
Zookeeper面試題總結(jié)
本文公眾號來源:艾小仙
作者:艾小仙
本文已收錄至我的GitHub
【對線面試官】系列?一周兩篇持續(xù)更新中!
前文回顧:什么是ZooKeeper?
談?wù)勀銓ookeeper的理解?
Zookeeper是一個開源的分布式協(xié)調(diào)服務(wù),由雅虎公司創(chuàng)建,由于最初雅虎公司的內(nèi)部研究小組的項目大多以動物的名字命名,所以后來就以Zookeeper(動物管理員)來命名了,而就是由Zookeeper來負責(zé)這些分布式組件環(huán)境的協(xié)調(diào)工作。
他的目標是可以提供高性能、高可用和順序訪問控制的能力,同時也是為了解決分布式環(huán)境下數(shù)據(jù)一致性的問題。
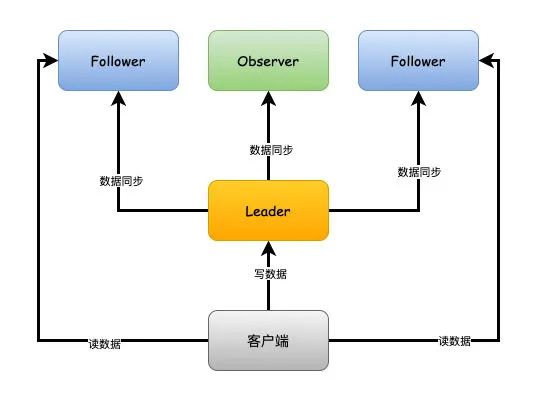
集群
首先,Zookeeper集群中有幾個關(guān)鍵的概念,Leader、Follower和Observer,Zookeeper中通常只有Leader節(jié)點可以寫入,F(xiàn)ollower和Observer都只是負責(zé)讀,但是Follower會參與節(jié)點的選舉和過半寫成功,Observer則不會,他只是單純的提供讀取數(shù)據(jù)的功能。
通常這樣設(shè)置的話,是為了避免太多的從節(jié)點參與過半寫的過程,導(dǎo)致影響性能,這樣Zookeeper只要使用一個幾臺機器的小集群就可以實現(xiàn)高性能了,如果要橫向擴展的話,只需要增加Observer節(jié)點即可。
Zookeeper建議集群節(jié)點個數(shù)為奇數(shù),只要超過一半的機器能夠正常提供服務(wù),那么整個集群都是可用的狀態(tài)。
數(shù)據(jù)節(jié)點Znode
Zookeeper中數(shù)據(jù)存儲于內(nèi)存之中,這個數(shù)據(jù)節(jié)點就叫做Znode,他是一個樹形結(jié)構(gòu),比如/a/b/c類似。
而Znode又分為持久節(jié)點、臨時節(jié)點、順序節(jié)點三大類。
持久節(jié)點是指只要被創(chuàng)建,除非主動移除,否則都應(yīng)該一直保存在Zookeeper中。
臨時節(jié)點不同的是,他的生命周期和客戶端Session會話一樣,會話失效,那么臨時節(jié)點就會被移除。
還有就是臨時順序節(jié)點和持久順序節(jié)點,除了基本的特性之外,子節(jié)點的名稱還具有有序性。
會話Session
會話自然就是指Zookeeper客戶端和服務(wù)端之間的通信,他們使用TCP長連接的方式保持通信,通常,肯定會有心跳檢測的機制,同時他可以接受來自服務(wù)器的Watch事件通知。
事件監(jiān)聽器Wather
用戶可以在指定的節(jié)點上注冊Wather,這樣在事件觸發(fā)的時候,客戶端就會收到來自服務(wù)端的通知。
權(quán)限控制ACL
Zookeeper使用ACL來進行權(quán)限的控制,包含以下5種:
CREATE,創(chuàng)建子節(jié)點權(quán)限 DELETE,刪除子節(jié)點權(quán)限 READ,獲取節(jié)點數(shù)據(jù)和子節(jié)點列表權(quán)限 WRITE,更新節(jié)點權(quán)限 ADMIN,設(shè)置節(jié)點ACL權(quán)限
所以,Zookeeper通過集群的方式來做到高可用,通過內(nèi)存數(shù)據(jù)節(jié)點Znode來達到高性能,但是存儲的數(shù)據(jù)量不能太大,通常適用于讀多寫少的場景。
Zookeeper有哪些應(yīng)用場景?
