GUI實(shí)戰(zhàn)|Python做一個(gè)文檔圖片提取軟件

大家好,在上周的辦公自動(dòng)化系列文章中,我們已經(jīng)講解了如何用Python讀取與寫入Excel圖片,在上上周的GUI系列文章中,也講解了如何制作一個(gè)圖片查看軟件。
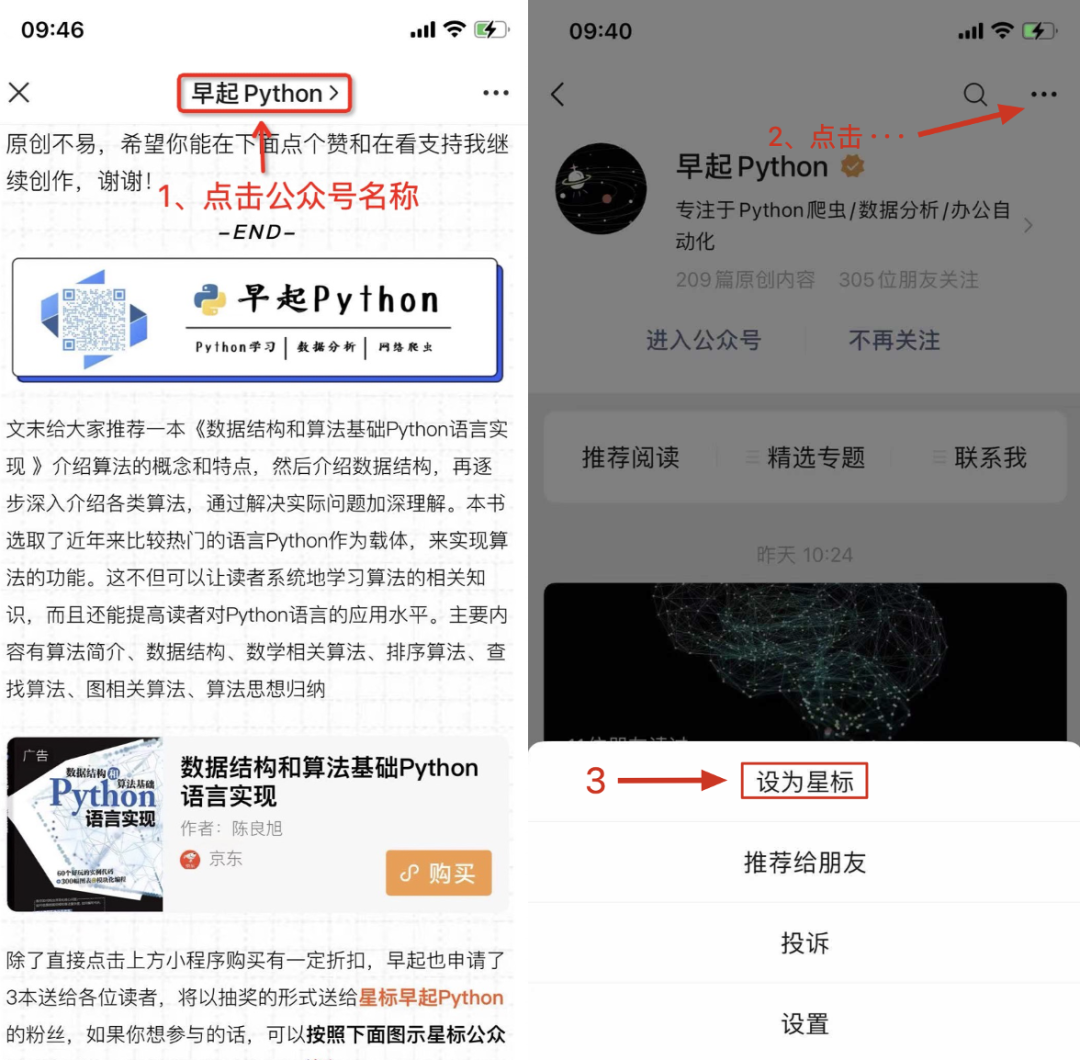
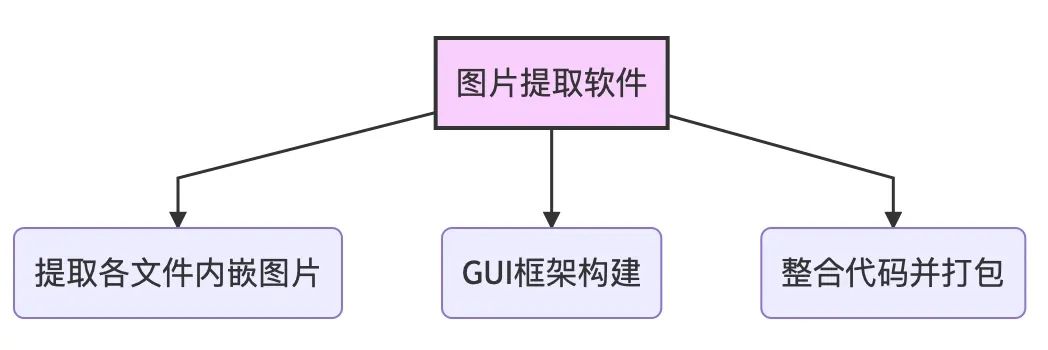
本文將進(jìn)一步講解如何用Python提取PDF與Word中圖片,并結(jié)合之前講解過(guò)的GUI框架PysimpleGUI,做一個(gè)多文件圖片提取軟件,效果如下:
本文主要將分為以下部分講解:
PDF、Word、Excel文件圖片提取 構(gòu)造圖片提取器GUI框架 整合代碼并打包
主要涉及的Python模塊有:
PILPySimpleGUIrewin32oszipfilefitz
? 準(zhǔn)備工作
首先使用pip安裝相關(guān)依賴模塊
pip?install?pillow???#這是對(duì)模塊PTL的安裝
pip?install?pypiwin32????#這是對(duì)win32的安裝
pip?install?os?
pip?install?zipfile
pip?install?PyMuPDF??#這是引用fitz對(duì)PDF操作的包
pip?install?PySimpleGui
? 一、提取各文件內(nèi)嵌圖片
在之前的文章有講過(guò),讀取Excel有兩種方法。一種是將后綴名改成.zip格式進(jìn)行提取,一種是通過(guò)Pillow模塊對(duì)Excel進(jìn)行圖片復(fù)制與保存。而在我們這次3種文件格式的圖片提取當(dāng)中,Excel提取圖片方法和之前一樣。
Word提取圖片方法和通過(guò).zip提取方法類似,PDF提取圖片方法要用到新的模塊。由于Excel提取圖片的兩種方法在之前的文章講過(guò),故這里只講解PDF和Word的提取方法。
1.1 提取Word圖片思路
和以前一樣,我們先看代碼再講解
path?=?values["lujing"]??
count?=?1
for?file?in?os.listdir(path):
????new_file?=?file.replace(".docx",".zip")
????os.rename(os.path.join(path,file),os.path.join(path,new_file))
????count+=1??????
????number?=?0
????craterDir?=?values["lujing"]?+?'/'??#?存放zip文件的文件夾路徑
????saveDir?=?values["lujing"]?+?'/'?#?存放圖片的路徑
????list_dir?=?os.listdir(craterDir)?#?獲取所有的zip文件名
????for?i?in?range(len(list_dir)):
????????if?'zip'?not?in?list_dir[i]:
????????????list_dir[i]?=?''
????????????while?''?in?list_dir:
