
ACID的實(shí)現(xiàn)原理
點(diǎn)擊上方藍(lán)色字體,選擇“標(biāo)星公眾號”
優(yōu)質(zhì)文章,第一時(shí)間送達(dá)
引言
ACID是事務(wù)的特點(diǎn)也是必須的要求,只有保證ACID事務(wù)的執(zhí)行才不會出錯(cuò),分別是原子性、一致性、隔離性和持久性。我們知道典型的MySQL事務(wù)是這樣執(zhí)行的:
start transaction 開啟事務(wù)
commit 提交事務(wù)
rollback 回滾事務(wù)
注意兩個(gè)默認(rèn)機(jī)制:
如果沒有顯示開啟事務(wù),每條SQL都是單獨(dú)的事務(wù)
自動(dòng)提交機(jī)制
下面我們就來分析一下ACID是如何實(shí)現(xiàn)的?以及它和鎖機(jī)制、隔離級別的關(guān)系。
實(shí)現(xiàn)原理
1、原子性(Atomicity)
原子性就是說事務(wù)是一個(gè)不可分割的基本單位,其中的操作要么全部執(zhí)行,要么都不執(zhí)行,其實(shí)就是rollback的實(shí)現(xiàn)機(jī)制,原子性實(shí)現(xiàn)的原理是通過undo log。
undo log是邏輯日志,它記錄的是每條sql。當(dāng)事務(wù)對數(shù)據(jù)庫進(jìn)行修改時(shí),InnoDB 會生成對應(yīng)的 undo log,如果事務(wù)執(zhí)行失敗調(diào)用了rollback,便可以利用 undo log 中的信息將數(shù)據(jù)回滾到修改之前的樣子。
對于每個(gè) insert,回滾時(shí)會執(zhí)行 delete。
對于每個(gè) delete,回滾時(shí)會執(zhí)行 insert。
對于每個(gè) update,回滾時(shí)會執(zhí)行一個(gè)相反的 update,把數(shù)據(jù)改回去。
2、持久性(Durability)
持久性是指事務(wù)一旦提交,它對數(shù)據(jù)庫的改變就應(yīng)該是永久性的。接下來的其他操作或故障不應(yīng)該對其有任何影響。重點(diǎn)就是如何保證數(shù)據(jù)庫宕機(jī)數(shù)據(jù)不受影響。實(shí)現(xiàn)原理是通過redo log
要想深入了解redolog,需要事先了解MySQL的存儲引擎是怎么從磁盤讀取數(shù)據(jù),又是如何把數(shù)據(jù)刷回磁盤的?這里以InnoDB為例,由于磁盤IO速度很慢,因此InnoDB不直接與磁盤打交道,而是通過Buffer Pool緩沖池,以此來加速讀和加速寫。
加速讀指的是讀取時(shí)會優(yōu)先從Buffer Pool讀取,如果 Buffer Pool 中沒有,則從磁盤讀取后放入 Buffer Pool。
加讀寫指的是當(dāng)向數(shù)據(jù)庫寫入數(shù)據(jù)時(shí),會首先寫入 Buffer Pool,Buffer Pool 中修改的數(shù)據(jù)會定期刷新到磁盤中,這一過程稱為刷臟。
但是如果buffer中保存的數(shù)據(jù)還沒刷新到磁盤數(shù)據(jù)庫就宕機(jī)了,會造成數(shù)據(jù)永久丟失。于是引入redo log解決這個(gè)問題,原理是WAL,先寫log,再寫buffer,并且每次事務(wù)提交都會把redo log刷新到磁盤。這個(gè)時(shí)候如果數(shù)據(jù)庫宕機(jī),也可以通過redo log的記錄恢復(fù)所有數(shù)據(jù)。
你可能會有的兩個(gè)疑問:
為什么buffer pool中的數(shù)據(jù)要定期刷臟,如果每次事務(wù)提交都刷新到磁盤,就不需要redo log
因?yàn)槊看涡薷牡臄?shù)據(jù)隨機(jī),buffer pool刷臟過程是隨機(jī)IO,速度很慢,而redo log是追加操作,數(shù)據(jù)都是連續(xù)的,屬于順序IO。第二個(gè)原因是刷臟都是以數(shù)據(jù)頁為單位的,一個(gè)小修改都要整頁寫入,而redo log中只包含真正修改的部分,無效IO減少。
redo log 和 bin log的關(guān)系,bin log是否與持久性有關(guān)?
