一夜之間,年輕人最喜歡的彈幕視頻網(wǎng)站突然崩潰了半小時,隨后 A 站、豆瓣也如出一轍。有網(wǎng)友稱“著火”所至,但上海消防隊隨后出來辟謠。那么,究竟是怎么回事?

崩了!勞累了一天的年輕人們,正準備躺平拿出手機,打開那熟悉的小破站 App,一鍵三連自己最喜愛的 up 主的最新視頻。突然發(fā)現(xiàn):
瞬間,“B 站崩了”的消息登上熱搜,微博運維心頭一緊。
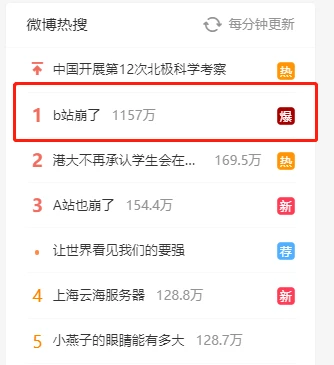
部分網(wǎng)友表示:A 站、豆瓣等網(wǎng)站也出現(xiàn)訪問故障,重連 Wi-Fi 也沒有用。

今日凌晨,B 站發(fā)布公告稱,昨晚,B 站的部分服務器機房發(fā)生故障,造成無法訪問。技術(shù)團隊隨即進行了問題排查和修復,現(xiàn)在服務已經(jīng)陸續(xù)恢復正常。

短短幾分鐘,關于 B 站的各種揣測消息就變成了百家講壇:
有火災說、刪庫跑路說、刑事案件說、服務器供應商說、黑客攻擊說、大樓坍塌說、外星人說……

還有人煞有介事地 Po 出了 B 站運營小妹的朋友圈,說 B 站停電了……
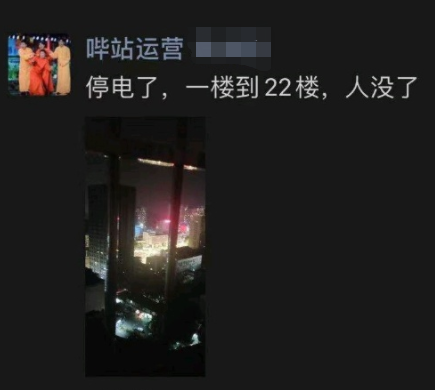
隨后立刻有專業(yè)人士指出:B 站作為一個上市的互聯(lián)網(wǎng)公司,服務器多地備份是最最起碼的事,樓里停電這個解釋,估計只能騙騙沒有學過數(shù)據(jù)庫的高中生。
至于 A 站和晉江文學網(wǎng)為什么會掛,很可能是因為 B 站掛了,大批用戶無片可看,就涌入 A 站和豆瓣,造成網(wǎng)站的流量激增,哪怕 A 站和 B 站不共用云服務,也可能被壓垮。
B 站 7000 多萬日活網(wǎng)友的威力可見一斑。

①知乎作者 @黃玨珅 盲猜了一下,應該是 etcd 掛了。
通常來說,能造成幾乎所有請求都 502 的,要不就是前端和后端之間的網(wǎng)絡通路全掛了,要不就是后端的服務全都掛了。
那么現(xiàn)在的大型互聯(lián)網(wǎng)公司的基礎設施是怎樣的呢,大多數(shù)使用了 Kubernetes,實現(xiàn)全國各地的數(shù)據(jù)中心的容器編排、網(wǎng)絡虛擬化等。
而 Kubernetes 的設計上,網(wǎng)絡插件和 pod 編排又是相對獨立的。
如果只是網(wǎng)絡插件出問題了,那么部分服務器上的網(wǎng)絡插件的緩存還在,一定有部分用戶還能正常使用。
現(xiàn)在所有的都掛了,那只能是 etcd 掛掉,導致反向代理無法通過 etcd 找到對應的 pod 的虛擬 ip,又無法通過網(wǎng)絡插件與對應的 pod 通信。
②知乎作者 @k8seasy 則認為這個基本屬于站點本身故障。從恢復時間看 30 分鐘左右,并且?guī)缀?100% 恢復,說明應該是某個核心組件崩潰了,導致核心服務不可用。
出現(xiàn)這種可能的不少,最有可能的原因是上線新版本,開始沒問題,升級了部分集群,結(jié)果新版本有 Bug,到了某個時刻直接掛了,老版本的壓力一大也沒扛住。然后緊急定位,回滾解決。
也有網(wǎng)友提出,此次事件與云服務商離不開干系:
云服務提供商提供的 CDN 出現(xiàn)意外之后,大量請求繞過 CDN 直接打到網(wǎng)關,網(wǎng)關收到大量請求,自動啟動了容災策略。
容災策略啟動服務降級。服務降級了但沒完全降,CDN 掛了,網(wǎng)關也跟著掛了,服務雪崩,一直崩到整個環(huán)境。在互聯(lián)網(wǎng)歷史上,“小破站”這樣的宕機事件只能算是“灑灑水”,不信?我們來看看其他互聯(lián)網(wǎng)大咖們是如何玩轉(zhuǎn)宕機的。
7 小時不能上微信:2013 年 7 月 22 日,微信服務宕機,造成了將近 7 個小時的網(wǎng)絡中斷。據(jù)微信官方公布信息,由于上海一支施工隊挖斷了通信光纜,導致騰訊華東數(shù)據(jù)處理中心的業(yè)務請求紛紛轉(zhuǎn)向華南和華北,進而導致了業(yè)務的全面癱瘓。
用支付寶“剁手”失敗:2015 年 5 月 27 日下午,部分用戶反映其支付寶出現(xiàn)網(wǎng)絡故障,賬號無法登錄或支付。支付寶官方表示,故障是由于杭州市蕭山區(qū)某地光纖被挖斷導致,該事件造成部分用戶無法使用支付寶。隨后支付寶工程師緊急將用戶請求切換至其他機房,受影響的用戶開始逐步恢復。到了晚上 7 點 20 分,支付寶方面宣布用戶服務已經(jīng)完全恢復正常。

