
三個優(yōu)秀的PyTorch實現(xiàn)語義分割框架
點擊下方卡片,關(guān)注“新機器視覺”公眾號
視覺/圖像重磅干貨,第一時間送達(dá)
使用的VOC數(shù)據(jù)集鏈接開放在文章中,預(yù)訓(xùn)練模型已上傳Github,環(huán)境我使用Colab pro,大家下載模型做預(yù)測即可。
代碼鏈接: https://github.com/lixiang007666/segmentation-learning-experiment-pytorch
使用方法:
-
下載VOC數(shù)據(jù)集,將 JPEGImagesSegmentationClass兩個文件夾放入到data文件夾下。 -
終端切換到目標(biāo)目錄,運行 python train.py -h查看訓(xùn)練
(torch) qust116-jq@qustx-X299-WU8:~/語義分割$ python train.py -h
usage: train.py [-h] [-m {Unet,FCN,Deeplab}] [-g GPU]
choose the model
optional arguments:
-h, --help show this help message and exit
-m {Unet,FCN,Deeplab}, --model {Unet,FCN,Deeplab}
輸入模型名字
-g GPU, --gpu GPU 輸入所需GPU
選擇模型和GPU編號進(jìn)行訓(xùn)練,例如運行python train.py -m Unet -g 0
-
預(yù)測需要手動修改 predict.py中的模型
如果對FCN非常了解的,可以直接跳過d2l(動手學(xué)深度學(xué)習(xí))的講解到最后一部分。
2 數(shù)據(jù)集
VOC數(shù)據(jù)集一般是用來做目標(biāo)檢測,在2012版本中,加入了語義分割任務(wù)。
基礎(chǔ)數(shù)據(jù)集中包括:含有1464張圖片的訓(xùn)練集,1449的驗證集和1456的測試集。一共有21類物體。
PASCAL VOC分割任務(wù)中,共有20個類別的對象,其他內(nèi)容作為背景類,其中紅色代表飛機類,黑色是背景,飛機邊界部分用米黃色(看著像白色)線條描繪,表示分割模糊區(qū)。
其中,分割標(biāo)簽都是png格式的圖像,該圖像其實是單通道的顏色索引圖像,該圖像除了有一個單通道和圖像大小一樣的索引圖像外,還存儲了256個顏色值列表(調(diào)色板),每一個索引值對應(yīng)調(diào)色板里一個RGB顏色值,因此,一個單通道的索引圖+調(diào)色板就能表示彩色圖。
原圖:
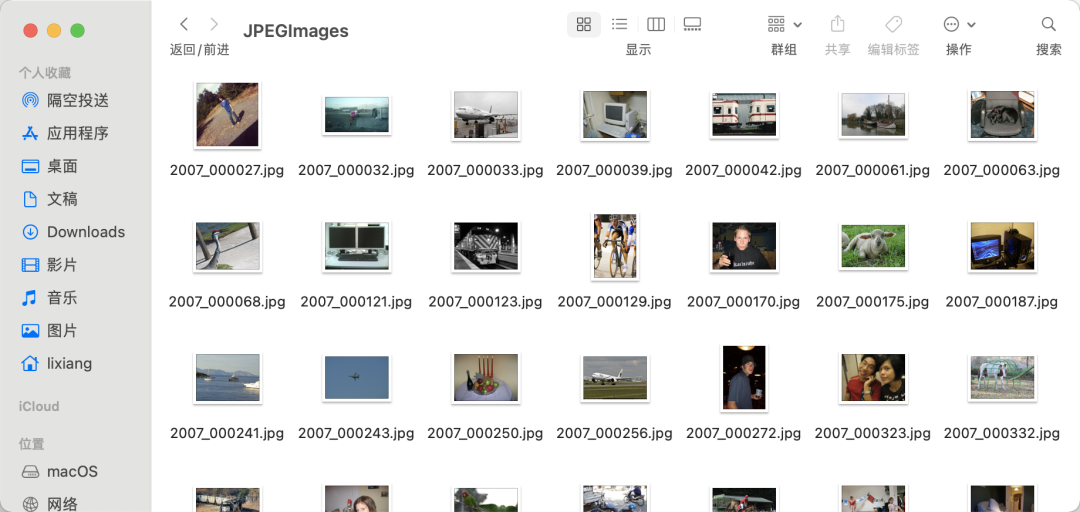
標(biāo)簽:
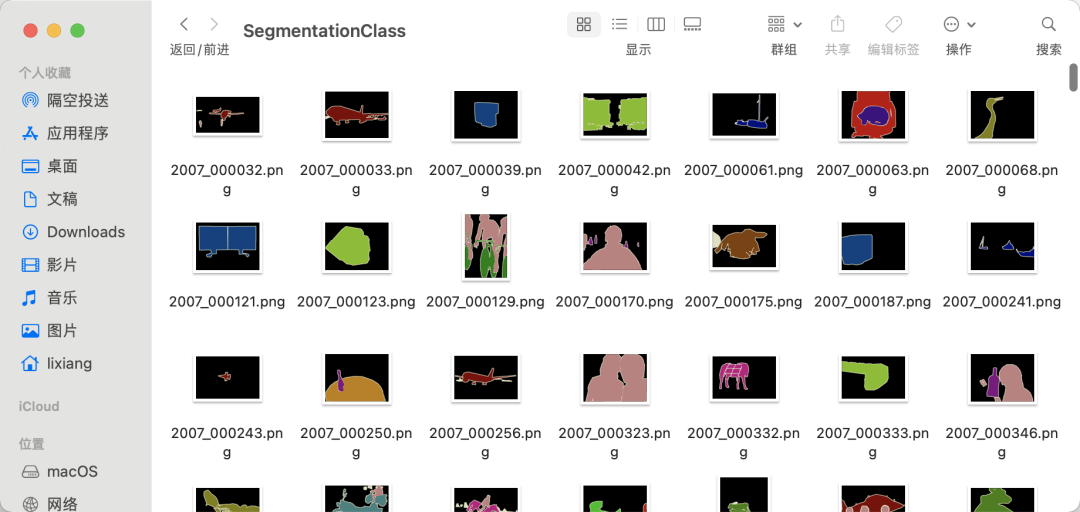
挑選一張圖像可以發(fā)現(xiàn),單張圖像分割類別不只兩類,且每張圖像類別不固定。

語義分割能對圖像中的每個像素分類。全卷積網(wǎng)絡(luò) (fully convolutional network,F(xiàn)CN) 采用卷積神經(jīng)網(wǎng)絡(luò)實現(xiàn)了從圖像像素到像素類別的變換 。與我們之前在圖像分類或目標(biāo)檢測部分介紹的卷積神經(jīng)網(wǎng)絡(luò)不同,全卷積網(wǎng)絡(luò)將中間層特征圖的高和寬變換回輸入圖像的尺寸:這是通過中引入的轉(zhuǎn)置卷積(transposed convolution)層實現(xiàn)的。因此,輸出的類別預(yù)測與輸入圖像在像素級別上具有一一對應(yīng)關(guān)系:給定空間維上的位置,通道維的輸出即該位置對應(yīng)像素的類別預(yù)測。
%matplotlib inline
import torch
import torchvision
from torch import nn
from torch.nn import functional as F
from d2l import torch as d2l
3.1 網(wǎng)絡(luò)結(jié)構(gòu)
全卷積網(wǎng)絡(luò)先使用卷積神經(jīng)網(wǎng)絡(luò)抽取圖像特征,然后通過
卷積層將通道數(shù)變換為類別個數(shù),最后再通過轉(zhuǎn)置卷積層將特征圖的高和寬變換為輸入圖像的尺寸。因此,模型輸出與輸入圖像的高和寬相同,且最終輸出的通道包含了該空間位置像素的類別預(yù)測。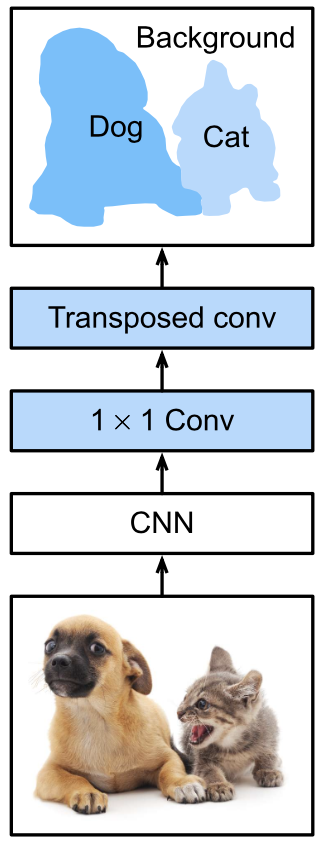