????????????????list_dir.remove('')????????????????????????????
????????????????for?zip_name?in?list_dir:
????????????????????#?默認(rèn)模式r,讀
????????????????????azip?=?zipfile.ZipFile(craterDir?+?zip_name)
????????????????????#?返回所有文件夾和文件
????????????????????namelist?=?(azip.namelist())
????????????????????for?idx?in?range(0,len(namelist)):
????????????????????????if?namelist[idx][:11]?==?'word/media/':#圖片是在這個(gè)路徑下
????????????????????????????img_name?=?saveDir?+?str(number)+'.jpg'
????????????????????????????f?=?azip.open(namelist[idx])
????????????????????????????img?=?Image.open(f)
????????????????????????????img?=?img.convert("RGB")
????????????????????????????img.save(img_name,"JPEG")
????????????????????????????number?+=?1
????????????????????????????azip.close()??#關(guān)閉文件,必須有,釋放內(nèi)存
這里的代碼和GUI中通過(guò).zip方式提取Excel圖片的代碼思路是一樣的。
“
path = values["lujing"]這里是讀取GUI中鍵為**“l(fā)ujing”**的值,也即文件存儲(chǔ)位置,用于os模塊讀取與操作。
new_file = file.replace(".docx",".zip")是替換后綴名,如果是Excel的話,就把.docx改成.xlsx或xls。
craterDir = values["lujing"] + '/'?這是存放zip文件的文件夾路徑,注意這里讀取到的鍵為“l(fā)ujing”的值后要在后面添加/。”
saveDir = values["lujing"] + '/'?這是存放圖片的路徑,同理,和上面一樣加個(gè)/號(hào)。
最后說(shuō)一下與Excel提取相比,最大的不同是下面的代碼
if namelist[idx][:11] == 'word/media/':細(xì)心的讀者可以發(fā)現(xiàn),與Excel提取相比,中括號(hào)里面的值改了。
很好理解,我們可以打印namelist[idx],可以發(fā)現(xiàn)在索引0到10是'word/media/'所在位置。而在Excel中是前9位。
感興趣的讀者可以翻看之前的文章,那里有對(duì)這段代碼的詳細(xì)解析,這里不多做介紹。
1.2 提取PDF圖片思路
和之前的excel提取圖片一樣,在一個(gè)pdf中放入4張圖片,我們將它壓縮為zip文件?
讀取后?
相關(guān)代碼如下:
def?pdf2pic(path,?pic_path):
????doc?=?fitz.open(path)
????nums?=?doc._getXrefLength()
????imgcount?=?0?
????for?i?in?range(1,?nums):
????????text?=?doc._getXrefString(i)
????????if?('Width?2550'?in?text)?and?('Height?3300'?in?text)?or?('thumbnail'?in?text):
????????????continue
????????????checkXO?=?r"/Type(?=?*/XObject)"
????????????checkIM?=?r"/Subtype(?=?*/Image)"
????????????isXObject?=?re.search(checkXO,?text)
????????????isImage?=?re.search(checkIM,?text)
????????????if?not?isXObject?or?not?isImage:
????????????????continue
????????????????imgcount?+=?1
????????????????pix?=?fitz.Pixmap(doc,?i)
????????????????img_name?=?"img{}.png".format(imgcount)
????????????????if?pix.n?5:
????????????????????try:
????????????????????????pix.writePNG(os.path.join(pic_path,?img_name))
????????????????????????pix?=?None
????????????????????????except:
????????????????????????????pix0?=?fitz.Pixmap(fitz.csRGB,?pix)
????????????????????????????pix0.writePNG(os.path.join(pic_path,?img_name))
????????????????????????????pix0?=?None
if?__name__?==?'__main__':
?path?=?values["lujing"]+?'/'?+?values["wenjian"]
????pic_path?=?values["lujing"]
????pdf2pic(path,?pic_path)
先說(shuō)一下這段代碼的思路吧,由于PDF不能像Excel和Word一樣改后綴名進(jìn)行提取,故這里運(yùn)用python的一個(gè)模塊PyMuPDF,過(guò)程如下
讀取PDF并遍歷每一頁(yè) 篩選無(wú)用的元素并用正則表達(dá)式獲取圖片 生成并保存圖片
fitz.open(path)是打開(kāi)PDF文件夾,這里的path是需要在GUI界面中獲取用戶的文件存放路徑于文件名的。
for?i?in?range(1,?nums):
????text?=?doc._getXrefString(i)
這是我們的第一步讀取并遍歷,將讀取到的字符串內(nèi)容放入到text中
if?('Width?2550'?in?text)?and?('Height?3300'?in?text)?or?('thumbnail'?in?text):
?continue
由于PDF每一頁(yè)的背景就是一張圖片,故我們可以通過(guò)寬高來(lái)尋找這些背景圖片并用continue把他們剔除。
checkXO?=?r"/Type(?=?*/XObject)"
checkIM?=?r"/Subtype(?=?*/Image)"
isXObject?=?re.search(checkXO,?text)
isImage?=?re.search(checkIM,?text)
if?not?isXObject?or?not?isImage:
????continue
我們通過(guò)實(shí)驗(yàn)發(fā)現(xiàn)圖片所對(duì)應(yīng)的字符串在checkxo與checkIM這兩個(gè)中。故用正則表達(dá)式在text中進(jìn)行索引提取,用到了re模塊的search函數(shù)。如果不是這兩個(gè)字符串就用continue剔除。
pix?=?fitz.Pixmap(doc,?i)
img_name?=?"img{}.png".format(imgcount)
if?pix.n?5:
?try:
??pix.writePNG(os.path.join(pic_path,?img_name))
??pix?=?None
?except:
??pix0?=?fitz.Pixmap(fitz.csRGB,?pix)
??pix0.writePNG(os.path.join(pic_path,?img_name))
??pix0?=?None
這是最后一步生成與保存圖片
“
pix = fitz.Pixmap(doc, i)是生成圖像語(yǔ)句,doc代表PDF文件,i代表遍歷每個(gè)圖片對(duì)象的索引值。”
img_name = "img{}.png".format(imgcount)是設(shè)置圖像名語(yǔ)句,用提取到的圖片的序列號(hào)作為命名格式。
而后if嵌套try那幾行代碼是保存圖像語(yǔ)句。如果pix.n<5,可以直接存為PNG,否者將進(jìn)行RGB變換在保存。
由于代碼采用的是def函數(shù)編寫模式,故最后還要一個(gè)函數(shù)的初始化:if __name__ == '__main__':
至此,3種文件格式(Excel、Word、PDF)圖片提取方法已全部講解,接下來(lái)就是重中之重GUI構(gòu)建了。
? 二、GUI框架構(gòu)建
先看完整代碼:
import?PySimpleGUI?as?sg
sg.ChangeLookAndFeel('GreenTan')???#更換主題
menu_def?=?[['&使用說(shuō)明',?['&注意']]]
layout?=?[
????[sg.Menu(menu_def,?tearoff=True)],
????[sg.Frame(layout=[
????[sg.Radio('Excel1',?"RADIO1",size=(10,1),key="Excel1"),??sg.Radio('Word',?"RADIO1",default=True,key="Word")],
????[sg.Radio('Excel2',?"RADIO1",?enable_events=True,?size=(10,1),key="Excel2"),?sg.Radio('PDF',?"RADIO1",key="PDF")]],?title='選項(xiàng)',title_color='red',?relief=sg.RELIEF_SUNKEN,?tooltip='Use?these?to?set?flags')],
????[sg.Text('文件位置',?size=(8,?1),?auto_size_text=False,?justification='right'),
?????sg.InputText(enable_events=True,key="lujing"),?sg.FolderBrowse()],
????[sg.Text('文件名字',?size=(8,?1),?justification='right'),
?????sg.InputText(enable_events=True,key="wenjian")],
????[sg.Submit(tooltip='文件'),?sg.Cancel()]]
window?=?sg.Window('圖片提取器',?layout,?default_element_size=(40,?1),?grab_anywhere=False)
while?True:
????event,?values?=?window.read()
????if?event?==?"Submit":
????????if?values["Excel2"]?==?True:
???'''
???事件綁定
???'''
????????????sg.Popup("提取成功")
????????if?values["Excel1"]?==?True:
???'''
???事件綁定
???'''
????????????sg.Popup("提取成功")
????????if?values["Word"]?==?True:
???'''
???事件綁定
???'''
????????????sg.Popup("提取成功")?
????????if?values["PDF"]?==?True:
???'''
???事件綁定
???'''
????????????sg.Popup("提取成功")
????if?event?==?"Cancel"?or?event?==?sg.WIN_CLOSED:
????????break????
????if?event?==?"注意":
????????sg.Popup("作用講解:",
?????????????????"Excel1 :解析選定位置中所有的Excel文件,無(wú)需在文件名處填寫",
?????????????????"Excel2 :解析選定位置中單個(gè)指定的Excel文件,需在文件名處填寫",
?????????????????"Word :??解析選定位置中單個(gè)指定的docx結(jié)尾的文件,無(wú)需在文件名處填寫",
?????????????????"PDF :???解析選定位置中單個(gè)指定的PDF文件,需在文件名處填寫")
window.close()???????????
效果呈現(xiàn):
代碼解析:做PySimpleGUI還是原來(lái)那個(gè)步驟:
Import ? Create some widgets Create the window Create the event loop
當(dāng)然,做GUI之前就是先想清楚自己的圖形交互頁(yè)面長(zhǎng)什么樣,像我就是現(xiàn)在紙上畫一個(gè)大概,這樣更有益于制作頁(yè)面。
第一步先引用模塊
第二步添加元素(小部件)到容器(layout)中,這里先介紹一下用到的部件:
“
Menu:顧名思義,這是菜單欄,每個(gè)GUI都必帶一個(gè)菜單欄來(lái)提示使用者該如何做,我們這里用了menu_def這個(gè)布局來(lái)完成菜單的設(shè)置。
Frame:這個(gè)跟layout布局完全相同,工作方式也一樣,他們都是容器元素。可以看到“選項(xiàng)”那里是一個(gè)凹槽的正方形,里面裝有四個(gè)選項(xiàng),作用就是這個(gè)。注意,&這個(gè)符號(hào)的作用是創(chuàng)建相同類型的菜單,這里只有注意事項(xiàng)這一個(gè)菜單,故可以不用管,讀者如果想添加同樣的菜單的話必須添加一個(gè)&。tearoff=True這個(gè)參數(shù)是菜單欄中每個(gè)子選項(xiàng)上面加虛線。
Radio:?jiǎn)芜x按鈕。我們只可以在同樣的id上選擇一個(gè)選項(xiàng)。id就是指代碼中的“ra-dio1”。其中每個(gè)radio函數(shù)的第一個(gè)參數(shù)是文本內(nèi)容,這里就是我們要進(jìn)行提取的4個(gè)文件格式。而“size”就是位置,每行的第一個(gè)設(shè)同樣的參數(shù)(10,1)。最后就是我們進(jìn)行事件幫綁定的鍵,其中“enable_events”可以不寫因?yàn)槲覀冎皇钦{(diào)用它而不用去對(duì)它產(chǎn)生事件。
Text:之前有講是不能改的正文內(nèi)容。同樣這里設(shè)置的位置參數(shù)(8,1),justification='right'有點(diǎn)類似我們平常用word那個(gè)向右對(duì)其。
InputText:需要用戶輸入的正文內(nèi)容。這里有兩個(gè)需要我們填寫的地方:文件位置和文件名。這里需要設(shè)置鍵,因?yàn)樵诤竺媸录壎ㄖ形覀冃枰{(diào)用文件存儲(chǔ)路徑和文件名,在文中上半部分有提到過(guò)。
FolderBrowse:簡(jiǎn)易的打開(kāi)文件路徑操作,不用你去復(fù)制路徑。
Submit:確定按鈕,這里綁定為執(zhí)行提取文檔圖片事件”
Cancel:退出主程序按鈕。
第三步就是創(chuàng)建窗口來(lái)容納這些元素布置。
第四步創(chuàng)建事件循環(huán),可以看到代碼,都是一樣的套路:當(dāng)用戶按下submit按鈕時(shí)系統(tǒng)將進(jìn)行判斷你按的是哪個(gè)單選按鈕,進(jìn)而進(jìn)行相對(duì)應(yīng)的事件執(zhí)行。當(dāng)你按下cancel或者×時(shí),就是退出主程序。當(dāng)你按菜單中的注意時(shí),就會(huì)彈出一個(gè)對(duì)話框告訴你這個(gè)系統(tǒng)怎么用。
在事件循環(huán)中,我們用values[]的布爾值來(lái)判斷我們選的是哪個(gè)單選按鈕,有讀者疑問(wèn)為什么不用event=,因?yàn)槲覀冊(cè)诘谝粋€(gè)if當(dāng)中用了event所以第二個(gè)if當(dāng)中需要換一個(gè)判斷方法。
至此,GUI部分就搞定了!感興趣的讀者可以繼續(xù)在上面添加功能。
? 三、打包
我們將完整代碼整合在一起,后安裝pyinstaller模塊
pip?install?pyinstaller
如果你的上述項(xiàng)目代碼文件命名為:photo.py。那么你要用下面命令進(jìn)行打包
pyinstaller?photo.py
最后打包成功之后,你會(huì)在py文件所在文件夾看到一個(gè)dist的子文件夾。進(jìn)去之后,找到pachong.exe文件并運(yùn)行它即可。
注意,文件夾里附帶了很多文件,你可以刪除它。當(dāng)然,如果嫌麻煩就直接從photo.py文件用Python執(zhí)行。
本文的全部代碼全部都在文中,你可以將它組合來(lái)得到完整代碼或者在后臺(tái)回復(fù)1219獲取。
原創(chuàng)不易,希望你能在下面點(diǎn)個(gè)贊和在看支持我繼續(xù)創(chuàng)作,謝謝!
-END-
文末給大家推薦一本《數(shù)據(jù)結(jié)構(gòu)和算法基礎(chǔ)Python語(yǔ)言實(shí)現(xiàn)?》介紹算法的概念和特點(diǎn),然后介紹數(shù)據(jù)結(jié)構(gòu),再逐步深入介紹各類算法,通過(guò)解決實(shí)際問(wèn)題加深理解。本書(shū)選取了近年來(lái)比較熱門的語(yǔ)言Python作為載體,來(lái)實(shí)現(xiàn)算法的功能。這不但可以讓讀者系統(tǒng)地學(xué)習(xí)算法的相關(guān)知識(shí),而且還能提高讀者對(duì)Python語(yǔ)言的應(yīng)用水平。主要內(nèi)容有算法簡(jiǎn)介、數(shù)據(jù)結(jié)構(gòu)、數(shù)學(xué)相關(guān)算法、排序算法、查找算法、圖相關(guān)算法、算法思想歸納
除了直接點(diǎn)擊上方小程序購(gòu)買有一定折扣,早起也申請(qǐng)了3本送給各位讀者,將以抽獎(jiǎng)的形式送給星標(biāo)早起Python的粉絲,如果你想?yún)⑴c的話,可以按照下面圖示星標(biāo)公眾號(hào)后在后臺(tái)回復(fù)送書(shū),祝大家好運(yùn)?