完全無關(guān),兩者的層次和維度都不相同。bin log是server端的,用于備份和恢復(fù)數(shù)據(jù)、主從復(fù)制等,而redo log是innodb特有的,用于保證異常情況下數(shù)據(jù)安全。當(dāng)然redo log的二階段提交也是必要的,用來保證redo log和bin log的一致性。
3、隔離性(Isolation)
1. 引言
這是個(gè)重頭戲,涉及到很多方面的內(nèi)容
隔離性指的是事物內(nèi)部的操作與其他事務(wù)是隔離的,并發(fā)執(zhí)行的事務(wù)之間不能互相干擾。不同的隔離級別事務(wù)并發(fā)程度也不相同,能解決的問題也不同。一般來說,隔離級別越高并發(fā)程度越低,因?yàn)橐硬煌逆i。
MySQL隔離級別 -- 可能產(chǎn)生的問題:
讀未提交 -- 臟讀、不可重復(fù)讀、幻讀
讀已提交 -- 不可重復(fù)讀、幻讀
可重復(fù)讀 -- 幻讀
串行化 -- 無
先對各個(gè)級別加鎖情況做個(gè)介紹,讓你有個(gè)基本概念:
讀未提交級別:不需要加任何鎖,因此它的并發(fā)程度最高,但同時(shí)也會引發(fā)各種并發(fā)問題
讀已提交級別:讀不需要加鎖,但是寫需要加排它鎖/MVCC
可重復(fù)讀級別:有兩種不同的實(shí)現(xiàn)方式,一是悲觀鎖即讀加共享鎖,寫加排它鎖,這種方式并發(fā)程度低;二是樂觀鎖即MVCC,它的優(yōu)勢是不加鎖,使用undo log和視圖的概念實(shí)現(xiàn),并發(fā)程度高
串行化:讀加共享鎖,寫加排他鎖,讀寫互斥
可以看到,隨著隔離級別的提高,假的鎖也更多,并發(fā)程度自然更低。實(shí)際應(yīng)用時(shí)要根據(jù)業(yè)務(wù)需求,選擇最合適的隔離級別。
其實(shí)隔離性本質(zhì)上就是解決兩個(gè)問題:
(一個(gè)事務(wù))寫操作對(另一個(gè)事務(wù))寫操作的影響:只能通過鎖機(jī)制(當(dāng)前讀,讀取最新數(shù)據(jù))
(一個(gè)事務(wù))寫操作對(另一個(gè)事務(wù))讀操作的影響:目標(biāo)就是不通過加鎖也能解決,目前最優(yōu)解是MVCC(快照讀,不需要最新的數(shù)據(jù))
2. 鎖的分類
接下來簡單介紹一下數(shù)據(jù)庫的鎖,可以從兩個(gè)維度進(jìn)行分析:
一、從鎖范圍分,可以把鎖分為:全局鎖、表級鎖、行級鎖,鎖的精度逐漸增加,鎖精度越高,需要同時(shí)鎖住的數(shù)據(jù)越少,并發(fā)程度越高
二、從鎖的作用分,可以把鎖分為:共享鎖(其他鎖只能讀不能寫)、排他鎖(其他鎖不能讀也不能寫),很明顯,共享鎖的并發(fā)程度更高
3. MVCC的實(shí)現(xiàn)原理
主要依靠數(shù)據(jù)的隱藏列(也可以稱之為標(biāo)記位)和 undo log。其中數(shù)據(jù)的隱藏列包括了該行數(shù)據(jù)的版本號、刪除時(shí)間、指向 undo log 的指針等等。當(dāng)讀取數(shù)據(jù)時(shí),MySQL 可以通過隱藏列判斷是否需要回滾并找到回滾需要的 undo log,從而實(shí)現(xiàn) MVCC。
在InnoDB中,會在每行數(shù)據(jù)后添加兩個(gè)額外的隱藏的值來實(shí)現(xiàn)MVCC,這兩個(gè)值一個(gè)記錄這行數(shù)據(jù)何時(shí)被創(chuàng)建,另外一個(gè)記錄這行數(shù)據(jù)何時(shí)過期(或者被刪除)。在實(shí)際操作中,存儲的并不是時(shí)間,而是事務(wù)的版本號,每開啟一個(gè)新事務(wù),事務(wù)的版本號就會遞增。在可重讀Repeatable reads事務(wù)隔離級別下:
SELECT時(shí),讀取創(chuàng)建版本號<=當(dāng)前事務(wù)版本號,刪除版本號為空或>當(dāng)前事務(wù)版本號。
符合了以上兩點(diǎn)則返回查詢結(jié)果。
1、InnoDB 只查找版本早于當(dāng)前事務(wù)版本的數(shù)據(jù)行(也就是數(shù)據(jù)行的版本必須小于等于事務(wù)的版本),這確保當(dāng)前事務(wù)讀取的行都是事務(wù)之前已經(jīng)存在的,或者是由當(dāng)前事務(wù)創(chuàng)建或修改的行
2、行的刪除操作的版本一定是未定義的或者大于當(dāng)前事務(wù)的版本號,確定了當(dāng)前事務(wù)開始之前,行沒有被刪除
INSERT時(shí),保存當(dāng)前事務(wù)版本號為行的創(chuàng)建版本號
InnoDB 為每個(gè)新增行記錄當(dāng)前系統(tǒng)版本號作為創(chuàng)建 ID。
DELETE時(shí),保存當(dāng)前事務(wù)版本號為行的刪除版本號
InnoDB 為每個(gè)刪除行的記錄當(dāng)前系統(tǒng)版本號作為行的刪除 ID。
UPDATE時(shí),插入一條新紀(jì)錄,保存當(dāng)前事務(wù)版本號為行創(chuàng)建版本號,同時(shí)保存當(dāng)前事務(wù)版本號到原來刪除的行
這里簡單做下總結(jié):
insert 操作時(shí) “創(chuàng)建時(shí)間”=DB_ROW_ID,這時(shí),“刪除時(shí)間 ”是未定義的;
update 時(shí),復(fù)制新增行的“創(chuàng)建時(shí)間”=DB_ROW_ID,刪除時(shí)間未定義,舊數(shù)據(jù)行“創(chuàng)建時(shí)間”不變,刪除時(shí)間=該事務(wù)的 DB_ROW_ID;
delete 操作,相應(yīng)數(shù)據(jù)行的“創(chuàng)建時(shí)間”不變,刪除時(shí)間=該事務(wù)的 DB_ROW_ID;
select 操作對兩者都不修改,只讀相應(yīng)的數(shù)據(jù)
4. 可重復(fù)讀的實(shí)現(xiàn)
快照讀(MVCC)
