
開源云原生成本優(yōu)化神器 Crane 使用教程
Crane(https://gocrane.io/) 是一個基于 FinOps 的云資源分析與成本優(yōu)化平臺,它的愿景是在保證客戶應(yīng)用運行質(zhì)量的前提下實現(xiàn)極致的降本。Crane 已經(jīng)在騰訊內(nèi)部自研業(yè)務(wù)實現(xiàn)了大規(guī)模落地,部署數(shù)百個 K8s 集群、管控 CPU 核數(shù)達百萬,在降本增效方面取得了階段性成果。以騰訊某部門集群優(yōu)化為例,通過使用 FinOps Crane,該部門在保障業(yè)務(wù)穩(wěn)定的情況下,資源利用率提升了 3 倍;騰訊另一自研業(yè)務(wù)落地 Crane 后,在一個月內(nèi)實現(xiàn)了總 CPU 規(guī)模 40 萬核的節(jié)省量,相當(dāng)于成本節(jié)約超 1000 萬元/月。
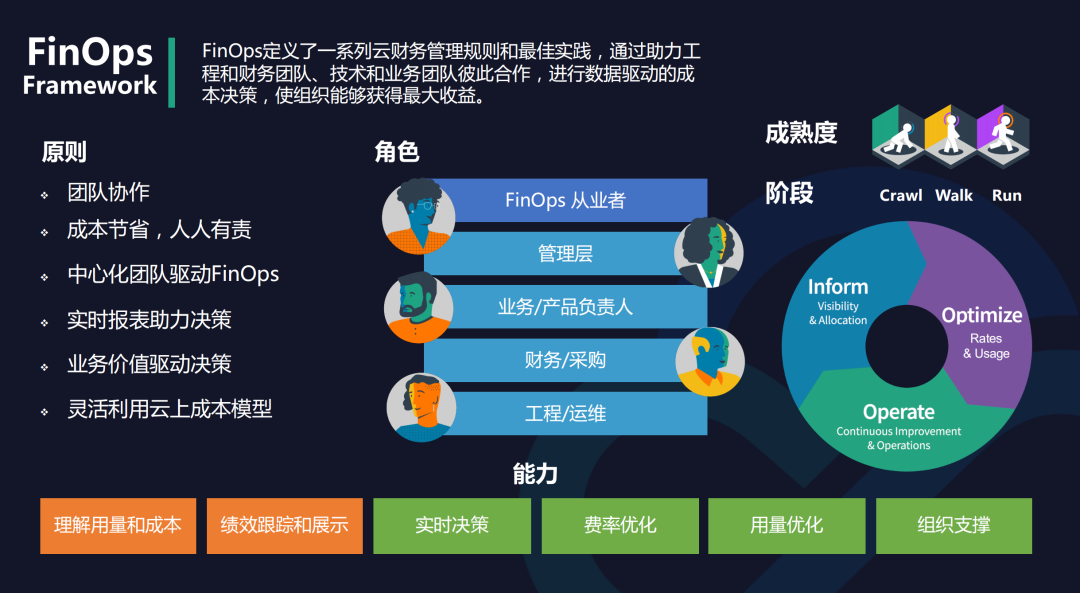
Crane 會通過下面 3 個方面來開啟成本優(yōu)化之旅:
成本展示: Kubernetes 資源( Deployments, StatefulSets )的多維度聚合與展示。 成本分析: 周期性的分析集群資源的狀態(tài)并提供優(yōu)化建議。 成本優(yōu)化: 通過豐富的優(yōu)化工具更新配置達成降本的目標(biāo)。
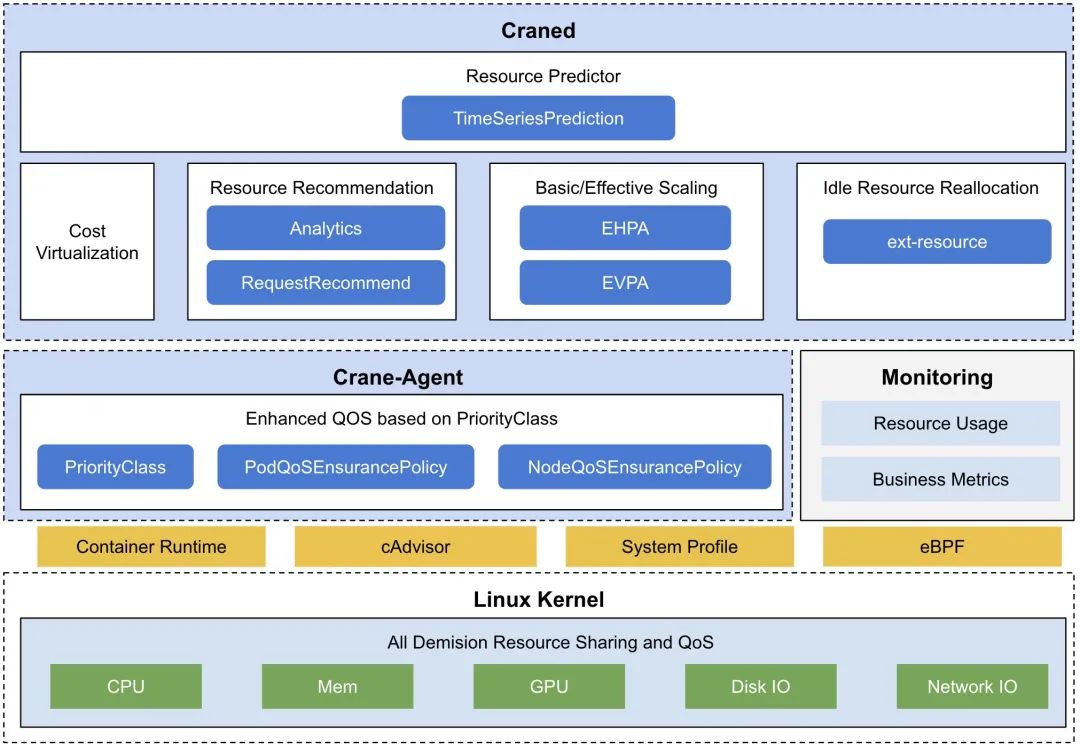
核心功能包括:成本可視化和優(yōu)化評估;內(nèi)置了多種推薦器 - 資源推薦、副本推薦、閑置資源推薦;基于預(yù)測的水平彈性器;負載感知的調(diào)度器;基于 QOS 的混部。下面我們來詳細了解下 Crane 的各項功能。
安裝
我們這里使用 Helm 的方式來進行安裝,首先需要安裝 Prometheus 和 Grafana(如果您已經(jīng)在環(huán)境中部署了 Prometheus 和 Grafana,可以跳過該步驟)。
Crane 使用 Prometheus 獲取集群工作負載對資源的使用情況,可以使用如下所示命令安裝 Prometheus:
$ helm repo add prometheus-community https://finops-helm.pkg.coding.net/gocrane/prometheus-community
$ helm upgrade --install prometheus -n crane-system \
--set pushgateway.enabled=false \
--set alertmanager.enabled=false \
--set server.persistentVolume.enabled=false \
-f https://gitee.com/finops/helm-charts/raw/main/integration/prometheus/override_values.yaml \
--create-namespace prometheus-community/prometheus
由于 Crane 的 Fadvisor 會使用 Grafana 來展示成本預(yù)估,所以我們也需要安裝 Grafana:
$ helm repo add grafana https://finops-helm.pkg.coding.net/gocrane/grafana
$ helm upgrade --install grafana \
-f https://gitee.com/finops/helm-charts/raw/main/integration/grafana/override_values.yaml \
-n crane-system \
--create-namespace grafana/grafana
上面我們指定的 values 文件中配置了 Prometheus 數(shù)據(jù)源以及一些相關(guān)的 Dashboard,直接安裝后即可使用。
然后接下來安裝 crane 與 fadvisor,同樣直接使用 Helm Chart 安裝即可,如下命令所示:
$ helm repo add crane https://finops-helm.pkg.coding.net/gocrane/gocrane
$ helm upgrade --install crane -n crane-system --create-namespace crane/crane
$ helm upgrade --install fadvisor -n crane-system --create-namespace crane/fadvisor
安裝后可以查看 Pod 列表了解應(yīng)用狀態(tài):
$ kubectl get pods -n crane-system
NAME READY STATUS RESTARTS AGE
crane-agent-8jrs5 0/1 CrashLoopBackOff 71 (2m26s ago) 3h23m
crane-agent-t2rpz 0/1 CrashLoopBackOff 71 (65s ago) 3h23m
craned-776c7b6c75-gx8cp 2/2 Running 0 3h28m
fadvisor-56fcc547b6-zvf6r 1/1 Running 0 158m
grafana-5cd57f9f6b-d7nk5 1/1 Running 0 3h32m
metric-adapter-887f6548d-qcbb8 1/1 Running 0 3h28m
prometheus-kube-state-metrics-5f6f856ffb-4lrrr 1/1 Running 0 3h34m
prometheus-node-exporter-97vmz 1/1 Running 0 3h27m
prometheus-node-exporter-m2gr9 1/1 Running 0 3h27m
prometheus-server-7744f66fb4-lw2sz 2/2 Running 0 3h34m
需要注意我們這里 crane-agent 啟動失敗了,這是因為我的 K8s 集群使用的是 containerd 這種容器運行時,需要明確聲明指定使用的運行時 endpoint:
$ kubectl edit ds crane-agent -n crane-system
# ......
spec:
containers:
- args:
- --v=2
- --runtime-endpoint=/run/containerd/containerd.sock # 指定有containerd的sock文件
command:
- /crane-agent
# ......
此外還需要更新 crane-agent 的 rbac 權(quán)限:
$ kubectl edit clusterrole crane-agent
# ......
- apiGroups:
- ensurance.crane.io
resources:
- podqosensurancepolicies
- nodeqoss # 增加 nodeqoss 和 podqoss 資源的權(quán)限
- podqoss
# ......
然后我們可以再創(chuàng)建一個 Ingress 對象來暴露 crane 的 dashboard 服務(wù):
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: ingress-crane-dashboard
namespace: crane-system
spec:
ingressClassName: nginx
rules:
- host: crane.k8s.local # change to your domain
http:
paths:
- path: /
pathType: Prefix
backend:
service:
name: craned
port:
number: 9090
直接應(yīng)用該 ingress 資源對象即可,當(dāng)然前提是你已經(jīng)安裝了 ingress-nginx:
$ kubectl get pods -n ingress-nginx
NAME READY STATUS RESTARTS AGE
ingress-nginx-controller-7647c44fb9-6gcsf 1/1 Running 8 (44m ago) 21d
ingress-nginx-defaultbackend-7fc5bfd66c-gqmmj 1/1 Running 8 (44m ago) 21d
$ kubectl get ingress -n crane-system
NAME CLASS HOSTS ADDRESS PORTS AGE
ingress-crane-dashboard nginx crane.k8s.local 192.168.0.52 80 11s
將 crane.k8s.local 映射到 192.168.0.52 后就可以訪問 crane 的 dashboard 了:
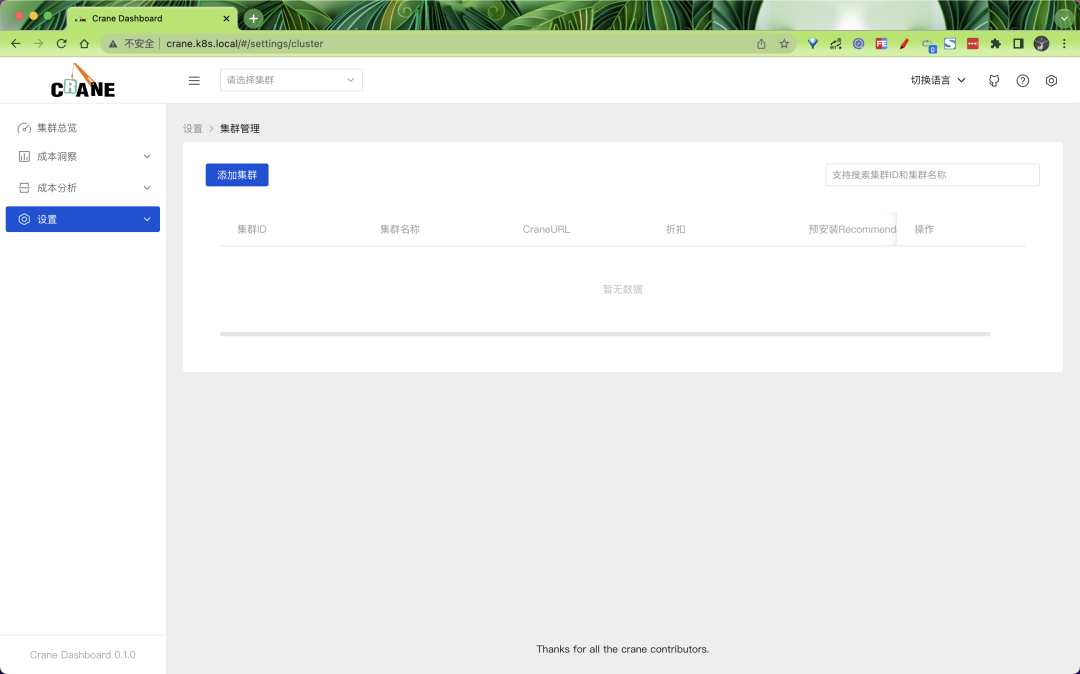
第一次訪問 dashboard 的時候需要添加一個 K8s 集群,添加添加集群按鈕開始添加,填入正確的 CRNE Endpoint 地址即可。
然后切換到集群總覽可以查看到當(dāng)前集群的一些成本相關(guān)數(shù)據(jù),由于目前數(shù)據(jù)還不足,所以會有一些空的圖表。
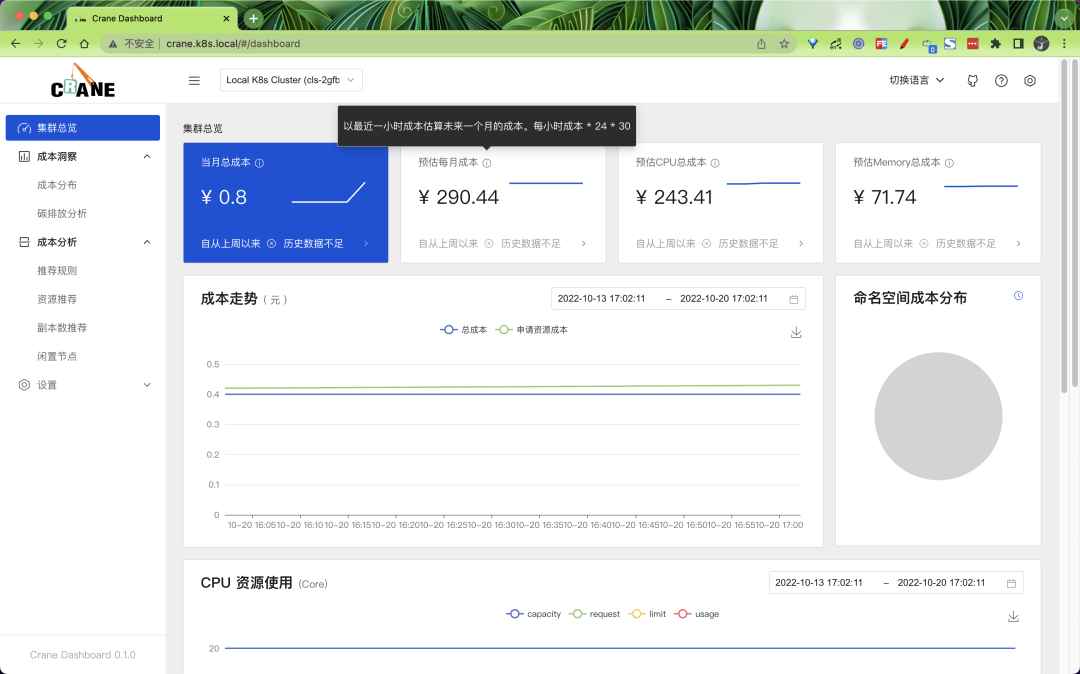
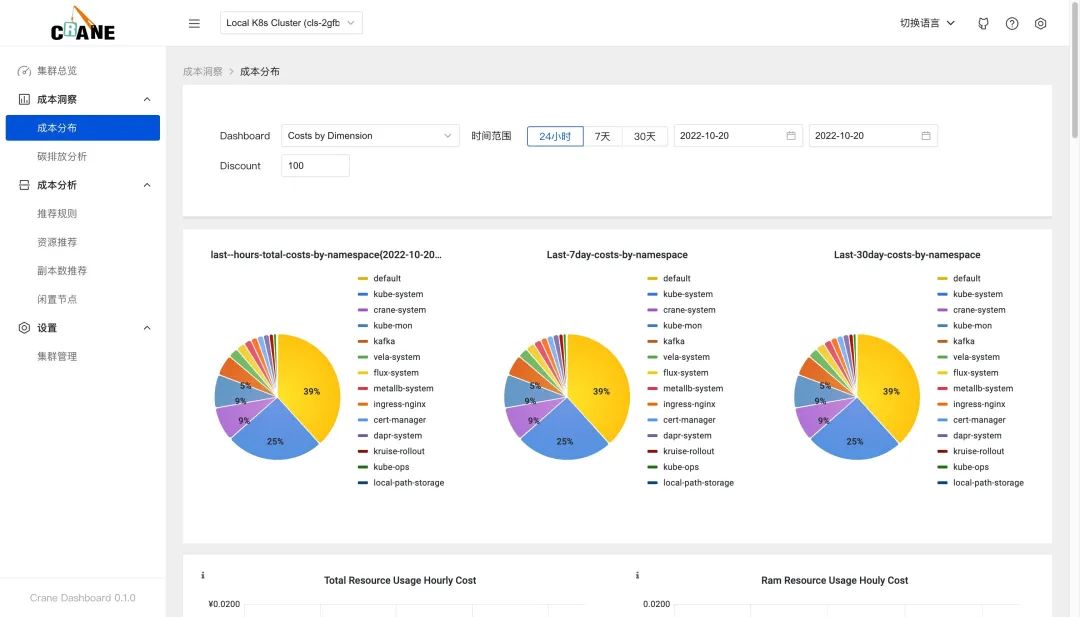
智能推薦
在 dasbhoard 中開箱后就可以看到相關(guān)的成本數(shù)據(jù),是因為在添加集群的時候我們安裝了推薦的規(guī)則。
推薦框架會自動分析集群的各種資源的運行情況并給出優(yōu)化建議。Crane 的推薦模塊會定期檢測發(fā)現(xiàn)集群資源配置的問題,并給出優(yōu)化建議。智能推薦提供了多種 Recommender 來實現(xiàn)面向不同資源的優(yōu)化推薦。
在成本分析>推薦規(guī)則頁面可以看到我們安裝的兩個推薦規(guī)則。
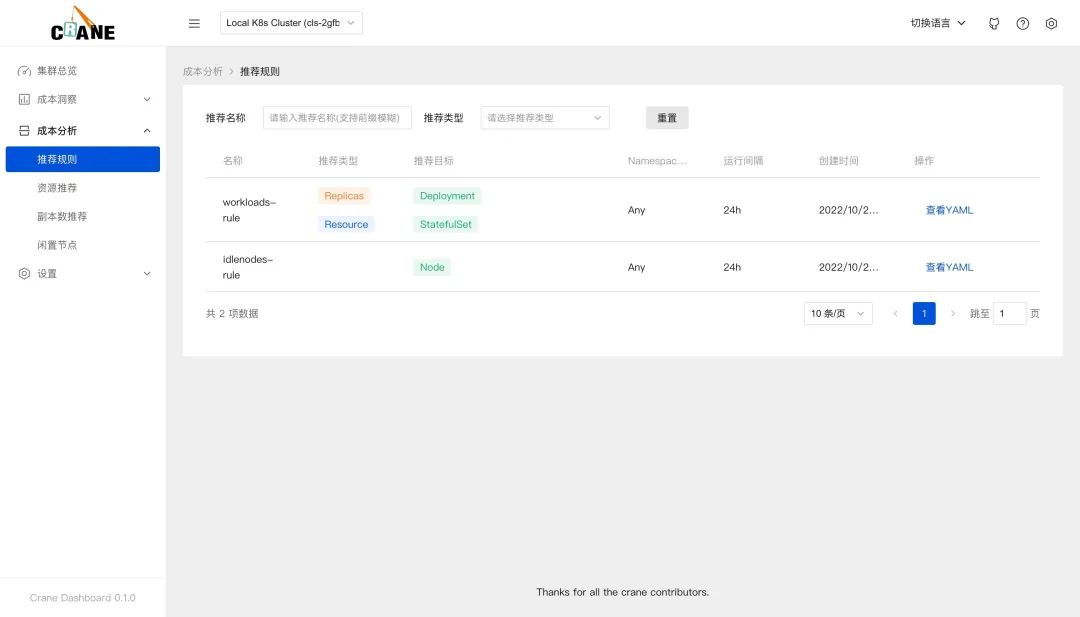
RecommendationRule CRD 對象:$ kubectl get RecommendationRule
NAME RUNINTERVAL AGE
idlenodes-rule 24h 16m
workloads-rule 24h 16m
workloads-rule 這個推薦規(guī)則的資源對象如下所示:
apiVersion: analysis.crane.io/v1alpha1
kind: RecommendationRule
metadata:
name: workloads-rule
labels:
analysis.crane.io/recommendation-rule-preinstall: "true"
spec:
resourceSelectors:
- kind: Deployment
apiVersion: apps/v1
- kind: StatefulSet
apiVersion: apps/v1
namespaceSelector:
any: true
runInterval: 24h
recommenders:
- name: Replicas
- name: Resource
RecommendationRule 是一個全部范圍內(nèi)的對象,該推薦規(guī)則會對所有命名空間中的 Deployments 和 StatefulSets 做資源推薦和副本數(shù)推薦。相關(guān)規(guī)范屬性如下所示:
每隔 24 小時運行一次分析推薦,
runInterval格式為時間間隔,比如: 1h,1m,設(shè)置為空表示只運行一次。待分析的資源通過配置
resourceSelectors數(shù)組設(shè)置,每個resourceSelector通過kind、apiVersion、name選擇 K8s 中的資源,當(dāng)不指定 name 時表示在namespaceSelector基礎(chǔ)上的所有資源。namespaceSelector定義了待分析資源的命名空間,any: true表示選擇所有命名空間。recommenders定義了待分析的資源需要通過哪些Recommender進行分析。目前支持兩種Recommender:資源推薦(Resource): 通過 VPA 算法分析應(yīng)用的真實用量推薦更合適的資源配置 副本數(shù)推薦(Replicas): 通過 HPA 算法分析應(yīng)用的真實用量推薦更合適的副本數(shù)量
資源推薦
Kubernetes 用戶在創(chuàng)建應(yīng)用資源時常常是基于經(jīng)驗值來設(shè)置 request 和 limit,通過資源推薦的算法分析應(yīng)用的真實用量推薦更合適的資源配置,你可以參考并采納它提升集群的資源利用率。該推薦算法模型采用了 VPA 的滑動窗口(Moving Window)算法進行推薦:
通過監(jiān)控數(shù)據(jù),獲取 Workload 過去一周(可配置)的 CPU 和內(nèi)存的歷史用量。 算法考慮數(shù)據(jù)的時效性,較新的數(shù)據(jù)采樣點會擁有更高的權(quán)重。 CPU 推薦值基于用戶設(shè)置的目標(biāo)百分位值計算,內(nèi)存推薦值基于歷史數(shù)據(jù)的最大值。
副本數(shù)推薦
Kubernetes 用戶在創(chuàng)建應(yīng)用資源時常常是基于經(jīng)驗值來設(shè)置副本數(shù)。通過副本數(shù)推薦的算法分析應(yīng)用的真實用量推薦更合適的副本配置,同樣可以參考并采納它提升集群的資源利用率。其實現(xiàn)的基本算法是基于工作負載歷史 CPU 負載,找到過去七天內(nèi)每小時負載最低的 CPU 用量,計算按 50%(可配置)利用率和工作負載 CPU Request 應(yīng)配置的副本數(shù)。
當(dāng)我們部署 crane 的時候會在同一個命名空間中創(chuàng)建一個名為 recommendation-configuration 的 ConfigMap 對象,包含一個 yaml 格式的 RecommendationConfiguration,該配置訂閱了 recommender 的配置,如下所示:
$ kubectl get cm recommendation-configuration -n crane-system -oyaml
apiVersion: v1
data:
config.yaml: |-
apiVersion: analysis.crane.io/v1alpha1
kind: RecommendationConfiguration
