
Hudi 實(shí)踐 | Apache Hudi 在 B 站構(gòu)建實(shí)時(shí)數(shù)據(jù)湖的實(shí)踐
摘要:本文作者喻兆靖,介紹了為什么 B 站選擇 Flink + Hudi 的數(shù)據(jù)湖技術(shù)方案,以及針對(duì)其做出的優(yōu)化。主要內(nèi)容為:
傳統(tǒng)離線數(shù)倉痛點(diǎn) 數(shù)據(jù)湖技術(shù)方案 Hudi 任務(wù)穩(wěn)定性保障 數(shù)據(jù)入湖實(shí)踐 增量數(shù)據(jù)湖平臺(tái)收益 社區(qū)貢獻(xiàn) 未來的發(fā)展與思考
 GitHub 地址
GitHub 地址 一、傳統(tǒng)離線數(shù)倉痛點(diǎn)
1. 痛點(diǎn)
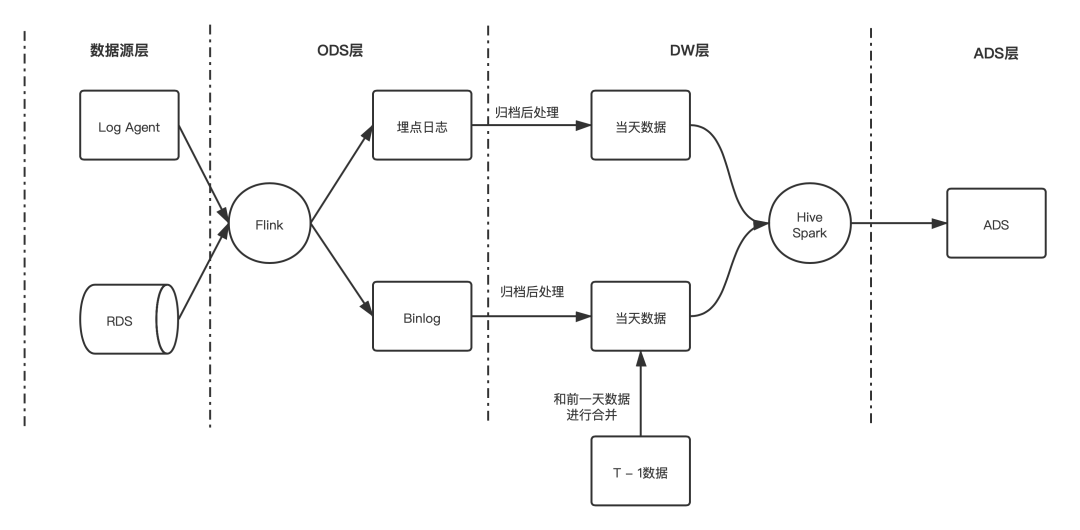
大規(guī)模的數(shù)據(jù)落地 HDFS 后,只能在凌晨分區(qū)歸檔后才能查詢并做下一步處理;
數(shù)據(jù)量較大的 RDS 數(shù)據(jù)同步,需要在凌晨分區(qū)歸檔后才能處理,并且需要做排序、去重以及 join 前一天分區(qū)的數(shù)據(jù),才能產(chǎn)生出當(dāng)天的數(shù)據(jù);
僅能通過分區(qū)粒度讀取數(shù)據(jù),在分流等場景下會(huì)出現(xiàn)大量的冗余 IO。
調(diào)度啟動(dòng)晚;
合并速度慢;
重復(fù)讀取多。
2. 痛點(diǎn)思考
調(diào)度啟動(dòng)晚
思路:既然 Flink 落 ODS 是準(zhǔn)實(shí)時(shí)寫入的,有明確的文件增量概念,可以使用基于文件的增量同 步,將清洗、補(bǔ)維、分流等邏輯通過增量的方式進(jìn)行處理,這樣就可以在 ODS 分區(qū)未歸檔的時(shí) 候就處理數(shù)據(jù),理論上數(shù)據(jù)的延遲只取決于最后一批文件的處理時(shí)間。
合并速度慢
思路:既然讀取已經(jīng)可以做到增量化了,那么合并也可以做到增量化,可以通過數(shù)據(jù)湖的能力結(jié) 合增量讀取完成合并的增量化。
重復(fù)讀取多
思路:重復(fù)讀取多的主要原因是分區(qū)的粒度太粗了,只能精確到小時(shí)/天級(jí)別。我們需要嘗試一 些更加細(xì)粒度的數(shù)據(jù)組織方案,將 Data Skipping 可以做到字段級(jí)別,這樣就可以進(jìn)行高效的數(shù) 據(jù)查詢了。
3. 解決方案: Magneto - 基于 Hudi 的增量數(shù)據(jù)湖平臺(tái)
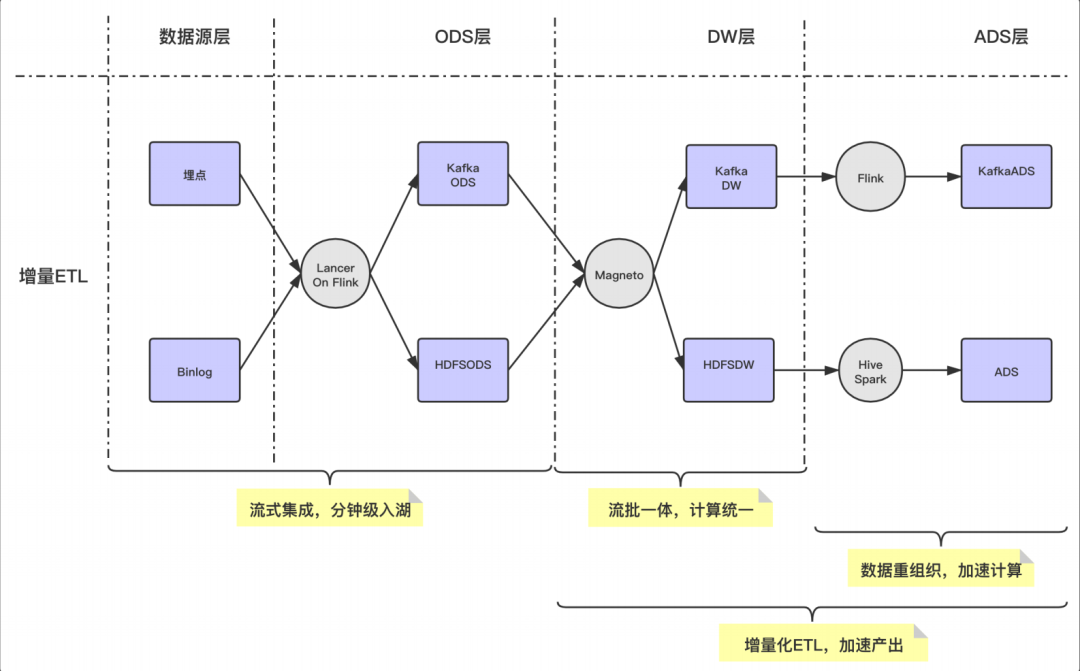
Flow
使用流式 Flow 的方式,統(tǒng)一離線和實(shí)時(shí)的 ETL Pipline。
Organizer
數(shù)據(jù)重組織,加速查詢;
支持增量數(shù)據(jù)的 compaction。
Engine
計(jì)算層使用 Flink,存儲(chǔ)層使用 Hudi。
Metadata
提煉表計(jì)算 SQL 邏輯;
標(biāo)準(zhǔn)化 Table Format 計(jì)算范式。
二、數(shù)據(jù)湖技術(shù)方案
1. Iceberg 與 Hudi 的取舍
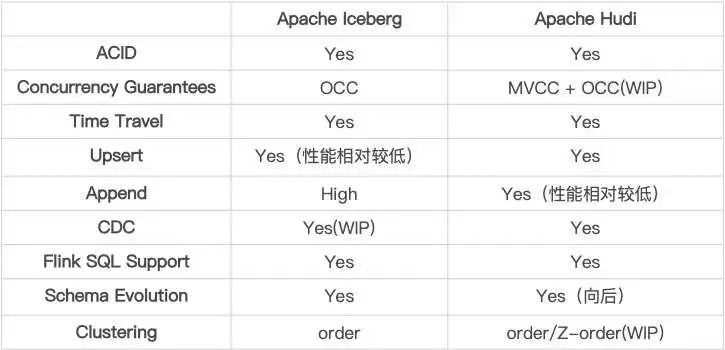
■ 1.1 技術(shù)細(xì)節(jié)對(duì)比
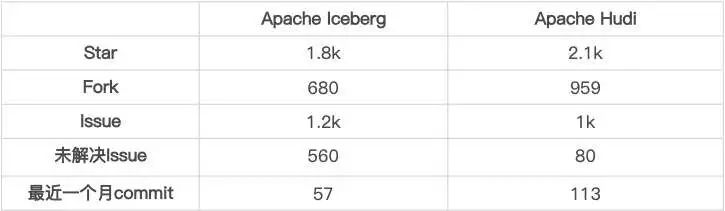
■ 1.2 社區(qū)活躍度對(duì)比
■ 1.3 總結(jié)
對(duì) Append 的支持
Iceberg 設(shè)計(jì)之初的主要支持方案,針對(duì)該場景做了很多優(yōu)化。Hudi 在 0.9 版本中對(duì) Appned 模式進(jìn)行了支持,目前在大部分場景下和 Iceberg 的差距不大, 目前的 0.10 版本中仍然在持續(xù)優(yōu)化,與 Iceberg 的性能已經(jīng)非常相近了。
對(duì) Upsert 的支持
Hudi 設(shè)計(jì)之初的主要支持方案,相對(duì)于 Iceberg 的設(shè)計(jì),性能和文件數(shù)量上有非常明顯的優(yōu) 勢(shì),并且 Compaction 流程和邏輯全部都是高度抽象的接口。Iceberg 對(duì)于 Upsert 的支持啟動(dòng)較晚,社區(qū)方案在性能、小文件等地方與 Hudi 還有比較明顯 的差距。
社區(qū)活躍度
Hudi 的社區(qū)相較于 Iceberg 社區(qū)明顯更加活躍,得益于社區(qū)活躍,Hudi 對(duì)于功能的豐富程度與 Iceberg 拉開了一定的差距。
2. 選擇 Flink + Hudi 作為寫入方式
我們選擇 Flink + Hudi 的方式集成 Hudi 的主要原因有三個(gè):
我們部分自己維護(hù)了 Flink 引擎,支撐了全公司的實(shí)時(shí)計(jì)算,從成本上考慮不想同時(shí)維護(hù)兩套計(jì)算引擎,尤其是在我們內(nèi)部 Spark 版本也做了很多內(nèi)部修改的情況下。 Spark + Hudi 的集成方案主要有兩種 Index 方案可供選擇,但是都有劣勢(shì): Bloom Index:使用 Bloom Index 的話,Spark 會(huì)在寫入的時(shí)候,每個(gè) task 都去 list 一遍所有的文件,讀取 footer 內(nèi)寫入的 Bloom 過濾數(shù)據(jù),這樣會(huì)對(duì)我們內(nèi)部壓力已經(jīng)非常大的 HDFS 造成非常恐怖的壓力。 Hbase Index:這種方式倒是可以做到 O(1) 的找到索引,但是需要引入外部依賴,這樣會(huì)使整個(gè)方案變的比較重。 我們需要和 Flink 增量處理的框架進(jìn)行對(duì)接。
3. Flink + Hudi 集成的優(yōu)化
■ 3.1 Hudi 0.8 版本集成 Flink 方案
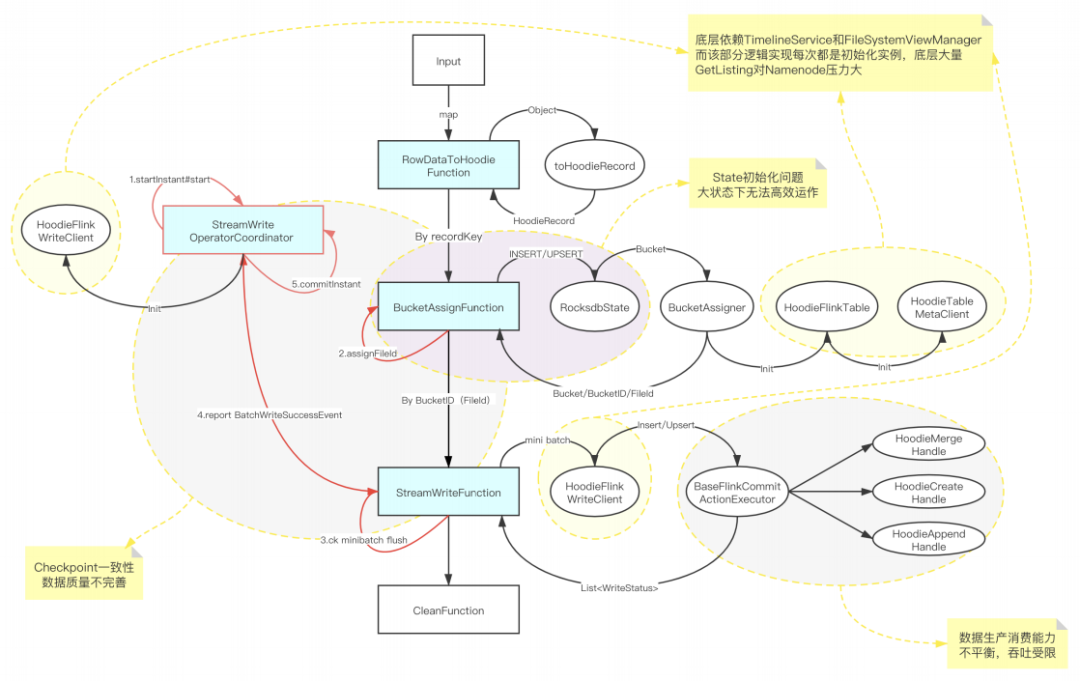
■ 3.2 Bootstrap State 冷啟動(dòng)
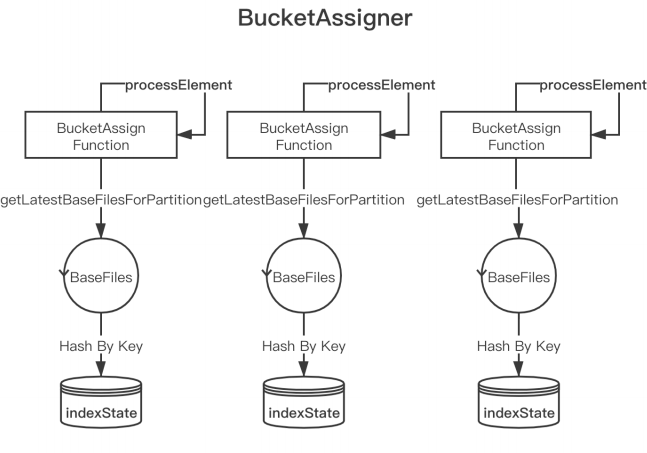
