
【Python基礎】Pandas三種實現(xiàn)數(shù)據(jù)透視表的方法
前言
主要想做的事情用大白話來講就是:一個dataframe里面對于兩個列做分組,最后算一個value對應于這兩個列的分組來算值的矩陣,這個矩陣的行為其中一個列,列也為其中一個列。
新建一個df
import?pandas?as?pd
import?numpy?as?np
v?=?[1,?2,?3,?3,?3]
a?=?pd.DataFrame({'v':?v})
d?=?[2?,?4,?4,?5,?4]
a['d']?=?d
c?=?['c'?,?'h',?'d',?'e',??'c']
a['c']?=?c
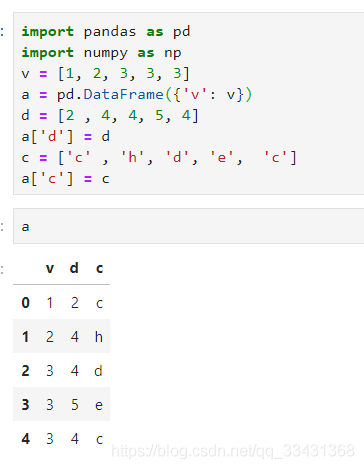
df用兩列進行分組grouby
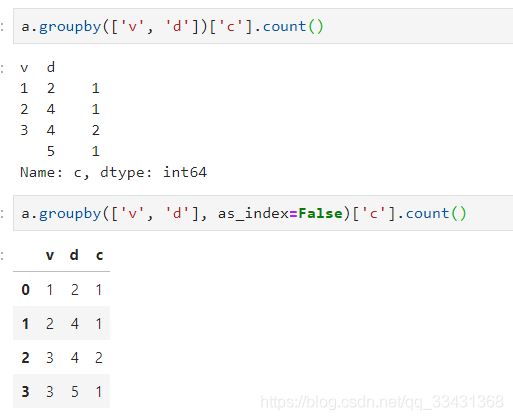
a.groupby(['v',?'d'])['c'].count()
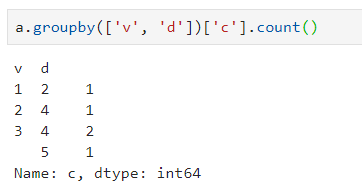 我的要干的事情 就是把這個v當作列index,d當作行columns,之后把對應的分組的’c‘.count()放到對應的索引loc處,不存在的值用0填補。
我的要干的事情 就是把這個v當作列index,d當作行columns,之后把對應的分組的’c‘.count()放到對應的索引loc處,不存在的值用0填補。
最后得到一個以v為index, d為column的df,也可以搞成對應的矩陣matrix
第一種方法:pd.crosstab
cpd?=?pd.crosstab(a['v'],?a['d'],?a['c'],?aggfunc='count')
cpd
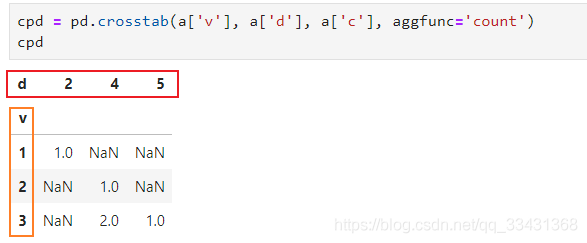
查看index和columns

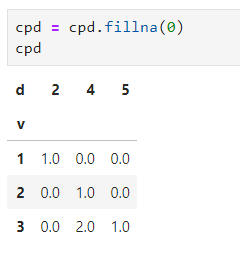
我們再來一步就可以得到我們想要的了,把nan填充一下。
cpd?=?cpd.fillna(0)
cpd
轉換為array和list的方法
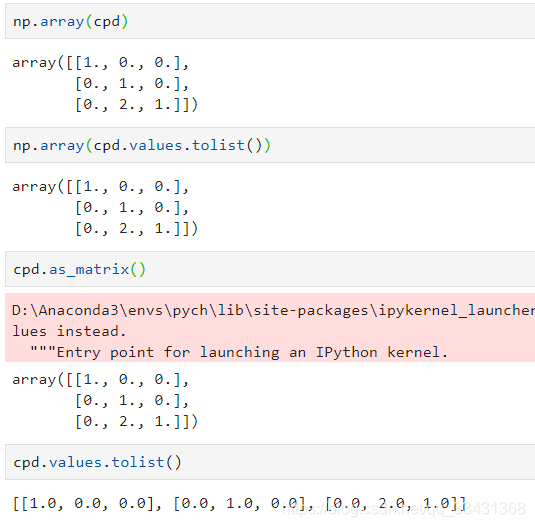
cpd_arr1?=?np.array(cpd)
cpd_arr2?=?np.array(cpd.values.tolist())
cpd_arr3?=?cpd.as_matrix()
cpd_list?=?cpd.values.tolist()
整體流程
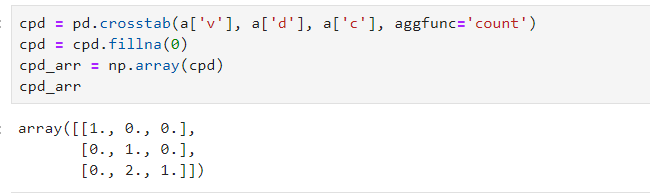
cpd?=?pd.crosstab(a['v'],?a['d'],?a['c'],?aggfunc='count')
cpd?=?cpd.fillna(0)
cpd_arr?=?np.array(cpd)
cpd_arr
總結一句話
np.array(pd.crosstab(a['v'],?a['d'],?a['c'],?aggfunc='count').fillna(0))

第二種方法:pivot()
groupby的as_index=False
a.groupby(['v',?'d'],?as_index=False)['c'].count()
把操作的三列的值恢復到df上,每一個列還是對應的列。
pivot
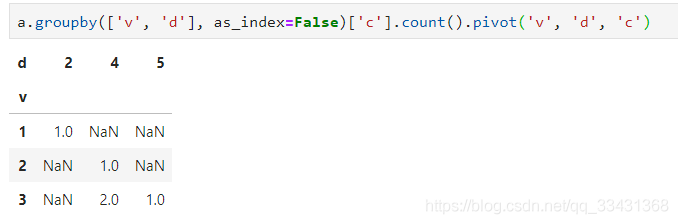
a.groupby(['v',?'d'],?as_index=False)['c'].count().pivot('v',?'d',?'c')
對應關系如下:
整體流程
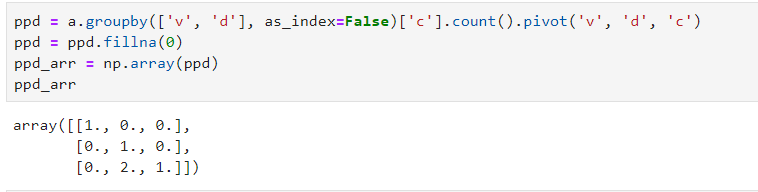
ppd?=?a.groupby(['v',?'d'],?as_index=False)['c'].count().pivot('v',?'d',?'c')
ppd?=?ppd.fillna(0)
ppd_arr?=?np.array(ppd)
ppd_arr
總結一句話
np.array(a.groupby(['v',?'d'],?as_index=False)['c'].count().pivot('v',?'d',?'c').fillna(0))

第三種方法:pivot_table
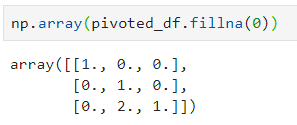
pivoted_df=pd.pivot_table(a[['v','d','c']],?
??????????????????????????values='c',?index=['v'],
??????????????????????????columns=['d'],?aggfunc='count')
pivoted_df

往期精彩回顧
獲取一折本站知識星球優(yōu)惠券,復制鏈接直接打開:
https://t.zsxq.com/662nyZF
本站qq群1003271085。
加入微信群請掃碼進群(如果是博士或者準備讀博士請說明):
評論
圖片
表情