
記一次 Druid 超時配置的問題,引發(fā)對 Druid 時間配置項的探究
開心一刻
一天在路邊看到一個街頭采訪
記者:請問,假如你兒子娶媳婦,給多少彩禮合適呢
大爺:一百萬吧,再給一套房,一輛車
大爺沉思一下,繼續(xù)說到:如果有能力的話再給老丈人配一輛車,畢竟他把女兒養(yǎng)這么大也不容易
記者:那你兒子多大了?
大爺:我沒有兒子,有兩個女兒

問題背景
最近生產(chǎn)環(huán)境出現(xiàn)了一個問題,錯誤日志類似如下:
Failed to obtain JDBC Connection; nested exception is com.alibaba.druid.pool.GetConnectionTimeoutException: wait millis 1010, active 10, maxActive 10, creating 0, runningSqlCount 10 : select * from tbl_user日志信息提示的很明顯:獲取 JDBC Connection 失敗,因為從 Druid 連接池獲取 connection 超時了。

上圖的意思是:執(zhí)行 select * from tbl_user 之前,需要從 druid 連接池中獲取一個 connect
而此時連接池的狀態(tài)是:一共 10 個激活的 connect ,連接池最大創(chuàng)建 10 個 connect ,正在執(zhí)行 SQL 的 connect 也是 10 個。
所以不能創(chuàng)建新的 connect 那就等唄。一共等了 1010 毫秒,還是拿不到 connect ,就拋出 GetConnectionTimeoutException 異常。
簡單點說就是,連接池中連接數(shù)不夠,在規(guī)定的時間內(nèi)拿不到 connect。
那有人就說了:連接池的最大數(shù)量設(shè)置大一點,問題不就解決了嗎?
最大連接數(shù)設(shè)置大一點只能降低問題發(fā)生的概率,不能完全杜絕問題。因為網(wǎng)絡(luò)條件、硬件資源的使用情況等等都是不確定因素。
今天要講的不是連接池大小問題,而是超時設(shè)置問題。我們慢慢往下看。
問題復(fù)現(xiàn)
我們先來模擬下上述問題:
MySQL 版本:5.7.21 ,隔離級別:RR
Druid 版本:1.1.12
spring-jdbc 版本:5.2.3.RELEASE
DruidDataSource 初始化
為了方便演示,就手動初始化了:

多線程查詢
線程數(shù)多于連接池中 connect 數(shù)。

模擬慢查詢
如果查詢飛快,15 個查詢可能都用不上 10 個 connect ,所以我們需要簡單處理下。
很簡單,給表加寫鎖:
LOCK TABLES tbl_user WRITE給表 tbl_user 加上寫鎖,然后跑線程去查詢 tbl_user 的數(shù)據(jù)。
異常演示
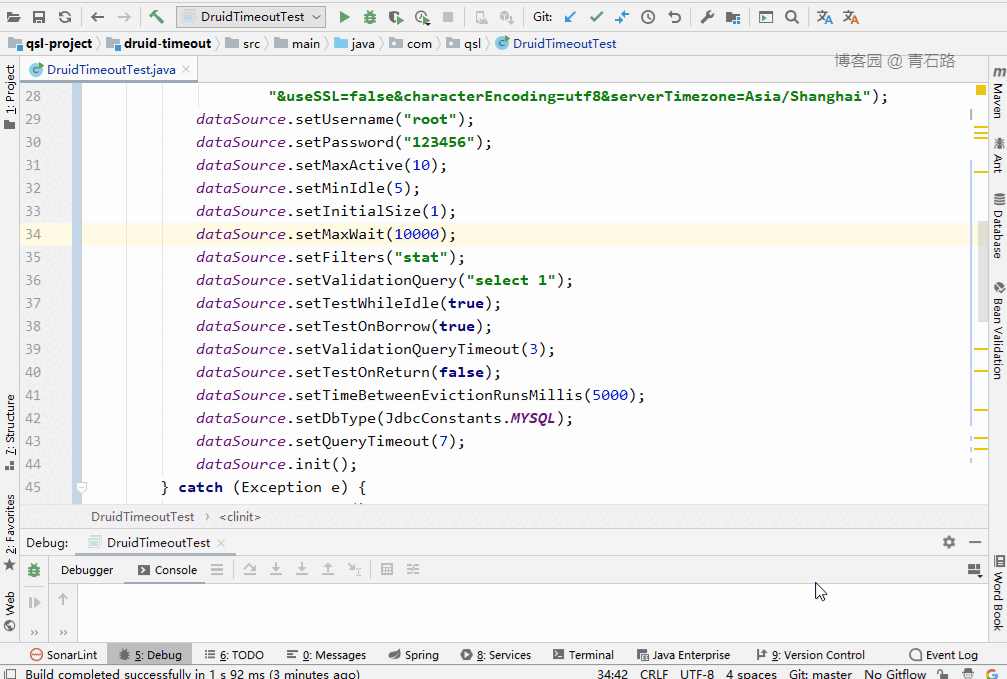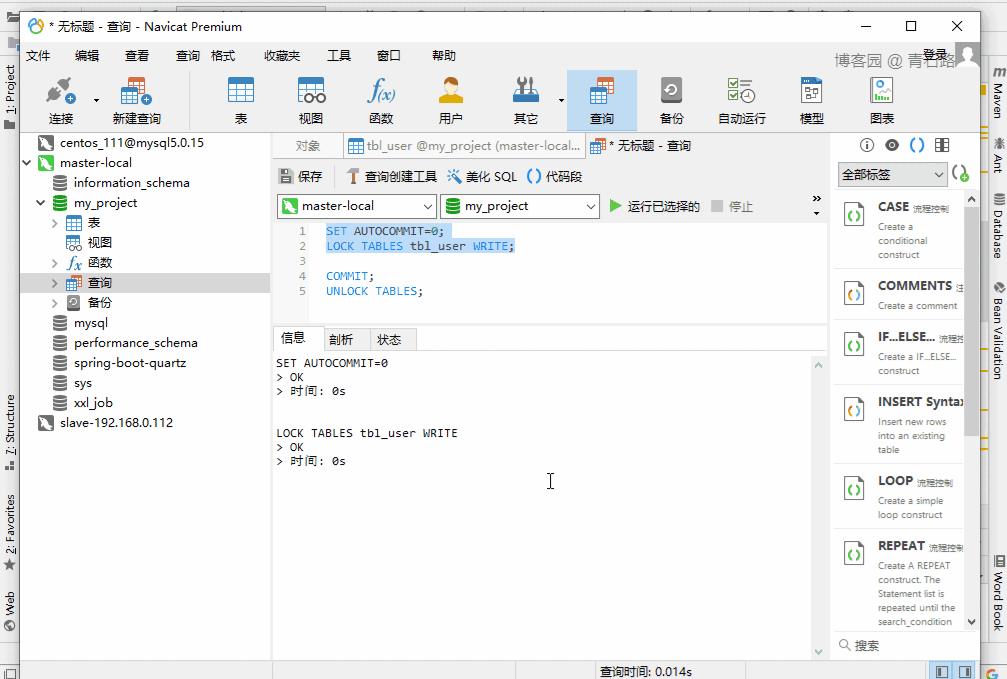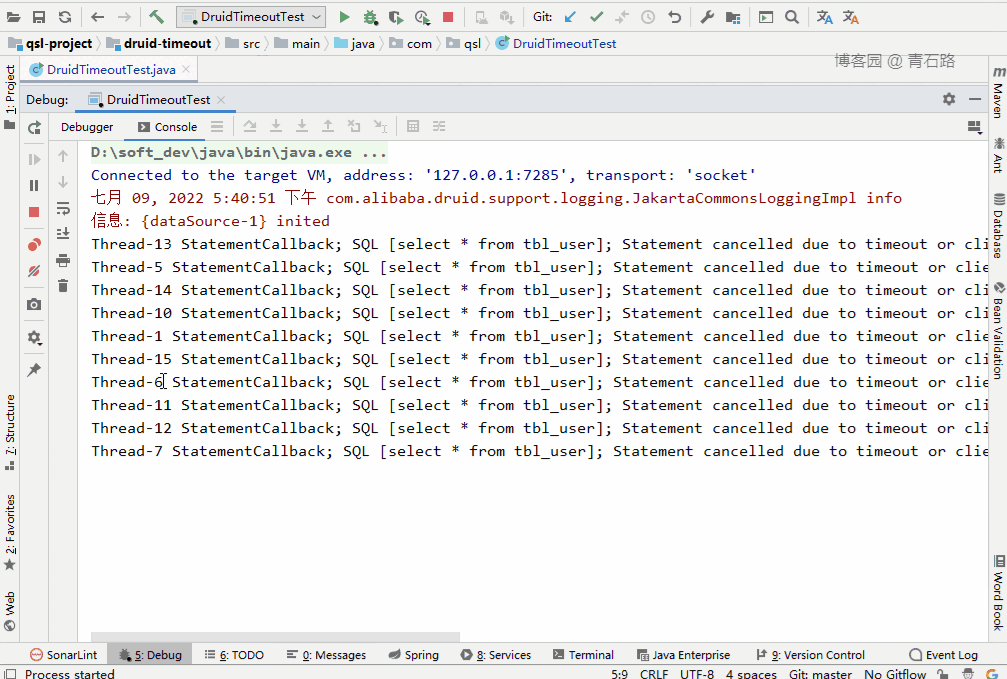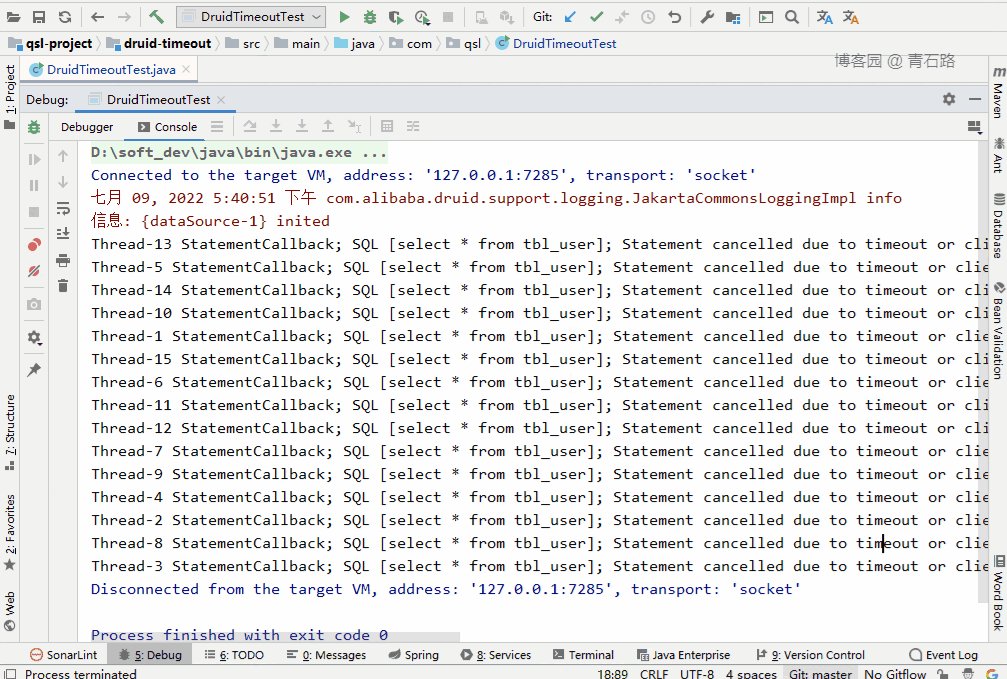
先鎖表,再啟動程序
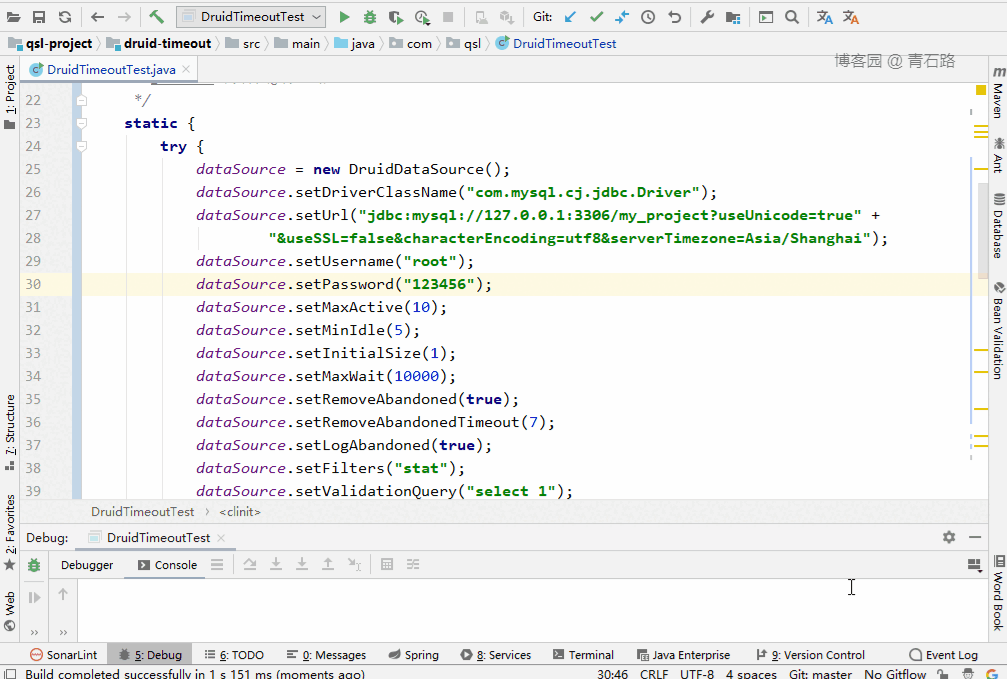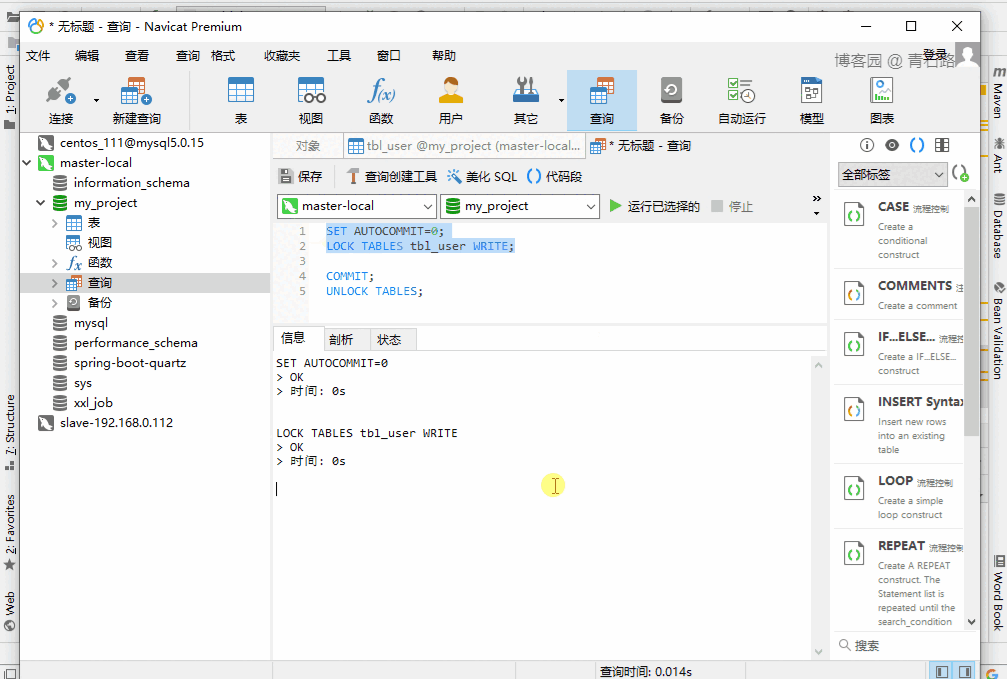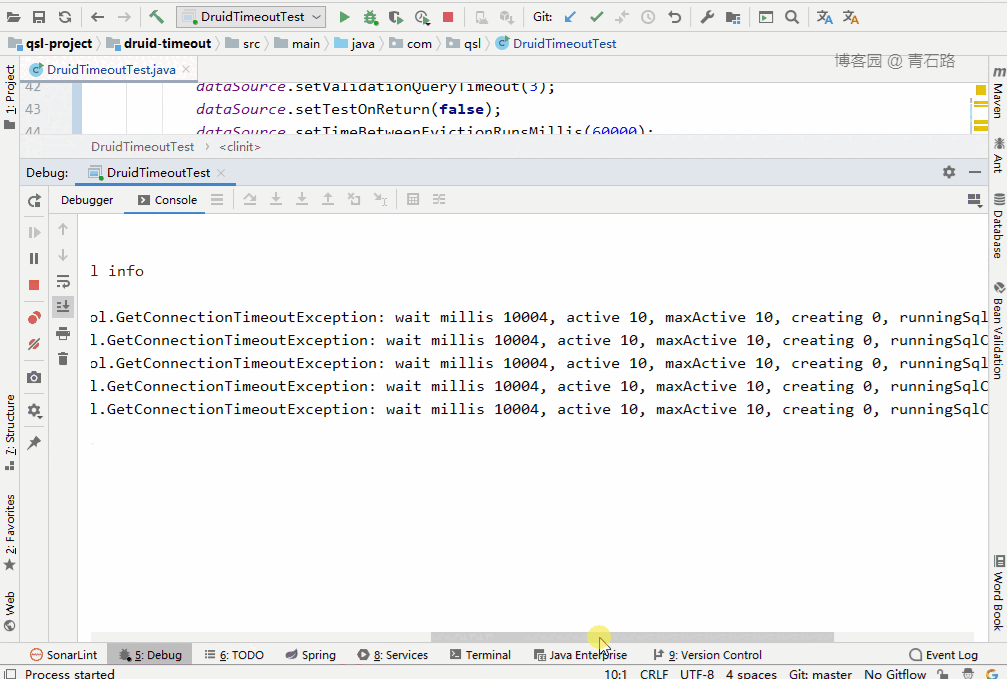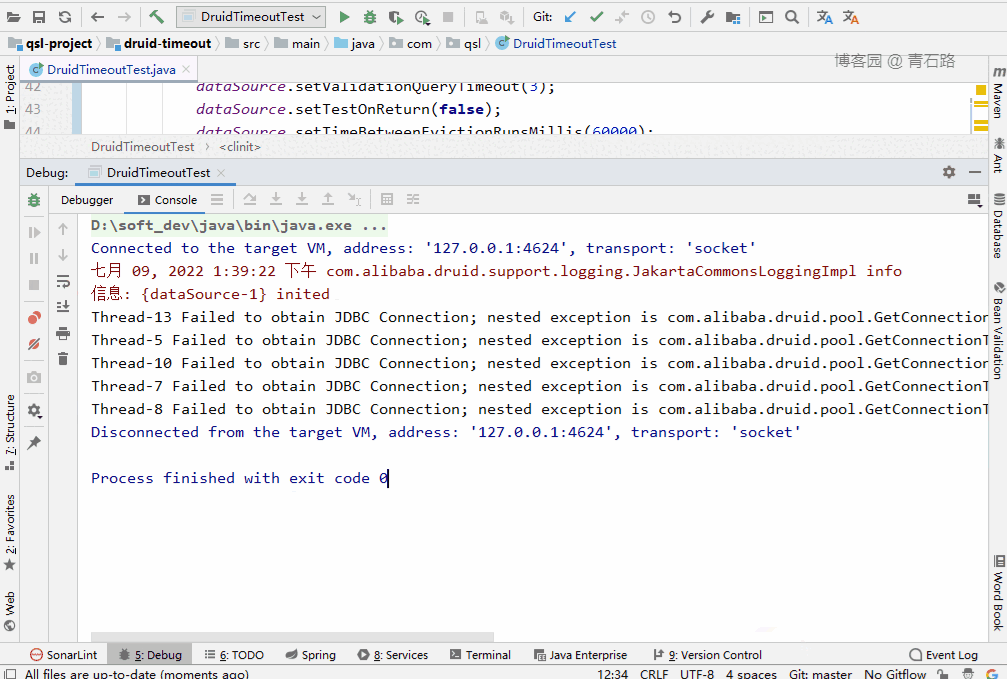
可以看到,15 個線程中,有 5 個線程獲取 connect 失敗:
Thread-13 Failed to obtain JDBC Connection; nested exception is com.alibaba.druid.pool.GetConnectionTimeoutException: wait millis 10004, active 10, maxActive 10, creating 0, runningSqlCount 10 : select * from tbl_userThread-5 Failed to obtain JDBC Connection; nested exception is com.alibaba.druid.pool.GetConnectionTimeoutException: wait millis 10004, active 10, maxActive 10, creating 0, runningSqlCount 10 : select * from tbl_userThread-10 Failed to obtain JDBC Connection; nested exception is com.alibaba.druid.pool.GetConnectionTimeoutException: wait millis 10004, active 10, maxActive 10, creating 0, runningSqlCount 10 : select * from tbl_userThread-7 Failed to obtain JDBC Connection; nested exception is com.alibaba.druid.pool.GetConnectionTimeoutException: wait millis 10004, active 10, maxActive 10, creating 0, runningSqlCount 10 : select * from tbl_userThread-8 Failed to obtain JDBC Connection; nested exception is com.alibaba.druid.pool.GetConnectionTimeoutException: wait millis 10004, active 10, maxActive 10, creating 0, runningSqlCount 10 : select * from tbl_user
示例代碼:druid-timeout
https://gitee.com/youzhibing/qsl-project/tree/master/druid-timeout
時間配置項
Druid 中關(guān)于時間的配置項有很多,我們我們重點來看下如下幾個:
maxWait
最大等待時長,單位是毫秒,-1 表示無限制。
從連接池獲取 connect;
如果有空閑的 connect ,則直接獲取到;
如果沒有則最長等待 maxWait 毫秒;
如果還獲取不到,則拋出 GetConnectionTimeoutException 異常。
removeAbandonedTimeout
設(shè)置 Druid 強制回收連接的時限,單位是秒。
從連接池獲取到 connect 開始算起,超過此值后, Druid 將強制回收該連接。
官網(wǎng)也有說明:連接泄漏監(jiān)測。
https://github.com/alibaba/druid/wiki/%E8%BF%9E%E6%8E%A5%E6%B3%84%E6%BC%8F%E7%9B%91%E6%B5%8B
validationQueryTimeout
檢測連接是否有效的超時時間,單位是秒,-1 表示無限制。
Druid 內(nèi)部的一個檢測 connect 是否有效的超時時間,需要結(jié)合 validationQuery 來配置。
timeBetweenEvictionRunsMillis
檢查空閑連接的頻率,單位是毫秒, 非正整數(shù)表示不進行檢查。
空閑連接檢查的間隔時間, Druid 池中的 connect 數(shù)量是一個動態(tài)從 minIdle 到 maxActive 擴張與收縮的過程。
connect 使用高峰期,數(shù)量會從 minIdle 擴張到 maxActive 。使用低峰期, connect 數(shù)量會從 maxActive 收縮到 minIdle 。
收縮的過程會回收一些空閑的 connect ,而 timeBetweenEvictionRunsMillis 就是檢查空閑連接的間隔時間。
queryTimeout
執(zhí)行查詢的超時時間,單位是秒,-1 表示無限制。
最終會應(yīng)用到 Statement 對象上,執(zhí)行時如果超過此時間,則拋出 SQLException 。
transactionQueryTimeout
執(zhí)行一個事務(wù)的超時時間,單位是秒。
minEvictableIdleTimeMillis
最小空閑時間,單位是毫秒,默認 30 分鐘。
如果連接池中非運行中的連接數(shù)大于 minIdle ,并且某些連接的非運行時間大于 minEvictableIdleTimeMillis ,則連接池會將這部分連接設(shè)置成 Idle 狀態(tài)并關(guān)閉。
maxEvictableIdleTimeMillis
最大空閑時間,單位是毫秒,默認 7 小時。
如果 minIdle 設(shè)置的比較大,連接池中的空閑連接數(shù)一直沒有超過 minIdle ,那么那些空閑連接是不是一直不用關(guān)閉?
當(dāng)然不是。
如果連接太久沒用,數(shù)據(jù)庫也會把它關(guān)閉(MySQL 默認 8 小時),這時如果連接池不把這條連接關(guān)閉,程序就會拿到一條已經(jīng)被數(shù)據(jù)庫關(guān)閉的連接。
為了避免這種情況, Druid 會判斷池中的連接狀態(tài)。如果非運行時間大于 maxEvictableIdleTimeMillis ,也會強行把它關(guān)閉,而不用判斷空閑連接數(shù)是否小于 minIdle 。
再看問題
其實前面的示例中設(shè)置了。

獲取 connect 的最大等待時長是 10000 毫秒,也就是 10 秒。
而 removeAbandonedTimeout 設(shè)置是 7 秒。
照理來說 connect 如果 7 秒未執(zhí)行完 SQL 查詢,就會被 Druid 強制回收進連接池,那么等待 10 秒應(yīng)該能夠獲取到 connect 。
為什么會拋出 GetConnectionTimeoutException 異常了?
這也就是文章標(biāo)題中的超時設(shè)置問題。
源碼探究
很顯然,我們從 dataSource.init(); 開始跟源碼,會看到如下一段代碼:

我們繼續(xù)跟 createAndStartDestroyThread():

重點來了,我們看下 DestroyTask 到底是怎么樣一個邏輯:

我們接著跟進 removeAbandoned ,關(guān)鍵代碼:

如果 connect 正在運行中是不會被強制回收進連接池的。
回到我們的示例:connect 都是在運行中,只是都在進行慢查詢,所以是無法被強制回收進連接池的,那么其他線程自然在 maxWait 時間內(nèi)無法獲取到 connect 。
至此,文章標(biāo)題中的問題的原因就找到了。
那么問題又來了:removeAbandonedTimeout 作用在哪?
我們再仔細閱讀下:連接泄漏監(jiān)測
https://github.com/alibaba/druid/wiki/%E8%BF%9E%E6%8E%A5%E6%B3%84%E6%BC%8F%E7%9B%91%E6%B5%8B
Druid 提供了 RemoveAbandanded 相關(guān)配置,目的是監(jiān)測連接泄露,回收那些長時間游離在連接池之外的空閑 connect。
可能因為程序問題,導(dǎo)致申請的 connect 在處理完 SQL 查詢后,不能回到連接池的懷抱。那么這個 connect 處理游離態(tài),它真實存在,但后續(xù)誰也申請不到它,這就是連接泄露。
而 removeAbandoned 的設(shè)計就是為了幫助這些泄露的 connect 回到連接池的懷抱。
解決問題
開啟 removeAbandoned 對性能有影響,官方不建議在生產(chǎn)環(huán)境使用。
那么我們接受官方的建議,不開啟 removeAbandoned (不配置即可,默認是關(guān)閉的)。
為了不讓慢查詢占用整個連接池,而拖垮整個應(yīng)用,我們設(shè)置查詢超時時間 queryTimeout 。
有兩種方式,一個是設(shè)置 DataSource 的 queryTimeout ,另一個是設(shè)置 JdbcTemplate 的 queryTimeout 。
如果兩個都設(shè)置,最終生效的是哪個,為什么?大家自己去分析,權(quán)當(dāng)是給大家留個一個作業(yè)。
這里就配置 DataSource 的 queryTimeout ,給大家演示下效果:
可以看到,所有線程都獲取到了 connect。
總結(jié)
Druid 的 removeAbandoned 對性能有影響,不建議開啟。removeAbandoned 的開啟后的作用要捋清楚,而非簡單的過期強制回收;
Druid 的時間配置項有很多,不局限于文中所講,但常用的就那么幾個,其他的保持默認值就好。配置的時候一定要弄清楚各個配置項的具體作業(yè),不要去猜!
查詢超時 queryTimeout 即可在 DataSource 配置,也可在 JdbcTemplate 配置。
轉(zhuǎn)自:青石路,
鏈接:cnblogs.com/youzhibing/p/16458860.html
推薦閱讀:
不是你需要中臺,而是一名合格的架構(gòu)師(附各大廠中臺建設(shè)PPT)
企業(yè)IT技術(shù)架構(gòu)規(guī)劃方案
論數(shù)字化轉(zhuǎn)型——轉(zhuǎn)什么,如何轉(zhuǎn)?
企業(yè)10大管理流程圖,數(shù)字化轉(zhuǎn)型從業(yè)者必備!
【中臺實踐】華為大數(shù)據(jù)中臺架構(gòu)分享.pdf