命名服務(wù)Name Service,依賴Zookeeper可以生成全局唯一的節(jié)點ID,來對分布式系統(tǒng)中的資源進行管理。 分布式協(xié)調(diào),這是Zookeeper的核心使用了。利用Wather的監(jiān)聽機制,一個系統(tǒng)的某個節(jié)點狀態(tài)發(fā)生改變,另外系統(tǒng)可以得到通知。 集群管理,分布式集群中狀態(tài)的監(jiān)控和管理,使用Zookeeper來存儲。 Master選舉,利用Zookeeper節(jié)點的全局唯一性,同時只有一個客戶端能夠創(chuàng)建成功的特點,可以作為Master選舉使用,創(chuàng)建成功的則作為Master。 分布式鎖,利用Zookeeper創(chuàng)建臨時順序節(jié)點的特性。
說說Wather監(jiān)聽機制和它的原理?
Zookeeper可以提供分布式數(shù)據(jù)的發(fā)布/訂閱功能,依賴的就是Wather監(jiān)聽機制。
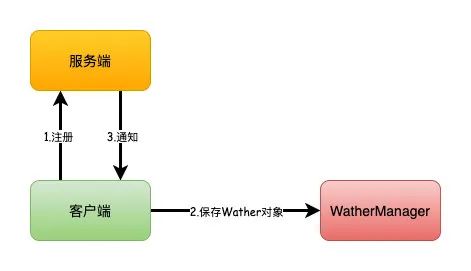
客戶端可以向服務(wù)端注冊Wather監(jiān)聽,服務(wù)端的指定事件觸發(fā)之后,就會向客戶端發(fā)送一個事件通知。
他有幾個特性:
一次性:一旦一個Wather觸發(fā)之后,Zookeeper就會將它從存儲中移除 客戶端串行:客戶端的Wather回調(diào)處理是串行同步的過程,不要因為一個Wather的邏輯阻塞整個客戶端 輕量:Wather通知的單位是WathedEvent,只包含通知狀態(tài)、事件類型和節(jié)點路徑,不包含具體的事件內(nèi)容,具體的時間內(nèi)容需要客戶端主動去重新獲取數(shù)據(jù)
主要流程如下:
客戶端向服務(wù)端注冊Wather監(jiān)聽 保存Wather對象到客戶端本地的WatherManager中 服務(wù)端Wather事件觸發(fā)后,客戶端收到服務(wù)端通知,從WatherManager中取出對應(yīng)Wather對象執(zhí)行回調(diào)邏輯
Zookeeper是如何保證數(shù)據(jù)一致性的?
Zookeeper通過ZAB原子廣播協(xié)議來實現(xiàn)數(shù)據(jù)的最終順序一致性,他是一個類似2PC兩階段提交的過程。
由于Zookeeper只有Leader節(jié)點可以寫入數(shù)據(jù),如果是其他節(jié)點收到寫入數(shù)據(jù)的請求,則會將之轉(zhuǎn)發(fā)給Leader節(jié)點。
主要流程如下:
Leader收到請求之后,將它轉(zhuǎn)換為一個proposal提議,并且為每個提議分配一個全局唯一遞增的事務(wù)ID:zxid,然后把提議放入到一個FIFO的隊列中,按照FIFO的策略發(fā)送給所有的Follower Follower收到提議之后,以事務(wù)日志的形式寫入到本地磁盤中,寫入成功后返回ACK給Leader Leader在收到超過半數(shù)的Follower的ACK之后,即可認為數(shù)據(jù)寫入成功,就會發(fā)送commit命令給Follower告訴他們可以提交proposal了

ZAB包含兩種基本模式,崩潰恢復(fù)和消息廣播。
整個集群服務(wù)在啟動、網(wǎng)絡(luò)中斷或者重啟等異常情況的時候,首先會進入到崩潰恢復(fù)狀態(tài),此時會通過選舉產(chǎn)生Leader節(jié)點,當集群過半的節(jié)點都和Leader狀態(tài)同步之后,ZAB就會退出恢復(fù)模式。之后,就會進入消息廣播的模式。
那么,Zookeeper如何進行Leader選舉的?
