
SQL、Pandas和Spark:如何實(shí)現(xiàn)數(shù)據(jù)透視表?
導(dǎo)讀
數(shù)據(jù)透視表是一個(gè)很重要的數(shù)據(jù)統(tǒng)計(jì)操作,最有代表性的當(dāng)屬在Excel中實(shí)現(xiàn)(甚至說(shuō)提及Excel,個(gè)人認(rèn)為其最有用的當(dāng)屬三類(lèi):好用的數(shù)學(xué)函數(shù)、便捷的圖表制作以及強(qiáng)大的數(shù)據(jù)透視表功能)。所以,今天本文就圍繞數(shù)據(jù)透視表,介紹一下其在SQL、Pandas和Spark中的基本操作與使用,這也是沿承這一系列的文章之一。

在上述簡(jiǎn)介中,有兩個(gè)關(guān)鍵詞值得注意:排列和匯總,其中匯總意味著要產(chǎn)生聚合統(tǒng)計(jì),即groupby操作;排列則實(shí)際上隱含著使匯總后的結(jié)果有序。當(dāng)然,如果說(shuō)只實(shí)現(xiàn)這兩個(gè)需求還不能完全表達(dá)出數(shù)據(jù)透視表與常規(guī)的groupby有何區(qū)別,所以不妨首先看個(gè)例子:
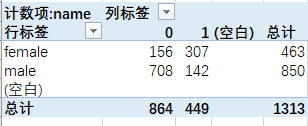
通過(guò)上表,明顯可以看出女性中約有2/3的人得以生還,而男性中則僅有不到20%的人得以生還。當(dāng)然,這是數(shù)據(jù)透視表的最基本操作,大家應(yīng)該也都熟悉,本文不做過(guò)多展開(kāi)。
值得補(bǔ)充的是:實(shí)際上為了完成不同性別下的生還人數(shù),我們完全可以使用groupby(sex, survived)這兩個(gè)字段+count實(shí)現(xiàn)這一需求,而數(shù)據(jù)透視表則僅僅是在此基礎(chǔ)上進(jìn)一步完成行轉(zhuǎn)列的pivot操作而已。理解了數(shù)據(jù)透視表的這一核心功能,對(duì)于我們下面介紹數(shù)據(jù)透視表在三大工具中的適用將非常有幫助!
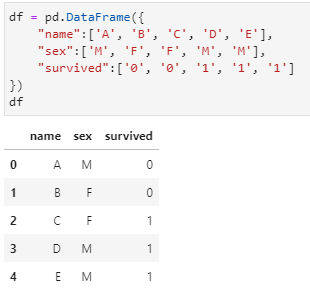

可以明顯注意到該函數(shù)的4個(gè)主要參數(shù):
values:對(duì)哪一列進(jìn)行匯總統(tǒng)計(jì),在此需求中即為name字段;
index:匯總后以哪一列作為行,在此需求中即為sex字段;
columns:匯總后以哪一列作為列,在此需求中即為survived;
aggfunc:執(zhí)行什么聚合函數(shù),在此需求中即為count,該參數(shù)的默認(rèn)參數(shù)為mean,但只適用于數(shù)值字段。
而后,分別傳入相應(yīng)參數(shù),得到數(shù)據(jù)透視表結(jié)果如下:
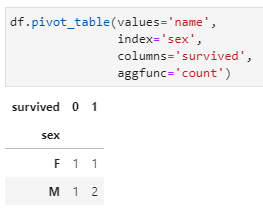
上述需求很簡(jiǎn)單,需要注意以下兩點(diǎn):
pandas中的pivot_table還支持其他多個(gè)參數(shù),包括對(duì)空值的操作方式等;
上述數(shù)據(jù)透視表的結(jié)果中,無(wú)論是行中的兩個(gè)key("F"和"M")還是列中的兩個(gè)key(0和1),都是按照字典序排序的結(jié)果,這也呼應(yīng)了Excel中關(guān)于數(shù)據(jù)透視表的介紹。
Spark作為分布式的數(shù)據(jù)分析工具,其中spark.sql組件在功能上與Pandas極為相近,在某種程度上個(gè)人一直將其視為Pandas在大數(shù)據(jù)中的實(shí)現(xiàn)。在Spark中實(shí)現(xiàn)數(shù)據(jù)透視表的操作也相對(duì)容易,只是不如pandas中的自定義參數(shù)來(lái)得強(qiáng)大。
首先仍然給出在Spark中的構(gòu)造數(shù)據(jù):

