
長鏈接轉短鏈的那些難事!!!
點擊上方藍色“架構師修行之路”,選擇“設為星標”
學最好的別人,做最好的我們
短網(wǎng)址的長度
短網(wǎng)址的長度該設計為多少呢?當前互聯(lián)網(wǎng)上的網(wǎng)頁總數(shù)大概是 45億(參考 http://www.worldwidewebsize.com),超過了
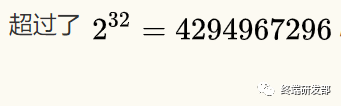
,那么用一個64位整數(shù)足夠了。
一個64位整數(shù)如何轉化為字符串呢?,假設我們只是用大小寫字母加數(shù)字,那么可以看做是62進制數(shù),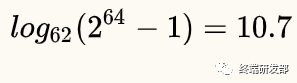 ,即字符串最長11就足夠了。
,即字符串最長11就足夠了。
實際生產(chǎn)中,還可以再短一點,比如新浪微博采用的長度就是7,因為 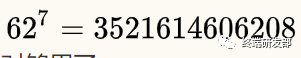 ,這個量級遠遠超過互聯(lián)網(wǎng)上的URL總數(shù)了,絕對夠用了。
,這個量級遠遠超過互聯(lián)網(wǎng)上的URL總數(shù)了,絕對夠用了。
現(xiàn)代的web服務器(例如Apache, Nginx)大部分都區(qū)分URL里的大小寫了,所以用大小寫字母來區(qū)分不同的URL是沒問題的。
因此,正確答案:長度不超過7的字符串,由大小寫字母加數(shù)字共62個字母組成
一對一還是一對多映射?
一個長網(wǎng)址,對應一個短網(wǎng)址,還是可以對應多個短網(wǎng)址?這也是個重大選擇問題
一般而言,一個長網(wǎng)址,在不同的地點,不同的用戶等情況下,生成的短網(wǎng)址應該不一樣,這樣,在后端數(shù)據(jù)庫中,可以更好的進行數(shù)據(jù)分析。如果一個長網(wǎng)址與一個短網(wǎng)址一一對應,那么在數(shù)據(jù)庫中,僅有一行數(shù)據(jù),無法區(qū)分不同的來源,就無法做數(shù)據(jù)分析了。
以這個7位長度的短網(wǎng)址作為唯一ID,這個ID下可以掛各種信息,比如生成該網(wǎng)址的用戶名,所在網(wǎng)站,HTTP頭部的 User Agent等信息,收集了這些信息,才有可能在后面做大數(shù)據(jù)分析,挖掘數(shù)據(jù)的價值。短網(wǎng)址服務商的一大盈利來源就是這些數(shù)據(jù)。
正確答案:一對多
如何計算短網(wǎng)址
現(xiàn)在我們設定了短網(wǎng)址是一個長度為7的字符串,如何計算得到這個短網(wǎng)址呢?
最容易想到的辦法是哈希,先hash得到一個64位整數(shù),將它轉化為62進制整,截取低7位即可。但是哈希算法會有沖突,如何處理沖突呢,又是一個麻煩。這個方法只是轉移了矛盾,沒有解決矛盾,拋棄。
MySQL數(shù)據(jù)庫有一個自增ID,能不能借鑒這個呢?每來一個長網(wǎng)址,就給它發(fā)一個號碼,這個號碼不斷的自增。這個方法跟哈希相比,好處是沒有沖突,不用考慮處理沖突的問題。如何實現(xiàn)單臺的發(fā)號服務器呢?可以用一臺MySQL服務器來做(一定要用 REPLACE INTO,不要存儲所有ID),也可用一臺Redis服務器(用INCR),一行代碼也不用寫;也可以自己寫一個RESTful API,代碼也很簡單,就不贅述了。
單臺發(fā)號器有什么缺點呢?它是一個單點故障(SPOF, Single Point Of Failure),也會成為性能瓶頸(其實,如果你的QPS能大到壓垮這臺MySQL,那說明你的短網(wǎng)址服務很成功,可以考慮上市了:D),所以它適合中小型企業(yè),對于超大型企業(yè)(以及在面試顯得追求高大上),我們還是要繼續(xù)思考更好的方案,請接著往下看。
下面開始講如何打造多臺機器組成的分布式發(fā)號器。
使用UUID算法或者MongoDB產(chǎn)生的ObjectID。其實MongoDB的ObjectID也算是一種UUID,這類算法,每臺機器可以獨立工作,天然是分布式的,但是這類算法產(chǎn)生的ID通常都很長,那短網(wǎng)址服務還有什么意義呢?所以這個方法不行。
多臺MySQL服務器。前面講了單臺MySQL作為發(fā)號服務器,那么自然可以擴展一下,比如用8臺MySQL服務器協(xié)同工作,第一臺MySQL初始值是1,每次自增8,第二臺MySQL初始值是2,每次自增8,一次類推。前面用一個 round-robin load balancer 擋著,每來一個長網(wǎng)址請求,由 round-robin balancer 隨機地將請求發(fā)給10臺MySQL中的任意一個,然后返回一個ID。Flickr用的就是這個方案,僅僅使用了兩臺MySQL服務器。這個方法僅有的一個缺點是,ID是連續(xù)的,容易被爬蟲抓數(shù)據(jù),爬蟲基本不用寫代碼,順著ID一個一個發(fā)請求就是了,太方便了(手動斜眼)。
分布式ID生成器(Distributed Id Generator)。分布式的產(chǎn)生唯一的ID,比如 Twitter 有個成熟的開源項目,就是專門做這個的,Twitter Snowflake 。Snowflake的核心算法如下:
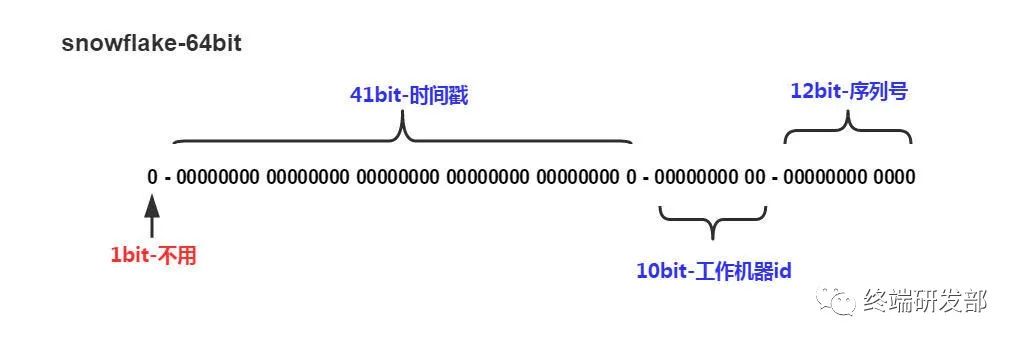
最高位不用,最高位不用,永遠為0,其余三組bit占位均可浮動,看具體的業(yè)務需求而定。默認情況下41bit的時間戳可以支持該算法使用到2082年,10bit的工作機器id可以支持1023臺機器,序列號支持1毫秒產(chǎn)生4095個自增序列id。
Instagram用了類似的方案,41位表示時間戳,13位表示shard Id(一個shard Id對應一臺PostgreSQL機器),最低10位表示自增ID,怎么樣,跟Snowflake的設計非常類似吧。這個方案用一個PostgreSQL集群代替了Twitter Snowflake 集群,優(yōu)點是利用了現(xiàn)成的PostgreSQL,容易懂,維護方便。
因此,正確答案:分布式發(fā)號器(Distributed ID Generator),F(xiàn)lick, Twitter Snowflake 和 Instagram的方案都是不錯的選擇。
如何存儲
如果存儲短網(wǎng)址和長網(wǎng)址的對應關系?以短網(wǎng)址為 primary key, 長網(wǎng)址為value, 可以用傳統(tǒng)的關系數(shù)據(jù)庫存起來,例如MySQL, PostgreSQL,也可以用任意一個分布式KV數(shù)據(jù)庫,例如Redis, LevelDB。
如果你手癢想要手工設計這個存儲,那就是另一個話題了,你需要完整地造一個KV存儲引擎輪子。當前流行的KV存儲引擎有LevelDB何RockDB,去讀它們的源碼吧。
301還是302重定向
這也是一個有意思的問題。這個問題主要是考察你對301和302的理解,以及瀏覽器緩存機制的理解。
301是永久重定向,302是臨時重定向。短地址一經(jīng)生成就不會變化,所以用301是符合http語義的。但是如果用了301, Google,百度等搜索引擎,搜索的時候會直接展示真實地址,那我們就無法統(tǒng)計到短地址被點擊的次數(shù)了,也無法收集用戶的Cookie, User Agent 等信息,這些信息可以用來做很多有意思的大數(shù)據(jù)分析,也是短網(wǎng)址服務商的主要盈利來源。
所以,正確答案是302重定向。
可以抓包看看新浪微博的短網(wǎng)址是怎么做的,使用 Chrome 瀏覽器,訪問這個URL http://t.cn/RX2VxjI,是我事先發(fā)微博自動生成的短網(wǎng)址。來抓包看看返回的結果是啥,
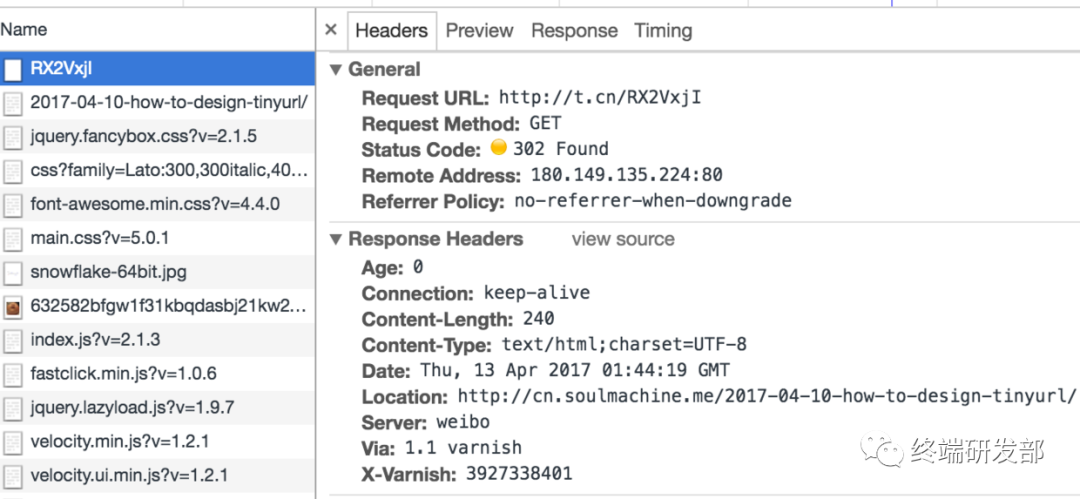
可見新浪微博用的就是302臨時重定向。
預防攻擊
如果一些別有用心的黑客,短時間內(nèi)向TinyURL服務器發(fā)送大量的請求,會迅速耗光ID,怎么辦呢?
首先,限制IP的單日請求總數(shù),超過閾值則直接拒絕服務。
光限制IP的請求數(shù)還不夠,因為黑客一般手里有上百萬臺肉雞的,IP地址大大的有,所以光限制IP作用不大。
可以用一臺Redis作為緩存服務器,存儲的不是 ID->長網(wǎng)址,而是 長網(wǎng)址->ID,僅存儲一天以內(nèi)的數(shù)據(jù),用LRU機制進行淘汰。這樣,如果黑客大量發(fā)同一個長網(wǎng)址過來,直接從緩存服務器里返回短網(wǎng)址即可,他就無法耗光我們的ID了。
轉載 http://cn.soulmachine.me/2017-04-10-how-to-design-tinyurl/


程序員的媽媽居然是產(chǎn)品經(jīng)理,她會如何逼你結婚?