而在國外,網(wǎng)絡宕機的事件更是屢見不鮮。
亞馬遜云服務罷工:2015 年 9 月,亞馬遜的云服務器因收到來自新上線的 DynamoDB 功能帶來的大量數(shù)據(jù)請求,導致其因過載而宕機。于是,包括 Reddit、Tinder、Netflix 和 IMDB 在內(nèi)的眾多流行應用和網(wǎng)址直接罷工了數(shù)小時。
除了 Netflix,絕大多數(shù)亞馬遜云服務的客戶在此次“突擊檢查”中,都被發(fā)現(xiàn)毫無準備。而 Netflix 此前已經(jīng)使用過一種名為“混沌工程”的技術(shù)來模擬類似服務中斷事件的發(fā)生,使得這起事故對其影響降到了最小。

納斯達克停擺:2013 年 8 月 22 日,由于納斯達克交易所的備用服務器中出現(xiàn)了一個嚴重的 Bug,直接導致納斯達克停擺了 3 個多小時。當其恢復運作時,已經(jīng)引起了市場恐慌,大量交易員涌向交易窗口,出售交易所運營商納斯達克 OMX 集團的股票,導致 OMX 集團的股價當日一度大跌逾 5%。
事后有人評估,由于納斯達克停擺造成的經(jīng)濟損失可能達數(shù)億美元。

全美大宕機:2016 年 10 月 21 日早晨,許多美國用戶突然發(fā)現(xiàn)包括 Twitter、CNN、Spotify 等大型網(wǎng)站均無法登陸。這場網(wǎng)絡癱瘓從美國東部開始,一路蔓延至全美區(qū)域。事后發(fā)現(xiàn)查明,原因是服務器遭受了黑客的 DDoS 攻擊。
關于 B 站宕機事故,開源基礎軟件公司 Zilliz 的質(zhì)量保障團隊負責人喬燕良做了較為專業(yè)客觀的分析:
現(xiàn)在的網(wǎng)站故障造成的原因主要可分為軟件服務引起的故障和硬件服務引起的故障。
軟件服務故障一般可理解為代碼邏輯缺陷,常見的是新增或更新某個功能而引入缺陷導致整個服務中斷,硬件服務故障一般是由于某些服務設備的損壞造成的服務中斷,比如光纖被挖斷了。
如果要降低宕機風險,就需要提高服務的高可用性。首先從架構(gòu)上,建議采用云原生架構(gòu),實現(xiàn)自動容錯機制和故障隔離,從而能夠在服務出現(xiàn)故障時快速遷移或回滾。
其次為防止硬件故障類風險,需要有完善的災備方案,同城雙活或異地災備目前都已經(jīng)有比較成熟的方案,國內(nèi)企業(yè)在這塊投入相對比較“節(jié)約”。
關于 B 站的高可用架構(gòu)可查看文章:《月均活躍用戶達1.3億,B站高可用架構(gòu)實踐》
來源:轉(zhuǎn)載自公眾號新智元(ID:AI_era)
參考資料:http://www.zhihu.com/question/472065470
回復 【實戰(zhàn)】獲取20套實戰(zhàn)源碼回復 【小程序】學獲取15套【入門+實戰(zhàn)+賺錢】小程序源碼回復 【python】學微獲取全套0基礎Python知識手冊回復 【2019】獲取2019 .NET 開發(fā)者峰會資料PPT




