
冠軍方案!2023第二屆廣州·琶洲算法大賽
Datawhale干貨
作者:唐楚柳,算法工程師,冠軍選手
1.簡介
大家好我是?Alex,31歲,現為一名圖像算法工程師,主要研究方向是計算機視覺圖像識別。工作之余的研究興趣包括ocr,aigc,llm,vit。獲得
-
2021 CVPR PIC Challenge: 3D Face Reconstruction From Multiple 2D Images(第7名) -
2021 IKCEST第三屆“一帶一路”國際大數據競賽(第10名) -
2022“域見杯”醫(yī)檢人工智能開發(fā)者大賽(第6名) -
2022 粵港澳大灣區(qū)(黃埔)國際算法算例大賽-路測3D感知算法(第4名) -
2023 CVPR 2023 1st foundation model challenge-Track1(第6名)
本次主要分享在2023第二屆廣州·琶洲算法大賽基于文心交通大模型的多任務聯合訓練賽題的Rank1方案。

2.賽題分析
近年來,智慧汽車、人工智能等產業(yè)發(fā)展,為智能交通發(fā)展創(chuàng)造了良好的發(fā)展機遇。智能交通相關技術已經滲透到我們的日常生活中,但是現有大模型的多任務處理模式以及傳統的感知方法(如分類、檢測、分割等)無法滿足我們對更廣交通場景以及更高自動駕駛水平的追逐。我們從當前實際技術研究中的關鍵問題出發(fā),解決多任務、多數據間沖突的問題。本賽道聯合分類、檢測、分割三項CV任務三大數據集至單一大模型中,使得單一大模型具備能力的同時獲得領先于特定單任務模型的性能。
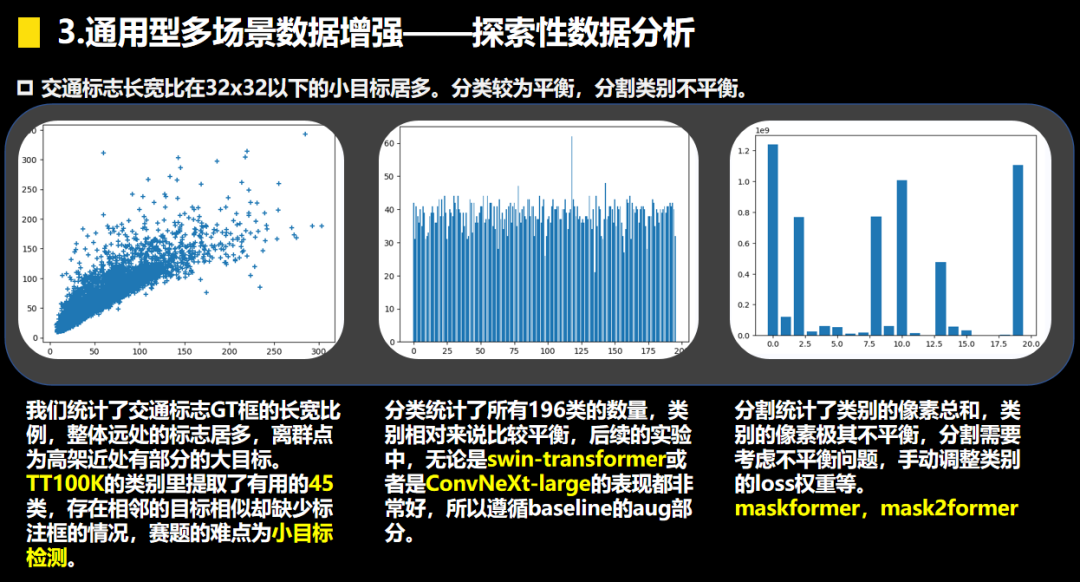
3.解題思路
在本次賽題的數據挖掘中,我們發(fā)現賽題的難點在于類別不平衡的語義分割和小目標檢測,在backbone選型的問題上我們有一點小分歧,Convnext-Large 和Swin-L。從實踐的角度看在數據量充足的情況考慮transformer,而數據量少的情況下優(yōu)先考慮cnn,當前比較 優(yōu)秀的兩個backbone為swin-transformer和convnxet。我們在這兩個backbone上的實驗比較多,主要為了解決類別不平衡的語義分割和小目標檢測,主要圍繞以下的幾點展開:
-
骨干網絡選型Convnext-Large 和Swin-Large -
檢測頭和分割頭的選型 (DINO,RT-DETR,YOLOv5,yolov7)(upernet,maskformer,mask2former) -
多尺度訓練 -
檢測的sahi切圖方案。 -
檢測的copypaste方案。 -
TTA 后處理 (檢測的多尺度推理,分割的多次結果ensemble mulit scale推理)
4.方案
4.1 ConvNeXt多任務網絡結構
我們的整體的方案如下圖所示,主體的網絡結構為ConvNeXt-Large,在網絡的每一個stage后輸出一個特征圖feature,主體的設計為三個任務共享feature,目標檢測部分單獨使用一個FPN(輸入為feature1,2,3)后接上yolov5Head,分類使用了feature4的特征,分割使用feature1,2,3,4,后接上mask2former Head。
4.2 YOLOCSPPAN的網絡結構圖
P2,P3,P4 對應4.1中的feature2,3,4。P4經過卷積,上采樣和P3在通道上合并,由CSPLayer提取特征得到新P3,同理得到最終的P2,
最終輸出的P2經過stride為2的卷積和新P3在通道上合并,由CSPLayer提取特征得到最終輸出的P3,最終輸出的P3經過stride為2的卷積和P4在通道上合并,由CSPLayer提取特征得到最終輸出的P4.