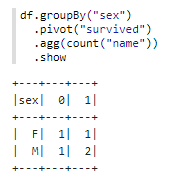
當(dāng)然,注意到這里仍然是保持了數(shù)據(jù)透視表結(jié)果中行key和列key的有序。
這一系列的文章中,一般都是將SQL排在首位進(jìn)行介紹,但本文在介紹數(shù)據(jù)透視表時(shí)有意將其在SQL中的操作放在最后,這是因?yàn)樵赟QL中實(shí)現(xiàn)數(shù)據(jù)透視表是相對(duì)最為復(fù)雜的。實(shí)際上,SQL中原生并不支持?jǐn)?shù)據(jù)透視表功能,只能通過(guò)衍生操作來(lái)曲線達(dá)成需求。
上述在分析數(shù)據(jù)透視表中,將其定性為groupby操作+行轉(zhuǎn)列的pivot操作,那么在SQL中實(shí)現(xiàn)數(shù)據(jù)透視表就將需要groupby和行轉(zhuǎn)列兩項(xiàng)操作,所幸的是二者均可獨(dú)立實(shí)現(xiàn),簡(jiǎn)單組合即可。
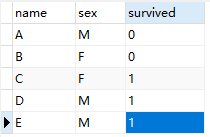
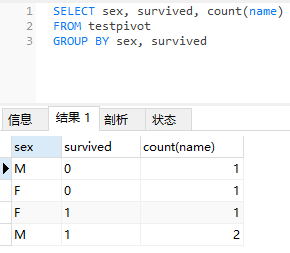
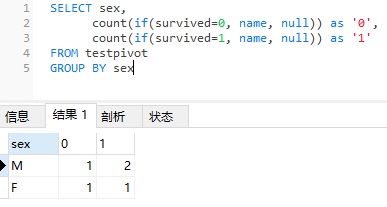
上述SQL語(yǔ)句中,僅對(duì)sex字段進(jìn)行g(shù)roupby操作,而后在執(zhí)行count(name)聚合統(tǒng)計(jì)時(shí),由直接count聚合調(diào)整為兩個(gè)count條件聚合,即:
如果survived字段=0,則對(duì)name計(jì)數(shù),否則不計(jì)數(shù)(此處設(shè)置為null,因?yàn)閏ount計(jì)數(shù)時(shí)會(huì)忽略null值),得到的結(jié)果記為survived=0的個(gè)數(shù);
如果survived字段=1,則對(duì)name計(jì)數(shù),否則不計(jì)數(shù),此時(shí)得到的結(jié)果記為survived=1的個(gè)數(shù)。
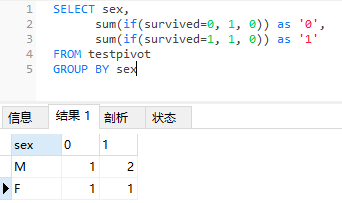
當(dāng)然,二者的結(jié)果是一樣的。
以上就是數(shù)據(jù)透視表在SQL、Pandas和Spark中的基本操作,應(yīng)該講都還是比較方便的,僅僅是在SQL中需要稍加使用個(gè)小技巧。希望能對(duì)大家有所幫助,如果覺(jué)得有用不妨點(diǎn)個(gè)在看!
相關(guān)閱讀: