
Hudi 實踐 | 基于 Apache Hudi 構(gòu)建分析型數(shù)據(jù)湖

為了更好地發(fā)展業(yè)務(wù),每個組織都在迅速采用分析。在分析過程的幫助下,產(chǎn)品團隊正在接收來自用戶的反饋,并能夠以更快的速度交付新功能。通過分析提供的對用戶的更深入了解,營銷團隊能夠調(diào)整他們的活動以針對特定受眾。只有當(dāng)我們能夠大規(guī)模提供分析時,這一切才有可能。
對數(shù)據(jù)湖的需求
在 NoBrokercom[1],出于操作目的,事務(wù)數(shù)據(jù)存儲在基于 SQL 的數(shù)據(jù)庫中,事件數(shù)據(jù)存儲在 No-SQL 數(shù)據(jù)庫中。這些應(yīng)用程序 dB 未針對分析工作負載進行調(diào)整。此外,為了更全面地了解客戶和業(yè)務(wù),通常需要跨交易和事件數(shù)據(jù)加入數(shù)據(jù)。這些限制大大減慢了分析過程。為了解決這些問題,我們開發(fā)了一個名為 STARSHIP 的數(shù)據(jù)平臺,它提供了所有 Nobroker 數(shù)據(jù)的集中存儲庫,并且可以通過 SQL 訪問。
STARSHIP 正在為 40TB+ 快速發(fā)展的數(shù)據(jù)提供分析。在 Nobroker 上發(fā)生的任何事件或交易,都可以在 30 分鐘內(nèi)在 Starship 中進行分析。
它的一個組成部分是構(gòu)建針對分析優(yōu)化的數(shù)據(jù)存儲層。Parquet 和 ORC 數(shù)據(jù)格式提供此功能,但它們?nèi)鄙俑潞蛣h除功能。
Apache Hudi
Apache Hudi 是一個開源數(shù)據(jù)管理框架,提供列數(shù)據(jù)格式的記錄級插入、更新和刪除功能。我們在將數(shù)據(jù)帶到 STARSHIP 的所有 ETL 管道中廣泛使用 Apache Hudi。我們使用 Apache Hudi 的 DeltaStreamer 實用程序采用增量數(shù)據(jù)攝取。我們已經(jīng)能夠增強 DeltaStreamer 以適應(yīng)我們的業(yè)務(wù)邏輯和數(shù)據(jù)特征。
DeltaStreamer
在到達分布式云存儲之前,數(shù)據(jù)通過 Apache Hudi 中的多個相互連接的模塊進行處理。這些模塊可以獨立工作,也可以通過 Delta-streamer 實用程序工作,從而簡化整個 ETL 流程。盡管提供的默認功能有限,但它允許使用可擴展的 Java 類進行定制。
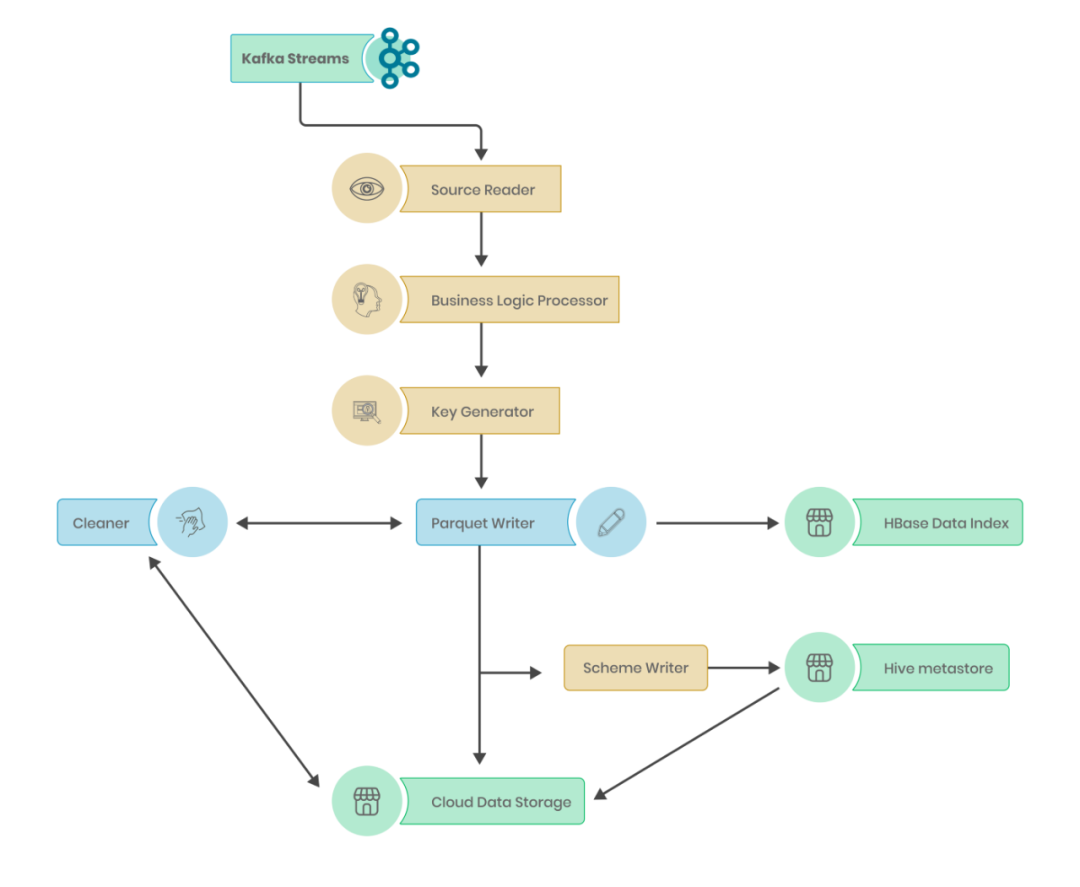
源讀取器
源讀取器是 Hudi 數(shù)據(jù)處理中的第一個也是最重要的模塊,用于從上游讀取數(shù)據(jù)。Hudi 提供支持類,可以從本地文件(如 JSON、Avro 和 Kafka 流)讀取。在我們的數(shù)據(jù)管道中,CDC 事件以 Avro 格式生成到 Kafka。我們擴展了源類以添加來自 Kafka 的增量讀取,每次讀取一個特定的編號。來自存儲的檢查點的消息,我們添加了一項功能,將 Kafka 偏移量附加為數(shù)據(jù)列。
# Reading data from Kafka from given Offset ranges
baseConsumerRDD = KafkaUtils.createRDD(
sparkContext,
KafkaParams,
offsetRanges,
consistent_location_strategy,
)
.filter(x -> x != null)
.filter(x -> x.value() != null);
# Adding Message offset to the data
baseRDD = baseConsumerRDD.map(x ->"{
\"starship_offset\":"+x.offset()
+","
+"\"starship_value\": "
+ x.value().toString() +
"}"
);
# Reading into Spark data frame & Applying schema
table_df = sparkSession.read()
.schema(table.getIncomingSchema())
.json(baseRDD)
.select(
"starship_value.*",
"starship_offset"
);在初始數(shù)據(jù)讀取之后,我們還強制執(zhí)行從 Kafka 模式注冊表或用戶提供的自定義模式獲取的模式。
業(yè)務(wù)邏輯處理器
從 Source reader 帶入 Spark 數(shù)據(jù)幀的數(shù)據(jù)將采用原始格式。為了使其可用于分析,我們需要對數(shù)據(jù)進行清理、標(biāo)準化和添加業(yè)務(wù)邏輯。STARSHIP 中的每個數(shù)據(jù)點都經(jīng)過以下轉(zhuǎn)換,以確保數(shù)據(jù)質(zhì)量。
? case標(biāo)準化:下/上case。
? 日期格式轉(zhuǎn)換:將各種字符串日期格式轉(zhuǎn)換為毫秒。
? 時區(qū)標(biāo)準化:將所有時區(qū)的數(shù)據(jù)轉(zhuǎn)換為 UTC。
? 電話號碼標(biāo)準化:將電話號碼格式化為“國家代碼 - 電話號碼”格式。
? 數(shù)據(jù)類型轉(zhuǎn)換:將引用的數(shù)字轉(zhuǎn)換為 Int/Long,轉(zhuǎn)換為文本格式等。
? 屏蔽和散列:使用散列算法屏蔽敏感信息。
? 自定義 SQL 查詢處理:如果需要對特定列應(yīng)用自定義過濾器,它們可以作為 SQL 子句傳遞。
? 地理點數(shù)據(jù)處理:將地理點數(shù)據(jù)處理為 Parquet 支持的格式。
? 列標(biāo)準化:將所有列名轉(zhuǎn)換為蛇形大小寫并展平任何嵌套列。
鍵生成器
Hudi 中的每一行都使用一組鍵表示,以提供行級別的更新和刪除。Hudi 要求每個數(shù)據(jù)點都有一個主鍵、一個排序鍵以及在分區(qū)的情況下還需要一個分區(qū)鍵。
? 主鍵:識別一行是更新還是新插入。
? 排序鍵:識別當(dāng)前批次事件中每個主鍵的最新事件,以防同一批次中同一行出現(xiàn)多個事件。
? 分區(qū)鍵:以分區(qū)格式寫入數(shù)據(jù)。
對來自 CDC 管道的事件進行排序變得很棘手,尤其是在同一邏輯處理多種類型的流時。為此,我們編寫了一個鍵生成器類,它根據(jù)輸入數(shù)據(jù)流源處理排序邏輯,并提供對多個鍵作為主鍵的支持。
Parquet寫入器
一旦數(shù)據(jù)處于最終轉(zhuǎn)換格式,Hudi writer 將負責(zé)寫入過程。每個新的數(shù)據(jù)攝取周期稱為一次提交并與提交編號相關(guān)聯(lián)。
? 提交開始:攝取從在云存儲中創(chuàng)建的“
.commit_requested”文件開始。 ? 提交飛行:一旦處理完所有轉(zhuǎn)換后開始寫入過程,就會創(chuàng)建一個“