recommenders:
- name: Replicas # 副本數(shù)推薦
acceptedResources:
- kind: Deployment
apiVersion: apps/v1
- kind: StatefulSet
apiVersion: apps/v1
- name: Resource # 資源推薦
acceptedResources:
- kind: Deployment
apiVersion: apps/v1
- kind: StatefulSet
apiVersion: apps/v1
kind: ConfigMap
metadata:
name: recommendation-configuration
namespace: crane-system
需要注意的是資源類型和 recommenders 需要可以匹配,比如 Resource 推薦默認只支持 Deployments 和 StatefulSets。
同樣的也可以再查看一次閑置節(jié)點推薦規(guī)則的資源對象,如下所示:
$ kubectl get recommendationrule idlenodes-rule -oyaml
apiVersion: analysis.crane.io/v1alpha1
kind: RecommendationRule
metadata:
labels:
analysis.crane.io/recommendation-rule-preinstall: "true"
name: idlenodes-rule
spec:
namespaceSelector:
any: true
recommenders:
- name: IdleNode
resourceSelectors:
- apiVersion: v1
kind: Node
runInterval: 24h
創(chuàng)建 RecommendationRule 配置后,RecommendationRule 控制器會根據(jù)配置定期運行推薦任務(wù),給出優(yōu)化建議生成 Recommendation 對象,然后我們可以根據(jù)優(yōu)化建議 Recommendation 調(diào)整資源配置。
比如我們這里集群中已經(jīng)生成了多個優(yōu)化建議 Recommendation 對象。
$ kubectl get recommendations
NAME TYPE TARGETKIND TARGETNAMESPACE TARGETNAME STRATEGY PERIODSECONDS ADOPTIONTYPE AGE
workloads-rule-resource-8whzs Resource StatefulSet default nacos Once StatusAndAnnotation 34m
workloads-rule-resource-hx4cp Resource StatefulSet default redis-replicas Once StatusAndAnnotation 34m
# ......
可以隨便查看任意一個優(yōu)化建議對象。
$ kubectl get recommend workloads-rule-resource-g7nwp -n crane-system -oyaml
apiVersion: analysis.crane.io/v1alpha1
kind: Recommendation
metadata:
name: workloads-rule-resource-g7nwp
namespace: crane-system
spec:
adoptionType: StatusAndAnnotation
completionStrategy:
completionStrategyType: Once
targetRef:
apiVersion: apps/v1
kind: Deployment
name: fadvisor
namespace: crane-system
type: Resource
status:
action: Patch
conditions:
- lastTransitionTime: "2022-10-20T07:43:49Z"
message: Recommendation is ready
reason: RecommendationReady
status: "True"
type: Ready
currentInfo: '{"spec":{"template":{"spec":{"containers":[{"name":"fadvisor","resources":{"requests":{"cpu":"0","memory":"0"}}}]}}}}'
lastUpdateTime: "2022-10-20T07:43:49Z"
recommendedInfo: '{"spec":{"template":{"spec":{"containers":[{"name":"fadvisor","resources":{"requests":{"cpu":"114m","memory":"120586239"}}}]}}}}'
recommendedValue: |
resourceRequest:
containers:
- containerName: fadvisor
target:
cpu: 114m
memory: "120586239"
targetRef: {}
在 dashboard 的資源推薦頁面也能查看到優(yōu)化建議列表。
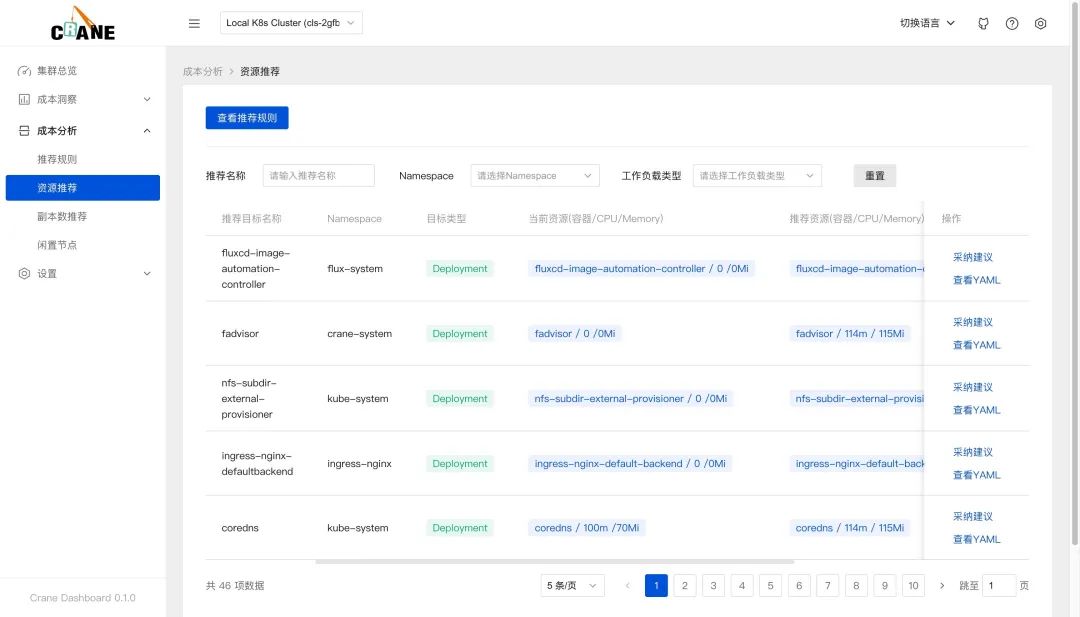
采納建議即可獲取優(yōu)化的執(zhí)行命令。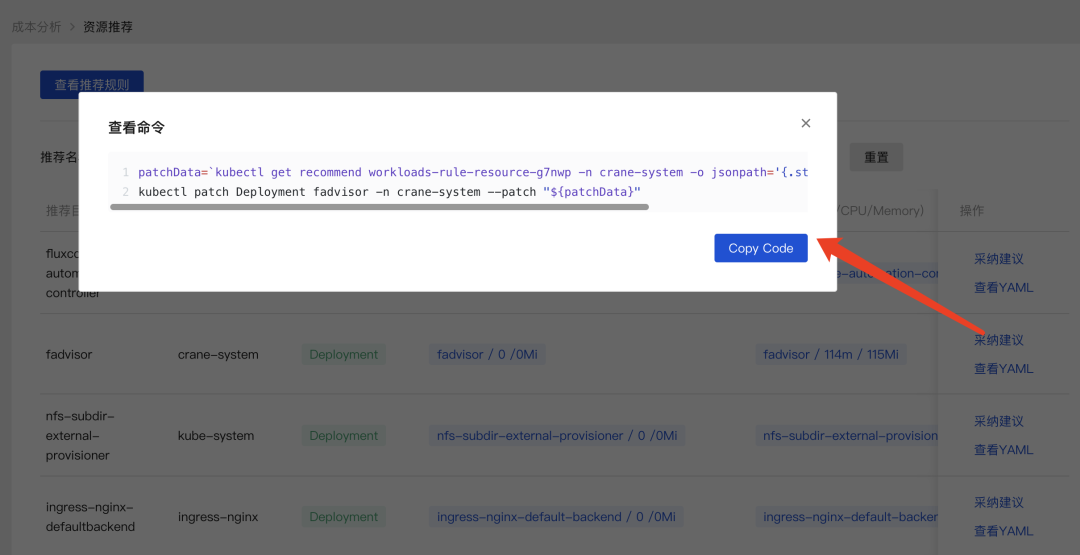
resources 資源數(shù)據(jù)。patchData=`kubectl get recommend workloads-rule-resource-g7nwp -n crane-system -o jsonpath='{.status.recommendedInfo}'`;kubectl patch Deployment fadvisor -n crane-system --patch "${patchData}"
對于閑置節(jié)點推薦,由于節(jié)點的下線在不同平臺上的步驟不同,用戶可以根據(jù)自身需求進行節(jié)點的下線或者縮容。
應(yīng)用在監(jiān)控系統(tǒng)(比如 Prometheus)中的歷史數(shù)據(jù)越久,推薦結(jié)果就越準確,建議生產(chǎn)上超過兩周時間。對新建應(yīng)用的預(yù)測往往不準。
自定義推薦
Recommendation Framework 提供了一套可擴展的 Recommender 框架并支持了內(nèi)置的 Recommender,用戶可以實現(xiàn)一個自定義的 Recommender,或者修改一個已有的 Recommender。
和 K8s 調(diào)度框架類似,Recommender 接口定義了一次推薦需要實現(xiàn)的四個階段和八個擴展點,這些擴展點會在推薦過程中按順序被調(diào)用。這些擴展點中的一些可以改變推薦決策,而另一些僅用來提供信息。
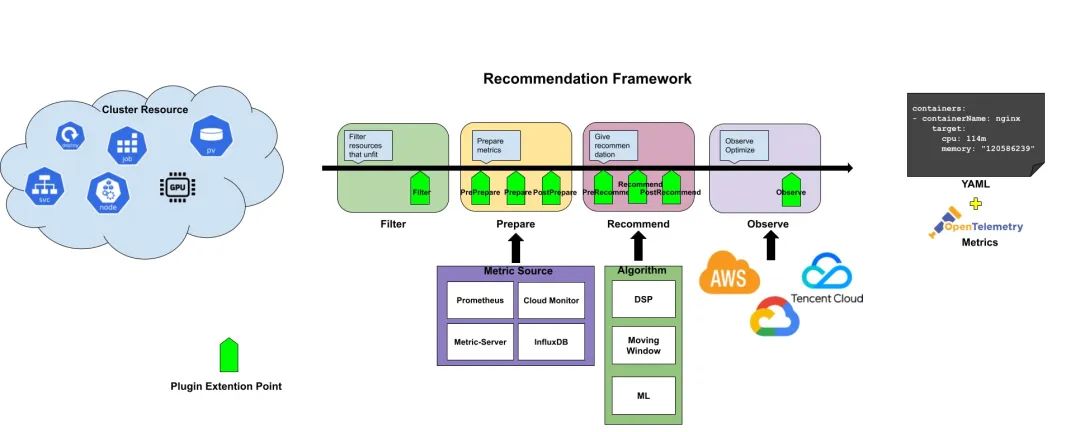
Recommender 接口定義如下所示:
type Recommender interface {
Name() string
framework.Filter
framework.PrePrepare
framework.Prepare
framework.PostPrepare
framework.PreRecommend
framework.Recommend
framework.PostRecommend
framework.Observe
}
// Phase: Filter
type Filter interface {
// Filter 將過濾無法通過目標(biāo)推薦器推薦的資源
Filter(ctx *RecommendationContext) error
}
// Phase: Prepare
type PrePrepare interface {
CheckDataProviders(ctx *RecommendationContext) error
}
type Prepare interface {
CollectData(ctx *RecommendationContext) error
}
type PostPrepare interface {
PostProcessing(ctx *RecommendationContext) error
}
type PreRecommend interface {
PreRecommend(ctx *RecommendationContext) error
}
// Phase: Recommend
type Recommend interface {
Recommend(ctx *RecommendationContext) error
}
type PostRecommend interface {
Policy(ctx *RecommendationContext) error
}
// Phase: Observe
type Observe interface {
Observe(ctx *RecommendationContext) error
}
整個推薦過程分成了四個階段:Filter、Prepare、Recommend、Observe,階段的輸入是需要分析的 Kubernetes 資源,輸出是推薦的優(yōu)化建議。接口中的 RecommendationContext 保存了一次推薦過程中的上下文,包括推薦目標(biāo)、RecommendationConfiguration 等信息,我們可以根據(jù)自身需求增加更多的內(nèi)容。
比如資源推薦就實現(xiàn)了 Recommender 接口,主要做了下面 3 個階段的處理:
Filter 階段:過濾沒有 Pod 的工作負載 Recommend 推薦:采用 VPA 的滑動窗口算法分別計算每個容器的 CPU 和內(nèi)存并給出對應(yīng)的推薦值 Observe 推薦:將推薦資源配置記錄到 crane_analytics_replicas_recommendation指標(biāo)
除了核心的智能推薦功能之外,Crane 還有很多高級特性,比如可以根據(jù)實際的節(jié)點利用率的動態(tài)調(diào)度器、基于流量預(yù)測的彈性 HPA 等等。
智能調(diào)度器
Crane 除了提供了智能推薦功能之外,還提供了一個調(diào)度器插件 Crane-scheduler 可以實現(xiàn)智能調(diào)度和完成拓撲感知調(diào)度與資源分配的工作。
動態(tài)調(diào)度器
K8s 的原生調(diào)度器只能通過資源的 requests 值來調(diào)度 pod,這很容易造成一系列負載不均的問題:
對于某些節(jié)點,實際負載與資源請求相差不大,這會導(dǎo)致很大概率出現(xiàn)穩(wěn)定性問題。 對于其他節(jié)點來說,實際負載遠小于資源請求,這將導(dǎo)致資源的巨大浪費。
為了解決這些問題,動態(tài)調(diào)度器根據(jù)實際的節(jié)點利用率構(gòu)建了一個簡單但高效的模型,并過濾掉那些負載高的節(jié)點來平衡集群。
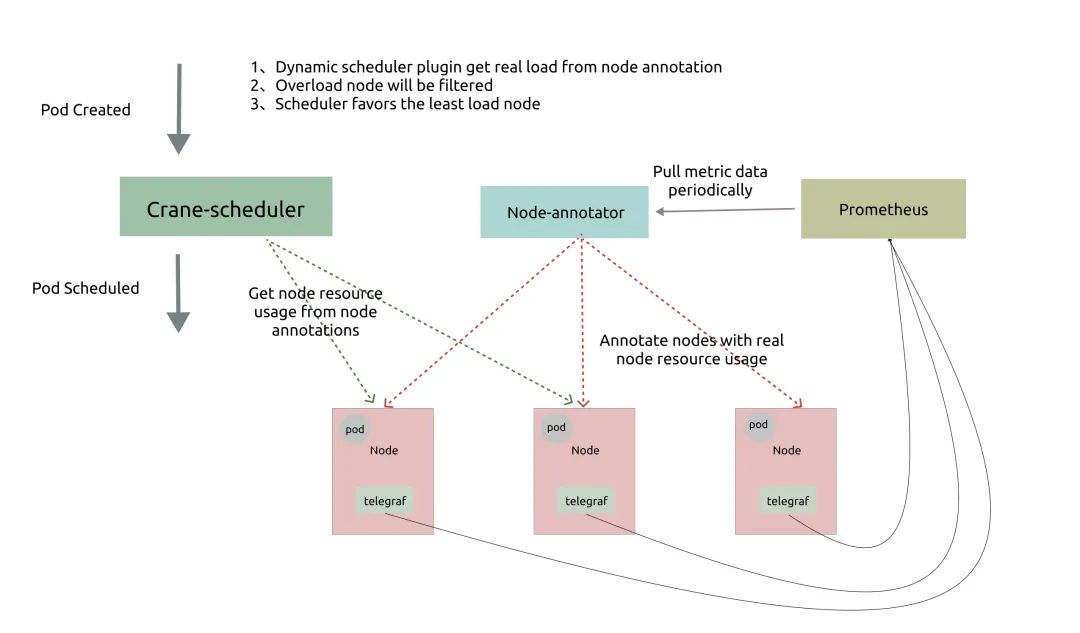
Node-annotator定期從 Prometheus 拉取數(shù)據(jù),并以 annotations 的形式在節(jié)點上用時間戳標(biāo)記它們。Dynamic plugin直接從節(jié)點的 annotations 中讀取負載數(shù)據(jù),過濾并基于簡單的算法對候選節(jié)點進行評分。
動態(tài)調(diào)度器提供了一個默認值調(diào)度策略,配置文件如下所示:
# policy.yaml
apiVersion: scheduler.policy.crane.io/v1alpha1
kind: DynamicSchedulerPolicy
spec:
syncPolicy:
##cpu usage
- name: cpu_usage_avg_5m
period: 3m
- name: cpu_usage_max_avg_1h
period: 15m
- name: cpu_usage_max_avg_1d
period: 3h
##memory usage
- name: mem_usage_avg_5m
period: 3m
- name: mem_usage_max_avg_1h
period: 15m
- name: mem_usage_max_avg_1d
period: 3h
predicate:
##cpu usage
- name: cpu_usage_avg_5m
maxLimitPecent: 0.65
- name: cpu_usage_max_avg_1h
maxLimitPecent: 0.75
##memory usage
- name: mem_usage_avg_5m
maxLimitPecent: 0.65
- name: mem_usage_max_avg_1h
maxLimitPecent: 0.75
priority:
##cpu usage
- name: cpu_usage_avg_5m
weight: 0.2
- name: cpu_usage_max_avg_1h
weight: 0.3
- name: cpu_usage_max_avg_1d
weight: 0.5
##memory usage
- name: mem_usage_avg_5m
weight: 0.2
- name: mem_usage_max_avg_1h
weight: 0.3
- name: mem_usage_max_avg_1d
weight: 0.5
hotValue:
- timeRange: 5m
count: 5
- timeRange: 1m
count: 2
我們可以根據(jù)實際需求自定義該策略配置,默認策略依賴于以下指標(biāo):
cpu_usage_avg_5m cpu_usage_max_avg_1h cpu_usage_max_avg_1d mem_usage_avg_5m mem_usage_max_avg_1h mem_usage_max_avg_1d
這幾個指標(biāo)我們這里是通過記錄規(guī)則創(chuàng)建的,可以查看 Prometheus 的配置文件來了解詳細信息:
$ kubectl get cm -n crane-system prometheus-server -oyaml
apiVersion: v1
data:
alerting_rules.yml: |
{}
alerts: |
{}
allow-snippet-annotations: "false"
prometheus.yml: |
global:
evaluation_interval: 1m
scrape_interval: 1m
scrape_timeout: 10s
rule_files:
- /etc/config/recording_rules.yml
- /etc/config/alerting_rules.yml
- /etc/config/rules
- /etc/config/alerts
scrape_configs:
- job_name: prometheus
static_configs:
- targets:
- localhost:9090
# ......
recording_rules.yml: |
groups:
- interval: 3600s
name: costs.rules
rules:
# ......
- interval: 30s
name: scheduler.rules.30s
rules:
- expr: 100 - (avg by (instance) (irate(node_cpu_seconds_total{mode="idle"}[90s]))
* 100)
record: cpu_usage_active
- expr: 100*(1-node_memory_MemAvailable_bytes/node_memory_MemTotal_bytes)
record: mem_usage_active
- interval: 1m
name: scheduler.rules.1m
rules:
- expr: avg_over_time(cpu_usage_active[5m])
record: cpu_usage_avg_5m
- expr: avg_over_time(mem_usage_active[5m])
record: mem_usage_avg_5m
- interval: 5m
name: scheduler.rules.5m
rules:
- expr: max_over_time(cpu_usage_avg_5m[1h])
record: cpu_usage_max_avg_1h
- expr: max_over_time(cpu_usage_avg_5m[1d])
record: cpu_usage_max_avg_1d
- expr: max_over_time(mem_usage_avg_5m[1h])
record: mem_usage_max_avg_1h
- expr: max_over_time(mem_usage_avg_5m[1d])
record: mem_usage_max_avg_1d
rules: |
{}
kind: ConfigMap
metadata:
name: prometheus-server
namespace: crane-system
在調(diào)度的 Filter 階段,如果該節(jié)點的實際使用率大于上述任一指標(biāo)的閾值,則該節(jié)點將被過濾。而在 Score 階段,最終得分是這些指標(biāo)值的加權(quán)和。
在生產(chǎn)集群中,可能會頻繁出現(xiàn)調(diào)度熱點,因為創(chuàng)建 Pod 后節(jié)點的負載不能立即增加。因此,我們定義了一個額外的指標(biāo),名為 hotValue,表示節(jié)點最近幾次的調(diào)度頻率,并且節(jié)點的最終優(yōu)先級是最終得分減去 hotValue。
我們可以在 K8s 集群中安裝 Crane-scheduler 作為第二個調(diào)度器來進行驗證:
$ helm repo add crane https://finops-helm.pkg.coding.net/gocrane/gocrane
$ helm upgrade --install scheduler -n crane-system --create-namespace --set global.prometheusAddr="http://prometheus-server.crane-system.svc.cluster.local:8080" crane/scheduler
安裝后會創(chuàng)建一個名為 scheduler-config 的 ConfigMap 對象,里面包含的就是調(diào)度器的配置文件,我們會在配置中啟用 Dynamic 動態(tài)調(diào)度插件:
$ kubectl get cm -n crane-system scheduler-config -oyaml
apiVersion: v1
data:
scheduler-config.yaml: |
apiVersion: kubescheduler.config.k8s.io/v1beta2
kind: KubeSchedulerConfiguration
leaderElection:
leaderElect: false
profiles:
- schedulerName: crane-scheduler
plugins:
filter:
enabled:
- name: Dynamic
score:
enabled:
- name: Dynamic
weight: 3
pluginConfig:
- name: Dynamic
args:
policyConfigPath: /etc/kubernetes/policy.yaml
kind: ConfigMap
metadata:
name: scheduler-config
namespace: crane-system
安裝完成后我們可以任意創(chuàng)建一個 Pod,并通過設(shè)置 schedulerName: crane-scheduler 屬性明確指定使用該調(diào)度器進行調(diào)度,如下所示:
apiVersion: apps/v1
kind: Deployment
metadata:
name: cpu-stress
spec:
selector:
matchLabels:
app: cpu-stress
replicas: 1
template:
metadata:
labels:
app: cpu-stress
spec:
schedulerName: crane-scheduler
hostNetwork: true
tolerations:
- key: node.kubernetes.io/network-unavailable
operator: Exists
effect: NoSchedule
containers:
- name: stress
image: docker.io/gocrane/stress:latest
command: ["stress", "-c", "1"]
resources:
requests:
memory: "1Gi"
cpu: "1"
limits:
memory: "1Gi"
cpu: "1"
直接創(chuàng)建上面的資源對象,正常創(chuàng)建的 Pod 就會通過 Crane Scheduler 調(diào)度器進行調(diào)度了:
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Scheduled 22s crane-scheduler Successfully assigned default/cpu-stress-cc8656b6c-hsqdg to node2
Normal Pulling 22s kubelet Pulling image "docker.io/gocrane/stress:latest"
如果想默認使用該動態(tài)調(diào)度器,則可以使用該調(diào)度器去替換掉默認的調(diào)度器即可。
拓撲感知調(diào)度
Crane-Scheduler 和 Crane-Agent 配合工作可以完成拓撲感知調(diào)度與資源分配的工作。Crane-Agent 從節(jié)點采集資源拓撲,包括 NUMA、Socket、設(shè)備等信息,匯總到 NodeResourceTopology 這個自定義資源對象中。
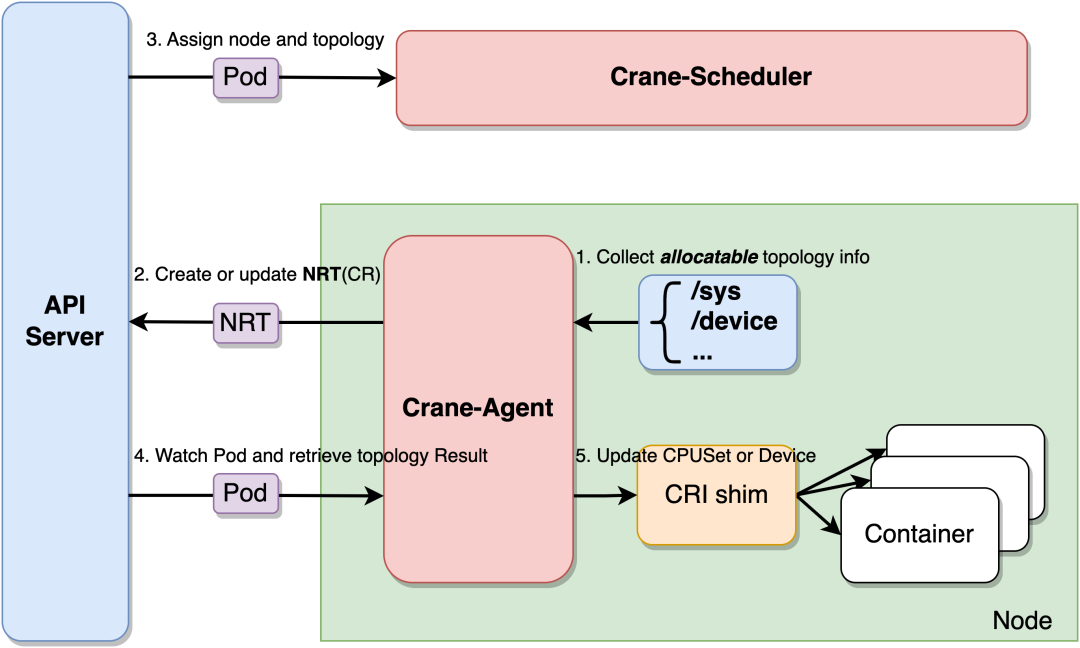
Crane-Scheduler 在調(diào)度時會參考節(jié)點的 NodeResourceTopology 對象獲取到節(jié)點詳細的資源拓撲結(jié)構(gòu),在調(diào)度到節(jié)點的同時還會為 Pod 分配拓撲資源,并將結(jié)果寫到 Pod 的 annotations 中。Crane-Agent 在節(jié)點上 Watch 到 Pod 被調(diào)度后,從 Pod 的 annotations 中獲取到拓撲分配結(jié)果,并按照用戶給定的 CPU 綁定策略進行 CPUSet 的細粒度分配。
Crane 中提供了四種 CPU 分配策略,分別如下:
none:該策略不進行特別的 CPUSet 分配,Pod 會使用節(jié)點 CPU 共享池。exclusive:該策略對應(yīng) kubelet 的 static 策略,Pod 會獨占 CPU 核心,其他任何 Pod 都無法使用。numa:該策略會指定 NUMA Node,Pod 會使用該 NUMA Node 上的 CPU 共享池。immovable:該策略會將 Pod 固定在某些 CPU 核心上,但這些核心屬于共享池,其他 Pod 仍可使用。首先需要在 Crane-Agent 啟動參數(shù)中添加 --feature-gates=NodeResourceTopology=true,CraneCPUManager=true 開啟拓撲感知調(diào)度特性。
然后修改 kube-scheduler 的配置文件(scheduler-config.yaml ) 啟用動態(tài)調(diào)度插件并配置插件參數(shù):
apiVersion: kubescheduler.config.k8s.io/v1beta2
kind: KubeSchedulerConfiguration
leaderElection:
leaderElect: true
clientConnection:
kubeconfig: "REPLACE_ME_WITH_KUBE_CONFIG_PATH"
profiles:
- schedulerName: default-scheduler # 可以改成自己的調(diào)度器名稱
plugins:
preFilter:
enabled:
- name: NodeResourceTopologyMatch
filter:
enabled:
- name: NodeResourceTopologyMatch
score:
enabled:
- name: NodeResourceTopologyMatch
weight: 2
reserve:
enabled:
- name: NodeResourceTopologyMatch
preBind:
enabled:
- name: NodeResourceTopologyMatch
正確安裝組件后,每個節(jié)點均會生成 NodeResourceTopology 對象。
$ kubectl get nrt
NAME CRANE CPU MANAGER POLICY CRANE TOPOLOGY MANAGER POLICY AGE
node1 Static SingleNUMANodePodLevel 35d
可以看出集群中節(jié)點 node1 已生成對應(yīng)的 NRT 對象,此時 Crane 的 CPU Manager Policy 為 Static,節(jié)點默認的 Topology Manager Policy 為 SingleNUMANodePodLevel,代表節(jié)點不允許跨 NUMA 分配資源。
使用以下實例進行調(diào)度測試:
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
labels:
app: nginx
spec:
selector:
matchLabels:
app: nginx
template:
metadata:
annotations:
topology.crane.io/topology-awareness: "true" # 添加注解,表示Pod需要感知CPU拓撲,資源分配不允許跨NUMA。若不指定,則拓撲策略默認繼承節(jié)點上的topology.crane.io/topology-awareness標(biāo)簽
topology.crane.io/cpu-policy: "exclusive" # 添加注解,表示Pod的CPU分配策略為exclusive策略。
labels:
app: nginx
spec:
containers:
- image: nginx
name: nginx
resources:
limits:
cpu: "2" # 需要limits.cpu值,如果要開啟綁核,則該值必須等于requests.cpu。
memory: 2Gi
應(yīng)用后可以從 annotations 中查看 Pod 的拓撲分配結(jié)果,發(fā)現(xiàn) Pod 在 NUMA Node0 上被分配了 2 個 CPU 核心。
$ kubectl get pod -o custom-columns=name:metadata.name,topology-result:metadata.annotations."topology\.crane\.io/topology-result"
name topology-result
nginx-deployment-754d99dcdf-mtcdp [{"name":"node0","type":"Node","resources":{"capacity":{"cpu":"2"}}}]
實現(xiàn)基于流量預(yù)測的彈性