下面,我們使用在ImageNet數(shù)據(jù)集上預(yù)訓(xùn)練的ResNet-18模型來提取圖像特征,并將該網(wǎng)絡(luò)實例記為pretrained_net。該模型的最后幾層包括全局平均匯聚層和全連接層,然而全卷積網(wǎng)絡(luò)中不需要它們。
pretrained_net = torchvision.models.resnet18(pretrained=True)
list(pretrained_net.children())[-3:]
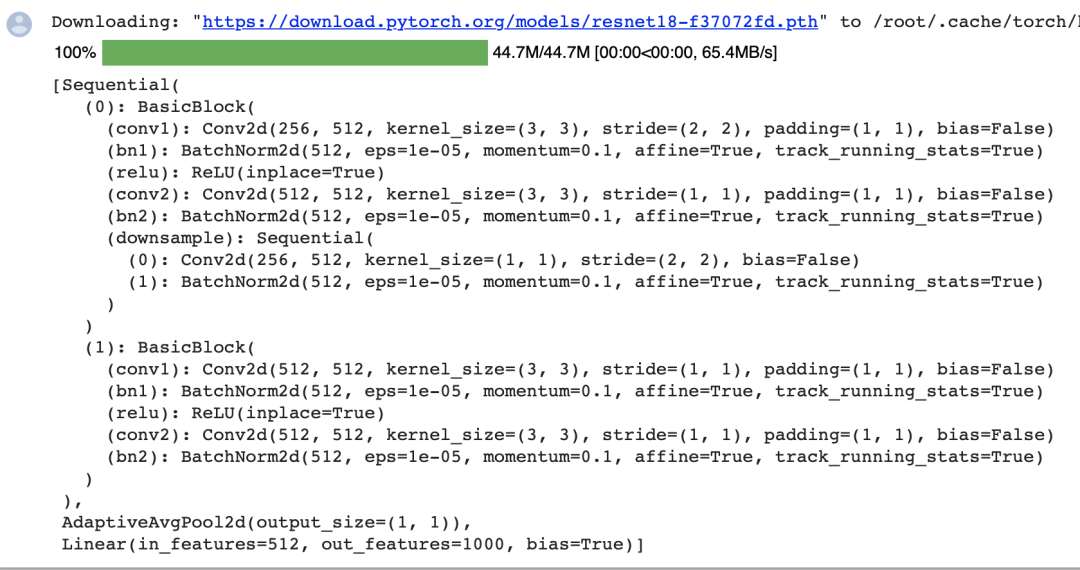 創(chuàng)建一個全卷積網(wǎng)絡(luò)實例
創(chuàng)建一個全卷積網(wǎng)絡(luò)實例net。它復(fù)制了Resnet-18中大部分的預(yù)訓(xùn)練層,但除去最終的全局平均匯聚層和最接近輸出的全連接層。
net = nn.Sequential(*list(pretrained_net.children())[:-2])
給定高度和寬度分別為320和480的輸入,net的前向計算將輸入的高和寬減小至原來的
,即10和15。
X = torch.rand(size=(1, 3, 320, 480))
net(X).shape
 使用
卷積層將輸出通道數(shù)轉(zhuǎn)換為Pascal VOC2012數(shù)據(jù)集的類數(shù)(21類)。最后,我們需要將要素地圖的高度和寬度增加32倍,從而將其變回輸入圖像的高和寬。
使用
卷積層將輸出通道數(shù)轉(zhuǎn)換為Pascal VOC2012數(shù)據(jù)集的類數(shù)(21類)。最后,我們需要將要素地圖的高度和寬度增加32倍,從而將其變回輸入圖像的高和寬。
回想一下卷積層輸出形狀的計算方法:
由于 且 ,我們構(gòu)造一個步幅為 的轉(zhuǎn)置卷積層,并將卷積核的高和寬設(shè)為 ,填充為 。
我們可以看到如果步幅為 ,填充為 (假設(shè) 是整數(shù))且卷積核的高和寬為 ,轉(zhuǎn)置卷積核會將輸入的高和寬分別放大 倍。
num_classes = 21
net.add_module('final_conv', nn.Conv2d(512, num_classes, kernel_size=1))
net.add_module('transpose_conv', nn.ConvTranspose2d(num_classes, num_classes,
kernel_size=64, padding=16, stride=32))
3.2 初始化轉(zhuǎn)置卷積層
將圖像放大通常使用上采樣(upsampling)方法。雙線性插值(bilinear interpolation) 是常用的上采樣方法之一,它也經(jīng)常用于初始化轉(zhuǎn)置卷積層。
為了解釋雙線性插值,假設(shè)給定輸入圖像,我們想要計算上采樣輸出圖像上的每個像素。
首先,將輸出圖像的坐標(biāo) (??,??) 映射到輸入圖像的坐標(biāo) (??′,??′) 上。例如,根據(jù)輸入與輸出的尺寸之比來映射。請注意,映射后的 ??′ 和 ??′ 是實數(shù)。
然后,在輸入圖像上找到離坐標(biāo) (??′,??′) 最近的4個像素。
最后,輸出圖像在坐標(biāo) (??,??) 上的像素依據(jù)輸入圖像上這4個像素及其與 (??′,??′) 的相對距離來計算。
雙線性插值的上采樣可以通過轉(zhuǎn)置卷積層實現(xiàn),內(nèi)核由以下bilinear_kernel函數(shù)構(gòu)造。限于篇幅,我們只給出bilinear_kernel函數(shù)的實現(xiàn),不討論算法的原理。
def bilinear_kernel(in_channels, out_channels, kernel_size):
factor = (kernel_size + 1) // 2
if kernel_size % 2 == 1:
center = factor - 1
else:
center = factor - 0.5
og = (torch.arange(kernel_size).reshape(-1, 1),
torch.arange(kernel_size).reshape(1, -1))
filt = (1 - torch.abs(og[0] - center) / factor) * \
(1 - torch.abs(og[1] - center) / factor)
weight = torch.zeros((in_channels, out_channels,
kernel_size, kernel_size))
