
【機器學習】一文徹底搞懂自動機器學習AutoML:H2O
前面和大家一起學習了一文徹底搞懂自動機器學習AutoML:Auto-Sklearn,今天將和大家一起研習另一個AutoML框架H2O,本文從安裝、實例詳盡介紹框架的使用方法,最后深入研習了該框架對模型可解釋部分,一起研習吧!
H2O 是一個用于分布式、可擴展機器學習的內(nèi)存平臺。H2O 使用熟悉的界面,如 R、Python、Scala、Java、JSON 和 Flow notebook/web 界面,并與 Hadoop 和 Spark 等大數(shù)據(jù)技術(shù)無縫協(xié)作。H2O 提供了許多流行算法的實現(xiàn),例如廣義線性模型 (GLM)、梯度提升機(包括 XGBoost)、隨機森林、深度神經(jīng)網(wǎng)絡(luò)、堆疊集成、樸素貝葉斯、廣義加性模型 (GAM)、Cox 比例風險、K- Means、PCA、Word2Vec,以及全自動機器學習算法(H2O AutoML)。
安裝
從命令行下載并運行
如果計劃專門使用 H2O 的 Web GUI Flow[4],那么應(yīng)該使用這種方法。
單擊h2o下載[5]頁面上的按鈕。這會下載一個 zip 文件,其中包含你開始使用所需的所有內(nèi)容。 Download H2O從你的終端,解壓縮并啟動 H2O,如下例所示。
cd?~/Downloads
unzip?h2o-3.30.0.6.zip
cd?h2o-3.30.0.6
java?-jar?h2o.jar
將瀏覽器指向 http://localhost:54321以打開 H2O Flow Web GUI。
python
在終端窗口中運行以下命令以安裝 H2O for Python。
安裝依賴項(如果需要,在前面加上 sudo):
pip?install?requests
pip?install?tabulate
pip?install?future
注意:這些是運行 H2O 所需的依賴項。完整的依賴項列表保存在以下文件中:https[6] ://github.com/h2oai/h2o-3/blob/master/h2o-py/conda/h2o/meta.yaml 。
用于 pip安裝此版本的 H2O Python 模塊。
pip?install?-f?http://h2o-release.s3.amazonaws.com/h2o/latest_stable_Py.html?h2o

還需要安裝Java環(huán)境,因為底層是Java所寫,
導入數(shù)據(jù)
這里使用kaggle中Titanic數(shù)據(jù)為分析例子。詳情可參見kaggle泰坦尼克案例[7]。
import?h2o
import?pandas?as?pd
h2o.init()
#?h2o導入方式
#?train_1?=?h2o.import_file("/kaggle/input/titanic/train.csv")
#?test_1?=?h2o.import_file("/kaggle/input/titanic/test.csv")
#?pandas導入方式
train?=?pd.read_csv('/kaggle/input/titanic/train.csv')
test?=?pd.read_csv('/kaggle/input/titanic/test.csv')
數(shù)據(jù)處理
如果你是個新手,剛開始接觸數(shù)據(jù)預處理,建議可以試試H2O。如下一些常用的操作,官網(wǎng)上都是有例子的:
上傳文件
導入文件
導入多個文件
下載數(shù)據(jù)
更改列類型
合并來自兩個數(shù)據(jù)集的列
合并來自兩個數(shù)據(jù)集的行
填寫 NA
通過...分組
輸入數(shù)據(jù)
合并兩個數(shù)據(jù)集
透視表
替換框架中的值
切片列
切片行
對列進行排序
將數(shù)據(jù)集拆分為訓練/測試/驗證
標記字符串
H2O 也有特征工程的方法。目標編碼是一種分類編碼技術(shù),它用目標變量的平均值替換分類值(對于高基數(shù)特征特別有用)。Word2vec 是一種文本處理方法,它將文本語料庫轉(zhuǎn)換為詞向量的輸出。
本例子中,使用慣用的pandas進行相關(guān)分析。
train_indexs?=?train.index
test_indexs?=?test.index
print(len(train_indexs),?len(test_indexs))
#?(891,?418)
df?=??pd.concat(objs=[train,?test],?axis=0).reset_index(drop=True)
df?=?df.drop('PassengerId',?axis=1)
train?=?df.loc[train_indexs]
test?=?df[len(train_indexs):]
test?=?test.drop(labels=["Survived"],?axis=1)
AutoML
H2O是簡化機器學習的第一步,涉及為各種機器學習算法開發(fā)簡單、統(tǒng)一的接口。
H2O 的 AutoML 可用于自動化機器學習工作流程,其中包括在用戶指定的時間限制內(nèi)自動訓練和調(diào)整許多模型。
H2O 提供了許多適用于AutoML對象以及單個模型的模型可解釋性方法。可以通過單個函數(shù)調(diào)用自動生成解釋,提供一個簡單的界面來探索和解釋 AutoML 模型。
必需參數(shù)
所需數(shù)據(jù)參數(shù)
y:此參數(shù)是目標變量列的名稱(或索引) training_frame:指定訓練集。
所需的停止參數(shù)
必須指定以下停止策略之一(基于時間或模型數(shù)量)。設(shè)置這兩個選項后,AutoML 運行將在達到這些限制之一時立即停止。
max_runtime_secs:此參數(shù)指定 AutoML 進程將運行的最長時間。默認值為 0(無限制),但如果用戶未指定max_runtime_secs和max_models指定,則動態(tài)設(shè)置為 1 小時。max_models:指定在 AutoML 運行中構(gòu)建的最大模型數(shù),不包括 Stacked Ensemble 模型。默認為 NULL/None。
部分可選數(shù)據(jù)參數(shù)
