
Spark查詢太慢?試試這款MPP數(shù)據(jù)庫吧!
導(dǎo)讀:Greenplum數(shù)據(jù)庫是基于MPP架構(gòu)的開源大數(shù)據(jù)平臺,具有良好的彈性和線性擴(kuò)展能力,內(nèi)置并行存儲、并行通信、并行計(jì)算和并行優(yōu)化功能,兼容SQL標(biāo)準(zhǔn),具有強(qiáng)大、高效的PB級數(shù)據(jù)存儲、處理和實(shí)時分析能力,同時支持涵蓋OLTP型業(yè)務(wù)的混合負(fù)載,可部署于企業(yè)裸機(jī)、容器、私有云和公有云中,已為全球金融、電信、制造等行業(yè)核心生產(chǎn)系統(tǒng)提供支撐。
一、Greenplum數(shù)據(jù)庫架構(gòu)
Greenplum數(shù)據(jù)庫是典型的主從架構(gòu),一個Greenplum集群通常由一個Master節(jié)點(diǎn)、一個Standby Master節(jié)點(diǎn)以及多個Segment實(shí)例組成,節(jié)點(diǎn)之間通過高速網(wǎng)絡(luò)互連,如下圖所示。Standby Master節(jié)點(diǎn)為Master節(jié)點(diǎn)提供高可用支持,Mirror Segment實(shí)例為Segment實(shí)例提供高可用支持。當(dāng)Master節(jié)點(diǎn)出現(xiàn)故障時,數(shù)據(jù)庫管理系統(tǒng)可以快速切換到Standby Master節(jié)點(diǎn)繼續(xù)提供服務(wù)。
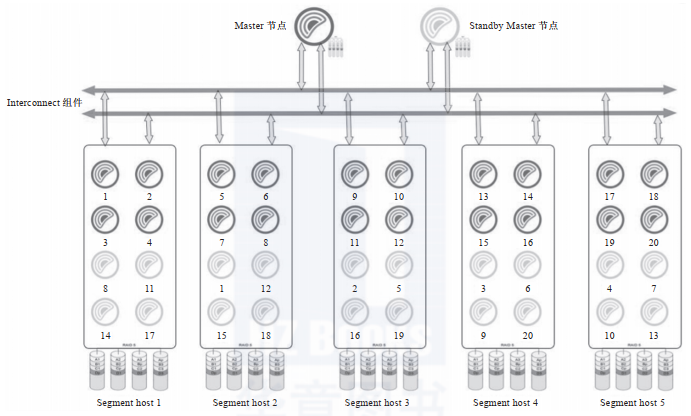
從軟件的角度看,Greenplum數(shù)據(jù)庫由Master節(jié)點(diǎn)、Segment實(shí)例和Interconnect組件三部分組成,各個功能模塊在系統(tǒng)中承載不同的角色。
Master節(jié)點(diǎn)是Greenplum數(shù)據(jù)庫的主節(jié)點(diǎn),也是數(shù)據(jù)庫的入口,主要負(fù)責(zé)接收用戶的SQL請求,將其生成并行查詢計(jì)劃并優(yōu)化,然后將查詢計(jì)劃分配給所有的Segment實(shí)例進(jìn)行處理,協(xié)調(diào)集群的各個Segment實(shí)例按照查詢計(jì)劃一步一步地并行處理,最后獲取Segment實(shí)例的計(jì)算結(jié)果并匯總后返回給客戶端。
從用戶的角度看Greenplum集群,看到的只是Master節(jié)點(diǎn),無須關(guān)心集群內(nèi)部機(jī)制,所有的并行處理都是在Master節(jié)點(diǎn)控制下自動完成的。Master節(jié)點(diǎn)一般只存儲系統(tǒng)數(shù)據(jù),不存儲用戶數(shù)據(jù)。為了提高系統(tǒng)可用性,我們通常會在Greenplum集群的最后一個數(shù)據(jù)節(jié)點(diǎn)上增加一個Standby Master節(jié)點(diǎn)。
