk 均可添加到這里。
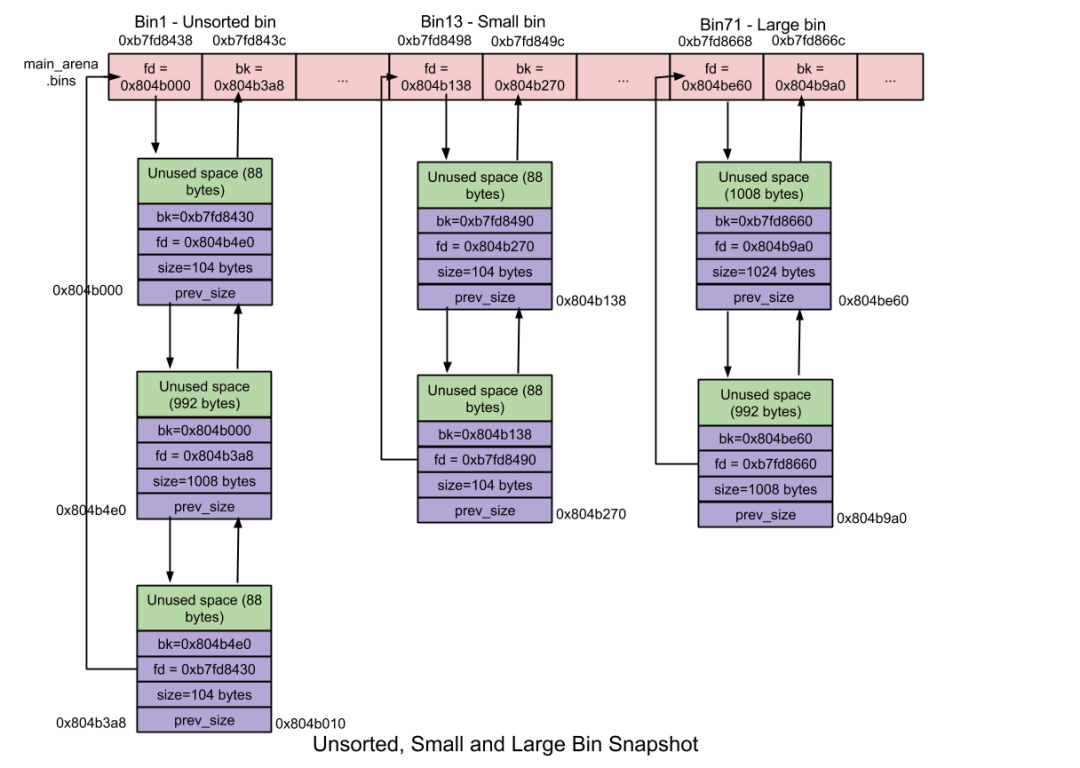
5.3. Small Bin
大小小于 512 字節(jié)的 chunk 被稱為 「small chunk」,而保存 small chunks 的 bin 被稱為 「small bin」。在內(nèi)存分配回收的速度上,small bin 比 large bin 更快。
數(shù)量:62
每個(gè) small bin 都維護(hù)著一條 free chunk 的雙向循環(huán)鏈表。采用雙向鏈表的原因是,small bins 中的 chunk 可能會(huì)從鏈表中部摘除。這里新增項(xiàng)放在鏈表的頭部位置,而從鏈表的尾部位置移除項(xiàng)。—— FIFO chunk 大小:8 字節(jié)遞增
Small bins 由一系列所維護(hù) chunk 大小以 8 字節(jié)遞增的 bins 組成。舉例而言, small bin[0](Bin 2)維護(hù)著大小為 16 字節(jié)的 chunks、small bin[1](Bin 3)維護(hù)著大小為 24 字節(jié)的 chunks ,依此類推……指定 small bin 中所有 chunk 大小均相同,因此無(wú)需排序; 合并 —— 相鄰的 free chunk 將被合并,這減緩了內(nèi)存碎片化,但是減慢了
free的速度;malloc(small chunk)初始情況下,small bins 都是 NULL,因此盡管用戶請(qǐng)求 small chunk ,提供服務(wù)的將是 unsorted bin 路徑而不是 small bin 路徑; 第一次調(diào)用 malloc時(shí),維護(hù)在 malloc_state 中的 small bins 和 large bins 將被初始化,它們都會(huì)指向自身以表示其為空;此后當(dāng) small bin 非空,相應(yīng)的 bin 會(huì)摘除其中最后一個(gè) chunk 并返回給用戶; free(small chunk)freechunk 的時(shí)候,檢查其前后的 chunk 是否空閑,若是則合并,也即把它們從所屬的鏈表中摘除并合并成一個(gè)新的 chunk,新 chunk 會(huì)添加在 unsorted bin 的前端。
5.4. Large Bin
大小大于等于 512 字節(jié)的 chunk 被稱為「large chunk」,而保存 large chunks 的 bin 被稱為 「large bin」。在內(nèi)存分配回收的速度上,large bin 比 small bin 慢。
數(shù)量:63
32 個(gè) bins 所維護(hù)的 chunk 大小以 64B 遞增,也即 large chunk[0](Bin 65) 維護(hù)著大小為 512B ~ 568B 的 chunk 、large chunk[1](Bin 66) 維護(hù)著大小為 576B ~ 632B 的 chunk,依此類推……16 個(gè) bins 所維護(hù)的 chunk 大小以 512 字節(jié)遞增; 8 個(gè) bins 所維護(hù)的 chunk 大小以 4096 字節(jié)遞增; 4 個(gè) bins 所維護(hù)的 chunk 大小以 32768 字節(jié)遞增; 2 個(gè) bins 所維護(hù)的 chunk 大小以 262144 字節(jié)遞增; 1 個(gè) bin 維護(hù)所有剩余 chunk 大小; 每個(gè) large bin 都維護(hù)著一條 free chunk 的雙向循環(huán)鏈表。采用雙向鏈表的原因是,large bins 中的 chunk 可能會(huì)從鏈表中的任意位置插入及刪除。 這 63 個(gè) bins 不像 small bin ,large bin 中所有 chunk 大小不一定相同,各 chunk 大小遞減保存。最大的 chunk 保存頂端,而最小的 chunk 保存在尾端; 合并 —— 兩個(gè)相鄰的空閑 chunk 會(huì)被合并;
