
幾十萬實例線上系統(tǒng)的抖動問題定位
本文是武漢 gopher meetup 的分享內(nèi)容整理而成,分享內(nèi)容在“無人值守”的兩篇和其它社區(qū)分享中亦有提及。(也就是說你看過那兩篇,這個可以不用看了)
先來看看苦逼的開發(fā)人員
老板說:

隊友說:

外組同事說:

底層團(tuán)隊說:

你:

業(yè)界的思路?
混口飯吃也是不容易,既然有問題了,我們還是要解決的。要先看看有沒有現(xiàn)成的思路可以借鑒?
Google 在這篇論文[1]里提到過其內(nèi)部的線上 profile 流程:
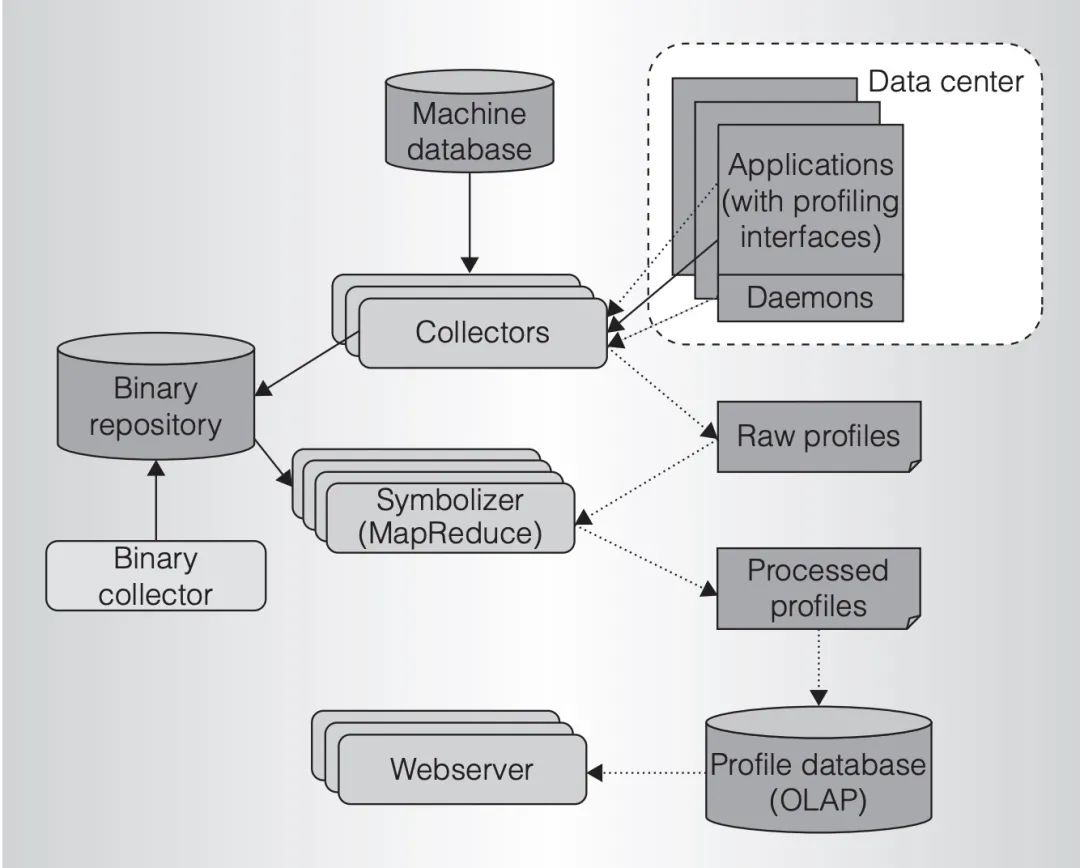
架構(gòu)圖已經(jīng)比較簡單了,線上應(yīng)用暴露 profile 接口,collector 定時將 profile 信息采集到二進(jìn)制存儲,由統(tǒng)一的在線平臺展示。
這篇論文催生了一些開源項目和創(chuàng)業(yè)公司,例如在 這篇文章[2] 中,對 continuous profiling 有很不錯的解釋。
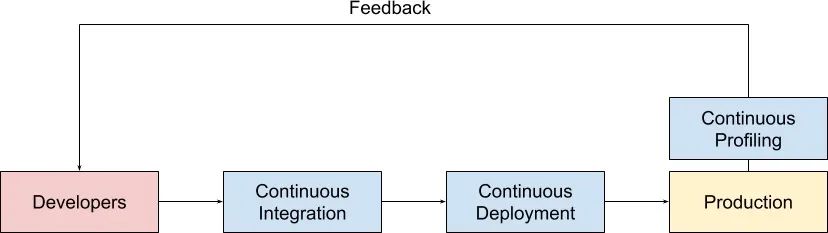
我們?nèi)粘5?CI 和 CD 流水線可以高頻次發(fā)布線上系統(tǒng),當(dāng)線上有 continuous profiling 系統(tǒng)在運(yùn)行時,每次發(fā)布我們都能夠得到實時的性能快照,并與發(fā)布前的性能做快速對照。
系統(tǒng)的性能問題和其它技術(shù)問題一樣,同樣是發(fā)現(xiàn)得越早,解決起來就越快,損失越小。
Google Cloud 上也有 profiler 相關(guān)的產(chǎn)品[3],是由 Go 原先的 pprof 開發(fā)者開發(fā)的,她在文章中聲稱每分鐘對應(yīng)用采集 10s 的 profile[4],大約有 5% 的性能損失,還是可以接受的。
簡單來說,continuous profiling 帶給我們的優(yōu)勢主要就是三點:
縮短性能問題反饋周期 節(jié)省服務(wù)器成本 改進(jìn)開發(fā)者的工作流程
有了思路,再看看有沒有具體的開源產(chǎn)品可以參考。
相關(guān)開源產(chǎn)品
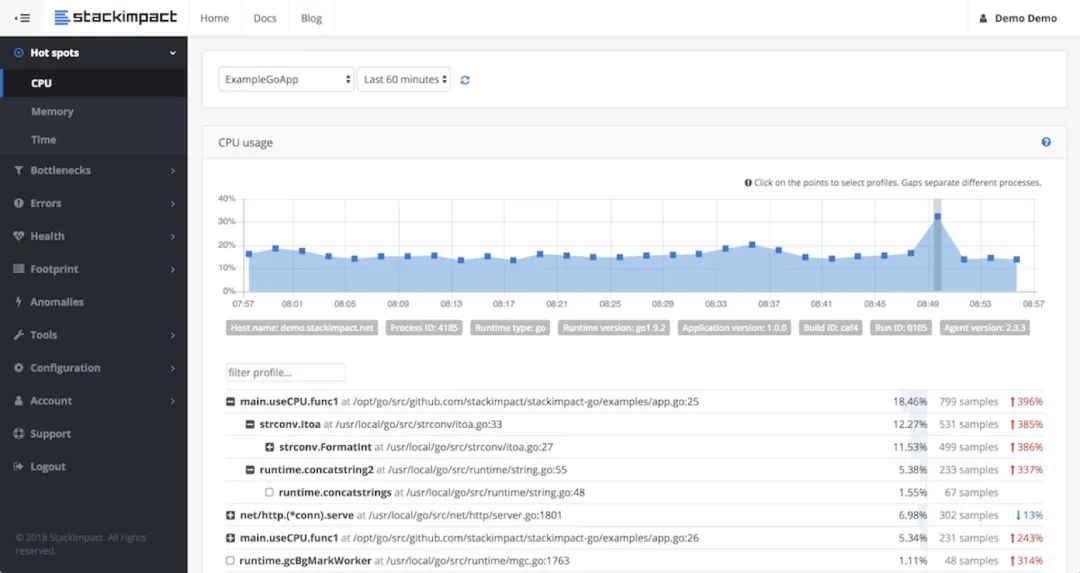
stackimpact-go 是社區(qū)比較早的開源項目了,不過只開源了 client 部分,所以 dashboard 和后端部分一直是一個謎,不過我們大概也能看出來,有這種曲線圖形式的 profile 數(shù)據(jù),有性能衰減時能及時發(fā)現(xiàn)。
conprof 其實也差不多。
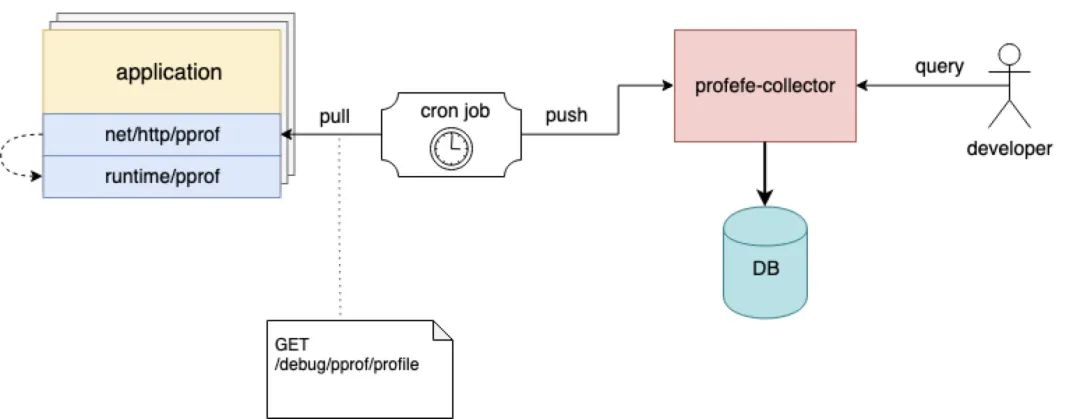
profefe 也差不多。
看起來思路都一樣,這個需求很簡單,我們只要找監(jiān)控團(tuán)隊幫忙做一套皮膚就可以了!
但監(jiān)控團(tuán)隊也很無奈。

我們的方案
求人不如求己,我們需要定位的是抖動問題,那我們以 5s 為單位,把進(jìn)程的 CPU 使用(gopsutil),RSS(gopsutil),goroutine 數(shù)(runtime.NumGoroutine),用 10 大小的環(huán)形數(shù)組保存下來,每次采集到新值時,與之前多個周期的平均值進(jìn)行 diff 就可以了:
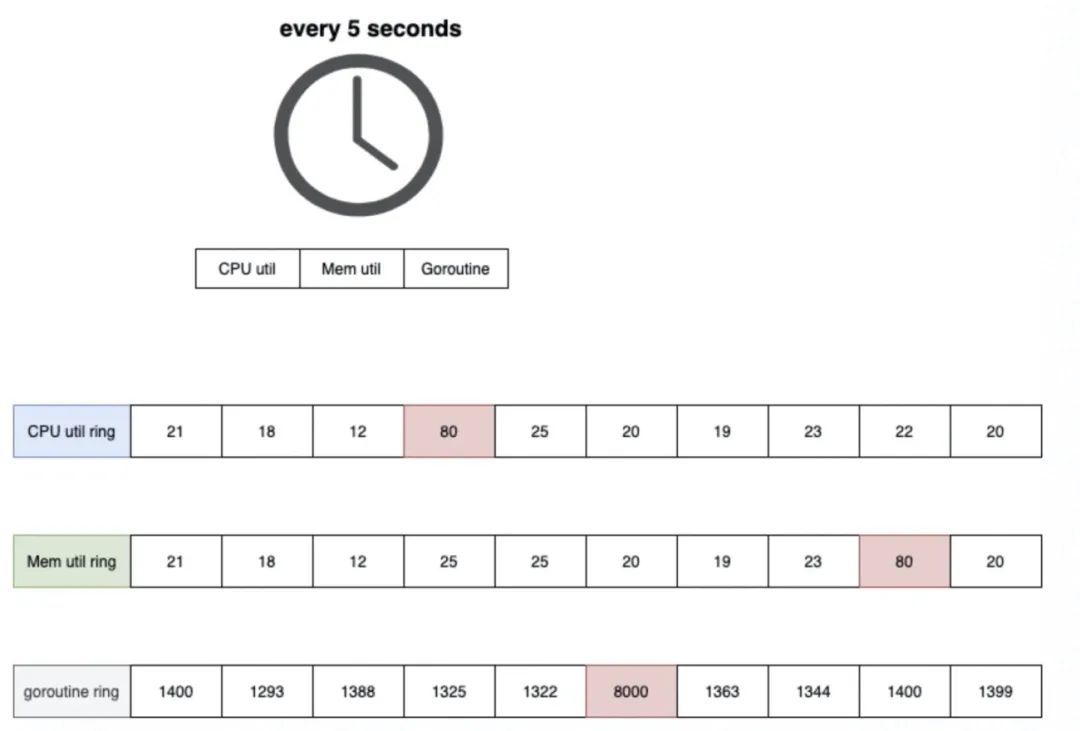
當(dāng)波動率超過可以接受的范圍,則認(rèn)為當(dāng)前進(jìn)程發(fā)生了資源使用抖動,那么:
若 CPU 抖動,從當(dāng)前開始采集 CPU profile 5秒 若 RSS 抖動,將當(dāng)前進(jìn)程的 heap profile 記錄下來 若 goroutine 抖動,將當(dāng)前進(jìn)程的 goroutine profile 記錄下來
一套方案做下來,還挺簡單的。當(dāng)我們收到模塊的 CPU、內(nèi)存或 goroutine 數(shù)報警時,上線到相應(yīng)的實例來查看即可。
實際的案例
解碼 bug
某模塊突然出現(xiàn)了 RSS 使用飚升,上線看之后發(fā)現(xiàn)自動 dump 文本的 profile 中,單個對象的 inuse_space 超過了 1GB:
// inuse_objects: inuse_space [alloc_objects : alloc_space]
1 : 1024000000 [1 : 1024000000] git.xxx.xxx
這是很反常的,閱讀代碼后發(fā)現(xiàn)在 decode 中沒有對這些情況進(jìn)行一定的防御操作,有形如下面的代碼:
var l = readLenFromPacket()
var list = make([]byte, l)
雖然理論上 body 是可以傳 1GB 的,不過內(nèi)部的 RPC 框架,還是應(yīng)該對這種情況進(jìn)行一些限制。
CPU 尖刺
有些在線系統(tǒng)是定時任務(wù)調(diào)用的,所以其訪問峰值非常不平均,在定時任務(wù)觸發(fā)后,會有一段時間 CPU 使用非常高,有了自動 CPU profile dump,就非常容易找到具體哪里使用的 CPU 很高了。
goroutine 泄露
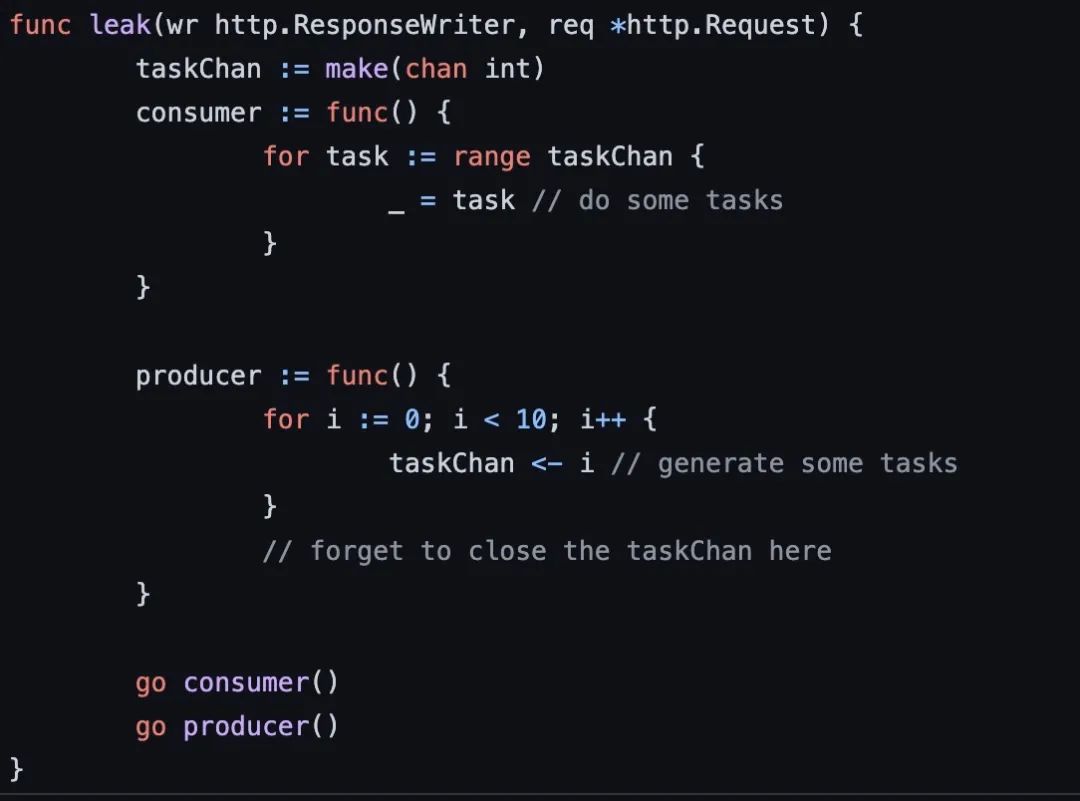
類似這樣的 goroutine 泄露問題,也是可以很容易發(fā)現(xiàn)的。
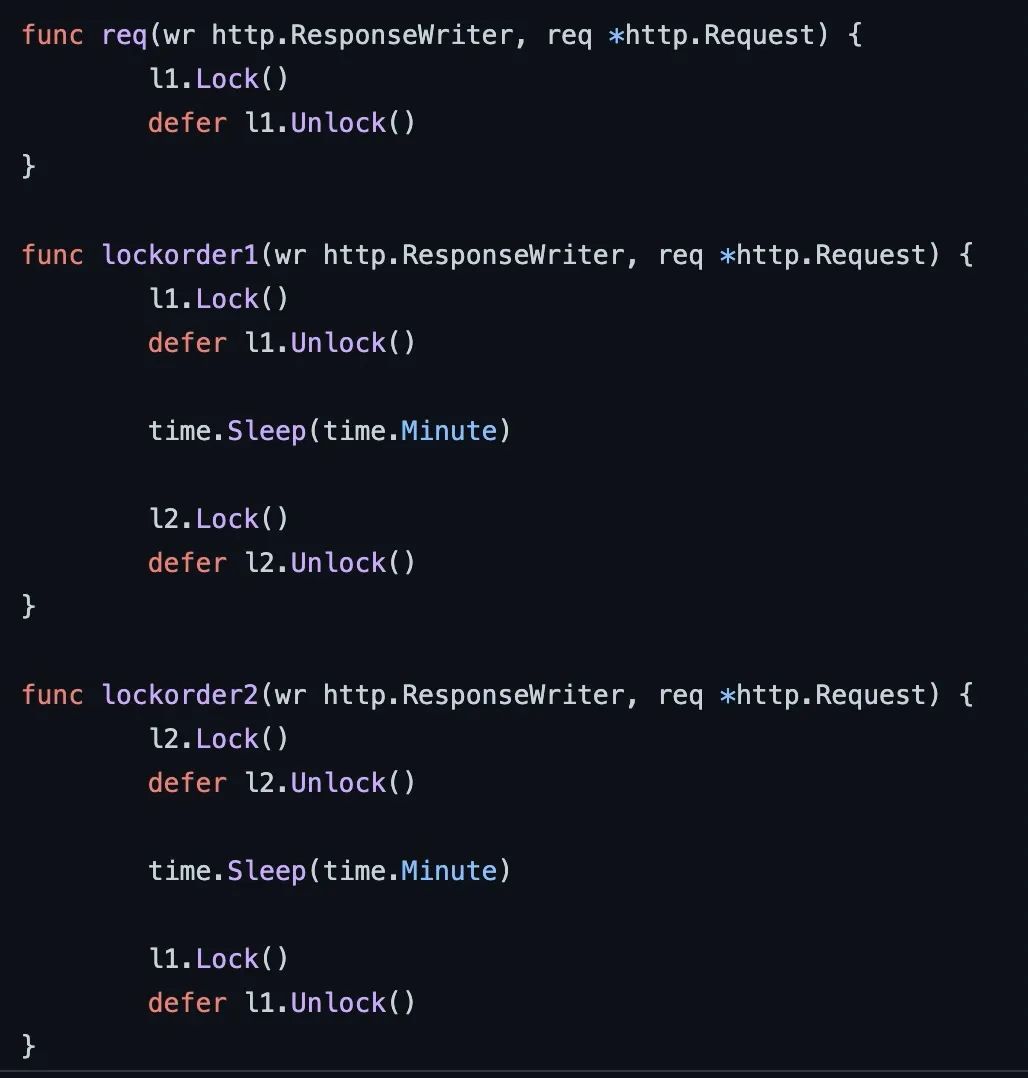
deadlock(擴(kuò)展)
因為我們可以采集到所有 goroutine 的棧信息,所以理論上通過遍歷我們可以發(fā)現(xiàn)哪些 goroutine 是持鎖的,例如下列代碼,當(dāng)發(fā)生死鎖時,我們可以直接把持鎖的 goroutine dump 下來,就很容易發(fā)現(xiàn)死鎖了:
thread block(擴(kuò)展)
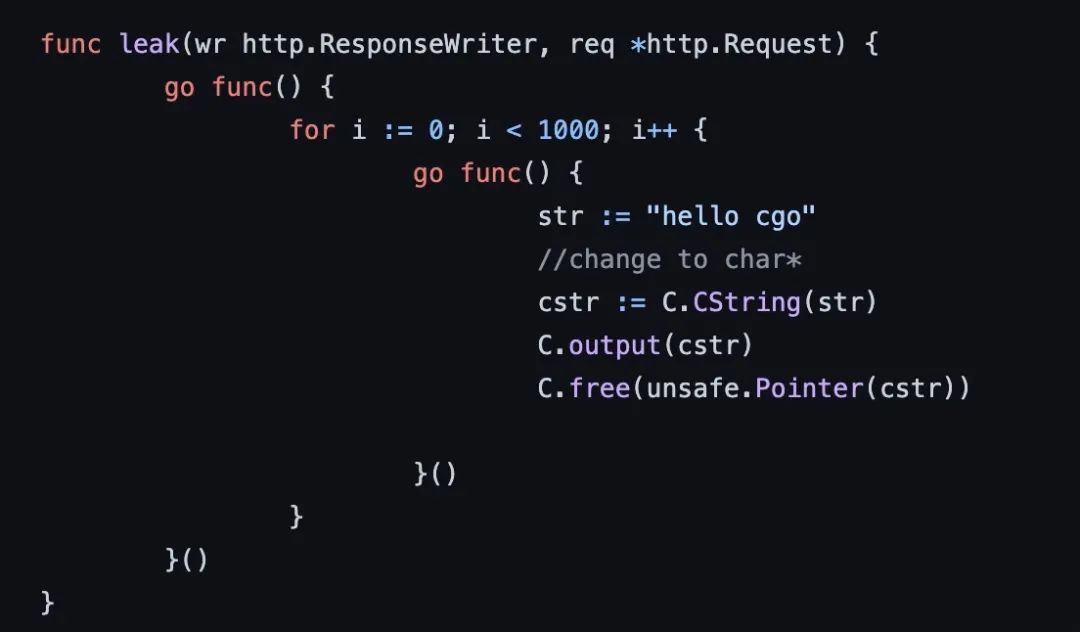 當(dāng)線程因為調(diào)用 cgo 等原因發(fā)生了阻塞,會造成線程數(shù)暴漲,這時候我們可以將 goroutine 和 thread profile dump 下來,進(jìn)行診斷。
當(dāng)線程因為調(diào)用 cgo 等原因發(fā)生了阻塞,會造成線程數(shù)暴漲,這時候我們可以將 goroutine 和 thread profile dump 下來,進(jìn)行診斷。
總結(jié)
有了自動化的工具,日子更好過了。
這篇論文: https://research.google/pubs/pub36575/
[2]這篇文章: https://www.opsian.com/blog/what-is-continuous-profiling/
[3]產(chǎn)品: https://cloud.google.com/profiler/
[4]profile: https://medium.com/google-cloud/continuous-profiling-of-go-programs-96d4416af77b