
單目標(biāo)跟蹤小綜述
點(diǎn)擊上方“小白學(xué)視覺(jué)”,選擇加"星標(biāo)"或“置頂”
重磅干貨,第一時(shí)間送達(dá)
最近看了幾篇關(guān)于單目標(biāo)跟蹤的paper,為了方便自己梳理脈絡(luò)同時(shí)和大家交流討論,將一些重要的paper整理在這。
首先用一張圖羅列下本文涉及到的paper:
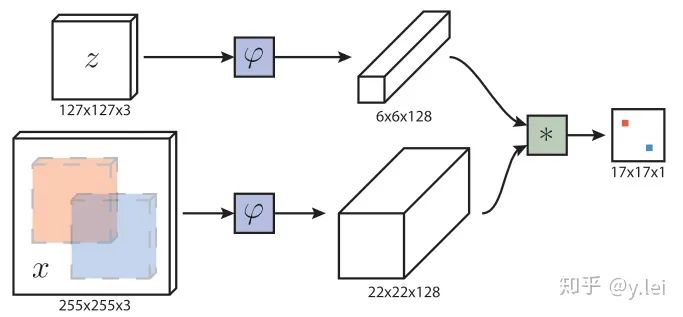
首先簡(jiǎn)單介紹下siamfc的網(wǎng)絡(luò)框架,圖中z是模板(即待跟蹤的目標(biāo)),x是當(dāng)前幀的圖像,  是用于提取圖像特征的卷積網(wǎng)絡(luò),因?yàn)樽饔糜冢?srch_img)的與作用于z(template)的完全一樣所以稱為孿生網(wǎng)絡(luò)(siamese),經(jīng)過(guò)卷積網(wǎng)絡(luò)提取特征后分別得到x和z的feature map,然后將二者卷積(
是用于提取圖像特征的卷積網(wǎng)絡(luò),因?yàn)樽饔糜冢?srch_img)的與作用于z(template)的完全一樣所以稱為孿生網(wǎng)絡(luò)(siamese),經(jīng)過(guò)卷積網(wǎng)絡(luò)提取特征后分別得到x和z的feature map,然后將二者卷積(  表示卷積),即將6×6×128的feature map當(dāng)做卷積核,在22×22×128上進(jìn)行卷積得到17×17×1的heatmap,heatmap上值最大的點(diǎn)就對(duì)應(yīng)于x圖像中目標(biāo)的中心。
表示卷積),即將6×6×128的feature map當(dāng)做卷積核,在22×22×128上進(jìn)行卷積得到17×17×1的heatmap,heatmap上值最大的點(diǎn)就對(duì)應(yīng)于x圖像中目標(biāo)的中心。
下面說(shuō)一些細(xì)節(jié),首先網(wǎng)絡(luò)是5層不帶padding的AlexNet。顯然5層不符合深度學(xué)習(xí)“深”的理念,但是由于網(wǎng)絡(luò)不能加padding所以限制了網(wǎng)絡(luò)深度,為什么不能padding呢,事實(shí)上target在x上的位置,我們是從heatmap得到,這是基于卷積的平移等變性,即target在x上平移了n,相應(yīng)的就會(huì)在heatmap上平移n/stride,且值不會(huì)變。但如果加入了padding,對(duì)于圖像邊緣的像素,雖然也會(huì)平移,但值會(huì)變,因?yàn)閜adding對(duì)圖像的邊緣進(jìn)行了改變。siamRPN++和siamDW解決了這個(gè)問(wèn)題,后面會(huì)詳細(xì)講。然后是訓(xùn)練時(shí),x和z的獲取方式:z是以第一幀的bbox的中心為中心裁剪出一塊圖像,再將這塊圖像縮放到127×127,255×255的srchimg也是類似得到的。
 ,y為預(yù)測(cè)值,v為標(biāo)簽值,這里關(guān)于label的設(shè)置也有一些可以優(yōu)化的點(diǎn),使用focal loss是否對(duì)模型的判別性是否會(huì)更高呢。
,y為預(yù)測(cè)值,v為標(biāo)簽值,這里關(guān)于label的設(shè)置也有一些可以優(yōu)化的點(diǎn),使用focal loss是否對(duì)模型的判別性是否會(huì)更高呢。1. SiamRPN
