別再問(wèn)如何用Python提取PDF內(nèi)容了!


導(dǎo)讀
大家好,在之前的辦公自動(dòng)化系列文章中我們已經(jīng)詳細(xì)介紹了?如何使用Python批量處理PDF文件,包括合并、拆分、水印、加密等操作。
今天我們?cè)俅位氐絇DF,詳細(xì)講解如何使用Python從PDF提取指定的信息。我們將以一份年度報(bào)告PDF為例進(jìn)行介紹,內(nèi)含大量文字、表格、圖片,具體如下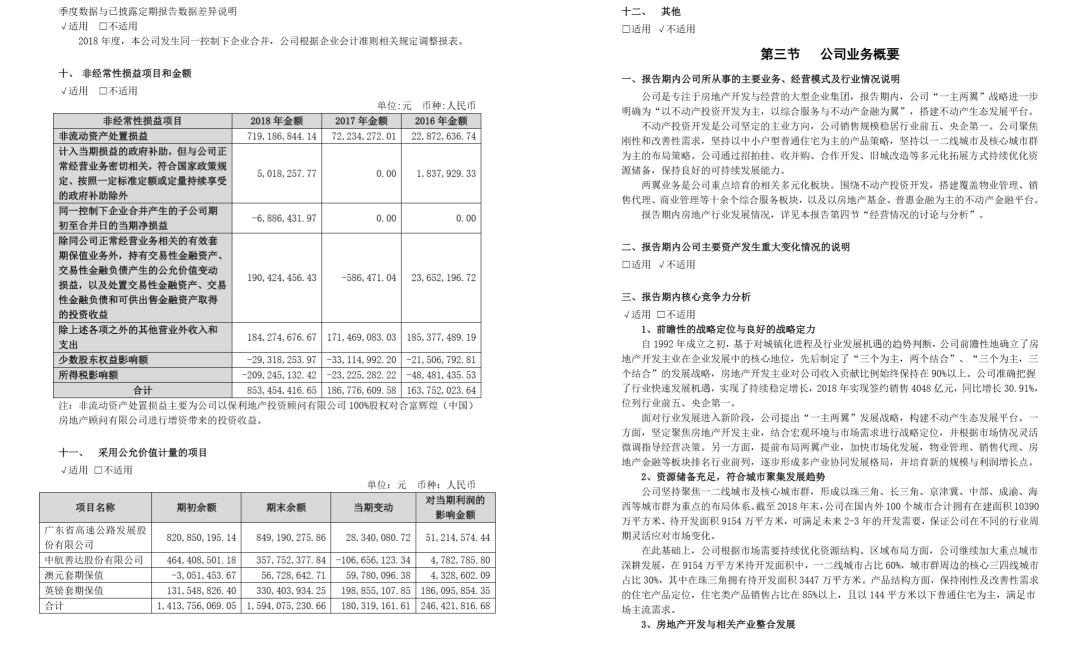
模塊安裝
首先需要安裝兩個(gè)模塊,第一個(gè)是pdfplumber,在命令行使用pip安裝即可?
pip?install?pdfplumber
第二個(gè)是fitz, 它是pymupdf中的一個(gè)模塊,同樣可以使用pip輕松安裝
pip?install?pymupdf
文字信息提取
使用Python提取PDF中文字代碼思路如下
利用 pdfplumber打開一個(gè) PDF 文件獲取指定的頁(yè),或者遍歷每一頁(yè) 利用 .extract_text()方法提取當(dāng)前頁(yè)的文字
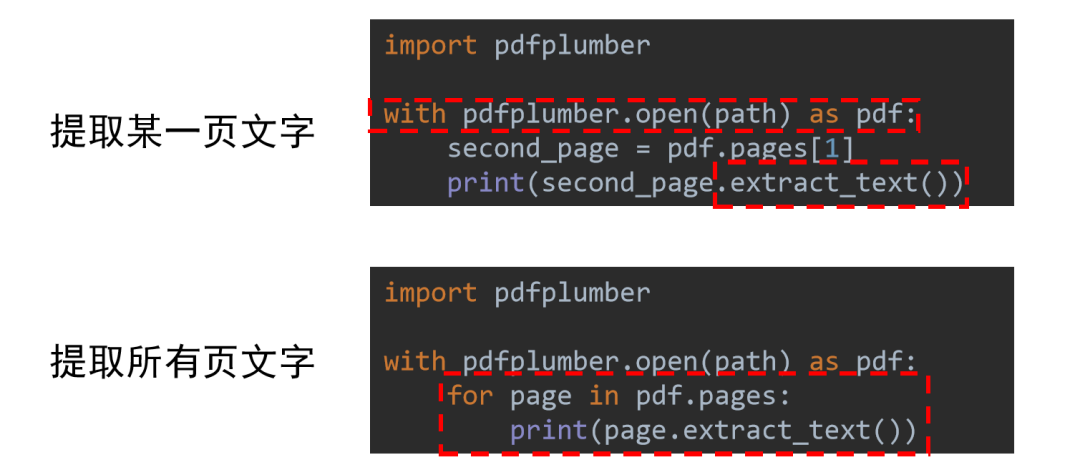 現(xiàn)在讓我們用上述代碼嘗試提取示例數(shù)據(jù)中第12頁(yè)的文字?
現(xiàn)在讓我們用上述代碼嘗試提取示例數(shù)據(jù)中第12頁(yè)的文字?
import?pdfplumber
file_path?=?r'C:\xxxx\practice.PDF'
with?pdfplumber.open(file_path)?as?pdf:
????page?=?pdf.pages[11]
????print(page.extract_text())
結(jié)果如下圖所示 接著可以將內(nèi)容通過(guò)導(dǎo)入
接著可以將內(nèi)容通過(guò)導(dǎo)入python-docx并借助wordfile.add_paragraph()寫入Word文件中,而這個(gè)模塊我們已經(jīng)講解很多次,此處就不再贅述。
表格信息提取
使用Python提取單個(gè)表格和提取單頁(yè)文字的代碼非常類似,用的是.extract_table()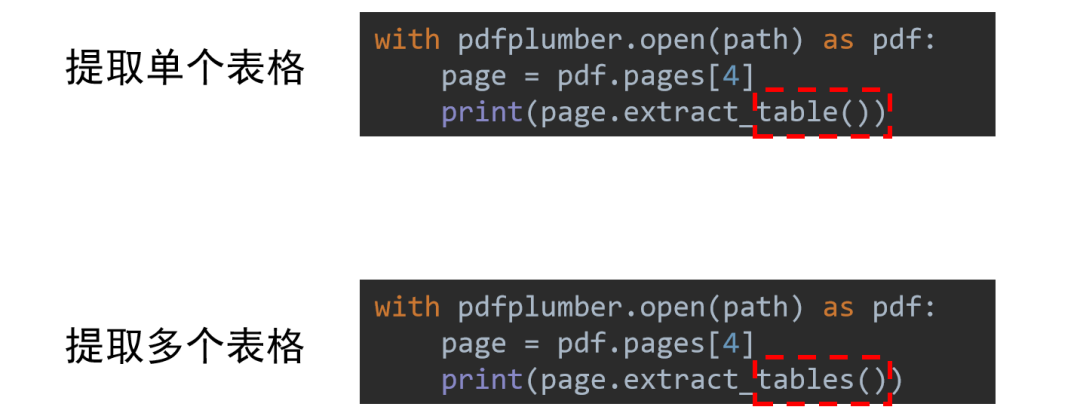 但需要注意的是
但需要注意的是.extract_table()默認(rèn)提取指定頁(yè)面的第一個(gè)表格,如果當(dāng)前頁(yè)面有多個(gè)表格都需要提取,則要直接使用.extract_tables()
例如示例文件中第 13 頁(yè)有 2 個(gè)表格,我們分別利用.extract_table()和.extract_tables()觀察輸出結(jié)果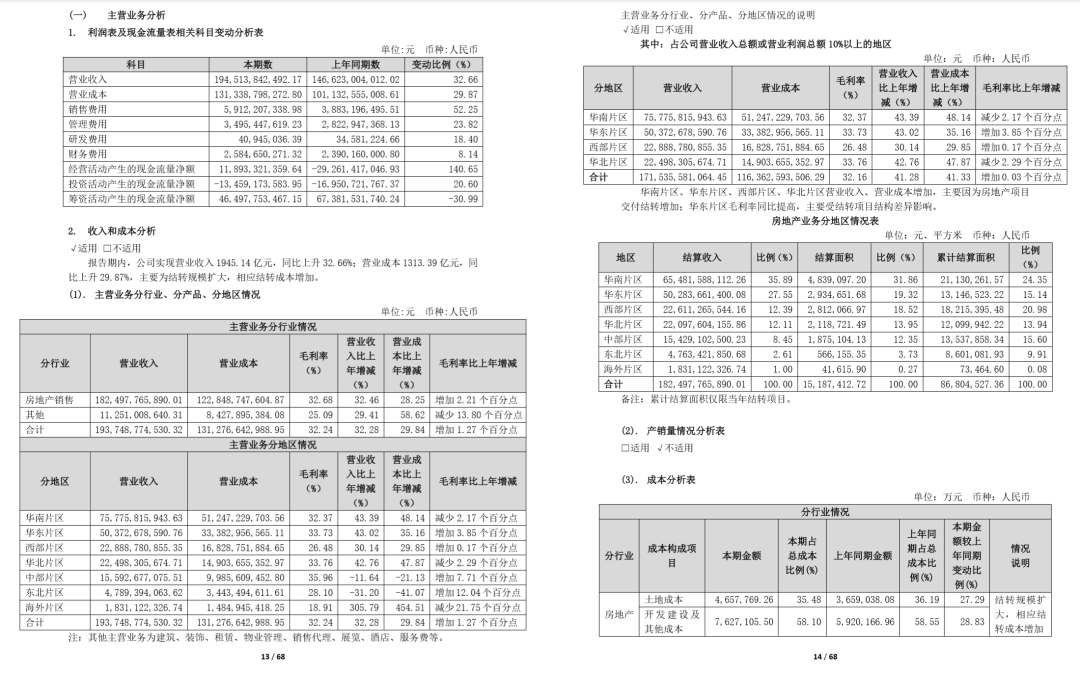
import?pdfplumber
file_path?=?r'C:\xxxx\practice.PDF'
with?pdfplumber.open(file_path)?as?pdf:
????page?=?pdf.pages[12]
????print(page.extract_table())
結(jié)果如下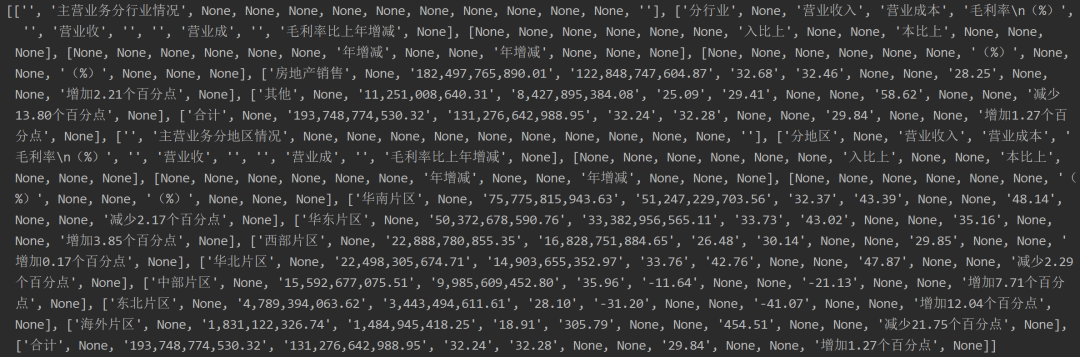 可以看到是一個(gè)嵌套列表,熟悉這種格式的人會(huì)理解想到可以
可以看到是一個(gè)嵌套列表,熟悉這種格式的人會(huì)理解想到可以pandas或者遍歷該嵌套列表后借助openpyxl的sheet.append(list)寫入Excel文件中,
import?pdfplumber
file_path?=?r'C:\xxxx\practice.PDF'
with?pdfplumber.open(file_path)?as?pdf:
????page?=?pdf.pages[12]
????print(page.extract_tables())
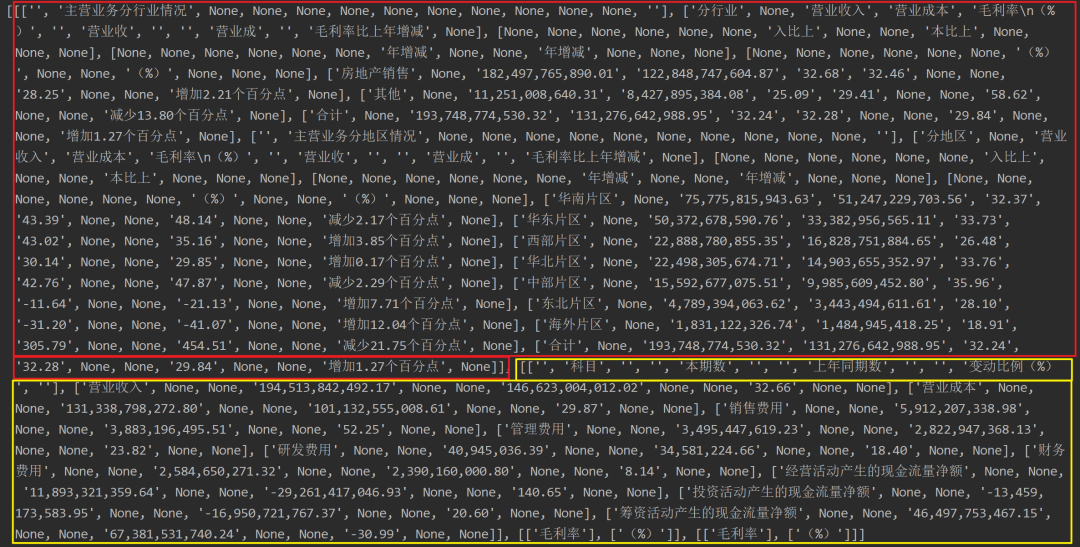 而
而.extract_tables()提取當(dāng)前頁(yè)所有表格會(huì)產(chǎn)生了一個(gè)三級(jí)嵌套列表,第一層的列表就代表每一個(gè)表格,之后也可以利用其他庫(kù)寫入Excel。
圖片提取
對(duì)于圖片提取,現(xiàn)在沒(méi)有任何一個(gè)模塊可以做到百分之百的提取。本文只介紹基于fitz模塊的代碼,基本思路是通過(guò)正則查找圖片并將其輸出
例如提取示例文件中的圖片,代碼可以這么寫?
import?fitz
import?re
import?os
file_path?=?r'C:\xxx\practice.PDF'
dir_path?=?r'C:\xxx'?#?存放圖片的文件夾
def?pdf2pic(path,?pic_path):
????checkXO?=?r"/Type(?=?*/XObject)"
????checkIM?=?r"/Subtype(?=?*/Image)"
????pdf?=?fitz.open(path)
????lenXREF?=?pdf._getXrefLength()
????imgcount?=?0
????for?i?in?range(1,?lenXREF):
????????text?=?pdf._getXrefString(i)
????????isXObject?=?re.search(checkXO,?text)
????????isImage?=?re.search(checkIM,?text)
????????if?not?isXObject?or?not?isImage:
????????????continue
????????imgcount?+=?1
????????pix?=?fitz.Pixmap(pdf,?i)
????????new_name?=?f"img_{imgcount}.png"
????????if?pix.n?5:
????????????pix.writePNG(os.path.join(pic_path,?new_name))
????????else:
????????????pix0?=?fitz.Pixmap(fitz.csRGB,?pix)
????????????pix0.writePNG(os.path.join(pic_path,?new_name))
????????????pix0?=?None
????????pix?=?None
pdf2pic(file_path,?dir_path)
結(jié)果如下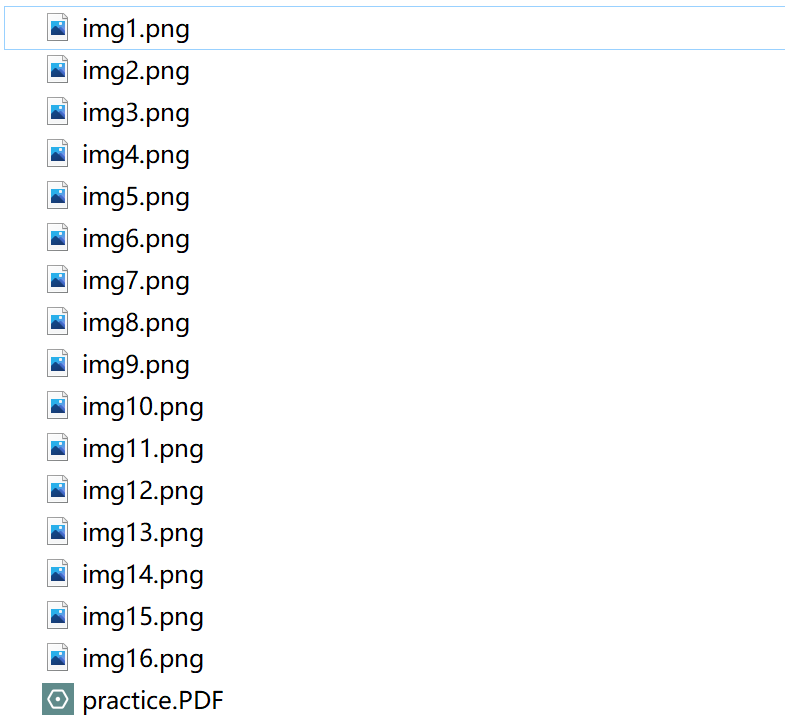 可以看到成功提取了圖片,但PDF中的圖片遠(yuǎn)不止這些,如果你有其他思路或者方法可以在留言區(qū)與我交流。
可以看到成功提取了圖片,但PDF中的圖片遠(yuǎn)不止這些,如果你有其他思路或者方法可以在留言區(qū)與我交流。
寫在最后
最后要說(shuō)明的是,在上一篇文章及本文中我們剖析了每一行代碼。但針對(duì)PDF的模塊較多,且有些模塊功能并不完善,代碼也沒(méi)有類似OFFICE三件套操作那般簡(jiǎn)潔,因此更多時(shí)候以理解為主,不需要完全掌握寫,會(huì)用會(huì)改即可!
當(dāng)然還是希望大家能夠理解Python辦公自動(dòng)化的一個(gè)核心就是批量操作-解放雙手,并且能與日常辦公結(jié)合讓復(fù)雜的工作自動(dòng)化!
今天的文章就到這里,原創(chuàng)不易,如果喜歡的話請(qǐng)給我一波三連支持吧(在看、轉(zhuǎn)發(fā)、留言)
-END-
本文為公眾號(hào)早起Python專欄作者陳熹原創(chuàng),轉(zhuǎn)載請(qǐng)后臺(tái)聯(lián)系,未經(jīng)授權(quán)的任何形式轉(zhuǎn)載均視為侵權(quán)!