weight[range(in_channels), range(out_channels), :, :] = filt
return weight
用雙線性插值的上采樣實驗它由轉(zhuǎn)置卷積層實現(xiàn)。我們構(gòu)造一個將輸入的高和寬放大2倍的轉(zhuǎn)置卷積層,并將其卷積核用bilinear_kernel函數(shù)初始化。
conv_trans = nn.ConvTranspose2d(3, 3, kernel_size=4, padding=1, stride=2,
bias=False)
conv_trans.weight.data.copy_(bilinear_kernel(3, 3, 4));
在全卷積網(wǎng)絡(luò)中,我們用雙線性插值的上采樣初始化轉(zhuǎn)置卷積層。對于 1×1卷積層,我們使用Xavier初始化參數(shù)。
W = bilinear_kernel(num_classes, num_classes, 64)
net.transpose_conv.weight.data.copy_(W);
3.3 訓(xùn)練
損失函數(shù)和準(zhǔn)確率計算與圖像分類中的并沒有本質(zhì)上的不同,因為我們使用轉(zhuǎn)置卷積層的通道來預(yù)測像素的類別,所以在損失計算中通道維是指定的。此外,模型基于每個像素的預(yù)測類別是否正確來計算準(zhǔn)確率。
def loss(inputs, targets):
return F.cross_entropy(inputs, targets, reduction='none').mean(1).mean(1)
num_epochs, lr, wd, devices = 5, 0.001, 1e-3, d2l.try_all_gpus()
trainer = torch.optim.SGD(net.parameters(), lr=lr, weight_decay=wd)
d2l.train_ch13(net, train_iter, test_iter, loss, trainer, num_epochs, devices)
4 開源代碼和Dataset
數(shù)據(jù)集下載地址:http://host.robots.ox.ac.uk/pascal/VOC/voc2012/VOCtrainval_11-May-2012.tar
輸入樣本:
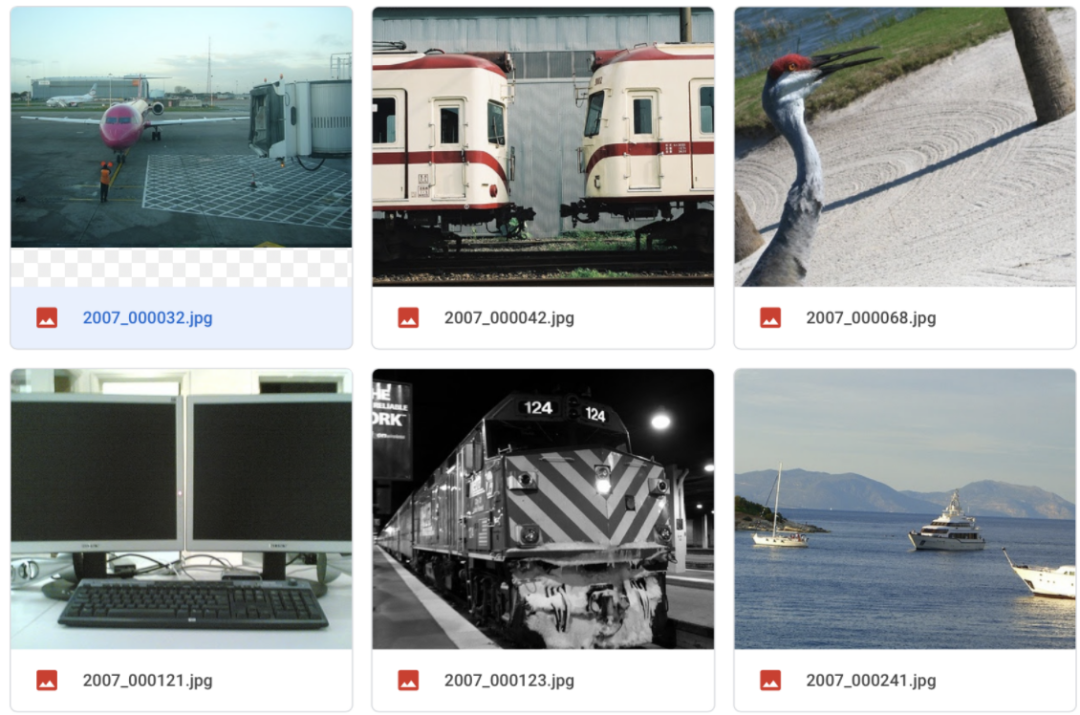
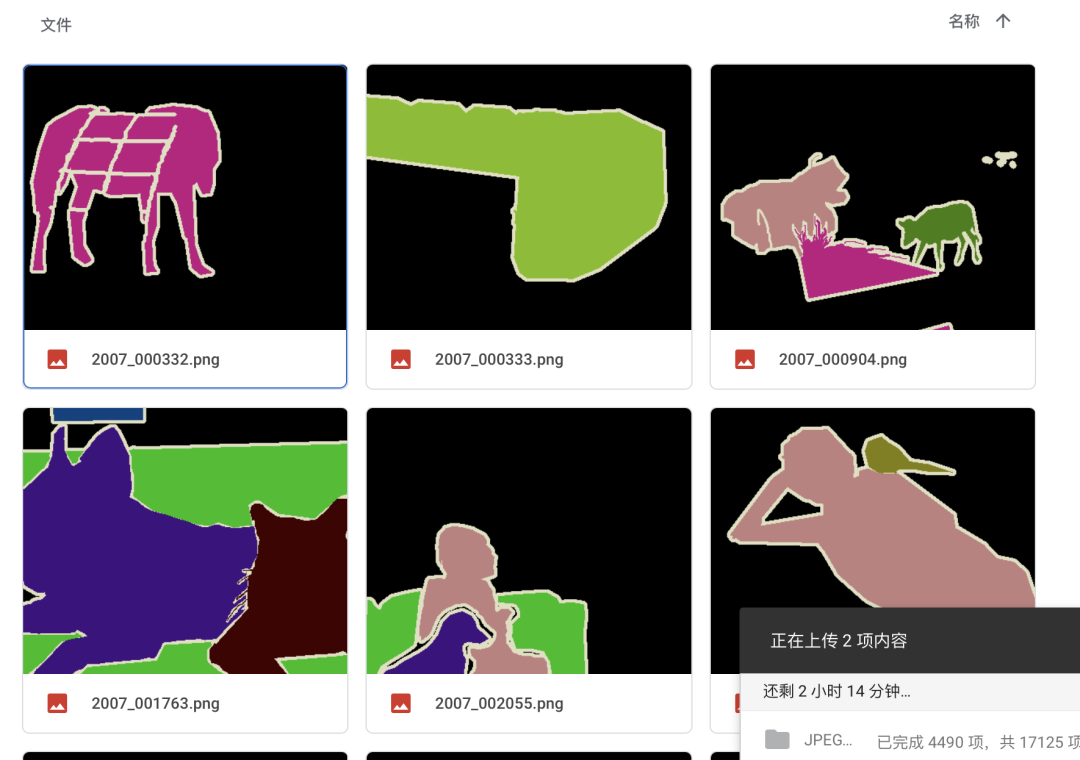
輸出樣本:
運行Segmentat_pytorch.ipynp:
 訓(xùn)練:
訓(xùn)練:
!python3 train.py -m Unet -g 0
預(yù)測:
模型代碼包括FCN、U-Net和Deeplab的實現(xiàn),大家可以更方便的更換模型訓(xùn)練和預(yù)測。
DeeplabV3分割結(jié)果: FCN分割結(jié)果:
FCN分割結(jié)果:
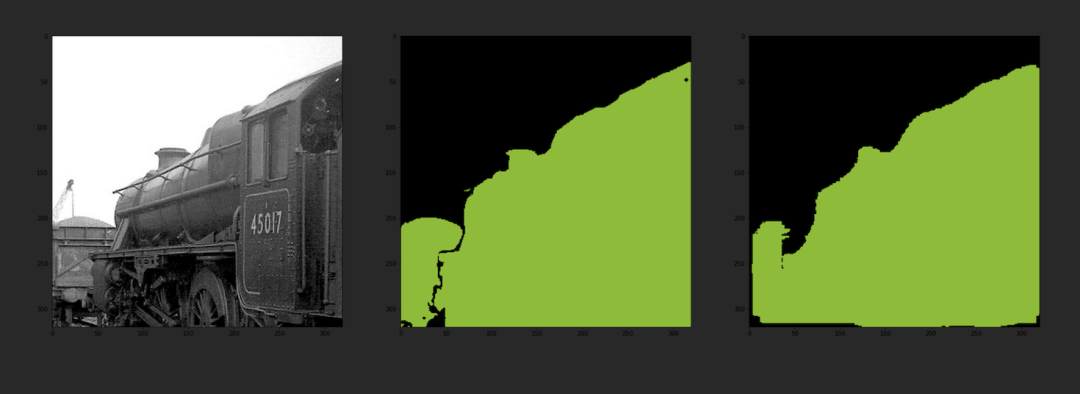
U-Net分割結(jié)果: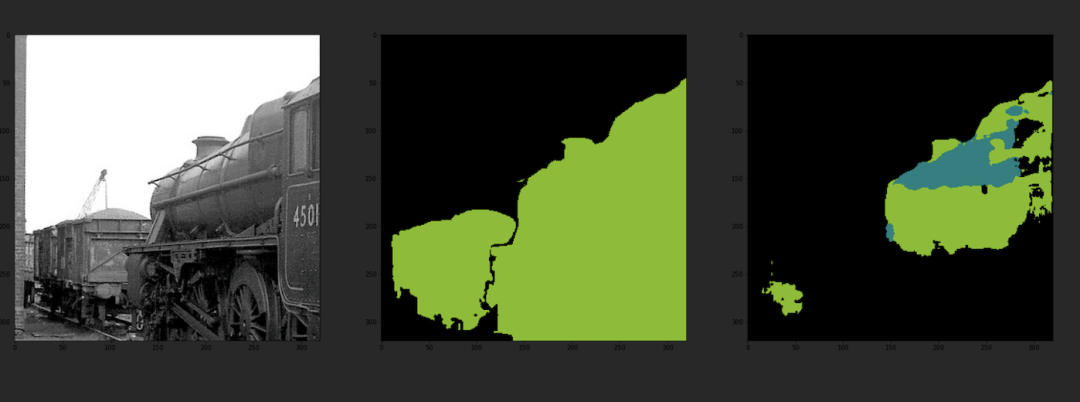
記得點個Star哦!
5 總結(jié)
通過與分割標(biāo)準(zhǔn)圖像的對比,可以發(fā)現(xiàn)該模型的輸出分割圖像與分割標(biāo)準(zhǔn)圖像幾乎一致,同時模型的輸出分割圖像與原圖也較好的融合,說明該模型具有較好的準(zhǔn)確性。
此外,從輸入圖像大小來看,該模型可以輸入任意大小的圖像,并輸出相同大小的已經(jīng)標(biāo)簽好的分割圖像。由于是針對PASCAL VOC數(shù)據(jù)集圖像進(jìn)行的分割,PASCAL VOC數(shù)據(jù)集中只支持20個類別(背景為第21個類別),所以在分割時,遇到不在20個類別中的事物都將其標(biāo)為背景。
但總體來說,該模型對PASCAL VOC數(shù)據(jù)集的圖像分割達(dá)到了較高準(zhǔn)確率。
6 參考
[1].https://zh-v2.d2l.ai/index.html
個人簡介:李響Superb,CSDN百萬訪問量博主,普普通通男大學(xué)生,深度學(xué)習(xí)算法、醫(yī)學(xué)圖像處理專攻,偶爾也搞全棧開發(fā),沒事就寫文章。
博客地址:lixiang.blog.csdn.net
—版權(quán)聲明—
僅用于學(xué)術(shù)分享,版權(quán)屬于原作者。
若有侵權(quán),請聯(lián)系微信號:yiyang-sy 刪除或修改!