Kubernetes HPA 支持了豐富的彈性擴展能力,Kubernetes 平臺開發(fā)者部署服務(wù)實現(xiàn)自定義 Metric 的服務(wù),Kubernetes 用戶配置多項內(nèi)置的資源指標(biāo)或者自定義 Metric 指標(biāo)實現(xiàn)自定義水平彈性。
EffectiveHorizontalPodAutoscaler(簡稱 EHPA)是 Crane 提供的彈性伸縮產(chǎn)品,它基于社區(qū) HPA 做底層的彈性控制,支持更豐富的彈性觸發(fā)策略(預(yù)測,觀測,周期),讓彈性更加高效,并保障了服務(wù)的質(zhì)量。
提前擴容,保證服務(wù)質(zhì)量:通過算法預(yù)測未來的流量洪峰提前擴容,避免擴容不及時導(dǎo)致的雪崩和服務(wù)穩(wěn)定性故障。 減少無效縮容:通過預(yù)測未來可減少不必要的縮容,穩(wěn)定工作負載的資源使用率,消除突刺誤判。 支持 Cron 配置:支持 Cron-based 彈性配置,應(yīng)對大促等異常流量洪峰。 兼容社區(qū):使用社區(qū) HPA 作為彈性控制的執(zhí)行層,能力完全兼容社區(qū)。
Effective HPA 兼容社區(qū)的 Kubernetes HPA 的能力,提供了更智能的彈性策略,比如基于預(yù)測的彈性和基于 Cron 周期的彈性等。在了解如何使用 EHPA 之前,我們有必要來詳細了解下 K8s 中的 HPA 對象。通過此伸縮組件,Kubernetes 集群可以利用監(jiān)控指標(biāo)(CPU 使用率等)自動擴容或者縮容服務(wù)中的 Pod 數(shù)量,當(dāng)業(yè)務(wù)需求增加時,HPA 將自動增加服務(wù)的 Pod 數(shù)量,提高系統(tǒng)穩(wěn)定性,而當(dāng)業(yè)務(wù)需求下降時,HPA 將自動減少服務(wù)的 Pod 數(shù)量,減少對集群資源的請求量,甚至還可以配合 Cluster Autoscaler 實現(xiàn)集群規(guī)模的自動伸縮,節(jié)省 IT 成本。
不過目前默認的 HPA 對象只能支持根據(jù) CPU 和內(nèi)存的閾值檢測擴縮容,但也可以通過 custom metric api 來調(diào)用 Prometheus 實現(xiàn)自定義 metric,這樣就可以實現(xiàn)更加靈活的監(jiān)控指標(biāo)實現(xiàn)彈性伸縮了。
默認情況下,HPA 會通過 metrics.k8s.io 這個接口服務(wù)來獲取 Pod 的 CPU、內(nèi)存指標(biāo),CPU 和內(nèi)存這兩者屬于核心指標(biāo),metrics.k8s.io 服務(wù)對應(yīng)的后端服務(wù)一般是 metrics-server,所以在使用 HPA 的時候需要安裝該應(yīng)用。
如果 HPA 要通過非 CPU、內(nèi)存的其他指標(biāo)來伸縮容器,我們則需要部署一套監(jiān)控系統(tǒng)如 Prometheus,讓 Prometheus 采集各種指標(biāo),但是 Prometheus 采集到的 metrics 指標(biāo)并不能直接給 K8s 使用,因為兩者數(shù)據(jù)格式是不兼容的,因此需要使用到另外一個組件 prometheus-adapter,該組件可以將 Prometheus 的 metrics 指標(biāo)數(shù)據(jù)格式轉(zhuǎn)換成 K8s API 接口能識別的格式,另外我們還需要在 K8s 注冊一個服務(wù)(即 custom.metrics.k8s.io),以便 HPA 能通過 /apis/ 進行訪問。
需要注意的是 Crane 提供了一個 metric-adapter 組件,該組件和 prometheus-adapter 都基于 custom-metric-apiserver 實現(xiàn)了 Custom Metric 和 External Metric 的 ApiService,在安裝 Crane 時會將對應(yīng)的 ApiService 安裝為 Crane 的 metric-adapter,所以它會和 prometheus-adapter 沖突,因為 Prometheus 是當(dāng)下最流行的開源監(jiān)控系統(tǒng),所以我們更愿意使用它來獲取用戶的自定義指標(biāo),那么我們就需要去安裝 prometheus-adapter,但是在安裝之前需要刪除 Crane 提供的 ApiService。
# 查看當(dāng)前集群 ApiService
$ kubectl get apiservice |grep crane-system
v1beta1.custom.metrics.k8s.io crane-system/metric-adapter True 3h51m
v1beta1.external.metrics.k8s.io crane-system/metric-adapter True 3h51m
# 刪除 crane 安裝的 ApiService
$ kubectl delete apiservice v1beta1.custom.metrics.k8s.io
$ kubectl delete apiservice v1beta1.external.metrics.k8s.io
然后通過 Helm Chart 來安裝 Prometheus Adapter:
$ helm repo add prometheus-community https://prometheus-community.github.io/helm-charts
$ helm repo update
# 指定有 prometheus 地址
$ helm upgrade --install prometheus-adapter -n crane-system prometheus-community/prometheus-adapter --set image.repository=cnych/prometheus-adapter,prometheus.url=http://prometheus-server.crane-system.svc,prometheus.port=8080
當(dāng) prometheus-adapter 安裝成功后我們再將 ApiService 改回 Crane 的 metric-adapter,應(yīng)用下面的資源清單即可:
apiVersion: apiregistration.k8s.io/v1
kind: APIService
metadata:
name: v1beta1.custom.metrics.k8s.io
spec:
service:
name: metric-adapter
namespace: crane-system
group: custom.metrics.k8s.io
version: v1beta1
insecureSkipTLSVerify: true
groupPriorityMinimum: 100
versionPriority: 100
---
apiVersion: apiregistration.k8s.io/v1
kind: APIService
metadata:
name: v1beta1.external.metrics.k8s.io
spec:
service:
name: metric-adapter
namespace: crane-system
group: external.metrics.k8s.io
version: v1beta1
insecureSkipTLSVerify: true
groupPriorityMinimum: 100
versionPriority: 100
應(yīng)用了上面的對象后,ApiService 改回了 Crane 的 metric-adapter,那么就不能使用 prometheus-adapter 的自定義 Metrics 功能,我們可以通過 Crane 的 metric-adapter 提供的 RemoteAdapter 功能將請求轉(zhuǎn)發(fā)給 prometheus-adapter。
修改 metric-adapter 的配置,將 prometheus-adapter 的 Service 配置成 Crane Metric Adapter 的 RemoteAdapter。
$ kubectl edit deploy metric-adapter -n crane-system
apiVersion: apps/v1
kind: Deployment
metadata:
name: metric-adapter
namespace: crane-system
spec:
template:
spec:
containers:
- args:
# 添加外部 Adapter 配置
- --remote-adapter=true
- --remote-adapter-service-namespace=crane-system
- --remote-adapter-service-name=prometheus-adapter
- --remote-adapter-service-port=443
# ......
這是因為 Kubernetes 限制一個 ApiService 只能配置一個后端服務(wù),為了在一個集群內(nèi)使用 Crane 提供的 Metric 和 prometheus-adapter 提供的 Metric,Crane 支持了 RemoteAdapter 來解決該問題:
Crane Metric-Adapter 支持配置一個 Kubernetes Service 作為一個遠程 Adapter Crane Metric-Adapter 處理請求時會先檢查是否是 Crane 提供的 Local Metric,如果不是,則轉(zhuǎn)發(fā)給遠程 Adapter
下面我們來部署一個示例應(yīng)用,用來測試自定義指標(biāo)的容器彈性伸縮。如下所示的應(yīng)用暴露了 Metric 展示每秒收到的 http 請求數(shù)量。
# sample-app.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: sample-app
spec:
selector:
matchLabels:
app: sample-app
template:
metadata:
labels:
app: sample-app
spec:
containers:
- image: luxas/autoscale-demo:v0.1.2
name: metrics-provider
resources:
limits:
cpu: 500m
requests:
cpu: 200m
ports:
- containerPort: 8080
---
apiVersion: v1
kind: Service
metadata:
name: sample-app
spec:
ports:
- name: http
port: 80
targetPort: 8080
selector:
app: sample-app
type: NodePort
當(dāng)應(yīng)用部署完成后,我們可以通過命令檢查 http_requests_total 指標(biāo)數(shù)據(jù):
$ curl http://$(kubectl get service sample-app -o jsonpath='{ .spec.clusterIP }')/metrics
# HELP http_requests_total The amount of requests served by the server in total
# TYPE http_requests_total counter
http_requests_total 1
然后我們需要在 Prometheus 中配置抓取 sample-app 的指標(biāo),我們這里使用如下所示命令添加抓取配置:
$ kubectl edit cm -n crane-system prometheus-server
# 添加抓取 sample-app 配置
- job_name: sample-app
kubernetes_sd_configs:
- role: pod
relabel_configs:
- action: keep
regex: default;sample-app-(.+)
source_labels:
- __meta_kubernetes_namespace
- __meta_kubernetes_pod_name
- action: labelmap
regex: __meta_kubernetes_pod_label_(.+)
- action: replace
source_labels:
- __meta_kubernetes_namespace
target_label: namespace
- source_labels: [__meta_kubernetes_pod_name]
action: replace
target_label: pod
配置生效后我們可以在 Prometheus Dashboard 中查詢對應(yīng)的指標(biāo):
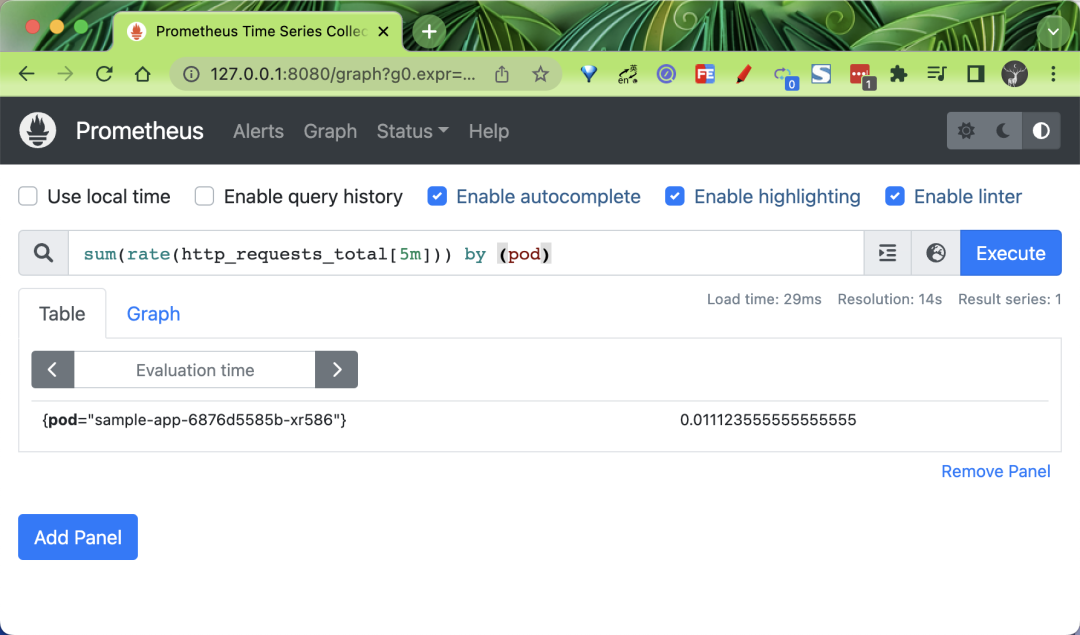