Segment是Greenplum實(shí)際存儲數(shù)據(jù)和進(jìn)行數(shù)據(jù)讀取計(jì)算的節(jié)點(diǎn),每個Segment都可以視為一個獨(dú)立的PostgreSQL實(shí)例,上面存放著一部分用戶數(shù)據(jù),同時參與SQL執(zhí)行工作。Greenplum Datanode通常是指Segment實(shí)例所在的主機(jī),用戶可以根據(jù)Datanode的CPU數(shù)、內(nèi)存大小、網(wǎng)絡(luò)寬帶等來確定其上面的Segment實(shí)例個數(shù)。官方建議一個Datanode上面部署2~8個Segment實(shí)例。Segment實(shí)例越多,單個實(shí)例上面的數(shù)據(jù)越少(平均分配的情況下),單個Datanode的資源使用越充分,查詢執(zhí)行速度就越快。Datanode服務(wù)器的數(shù)量根據(jù)集群的數(shù)據(jù)量來確定,最大可以支持上千臺。另外,為了提高數(shù)據(jù)的安全性,我們有時候會在生產(chǎn)環(huán)境中創(chuàng)建Mirror Segment實(shí)例作為備份鏡像。
Interconnect是Master節(jié)點(diǎn)與Segment實(shí)例、Segment實(shí)例與Segment實(shí)例之間進(jìn)行數(shù)據(jù)傳輸?shù)慕M件,它基于千兆交換機(jī)或者萬兆交換機(jī)實(shí)現(xiàn)數(shù)據(jù)在節(jié)點(diǎn)之間的高速傳輸。默認(rèn)情況下,Interconnect組件使用UDP在集群網(wǎng)絡(luò)節(jié)點(diǎn)之間傳輸數(shù)據(jù),因?yàn)閁DP無法保證服務(wù)質(zhì)量,所以Interconnect組件在應(yīng)用層實(shí)現(xiàn)了數(shù)據(jù)包驗(yàn)證功能,從而達(dá)到和TCP一樣的可靠性。
Greenplum執(zhí)行查詢語句的過程如下:當(dāng)GP Server收到用戶發(fā)起的查詢語句時,會對查詢語句進(jìn)行編譯、優(yōu)化等操作,生成并行執(zhí)行計(jì)劃,分發(fā)給Segment實(shí)例執(zhí)行;Segment實(shí)例通過Interconnect組件和Master節(jié)點(diǎn)、其他Segment實(shí)例交換數(shù)據(jù),然后執(zhí)行查詢語句,執(zhí)行完畢后,會將數(shù)據(jù)發(fā)回給Master節(jié)點(diǎn),最后Master節(jié)點(diǎn)匯總返回的數(shù)據(jù)并將其反饋給查詢終端。
二、Greenplum的優(yōu)勢
首先,與傳統(tǒng)數(shù)據(jù)庫相比,Greenplum作為分布式數(shù)據(jù)庫,本身具有高性能優(yōu)勢。對各行各業(yè)來說,OLTP系統(tǒng)最重要的是在保證ACID事務(wù)管理屬性的前提下滿足業(yè)務(wù)的并發(fā)需求,對于大多數(shù)非核心應(yīng)用場景,MySQL、SQL Server、DB2、Oracle都可以滿足系統(tǒng)要求,并且隨著MySQL性能的優(yōu)化和云原生數(shù)據(jù)庫的發(fā)展,基于MySQL或者PostgreSQL商業(yè)化的數(shù)據(jù)庫會越來越普及。數(shù)據(jù)中臺的定位是一個OLAP系統(tǒng),上述數(shù)據(jù)庫就很難滿足海量數(shù)據(jù)并發(fā)查詢的要求了。上述數(shù)據(jù)庫的橫向擴(kuò)展能力有限,并且軟硬件成本高昂,不適合作為OLAP系統(tǒng)的數(shù)據(jù)庫。Greenplum作為一款基于MPP架構(gòu)的數(shù)據(jù)庫,具有開源、易于擴(kuò)展、高查詢性能的特點(diǎn),性價比碾壓DB2、Oracle、Teradata等傳統(tǒng)數(shù)據(jù)庫。