FPN輸出的P2,3,4會傳入三個yolov5Head,ConvNeXt配合yolohead會有較高的漲點(圖出自百度AI公眾號-匯集YOLO系列經典和前沿算法,實現高精度實時檢測!)
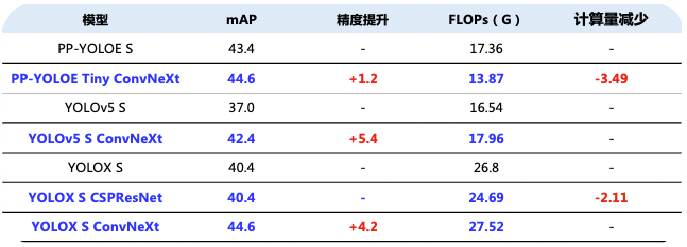

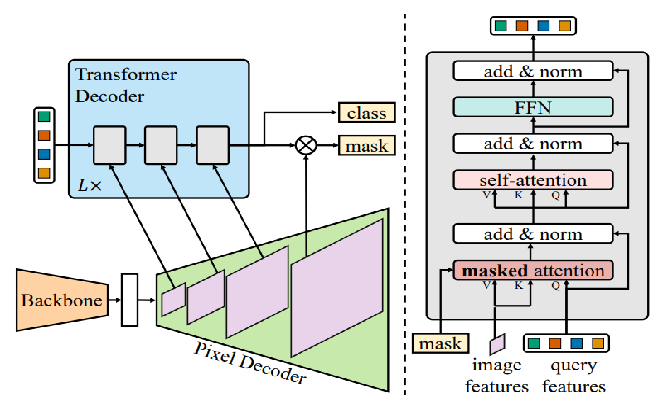
SegmentationHead我們考慮到了像素的類別不平衡的問題,最先開始調試MaskFormer,Masks2Former同時調試了,從下圖我們可以看出Mask2Former在semantic的指標上比高出MaskFormer 1.1%,而在instance和panoptic上比MaskFormer高出5.1%和10%。
MaskFormer和Mask2Former的區(qū)別在于后者使用了多尺度的信息。