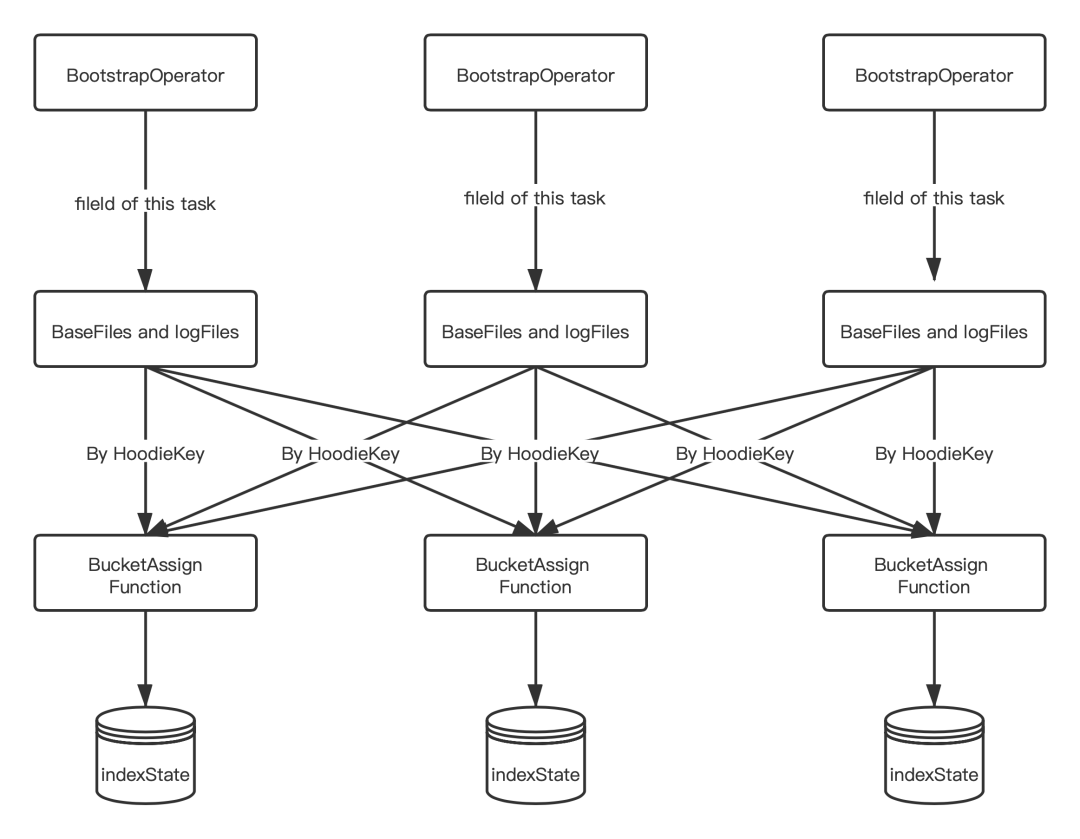
每個(gè) Bootstrap Operator 在初始化時(shí),加載屬于當(dāng)前 Task 的 fileId 相關(guān)的 BaseFile 和 logFile;
將 BaseFile 和 logFile 中的 recordKey 組裝成 HoodieKey,通過 Key By 的形式發(fā)送給 BucketAssignFunction,然后將 HoodieKey 作為索引存儲(chǔ)在 BucketAssignFunction 的 state 中。
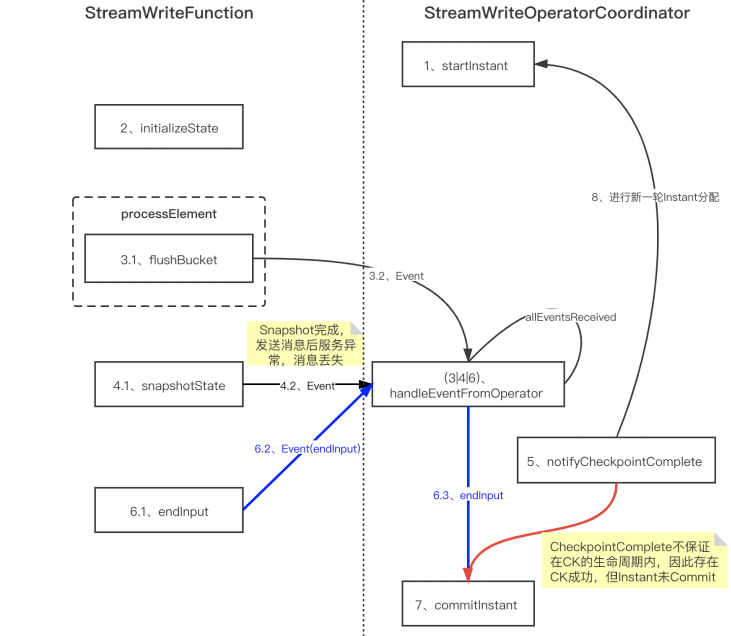
■ 3.3 Checkpoint 一致性優(yōu)化
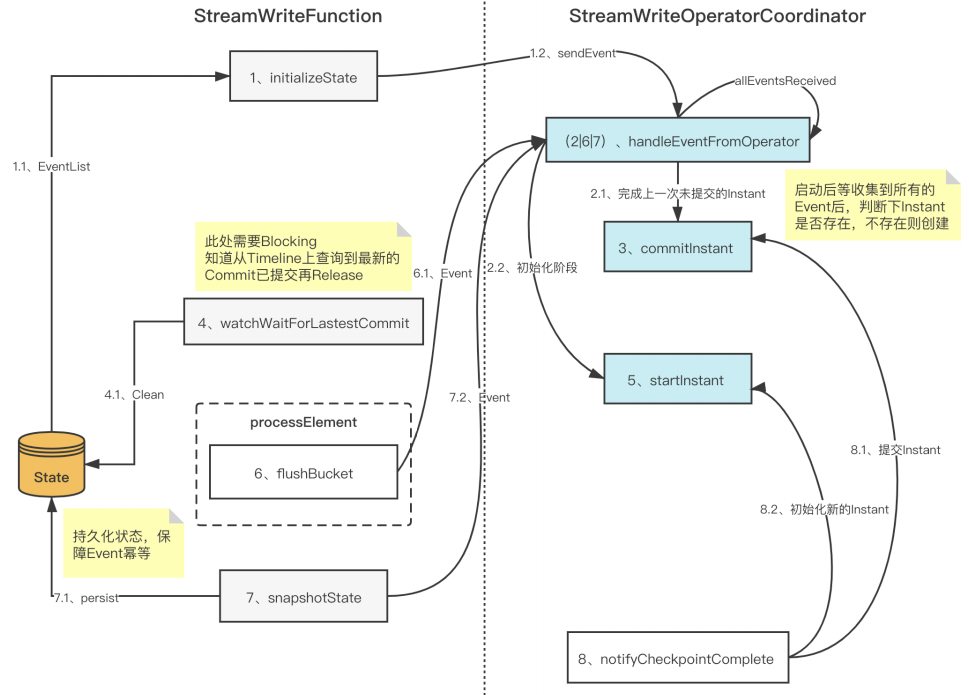
■ 3.4 Append 模式支持及優(yōu)化
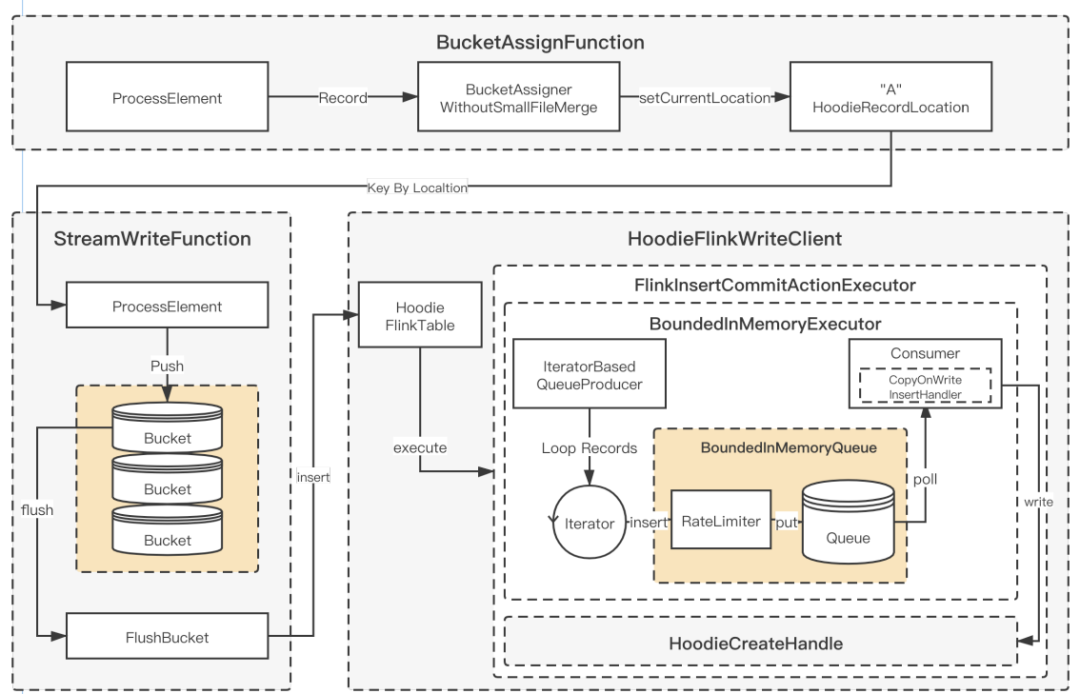
支持每次 FlushBucket 寫入一個(gè)新的文件,避免出現(xiàn)讀寫的放大;
添加參數(shù),支持關(guān)閉 BoundedInMemeoryQueue 內(nèi)部的限速機(jī)制,在 Flink Append 模式下只需要將 Queue 的大小和 Bucket buffer 設(shè)置成同樣的大小就可以了;
針對(duì)每個(gè) CK 產(chǎn)生的小文件,制定自定義 Compaction 計(jì)劃;
通過以上的開發(fā)和優(yōu)化之后,在純 Insert 場景下性能可達(dá)原先 COW 的 5 倍。
三、Hudi 任務(wù)穩(wěn)定性保障
1. Hudi 集成 Flink Metrics
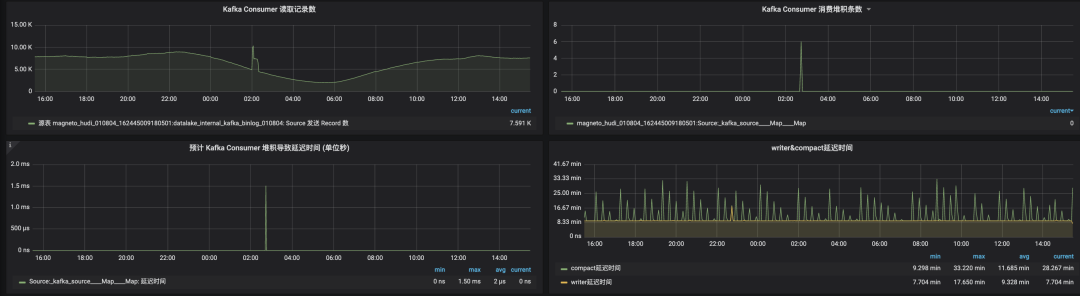
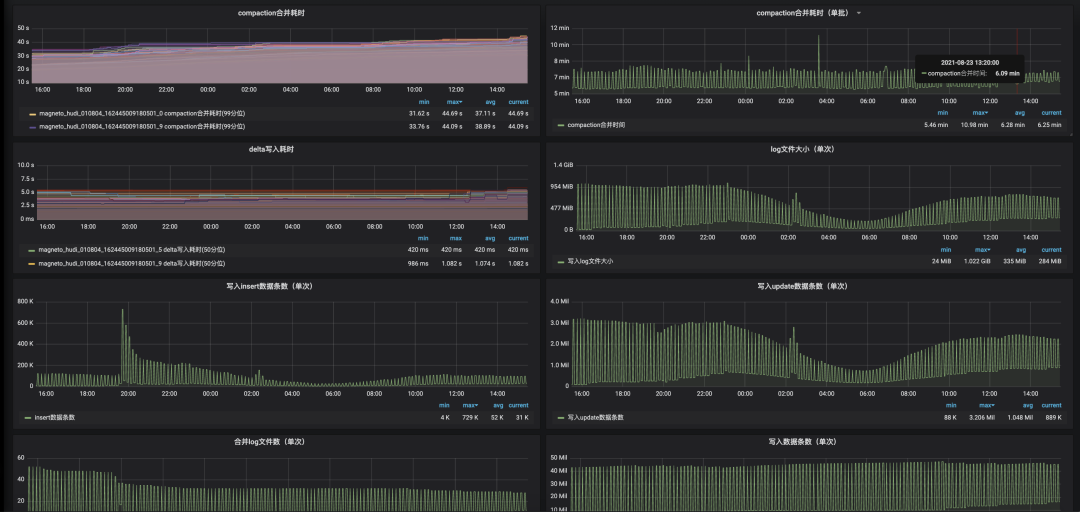
2. 系統(tǒng)內(nèi)數(shù)據(jù)校驗(yàn)
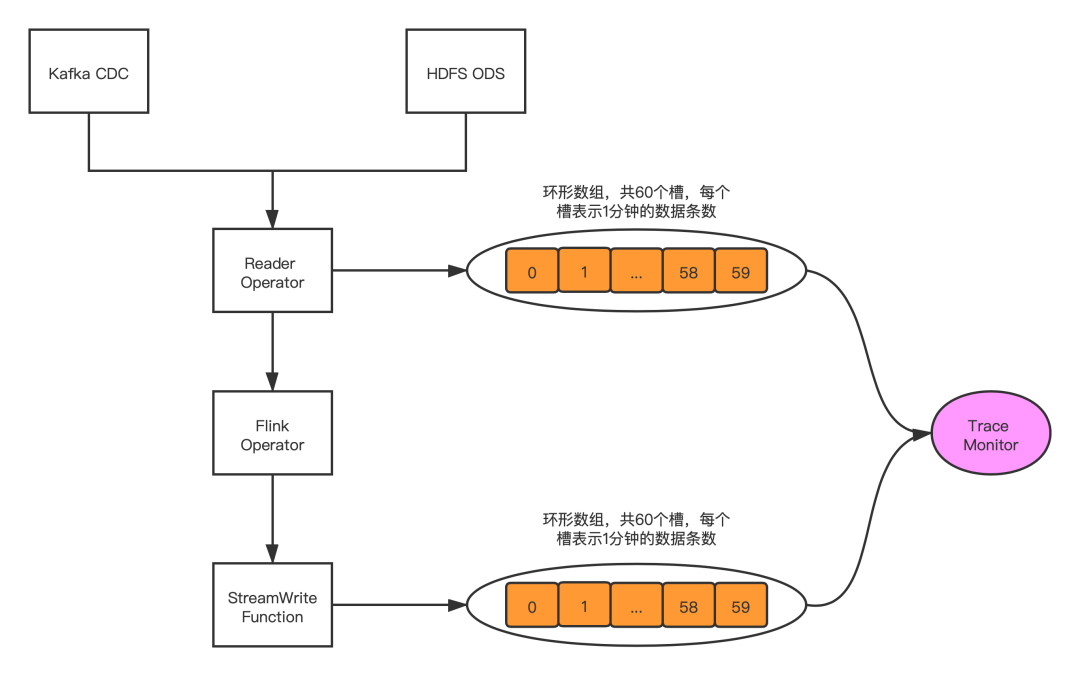
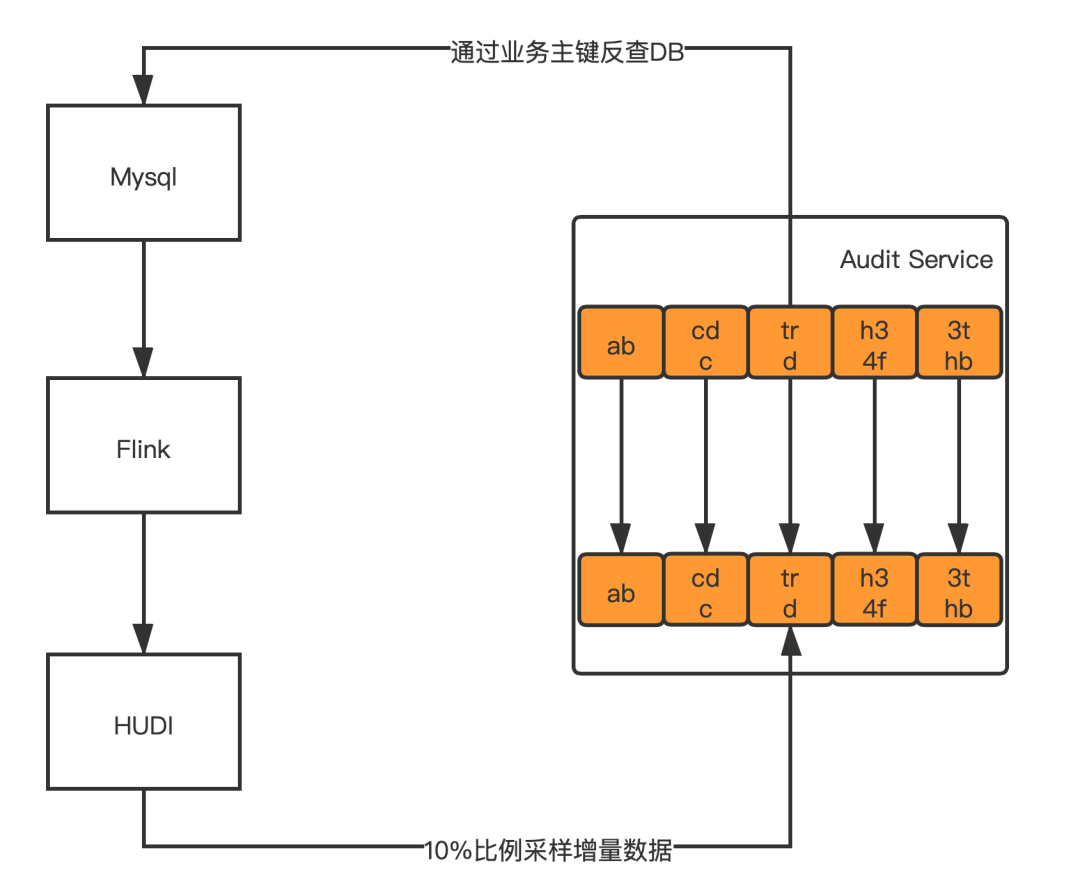
3. 系統(tǒng)外數(shù)據(jù)校驗(yàn)
四、數(shù)據(jù)入湖實(shí)踐
1. CDC數(shù)據(jù)入湖
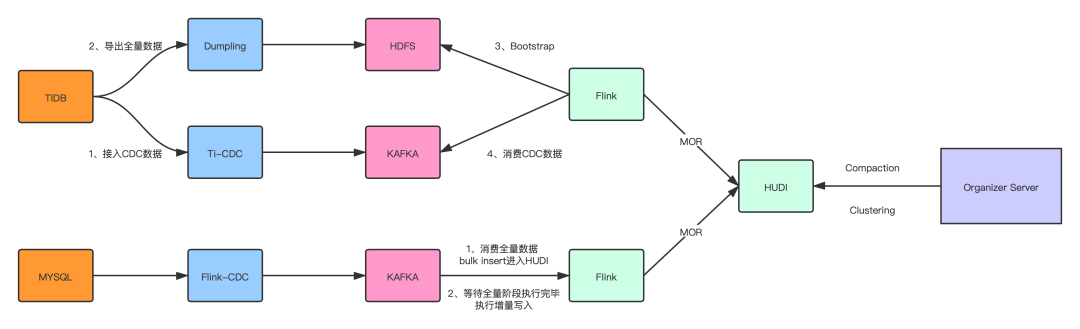
■ 1.1 TiDB入湖方案
啟動(dòng) TI-CDC,將 TIDB 的 CDC 數(shù)據(jù)寫入對(duì)應(yīng)的 Kafka topic;
利用 TiDB 提供的 Dumpling 組件,修改部分源碼,支持直接寫入 HDFS;
啟動(dòng) Flink 將全量數(shù)據(jù)通過 Bulk Insert 的方式寫入 Hudi;
消費(fèi)增量的 CDC 數(shù)據(jù),通過 Flink MOR 的方式寫入 Hudi。
■ 1.2 MySQL 入湖方案
啟動(dòng) Flink-CDC 任務(wù)將全量數(shù)據(jù)以及 CDC 數(shù)據(jù)導(dǎo)入 Kafka topic;
啟動(dòng) Flink Batch 任務(wù)讀取全量數(shù)據(jù),通過 Bulk Insert 寫入 Hudi;
切換為 Flink Streaming 任務(wù)將增量 CDC 數(shù)據(jù)通過 MOR 的方式寫入 Hudi。
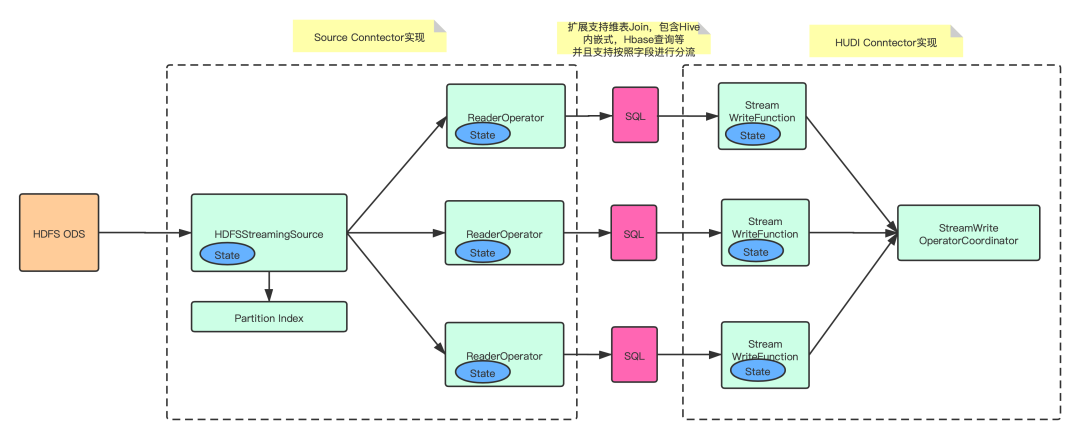
2. 日志數(shù)據(jù)增量入湖
實(shí)現(xiàn) HDFSStreamingSource 和 ReaderOperator,增量同步 ODS 的數(shù)據(jù)文件,并且通過寫入 ODS 的分區(qū)索引信息,減少對(duì) HDFS 的 list 請(qǐng)求;
支持 transform SQL 配置化,允許用戶進(jìn)行自定義邏輯轉(zhuǎn)化,包括但不限于維表 join、自定義 udf、按字段分流等;
實(shí)現(xiàn) Flink on Hudi 的 Append 模式,大幅提升不需要合并的數(shù)據(jù)寫入速率。
五、增量數(shù)據(jù)湖平臺(tái)收益
通過 Flink 增量同步大幅度提升了數(shù)據(jù)同步的時(shí)效性,分區(qū)就緒時(shí)間從 2:00~5:00 提前到 00:30 分內(nèi);
存儲(chǔ)引擎使用 Hudi,提供用戶基于 COW、MOR 的多種查詢方式,讓不同用戶可以根據(jù)自己 的應(yīng)用場景選擇合適的查詢方式,而不是單純的只能等待分區(qū)歸檔后查詢;
相較于之前數(shù)倉的 T+1 Binlog 合并方式,基于 Hudi 的自動(dòng) Compaction 使得用戶可以將 Hive 當(dāng)成 MySQL 的快照進(jìn)行查詢;
大幅節(jié)約資源,原先需要重復(fù)查詢的分流任務(wù)只需要執(zhí)行一次,節(jié)約大約 18000 core。
六、社區(qū)貢獻(xiàn)
上述優(yōu)化都已經(jīng)合并到 Hudi 社區(qū),B站在未來會(huì)進(jìn)一步加強(qiáng) Hudi 的建設(shè),與社區(qū)一起成?。
七、未來的發(fā)展與思考
平臺(tái)支持流批一體,統(tǒng)一實(shí)時(shí)與離線邏輯;
推進(jìn)數(shù)倉增量化,達(dá)成 Hudi ODS -> Flink -> Hudi DW -> Flink -> Hudi ADS 的全流程;
在 Flink 上支持 Hudi 的 Clustering,體現(xiàn)出 Hudi 在數(shù)據(jù)組織上的優(yōu)勢(shì),并探索 Z-Order 等加速多維查詢的性能表現(xiàn);
支持 inline clustering。
熱點(diǎn)推薦
Flink Forward Asia 2021 正式啟動(dòng)!議題火熱征集中! 30 萬獎(jiǎng)金等你來!第三屆 Apache Flink 極客挑戰(zhàn)賽暨 AAIG CUP 報(bào)名開始
 戳我,查看更多技術(shù)干貨!
戳我,查看更多技術(shù)干貨!