其次,Greenplum作為分布式數(shù)據(jù)庫,和同為分布式數(shù)據(jù)庫的Hive相比,優(yōu)勢也非常明顯。早期Hadoop的無模式數(shù)據(jù)已經(jīng)讓開發(fā)者飽受痛苦,后面興起的Hive、Presto、Spark SQL雖然支持簡單的SQL,但是查詢性能仍然是分鐘級別的,很難滿足OLAP的實(shí)時分析需求。后期雖有Impala+Kudu,但是查詢性能仍然弱于同為MPP架構(gòu)的Greenplum。除此之外,Hadoop生態(tài)圈非常復(fù)雜,安裝和維護(hù)的工作量都很大,沒有專業(yè)的運(yùn)維團(tuán)隊(duì)很難支撐系統(tǒng)運(yùn)行。而Greenplum支持的SQL標(biāo)準(zhǔn)最全面,查詢性能在毫秒級,不僅能很好地支持?jǐn)?shù)據(jù)ETL處理和OLAP查詢,還支持增刪改等操作,是一款綜合實(shí)力非常強(qiáng)的數(shù)據(jù)庫。相對于Hadoop多個組件組成的龐大系統(tǒng),Greenplum數(shù)據(jù)庫在易用性、可靠性、穩(wěn)定性、開發(fā)效率等方面都有非常明顯的優(yōu)勢。
最后,Greenplum作為MPP數(shù)據(jù)庫中的一員,相對于其他MPP架構(gòu)數(shù)據(jù)庫,也具有非常明顯的優(yōu)勢。Greenplum研發(fā)歷史長、應(yīng)用范圍廣、開源穩(wěn)定、生態(tài)系統(tǒng)完善。生態(tài)系統(tǒng)完善是指Greenplum的工具箱非常多:GPload可滿足高速加載需求,PXF可滿足外置表和文件存儲需求,MADlib可滿足數(shù)據(jù)挖掘需求,GPCC可滿足系統(tǒng)監(jiān)控運(yùn)維需求。相對于TiDB、TBase、GaussDB等新興數(shù)據(jù)庫來說,Greenplum的應(yīng)用案例最多,生態(tài)系統(tǒng)最完善,并且Bug更少。同時,TiDB、TBase、GaussDB等數(shù)據(jù)庫都定位于優(yōu)先滿足OLTP的同時提高OLAP的性能,而Greenplum是以O(shè)LAP優(yōu)先的。雖然前者也有優(yōu)勢,但是將OLAP和OLTP合并實(shí)現(xiàn)起來存在以下困難:數(shù)據(jù)分布在不同的系統(tǒng)已經(jīng)是行業(yè)現(xiàn)實(shí),沒有辦法將數(shù)據(jù)集中到同一個數(shù)據(jù)庫;數(shù)據(jù)中臺天然就是一個OLAP系統(tǒng),沒有辦法按照OLTP模式設(shè)計(jì)。綜上,作為分布式關(guān)系型數(shù)據(jù)庫,Greenplum是搭建數(shù)據(jù)中臺的首選數(shù)據(jù)庫。
如下圖是阿里巴巴大數(shù)據(jù)平臺進(jìn)化歷程。2010年前后,阿里巴巴曾經(jīng)使用Greenplum來替換Oracle集群,將其作為數(shù)據(jù)分析平臺。從數(shù)量上說,Greenplum在2010年實(shí)現(xiàn)了Oracle 10倍數(shù)據(jù)量的管理,即1000TB。但Oracle的架構(gòu)這些年沒有太大變化,而Greenplum數(shù)據(jù)庫已有翻天覆地的革新。在阿里巴巴應(yīng)用的時代,Greenplum還是EMC旗下的商用數(shù)據(jù)庫,平臺尚在發(fā)育期,功能也不太完善。而如今的Greenplum已經(jīng)是社區(qū)開源的產(chǎn)品,內(nèi)核PostgreSQL也已完成了多個版本的升級迭代,現(xiàn)在更是輕輕松松支持上千臺服務(wù)器的集群,因此承載PB級的數(shù)據(jù)自不在話下。