SiamRPN是CASIA在2018提出來(lái)的網(wǎng)絡(luò),它將siam與檢測(cè)領(lǐng)域的RPN進(jìn)行結(jié)合。關(guān)于RPN(faster RCNN)可以參看faster RCNN,這篇帖子寫(xiě)得非常好。在檢測(cè)領(lǐng)域RPN本意是用作檢測(cè),它將feature map上的各個(gè)點(diǎn)當(dāng)做錨點(diǎn),并映射到映射到輸入圖片上,再在每個(gè)錨點(diǎn)周圍取9個(gè)尺度不同的錨框,對(duì)每個(gè)錨框進(jìn)行檢測(cè)是否有物體以及位置回歸。
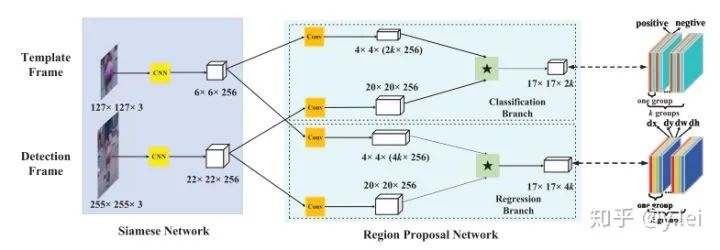
siamRPN的網(wǎng)絡(luò)框架見(jiàn)上圖,這里可以從one-shot的思路理解sianRPN,我們把template分支的embedding當(dāng)作卷積核,srch_img分支當(dāng)作feature map,在template與srchimg卷積之前,先將卷積核(即template得到的feature map)通過(guò)1*1卷積升維到原來(lái)的2k(用于cls)和4k(用于位置的reg)倍。然后拉出分類與位置回歸兩個(gè)分支。(建議沒(méi)看多RPN的朋友看下上面推薦的那篇講faster rcnn的帖子,看完這里就自然懂了)。這里的anchor到底是什么呢,根據(jù)筆者粗淺的理解,siamfc相當(dāng)于直接將template與srching直接卷積匹配,而siamRPN在template上引入k個(gè)anchor相當(dāng)于選取了k個(gè)尺度與srch_img進(jìn)行匹配,解決了尺度問(wèn)題。(筆者對(duì)anchor的理解還不夠深入,后面深入研究下再寫(xiě)一篇文章專門(mén)探討anchor的本質(zhì)及其優(yōu)缺點(diǎn))
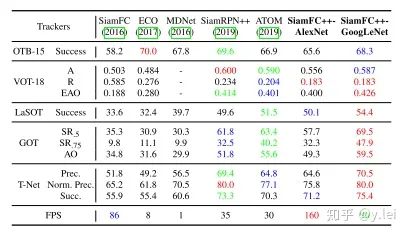
siamRPN無(wú)論是在A還是R上都優(yōu)于siamfc(這里補(bǔ)充一下,對(duì)于跟蹤而言主要有兩個(gè)子指標(biāo)A(accuracy)與R(robust), A主要是跟蹤的位置要準(zhǔn),R主要是模型的判別性要高,即能夠準(zhǔn)確識(shí)別哪些是目標(biāo),從而判斷出目標(biāo)的大致位置。關(guān)于R與A可參見(jiàn)VOT評(píng)價(jià)指標(biāo)),也就是說(shuō)siamrpn的模型判別性與準(zhǔn)確性都比siamfc好,結(jié)果見(jiàn)下圖。
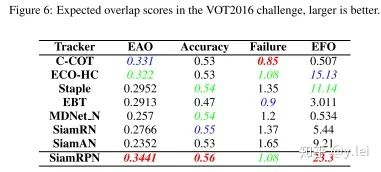
筆者認(rèn)為,準(zhǔn)確性的提升主要來(lái)自與siamrpn將位置回歸單獨(dú)拉出來(lái)作為一個(gè)分支,這一點(diǎn)在后續(xù)的siamfc++中也可以看到作者相關(guān)的論述。在模型判別性方面,筆者認(rèn)為,提升的關(guān)鍵在于siamrpn在進(jìn)行匹配(即template與srchimg卷積的過(guò)程)時(shí),由于引入了k個(gè)anchors,相當(dāng)于從k個(gè)尺度對(duì)template與srch_img進(jìn)行更加細(xì)粒度的匹配,效果更好也是情理之中。另外很重要的一點(diǎn)就是sianrpn解決了尺度問(wèn)題。
2. DaSiamRPN
關(guān)于這篇文章,筆者之前在github上做過(guò)一些筆記,這里就簡(jiǎn)單摘錄一些,具體筆記見(jiàn)DaSiamRPN。
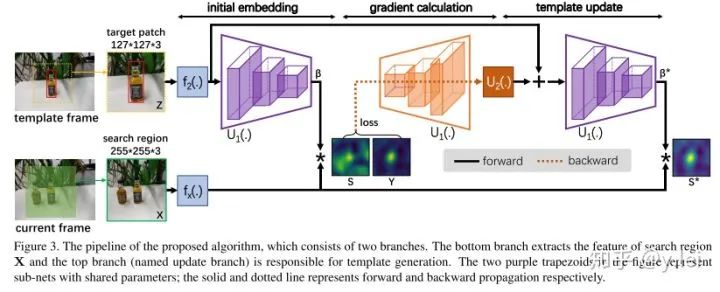
DasiamRPN并沒(méi)有對(duì)siamfc的網(wǎng)絡(luò)結(jié)構(gòu)進(jìn)行過(guò)多的改進(jìn),而是從訓(xùn)練數(shù)據(jù),模板更新,搜索區(qū)域三個(gè)角度對(duì)模型的rubost進(jìn)行了提升。使得SiamRPN網(wǎng)絡(luò)能夠適應(yīng)長(zhǎng)期跟蹤。
首先作者對(duì)siamrpn的缺點(diǎn)進(jìn)行了分析,主要有三點(diǎn):
在訓(xùn)練階段,存在樣本不均衡問(wèn)題。即大部分樣本都是沒(méi)有語(yǔ)義的背景(注:背景不是非target的物體,而是指那些既不屬于target,也不屬于干擾物,沒(méi)有語(yǔ)義的圖像塊,例如大片白色。)這就導(dǎo)致了網(wǎng)絡(luò)學(xué)到的僅僅是對(duì)于背景與前景的區(qū)分,即在圖像中提取出物體,但我們希望網(wǎng)絡(luò)還能夠識(shí)別target與非target物體。作者從數(shù)據(jù)增強(qiáng)的角度解決此問(wèn)題。
模型判別性不足,缺乏模板的更新,即在heatmap中很多非target的物體得分也很高;甚至當(dāng)圖像中沒(méi)有目標(biāo)時(shí),依然會(huì)有很高的得分存在。作者認(rèn)為與target相似的物體對(duì)于增強(qiáng)模型的判別性有幫助,因此提出了distractor-aware module對(duì)干擾(得分很高的框)進(jìn)行學(xué)習(xí),更新模板,從而提高siam判別性。但是排名靠前的都是與target很相似的物體,也就是說(shuō)該更新只利用到了target的信息,沒(méi)有利用到背景信息。
由于第二個(gè)缺陷,原始的siam以及siamRPN使用了余弦窗,因此當(dāng)目標(biāo)丟失,然后從另一個(gè)位置出現(xiàn),此時(shí)siam不能重新識(shí)別target, (siamRPN的搜索區(qū)域是上一陣的中心加上預(yù)設(shè)的搜索區(qū)域大小形成的搜索框),該缺陷導(dǎo)致siam無(wú)法適應(yīng)長(zhǎng)時(shí)間跟蹤的問(wèn)題。對(duì)此作者提出了local-to-global的搜索策略,其實(shí)就是隨著目標(biāo)消失幀數(shù)的增加,搜索區(qū)域逐漸擴(kuò)大。
針對(duì)這三個(gè)問(wèn)題,作者給出了相應(yīng)的解決方案。首先對(duì)于數(shù)據(jù)問(wèn)題,當(dāng)然是使用數(shù)據(jù)增強(qiáng),主要方法有:增加訓(xùn)練集中物體的類別;訓(xùn)練時(shí)使用來(lái)自同一類別的負(fù)樣本,以及來(lái)自不同類別的正樣本輔助訓(xùn)練;增加圖像的運(yùn)動(dòng)模糊。關(guān)于template的更新問(wèn)題,作者對(duì)heatmap得到目標(biāo)先NMS去除一些冗余框,然后將相似度靠前的框(干擾物)拿出來(lái),讓網(wǎng)絡(luò)對(duì)其學(xué)習(xí),拉大target_embedding與這些干擾物之間的相似度。這樣的優(yōu)點(diǎn)在于既綜合了當(dāng)前幀的信息,同時(shí)因NMS靠前的都與目標(biāo)很相似,這就抑制了模板污染問(wèn)題。
3. siamMask
關(guān)于siamMask,先放一張效果圖,就可以知道他做的是什么工作。

簡(jiǎn)單來(lái)說(shuō)siamMask就是將跟蹤與分割結(jié)合到了一起,從其結(jié)果上,相比與之前的視頻分割工作,其提升了速度,相比與之前的DasaimRPN其提升了A與R.

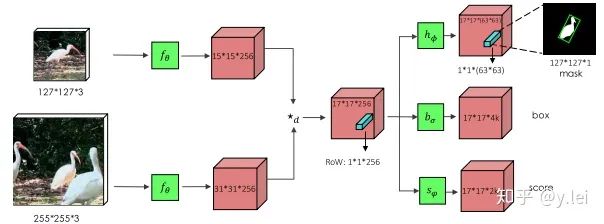
上圖是siamMask的網(wǎng)絡(luò)框架,從中我們也可以看出,就網(wǎng)絡(luò)本身而言,siamMask只是比siamRPN多了一個(gè)(分割)分支,即多了一個(gè)學(xué)習(xí)任務(wù)。
4. siamRPN++
siamRPN++可以說(shuō)是將siam系列網(wǎng)絡(luò)又推向一個(gè)高峰,它解決的是如何將siam網(wǎng)絡(luò)加深的問(wèn)題。筆者在寫(xiě)siamfc那部分時(shí)提到,siamfc中的backbone使用的是只有5層的AlexNet,且不含padding, 其實(shí)在siamrpn的backbone也很淺。這是因?yàn)榫W(wǎng)絡(luò)不能加padding, 不能加padding,那么隨著網(wǎng)絡(luò)深度的增加,feature map就會(huì)越來(lái)越小,特征丟失過(guò)多。而加padding則會(huì)破壞卷積的平移等變性。在siamrpn++中,作者是從實(shí)驗(yàn)效果的角度對(duì)padding進(jìn)行探究。作者認(rèn)為padding會(huì)給網(wǎng)絡(luò)帶來(lái)空間上的偏見(jiàn)。具體來(lái)說(shuō),padding就是在圖片邊緣加上黑邊,但是黑邊肯定不是我們的目標(biāo),而黑邊總是在邊緣,那么對(duì)于神經(jīng)網(wǎng)絡(luò)來(lái)說(shuō),它就會(huì)認(rèn)為邊緣都不是目標(biāo),即離邊緣越遠(yuǎn)的越可能是目標(biāo)。這就導(dǎo)致了神經(jīng)網(wǎng)絡(luò)總是習(xí)慣認(rèn)為圖像中心的是目標(biāo),而忽視目標(biāo)本身的特征,而siamfc的訓(xùn)練方法target也確實(shí)是在圖片中央。(這里需要指明的是,在siamfc的訓(xùn)練過(guò)程中,總是讓template與srch_img處于圖片的中央,作者在siamfc中說(shuō)因?yàn)樗麄兪褂昧巳矸e的結(jié)構(gòu),所以在siamfc中不會(huì)有空間上的bias,顯然這里的結(jié)果和siamrpn++的結(jié)果有矛盾,這也是筆者在寫(xiě)這篇貼子時(shí)想到的,siamfc到底有沒(méi)有空間的bias還有待筆者代碼測(cè)試,也歡迎評(píng)論區(qū)小伙伴討論。)
回到siamrpn++上來(lái),有了上面的分析,解決辦法自然也就有了,既然網(wǎng)絡(luò)總是習(xí)慣認(rèn)為中心是目標(biāo),那讓target不要總是在圖片中央不就好了,于是siamrpn++最大的貢獻(xiàn)就產(chǎn)生了,在訓(xùn)練時(shí)讓目標(biāo)相對(duì)于中心偏移幾個(gè)像素,論文中實(shí)驗(yàn)表明偏移64個(gè)像素最佳.
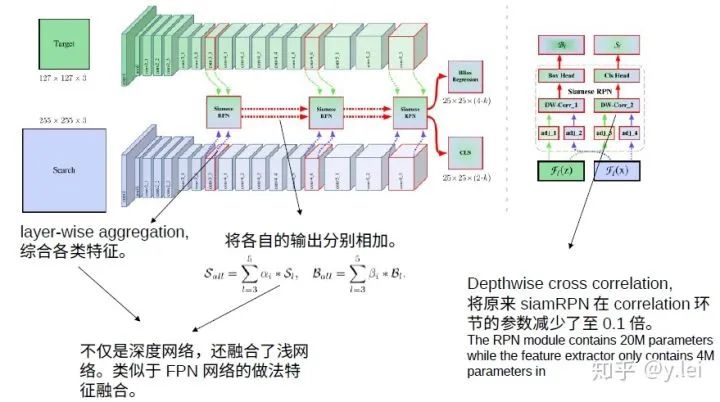
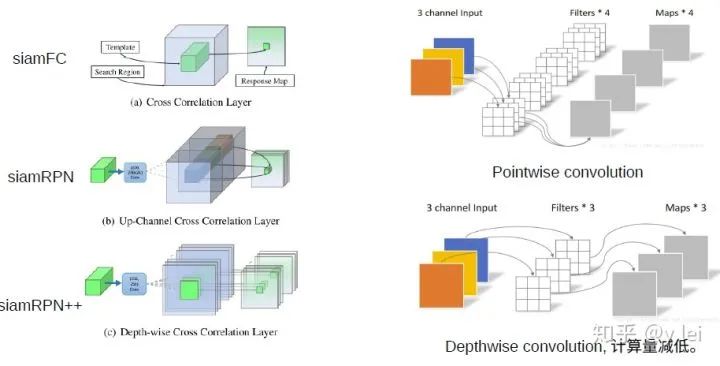

5. siamDW
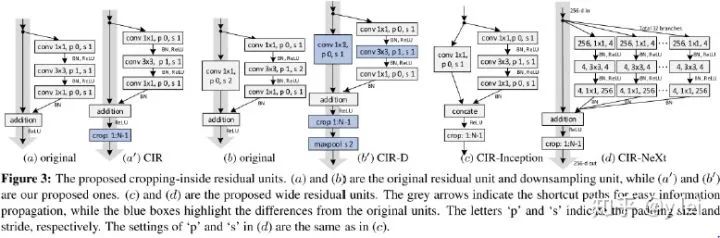
6. siamFC++
跟蹤網(wǎng)絡(luò)分為兩個(gè)子任務(wù),一個(gè)是分類,一個(gè)是位置的準(zhǔn)確估計(jì)。即網(wǎng)絡(luò)需要有分類與位置估計(jì)兩個(gè)分支。缺少分類分支,模型的判別性會(huì)降低,表現(xiàn)到VOT評(píng)價(jià)指標(biāo)上就是R不高;缺少位置估計(jì)分支,目標(biāo)的位置準(zhǔn)確度會(huì)降低,表現(xiàn)到VOT評(píng)價(jià)指標(biāo)上就是A不高。
分類與位置估計(jì)使用的feature map要分開(kāi)。即不能分類的feature map上直接得到位置的估計(jì),否則會(huì)降低A。
siam匹配的要是原始的exemplar,不能是與預(yù)設(shè)定的anchors匹配,否則模型的判別性會(huì)降低,siamFC++的A值略低于siamRPN++,但是R值在測(cè)試過(guò)的數(shù)據(jù)集上都比siamRPN++高,作者認(rèn)為就是anchors的原因,在論文的實(shí)驗(yàn)部分,作者進(jìn)行了實(shí)驗(yàn)發(fā)現(xiàn)siamRPN系列都是與anchors進(jìn)行匹配而不是exemplar本身,但是anchors與exemplar之間存在一些差異,導(dǎo)致siamRPN的魯棒性不高。
不能加入數(shù)據(jù)分布的先驗(yàn)知識(shí),例如原始siamFC的三種尺度變換,anchors等實(shí)際上都是對(duì)目標(biāo)尺度的一種先驗(yàn),否則會(huì)影響模型的通用性。
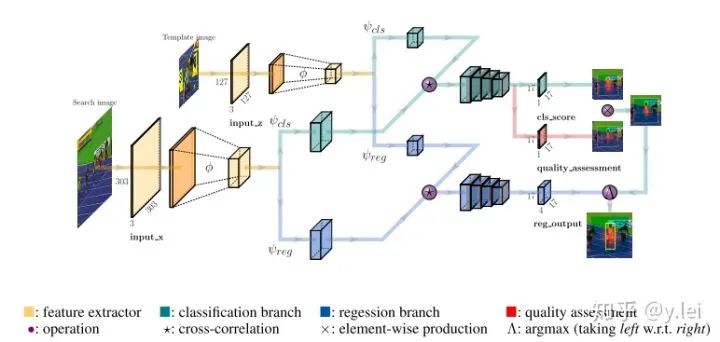

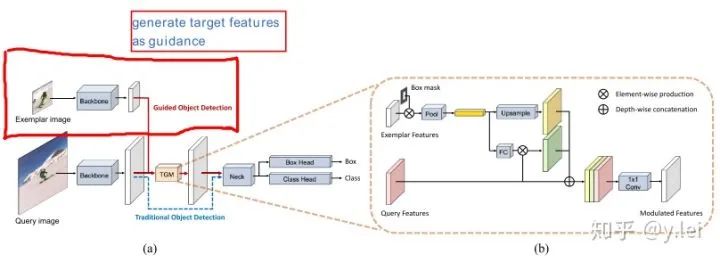
如何將exemplar與srch img 融合到一起,目的就是告訴網(wǎng)絡(luò)需要跟蹤的對(duì)象,實(shí)際上也就是作者提出的第一個(gè)難點(diǎn)。
網(wǎng)絡(luò)不可能提前知道要跟蹤的目標(biāo)從而進(jìn)行相應(yīng)的訓(xùn)練,如何使得網(wǎng)絡(luò)能夠識(shí)別出“臨時(shí)”挑選的目標(biāo)。采用meta-learning的方法如何避免過(guò)擬合。
siam成功的地方在于將上述兩個(gè)問(wèn)題轉(zhuǎn)化為匹配問(wèn)題,即在srch img中匹配exemplar,siam的問(wèn)題在于網(wǎng)絡(luò)的判別性,即不會(huì)匹配到背景,另外exemplar是否更新,如何更新,尺度變換問(wèn)題如何解決。
提出了target-guidance module(TGM)將exemplar圖像融合到檢測(cè)的feature map里。
在線學(xué)習(xí)Meta-learning對(duì)classification head微調(diào)。
在線更新權(quán)重
anchored updating strategy減少M(fèi)eta-learning的overfitting。
交流群
歡迎加入公眾號(hào)讀者群一起和同行交流,目前有SLAM、三維視覺(jué)、傳感器、自動(dòng)駕駛、計(jì)算攝影、檢測(cè)、分割、識(shí)別、醫(yī)學(xué)影像、GAN、算法競(jìng)賽等微信群(以后會(huì)逐漸細(xì)分),請(qǐng)掃描下面微信號(hào)加群,備注:”昵稱+學(xué)校/公司+研究方向“,例如:”張三 + 上海交大 + 視覺(jué)SLAM“。請(qǐng)按照格式備注,否則不予通過(guò)。添加成功后會(huì)根據(jù)研究方向邀請(qǐng)進(jìn)入相關(guān)微信群。請(qǐng)勿在群內(nèi)發(fā)送廣告,否則會(huì)請(qǐng)出群,謝謝理解~