Leader的選舉可以分為兩個方面,同時選舉主要包含事務(wù)zxid和myid,節(jié)點主要包含LEADING\FOLLOWING\LOOKING3個狀態(tài)。
服務(wù)啟動期間的選舉 服務(wù)運行期間的選舉
服務(wù)啟動期間的選舉
首先,每個節(jié)點都會對自己進行投票,然后把投票信息廣播給集群中的其他節(jié)點 節(jié)點接收到其他節(jié)點的投票信息,然后和自己的投票進行比較,首先zxid較大的優(yōu)先,如果zxid相同那么則會去選擇myid更大者,此時大家都是LOOKING的狀態(tài) 投票完成之后,開始統(tǒng)計投票信息,如果集群中過半的機器都選擇了某個節(jié)點機器作為leader,那么選舉結(jié)束 最后,更新各個節(jié)點的狀態(tài),leader改為LEADING狀態(tài),follower改為FOLLOWING狀態(tài)
服務(wù)運行期間的選舉
如果開始選舉出來的leader節(jié)點宕機了,那么運行期間就會重新進行l(wèi)eader的選舉。
leader宕機之后,非observer節(jié)點都會把自己的狀態(tài)修改為LOOKING狀態(tài),然后重新進入選舉流程 生成投票信息(myid,zxid),同樣,第一輪的投票大家都會把票投給自己,然后把投票信息廣播出去 接下來的流程和上面的選舉是一樣的,都會優(yōu)先以zxid,然后選擇myid,最后統(tǒng)計投票信息,修改節(jié)點狀態(tài),選舉結(jié)束
那選舉之后又是怎樣進行數(shù)據(jù)同步的?
那實際上Zookeeper在選舉之后,F(xiàn)ollower和Observer(統(tǒng)稱為Learner)就會去向Leader注冊,然后就會開始數(shù)據(jù)同步的過程。
數(shù)據(jù)同步包含3個主要值和4種形式。
PeerLastZxid:Learner服務(wù)器最后處理的ZXID
minCommittedLog:Leader提議緩存隊列中最小ZXID
maxCommittedLog:Leader提議緩存隊列中最大ZXID
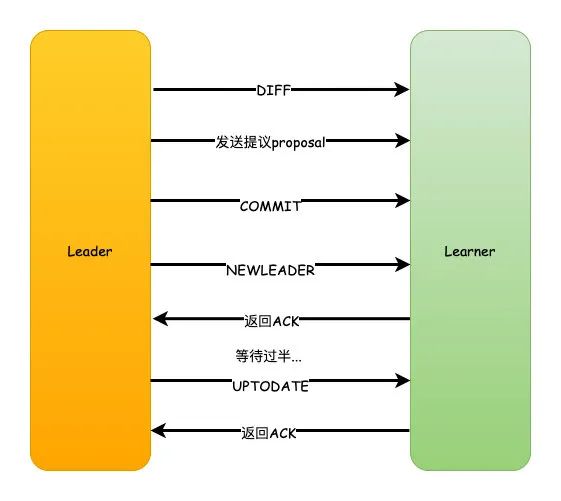
直接差異化同步 DIFF同步
如果PeerLastZxid在minCommittedLog和maxCommittedLog之間,那么則說明Learner服務(wù)器還沒有完全同步最新的數(shù)據(jù)。
首先Leader向Learner發(fā)送DIFF指令,代表開始差異化同步,然后把差異數(shù)據(jù)(從PeerLastZxid到maxCommittedLog之間的數(shù)據(jù))提議proposal發(fā)送給Learner 發(fā)送完成之后發(fā)送一個NEWLEADER命令給Learner,同時Learner返回ACK表示已經(jīng)完成了同步 接著等待集群中過半的Learner響應(yīng)了ACK之后,就發(fā)送一個UPTODATE命令,Learner返回ACK,同步流程結(jié)束
先回滾再差異化同步 TRUNC+DIFF同步
這個設(shè)置針對的是一個異常的場景。
如果Leader剛生成一個proposal,還沒有來得及發(fā)送出去,此時Leader宕機,重新選舉之后作為Follower,但是新的Leader沒有這個proposal數(shù)據(jù)。
舉個栗子:
假設(shè)現(xiàn)在的Leader是A,minCommittedLog=1,maxCommittedLog=3,剛好生成的一個proposal的ZXID=4,然后掛了。
重新選舉出來的Leader是B,B之后又處理了2個提議,然后minCommittedLog=1,maxCommittedLog=5。
這時候A的PeerLastZxid=4,在(1,5)之間。
那么這一條只存在于A的提議怎么處理?
A要進行事務(wù)回滾,相當于拋棄這條數(shù)據(jù),并且回滾到最接近于PeerLastZxid的事務(wù),對于A來說,也就是PeerLastZxid=3。
流程和DIFF一致,只是會先發(fā)送一個TRUNC命令,然后再執(zhí)行差異化DIFF同步。
僅回滾同步 TRUNC同步
針對PeerLastZxid大于maxCommittedLog的場景,流程和上述一致,事務(wù)將會被回滾到maxCommittedLog的記錄。
這個其實就更簡單了,也就是你可以認為TRUNC+DIFF中的例子,新的Leader B沒有處理提議,所以B中minCommittedLog=1,maxCommittedLog=3。
所以A的PeerLastZxid=4就會大于maxCommittedLog了,也就是A只需要回滾就行了,不需要執(zhí)行差異化同步DIFF了。
全量同步 SNAP同步
適用于兩個場景:
PeerLastZxid小于minCommittedLog Leader服務(wù)器上沒有提議緩存隊列,并且PeerLastZxid不等于Leader的最大ZXID
這兩種場景下,Leader將會發(fā)送SNAP命令,把全量的數(shù)據(jù)都發(fā)送給Learner進行同步。
有可能會出現(xiàn)數(shù)據(jù)不一致的問題嗎?
還是會存在的,我們可以分成3個場景來描述這個問題。
查詢不一致
因為Zookeeper是過半成功即代表成功,假設(shè)我們有5個節(jié)點,如果123節(jié)點寫入成功,如果這時候請求訪問到4或者5節(jié)點,那么有可能讀取不到數(shù)據(jù),因為可能數(shù)據(jù)還沒有同步到4、5節(jié)點中,也可以認為這算是數(shù)據(jù)不一致的問題。
解決方案可以在讀取前使用sync命令。
leader未發(fā)送proposal宕機
這也就是數(shù)據(jù)同步說過的問題。
leader剛生成一個proposal,還沒有來得及發(fā)送出去,此時leader宕機,重新選舉之后作為follower,但是新的leader沒有這個proposal。
這種場景下的日志將會被丟棄。
leader發(fā)送proposal成功,發(fā)送commit前宕機
如果發(fā)送proposal成功了,但是在將要發(fā)送commit命令前宕機了,如果重新進行選舉,還是會選擇zxid最大的節(jié)點作為leader,因此,這個日志并不會被丟棄,會在選舉出leader之后重新同步到其他節(jié)點當中。
如果作為注冊中心,Zookeeper 和Eureka、Consul、Nacos有什么區(qū)別?