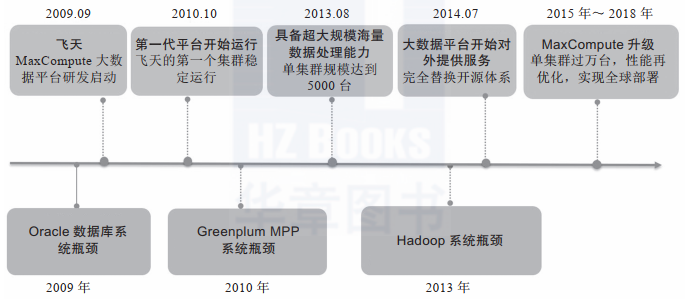
對于大多數(shù)有構(gòu)建數(shù)據(jù)中臺需求的企業(yè),1000TB已經(jīng)是一個無法企及的高度。大多數(shù)據(jù)企業(yè)的數(shù)據(jù)都在數(shù)TB到100TB的范圍內(nèi),這個規(guī)模的數(shù)據(jù)正是Greenplum的主要戰(zhàn)場。100TB以下規(guī)模的數(shù)據(jù)倉庫或者數(shù)據(jù)中臺,Hive發(fā)揮不了架構(gòu)上的優(yōu)勢,反而影響開發(fā)速度和運(yùn)維工作,實(shí)在是得不償失。
在查詢性能方面,Greenplum自然不是第一,雖然業(yè)界尚無定論,但是據(jù)筆者了解,目前ClickHouse是當(dāng)之無愧的OLAP冠軍。相對于ClickHouse,Greenplum勝在高性能的GPload插件、強(qiáng)大的ETL功能、不算太弱的增刪改性能。目前,數(shù)據(jù)中臺在穩(wěn)步向?qū)崟r流處理邁進(jìn),由于不擅長單條更新和刪除,因此ClickHouse只適合執(zhí)行離線數(shù)據(jù)查詢?nèi)蝿?wù),可以作為超大規(guī)模數(shù)據(jù)中臺的OLAP查詢引擎。
綜上所述,雖然Greenplum某些方面不是最優(yōu)秀的,但仍是最適合搭建數(shù)據(jù)中臺的分布式數(shù)據(jù)平臺,并且以Greenplum現(xiàn)有的性能和管理的數(shù)據(jù)規(guī)模,可以滿足絕大多數(shù)中小企業(yè)的數(shù)據(jù)中臺需求。
三、Greenplum性能測試
gpcheckperf是Greenplum數(shù)據(jù)庫自帶的性能測試工具,在指定的主機(jī)上啟動會話并進(jìn)行以下性能測試。
1)磁盤I/O測試(dd測試):測試邏輯磁盤或文件系統(tǒng)的順序吞吐性能,該工具使用dd命令。dd命令是一個標(biāo)準(zhǔn)的UNIX工具,記錄了在磁盤上讀寫一個大文件需要花費(fèi)的時間,以MB/s為單位計(jì)算磁盤I/O性能。默認(rèn)情況下,用于測試的文件尺寸按照主機(jī)上隨機(jī)訪問內(nèi)存(RAM)的兩倍計(jì)算。這樣確保了測試是真正地測試磁盤I/O而不是使用內(nèi)存緩存。
2)內(nèi)存帶寬測試:為了測試內(nèi)存帶寬,該工具使用STREAM基準(zhǔn)程序來測量可持續(xù)的內(nèi)存帶寬(以MB/s為單位)。本項(xiàng)測試內(nèi)容是檢驗(yàn)操作系統(tǒng)在不涉及CPU計(jì)算性能的情況下是否受系統(tǒng)內(nèi)存帶寬的限制。在數(shù)據(jù)集較大的應(yīng)用程序中(如在Greenplum數(shù)據(jù)庫中),低內(nèi)存帶寬是一個主要的性能問題。如果內(nèi)存帶寬明顯低于CPU的理論帶寬,則會導(dǎo)致CPU花費(fèi)大量的時間等待數(shù)據(jù)從系統(tǒng)內(nèi)存?zhèn)鬟f過來。