malloc(large chunk)User chunk(用戶請(qǐng)求大小)—— 返回給用戶; Remainder chunk (剩余大小)—— 添加到 unsorted bin。 初始情況下,large bin 都會(huì)是 NULL,因此盡管用戶請(qǐng)求 large chunk ,提供服務(wù)的將是 next largetst bin 路徑而不是 large bin 路勁 。 第一次調(diào)用 malloc時(shí),維護(hù)在 malloc_state 中的 small bin 和 large bin 將被初始化,它們都會(huì)指向自身以表示其為空;此后當(dāng) large bin 非空,如果相應(yīng) bin 中的最大 chunk 大小大于用戶請(qǐng)求大小,分配器就從該 bin 頂端遍歷到尾端,以找到一個(gè)大小最接近用戶請(qǐng)求的 chunk。一旦找到,相應(yīng) chunk 就會(huì)被切分成兩塊: 如果相應(yīng) bin 中的最大 chunk 大小小于用戶請(qǐng)求大小,分配器就會(huì)掃描 binmaps,從而查找最小非空 bin。如果找到了這樣的 bin,就從中選擇合適的 chunk 并切割給用戶;反之就使用 top chunk 響應(yīng)用戶請(qǐng)求。 free(large chunk)—— 類似于 small chunk 。
5.5. Top Chunk
一個(gè) arena 中最頂部的 chunk 被稱為「top chunk」。它不屬于任何 bin 。當(dāng)所有 bin 中都沒(méi)有合適空閑內(nèi)存時(shí),就會(huì)使用 top chunk 來(lái)響應(yīng)用戶請(qǐng)求。
當(dāng) top chunk 的大小比用戶請(qǐng)求的大小大的時(shí)候,top chunk 會(huì)分割為兩個(gè)部分:
User chunk,返回給用戶; Remainder chunk,剩余部分,將成為新的 top chunk。
當(dāng) top chunk 的大小比用戶請(qǐng)求的大小小的時(shí)候,top chunk 就通過(guò)sbrk(main arena)或mmap( thread arena)系統(tǒng)調(diào)用擴(kuò)容。
5.6. Last Remainder Chunk
「last remainder chunk」即最后一次 small request 中因分割而得到的剩余部分,它有利于改進(jìn)引用局部性,也即后續(xù)對(duì) small chunk 的malloc請(qǐng)求可能最終被分配得彼此靠近。
那么 arena 中的若干 chunks,哪個(gè)有資格成為 last remainder chunk 呢?
當(dāng)用戶請(qǐng)求 small chunk 而無(wú)法從 small bin 和 unsorted bin 得到服務(wù)時(shí),分配器就會(huì)通過(guò)掃描 binmaps 找到最小非空 bin。正如前文所提及的,如果這樣的 bin 找到了,其中最合適的 chunk 就會(huì)分割為兩部分:返回給用戶的 User chunk 、添加到 unsorted bin 中的 Remainder chunk。這一 Remainder chunk 就將成為 last remainder chunk。
那么引用局部性是如何達(dá)成的呢?
當(dāng)用戶的后續(xù)請(qǐng)求 small chunk,并且 last remainder chunk 是 unsorted bin 中唯一的 chunk,該 last remainder chunk 就將分割成兩部分:返回給用戶的 User chunk、添加到 unsorted bin 中的 Remainder chunk(也是 last remainder chunk)。因此后續(xù)的請(qǐng)求的 chunk 最終將被分配得彼此靠近。
劉翔,童薇,劉景寧,馮丹,陳勁龍.動(dòng)態(tài)內(nèi)存分配器研究綜述[J].計(jì)算機(jī)學(xué)報(bào),2018,41(10):2359-2378.
有收獲,點(diǎn)個(gè)在看?