當(dāng)你執(zhí)行 begin 開啟事務(wù)之后,MySQL 會拍下像下圖這樣的快照:

當(dāng)讀取的記錄的事務(wù)版本號小于當(dāng)前事務(wù)版本號,并且不再活躍事務(wù)中,說明修改該記錄的事務(wù)已經(jīng)被提交,此記錄可讀
當(dāng)讀取的記錄的事務(wù)版本號大號當(dāng)前事務(wù)版本號,說明修改該記錄的事務(wù)已經(jīng)未提交,此記錄不可讀,通過undo log往前找,直到找到第一個(gè) trx_id 等于或者小于自己事務(wù) ID 的記錄為止
當(dāng)前讀(間隙鎖)
與其他數(shù)據(jù)庫,MySQL數(shù)據(jù)庫的可重復(fù)讀可以解決幻讀問題,原理就通過間隙鎖,為某行記錄添加行鎖時(shí)同時(shí)為附近的記錄也添加行鎖,雖然這種實(shí)現(xiàn)方式很多時(shí)候會鎖住不需要鎖的區(qū)間。如下所示:
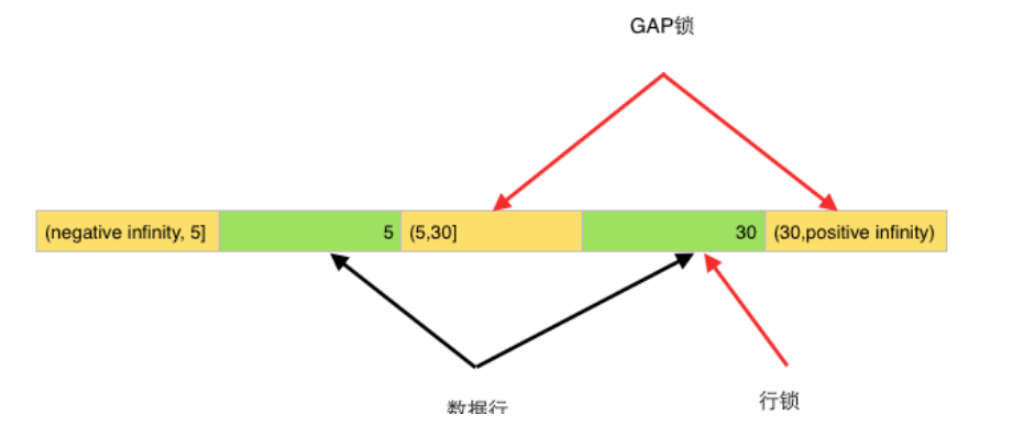
5. 讀已提交的實(shí)現(xiàn)
得益于MVCC,讀已提交的隔離級別也可以通過undo log+視圖的機(jī)制實(shí)現(xiàn),避免頻繁加鎖
具體的實(shí)現(xiàn)方式是每執(zhí)行一個(gè)SQL都要重新創(chuàng)建視圖,根據(jù)視圖各變量和記錄事務(wù)ID判斷此記錄可不可讀
為什么要每條SQL都要重復(fù)創(chuàng)建視圖呢?因此讀已提交隔離級別下可以讀到其他事務(wù)已提交的事務(wù),所以每條SQL執(zhí)行前都要更新視圖中的活躍事務(wù)ID。
4、一致性(Consistency)
致性是指事務(wù)執(zhí)行結(jié)束后,數(shù)據(jù)庫的完整性約束沒有被破壞,事務(wù)執(zhí)行的前后都是合法的數(shù)據(jù)狀態(tài)。數(shù)據(jù)庫的完整性約束包括但不限于:實(shí)體完整性(如行的主鍵存在且唯一)、列完整性(如字段的類型、大小、長度要符合要求)、外鍵約束、用戶自定義完整性(如轉(zhuǎn)賬前后,兩個(gè)賬戶余額的和應(yīng)該不變)
可以說,一致性是事務(wù)追求的最終目標(biāo):前面提到的原子性、持久性和隔離性,都是為了保證數(shù)據(jù)庫狀態(tài)的一致性。此外,除了數(shù)據(jù)庫層面的保障,一致性的實(shí)現(xiàn)也需要應(yīng)用層面進(jìn)行保障。
總結(jié)
本文從事務(wù)的四大特性出發(fā),結(jié)合日志機(jī)制、鎖機(jī)制以及隔離級別,簡單梳理了事務(wù)四大特性ACID的實(shí)現(xiàn)原理以及它們之間的關(guān)系,其中最重要的是隔離性的實(shí)現(xiàn),保護(hù)經(jīng)典樂觀鎖MVCC以及視圖機(jī)制,希望能對你理解MySQL事務(wù)有一點(diǎn)幫助。
作者 | Virtuals
來源 | cnblogs.com/sang-bit/p/15317854.html
