
Python 實現(xiàn) Excel 的讀寫操作「讀取 Excel 文件」
你好,我是悅創(chuàng)。
上一篇寫文件已經(jīng)搞定「Python 實現(xiàn) Excel 的讀寫操作「寫入Excel文件」」,接下來就要學(xué)習(xí)下 Excel 的讀操作。
寫入 Excel 的庫是 xlwt ,對應(yīng) write ;讀取 Excel 的庫是 xlrd ,對應(yīng)r ead ;xlrd 的安裝命令:pip install xlrd
首先導(dǎo)入 xlrd,然后打開前面寫好的 “虛假用戶數(shù)據(jù).xls”,代碼如下:
import xlrd
wb = xlrd.open_workbook('虛假用戶數(shù)據(jù).xls')
打開了文件之后,wb 代表當(dāng)前文件。讀取數(shù)據(jù),需要指定具體的 sheet,有兩種方式,分別是通過索引和名稱,如下代碼:
sheets = wb.sheets() # 獲取文件中全部的sheet,返回結(jié)構(gòu)是list。
sheet = sheets[0] # 通過索引順序獲取。
sheet = wb.sheet_by_index(0) # 直接通過索引順序獲取。
sheet = wb.sheet_by_name('第一個sheet') # 通過名稱獲取。
此時獲取到了 sheet 對象,然后從這里取出數(shù)據(jù)就可以。
sheet 的內(nèi)容是二維表格,取數(shù)據(jù)全靠行數(shù)和列數(shù),定位具體的格子,然后拿到格子里面的內(nèi)容。
「如果我們要取出全部的內(nèi)容咋辦?」 獲取 sheet 的總行數(shù)和列數(shù),然后循環(huán)就行。
取出總行數(shù)和列數(shù)的代碼如下:
rows = sheet.nrows
cols = sheet.ncols
rows就是總行數(shù),cols是總列數(shù)。有這兩值,然后兩層循環(huán),取數(shù)據(jù)就行。
那我們需要把 Excel 的每一行數(shù)據(jù)提取出來,而且我們一行有四列數(shù)據(jù)。四列數(shù)據(jù)變化的是:「列數(shù)」,不變的是:「行數(shù)」 —— 所以率先循環(huán)的就是 「行」 后循環(huán)的是 「列」 。
「Ps:第一層循環(huán)后會等待第二層循環(huán)全部循環(huán)完畢,后再繼續(xù)循環(huán)外層循環(huán)「第一層」。」
如下代碼:
for row in range(rows):
for col in range(cols):
print(sheet.cell(row, col).value, end=' , ')
print('\n')
「效果圖【只截圖頭部】:」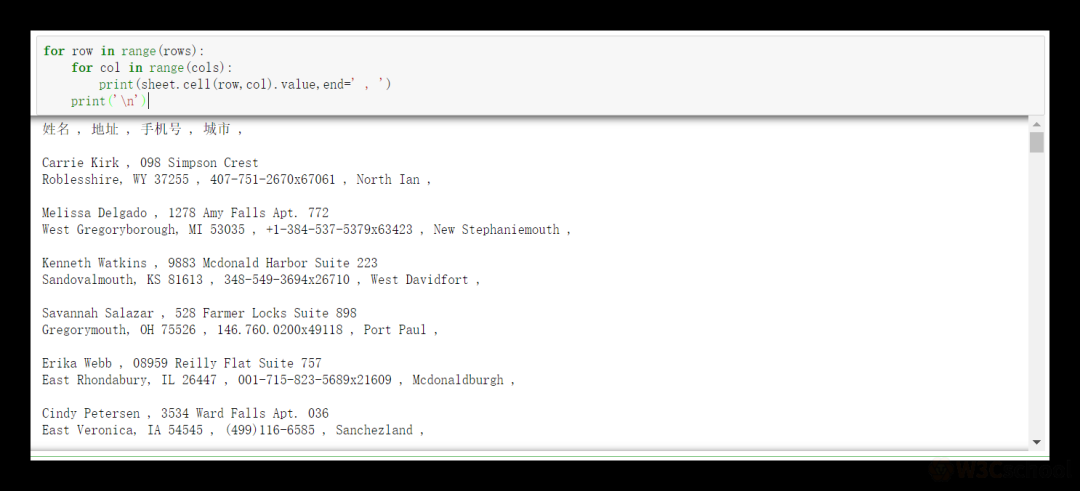
讀數(shù)據(jù),指定某行某列,定位到具體方格,取出里面的值即可,代碼是 sheet.cell(row,col).value 。