x:預測列名稱或索引的列表/向量。僅當用戶想要從一組預測變量中排除列時才需要指定此參數(shù)。如果在預測中應(yīng)使用所有列(除了目標變量),則不需要設(shè)置。 validation_frame:若nfolds == 0,不然此參數(shù)將被忽略。可以指定一個驗證frame,并用于提前停止單個模型和提前停止網(wǎng)格搜索(除非max_models或max_runtime_secs覆蓋基于指標的提前停止)。默認情況下,當nfolds > 1時,交叉驗證指標將用于早期停止,因此validation_frame將被忽略。leaderboard_frame:此參數(shù)允許用戶指定一個特定的數(shù)據(jù)框,用于在排行榜上對模型進行評分和排名。除了排行榜得分外,該框架不會用于任何其他用途。如果用戶未指定排行榜框架,則排行榜將使用交叉驗證指標,或者如果通過設(shè)置nfolds = 0關(guān)閉交叉驗證,則將從訓練框架自動生成排行榜框架。blending_frame:指定用于計算預測的框架,作為 Stacked Ensemble 模型 metalearner 的訓練框架。如果提供,所有由 AutoML 生成的 Stacked Ensemble 都將使用 Blending(又名 Holdout Stacking)而不是基于交叉驗證的默認 Stacking 方法進行訓練。fold_column:指定每個觀察具有交叉驗證折疊索引分配的列。這用于覆蓋 AutoML 運行中各個模型的默認、隨機、5 折交叉驗證方案。weights_column:指定具有觀察權(quán)重的列。將某些觀察值賦予零權(quán)重相當于將其從數(shù)據(jù)集中排除;給一個觀察相對權(quán)重 2 相當于重復該行兩次。
from?h2o.automl?import?H2OAutoML
hf?=?h2o.H2OFrame(train)
test_hf?=?h2o.H2OFrame(test)
hf.head()
#?選擇預測變量和目標
hf['Survived']?=?hf['Survived'].asfactor()
predictors?=?hf.drop('Survived').columns
response?=?'Survived'
#?切分數(shù)據(jù)集,添加停止條件參數(shù)為最大模型數(shù)和最大時間,然后訓練
train_hf,?valid_hf?=?hf.split_frame(ratios=[.8],?seed=1234)
aml?=?H2OAutoML(
????max_models=20,
????max_runtime_secs=300,
????seed=1234,
)
aml.train(x=predictors,
????????y=response,
????????training_frame=hf,
)
ModelMetricsBinomialGLM: stackedensemble
** Reported on train data. **
MSE: 0.052432901181573156
RMSE: 0.22898231630755497
LogLoss: 0.19414205126074563
Null degrees of freedom: 890
Residual degrees of freedom: 885
Null deviance: 1186.6551368246774
Residual deviance: 345.9611353466487
AIC: 357.9611353466487
AUC: 0.9815107745076109
AUCPR: 0.9762820080059409
Gini: 0.9630215490152219
lb?=?aml.leaderboard
lb.head(rows=5)
model_id auc logloss aucpr mean_per_class_error rmse mse