為了讓 HPA 能夠用到 Prometheus 采集到的指標(biāo),prometheus-adapter 通過使用 promql 語句來獲取指標(biāo),然后修改數(shù)據(jù)格式,并把重新組裝的指標(biāo)和值通過自己的接口暴露。而 HPA 會通過 /apis/custom.metrics.k8s.io/ 代理到 prometheus-adapter 的 service 上來獲取這些指標(biāo)。
如果把 Prometheus 的所有指標(biāo)到獲取一遍并重新組裝,那 adapter 的效率必然十分低下,因此 adapter 將需要讀取的指標(biāo)設(shè)計成可配置,讓用戶通過 ConfigMap 來決定讀取 Prometheus 的哪些監(jiān)控指標(biāo)。
我們這里使用 Helm Chart 方式安裝的 prometheus-adapter,其默認的 Rule 配置如下所示:
$ kubectl get cm -n crane-system prometheus-adapter -oyaml
apiVersion: v1
data:
config.yaml: |
rules:
- seriesQuery: '{__name__=~"^container_.*",container!="POD",namespace!="",pod!=""}'
seriesFilters: []
resources:
overrides:
namespace:
resource: namespace
pod:
resource: pod
name:
matches: ^container_(.*)_seconds_total$
as: ""
metricsQuery: sum(rate(<<.Series>>{<<.LabelMatchers>>,container!="POD"}[5m]))
by (<<.GroupBy>>)
# ...... 其他規(guī)則省略
kind: ConfigMap
metadata:
name: prometheus-adapter
namespace: crane-system
Prometheus adapter 的配置文件格式如上所示,它分為兩個部分,第一個是 rules,用于 custom metrics,另一個是 resourceRules,用于 metrics,如果你只用 Prometheus adapter 做 HPA,那么 resourceRules 就可以省略。
我們可以看到 rules 規(guī)則下面有很多的查詢語句,這些查詢語句的作用就是盡可能多的獲取指標(biāo),從而讓這些指標(biāo)都可以用于 HPA。也就是說通過 prometheus-adapter 可以將 Prometheus 中的任何一個指標(biāo)都用于 HPA,但是前提是你得通過查詢語句將它拿到(包括指標(biāo)名稱和其對應(yīng)的值)。也就是說,如果你只需要使用一個指標(biāo)做 HPA,那么你完全就可以只寫一條查詢,而不像上面使用了好多個查詢。整體上每個規(guī)則大致可以分為 4 個部分:
Discovery:它指定 Adapter 應(yīng)該如何找到該規(guī)則的所有 Prometheus 指標(biāo)Association:指定 Adapter 應(yīng)該如何確定和特定的指標(biāo)關(guān)聯(lián)的 Kubernetes 資源Naming:指定 Adapter 應(yīng)該如何在自定義指標(biāo) API 中暴露指標(biāo)Querying:指定如何將對一個獲多個 Kubernetes 對象上的特定指標(biāo)的請求轉(zhuǎn)換為對 Prometheus 的查詢
我們這里使用的 sample-app 應(yīng)用的指標(biāo)名叫 http_requests_total,通過上面的規(guī)則后會將 http_requests_total 轉(zhuǎn)換成 Pods 類型的 Custom Metric,可以獲得類似于 pods/http_requests 這樣的數(shù)據(jù)。
執(zhí)行以下命令,通過 Custom Metrics 指標(biāo)查詢方式,查看 HPA 可用指標(biāo)詳情。
$ kubectl get --raw "/apis/custom.metrics.k8s.io/v1beta1/namespaces/default/pods/*/http_requests" | jq .
{
"kind": "MetricValueList",
"apiVersion": "custom.metrics.k8s.io/v1beta1",
"metadata": {
"selfLink": "/apis/custom.metrics.k8s.io/v1beta1/namespaces/default/pods/%2A/http_requests"
},
"items": [
{
"describedObject": {
"kind": "Pod",
"namespace": "default",
"name": "sample-app-6876d5585b-wv8fl",
"apiVersion": "/v1"
},
"metricName": "http_requests",
"timestamp": "2022-10-27T11:19:05Z",
"value": "18m",
"selector": null
}
]
}
接下來我們就可以來測試下基于流量預(yù)測的容器彈性伸縮,這就需要用到 Crane 的 EHPA 對象了,我們可以使用上面的 pods/http_requests 自定義指標(biāo)來實現(xiàn)彈性功能。
許多業(yè)務(wù)在時間序列上天然存在周期性的,尤其是對于那些直接或間接為“人”服務(wù)的業(yè)務(wù)。這種周期性是由人們?nèi)粘;顒拥囊?guī)律性決定的。例如,人們習(xí)慣于中午和晚上點外賣;早晚總有交通高峰;即使是搜索等模式不那么明顯的服務(wù),夜間的請求量也遠低于白天時間。對于這類業(yè)務(wù)相關(guān)的應(yīng)用來說,從過去幾天的歷史數(shù)據(jù)中推斷出次日的指標(biāo),或者從上周一的數(shù)據(jù)中推斷出下周一的訪問量是很自然的想法。通過預(yù)測未來 24 小時內(nèi)的指標(biāo)或流量模式,我們可以更好地管理我們的應(yīng)用程序?qū)嵗€(wěn)定我們的系統(tǒng),同時降低成本。EHPA 對象可以使用 DSP 算法來預(yù)測應(yīng)用未來的時間序列數(shù)據(jù),DSP 是一種預(yù)測時間序列的算法,它基于 FFT(快速傅里葉變換),擅長預(yù)測一些具有季節(jié)性和周期的時間序列。
創(chuàng)建一個如下所示的 EHPA 資源對象,并開啟預(yù)測功能:
# sample-app-ehpa.yaml
apiVersion: autoscaling.crane.io/v1alpha1
kind: EffectiveHorizontalPodAutoscaler
metadata:
name: sample-app-ehpa
annotations:
# metric-query.autoscaling.crane.io 是固定的前綴,后面是 前綴.Metric名字,需跟 spec.metrics 中的 Metric.name 相同,前綴支持 pods、resource、external
metric-query.autoscaling.crane.io/pods.http_requests: "sum(rate(http_requests_total[5m])) by (pod)"
spec:
# ScaleTargetRef 是對需要縮放的工作負載的引用
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: sample-app
# minReplicas 是可以縮小到的縮放目標(biāo)的最小副本數(shù)
minReplicas: 1
# maxReplicas 是可以擴大到的縮放目標(biāo)的最大副本數(shù)
maxReplicas: 10
# scaleStrategy 表示縮放目標(biāo)的策略,值可以是 Auto 或 Manual
scaleStrategy: Auto
# metrics 包含用于計算所需副本數(shù)的規(guī)范。
metrics:
# 在使用預(yù)測算法預(yù)測時,你可能會擔(dān)心預(yù)測數(shù)據(jù)不準帶來一定的風(fēng)險,EHPA 在計算副本數(shù)時,不僅會按預(yù)測數(shù)據(jù)計算,同時也會考慮實際監(jiān)控數(shù)據(jù)來兜底,提升彈性的安全性,所以可以定義下面的 Resource 監(jiān)控數(shù)據(jù)來兜底
# - type: Resource
- type: Pods
pods:
metric:
name: http_requests
target:
type: AverageValue
averageValue: 500m # 當(dāng)出現(xiàn)了小數(shù)點,K8s 又需要高精度時,會使用單位 m 或k。例如1001m=1.001,1k=1000。
# prediction 定義了預(yù)測資源的配置,如果未指定,則默認不啟用預(yù)測功能
prediction:
predictionWindowSeconds: 3600 # PredictionWindowSeconds 是預(yù)測未來指標(biāo)的時間窗口
predictionAlgorithm:
algorithmType: dsp # 指定dsp為預(yù)測算法
dsp:
sampleInterval: "60s" # 監(jiān)控數(shù)據(jù)的采樣間隔為1分鐘
historyLength: "7d" # 拉取過去7天的監(jiān)控指標(biāo)作為預(yù)測的依據(jù)
在上面的資源對象中添加了一個 metric-query.autoscaling.crane.io/pods.http_requests: "sum(rate(http_requests_total[5m])) by (pod)" 的 注解,這樣就可以開啟自定義指標(biāo)的預(yù)測功能了。
相應(yīng)的在規(guī)范中定義了 spec.prediction 屬性,用來指定預(yù)測資源的配置,其中的 predictionWindowSeconds 屬性用來指定預(yù)測未來指標(biāo)的時間窗口,predictionAlgorithm 屬性用來指定預(yù)測的算法,比如我們這里配置的 algorithmType: dsp 表示使用 DSP(Digital Signal Processing)算法進行預(yù)測,該算法使用在數(shù)字信號處理領(lǐng)域中常用的的離散傅里葉變換、自相關(guān)函數(shù)等手段來識別、預(yù)測周期性的時間序列,關(guān)于該算法的實現(xiàn)原理可以查看官方文檔 https://gocrane.io/zh-cn/docs/tutorials/timeseriees-forecasting-by-dsp/ 的相關(guān)介紹,或者查看源碼以了解背后原理,相關(guān)代碼位于 pkg/prediction/dsp 目錄下。此外在 prediction.predictionAlgorithm.dsp 下面還可以配置 dsp 算法的相關(guān)參數(shù),比如我們這里配置的 sampleInterval: "60s" 表示監(jiān)控數(shù)據(jù)的采樣間隔為 1 分鐘,historyLength: "7d" 表示拉取過去 7 天的監(jiān)控指標(biāo)作為預(yù)測的依據(jù),此外還可以配置預(yù)測方式等。
然后核心的配置就是 spec.metrics 了,用來指定計算所需副本數(shù)的規(guī)范,我們這里指定了基于 Pods 指標(biāo)的計算方式。
- type: Pods
pods:
metric:
name: http_requests
target:
type: AverageValue
averageValue: 500m
上面的配置表示當(dāng) pods/http_requests 的自定義指標(biāo)平均值達到 500m 后就可以觸發(fā) HPA 縮放,這里有一個點需要注意自定義指標(biāo)的 pods.metric.name 的值必須和 annotations 注解 metric-query.autoscaling.crane.io/pods.<metric name> 指標(biāo)名保持一致。
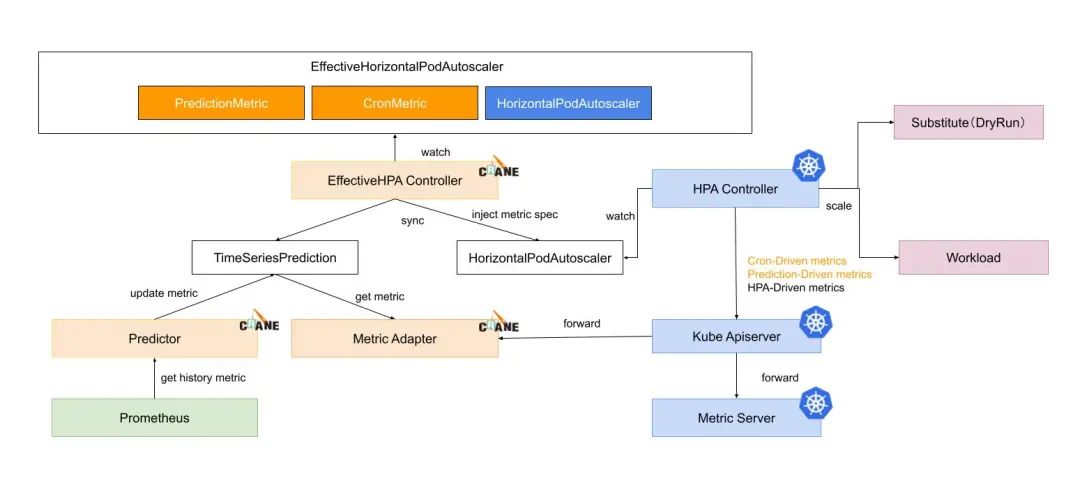
EHPA 對象水平彈性的執(zhí)行流程如下所示:
EffectiveHPAController創(chuàng)建HorizontalPodAutoscaler和TimeSeriesPrediction對象PredictionCore從 Prometheus 獲取歷史 metric 通過預(yù)測算法計算,將結(jié)果記錄到TimeSeriesPredictionHPAController通過 metric client 從 KubeApiServer 讀取 metric 數(shù)據(jù)KubeApiServer將請求路由到 Crane 的 Metric-Adapter。HPAController計算所有的 Metric 返回的結(jié)果得到最終的彈性副本推薦。HPAController調(diào)用 scale API 對目標(biāo)應(yīng)用擴/縮容。
整體流程如下所示:
直接應(yīng)用上面的 EPHA 對象即可:
$ kubectl apply -f sample-app-ehpa.yaml
effectivehorizontalpodautoscaler.autoscaling.crane.io/sample-app-ehpa created
$ kubectl get ehpa
NAME STRATEGY MINPODS MAXPODS SPECIFICPODS REPLICAS AGE
sample-app-ehpa Auto 1 10 1 17s
由于我們開啟了自動預(yù)測功能,所以 EPHA 對象創(chuàng)建后會創(chuàng)建一個對應(yīng)的 TimeSeriesPrediction 對象:
$ kubectl get tsp
NAME TARGETREFNAME TARGETREFKIND PREDICTIONWINDOWSECONDS AGE
ehpa-sample-app-ehpa sample-app Deployment 3600 3m50s
$ kubectl get tsp ehpa-sample-app-ehpa -oyaml
apiVersion: prediction.crane.io/v1alpha1
kind: TimeSeriesPrediction
metadata:
name: ehpa-sample-app-ehpa
namespace: default
spec:
predictionMetrics:
- algorithm:
algorithmType: dsp
dsp:
estimators: {}
historyLength: 7d
sampleInterval: 60s
expressionQuery:
expression: sum(http_requests{})
resourceIdentifier: pods.http_requests
type: ExpressionQuery
predictionWindowSeconds: 3600
targetRef:
apiVersion: apps/v1
kind: Deployment
name: sample-app
namespace: default
status:
conditions:
- lastTransitionTime: "2022-10-27T13:01:14Z"
message: not all metric predicted
reason: PredictPartial
status: "False"
type: Ready
predictionMetrics:
- ready: false
resourceIdentifier: pods.http_requests
在 status 中可以看到包含 not all metric predicted 這樣的信息,這是因為應(yīng)用運行時間較短,可能會出現(xiàn)無法預(yù)測的情況。同樣也會自動創(chuàng)建一個對應(yīng)的 HPA 對象:
$ kubectl get hpa
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
ehpa-sample-app-ehpa Deployment/sample-app 16m/500m 1 10 1 69m
然后我們可以使用 ab 命令對 sample-app 做一次壓力測試,正常也可以觸發(fā)該應(yīng)用的彈性擴容。
$ kubectl get svc sample-app
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
sample-app NodePort 10.104.163.144 <none> 80:31941/TCP 3h59m
# 對 nodeport 服務(wù)做壓力測試
$ ab -c 50 -n 2000 http://192.168.0.106:31941/
$ kubectl get hpa
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
ehpa-sample-app-ehpa Deployment/sample-app 7291m/500m 1 10 10 71m
$ kubectl describe hpa ehpa-sample-app-ehpa
Name: ehpa-sample-app-ehpa
# ......
Metrics: ( current / target )
"http_requests" on pods: 8350m / 500m
Min replicas: 1
Max replicas: 10
Deployment pods: 10 current / 10 desired
Conditions:
Type Status Reason Message
---- ------ ------ -------
AbleToScale True ReadyForNewScale recommended size matches current size
ScalingActive True ValidMetricFound the HPA was able to successfully calculate a replica count from pods metric http_requests
ScalingLimited True TooManyReplicas the desired replica count is more than the maximum replica count
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal SuccessfulRescale 57s horizontal-pod-autoscaler New size: 4; reason: pods metric http_requests above target
Normal SuccessfulRescale 42s horizontal-pod-autoscaler New size: 8; reason: pods metric http_requests above target
Normal SuccessfulRescale 27s horizontal-pod-autoscaler New size: 10; reason: pods metric http_requests above target
我們可以使用如下所示命令來查看 EHPA 自動生成的 HPA 對象的資源清單:
$ kubectl get hpa.v2beta2.autoscaling ehpa-sample-app-ehpa -oyaml
apiVersion: autoscaling/v2beta2
kind: HorizontalPodAutoscaler
metadata:
name: ehpa-sample-app-ehpa
namespace: default
spec:
maxReplicas: 10
metrics:
- pods:
metric:
name: http_requests
target:
averageValue: 500m
type: AverageValue
type: Pods
minReplicas: 1
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: sample-app
# ...... 省略其他部分
可以觀測到已經(jīng)創(chuàng)建出基于自定義指標(biāo)預(yù)測的 Metric: http_requests,由于生產(chǎn)環(huán)境的復(fù)雜性,基于多指標(biāo)的彈性(CPU/Memory/自定義指標(biāo))往往是生產(chǎn)應(yīng)用的常見選擇,因此 Effective HPA 通過預(yù)測算法覆蓋了多指標(biāo)的彈性,達到了幫助更多業(yè)務(wù)在生產(chǎn)環(huán)境落地水平彈性的成效。
除此之外 EHPA 對象還支持基于 cron 的自動縮放,除了基于監(jiān)控指標(biāo),有時節(jié)假日和工作日的工作負載流量存在差異,簡單的預(yù)測算法可能效果不佳。然后可以通過設(shè)置周末 cron 來支持更大數(shù)量的副本來彌補預(yù)測的不足。對于一些非 web 流量的應(yīng)用,比如一些應(yīng)用不需要在周末使用,可以把工作負載的副本數(shù)減少到 1,也可以配置 cron 來降低你的服務(wù)成本。
QOS 增強與混部
除了上面介紹的主要功能之外,crane 還具有很多 QoS 增強功能,QoS 相關(guān)能力保證了運行在 Kubernetes 上的 Pod 的穩(wěn)定性。crane 具有干擾檢測和主動回避能力,當(dāng)較高優(yōu)先級的 Pod 受到資源競爭的影響時,Disable Schedule、Throttle 以及 Evict 將應(yīng)用于低優(yōu)先級的 Pod,以保證節(jié)點整體的穩(wěn)定,目前已經(jīng)支持節(jié)點的 cpu/內(nèi)存 負載絕對值/百分比作為水位線,在發(fā)生干擾進行驅(qū)逐或壓制時,會進行精確計算,將負載降低到略低于水位線即停止操作,防止誤傷和過渡操作。
同時,crane 還支持自定義指標(biāo)適配整個干擾檢測框架,只需要完成排序定義等一些操作,即可復(fù)用包含精確操作在內(nèi)的干擾檢測和回避流程。
此外 crane 還具有預(yù)測算法增強的彈性資源超賣能力,將集群內(nèi)的空閑資源復(fù)用起來,同時結(jié)合 crane 的預(yù)測能力,更好地復(fù)用閑置資源,當(dāng)前已經(jīng)支持 cpu 和內(nèi)存的空閑資源回收。同時具有彈性資源限制功能,限制使用彈性資源的 workload 最大和最小資源使用量,避免對高優(yōu)業(yè)務(wù)的影響和饑餓問題。
同時具備增強的旁路 cpuset 管理能力,在綁核的同時提升資源利用效率。
總結(jié)
2022 年,騰訊云原生 FinOps Crane 項目組,結(jié)合行業(yè)及產(chǎn)業(yè)的發(fā)展趨勢,聯(lián)動中國產(chǎn)業(yè)互聯(lián)網(wǎng)發(fā)展聯(lián)盟、中國信通院、中國電子節(jié)能技術(shù)協(xié)會、FinOps 基金會及中國內(nèi)外眾多生態(tài)合作伙伴,開展及推動技術(shù)標(biāo)準、國內(nèi)聯(lián)盟、國際開源、雙碳升級等多維度的成果落地,輸出了系列白皮書和標(biāo)準指南,旨在助力企業(yè)和生態(tài)更良性發(fā)展和應(yīng)用先進技術(shù),達成降本增效,節(jié)能減排目標(biāo)方向。
我們可以自己在 K8s 集群中安裝 crane 來獲取這些相關(guān)功能,此外這些能力也都會在騰訊云 TKE 的原生節(jié)點產(chǎn)品 Housekeeper 中提供,新推出的 TKE Housekeeper 是騰訊云推出的全新 K8s 運維范式,可以幫助企業(yè)像管理 Workload 一樣聲明式管理 Node 節(jié)點,高效解決節(jié)點維護、資源規(guī)劃等各種各樣的運維問題。
毫無疑問,Crane 已經(jīng)是 K8s 集群中用于云資源分析和經(jīng)濟的最佳 FinOps 平臺了。目前,騰訊云 Crane 已進入 CNCF LandScape,這意味著 Crane 已成為云原生領(lǐng)域的重要項目。面向未來,騰訊云還將持續(xù)反饋開源社區(qū)、共建開源生態(tài),幫助更多企業(yè)通過云原生全面釋放生產(chǎn)力,加速實現(xiàn)數(shù)字化和綠色化雙轉(zhuǎn)型。
最后,上周末舉行的騰訊云 Techo Day 技術(shù)開放日活動也對 Crane 進行了深入解析,相關(guān)資料及課件被收錄進了《騰訊云云原生工具指南》里,除此以外,里面還涵蓋了遨馳分布式云操作系統(tǒng)、微服務(wù)等多款熱門產(chǎn)品的技術(shù)原理解讀,幫助開發(fā)者用專業(yè)方法解決業(yè)務(wù)痛點,還有多個云原生實踐標(biāo)桿案例分享,講述云原生如何實現(xiàn)價值,非常推薦給感興趣的朋友下載看看。

▲ 點擊上方卡片關(guān)注Github愛好者,獲取前沿開源作品