
MySQL八股文背誦版
這篇文章是一篇高質(zhì)量的MySQL面試相關(guān)文章,文章長一萬五千字左右,很多同學(xué)和我說這是他看到過的總結(jié)的最好的MySQL面經(jīng),題目后面的(*)表示面試中出現(xiàn)的頻率。PDF版在公眾號回復(fù)"面試手冊"即可。
推薦閱讀:
文章目錄:
什么是MySQL? *
MySQL常用的存儲引擎有什么?它們有什么區(qū)別? ***
數(shù)據(jù)庫的三大范式 **
MySQL的數(shù)據(jù)類型有哪些 **
索引 ***
什么是索引?
索引的優(yōu)缺點?
索引的數(shù)據(jù)結(jié)構(gòu)?
Hash索引和B+樹的區(qū)別?
索引的類型有哪些?
索引的種類有哪些?
B樹和B+樹的區(qū)別?
數(shù)據(jù)庫為什么使用B+樹而不是B樹?
什么是聚簇索引,什么是非聚簇索引?
非聚簇索引一定會進行回表查詢嗎?
索引的使用場景有哪些?
索引的設(shè)計原則?
如何對索引進行優(yōu)化?
如何創(chuàng)建/刪除索引?
使用索引查詢時性能一定會提升嗎?
什么是前綴索引?
什么是最左匹配原則?
索引在什么情況下會失效?
數(shù)據(jù)庫的事務(wù) ***
什么是數(shù)據(jù)庫的事務(wù)?
事務(wù)的四大特性是什么?
數(shù)據(jù)庫的并發(fā)一致性問題
數(shù)據(jù)庫的隔離級別有哪些?
隔離級別是如何實現(xiàn)的?
什么是MVCC?
數(shù)據(jù)庫的鎖 ***
什么是數(shù)據(jù)庫的鎖?
數(shù)據(jù)庫的鎖與隔離級別的關(guān)系?
數(shù)據(jù)庫鎖的類型有哪些?
MySQL中InnoDB引擎的行鎖模式及其是如何實現(xiàn)的?
什么是數(shù)據(jù)庫的樂觀鎖和悲觀鎖,如何實現(xiàn)?
什么是死鎖?如何避免?
SQL語句基礎(chǔ)知識
SQL語句主要分為哪幾類 *
SQL約束有哪些? **
什么是子查詢? **
了解MySQL的幾種連接查詢嗎? ***
mysql中in和exists的區(qū)別? **
varchar和char的區(qū)別? ***
MySQL中int(10)和char(10)和varchar(10)的區(qū)別? ***
drop、delete和truncate的區(qū)別? **
UNION和UNION ALL的區(qū)別? **
什么是臨時表,什么時候會使用到臨時表,什么時候刪除臨時表? *
大表數(shù)據(jù)查詢?nèi)绾芜M行優(yōu)化? ***
了解慢日志查詢嗎?統(tǒng)計過慢查詢嗎?對慢查詢?nèi)绾蝺?yōu)化? ***
為什么要設(shè)置主鍵? **
主鍵一般用自增ID還是UUID? **
字段為什么要設(shè)置成not null? **
如何優(yōu)化查詢過程中的數(shù)據(jù)訪問? ***
如何優(yōu)化長難的查詢語句? **
如何優(yōu)化LIMIT分頁? **
如何優(yōu)化UNION查詢 **
如何優(yōu)化WHERE子句 ***
SQL語句執(zhí)行的很慢原因是什么? ***
SQL語句的執(zhí)行順序? *
數(shù)據(jù)庫優(yōu)化
大表如何優(yōu)化? ***
什么是垂直分表、垂直分庫、水平分表、水平分庫? ***
分庫分表后,ID鍵如何處理? ***
MySQL的復(fù)制原理及流程?如何實現(xiàn)主從復(fù)制? ***
了解讀寫分離嗎? ***
什么是MySQL? *
百度百科上的解釋:MySQL是一種開放源代碼的關(guān)系型數(shù)據(jù)庫管理系統(tǒng)(RDBMS),使用最常用的數(shù)據(jù)庫管理語言--結(jié)構(gòu)化查詢語言(SQL)進行數(shù)據(jù)庫管理。MySQL是開放源代碼的,因此任何人都可以在General Public License的許可下下載并根據(jù)個性化的需要對其進行修改。
MySQL常用的存儲引擎有什么?它們有什么區(qū)別? ***
-
InnoDB
InnoDB是MySQL的默認存儲引擎,支持事務(wù)、行鎖和外鍵等操作。
-
MyISAM
MyISAM是MySQL5.1版本前的默認存儲引擎,MyISAM的并發(fā)性比較差,不支持事務(wù)和外鍵等操作,默認的鎖的粒度為表級鎖。
| InnoDB | MyISAM | |
|---|---|---|
| 外鍵 | 支持 | 不支持 |
| 事務(wù) | 支持 | 不支持 |
| 鎖 | 支持表鎖和行鎖 | 支持表鎖 |
| 可恢復(fù)性 | 根據(jù)事務(wù)日志進行恢復(fù) | 無事務(wù)日志 |
| 表結(jié)構(gòu) | 數(shù)據(jù)和索引是集中存儲的,.ibd和.frm | 數(shù)據(jù)和索引是分開存儲的,數(shù)據(jù).MYD,索引.MYI |
| 查詢性能 | 一般情況相比于MyISAM較差 | 一般情況相比于InnoDB較差 |
| 索引 | 聚簇索引 | 非聚簇索引 |
數(shù)據(jù)庫的三大范式 **
-
第一范式:確保每列保持原子性,數(shù)據(jù)表中的所有字段值都是不可分解的原子值。 -
第二范式:確保表中的每列都和主鍵相關(guān) -
第三范式:確保每列都和主鍵列直接相關(guān)而不是間接相關(guān)
MySQL的數(shù)據(jù)類型有哪些 **
-
整數(shù)
TINYINT、SMALLINT、MEDIUMINT、INT、BIGINT分別占用8、16、24、32、64位存儲空間。值得注意的是,INT(10)中的10只是表示顯示字符的個數(shù),并無實際意義。一般和UNSIGNED ZEROFILL配合使用才有實際意義,例如,數(shù)據(jù)類型INT(3),屬性為UNSIGNED ZEROFILL,如果插入的數(shù)據(jù)為3的話,實際存儲的數(shù)據(jù)為003。
-
浮點數(shù)
FLOAT、DOUBLE及DECIMAL為浮點數(shù)類型,DECIMAL是利用字符串進行處理的,能存儲精確的小數(shù)。相比于FLOAT和DOUBLE,DECIMAL的效率更低些。FLOAT、DOUBLE及DECIMAL都可以指定列寬,例如FLOAT(5,2)表示一共5位,兩位存儲小數(shù)部分,三位存儲整數(shù)部分。
-
字符串
字符串常用的主要有CHAR和VARCHAR,VARCHAR主要用于存儲可變長字符串,相比于定長的CHAR更節(jié)省空間。CHAR是定長的,根據(jù)定義的字符串長度分配空間。
應(yīng)用場景:對于經(jīng)常變更的數(shù)據(jù)使用CHAR更好,CHAR不容易產(chǎn)生碎片。對于非常短的列也是使用CHAR更好些,CHAR相比于VARCHAR在效率上更高些。一般避免使用TEXT/BLOB等類型,因為查詢時會使用臨時表,造成嚴重的性能開銷。
-
日期
比較常用的有year、time、date、datetime、timestamp等,datetime保存從1000年到9999年的時間,精度到秒,使用8字節(jié)的存儲空間,與時區(qū)無關(guān)。timestamp和UNIX的時間戳相同,保存從1970年1月1日午夜到2038年的時間,精度到秒,使用四個字節(jié)的存儲空間,并且與時區(qū)相關(guān)。
應(yīng)用場景:盡量使用timestamp,相比于datetime它有著更高的空間效率。
索引 ***
什么是索引?
百度百科的解釋:索引是對數(shù)據(jù)庫表的一列或者多列的值進行排序一種結(jié)構(gòu),使用索引可以快速訪問數(shù)據(jù)表中的特定信息。
索引的優(yōu)缺點?
優(yōu)點:
-
大大加快數(shù)據(jù)檢索的速度。 -
將隨機I/O變成順序I/O(因為B+樹的葉子節(jié)點是連接在一起的) -
加速表與表之間的連接
缺點:
-
從空間角度考慮,建立索引需要占用物理空間 -
從時間角度 考慮,創(chuàng)建和維護索引都需要花費時間,例如對數(shù)據(jù)進行增刪改的時候都需要維護索引。
索引的數(shù)據(jù)結(jié)構(gòu)?
索引的數(shù)據(jù)結(jié)構(gòu)主要有B+樹和哈希表,對應(yīng)的索引分別為B+樹索引和哈希索引。InnoDB引擎的索引類型有B+樹索引和哈希索引,默認的索引類型為B+樹索引。
-
B+樹索引
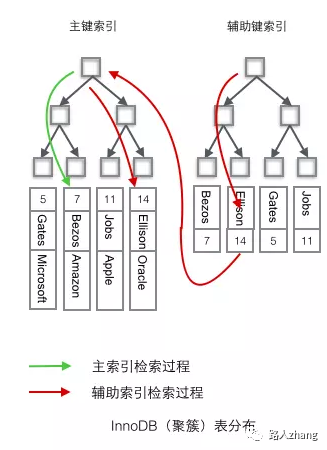
熟悉數(shù)據(jù)結(jié)構(gòu)的同學(xué)都知道,B+樹、平衡二叉樹、紅黑樹都是經(jīng)典的數(shù)據(jù)結(jié)構(gòu)。在B+樹中,所有的記錄節(jié)點都是按照鍵值大小的順序放在葉子節(jié)點上,如下圖。
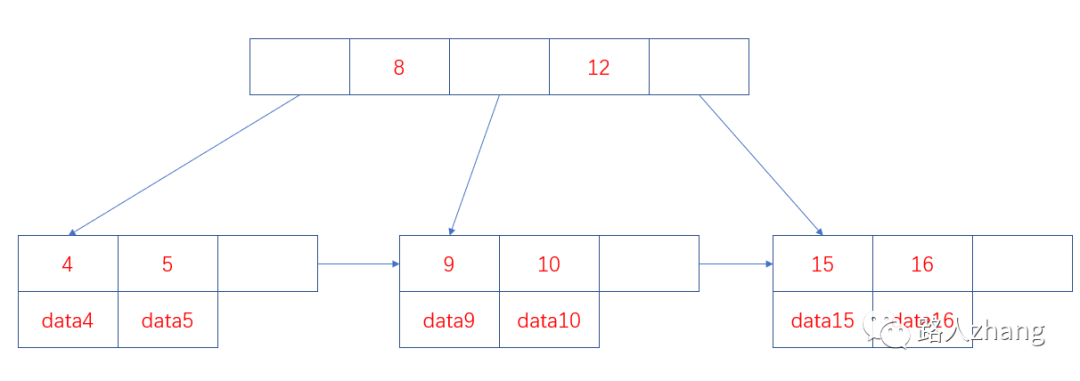
從上圖可以看出 ,因為B+樹具有有序性,并且所有的數(shù)據(jù)都存放在葉子節(jié)點,所以查找的效率非常高,并且支持排序和范圍查找。
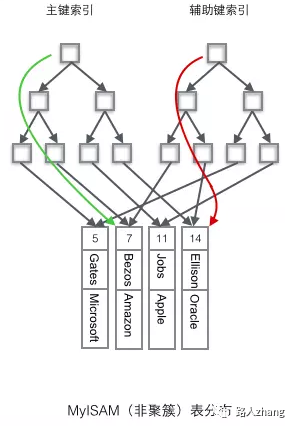
B+樹的索引又可以分為主索引和輔助索引。其中主索引為聚簇索引,輔助索引為非聚簇索引。聚簇索引是以主鍵作為B+ 樹索引的鍵值所構(gòu)成的B+樹索引,聚簇索引的葉子節(jié)點存儲著完整的數(shù)據(jù)記錄;非聚簇索引是以非主鍵的列作為B+樹索引的鍵值所構(gòu)成的B+樹索引,非聚簇索引的葉子節(jié)點存儲著主鍵值。所以使用非聚簇索引進行查詢時,會先找到主鍵值,然后到根據(jù)聚簇索引找到主鍵對應(yīng)的數(shù)據(jù)域。上圖中葉子節(jié)點存儲的是數(shù)據(jù)記錄,為聚簇索引的結(jié)構(gòu)圖,非聚簇索引的結(jié)構(gòu)圖如下:
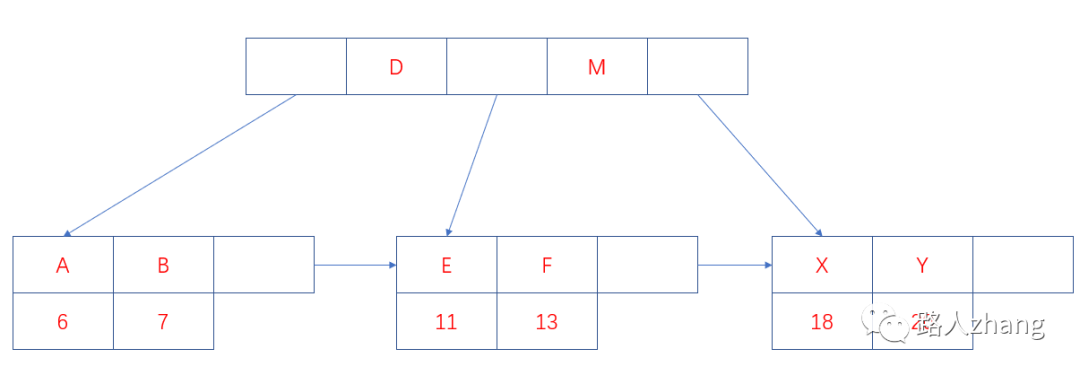
上圖中的字母為數(shù)據(jù)的非主鍵的列值,假設(shè)要查詢該列值為B的信息,則需先找到主鍵7,在到聚簇索引中查詢主鍵7所對應(yīng)的數(shù)據(jù)域。
-
哈希索引
哈希索引是基于哈希表實現(xiàn)的,對于每一行數(shù)據(jù),存儲引擎會對索引列通過哈希算法進行哈希計算得到哈希碼,并且哈希算法要盡量保證不同的列值計算出的哈希碼值是不同的,將哈希碼的值作為哈希表的key值,將指向數(shù)據(jù)行的指針作為哈希表的value值。這樣查找一個數(shù)據(jù)的時間復(fù)雜度就是o(1),一般多用于精確查找。
Hash索引和B+樹的區(qū)別?
因為兩者數(shù)據(jù)結(jié)構(gòu)上的差異導(dǎo)致它們的使用場景也不同,哈希索引一般多用于精確的等值查找,B+索引則多用于除了精確的等值查找外的其他查找。在大多數(shù)情況下,會選擇使用B+樹索引。
-
哈希索引不支持排序,因為哈希表是無序的。 -
哈希索引不支持范圍查找。 -
哈希索引不支持模糊查詢及多列索引的最左前綴匹配。 -
因為哈希表中會存在哈希沖突,所以哈希索引的性能是不穩(wěn)定的,而B+樹索引的性能是相對穩(wěn)定的,每次查詢都是從根節(jié)點到葉子節(jié)點
索引的類型有哪些?
MySQL主要的索引類型主要有FULLTEXT,HASH,BTREE,RTREE。
-
FULLTEXT
FULLTEXT即全文索引,MyISAM存儲引擎和InnoDB存儲引擎在MySQL5.6.4以上版本支持全文索引,一般用于查找文本中的關(guān)鍵字,而不是直接比較是否相等,多在CHAR,VARCHAR,TAXT等數(shù)據(jù)類型上創(chuàng)建全文索引。全文索引主要是用來解決WHERE name LIKE "%zhang%"等針對文本的模糊查詢效率低的問題。
-
HASH
HASH即哈希索引,哈希索引多用于等值查詢,時間復(fù)雜夫為o(1),效率非常高,但不支持排序、范圍查詢及模糊查詢等。
-
BTREE
BTREE即B+樹索引,INnoDB存儲引擎默認的索引,支持排序、分組、范圍查詢、模糊查詢等,并且性能穩(wěn)定。
-
RTREE
RTREE即空間數(shù)據(jù)索引,多用于地理數(shù)據(jù)的存儲,相比于其他索引,空間數(shù)據(jù)索引的優(yōu)勢在于范圍查找
索引的種類有哪些?
-
主鍵索引:數(shù)據(jù)列不允許重復(fù),不能為NULL,一個表只能有一個主鍵索引 -
組合索引:由多個列值組成的索引。 -
唯一索引:數(shù)據(jù)列不允許重復(fù),可以為NULL,索引列的值必須唯一的,如果是組合索引,則列值的組合必須唯一。 -
全文索引:對文本的內(nèi)容進行搜索。 -
普通索引:基本的索引類型,可以為NULL
B樹和B+樹的區(qū)別?
B樹和B+樹最主要的區(qū)別主要有兩點:
-
B樹中的內(nèi)部節(jié)點和葉子節(jié)點均存放鍵和值,而B+樹的內(nèi)部節(jié)點只有鍵沒有值,葉子節(jié)點存放所有的鍵和值。
-
B+樹的葉子節(jié)點是通過相連在一起的,方便順序檢索。
兩者的結(jié)構(gòu)圖如下。
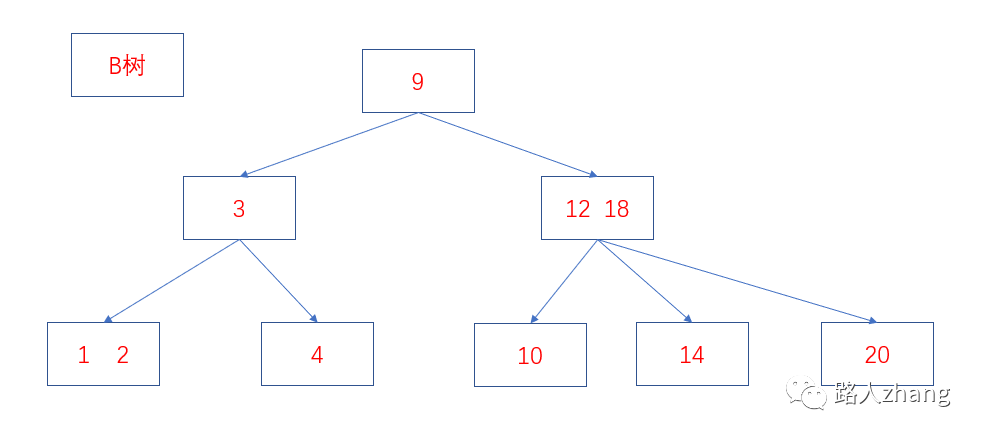
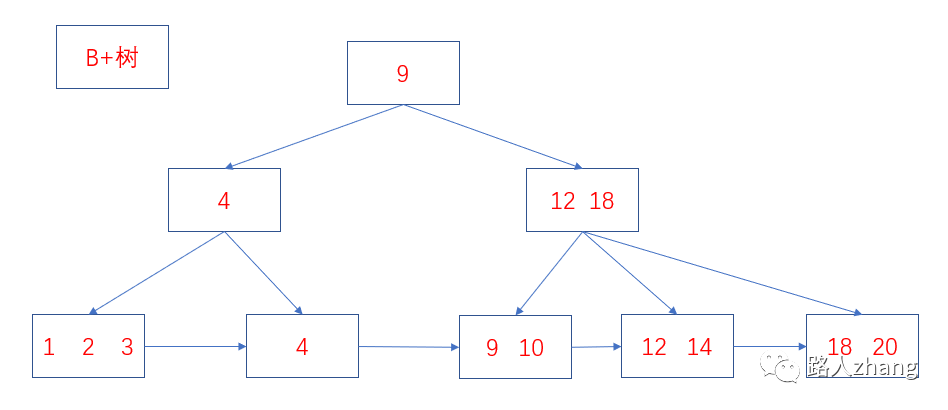
數(shù)據(jù)庫為什么使用B+樹而不是B樹?
-
B樹適用于隨機檢索,而B+樹適用于隨機檢索和順序檢索 -
B+樹的空間利用率更高,因為B樹每個節(jié)點要存儲鍵和值,而B+樹的內(nèi)部節(jié)點只存儲鍵,這樣B+樹的一個節(jié)點就可以存儲更多的索引,從而使樹的高度變低,減少了I/O次數(shù),使得數(shù)據(jù)檢索速度更快。 -
B+樹的葉子節(jié)點都是連接在一起的,所以范圍查找,順序查找更加方便 -
B+樹的性能更加穩(wěn)定,因為在B+樹中,每次查詢都是從根節(jié)點到葉子節(jié)點,而在B樹中,要查詢的值可能不在葉子節(jié)點,在內(nèi)部節(jié)點就已經(jīng)找到。
那在什么情況適合使用B樹呢,因為B樹的內(nèi)部節(jié)點也可以存儲值,所以可以把一些頻繁訪問的值放在距離根節(jié)點比較近的地方,這樣就可以提高查詢效率。綜上所述,B+樹的性能更加適合作為數(shù)據(jù)庫的索引。
什么是聚簇索引,什么是非聚簇索引?
聚簇索引和非聚簇索引最主要的區(qū)別是數(shù)據(jù)和索引是否分開存儲。
-
聚簇索引:將數(shù)據(jù)和索引放到一起存儲,索引結(jié)構(gòu)的葉子節(jié)點保留了數(shù)據(jù)行。 -
非聚簇索引:將數(shù)據(jù)進和索引分開存儲,索引葉子節(jié)點存儲的是指向數(shù)據(jù)行的地址。
在InnoDB存儲引擎中,默認的索引為B+樹索引,利用主鍵創(chuàng)建的索引為主索引,也是聚簇索引,在主索引之上創(chuàng)建的索引為輔助索引,也是非聚簇索引。為什么說輔助索引是在主索引之上創(chuàng)建的呢,因為輔助索引中的葉子節(jié)點存儲的是主鍵。
在MyISAM存儲引擎中,默認的索引也是B+樹索引,但主索引和輔助索引都是非聚簇索引,也就是說索引結(jié)構(gòu)的葉子節(jié)點存儲的都是一個指向數(shù)據(jù)行的地址。并且使用輔助索引檢索無需訪問主鍵的索引。
可以從非常經(jīng)典的兩張圖看看它們的區(qū)別(圖片來源于網(wǎng)絡(luò)):
非聚簇索引一定會進行回表查詢嗎?
上面是說了非聚簇索引的葉子節(jié)點存儲的是主鍵,也就是說要先通過非聚簇索引找到主鍵,再通過聚簇索引找到主鍵所對應(yīng)的數(shù)據(jù),后面這個再通過聚簇索引找到主鍵對應(yīng)的數(shù)據(jù)的過程就是回表查詢,那么非聚簇索引就一定會進行回表查詢嗎?
答案是不一定的,這里涉及到一個索引覆蓋的問題,如果查詢的數(shù)據(jù)在輔助索引上完全能獲取到便不需要回表查詢。例如有一張表存儲著個人信息包括id、name、age等字段。假設(shè)聚簇索引是以ID為鍵值構(gòu)建的索引,非聚簇索引是以name為鍵值構(gòu)建的索引,select id,name from user where name = 'zhangsan';這個查詢便不需要進行回表查詢因為,通過非聚簇索引已經(jīng)能全部檢索出數(shù)據(jù),這就是索引覆蓋的情況。如果查詢語句是這樣,select id,name,age from user where name = 'zhangsan';則需要進行回表查詢,因為通過非聚簇索引不能檢索出age的值。那應(yīng)該如何解決那呢?只需要將索引覆蓋即可,建立age和name的聯(lián)合索引再使用select id,name,age from user where name = 'zhangsan';進行查詢即可。
所以通過索引覆蓋能解決非聚簇索引回表查詢的問題。
索引的使用場景有哪些?
-
對于中大型表建立索引非常有效,對于非常小的表,一般全部表掃描速度更快些。 -
對于超大型的表,建立和維護索引的代價也會變高,這時可以考慮分區(qū)技術(shù)。 -
如何表的增刪改非常多,而查詢需求非常少的話,那就沒有必要建立索引了,因為維護索引也是需要代價的。 -
一般不會出現(xiàn)在where條件中的字段就沒有必要建立索引了。 -
多個字段經(jīng)常被查詢的話可以考慮聯(lián)合索引。 -
字段多且字段值沒有重復(fù)的時候考慮唯一索引。 -
字段多且有重復(fù)的時候考慮普通索引。
索引的設(shè)計原則?
-
最適合索引的列是在where后面出現(xiàn)的列或者連接句子中指定的列,而不是出現(xiàn)在SELECT關(guān)鍵字后面的選擇列表中的列。 -
索引列的基數(shù)越大,索引的效果越好,換句話說就是索引列的區(qū)分度越高,索引的效果越好。比如使用性別這種區(qū)分度很低的列作為索引,效果就會很差,因為列的基數(shù)最多也就是三種,大多不是男性就是女性。 -
盡量使用短索引,對于較長的字符串進行索引時應(yīng)該指定一個較短的前綴長度,因為較小的索引涉及到的磁盤I/O較少,并且索引高速緩存中的塊可以容納更多的鍵值,會使得查詢速度更快。 -
盡量利用最左前綴。 -
不要過度索引,每個索引都需要額外的物理空間,維護也需要花費時間,所以索引不是越多越好。
如何對索引進行優(yōu)化?
對索引的優(yōu)化其實最關(guān)鍵的就是要符合索引的設(shè)計原則和應(yīng)用場景,將不符合要求的索引優(yōu)化成符合索引設(shè)計原則和應(yīng)用場景的索引。
除了索引的設(shè)計原則和應(yīng)用場景那幾點外,還可以從以下兩方面考慮。
-
在進行查詢時,索引列不能是表達式的一部分,也不能是函數(shù)的參數(shù),因為這樣無法使用索引。例如 select * from table_name where a + 1 = 2 -
將區(qū)分度最高的索引放在前面 -
盡量少使用select*
索引的使用場景、索引的設(shè)計原則和如何對索引進行優(yōu)化可以看成一個問題。
如何創(chuàng)建/刪除索引?
創(chuàng)建索引:
-
使用CREATE INDEX 語句
CREATE INDEX index_name ON table_name (column_list); -
在CREATE TABLE時創(chuàng)建
CREATE TABLE user(
id INT PRIMARY KEY,
information text,
FULLTEXT KEY (information)
); -
使用ALTER TABLE創(chuàng)建索引
ALTER TABLE table_name ADD INDEX index_name (column_list);
刪除索引:
-
刪除主鍵索引
alter table 表名 drop primary key -
刪除其他索引
alter table 表名 drop key 索引名
使用索引查詢時性能一定會提升嗎?
不一定,前面在索引的使用場景和索引的設(shè)計原則中已經(jīng)提到了如何合理地使用索引,因為創(chuàng)建和維護索引需要花費空間和時間上的代價,如果不合理地使用索引反而會使查詢性能下降。
什么是前綴索引?
前綴索引是指對文本或者字符串的前幾個字符建立索引,這樣索引的長度更短,查詢速度更快。
使用場景:前綴的區(qū)分度比較高的情況下。
建立前綴索引的方式
ALTER TABLE table_name ADD KEY(column_name(prefix_length));
這里面有個prefix_length參數(shù)很難確定,這個參數(shù)就是前綴長度的意思。通常可以使用以下方法進行確定,先計算全列的區(qū)分度
SELECT COUNT(DISTINCT column_name) / COUNT(*) FROM table_name;
然后在計算前綴長度為多少時和全列的區(qū)分度最相似。
SELECT COUNT(DISTINCT LEFT(column_name, prefix_length)) / COUNT(*) FROM table_name;
不斷地調(diào)整prefix_length的值,直到和全列計算出區(qū)分度相近。
什么是最左匹配原則?
最左匹配原則:從最左邊為起點開始連續(xù)匹配,遇到范圍查詢(<、>、between、like)會停止匹配。
例如建立索引(a,b,c),大家可以猜測以下幾種情況是否用到了索引。
-
第一種
select * from table_name where a = 1 and b = 2 and c = 3
select * from table_name where b = 2 and a = 1 and c = 3上面兩次查詢過程中所有值都用到了索引,where后面字段調(diào)換不會影響查詢結(jié)果,因為MySQL中的優(yōu)化器會自動優(yōu)化查詢順序。
-
第二種
select * from table_name where a = 1
select * from table_name where a = 1 and b = 2
select * from table_name where a = 1 and b = 2 and c = 3答案是三個查詢語句都用到了索引,因為三個語句都是從最左開始匹配的。
-
第三種
select * from table_name where b = 1
select * from table_name where b = 1 and c = 2答案是這兩個查詢語句都沒有用到索引,因為不是從最左邊開始匹配的
-
第四種
select * from table_name where a = 1 and c = 2這個查詢語句只有a列用到了索引,c列沒有用到索引,因為中間跳過了b列,不是從最左開始連續(xù)匹配的。
-
第五種
select * from table_name where a = 1 and b < 3 and c < 1這個查詢中只有a列和b列使用到了索引,而c列沒有使用索引,因為根據(jù)最左匹配查詢原則,遇到范圍查詢會停止。
-
第六種
select * from table_name where a like 'ab%';
select * from table_name where a like '%ab'
select * from table_name where a like '%ab%'對于列為字符串的情況,只有前綴匹配可以使用索引,中綴匹配和后綴匹配只能進行全表掃描。
索引在什么情況下會失效?
在上面介紹了幾種不符合最左匹配原則的情況會導(dǎo)致索引失效,除此之外,以下這幾種情況也會導(dǎo)致索引失效。
-
條件中有or,例如 select * from table_name where a = 1 or b = 3 -
在索引上進行計算會導(dǎo)致索引失效,例如 select * from table_name where a + 1 = 2 -
在索引的類型上進行數(shù)據(jù)類型的隱形轉(zhuǎn)換,會導(dǎo)致索引失效,例如字符串一定要加引號,假設(shè) select * from table_name where a = '1'會使用到索引,如果寫成select * from table_name where a = 1則會導(dǎo)致索引失效。 -
在索引中使用函數(shù)會導(dǎo)致索引失效,例如 select * from table_name where abs(a) = 1 -
在使用like查詢時以%開頭會導(dǎo)致索引失效 -
索引上使用!、=、<>進行判斷時會導(dǎo)致索引失效,例如 select * from table_name where a != 1 -
索引字段上使用 is null/is not null判斷時會導(dǎo)致索引失效,例如 select * from table_name where a is null
數(shù)據(jù)庫的事務(wù) ***
什么是數(shù)據(jù)庫的事務(wù)?
百度百科的解釋:數(shù)據(jù)庫事務(wù)( transaction)是訪問并可能操作各種數(shù)據(jù)項的一個數(shù)據(jù)庫操作序列,這些操作要么全部執(zhí)行,要么全部不執(zhí)行,是一個不可分割的工作單位。事務(wù)由事務(wù)開始與事務(wù)結(jié)束之間執(zhí)行的全部數(shù)據(jù)庫操作組成。
事務(wù)的四大特性是什么?
-
原子性:原子性是指包含事務(wù)的操作要么全部執(zhí)行成功,要么全部失敗回滾。 -
一致性:一致性指事務(wù)在執(zhí)行前后狀態(tài)是一致的。 -
隔離性:一個事務(wù)所進行的修改在最終提交之前,對其他事務(wù)是不可見的。 -
持久性:數(shù)據(jù)一旦提交,其所作的修改將永久地保存到數(shù)據(jù)庫中。
數(shù)據(jù)庫的并發(fā)一致性問題
當(dāng)多個事務(wù)并發(fā)執(zhí)行時,可能會出現(xiàn)以下問題:
-
臟讀:事務(wù)A更新了數(shù)據(jù),但還沒有提交,這時事務(wù)B讀取到事務(wù)A更新后的數(shù)據(jù),然后事務(wù)A回滾了,事務(wù)B讀取到的數(shù)據(jù)就成為臟數(shù)據(jù)了。 -
不可重復(fù)讀:事務(wù)A對數(shù)據(jù)進行多次讀取,事務(wù)B在事務(wù)A多次讀取的過程中執(zhí)行了更新操作并提交了,導(dǎo)致事務(wù)A多次讀取到的數(shù)據(jù)并不一致。 -
幻讀:事務(wù)A在讀取數(shù)據(jù)后,事務(wù)B向事務(wù)A讀取的數(shù)據(jù)中插入了幾條數(shù)據(jù),事務(wù)A再次讀取數(shù)據(jù)時發(fā)現(xiàn)多了幾條數(shù)據(jù),和之前讀取的數(shù)據(jù)不一致。 -
丟失修改:事務(wù)A和事務(wù)B都對同一個數(shù)據(jù)進行修改,事務(wù)A先修改,事務(wù)B隨后修改,事務(wù)B的修改覆蓋了事務(wù)A的修改。
不可重復(fù)度和幻讀看起來比較像,它們主要的區(qū)別是:在不可重復(fù)讀中,發(fā)現(xiàn)數(shù)據(jù)不一致主要是數(shù)據(jù)被更新了。在幻讀中,發(fā)現(xiàn)數(shù)據(jù)不一致主要是數(shù)據(jù)增多或者減少了。
數(shù)據(jù)庫的隔離級別有哪些?
-
未提交讀:一個事務(wù)在提交前,它的修改對其他事務(wù)也是可見的。 -
提交讀:一個事務(wù)提交之后,它的修改才能被其他事務(wù)看到。 -
可重復(fù)讀:在同一個事務(wù)中多次讀取到的數(shù)據(jù)是一致的。 -
串行化:需要加鎖實現(xiàn),會強制事務(wù)串行執(zhí)行。
數(shù)據(jù)庫的隔離級別分別可以解決數(shù)據(jù)庫的臟讀、不可重復(fù)讀、幻讀等問題。
| 隔離級別 | 臟讀 | 不可重復(fù)讀 | 幻讀 |
|---|---|---|---|
| 未提交讀 | 允許 | 允許 | 允許 |
| 提交讀 | 不允許 | 允許 | 允許 |
| 可重復(fù)讀 | 不允許 | 不允許 | 允許 |
| 串行化 | 不允許 | 不允許 | 不允許 |
MySQL的默認隔離級別是可重復(fù)讀。
隔離級別是如何實現(xiàn)的?
事務(wù)的隔離機制主要是依靠鎖機制和MVCC(多版本并發(fā)控制)實現(xiàn)的,提交讀和可重復(fù)讀可以通過MVCC實現(xiàn),串行化可以通過鎖機制實現(xiàn)。
什么是MVCC?
MVCC(multiple version concurrent control)是一種控制并發(fā)的方法,主要用來提高數(shù)據(jù)庫的并發(fā)性能。
在了解MVCC時應(yīng)該先了解當(dāng)前讀和快照讀。
-
當(dāng)前讀:讀取的是數(shù)據(jù)庫的最新版本,并且在讀取時要保證其他事務(wù)不會修改當(dāng)前記錄,所以會對讀取的記錄加鎖。 -
快照讀:不加鎖讀取操作即為快照讀,使用MVCC來讀取快照中的數(shù)據(jù),避免加鎖帶來的性能損耗。
可以看到MVCC的作用就是在不加鎖的情況下,解決數(shù)據(jù)庫讀寫沖突問題,并且解決臟讀、幻讀、不可重復(fù)讀等問題,但是不能解決丟失修改問題。
MVCC的實現(xiàn)原理:
-
版本號
系統(tǒng)版本號:是一個自增的ID,每開啟一個事務(wù),系統(tǒng)版本號都會遞增。
事務(wù)版本號:事務(wù)版本號就是事務(wù)開始時的系統(tǒng)版本號,可以通過事務(wù)版本號的大小判斷事務(wù)的時間順序。
-
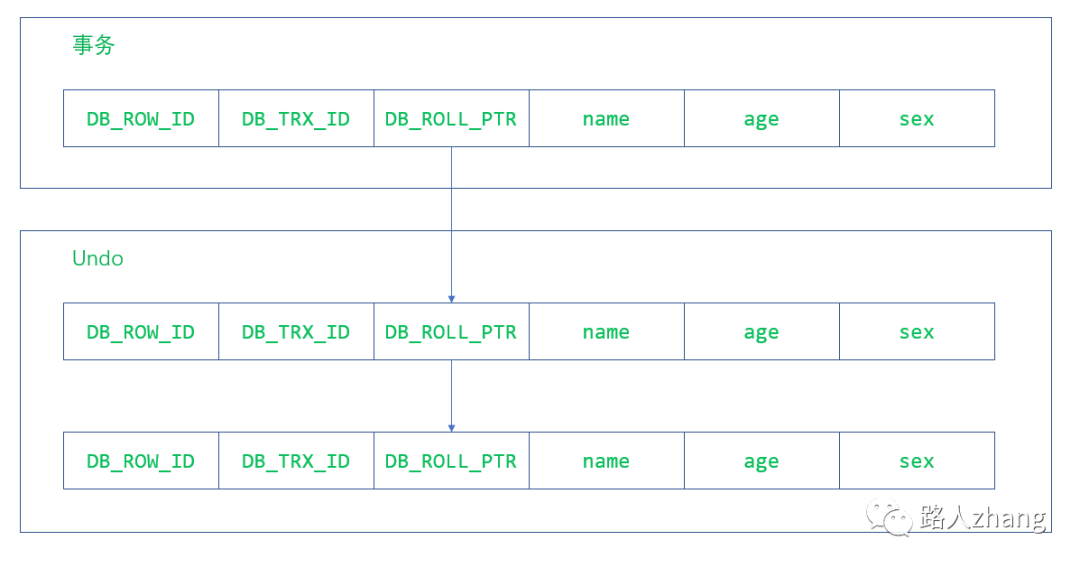
行記錄隱藏的列
DB_ROW_ID:所需空間6byte,隱含的自增ID,用來生成聚簇索引,如果數(shù)據(jù)表沒有指定聚簇索引,InnoDB會利用這個隱藏ID創(chuàng)建聚簇索引。
DB_TRX_ID:所需空間6byte,最近修改的事務(wù)ID,記錄創(chuàng)建這條記錄或最后一次修改這條記錄的事務(wù)ID。
DB_ROLL_PTR:所需空間7byte,回滾指針,指向這條記錄的上一個版本。
它們大致長這樣,省略了具體字段的值。·

-
undo日志
MVCC做使用到的快照會存儲在Undo日志中,該日志通過回滾指針將一個一個數(shù)據(jù)行的所有快照連接起來。它們大致長這樣。
舉一個簡單的例子說明下,比如最開始的某條記錄長這樣
現(xiàn)在來了一個事務(wù)對他的年齡字段進行了修改,變成了這樣
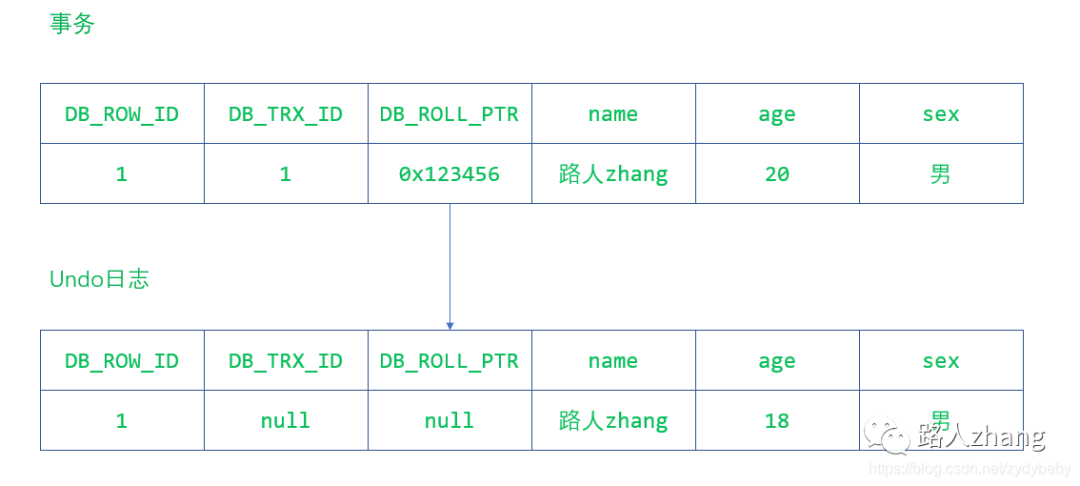
現(xiàn)在又來了一個事務(wù)2對它的性別進行了修改,它又變成了這樣
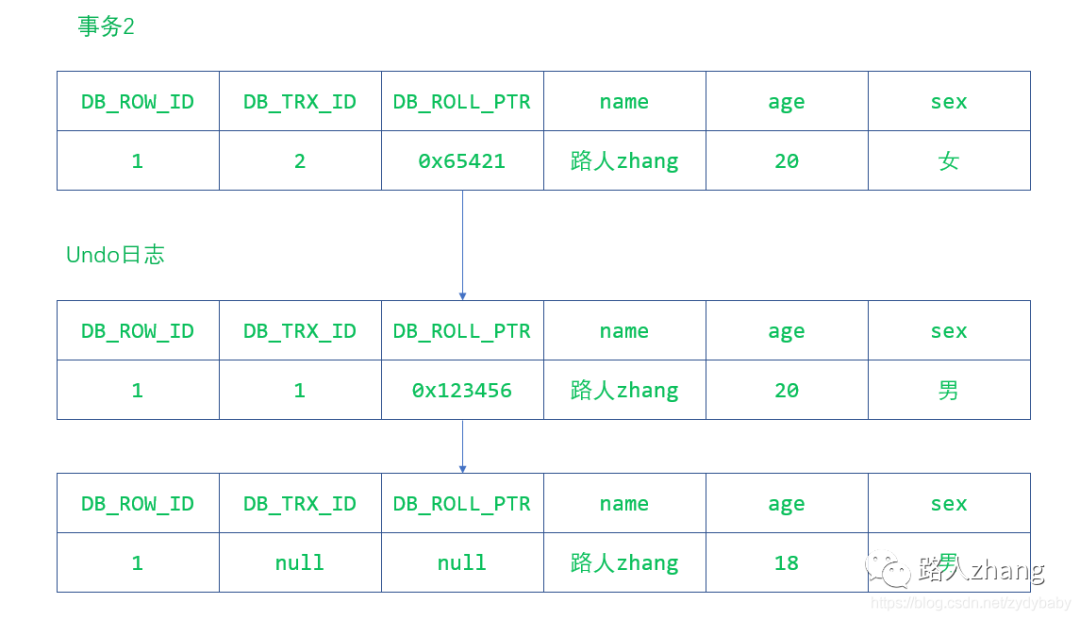
從上面的分析可以看出,事務(wù)對同一記錄的修改,記錄的各個會在Undo日志中連接成一個線性表,在表頭的就是最新的舊紀(jì)錄。
在重復(fù)讀的隔離級別下,InnoDB的工作流程:
-
SELECT
作為查詢的結(jié)果要滿足兩個條件:
-
當(dāng)前事務(wù)所要查詢的數(shù)據(jù)行快照的創(chuàng)建版本號必須小于當(dāng)前事務(wù)的版本號,這樣做的目的是保證當(dāng)前事務(wù)讀取的數(shù)據(jù)行的快照要么是在當(dāng)前事務(wù)開始前就已經(jīng)存在的,要么就是當(dāng)前事務(wù)自身插入或者修改過的。 -
當(dāng)前事務(wù)所要讀取的數(shù)據(jù)行快照的刪除版本號必須是大于當(dāng)前事務(wù)的版本號,如果是小于等于的話,表示該數(shù)據(jù)行快照已經(jīng)被刪除,不能讀取。 -
INSERT
將當(dāng)前系統(tǒng)版本號作為數(shù)據(jù)行快照的創(chuàng)建版本號。
-
DELETE
將當(dāng)前系統(tǒng)版本號作為數(shù)據(jù)行快照的刪除版本號。
-
UPDATE
保存當(dāng)前系統(tǒng)版本號為更新前的數(shù)據(jù)行快照創(chuàng)建行版本號,并保存當(dāng)前系統(tǒng)版本號為更新后的數(shù)據(jù)行快照的刪除版本號,其實就是,先刪除在插入即為更新。
總結(jié)一下,MVCC的作用就是在避免加鎖的情況下最大限度解決讀寫并發(fā)沖突的問題,它可以實現(xiàn)提交讀和可重復(fù)度兩個隔離級。
數(shù)據(jù)庫的鎖 ***
什么是數(shù)據(jù)庫的鎖?
當(dāng)數(shù)據(jù)庫有并發(fā)事務(wù)的時候,保證數(shù)據(jù)訪問順序的機制稱為鎖機制。
數(shù)據(jù)庫的鎖與隔離級別的關(guān)系?
| 隔離級別 | 實現(xiàn)方式 |
|---|---|
| 未提交讀 | 總是讀取最新的數(shù)據(jù),無需加鎖 |
| 提交讀 | 讀取數(shù)據(jù)時加共享鎖,讀取數(shù)據(jù)后釋放共享鎖 |
| 可重復(fù)讀 | 讀取數(shù)據(jù)時加共享鎖,事務(wù)結(jié)束后釋放共享鎖 |
| 串行化 | 鎖定整個范圍的鍵,一直持有鎖直到事務(wù)結(jié)束 |
數(shù)據(jù)庫鎖的類型有哪些?
按照鎖的粒度可以將MySQL鎖分為三種:
| MySQL鎖類別 | 資源開銷 | 加鎖速度 | 是否會出現(xiàn)死鎖 | 鎖的粒度 | 并發(fā)度 |
|---|---|---|---|---|---|
| 表級鎖 | 小 | 快 | 不會 | 大 | 低 |
| 行級鎖 | 大 | 慢 | 會 | 小 | 高 |
| 頁面鎖 | 一般 | 一般 | 不會 | 一般 | 一般 |
MyISAM默認采用表級鎖,InnoDB默認采用行級鎖。
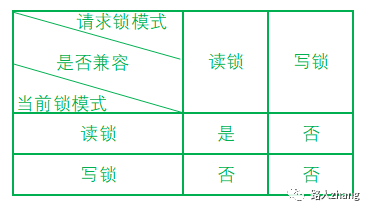
從鎖的類別上區(qū)別可以分為共享鎖和排他鎖
-
共享鎖:共享鎖又稱讀鎖,簡寫為S鎖,一個事務(wù)對一個數(shù)據(jù)對象加了S鎖,可以對這個數(shù)據(jù)對象進行讀取操作,但不能進行更新操作。并且在加鎖期間其他事務(wù)只能對這個數(shù)據(jù)對象加S鎖,不能加X鎖。 -
排他鎖:排他鎖又稱為寫鎖,簡寫為X鎖,一個事務(wù)對一個數(shù)據(jù)對象加了X鎖,可以對這個對象進行讀取和更新操作,加鎖期間,其他事務(wù)不能對該數(shù)據(jù)對象進行加X鎖或S鎖。
它們的兼容情況如下(不太會用excel,圖太丑了):
MySQL中InnoDB引擎的行鎖模式及其是如何實現(xiàn)的?
行鎖模式
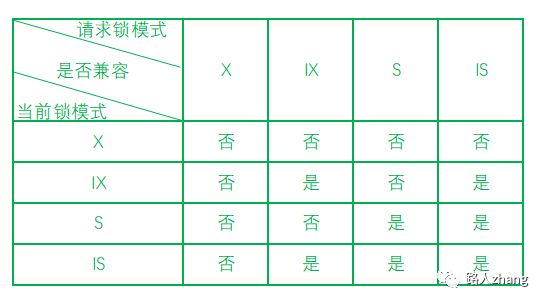
在存在行鎖和表鎖的情況下,一個事務(wù)想對某個表加X鎖時,需要先檢查是否有其他事務(wù)對這個表加了鎖或?qū)@個表的某一行加了鎖,對表的每一行都進行檢測一次這是非常低效率的,為了解決這種問題,實現(xiàn)多粒度鎖機制,InnoDB還有兩種內(nèi)部使用的意向鎖,兩種意向鎖都是表鎖。
-
意向共享鎖:簡稱IS鎖,一個事務(wù)打算給數(shù)據(jù)行加共享鎖前必須先獲得該表的IS鎖。 -
意向排他鎖:簡稱IX鎖,一個事務(wù)打算給數(shù)據(jù)行加排他鎖前必須先獲得該表的IX鎖。
有了意向鎖,一個事務(wù)想對某個表加X鎖,只需要檢查是否有其他事務(wù)對這個表加了X/IX/S/IS鎖即可。
鎖的兼容性如下:
行鎖實現(xiàn)方式:INnoDB的行鎖是通過給索引上的索引項加鎖實現(xiàn)的,如果沒有索引,InnoDB將通過隱藏的聚簇索引來對記錄進行加鎖。
InnoDB行鎖主要分三種情況:
-
Record lock:對索引項加鎖 -
Grap lock:對索引之間的“間隙”、第一條記錄前的“間隙”或最后一條后的間隙加鎖。 -
Next-key lock:前兩種放入組合,對記錄及前面的間隙加鎖。
InnoDB行鎖的特性:如果不通過索引條件檢索數(shù)據(jù),那么InnoDB將對表中所有記錄加鎖,實際產(chǎn)生的效果和表鎖是一樣的。
MVCC不能解決幻讀問題,在可重復(fù)讀隔離級別下,使用MVCC+Next-Key Locks可以解決幻讀問題。
什么是數(shù)據(jù)庫的樂觀鎖和悲觀鎖,如何實現(xiàn)?
樂觀鎖:系統(tǒng)假設(shè)數(shù)據(jù)的更新在大多數(shù)時候是不會產(chǎn)生沖突的,所以數(shù)據(jù)庫只在更新操作提交的時候?qū)?shù)據(jù)檢測沖突,如果存在沖突,則數(shù)據(jù)更新失敗。
樂觀鎖實現(xiàn)方式:一般通過版本號和CAS算法實現(xiàn)。
悲觀鎖:假定會發(fā)生并發(fā)沖突,屏蔽一切可能違反數(shù)據(jù)完整性的操作。通俗講就是每次去拿數(shù)據(jù)的時候都認為別人會修改,所以每次在拿數(shù)據(jù)的時候都會上鎖。
悲觀鎖的實現(xiàn)方式:通過數(shù)據(jù)庫的鎖機制實現(xiàn),對查詢語句添加for updata。
什么是死鎖?如何避免?
死鎖是指兩個或者兩個以上進程在執(zhí)行過程中,由于競爭資源或者由于彼此通信而造成的一種阻塞的現(xiàn)象。在MySQL中,MyISAM是一次獲得所需的全部鎖,要么全部滿足,要么等待,所以不會出現(xiàn)死鎖。在InnoDB存儲引擎中,除了單個SQL組成的事務(wù)外,鎖都是逐步獲得的,所以存在死鎖問題。
如何避免MySQL發(fā)生死鎖或鎖沖突:
-
如果不同的程序并發(fā)存取多個表,盡量以相同的順序訪問表。
-
在程序以批量方式處理數(shù)據(jù)的時候,如果已經(jīng)對數(shù)據(jù)排序,盡量保證每個線程按照固定的順序來處理記錄。
-
在事務(wù)中,如果需要更新記錄,應(yīng)直接申請足夠級別的排他鎖,而不應(yīng)該先申請共享鎖,更新時在申請排他鎖,因為在當(dāng)前用戶申請排他鎖時,其他事務(wù)可能已經(jīng)獲得了相同記錄的共享鎖,從而造成鎖沖突或者死鎖。
-
盡量使用較低的隔離級別
-
盡量使用索引訪問數(shù)據(jù),使加鎖更加準(zhǔn)確,從而減少鎖沖突的機會
-
合理選擇事務(wù)的大小,小事務(wù)發(fā)生鎖沖突的概率更低
-
盡量用相等的條件訪問數(shù)據(jù),可以避免Next-Key鎖對并發(fā)插入的影響。
-
不要申請超過實際需要的鎖級別,查詢時盡量不要顯示加鎖
-
對于一些特定的事務(wù),可以表鎖來提高處理速度或減少死鎖的概率。
SQL語句基礎(chǔ)知識
SQL語句主要分為哪幾類 *
-
數(shù)據(jù)據(jù)定義語言DDL(Data Definition Language):主要有CREATE,DROP,ALTER等對邏輯結(jié)構(gòu)有操作的,包括表結(jié)構(gòu)、視圖和索引。 -
數(shù)據(jù)庫查詢語言DQL(Data Query Language):主要以SELECT為主 -
數(shù)據(jù)操縱語言DML(Data Manipulation Language):主要包括INSERT,UPDATE,DELETE -
數(shù)據(jù)控制功能DCL(Data Control Language):主要是權(quán)限控制能操作,包括GRANT,REVOKE,COMMIT,ROLLBACK等。
SQL約束有哪些? **
-
主鍵約束:主鍵為在表中存在一列或者多列的組合,能唯一標(biāo)識表中的每一行。一個表只有一個主鍵,并且主鍵約束的列不能為空。 -
外鍵約束:外鍵約束是指用于在兩個表之間建立關(guān)系,需要指定引用主表的哪一列。只有主表的主鍵可以被從表用作外鍵,被約束的從表的列可以不是主鍵,所以創(chuàng)建外鍵約束需要先定義主表的主鍵,然后定義從表的外鍵。 -
唯一約束:確保表中的一列數(shù)據(jù)沒有相同的值,一個表可以定義多個唯一約束。 -
默認約束:在插入新數(shù)據(jù)時,如果該行沒有指定數(shù)據(jù),系統(tǒng)將默認值賦給該行,如果沒有設(shè)置沒默認值,則為NULL。 -
Check約束:Check會通過邏輯表達式來判斷數(shù)據(jù)的有效性,用來限制輸入一列或者多列的值的范圍。在列更新數(shù)據(jù)時,輸入的內(nèi)容必須滿足Check約束的條件。
什么是子查詢? **
子查詢:把一個查詢的結(jié)果在另一個查詢中使用
子查詢可以分為以下幾類:
-
標(biāo)量子查詢:指子查詢返回的是一個值,可以使用 =,>,<,>=,<=,<>等操作符對子查詢標(biāo)量結(jié)果進行比較,一般子查詢會放在比較式的右側(cè)。
SELECT * FROM user WHERE age = (SELECT max(age) from user) //查詢年紀(jì)最大的人 -
列子查詢:指子查詢的結(jié)果是n行一列,一般應(yīng)用于對表的某個字段進行查詢返回。可以使用IN、ANY、SOME和ALL等操作符,不能直接使用
SELECT num1 FROM table1 WHERE num1 > ANY (SELECT num2 FROM table2) -
行子查詢:指子查詢返回的結(jié)果一行n列
SELECT * FROM user WHERE (age,sex) = (SELECT age,sex FROM user WHERE name="zhangsan") -
表子查詢:指子查詢是n行n列的一個數(shù)據(jù)表
SELECT * FROM student WHERE (name,age,sex) IN (SELECT name,age,sex FROM class1) //在學(xué)生表中找到班級在1班的學(xué)生
了解MySQL的幾種連接查詢嗎? ***
MySQl的連接查詢主要可以分為外連接,內(nèi)連接,交叉連接
-
外連接
外連接主要分為左外連接(LEFT JOIN)、右外連接(RIGHT JOIN)、全外連接。
左外連接:顯示左表中所有的數(shù)據(jù)及右表中符合條件的數(shù)據(jù),右表中不符合條件的數(shù)據(jù)為null。
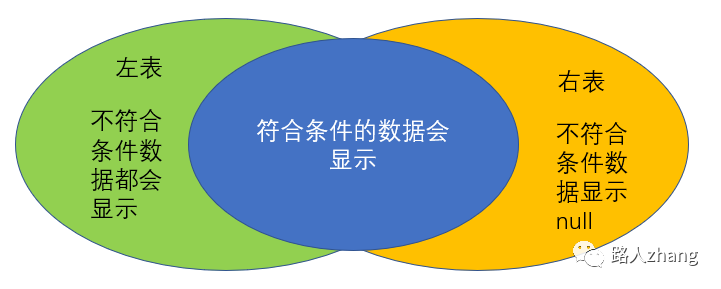
右外連接:顯示左表中所有的數(shù)據(jù)及右表中符合條件的數(shù)據(jù),右表中不符合條件的數(shù)據(jù)為null。
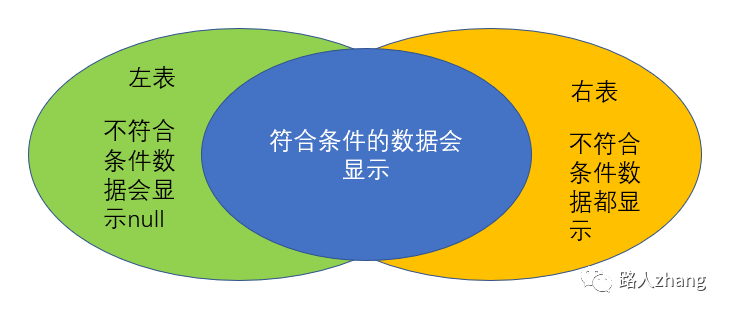
MySQL中不支持全外連接。
-
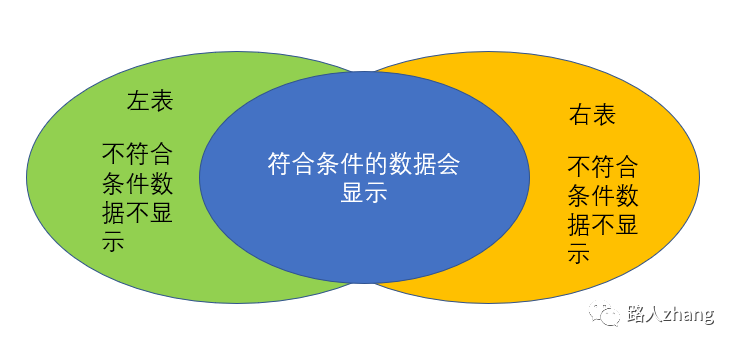
內(nèi)連接:只顯示符合條件的數(shù)據(jù)
-
交叉連接:使用笛卡爾積的一種連接。
笛卡爾積,百度百科的解釋:兩個集合X和Y的笛卡爾積表示為X × Y,第一個對象是X的成員而第二個對象是Y的所有可能有序?qū)Φ钠渲幸粋€成員 。例如:A={a,b},B={0,1,2},A × B = {(a,0),(a,1),(a,2),(b,0),(b,1),(b,2)}
舉例如下:有兩張表分為L表和R表。
L表
| A | B |
|---|---|
| a1 | b1 |
| a2 | b2 |
| a3 | b3 |
R表
| B | C |
|---|---|
| b1 | c1 |
| b2 | c2 |
| b4 | c3 |
-
左外連接 :
select L.`*`,R.`*` from L left join R on L.b=R.bA B B C a1 b1 b1 c1 a2 b2 b2 c2 a3 b3 null null -
右外連接:
select L.`*`,R.`*` from L right join R on L.b=R.bB C A B b1 c1 a1 b1 b2 c2 a2 b2 b4 c3 null null -
內(nèi)連接:
select L.`*`,R.`*` from L inner join R on L.b=R.bA B B C a1 b1 b1 c1 a2 b2 b2 c2 -
交叉連接:
select L.`*`,R.`*` from L,RA B B C a1 b1 b1 c1 a1 b1 b2 c2 a1 b1 b4 c3 a2 b2 b1 c1 a2 b2 b2 c2 a2 b2 b4 c3 a3 b3 b1 c1 a3 b3 b2 c2 a3 b3 b4 c3
mysql中in和exists的區(qū)別? **
in和exists一般用于子查詢。
-
使用exists時會先進行外表查詢,將查詢到的每行數(shù)據(jù)帶入到內(nèi)表查詢中看是否滿足條件;使用in一般會先進行內(nèi)表查詢獲取結(jié)果集,然后對外表查詢匹配結(jié)果集,返回數(shù)據(jù)。 -
in在內(nèi)表查詢或者外表查詢過程中都會用到索引。 -
exists僅在內(nèi)表查詢時會用到索引 -
一般來說,當(dāng)子查詢的結(jié)果集比較大,外表較小使用exist效率更高;當(dāng)子查詢尋得結(jié)果集較小,外表較大時,使用in效率更高。 -
對于not in和not exists,not exists效率比not in的效率高,與子查詢的結(jié)果集無關(guān),因為not in對于內(nèi)外表都進行了全表掃描,沒有使用到索引。not exists的子查詢中可以用到表上的索引。
varchar和char的區(qū)別? ***
-
varchar表示變長,char表示長度固定。當(dāng)所插入的字符超過他們的長度時,在嚴格模式下,會拒絕插入并提示錯誤信息,在一般模式下,會截取后插入。如char(5),無論插入的字符長度是多少,長度都是5,插入字符長度小于5,則用空格補充。對于varchar(5),如果插入的字符長度小于5,則存儲的字符長度就是插入字符的長度,不會填充。 -
存儲容量不同,對于char來說,最多能存放的字符個數(shù)為255。對于varchar,最多能存放的字符個數(shù)是65532。 -
存儲速度不同,char長度固定,存儲速度會比varchar快一些,但在空間上會占用額外的空間,屬于一種空間換時間的策略。而varchar空間利用率會高些,但存儲速度慢,屬于一種時間換空間的策略。
MySQL中int(10)和char(10)和varchar(10)的區(qū)別? ***
int(10)中的10表示的是顯示數(shù)據(jù)的長度,而char(10)和varchar(10)表示的是存儲數(shù)據(jù)的大小。
drop、delete和truncate的區(qū)別? **
| drop | delete | truncate | |
|---|---|---|---|
| 速度 | 快 | 逐行刪除,慢 | 較快 |
| 類型 | DDL | DML | DDL |
| 回滾 | 不可回滾 | 可回滾 | 不可回滾 |
| 刪除內(nèi)容 | 刪除整個表,數(shù)據(jù)行、索引都會被刪除 | 表結(jié)構(gòu)還在,刪除表的一部分或全部數(shù)據(jù) | 表結(jié)構(gòu)還在,刪除表的全部數(shù)據(jù) |
一般來講,刪除整個表,使用drop,刪除表的部分數(shù)據(jù)使用delete,保留表結(jié)構(gòu)刪除表的全部數(shù)據(jù)使用truncate。
UNION和UNION ALL的區(qū)別? **
union和union all的作用都是將兩個結(jié)果集合并到一起。
-
union會對結(jié)果去重并排序,union all直接直接返回合并后的結(jié)果,不去重也不進行排序。 -
union all的性能比union性能好。
什么是臨時表,什么時候會使用到臨時表,什么時候刪除臨時表? *
MySQL在執(zhí)行SQL語句的時候會臨時創(chuàng)建一些存儲中間結(jié)果集的表,這種表被稱為臨時表,臨時表只對當(dāng)前連接可見,在連接關(guān)閉后,臨時表會被刪除并釋放空間。
臨時表主要分為內(nèi)存臨時表和磁盤臨時表兩種。內(nèi)存臨時表使用的是MEMORY存儲引擎,磁盤臨時表使用的是MyISAM存儲引擎。
一般在以下幾種情況中會使用到臨時表:
-
FROM中的子查詢 -
DISTINCT查詢并加上ORDER BY -
ORDER BY和GROUP BY的子句不一樣時會產(chǎn)生臨時表 -
使用UNION查詢會產(chǎn)生臨時表
大表數(shù)據(jù)查詢?nèi)绾芜M行優(yōu)化? ***
-
索引優(yōu)化 -
SQL語句優(yōu)化 -
水平拆分 -
垂直拆分 -
建立中間表 -
使用緩存技術(shù) -
固定長度的表訪問起來更快 -
越小的列訪問越快
了解慢日志查詢嗎?統(tǒng)計過慢查詢嗎?對慢查詢?nèi)绾蝺?yōu)化? ***
慢查詢一般用于記錄執(zhí)行時間超過某個臨界值的SQL語句的日志。
相關(guān)參數(shù):
-
slow_query_log:是否開啟慢日志查詢,1表示開啟,0表示關(guān)閉。 -
slow_query_log_file:MySQL數(shù)據(jù)庫慢查詢?nèi)罩敬鎯β窂健? -
long_query_time:慢查詢閾值,當(dāng)SQL語句查詢時間大于閾值,會被記錄在日志上。 -
log_queries_not_using_indexes:未使用索引的查詢會被記錄到慢查詢?nèi)罩局小? -
log_output:日志存儲方式。“FILE”表示將日志存入文件。“TABLE”表示將日志存入數(shù)據(jù)庫。
如何對慢查詢進行優(yōu)化?
-
分析語句的執(zhí)行計劃,查看SQL語句的索引是否命中 -
優(yōu)化數(shù)據(jù)庫的結(jié)構(gòu),將字段很多的表分解成多個表,或者考慮建立中間表。 -
優(yōu)化LIMIT分頁。
為什么要設(shè)置主鍵? **
主鍵是唯一區(qū)分表中每一行的唯一標(biāo)識,如果沒有主鍵,更新或者刪除表中特定的行會很困難,因為不能唯一準(zhǔn)確地標(biāo)識某一行。
主鍵一般用自增ID還是UUID? **
使用自增ID的好處:
-
字段長度較uuid會小很多。 -
數(shù)據(jù)庫自動編號,按順序存放,利于檢索 -
無需擔(dān)心主鍵重復(fù)問題
使用自增ID的缺點:
-
因為是自增,在某些業(yè)務(wù)場景下,容易被其他人查到業(yè)務(wù)量。 -
發(fā)生數(shù)據(jù)遷移時,或者表合并時會非常麻煩 -
在高并發(fā)的場景下,競爭自增鎖會降低數(shù)據(jù)庫的吞吐能力
UUID:通用唯一標(biāo)識碼,UUID是基于當(dāng)前時間、計數(shù)器和硬件標(biāo)識等數(shù)據(jù)計算生成的。
使用UUID的優(yōu)點:
-
唯一標(biāo)識,不會考慮重復(fù)問題,在數(shù)據(jù)拆分、合并時也能達到全局的唯一性。 -
可以在應(yīng)用層生成,提高數(shù)據(jù)庫的吞吐能力。 -
無需擔(dān)心業(yè)務(wù)量泄露的問題。
使用UUID的缺點:
-
因為UUID是隨機生成的,所以會發(fā)生隨機IO,影響插入速度,并且會造成硬盤的使用率較低。 -
UUID占用空間較大,建立的索引越多,造成的影響越大。 -
UUID之間比較大小較自增ID慢不少,影響查詢速度。
最后說下結(jié)論,一般情況MySQL推薦使用自增ID。因為在MySQL的InnoDB存儲引擎中,主鍵索引是一種聚簇索引,主鍵索引的B+樹的葉子節(jié)點按照順序存儲了主鍵值及數(shù)據(jù),如果主鍵索引是自增ID,只需要按順序往后排列即可,如果是UUID,ID是隨機生成的,在數(shù)據(jù)插入時會造成大量的數(shù)據(jù)移動,產(chǎn)生大量的內(nèi)存碎片,造成插入性能的下降。
字段為什么要設(shè)置成not null? **
首先說一點,NULL和空值是不一樣的,空值是不占用空間的,而NULL是占用空間的,所以字段設(shè)為NOT NULL后仍然可以插入空值。
字段設(shè)置成not null主要有以下幾點原因:
-
NULL值會影響一些函數(shù)的統(tǒng)計,如count,遇到NULL值,這條記錄不會統(tǒng)計在內(nèi)。
-
B樹不存儲NULL,所以索引用不到NULL,會造成第一點中說的統(tǒng)計不到的問題。
-
NOT IN子查詢在有NULL值的情況下返回的結(jié)果都是空值。
例如user表如下
id username 0 zhangsan 1 lisi 2 null select * from `user` where username NOT IN (select username from `user` where id != 0),這條查詢語句應(yīng)該查到zhangsan這條數(shù)據(jù),但是結(jié)果顯示為null。 -
MySQL在進行比較的時候,NULL會參與字段的比較,因為NULL是一種比較特殊的數(shù)據(jù)類型,數(shù)據(jù)庫在處理時需要進行特殊處理,增加了數(shù)據(jù)庫處理記錄的復(fù)雜性。
如何優(yōu)化查詢過程中的數(shù)據(jù)訪問? ***
從減少數(shù)據(jù)訪問方面考慮:
-
正確使用索引,盡量做到索引覆蓋 -
優(yōu)化SQL執(zhí)行計劃
從返回更少的數(shù)據(jù)方面考慮:
-
數(shù)據(jù)分頁處理 -
只返回需要的字段
從減少服務(wù)器CPU開銷方面考慮:
-
合理使用排序 -
減少比較的操作 -
復(fù)雜運算在客戶端處理
從增加資源方面考慮:
-
客戶端多進程并行訪問 -
數(shù)據(jù)庫并行處理
如何優(yōu)化長難的查詢語句? **
-
將一個大的查詢分解為多個小的查詢 -
分解關(guān)聯(lián)查詢,使緩存的效率更高
如何優(yōu)化LIMIT分頁? **
-
在LIMIT偏移量較大的時候,查詢效率會變低,可以記錄每次取出的最大ID,下次查詢時可以利用ID進行查詢
-
建立復(fù)合索引
如何優(yōu)化UNION查詢 **
如果不需要對結(jié)果集進行去重或者排序建議使用UNION ALL,會好一些。
如何優(yōu)化WHERE子句 ***
-
不要在where子句中使用!=和<>進行不等于判斷,這樣會導(dǎo)致放棄索引進行全表掃描。 -
不要在where子句中使用null或空值判斷,盡量設(shè)置字段為not null。 -
盡量使用union all代替or -
在where和order by涉及的列建立索引 -
盡量減少使用in或者not in,會進行全表掃描 -
在where子句中使用參數(shù)會導(dǎo)致全表掃描 -
避免在where子句中對字段及進行表達式或者函數(shù)操作會導(dǎo)致存儲引擎放棄索引進而全表掃描
SQL語句執(zhí)行的很慢原因是什么? ***
-
如果SQL語句只是偶爾執(zhí)行很慢,可能是執(zhí)行的時候遇到了鎖,也可能是redo log日志寫滿了,要將redo log中的數(shù)據(jù)同步到磁盤中去。 -
如果SQL語句一直都很慢,可能是字段上沒有索引或者字段有索引但是沒用上索引。
SQL語句的執(zhí)行順序? *
SELECT DISTINCT
select_list
FROM
left_table
LEFT JOIN
right_table ON join_condition
WHERE
where_condition
GROUP BY
group_by_list
HAVING
having_condition
ORDER BY
order_by_condition
執(zhí)行順序如下:
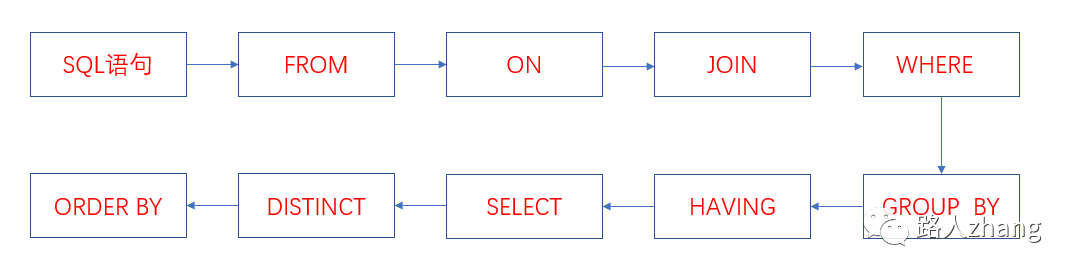
-
FROM:對SQL語句執(zhí)行查詢時,首先對關(guān)鍵字兩邊的表以笛卡爾積的形式執(zhí)行連接,并產(chǎn)生一個虛表V1。虛表就是視圖,數(shù)據(jù)會來自多張表的執(zhí)行結(jié)果。
-
ON:對FROM連接的結(jié)果進行ON過濾,并創(chuàng)建虛表V2
-
JOIN:將ON過濾后的左表添加進來,并創(chuàng)建新的虛擬表V3
-
WHERE:對虛擬表V3進行WHERE篩選,創(chuàng)建虛擬表V4
-
GROUP BY:對V4中的記錄進行分組操作,創(chuàng)建虛擬表V5
-
HAVING:對V5進行過濾,創(chuàng)建虛擬表V6
-
SELECT:將V6中的結(jié)果按照SELECT進行篩選,創(chuàng)建虛擬表V7
-
DISTINCT:對V7表中的結(jié)果進行去重操作,創(chuàng)建虛擬表V8,如果使用了GROUP BY子句則無需使用DISTINCT,因為分組的時候是將列中唯一的值分成一組,并且每組只返回一行記錄,所以所有的記錄都h是不同的。
-
ORDER BY:對V8表中的結(jié)果進行排序。
數(shù)據(jù)庫優(yōu)化
大表如何優(yōu)化? ***
-
限定數(shù)據(jù)的范圍:避免不帶任何限制數(shù)據(jù)范圍條件的查詢語句。 -
讀寫分離:主庫負責(zé)寫,從庫負責(zé)讀。 -
垂直分表:將一個表按照字段分成多個表,每個表存儲其中一部分字段。 -
水平分表:在同一個數(shù)據(jù)庫內(nèi),把一個表的數(shù)據(jù)按照一定規(guī)則拆分到多個表中。 -
對單表進行優(yōu)化:對表中的字段、索引、查詢SQL進行優(yōu)化。 -
添加緩存
什么是垂直分表、垂直分庫、水平分表、水平分庫? ***
垂直分表:將一個表按照字段分成多個表,每個表存儲其中一部分字段。一般會將常用的字段放到一個表中,將不常用的字段放到另一個表中。
垂直分表的優(yōu)勢:
-
避免IO競爭減少鎖表的概率。因為大的字段效率更低,第一數(shù)據(jù)量大,需要的讀取時間長。第二,大字段占用的空間更大,單頁內(nèi)存儲的行數(shù)變少,會使得IO操作增多。
-
可以更好地提升熱門數(shù)據(jù)的查詢效率。
垂直分庫:按照業(yè)務(wù)對表進行分類,部署到不同的數(shù)據(jù)庫上面,不同的數(shù)據(jù)庫可以放到不同的服務(wù)器上面。
垂直分庫的優(yōu)勢:
-
降低業(yè)務(wù)中的耦合,方便對不同的業(yè)務(wù)進行分級管理。 -
可以提升IO、數(shù)據(jù)庫連接數(shù)、解決單機硬件資源的瓶頸問題。
垂直拆分(分庫、分表)的缺點:
-
主鍵出現(xiàn)冗余,需要管理冗余列 -
事務(wù)的處理變得復(fù)雜 -
仍然存在單表數(shù)據(jù)量過大的問題
水平分表:在同一個數(shù)據(jù)庫內(nèi),把同一個表的數(shù)據(jù)按照一定規(guī)則拆分到多個表中。
水平分表的優(yōu)勢:
-
解決了單表數(shù)據(jù)量過大的問題 -
避免IO競爭并減少鎖表的概率
水平分庫:把同一個表的數(shù)據(jù)按照一定規(guī)則拆分到不同的數(shù)據(jù)庫中,不同的數(shù)據(jù)庫可以放到不同的服務(wù)器上。
水平分庫的優(yōu)勢:
-
解決了單庫大數(shù)據(jù)量的瓶頸問題 -
IO沖突減少,鎖的競爭減少,某個數(shù)據(jù)庫出現(xiàn)問題不影響其他數(shù)據(jù)庫(可用性),提高了系統(tǒng)的穩(wěn)定性和可用性
水平拆分(分表、分庫)的缺點:
-
分片事務(wù)一致性難以解決 -
跨節(jié)點JOIN性能差,邏輯會變得復(fù)雜 -
數(shù)據(jù)擴展難度大,不易維護
在系統(tǒng)設(shè)計時應(yīng)根據(jù)業(yè)務(wù)耦合來確定垂直分庫和垂直分表的方案,在數(shù)據(jù)訪問壓力不是特別大時應(yīng)考慮緩存、讀寫分離等方法,若數(shù)據(jù)量很大,或持續(xù)增長可考慮水平分庫分表,水平拆分所涉及的邏輯比較復(fù)雜,常見的方案有客戶端架構(gòu)和代理架構(gòu)。
分庫分表后,ID鍵如何處理? ***
分庫分表后不能每個表的ID都是從1開始,所以需要一個全局ID,設(shè)置全局ID主要有以下幾種方法:
-
UUID:優(yōu)點:本地生成ID,不需要遠程調(diào)用;全局唯一不重復(fù)。缺點:占用空間大,不適合作為索引。
-
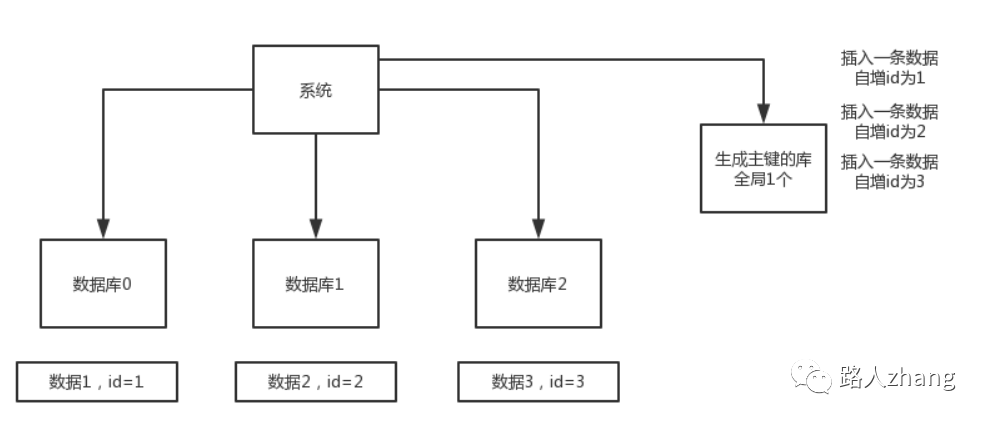
數(shù)據(jù)庫自增ID:在分庫分表表后使用數(shù)據(jù)庫自增ID,需要一個專門用于生成主鍵的庫,每次服務(wù)接收到請求,先向這個庫中插入一條沒有意義的數(shù)據(jù),獲取一個數(shù)據(jù)庫自增的ID,利用這個ID去分庫分表中寫數(shù)據(jù)。優(yōu)點:簡單易實現(xiàn)。缺點:在高并發(fā)下存在瓶頸。系統(tǒng)結(jié)構(gòu)如下圖(圖片來源于網(wǎng)絡(luò))
-
Redis生成ID:優(yōu)點:不依賴數(shù)據(jù)庫,性能比較好。缺點:引入新的組件會使得系統(tǒng)復(fù)雜度增加
-
Twitter的snowflake算法:是一個64位的long型的ID,其中有1bit是不用的,41bit作為毫秒數(shù),10bit作為工作機器ID,12bit作為序列號。
1bit:第一個bit默認為0,因為二進制中第一個bit為1的話為負數(shù),但是ID不能為負數(shù).
41bit:表示的是時間戳,單位是毫秒。
10bit:記錄工作機器ID,其中5個bit表示機房ID,5個bit表示機器ID。
12bit:用來記錄同一毫秒內(nèi)產(chǎn)生的不同ID。
-
美團的Leaf分布式ID生成系統(tǒng),美團點評分布式ID生成系統(tǒng)
MySQL的復(fù)制原理及流程?如何實現(xiàn)主從復(fù)制? ***
MySQL復(fù)制:為保證主服務(wù)器和從服務(wù)器的數(shù)據(jù)一致性,在向主服務(wù)器插入數(shù)據(jù)后,從服務(wù)器會自動將主服務(wù)器中修改的數(shù)據(jù)同步過來。
主從復(fù)制的原理:
主從復(fù)制主要有三個線程:binlog線程,I/O線程,SQL線程。
-
binlog線程:負責(zé)將主服務(wù)器上的數(shù)據(jù)更改寫入到二進制日志(Binary log)中。 -
I/O線程:負責(zé)從主服務(wù)器上讀取二進制日志(Binary log),并寫入從服務(wù)器的中繼日志(Relay log)中。 -
SQL線程:負責(zé)讀取中繼日志,解析出主服務(wù)器中已經(jīng)執(zhí)行的數(shù)據(jù)更改并在從服務(wù)器中重放
復(fù)制過程如下(圖片來源于網(wǎng)絡(luò)):
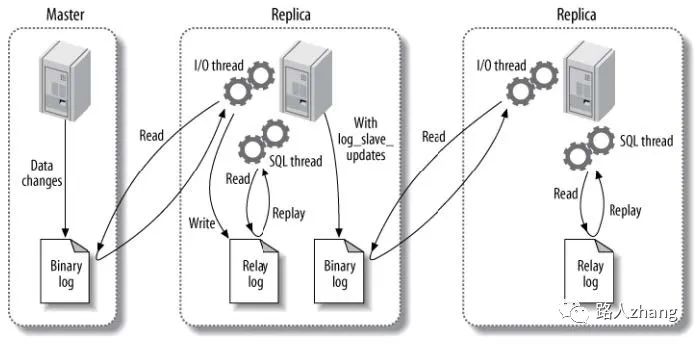
-
Master在每個事務(wù)更新數(shù)據(jù)完成之前,將操作記錄寫入到binlog中。 -
Slave從庫連接Master主庫,并且Master有多少個Slave就會創(chuàng)建多少個binlog dump線程。當(dāng)Master節(jié)點的binlog發(fā)生變化時,binlog dump會通知所有的Slave,并將相應(yīng)的binlog發(fā)送給Slave。 -
I/O線程接收到binlog內(nèi)容后,將其寫入到中繼日志(Relay log)中。 -
SQL線程讀取中繼日志,并在從服務(wù)器中重放。
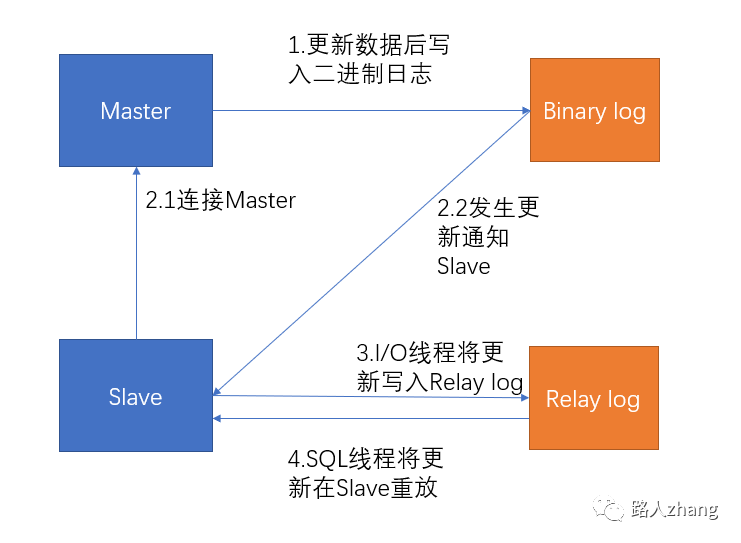
這里補充一個通俗易懂的圖。
主從復(fù)制的作用:
-
高可用和故障轉(zhuǎn)移 -
負載均衡 -
數(shù)據(jù)備份 -
升級測試
了解讀寫分離嗎? ***
讀寫分離主要依賴于主從復(fù)制,主從復(fù)制為讀寫分離服務(wù)。
讀寫分離的優(yōu)勢:
-
主服務(wù)器負責(zé)寫,從服務(wù)器負責(zé)讀,緩解了鎖的競爭 -
從服務(wù)器可以使用MyISAM,提升查詢性能及節(jié)約系統(tǒng)開銷 -
增加冗余,提高可用性