StackedEnsemble_BestOfFamily_4_AutoML_1_20211228_171936 0.880591 0.389491 0.868648 0.170573 0.346074 0.119767
GBM_5_AutoML_1_20211228_171936 0.880452 0.392546 0.87024 0.172323 0.347309 0.120624
StackedEnsemble_BestOfFamily_5_AutoML_1_20211228_171936 0.879773 0.391389 0.867679 0.175702 0.347747 0.120928
StackedEnsemble_AllModels_2_AutoML_1_20211228_171936 0.879339 0.395392 0.866278 0.175774 0.348615 0.121533
StackedEnsemble_BestOfFamily_3_AutoML_1_20211228_171936 0.878607 0.394689 0.86662 0.178339 0.348864 0.121706
valid_pred?=?aml.leader.predict(valid_hf)
metrics.accuracy_score(valid_pred.as_data_frame()['predict'],?valid_hf.as_data_frame()['Survived'])
0.9441340782122905
模型可解釋性
我們使用來自Kaggle的著名 Teleco Churn Dataset [8]來解釋可解釋性接口。數(shù)據(jù)集混合了數(shù)字變量和分類變量,我們感興趣的變量是“流失”,用于識別上個月內(nèi)離開的客戶。我們使用原始格式的數(shù)據(jù)集,因為我們的重點是解釋模型而不是模型性能。
h2o.explain()
輸出解釋模型
解釋多個模型
當h2o.explain()提供模型列表時,將默認生成以下全局解釋:
排行榜(比較所有模型) Leader模型的混淆矩陣(僅限分類) Leader模型的殘差分析(僅限回歸) 排行榜頂部基礎(chǔ)模型(非堆疊)的重要性 變量重要性熱圖(比較所有非堆疊模型) 模型相關(guān)熱圖(比較所有模型) 基于頂層樹模型(TreeSHAP)的SHAP總結(jié) 部分依賴多圖 (PD) (比較所有模型) 個體條件期望圖 (ICE)
解釋單個模型
當h2o.explain()提供單個模型時,我們得到以下全局解釋:
混淆矩陣(僅限分類) 殘差分析(僅限回歸) 變量重要性 部分依賴圖 (PD) 個體條件期望圖 (ICE)
解釋繪圖功能
函數(shù)內(nèi)部使用了許多單獨的繪圖explain()函數(shù)。其中一些函數(shù)將一組模型作為輸入,而其他函數(shù)一次只評估一個模型。
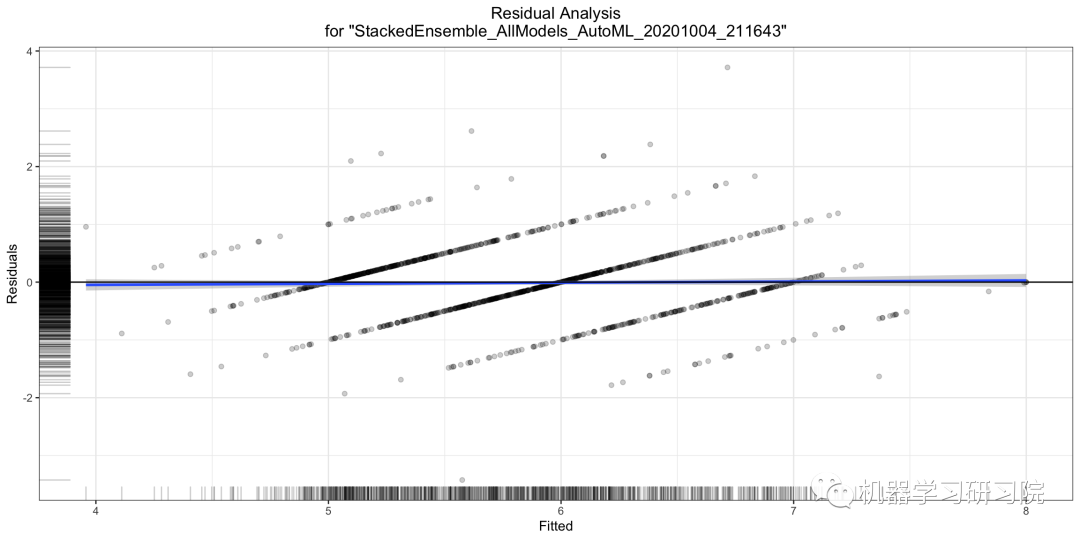
殘差分析
殘差分析在測試數(shù)據(jù)集上繪制擬合值與殘差。理想情況下,殘差應(yīng)該是隨機分布的。此圖中的模式可以指示模型選擇的潛在問題,例如,使用比必要更簡單的模型,不考慮異方差、自相關(guān)等。
ra_plot?=?model.residual_analysis_plot(test)