.commit_inflight”文件。 ? 提交結(jié)束:一旦數(shù)據(jù)成功寫入磁盤,就會創(chuàng)建最終的“
.commit”文件。
只有當(dāng)最終的 .commit 文件被創(chuàng)建時,攝取過程才被稱為成功。萬一發(fā)生故障,Hudi writer 會回滾對 parquet 文件所做的任何更改,并從最新的可用 .commit 文件中獲取新的攝取。如果我們每次提交都編寫新的 Parquet 文件,我們最終會得到一個很大的數(shù)字。小文件會減慢分析過程。為此,每次有新插入時,Hudi writer 會識別是否有任何小文件并向它們添加新插入,而不是寫入新文件。
在 Nobroker,我們確保每個 parquet 文件的大小至少為 100MB,以優(yōu)化分析的速度。
數(shù)據(jù)索引
除了寫入數(shù)據(jù),Hudi 還跟蹤特定行的存儲位置,以加快更新和刪除速度。此信息存儲在稱為索引的專用數(shù)據(jù)結(jié)構(gòu)中。Hudi 提供了多種索引實現(xiàn),例如布隆過濾器、簡單索引和 HBase 索引Hudi表。我們從布隆過濾器開始,但隨著數(shù)據(jù)的增加和用例的發(fā)展,我們轉(zhuǎn)向 HBase 索引,它提供了非常快速的行元數(shù)據(jù)檢索。
HBase 索引將我們的 ETL 管道的資源需求減少了 30%。
Schema寫入器
一旦數(shù)據(jù)被寫入云存儲,我們應(yīng)該能夠在我們的平臺上自動發(fā)現(xiàn)它。為此,Hudi 提供了一個模式編寫器,它可以更新任何用戶指定的模式存儲庫,了解新數(shù)據(jù)庫、表和添加到數(shù)據(jù)湖的列。我們使用 Hive 作為我們的集中Schema存儲庫。默認情況下Hudi 將源數(shù)據(jù)中的所有列以及所有元數(shù)據(jù)字段添加到模式存儲庫中。由于我們的數(shù)據(jù)平臺面向業(yè)務(wù),我們確保在編寫Schema時跳過元數(shù)據(jù)字段。這對性能沒有影響,但為分析用戶提供了更好的體驗。
在 Schema writer 的幫助下,業(yè)務(wù)可以在上游數(shù)據(jù)中添加一個新的特性,并且它可以在我們的數(shù)據(jù)平臺上使用,而無需任何人工干預(yù)。
Cleaner
在攝取過程中,會創(chuàng)建大量元數(shù)據(jù)文件和臨時文件。如果保持不變,它們會降低分析性能。Hudi 確保所有不必要的文件在需要時被歸檔和刪除。每次發(fā)生新的攝取時,一些現(xiàn)有的 Parquet 文件都會推出一個新版本。舊版本可用于跟蹤事件時間線和使查詢運行更長時間。他們慢慢地填滿了存儲空間。為此,Cleaner 提供了 2 種減少存儲空間的方法
? KEEP_LATEST_FILE_VERSIONS :最新的文件版本被保留,而舊的被刪除。
? KEEP_LATEST_COMMITS :僅保留 n 個最新提交寫入的文件版本。
我們的數(shù)據(jù)平臺經(jīng)過調(diào)整,可在 1 分鐘內(nèi)提供交互式查詢/報告。同時,我們確保舊文件版本最多保留 1 小時,以支持長時間運行的數(shù)據(jù)科學(xué)工作負載。
Apache Hudi 是 Starship Data 平臺最重要的部分之一。我們還有更多組件提供其他功能,例如可視化、交互式查詢引擎等。
引用鏈接
[1] NoBrokercom: [https://medium.com/@NoBroker](https://medium.com/@NoBroker)