| Nacos | Eureka | Consul | Zookeeper | |
|---|---|---|---|---|
| 一致性協(xié)議 | CP+AP | AP | CP | CP |
| 健康檢查 | TCP/HTTP/MYSQL/Client Beat | Client Beat | TCP/HTTP/gRPC/Cmd | Keep Alive |
| 負載均衡策略 | 權(quán)重/ metadata/Selector | Ribbon | Fabio | — |
| 雪崩保護 | 有 | 有 | 無 | 無 |
| 自動注銷實例 | 支持 | 支持 | 不支持 | 支持 |
| 訪問協(xié)議 | HTTP/DNS | HTTP | HTTP/DNS | TCP |
| 監(jiān)聽支持 | 支持 | 支持 | 支持 | 支持 |
| 多數(shù)據(jù)中心 | 支持 | 支持 | 支持 | 不支持 |
| 跨注冊中心同步 | 支持 | 不支持 | 支持 | 不支持 |
| SpringCloud集成 | 支持 | 支持 | 支持 | 不支持 |
| Dubbo集成 | 支持 | 不支持 | 不支持 | 支持 |
| K8S集成 | 支持 | 不支持 | 支持 | 不支持 |
最后,你對于CAP理論怎么理解?
CAP是一個分布式系統(tǒng)設(shè)計的定理,他包含3個部分,并且最多只能同時滿足其中兩個。
Consistency一致性,因為在一個分布式系統(tǒng)中,數(shù)據(jù)肯定需要在不同的節(jié)點之間進行同步,就比如Zookeeper,所以一致性就是指的是數(shù)據(jù)在不同的節(jié)點之間怎樣保證一致性,對于純理論的C而言,默認的規(guī)則是忽略掉延遲的,因為如果考慮延遲的話,因為數(shù)據(jù)同步的過程無論如何都會有延遲的,延遲的過程必然會帶來數(shù)據(jù)的不一致。 Availability可用性,這個指的是對于每一個請求,節(jié)點總是可以在合理的時間返回合理的響應(yīng),比如Zookeeper在進行數(shù)據(jù)同步時,無法對外提供讀寫服務(wù),不滿足可用性要求。這里常有的一個例子是說Zookeeper選舉期間無法提供服務(wù)不滿足A,這個說法并不準確,因為CAP關(guān)注的是數(shù)據(jù)的讀寫,選舉可以認為不在考慮范圍之內(nèi)。所以,可以認為對于數(shù)據(jù)的讀寫,無論響應(yīng)超時還是返回異常都可以認為是不滿足A。 Partition-tolerance分區(qū)容錯性,因為在一個分布式系統(tǒng)當中,很有可能由于部分節(jié)點的網(wǎng)絡(luò)問題導(dǎo)致整個集群之間的網(wǎng)絡(luò)不連通,所以就產(chǎn)生了網(wǎng)絡(luò)分區(qū),整個集群的環(huán)境被分隔成不同的的子網(wǎng),所以,一般說網(wǎng)絡(luò)不可能100%的不產(chǎn)生問題,所以P一定會存在。
為什么只能同時滿足CAP中的兩個呢?
以A\B兩個節(jié)點同步數(shù)據(jù)舉例,由于P的存在,那么可能AB同步數(shù)據(jù)出現(xiàn)問題。
如果選擇AP,由于A的數(shù)據(jù)未能正確同步到B,所以AB數(shù)據(jù)不一致,無法滿足C。
如果選擇CP,那么B就不能提供服務(wù),就無法滿足A。
巨人的肩膀:
https://my.oschina.net/yunqi/blog/3040280
《從Paxos到Zookeeper分布式一致性原理與實踐》
除了Zookeeper還可以看看其他面試題喲!目前已經(jīng)連載12篇啦!進度是一周更新兩篇,歡迎持續(xù)關(guān)注
【對線面試官】Java注解 【對線面試官】Java泛型 【對線面試官】 Java NIO 【對線面試官】Java反射 && 動態(tài)代理 【對線面試官】多線程基礎(chǔ) 【對線面試官】 CAS 【對線面試官】synchronized 【對線面試官】AQS&&ReentrantLock 【對線面試官】線程池 【對線面試官】ThreadLocal 【對線面試官】SpringMVC ...
掃描二維碼關(guān)注【面試造火箭】