3)網(wǎng)絡(luò)性能測試:為了測試網(wǎng)絡(luò)性能以及Greenplum數(shù)據(jù)庫Interconnect組件的性能,該工具運(yùn)行一種網(wǎng)絡(luò)基準(zhǔn)測試程序,該程序在當(dāng)前主機(jī)連續(xù)發(fā)送5s的數(shù)據(jù)流到測試包含的每臺遠(yuǎn)程主機(jī)上。數(shù)據(jù)被并行傳輸?shù)矫颗_遠(yuǎn)程主機(jī),并以MB/s為單位,分別報(bào)告最小、最大、平均和中位網(wǎng)絡(luò)傳輸速率。如果匯總的傳輸速率比預(yù)期慢(小于100MB/s),可以使用-r N選項(xiàng)串行運(yùn)行該網(wǎng)絡(luò)測試以獲取每臺主機(jī)的結(jié)果。要運(yùn)行全矩陣帶寬測試,用戶可以指定-r M選項(xiàng),這將導(dǎo)致每臺主機(jī)都發(fā)送和接收來自指定的其他主機(jī)的數(shù)據(jù)。該測試適用于驗(yàn)證交換結(jié)構(gòu)是否可以承受全矩陣負(fù)載。
gpcheckperf命令應(yīng)用舉例如下。
#使用/data1和/data2作為測試目錄在文件host_file中的所有主機(jī)上運(yùn)行磁盤I/O和內(nèi)存帶寬測試
gpcheckperf?-f?hostfile_gpcheckperf?-d?/data1?-d?/data2?-r?ds
#在名為sdw1和sdw2的主機(jī)上只使用測試目錄/data1運(yùn)行磁盤I/O測試。顯示單個主機(jī)結(jié)果并以詳細(xì)模式運(yùn)行
gpcheckperf?-h?sdw1?-h?sdw2?-d?/data1?-r?d?-D?-v
#使用測試目錄/tmp運(yùn)行并行網(wǎng)絡(luò)測試,其中hostfile_gpcheck_ic*指定同一Interconnect子網(wǎng)內(nèi)的所有網(wǎng)絡(luò)接口的主機(jī)地址名稱
gpcheckperf?-f?hostfile_gpchecknet_ic1?-r?N?-d?/tmp
gpcheckperf?-f?hostfile_gpchecknet_ic2?-r?N?-d?/tmp
性能測試時間通常較長,為了進(jìn)行完整的測試,我一般會創(chuàng)建如下測試腳本,在后臺執(zhí)行性能測試任務(wù)。
#創(chuàng)建如下shell腳本
[gpadmin@gp-master?~]$?cat?gpcheckperf-test.sh?
#!bin/bash
echo?"---------?start?-----------?"
a=`date?+"%Y-%m-%d?%H:%M:%S"`
echo?$a
gpcheckperf?-f?/data/greenplum/greenplum-db/all_hosts?-d?/data/greenplum/?-v
echo?"-------------?end?----------"
b=`date?+"%Y-%m-%d?%H:%M:%S"`
echo?$b?
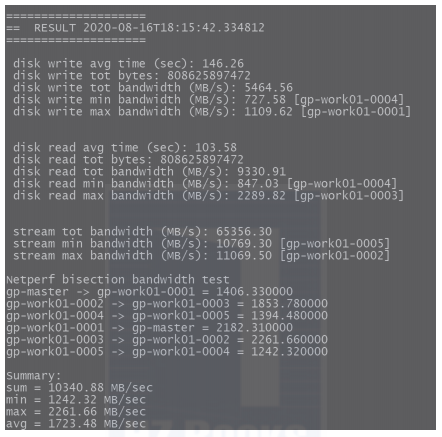
性能測試后臺執(zhí)行nohup sh gpcheckperf-test.sh &命令后,查看nohup.out的輸出結(jié)果,如下圖所示(每臺服務(wù)器采用10塊普通硬盤通過軟件組成Raid 5)。
關(guān)于作者:王春波,資深架構(gòu)師和數(shù)據(jù)倉庫專家,現(xiàn)任上海啟高信息科技有限公司大數(shù)據(jù)架構(gòu)師,Apache Doris和openGauss貢獻(xiàn)者,Greenplum中文社區(qū)參與者。?公眾號“數(shù)據(jù)中臺研習(xí)社”運(yùn)營者。

