
第12章 PyTorch圖像分割代碼框架-2
模型模塊
本書的第5-9章重點介紹了各種2D和3D的語義分割和實例分割網(wǎng)絡(luò)模型,所以在模型模塊中,我們需要做的事情就是將要實驗的分割網(wǎng)絡(luò)寫在該目錄下。有時候我們可能想嘗試不同的分割網(wǎng)絡(luò)結(jié)構(gòu),所以在該目錄下可以存在多個想要實驗的網(wǎng)絡(luò)模型定義文件。對于PASCAL VOC這樣的自然數(shù)據(jù)集,我們可能想實驗Deeplab v3+、PSPNet、RefineNet等網(wǎng)絡(luò)的訓(xùn)練效果。代碼11-3給出了Deeplab v3+網(wǎng)絡(luò)封裝后的主體部分,完整網(wǎng)絡(luò)搭建代碼可參考本書配套代碼對應(yīng)章節(jié)。
代碼11-3 Deeplab v3+網(wǎng)絡(luò)的主體部分
# 定義Deeplab V3+類class DeepLabHeadV3Plus(nn.Module):def __init__(self, in_channels, low_level_channels, num_classes, aspp_dilate=[12, 24, 36]):super(DeepLabHeadV3Plus, self).__init__()self.project = nn.Sequential(nn.Conv2d(low_level_channels, 48, 1, bias=False),nn.BatchNorm2d(48),nn.ReLU(inplace=True),)# ASPPself.aspp = ASPP(in_channels, aspp_dilate)# classifier headself.classifier = nn.Sequential(nn.Conv2d(304, 256, 3, padding=1, bias=False),nn.BatchNorm2d(256),nn.ReLU(inplace=True),nn.Conv2d(256, num_classes, 1))self._init_weight()# forward methoddef forward(self, feature):# print(feature['low_level'].shape)# print(feature['out'].shape)low_level_feature = self.project(feature['low_level'])output_feature = self.aspp(feature['out'])output_feature = F.interpolate(output_feature, size=low_level_feature.shape[2:], mode='bilinear', align_corners=False)return self.classifier(torch.cat([low_level_feature, output_feature], dim=1))# weight initilizedef _init_weight(self):for m in self.modules():if isinstance(m, nn.Conv2d):nn.init.kaiming_normal_(m.weight)elif isinstance(m, (nn.BatchNorm2d, nn.GroupNorm)):nn.init.constant_(m.weight, 1)nn.init.constant_(m.bias, 0)
對于復(fù)雜網(wǎng)絡(luò)搭建,一般都是采用自下而上的搭建方法,先搭建底層組件,再逐步向上封裝,對于本例中的Deeplab v3+,可以先分別搭建backbone骨干網(wǎng)絡(luò)、ASPP和編解碼結(jié)構(gòu),最后再進(jìn)行封裝。
工具函數(shù)模塊
工具函數(shù)是為項目完成各項功能所自定義的輔助函數(shù),可以統(tǒng)一定義在utils文件夾下,根據(jù)實際項目的不同,工具函數(shù)也各不相同。常用的工具函數(shù)包括各種損失函數(shù)的定義loss.py、訓(xùn)練可視化函數(shù)的定義visualize.py、用于記錄訓(xùn)練日志的log.py等。代碼11-4給出了一個關(guān)于Focal loss損失函數(shù)的定義,該損失函數(shù)作為工具函數(shù)可放在loss.py文件中。
代碼11-4 工具函數(shù)示例:定義一個Focal loss
# 導(dǎo)入相關(guān)庫import torchimport torch.nn as nnimport torch.nn.functional as F# 定義一個Focal loss類class FocalLoss(nn.Module):def __init__(self, alpha=1, gamma=2):super(FocalLoss, self).__init__()self.alpha = alphaself.gamma = gammadef forward(self, inputs, targets):# Compute cross-entropy lossce_loss = F.cross_entropy(inputs, targets, reduction='none')# Compute the focal losspt = torch.exp(-ce_loss)focal_loss = self.alpha * (1 - pt) ** self.gamma * ce_lossreturn focal_loss.mean()
配置模塊
配置模塊是為項目模型訓(xùn)練傳入各種參數(shù)而進(jìn)行設(shè)置的模塊,比如訓(xùn)練數(shù)據(jù)所在目錄、訓(xùn)練所需要的各種參數(shù)、訓(xùn)練過程是否需要可視化等。一般來說,我們有兩種方式來對項目執(zhí)行參數(shù)進(jìn)行配置管理,一種是直接在主函數(shù)main.py中使用argparse庫對參數(shù)進(jìn)行配置,然后再命令行中進(jìn)行傳入;另一種則是單獨(dú)定義一個config.py或者config.yaml文件來對所有參數(shù)進(jìn)行統(tǒng)一配置。基于argparse庫的參數(shù)配置管理簡單示例如代碼11-5所示。
代碼11-5 argparser參數(shù)配置管理
# 導(dǎo)入argparse庫import argparse# 創(chuàng)建參數(shù)管理器parser = argparse.ArgumentParser()# 涉及數(shù)據(jù)相關(guān)的參數(shù)管理parser.add_argument("--data_root", type=str, default='./dataset',help="path to Dataset")parser.add_argument("--save_root", type=str, default='./',help="path to save result")parser.add_argument("--dataset", type=str, default='voc',choices=['voc', 'cityscapes', 'ade'], help='Name of dataset')parser.add_argument("--num_classes", type=int, default=None,help="num classes (default: None)")
在上述代碼中,我們基于argparse給出了一小部分參數(shù)配置管理代碼,涉及訓(xùn)練數(shù)據(jù)相關(guān)的部分參數(shù),包括數(shù)據(jù)讀取路徑、存放路徑、訓(xùn)練所用數(shù)據(jù)集、分割類別數(shù)量等。
主函數(shù)模塊
主函數(shù)模塊main.py是項目的啟動模塊,該模塊將定義好的數(shù)據(jù)和模型模塊進(jìn)行組裝,并結(jié)合損失函數(shù)、優(yōu)化器、評估方法和可視化等組件,將config.py中配置好的項目參數(shù)傳入,根據(jù)訓(xùn)練-驗證的模式,執(zhí)行圖像分割項目模型訓(xùn)練和驗證。代碼11-6是VOC數(shù)據(jù)集訓(xùn)練驗證部分代碼。
代碼11-6 主函數(shù)模塊中的訓(xùn)練迭代部分
# 初始化區(qū)間損失interval_loss = 0while True:# 執(zhí)行訓(xùn)練model.train()cur_epochs += 1for (images, labels) in train_loader:cur_itrs += 1images = images.to(device, dtype=torch.float32)labels = labels.to(device, dtype=torch.long)optimizer.zero_grad()outputs = model(images)loss = criterion(outputs, labels)loss.backward()optimizer.step()np_loss = loss.detach().cpu().numpy()interval_loss += np_lossif vis is not None:vis.vis_scalar('Loss', cur_itrs, np_loss)# 打印訓(xùn)練信息if (cur_itrs) % opts.print_interval == 0:pass# 保存模型if (cur_itrs) % opts.val_interval == 0:pass# 日志記錄logger.info("Save the latest model to %s" % save_path_checkpoints)# 模型驗證print("validation...")model.eval()val_score, ret_samples = validate(opts=opts, model=model, loader=val_loader, device=device, metrics=metrics,ret_samples_ids=vis_sample_id)logger.info("Validation performance: %s", val_score)# 保存最優(yōu)模型if val_score['mean_dice'] > best_score:best_score = val_score['mean_dice']save_ckpt(os.path.join(save_path_checkpoints, 'best_%s_%s_os%d.pth' %(opts.model, opts.dataset, opts.output_stride)))logger.info("Save best-performance model so far to %s" % save_path_checkpoints)# 訓(xùn)練過程可視化if vis is not None:vis.vis_scalar("[Val] Overall Acc", cur_itrs, val_score['Overall Acc'])vis.vis_scalar("[Val] Mean IoU", cur_itrs, val_score['Mean IoU'])vis.vis_table("[Val] Class IoU", val_score['Class IoU'])for k, (img, target, lbl) in enumerate(ret_samples):img = (denorm(img) * 255).astype(np.uint8)target = train_dst.decode_target(target).transpose(2, 0, 1).astype(np.uint8)lbl = train_dst.decode_target(lbl).transpose(2, 0, 1).astype(np.uint8)concat_img = np.concatenate((img, target, lbl), axis=2)vis.vis_image('Sample %d' % k, concat_img)scheduler.step()
在代碼11-6中,我們展示了一個圖像分割項目主函數(shù)模塊中最核心的訓(xùn)練和驗證部分。在訓(xùn)練時,按照指定迭代次數(shù)保存模型和對訓(xùn)練過程進(jìn)行可視化展示。圖11-2為訓(xùn)練打印的部分信息。
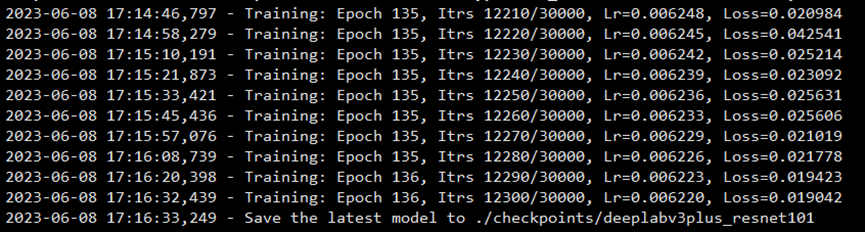
圖11-2 VOC訓(xùn)練過程信息
圖11-3為基于visdom的訓(xùn)練過程可視化展示,包括當(dāng)前訓(xùn)練配置參數(shù)信息,訓(xùn)練損失函數(shù)變化曲線、驗證集全局準(zhǔn)確率、mIoU和類別IoU等指標(biāo)變化曲線圖。
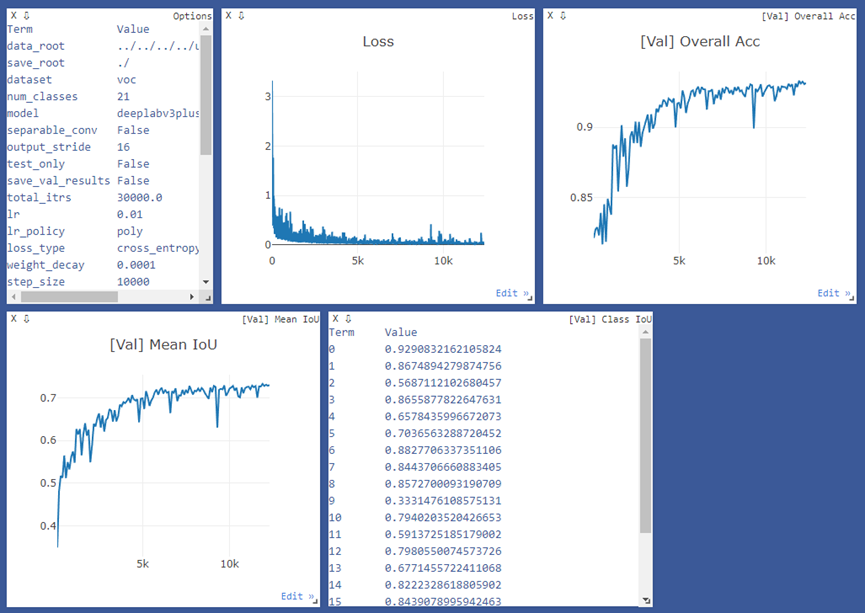
圖11-3 Deeplab v3+訓(xùn)練過程可視化
圖11-4展示了兩組訓(xùn)練過程中驗證集的輸入圖像、標(biāo)簽圖像和模型預(yù)測圖像的對比圖。可以看到,基于Deeplab v3+的分割模型在PASCAL VOC 2012上表現(xiàn)還不錯。

圖11-4 驗證集模型效果圖
后續(xù)全書內(nèi)容和代碼將在github上開源,請關(guān)注倉庫:
https://github.com/luwill/Deep-Learning-Image-Segmentation
(未完待續(xù))