
解析動態(tài)內(nèi)容
解析動態(tài)內(nèi)容
根據(jù)權(quán)威機(jī)構(gòu)發(fā)布的全球互聯(lián)網(wǎng)可訪問性審計報告,全球約有四分之三的網(wǎng)站其內(nèi)容或部分內(nèi)容是通過JavaScript動態(tài)生成的,這就意味著在瀏覽器窗口中“查看網(wǎng)頁源代碼”時無法在HTML代碼中找到這些內(nèi)容,也就是說我們之前用的抓取數(shù)據(jù)的方式無法正常運轉(zhuǎn)了。解決這樣的問題基本上有兩種方案,一是JavaScript逆向工程;另一種是渲染JavaScript獲得渲染后的內(nèi)容。
JavaScript逆向工程
下面我們以“360圖片”網(wǎng)站為例,說明什么是JavaScript逆向工程。其實所謂的JavaScript逆向工程就是找到通過Ajax技術(shù)動態(tài)獲取數(shù)據(jù)的接口。在瀏覽器中輸入http://image.so.com/z?ch=beauty就可以打開“360圖片”的“美女”版塊,如下圖所示。
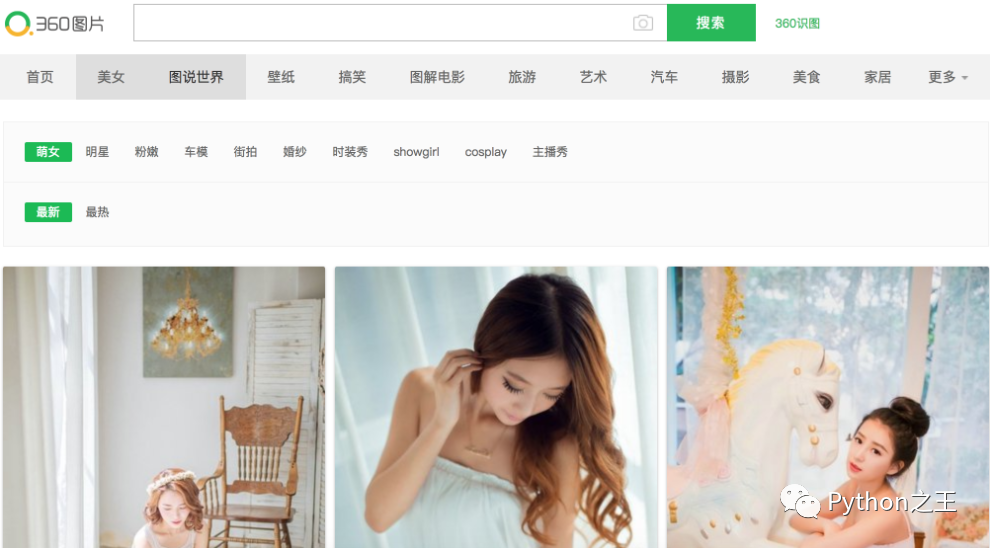
但是當(dāng)我們在瀏覽器中通過右鍵菜單“顯示網(wǎng)頁源代碼”的時候,居然驚奇的發(fā)現(xiàn)頁面的HTML代碼中連一個標(biāo)簽都沒有,那么我們看到的圖片是怎么顯示出來的呢?原來所有的圖片都是通過JavaScript動態(tài)加載的,而在瀏覽器的“開發(fā)人員工具”的“網(wǎng)絡(luò)”中可以找到獲取這些圖片數(shù)據(jù)的網(wǎng)絡(luò)API接口,如下圖所示。
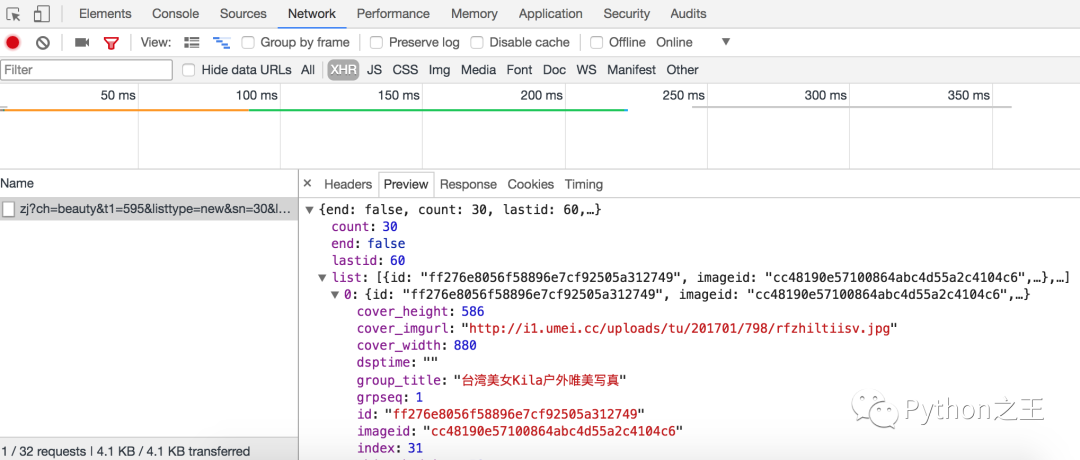
那么結(jié)論就很簡單了,只要我們找到了這些網(wǎng)絡(luò)API接口,那么就能通過這些接口獲取到數(shù)據(jù),當(dāng)然實際開發(fā)的時候可能還要對這些接口的參數(shù)以及接口返回的數(shù)據(jù)進(jìn)行分析,了解每個參數(shù)的意義以及返回的JSON數(shù)據(jù)的格式,這樣才能在我們的爬蟲中使用這些數(shù)據(jù)。
使用Selenium
盡管很多網(wǎng)站對自己的網(wǎng)絡(luò)API接口進(jìn)行了保護(hù),增加了獲取數(shù)據(jù)的難度,但是只要經(jīng)過足夠的努力,絕大多數(shù)還是可以被逆向工程的,但是在實際開發(fā)中,我們可以通過瀏覽器渲染引擎來避免這些繁瑣的工作,WebKit就是一個利用的渲染引擎。
WebKit的代碼始于1998年的KHTML項目,當(dāng)時它是Konqueror瀏覽器的渲染引擎。2001年,蘋果公司從這個項目的代碼中衍生出了WebKit并應(yīng)用于Safari瀏覽器,早期的Chrome瀏覽器也使用了該內(nèi)核。在Python中,我們可以通過Qt框架獲得WebKit引擎并使用它來渲染頁面獲得動態(tài)內(nèi)容,關(guān)于這個內(nèi)容請大家自行閱讀《爬蟲技術(shù):動態(tài)頁面抓取超級指南》一文。
如果沒有打算用上面所說的方式來渲染頁面并獲得動態(tài)內(nèi)容,其實還有一種替代方案就是使用自動化測試工具Selenium,它提供了瀏覽器自動化的API接口,這樣就可以通過操控瀏覽器來獲取動態(tài)內(nèi)容。首先可以使用pip來安裝Selenium。
pip3?install?selenium
下面以“阿里V任務(wù)”的“直播服務(wù)”為例,來演示如何使用Selenium獲取到動態(tài)內(nèi)容并抓取主播圖片。
import?requests
from?bs4?import?BeautifulSoup
def?main():
????resp?=?requests.get('https://v.taobao.com/v/content/live?catetype=704&from=taonvlang')
????soup?=?BeautifulSoup(resp.text,?'lxml')
????for?img_tag?in?soup.select('img[src]'):
????????print(img_tag.attrs['src'])
if?__name__?==?'__main__':
????main()
運行上面的程序會發(fā)現(xiàn)沒有任何的輸出,因為頁面的HTML代碼上根本找不到標(biāo)簽。接下來我們使用Selenium來獲取到頁面上的動態(tài)內(nèi)容,再提取主播圖片。
from?bs4?import?BeautifulSoup
from?selenium?import?webdriver
from?selenium.webdriver.common.keys?import?Keys
def?main():
????driver?=?webdriver.Chrome()
????driver.get('https://v.taobao.com/v/content/live?catetype=704&from=taonvlang')
????soup?=?BeautifulSoup(driver.page_source,?'lxml')
????for?img_tag?in?soup.body.select('img[src]'):
????????print(img_tag.attrs['src'])
if?__name__?==?'__main__':
????main()
在上面的程序中,我們通過Selenium實現(xiàn)對Chrome瀏覽器的操控,如果要操控其他的瀏覽器,可以創(chuàng)對應(yīng)的瀏覽器對象,例如Firefox、IE等。運行上面的程序,如果看到如下所示的錯誤提示,那是說明我們還沒有將Chrome瀏覽器的驅(qū)動添加到PATH環(huán)境變量中,也沒有在程序中指定Chrome瀏覽器驅(qū)動所在的位置。
selenium.common.exceptions.WebDriverException:?Message:?'chromedriver'?executable?needs?to?be?in?PATH.?Please?see?https://sites.google.com/a/chromium.org/chromedriver/home
為了解決上面的問題,可以到Selenium的官方網(wǎng)站找到瀏覽器驅(qū)動的下載鏈接并下載需要的驅(qū)動,在Linux或macOS系統(tǒng)下可以通過下面的命令來設(shè)置PATH環(huán)境變量,Windows下配置環(huán)境變量也非常簡單,不清楚的可以自行了解。
export?PATH=$PATH:/Users/Hao/Downloads/Tools/chromedriver/
其中/Users/Hao/Downloads/Tools/chromedriver/就是chromedriver所在的路徑。當(dāng)然,更為簡單的辦法是把chromedriver直接放在虛擬環(huán)境中,跟Python解釋器位于同一個路徑下就可以了。