4.3數據增強
隨機縮放(尺度變換):對輸入圖像進行隨機的放大或縮小操作,可以增加數據樣本的多樣性,使模型能夠處理不同尺度的目標物體。
隨機裁剪(位置變換):從輸入圖像中隨機裁剪出固定大小的區(qū)域作為訓練樣本,通過改變目標物體的位置來增加數據的多樣性。
隨機水平翻轉(鏡像):以一定的概率對輸入圖像進行水平翻轉操作,使得模型能夠學習到目標物體在不同方向上的特征。
高斯噪聲:向輸入圖像中添加高斯噪聲,可以增加圖像的復雜性,使得模型能夠更好地適應真實世界中的噪聲情況。
高斯模糊:對輸入圖像進行高斯模糊操作,可以減少圖像中的細節(jié)信息,從而使得模型能夠更關注目標物體的整體形狀和結構。
旋轉:對輸入圖像進行隨機旋轉操作,可以增加目標物體在不同角度下的樣本,提高模型對目標物體旋轉不變性的學習能力。
網格型變:通過對輸入圖像進行網格型扭曲操作,可以引入局部形變,增加數據的多樣性。
隨機色彩變換:對輸入圖像進行隨機的色彩變換,如調整亮度、對比度和飽和度等,以增加圖像的多樣性。
隨機天氣(BDD雨霧天氣居多):通過向輸入圖像中添加隨機的天氣效果,如雨、霧等,模擬真實場景下的變化,提高模型對復雜環(huán)境的適應能力。
這些數據增強方法的使用可以有效地增加訓練樣本的多樣性,從而提高模型對不同場景和變化的泛化能力。同時,合適的數據增強方法選擇也需要根據具體任務的特點和需求進行調整和優(yōu)化。

HSV 顏色增強:對輸入圖像進行 HSV 顏色空間的隨機調整,如調整亮度、對比度和飽和度等,以增加樣本的多樣性和泛化能力。
隨機裁剪:從輸入圖像中隨機裁剪出固定大小的區(qū)域作為訓練樣本,這有助于模型學習到不同目標物體的局部特征,并提高模型的魯棒性。
Resize 1024:將輸入圖像的大小調整為固定的尺寸(例如 1024x1024),這既有助于減少顯存占用,增大批量大小(BS),又能夠在一定程度上提高模型的檢測精度。
隨機翻轉:以一定的概率對輸入圖像進行水平或垂直翻轉操作,以增加數據樣本的多樣性,并保持目標物體的不變性。

4.4調參優(yōu)化策略
整體考慮到顯存數據集規(guī)模和模型收斂的節(jié)點 50000 iter 附近
訓練設置 58200 max_iter
由于是余弦周期 考慮在50000 節(jié)點 衰減學習率solver_steps=[50000],)

optimizer = L(build_lr_optimizer_lazy)(
optimizer_type='AdamW',
base_lr=1e-4,
weight_decay=1e-4,
grad_clip_enabled=True,
grad_clip_norm=0.1,
apply_decay_param_fun=None,
lr_multiplier=L(build_lr_scheduler_lazy)(
max_iters=60000,
warmup_iters=200,
solver_steps=[50000],
solver_gamma=0.1,
base_lr=1e-4,
sched='CosineAnnealingLR',
),
)
調參策略:
-
swin-tiny -
upernet -
maskformer/mask2former -
RT-DETR -
yolov5 -
swin-transformer -
slice det image -
copypaste
調優(yōu)過程:
我們從swin-tiny開始 再到convnext-L的upernet,dino(減少transformer層的)檢測的效果一直不佳。優(yōu)先考慮單任務的調參,從Segmentation開始,從PaddleSeg調試maskformer,mask2former其實在同階段已經調通,我們?yōu)榱斯?jié)省調優(yōu)的時間,mask2former需要更長的訓練周期 2Days more,而且maskformer的精度是接近當時榜上的最好的成績。檢測部分仍然很差,開始調優(yōu)ppyoloe-head,ppyolo的head train需要額外的參,過于復雜,所以調試了RT-DETR,這個過程中嘗試了slice切圖,2048的大尺度推理等策略,經過多輪的調參,我們把檢測的head換回yolov5 anchor base的head,繼續(xù)嘗試多尺度的ms tta。
在6月底,重新修改了baseline。使用convnext-L+maskformer-fc head -yolov5 head,作為新基線。繼續(xù)嘗試1024 切圖,mosaic 等transform。發(fā)現反而掉點,接下來對檢測的目標進行crop,隨機貼圖全類別做會導致seg的掉點,我們平衡了數據集,將<400 個目標的class 進行貼圖訓練,指標能到94.8 接下來換backbone,我們將backbone 換成swin-transformer-L 那么當前的結構為 swin-L+maskformer +fc head yolov5。seg 直接漲到 0.69 但是 配上RT-DETR head 檢測不佳。最終我們換回new base 7.1號的方案,把maskformer換成mask2former。
更多的實驗結果可以去我的repo查看:https://github.com/chuliuT/OneForAll_mask2former_yolov5
5.調參經驗
-
3e-4通常是一個很好的學習率,AdamW+CosineWarmup -
在模型選型的前期可以使用少量的數據和輕量級的網絡來嘗試調優(yōu) -
數據集的EDA分析在調優(yōu)的同時盡快找出賽題難點,需要處理的地方 -
數據增強的組合需要更多的實驗的嘗試,但有效的只有那么兩三個 -
模型訓練的收斂時間節(jié)點需要實驗去預估 -
不到最后一刻,不要放棄你的提交
6 .總結
隨著數據的規(guī)模大小和模型的日益更新,越來越多的研究者開始傾向于使用transformer模型來處理圖像任務。因為transformer模型具有較好的表現力和良好的遷移性,逐漸取代了傳統的convnet模型在圖像處理領域的主導地位。
然而,尺度變化一直是一個令人頭疼的問題。在處理圖像中的尺度變化時,嘗試了各種策略,如多尺度訓練和圖像金字塔等方法,以應對不同尺度下的物體檢測和分類任務。除了尺度變化,圖像中還存在著其他挑戰(zhàn),例如小目標檢測、細粒度分類和語義分割中的像素不平衡。
對于小目標檢測問題,采用了random_crop和ms推理的方式來提高性能。在細粒度分類任務中,致力于解決類別之間差異較小導致的難題,通過引入更加精細的特征表示和auto-augment來改善分類結果。而在語義分割任務中,類別像素不平衡問題一直存在,探索了各種通用和任務特定的解決方案,如不確定損失函數、像素平衡采樣等方法來解決。ConvNeXt和Swin-Transformer是當前主流的兩種模型派系。ConvNeXt具有更快的收斂時間,適合處理大規(guī)模數據集,而Swin-Transformer在表現力和遷移能力方面更好。
在本賽題中,我們在設計方案時考慮了精度和收斂時間之間的權衡關系,選擇了ConvNeXt-Large作為基礎網絡結構,并結合了clshead、mask2former和yolov5Head組合以達到更好的綜合性能。然而,在多任務訓練中,如何控制grad的scale仍然是一個待解決的問題。當前的訓練策略導致了語義分割任務過早進入收斂期,而分類和目標檢測任務仍處于欠擬合階段。展望未來,多任務大模型的聯合訓練仍然是一個具有挑戰(zhàn)性的課題。同時,在微調階段如何保持歷史知識也是一個重要的問題。視覺提示微調(Visual Prompt Tuning)給了我們一些啟示,但還需要進一步的研究和驗證其效果。我們相信通過不斷地探索和創(chuàng)新,可以進一步提升多任務視覺大模型的性能和應用范圍。
7 .參考文獻
[1]. Liu, Zhuang, et al. A ConvNet for the 2020s. arXiv preprint arXiv:2201.03545, 2022.
[2]. Liu, Ze, et al. Swin transformer: Hierarchical vision transformer using shifted windows. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. 2021. p. 10012-10022.
[3] https://mp.weixin.qq.com/s/Hki01Zs2lQgvLSLWS0btrA
[4] Per-Pixel Classification is Not All You Need for Semantic Segmentation
[5] Masked-attention Mask Transformer for Universal Image Segmentation
[6] DETRs Beat YOLOs on Real-time Object Detection
[7] Unified Perceptual Parsing for Scene Understanding
[8]https://aistudio.baidu.com/aistudio/projectdetail/6337782?sUid=930878&shared=1&ts=1691544272476
[9]https://github.com/xiteng01/CVPR2023_foundation_model_Track1
[10] https://github.com/HandsLing/CVPR2023-Track1-2rd-Solution