變量重要性
變量重要性圖顯示了模型中最重要變量的相對重要性。
該圖顯示了模型中最重要變量的相對重要性。H2O 在 0 和 1 之間縮放后顯示每個特征的重要性。變量重要性是通過每個變量的相對影響來計算的,主要用于像隨機森林這樣的基于樹的模型:在構(gòu)建樹時是否選擇了該變量進行拆分,以及平方誤差(整體樹)作為結(jié)果。
ra_plot?=?model.varimp_plot()
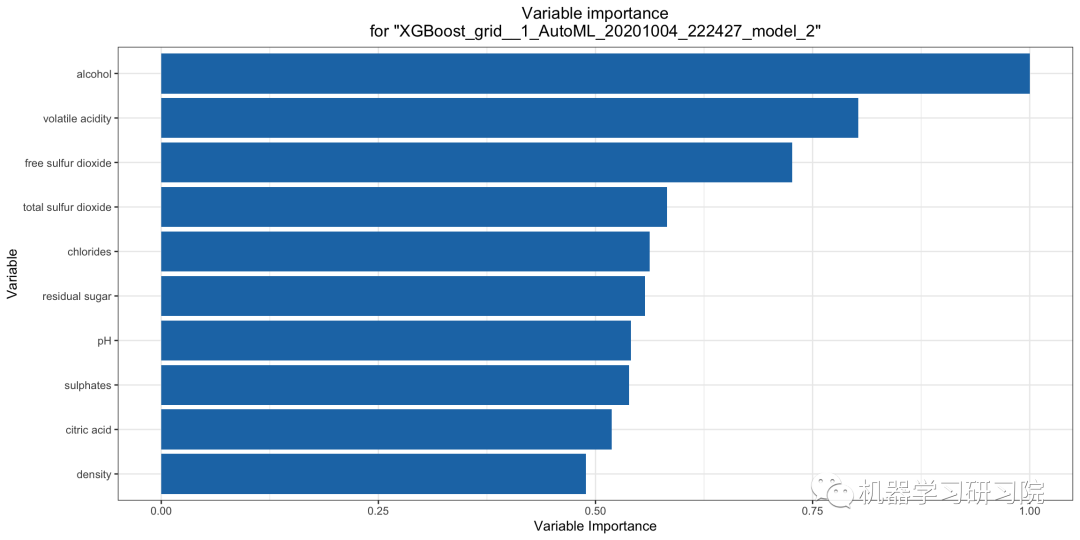
解釋這個圖很簡單。具有最長條的變量(也就是最頂部的)是最重要的,而具有最短條的變量(也就是最底部的)是最不重要的。
變量重要性熱圖
變量重要性熱圖顯示了多個模型中的重要變量。默認情況下,模型和變量按相似度排序。
H2O 中的一些模型為分類列的單熱(二進制指示符)編碼版本(例如深度學習、XGBoost)返回可變重要性。為了在所有模型類型中比較分類列的變量重要性,我們計算所有 one-hot 編碼特征的變量重要性的匯總,并返回原始分類特征的單個變量重要性。
va_plot?=?aml.varimp_heatmap()
#?或者如果需要一些模型的子集,就可以使用積分排行榜的一部分,
#?例如,使用MAE作為排序指標
va_plot?=?h2o.varimp_heatmap(aml.leaderboard.sort("mae").head(10))
#?甚至可以使用擴展排行榜
va_plot?=?h2o.varimp_heatmap(
???h2o.automl.get_leaderboard(
????????aml,extra_columns="training_time_ms"
????).sort("training_time_ms").head(10))
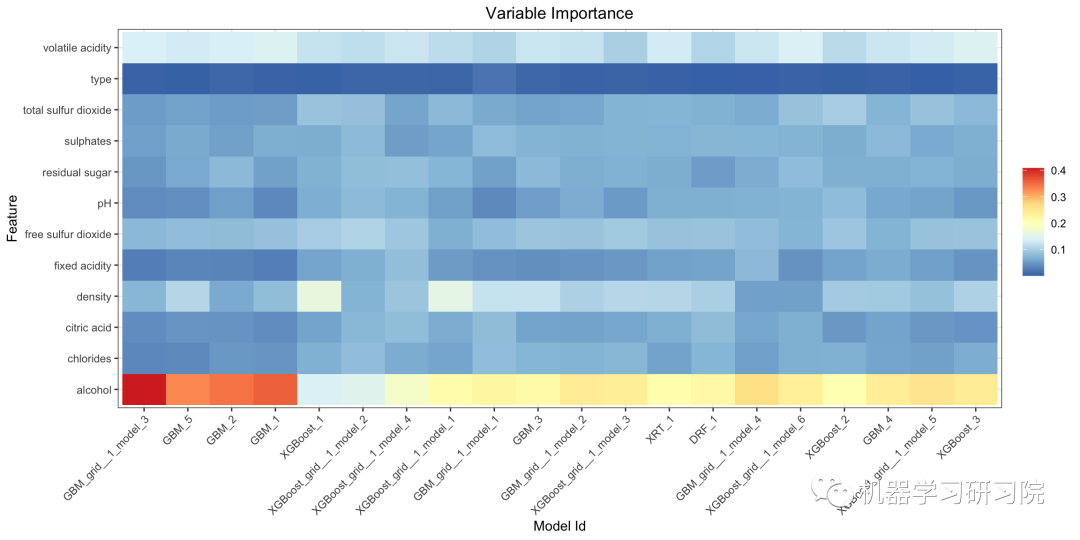
解釋
我們可以看顏色越深(紅色),對應(yīng)模型的變量的重要性就越高。即“alcihol”變量對所有 GBM / XGBoost 模型都比較重要,“type”對大多數(shù)模型并不重要。
模型相關(guān)熱圖
該圖顯示了模型預測之間的相關(guān)性。對于分類任務(wù),使用相同預測的頻率。默認情況下,模型按相似度排序(通過層次聚類計算)。GAM、GLM 和 RuleFit 等可解釋模型使用紅色文本突出顯示。
mc_plot?=?aml.model_correlation_heatmap(test)
#?或者如果需要一些模型的子集,就可以使用積分排行榜的一部分,
#?例如,使用MAE作為排序指標
mc_plot?=?h2o.model_correlation_heatmap(
??aml.leaderboard.sort("mae").head(10),?test)
#?甚至可以使用擴展排行榜
mc_plot?=?h2o.model_correlation_heatmap(
??h2o.automl.get_leaderboard(aml,
?????????????????????????????extra_columns="training_time_ms"
????????????????????????????).sort("training_time_ms").head(10),?test)
#?也可以在排行榜上使用更復雜的查詢,
#?例如,5個最快的模型之間的模型相關(guān)性訓練和堆疊整體
leaderboard?=?h2o.automl.get_leaderboard(aml,?extra_columns="training_time_ms").sort("training_time_ms")
mc_plot?=?h2o.model_correlation_heatmap(
??leaderboard.head(5).rbind(leaderboard[leaderboard["model_id"].grep("StackedEnsemble",?output_logical=True)]),?test)
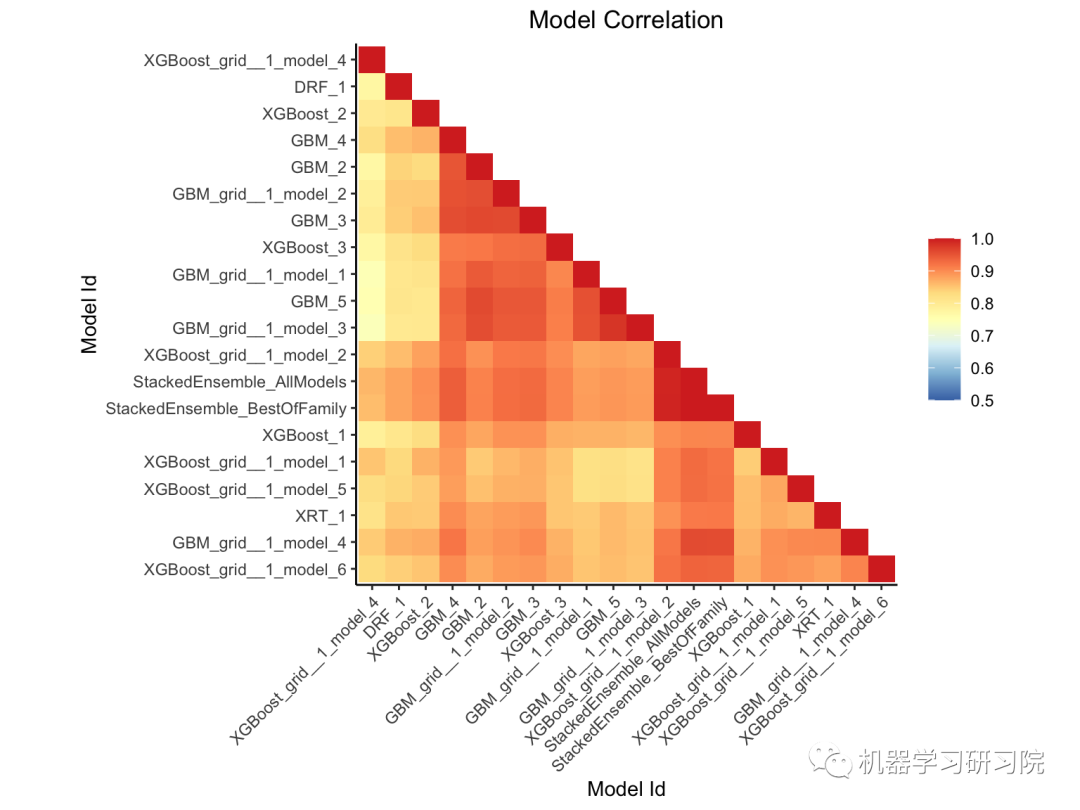
我們可以看到屬于同一家族的模型之間具有較強的相關(guān)性。顏色越深(紅色),兩個模型之間的相關(guān)性越強。
SHAP 總結(jié)圖
SHAP 值是SHapley Additive exPlanations的首字母縮寫詞,它解釋了給定變量具有特定值的影響,與如果該變量取某個基線值而我們所做的預測相比。如果你對SHAP不是很熟悉,推薦你查看??:??
用 SHAP 可視化解釋機器學習模型實用指南(上)
用 SHAP 可視化解釋機器學習模型實用指南(下)
shap_plot?=?model.shap_summary_plot(test)
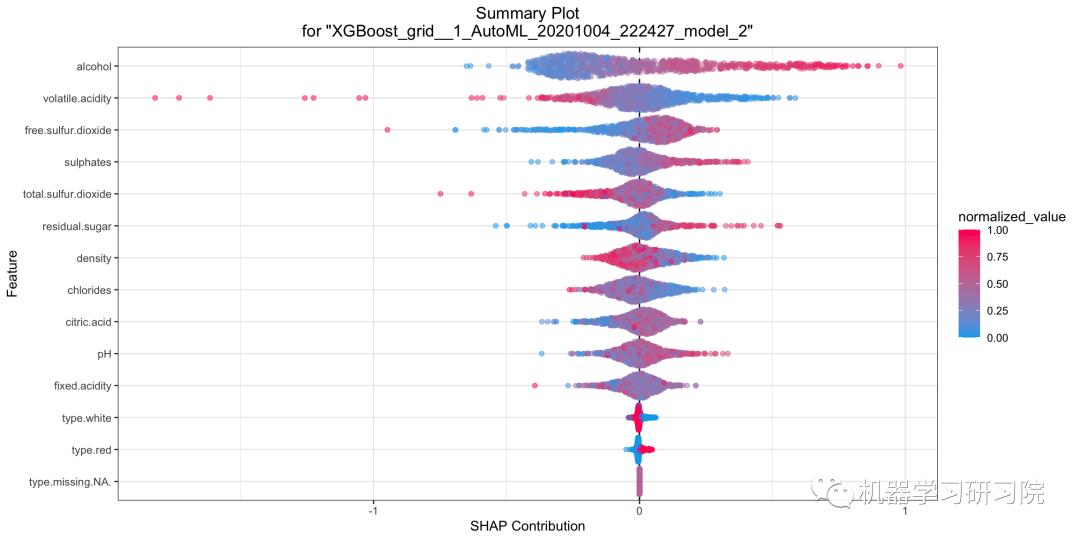
y軸表示變量名,通常按照從上到下的重要性降序排列。 x軸上的SHAP值表示log-odds的變化。從這個值中,我們可以提取事件的概率(在本例中是churn)。 漸變顏色表示該變量的原始值。在二元分類問題中(如我們的例子),它將使用兩種顏色,但它可以包含數(shù)值目標變量的整個光譜(回歸問題)。 圖中的每個點表示來自原始數(shù)據(jù)集的一條記錄。
SHAP 局部解釋
SHAP 解釋顯示了給定實例的特征的貢獻。特征貢獻和偏置項之和等于模型的原始預測,即應(yīng)用反向鏈接函數(shù)之前的預測。H2O 實現(xiàn)了 TreeSHAP,當特征相關(guān)時,可以增加對預測沒有影響的特征的貢獻。
shapr_plot?=?model.shap_explain_row_plot(test,?row_index=0)
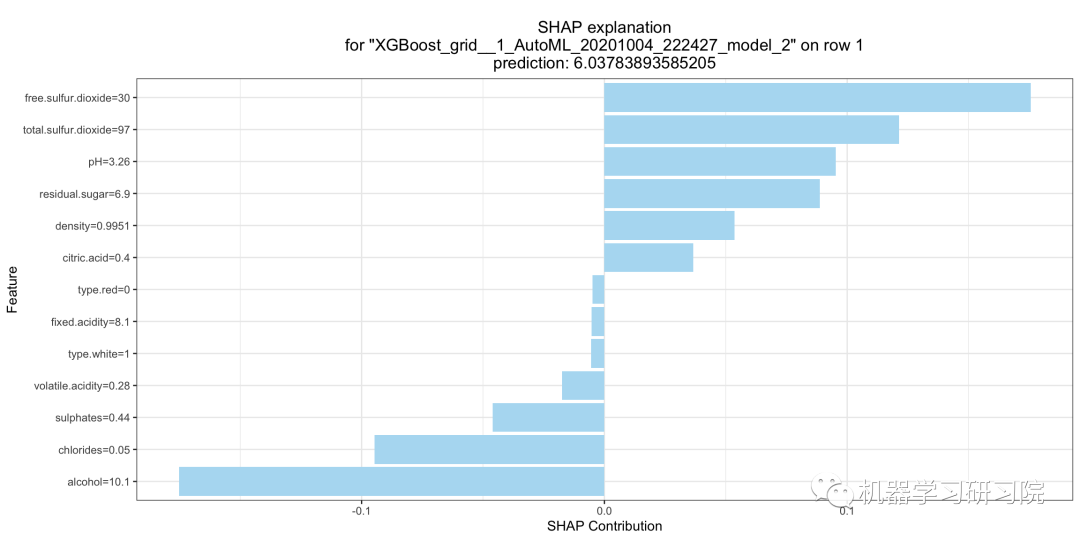
部分依賴圖(PDP)
雖然變量重要性顯示了哪些變量對預測的影響最大,但部分依賴圖顯示了變量如何影響預測。對于那些熟悉線性或回歸模型的人來說,PD 圖的解釋與這些回歸模型中的系數(shù)類似。
部分依賴圖 (PDP) 以圖形方式描述變量對響應(yīng)的邊際效應(yīng)。變量的影響是通過平均響應(yīng)的變化來衡量的。它假定計算 PDP 的特征與其他特征之間是獨立的。
pd_plot?=?aml.pd_multi_plot(test,?column)
#?或者如果需要一些模型的子集,就可以使用積分排行榜的一部分,
#?例如,使用MAE作為排序指標
pd_plot?=?h2o.pd_multi_plot(aml.leaderboard.sort("mae"),
????????????????????????????test,?column)
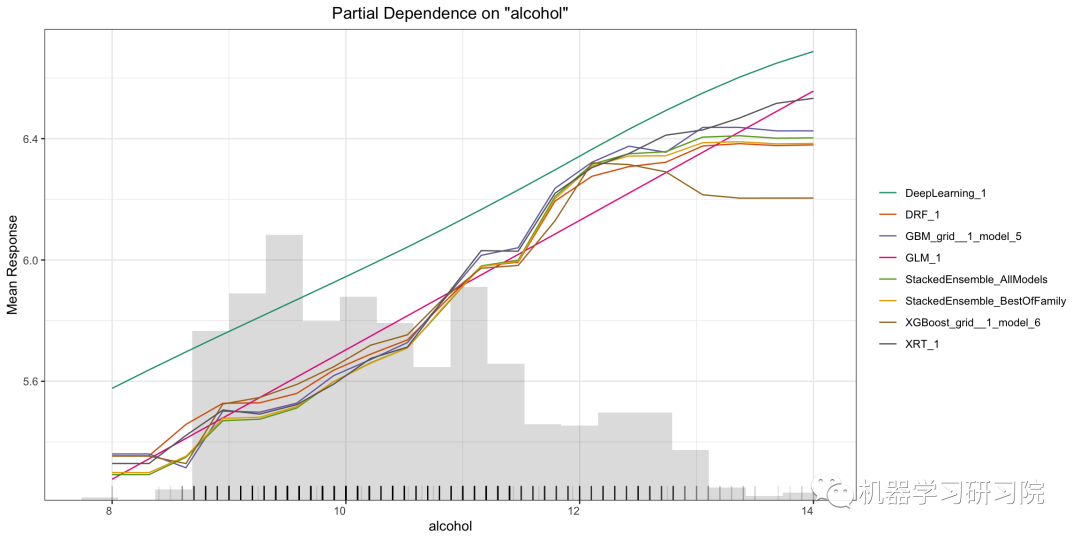
部分依賴單模型圖
這個可以回答該問題:控制所有其他特征,alcohol對紅酒質(zhì)量有什么影響?
pd_plot?=?model.pd_plot(test,?column)
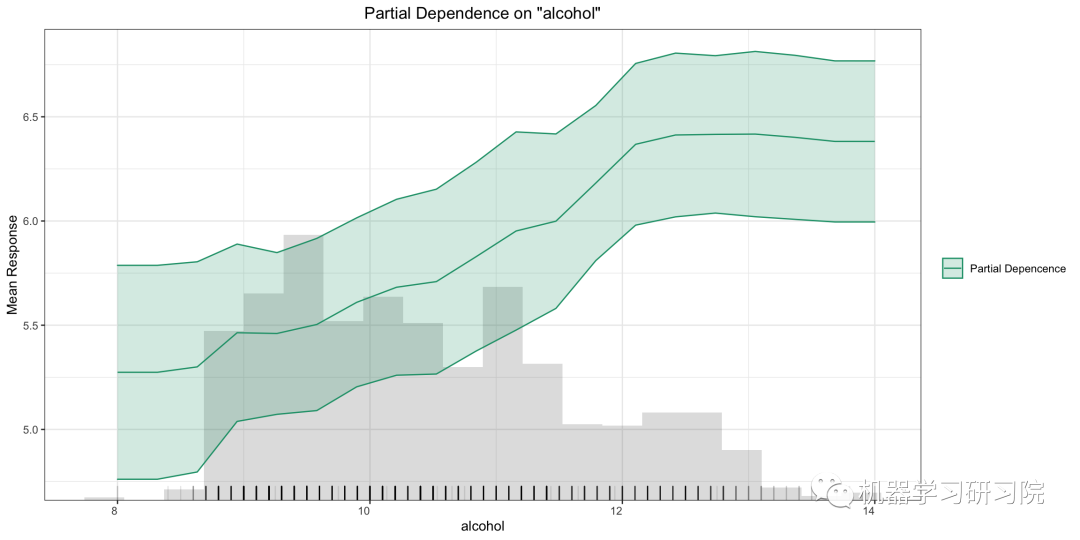
單模型、單行、PD 圖
pd_plot?=?model.pd_plot(test,?column,?row_index=0)
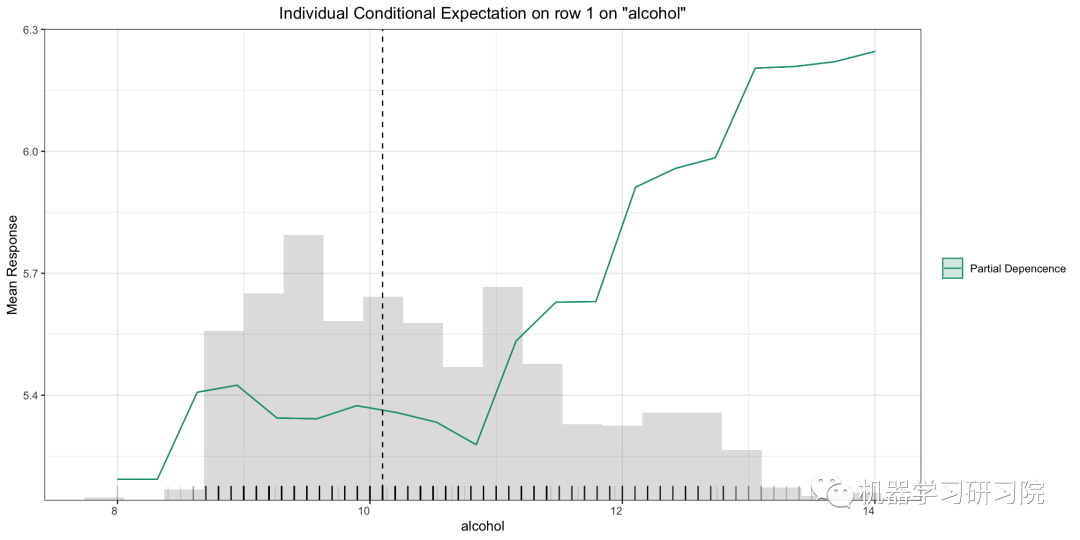
個體條件期望 (ICE) 圖
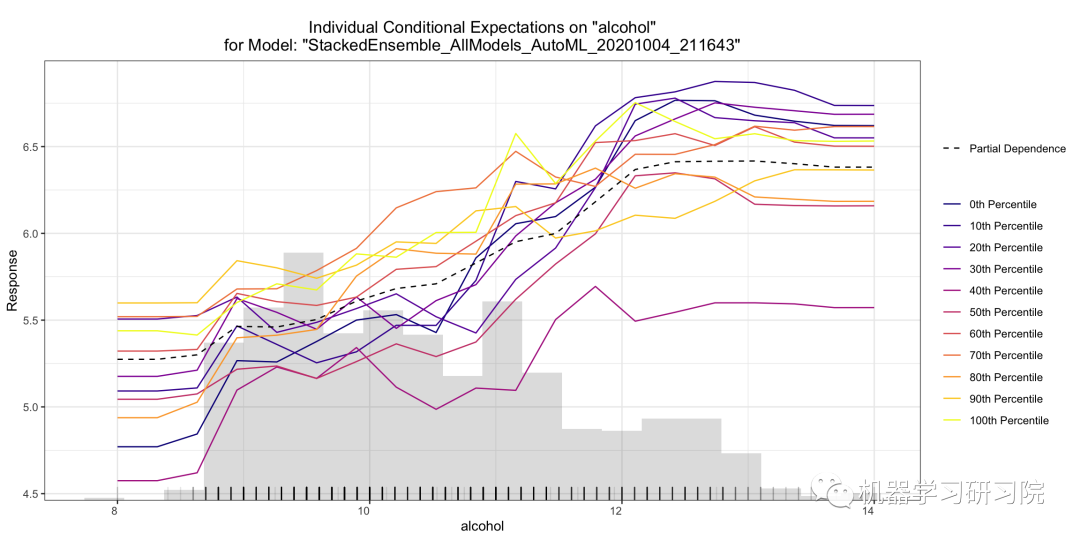
單個條件期望 (ICE) 圖以圖形方式描述了變量對響應(yīng)的邊際影響。ICE 圖類似于部分依賴圖(PDP);PDP 顯示變量的平均影響,而 ICE 圖顯示單個實例的影響。此函數(shù)將繪制每個十分位數(shù)的影響。
雖然 PDP 簡單易懂,但這種簡單性隱藏了各個實例之間潛在的有趣關(guān)系。例如,如果一個實例子集的特征值趨于負,而另一個子集趨于正,則平均過程可能會抵消它們。
ICE地塊解決了這個問題。ICE 圖展開曲線,這是 PDP 中聚合過程的結(jié)果。每條 ICE 曲線不是對預測進行平均,而是顯示改變實例特征值的預測。當在單個圖中一起呈現(xiàn)時,它顯示了實例子集之間的關(guān)系以及各個實例行為方式的差異。
ice_plot?=?model.ice_plot(test,?column)
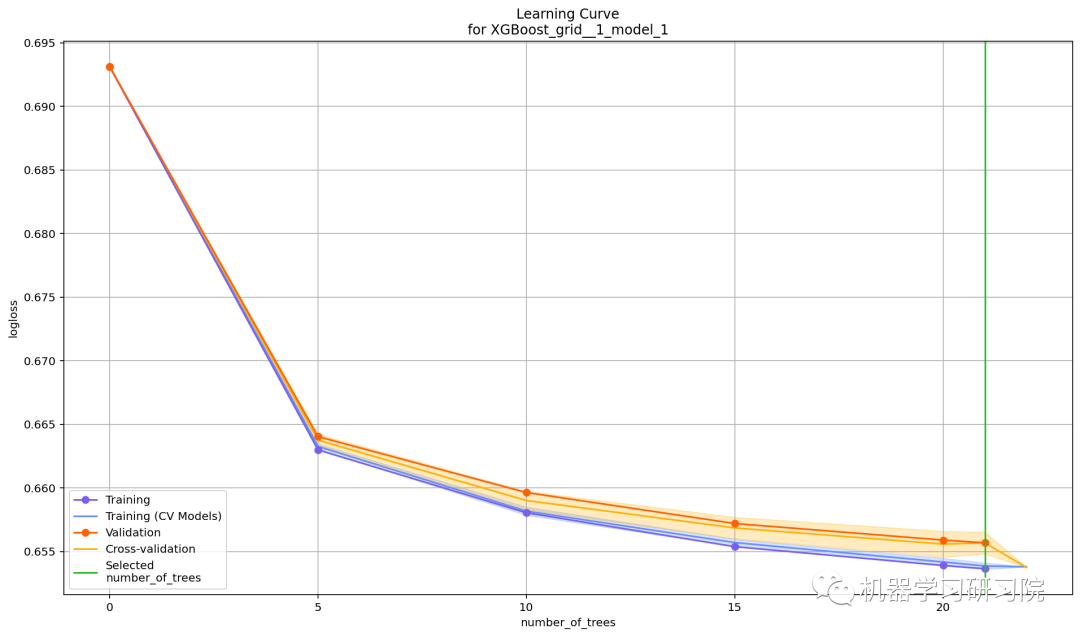
學習曲線
學習曲線圖顯示了誤差度量對學習進度的依賴性(例如 RMSE 與迄今為止在 GBM 中訓練的樹的數(shù)量)。該圖可以幫助診斷模型是過擬合還是欠擬合——在理想情況下,訓練曲線和驗證曲線會收斂。最多可以有 4 條曲線顯示錯誤,并且將繪制所有可用的指標:
訓練 驗證( validation_frame設(shè)置時可用)CV 模型訓練(在 nfolds>1時可用)交叉驗證(在 nfolds>1時可用)
learning_curve_plot?=?model.learning_curve_plot()
保存和導入模型
#?構(gòu)建模型
model?=?H2ODeepLearningEstimator(params)
model.train(params)
#?保存模型
model_path?=?h2o.save_model(model=model,?path="/tmp/mymodel",?force=True)
print(model_path)
>>>?/tmp/mymodel/DeepLearning_model_python_1441838096933
#?導入模型
saved_model?=?h2o.load_model(model_path)
#?將上面構(gòu)建的模型下載到本地機器
my_local_model?=?h2o.download_model(model,?path="/Users/UserName/Desktop")
#?上傳你剛才下載的模型
#?to?the?H2O?cluster
uploaded_model?=?h2o.upload_model(my_local_model)
參考資料
GitHub地址: https://github.com/h2oai/h2o-3
[2]Download地址: http://h2o-release.s3.amazonaws.com/h2o/latest_stable.html
[3]Document地址: https://docs.h2o.ai/h2o/latest-stable/h2o-docs/index.html
[4]Flow: http://docs.h2o.ai/h2o/latest-stable/h2o-docs/flow.html
[5]h2o下載: http://h2o-release.s3.amazonaws.com/h2o/latest_stable.html
[6]https: https://github.com/h2oai/h2o-3/blob/master/h2o-py/conda/h2o/meta.yaml
[7]kaggle泰坦尼克案例: https://www.kaggle.com/code/andreshg/titanic-dicaprio-s-safety-guide-h2o-automl/notebook
[8]Teleco Churn Dataset : https://www.kaggle.com/blastchar/telco-customer-churn
往期精彩回顧
適合初學者入門人工智能的路線及資料下載 (圖文+視頻)機器學習入門系列下載 中國大學慕課《機器學習》(黃海廣主講) 機器學習及深度學習筆記等資料打印 《統(tǒng)計學習方法》的代碼復現(xiàn)專輯 AI基礎(chǔ)下載 機器學習交流qq群955171419,加入微信群請掃碼: