
《微服務(wù)架構(gòu)設(shè)計模式》總結(jié),文末送書


經(jīng)常翻閱微服務(wù)材料的話,總會碰到 microservices.io 這個網(wǎng)站,總結(jié)了微服務(wù)方方面面的設(shè)計模式。網(wǎng)站的作者是 Chris Richardson。
這些相關(guān)的經(jīng)驗在 2018 年成為了《微服務(wù)架構(gòu)設(shè)計模式》這本書,并且 2019 年引進(jìn)國內(nèi)。當(dāng)時我第一時間購入了這本書,中間斷斷續(xù)續(xù)地一直沒看完。最近準(zhǔn)備分享內(nèi)容的時候又翻起這本書,這次完整地讀完了一遍。感覺應(yīng)該是目前微服務(wù)領(lǐng)域最好的一本書了。另一本《Building Microservices》也不錯,不過內(nèi)容還是稍微單薄了一些。
這本書為我們提供了宏觀上俯瞰微服務(wù)整個生態(tài)的大圖,比如:
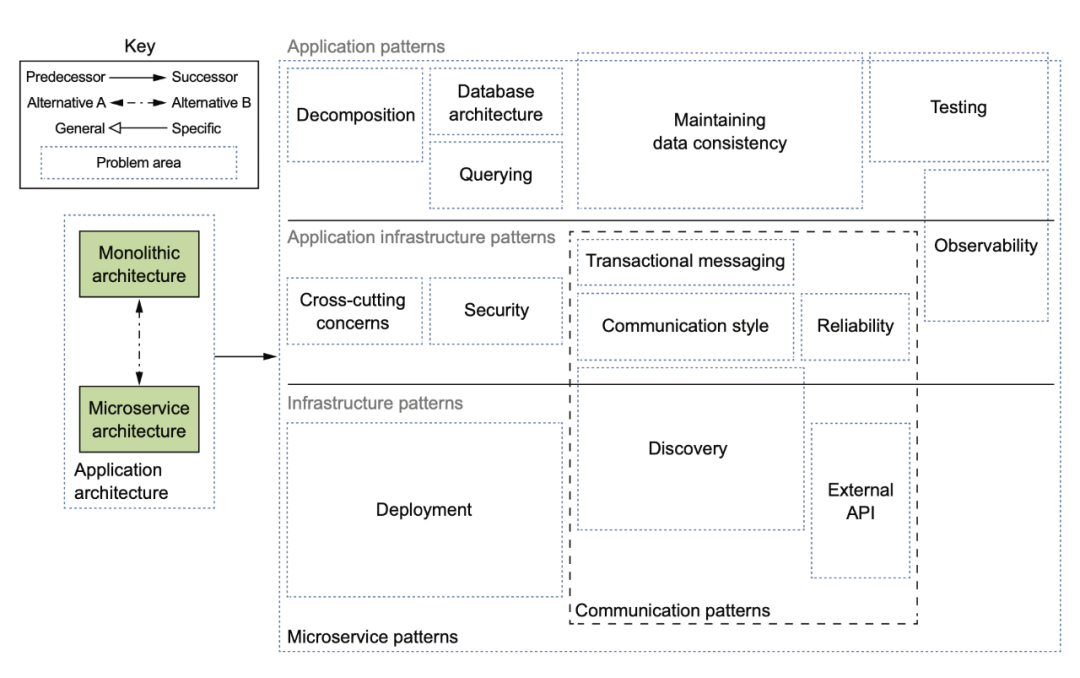
當(dāng)然,18 年的時候,service mesh 之類的東西還沒有太火,所以后來在網(wǎng)站上有個更新的版本:
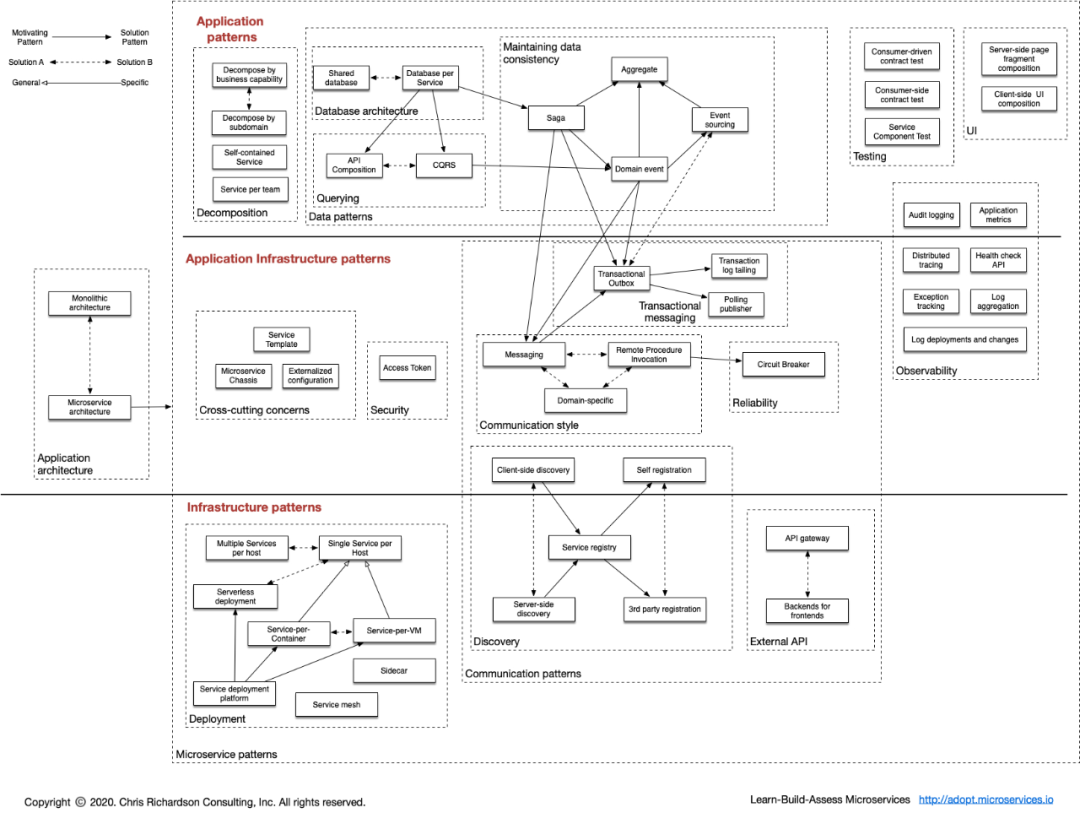
個人很喜歡這種大圖,不管什么領(lǐng)域,我只要照著圖去一點一點填坑就行了,沒有這樣的圖,總覺得是在望不見頭的技術(shù)森林里兜兜轉(zhuǎn)轉(zhuǎn),找不到北。
下面簡單寫一寫我對這本書的總結(jié),里面 saga 和測試的部分我就先省略了。
單體服務(wù)的困境
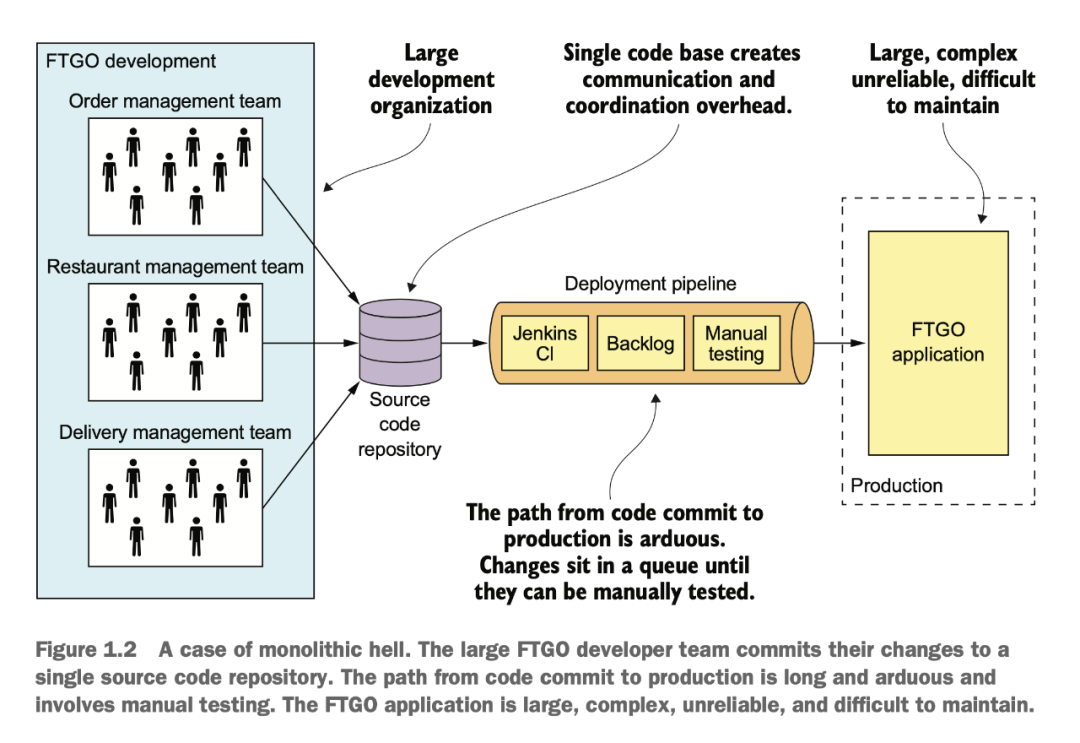
在單體時代,大家在一個倉庫里開發(fā),代碼沖突解決起來很麻煩,上線的 CI/CD pipeline 也是等待到死。
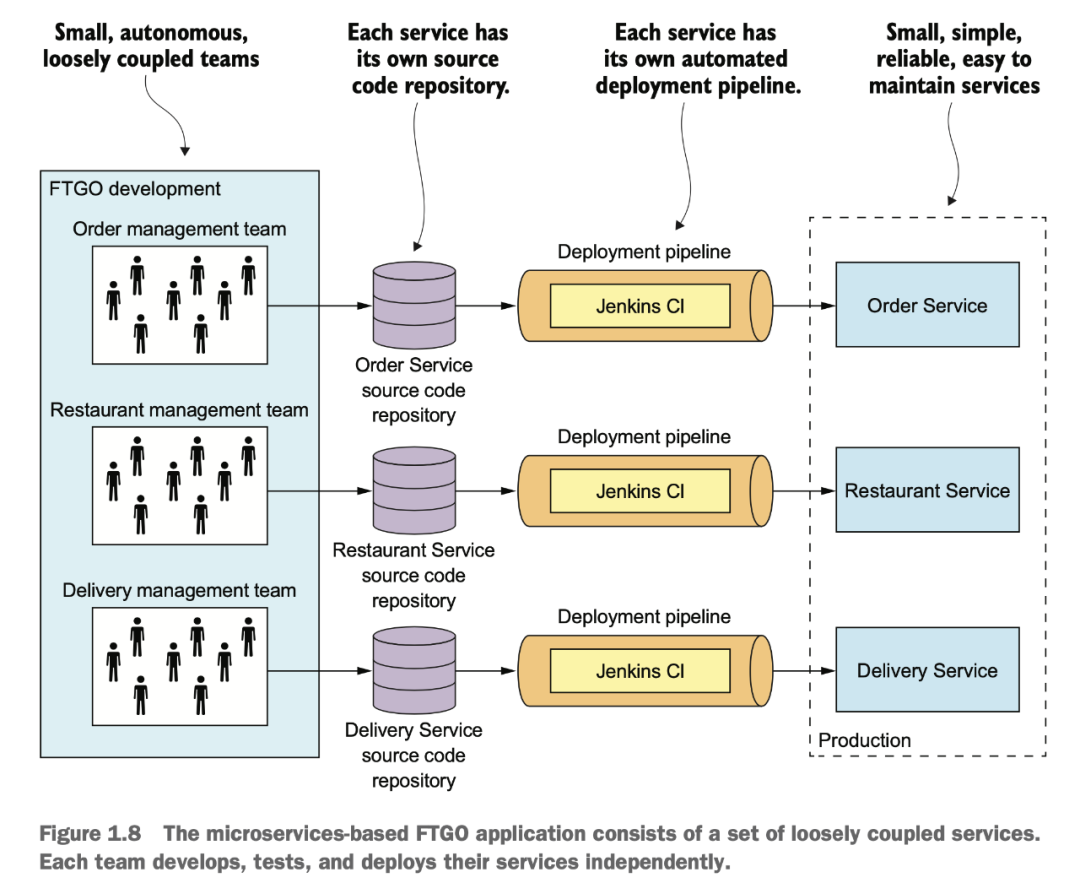
拆分了以后,至少大家有各自的代碼庫,各自的上線流程,各自的線上服務(wù)。這樣上線不打架了,上線以后也可以自己玩自己的灰度流程,一般不會互相影響。
服務(wù)拆分
雖然說是拆了,不過拆分也是要講究方法的。
書里提供了兩種思路,一種是按照業(yè)務(wù)/商業(yè)能力拆分,一種是按照 DDD 中的 sub domain 拆分。
供應(yīng)商管理
送餐員信息管理
餐館信息管理:管理餐館的訂單、營業(yè)時間、營業(yè)地點
消費者管理
管理消費者信息
訂單獲取和履行
消費者訂單管理:讓消費者可以創(chuàng)建、管理訂單
餐館訂單管理:讓餐館可以管理訂單的準(zhǔn)備過程
送餐管理
送餐員狀態(tài)管理:管理可以進(jìn)行接單操作的送餐員的實時狀態(tài)
配送管理:訂單配送追蹤
會計
消費者記賬:管理消費者的訂單記錄
餐館記賬:管理餐館的支付記錄
配送員記賬:管理配送員的收入信息
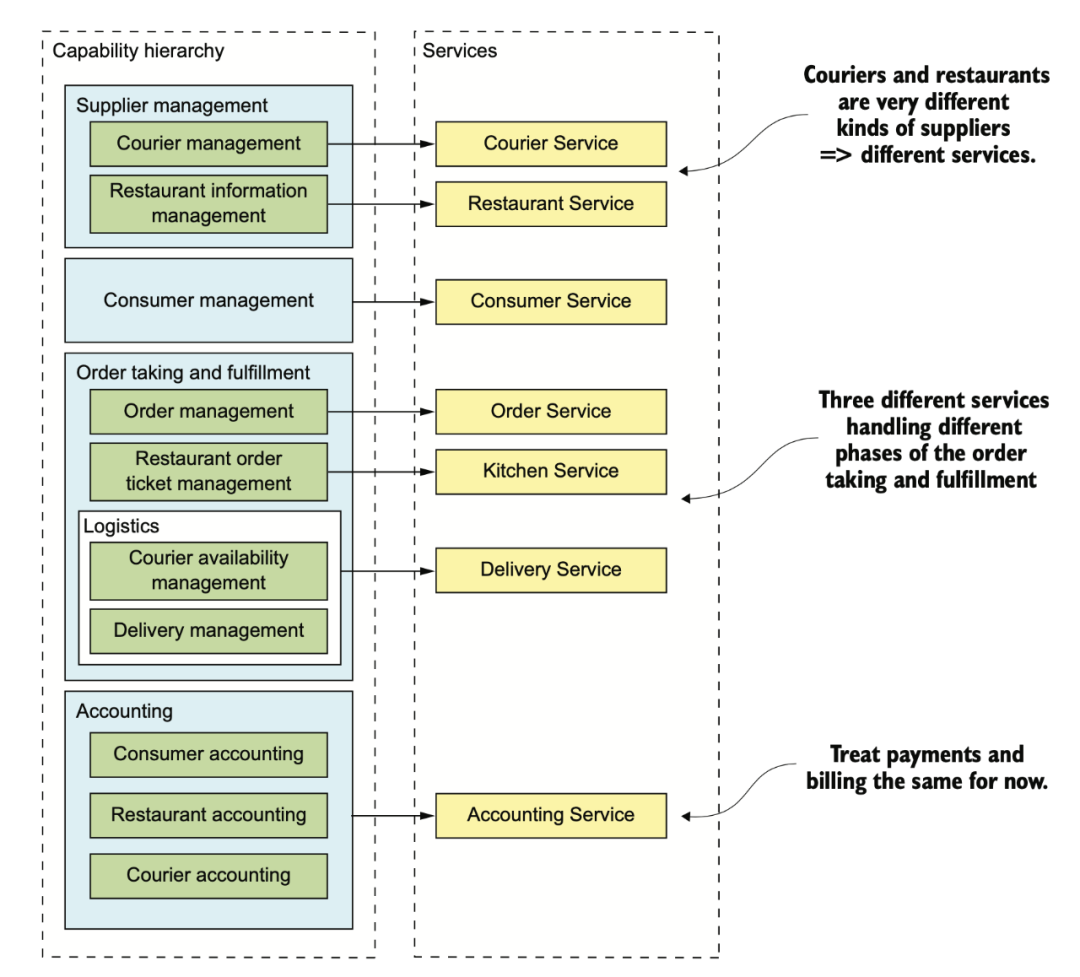
最終大概會形成上面這些服務(wù)。
用 DDD 來做分析,其實我們得到的結(jié)果也差不多:
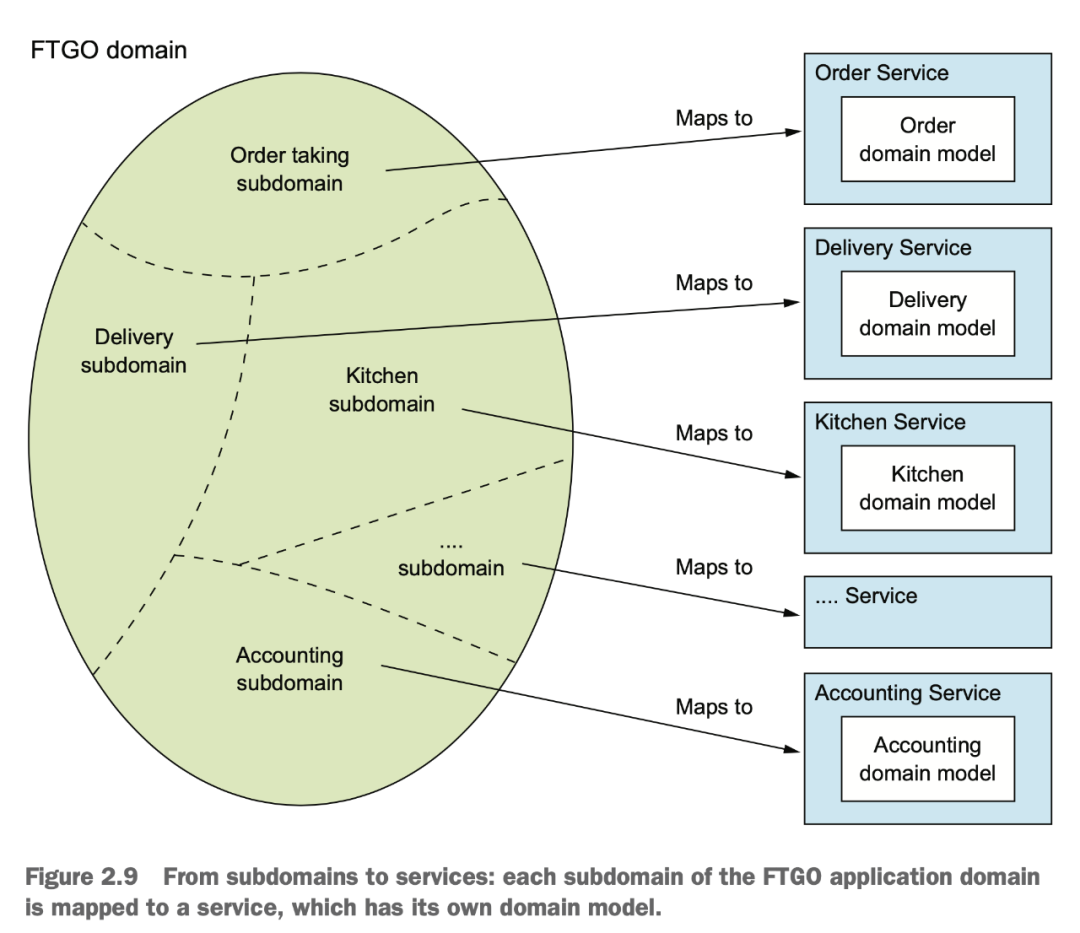
在拆分時,我們還應(yīng)該用 SOLID 中的 SRP 原則和另外一個閉包原則 CCP(common closure principle) 來進(jìn)行指導(dǎo)。
在拆分后,也要注意微服務(wù)的拆分會額外給我們帶來的問題:
網(wǎng)絡(luò)延遲
服務(wù)間同步通信導(dǎo)致可用性降低
在服務(wù)間維持?jǐn)?shù)據(jù)一致性
獲取一致的數(shù)據(jù)視圖
阻塞拆分的上帝類
服務(wù)集成
分布式服務(wù)通信大概可以分為 one-to-one 和 one-to-many:

RPC 很好理解,同步的 request/response。異步通信,一種是回調(diào)式的 request/response,一種是一對多的 pub/sub。
具體到 RPC 的話,可以使用多種協(xié)議和框架:

不過當(dāng) API 更新時,應(yīng)該遵循 semver 的規(guī)范進(jìn)行更新。社區(qū)里 gRPC 很多次更新都沒有遵守 semver,給它的依賴方都造成了不小的麻煩。感興趣的同學(xué)應(yīng)該可以搜到一些相關(guān)的事件。
不得不說 Google 的程序員也并不是事事靠譜。
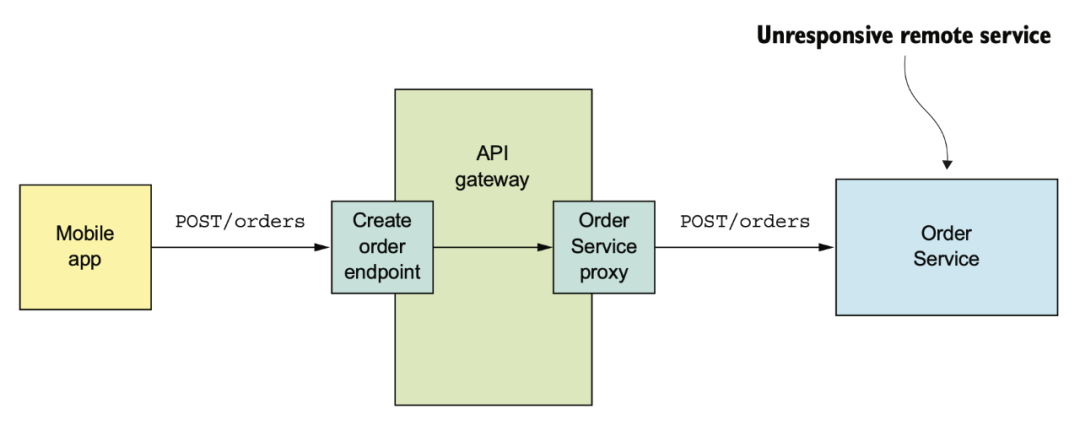
RPC 進(jìn)行服務(wù)集成的時候,要注意不要被某些不穩(wěn)定的服務(wù)慢響應(yīng)拖死,要注意設(shè)置超時,熔斷。
服務(wù)與服務(wù)之間要能找得到彼此,有兩種方式,一種是基于服務(wù)注冊中心的服務(wù)發(fā)現(xiàn)。
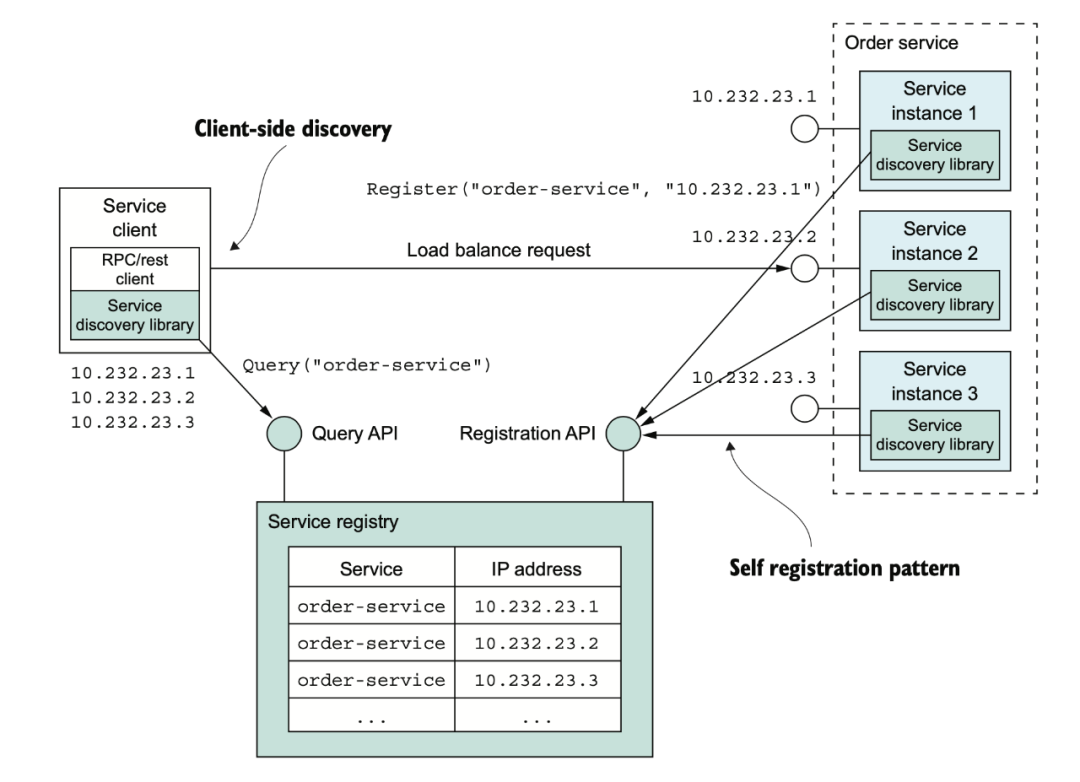
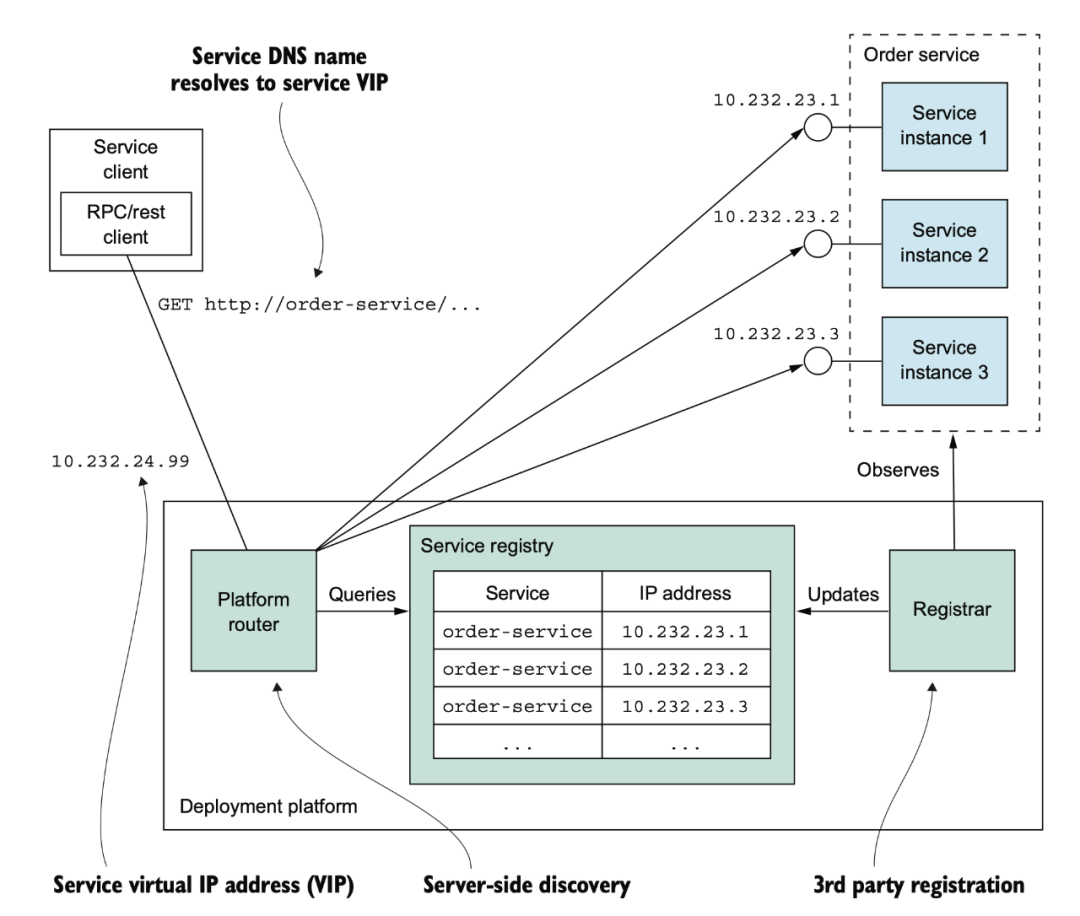
一種是基于 dns 的服務(wù)發(fā)現(xiàn)。基于 DNS 的現(xiàn)在應(yīng)該不太多了。
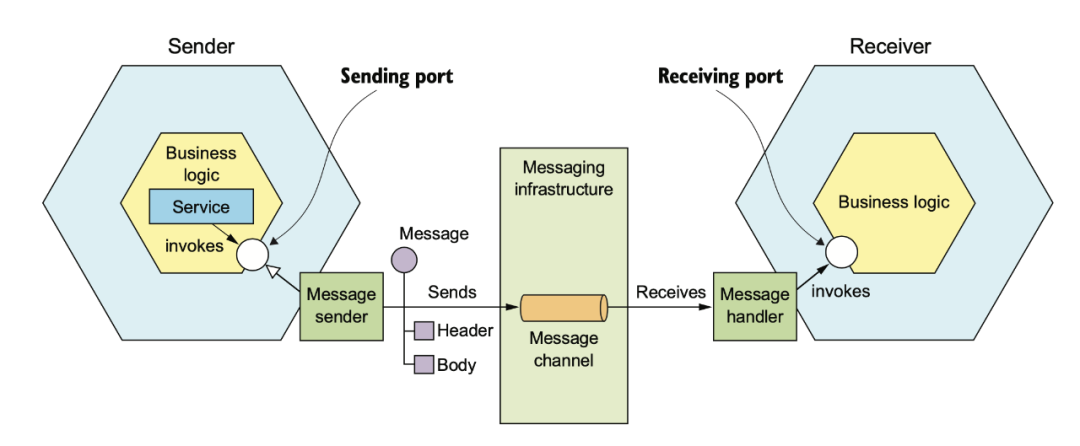
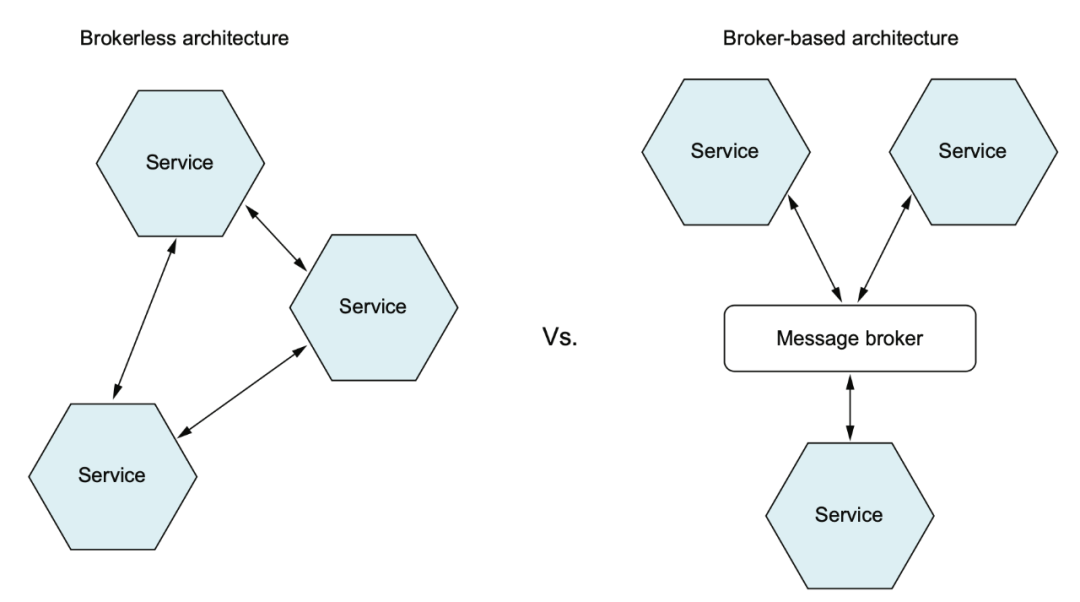
除了 RPC 以外,還可以使用消息來進(jìn)行服務(wù)間的集成。
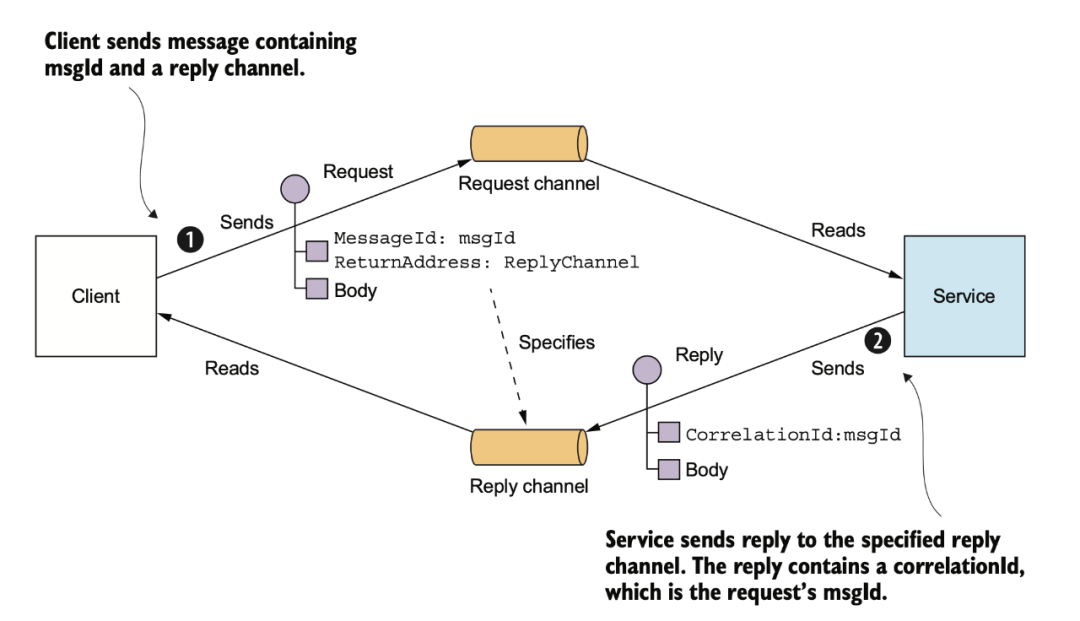
使用 MQ 也可以模擬 RPC 的 request/response,不過這樣會使你的服務(wù)強依賴于 MQ,如果 MQ 故障,那整個系統(tǒng)隨之崩潰。
一般我們使用的是 broker-based mq 通信,但也有無 broker 的異步通信,書中這里舉了個 ZeroMQ 的例子,之前個人不是很了解,需要再調(diào)研一下。
Event Sourcing
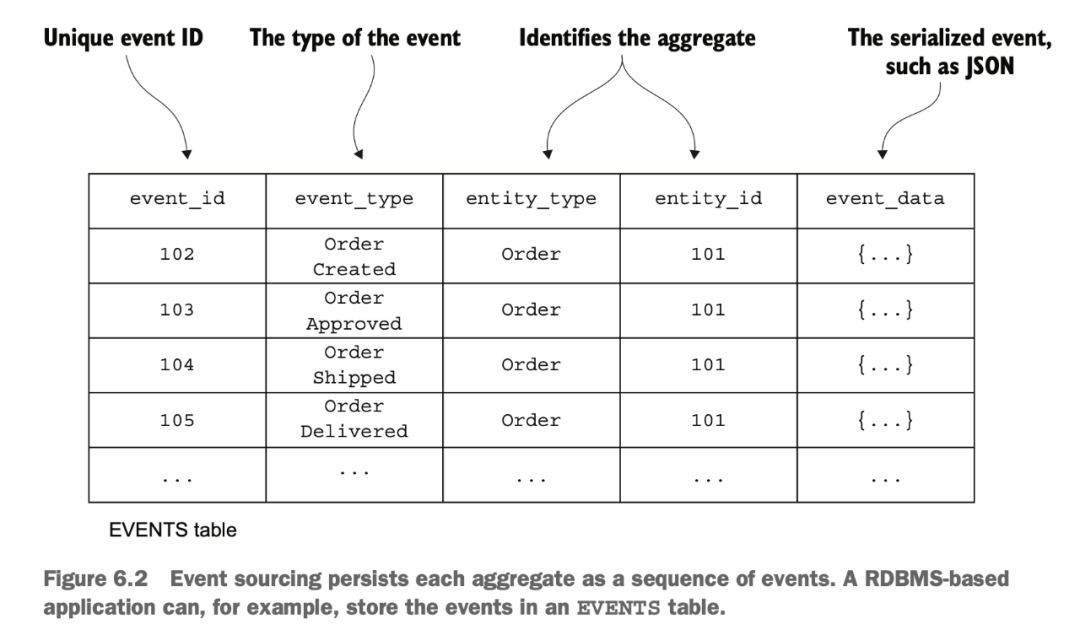
event sourcing 是一種特殊的設(shè)計模式,不記錄實體的終態(tài),而是記錄所有狀態(tài)修改的事件。然后通過對事件進(jìn)行計算來得到實體最終的狀態(tài)。
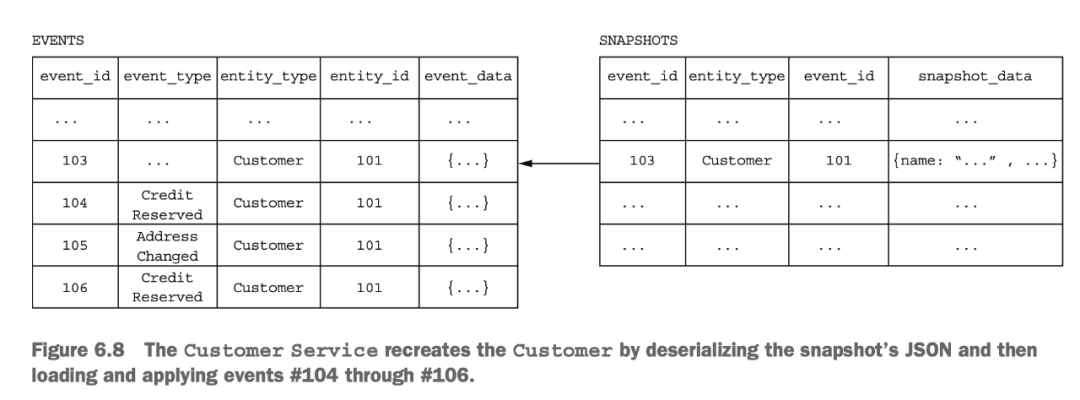
但這樣事件累積太多以后會有性能問題,所以可以對一部分歷史數(shù)據(jù)進(jìn)行計算,得到一個中間的快照,之后的計算在快照的基礎(chǔ)上再疊加。
看起來方案很酷,我們在實際工作中也確實在一些下游的計算邏輯中使用過這種設(shè)計模式,不過它也是有缺陷的:
事件本身結(jié)構(gòu)變化時,新老版本兼容比較難做
如果代碼中要同時處理新老版本數(shù)據(jù),那么升級幾次后會非常難維護(hù)
因為容易追溯,所以刪除數(shù)據(jù)變得非常麻煩,GDPR 類的法規(guī)要求用戶注銷時必須將歷史數(shù)據(jù)刪除干凈,這對 Event Sourcing 是一個巨大的挑戰(zhàn)
在使用異步消息來做解耦的時候,我們也會遇到一些實際的業(yè)務(wù)問題:
這個數(shù)據(jù)我需要,你能不能在消息里幫我透傳一下
你重構(gòu)的時候怎么把這個字段刪了,我還要用呢
你們原來的狀態(tài)機(jī)變更都有 event,本來有三個,怎么現(xiàn)在變成兩個了?
你們 API 故障的時候,怎么消息順序亂了?

這要求我們能有對上游的領(lǐng)域事件進(jìn)行校驗的系統(tǒng),這里可以參考 Google 的 schema validation 這個項目,之前我在 《MQ 正在變成臭水溝》一文中有詳述。這里就不提了。
查詢模式
很多查詢邏輯其實就是進(jìn)行 API 的數(shù)據(jù)組合,這個涉及到需要組合數(shù)據(jù)的 API 組合器,和數(shù)據(jù)提供方:
API 組合器:通過查詢數(shù)據(jù)提供方的服務(wù)實現(xiàn)查詢操作
數(shù)據(jù)提供方:提供數(shù)據(jù)
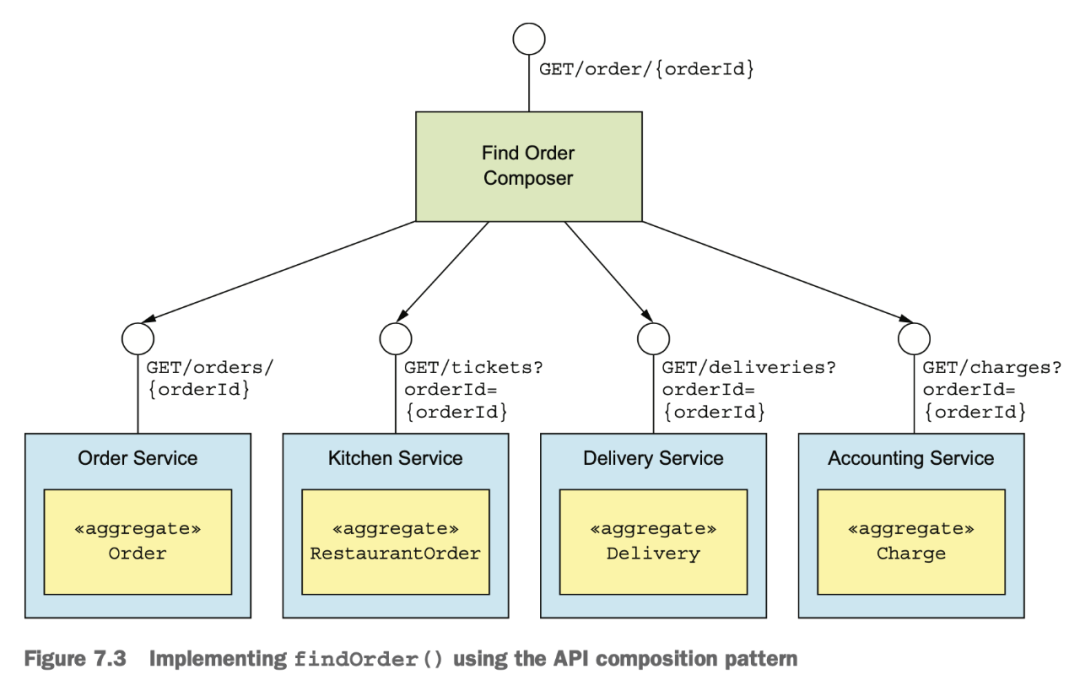
雖然看起來挺簡單,寫代碼的時候,下面這些問題還是難處理:
誰來負(fù)責(zé)拼裝這些數(shù)據(jù)?有時是應(yīng)用,有時是外部的 API Gateway,難以定立統(tǒng)一的標(biāo)準(zhǔn),在公司里也經(jīng)常扯皮
增加額外的開銷-一個請求要查詢很多接口
可用性降低-每個服務(wù)可用性 99.5%,實際接口可能是 99.5^5=97.5
事務(wù)數(shù)據(jù)一致性難保障-需要使用分布式事務(wù)框架/使用事務(wù)消息和冪等消費
CQRS
業(yè)務(wù)開發(fā)經(jīng)常自嘲是 CRUD 工程師,在架構(gòu)設(shè)計里,CRUD 的 R 可以單獨拆出來,像下面這樣。
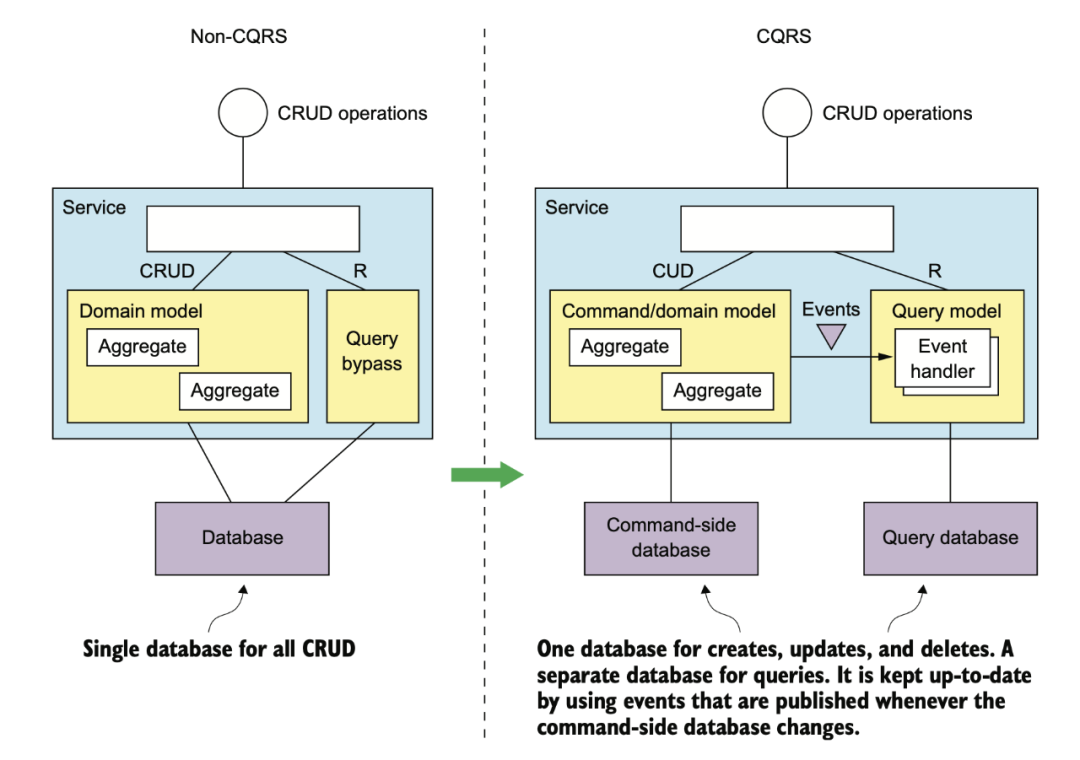
拆出來的好處?互聯(lián)網(wǎng)大多是寫少讀多的服務(wù),將關(guān)注點分離之后,讀服務(wù)和寫服務(wù)的存儲可以做異構(gòu)。
比如寫可以是 MySQL,而讀則可以是各種非常容易做橫向擴(kuò)展的 NoSQL。碰到檢索需求,讀還可以是 Elasticsearch。
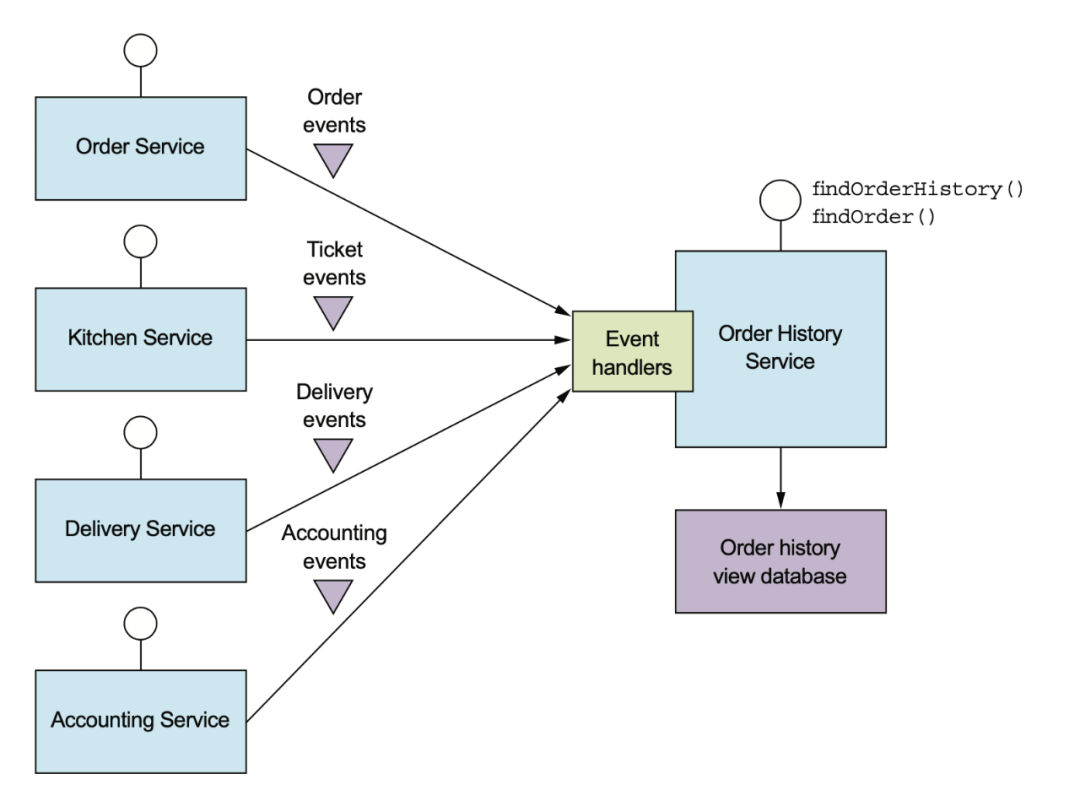
讀服務(wù)可以訂閱寫服務(wù)的 domain event,也可以是 MySQL 的 binlog。
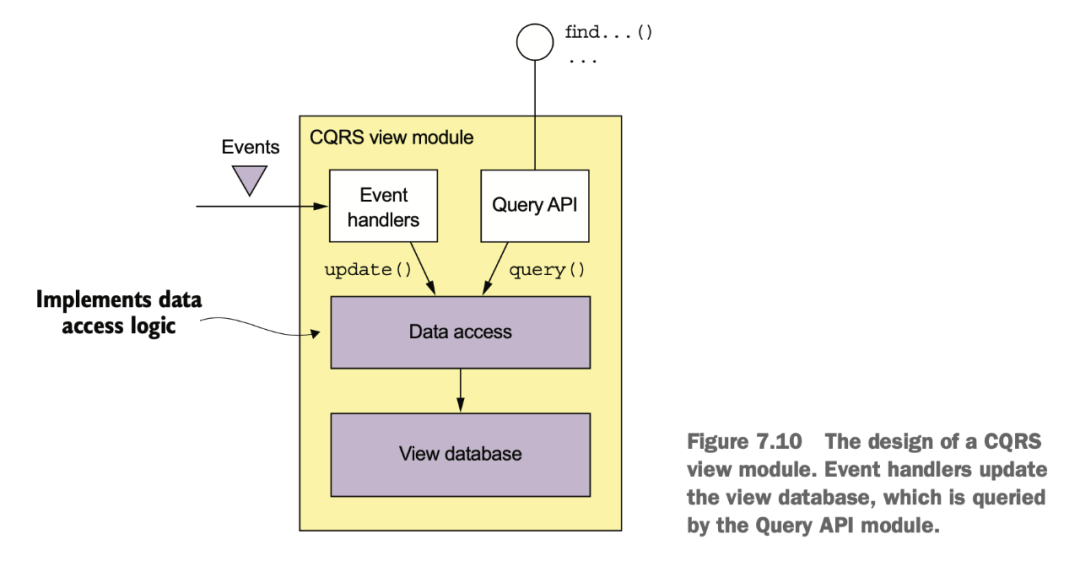
在消費上游數(shù)據(jù)時,需要根據(jù)業(yè)務(wù)邏輯去判斷有些狀態(tài)機(jī)要怎么做處理。這里其實數(shù)據(jù)上是有耦合的,并不是放個 MQ 和 domain event 就能解耦干凈了。
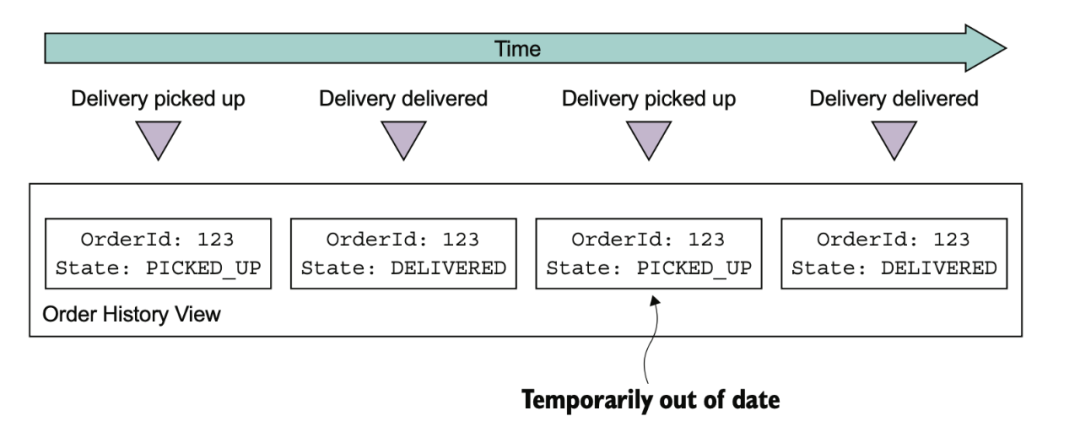
CQRS 的缺點也比較明顯:
架構(gòu)復(fù)雜
數(shù)據(jù)復(fù)制延遲問題
查詢一致性問題
并發(fā)更新問題處理
冪等問題需要處理
外部 API 模式
現(xiàn)在的互聯(lián)網(wǎng)公司一般客戶端都是多端,web、移動、向第三方開放的 open API。
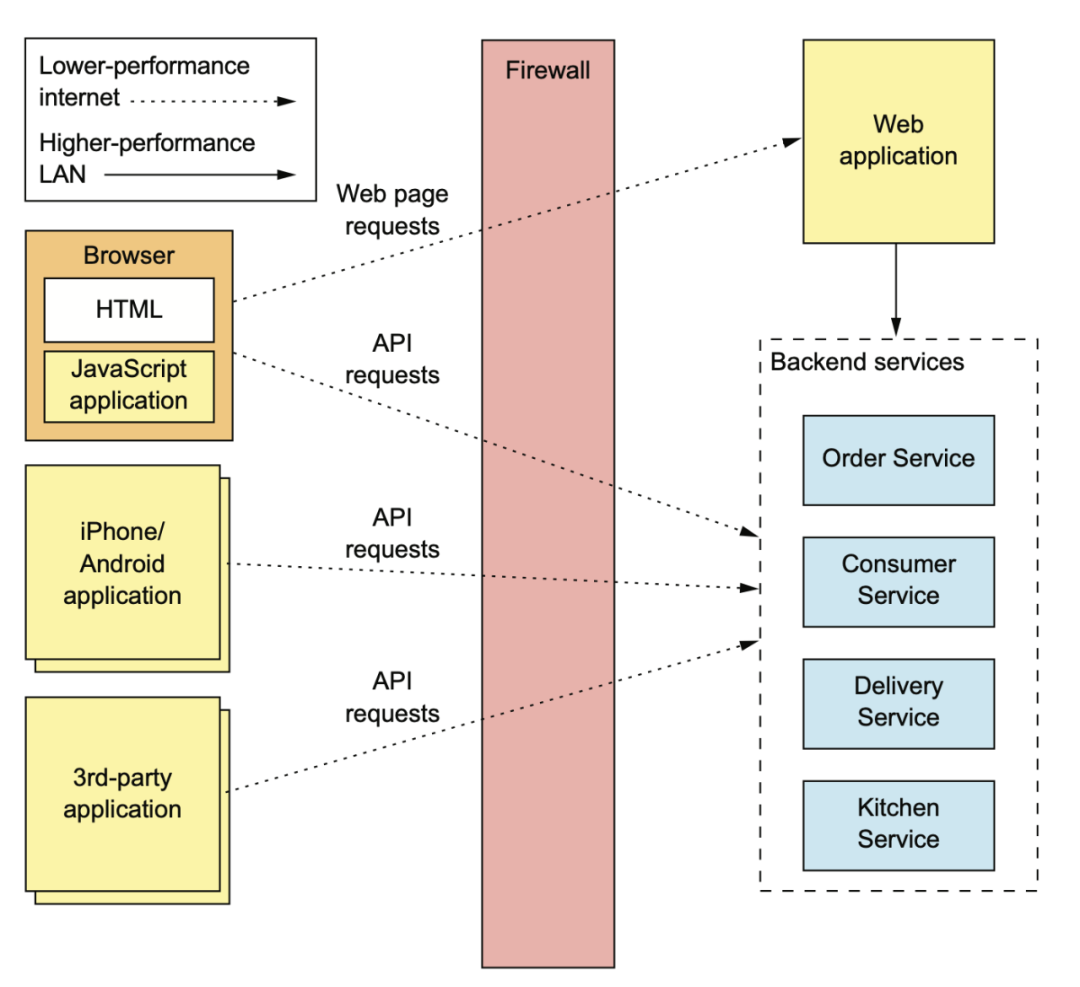
如果我們直接把之前用拆分方法拆出來的這些內(nèi)部 API 開放出去,那未來內(nèi)部的 API 想升級就會非常非常地麻煩。
在單體時代,客戶端走弱網(wǎng) internet,只需要一次調(diào)用。微服務(wù)化以后,如果不做任何優(yōu)化,那在 internet 這種慢速網(wǎng)絡(luò)上就需要有多次調(diào)用。
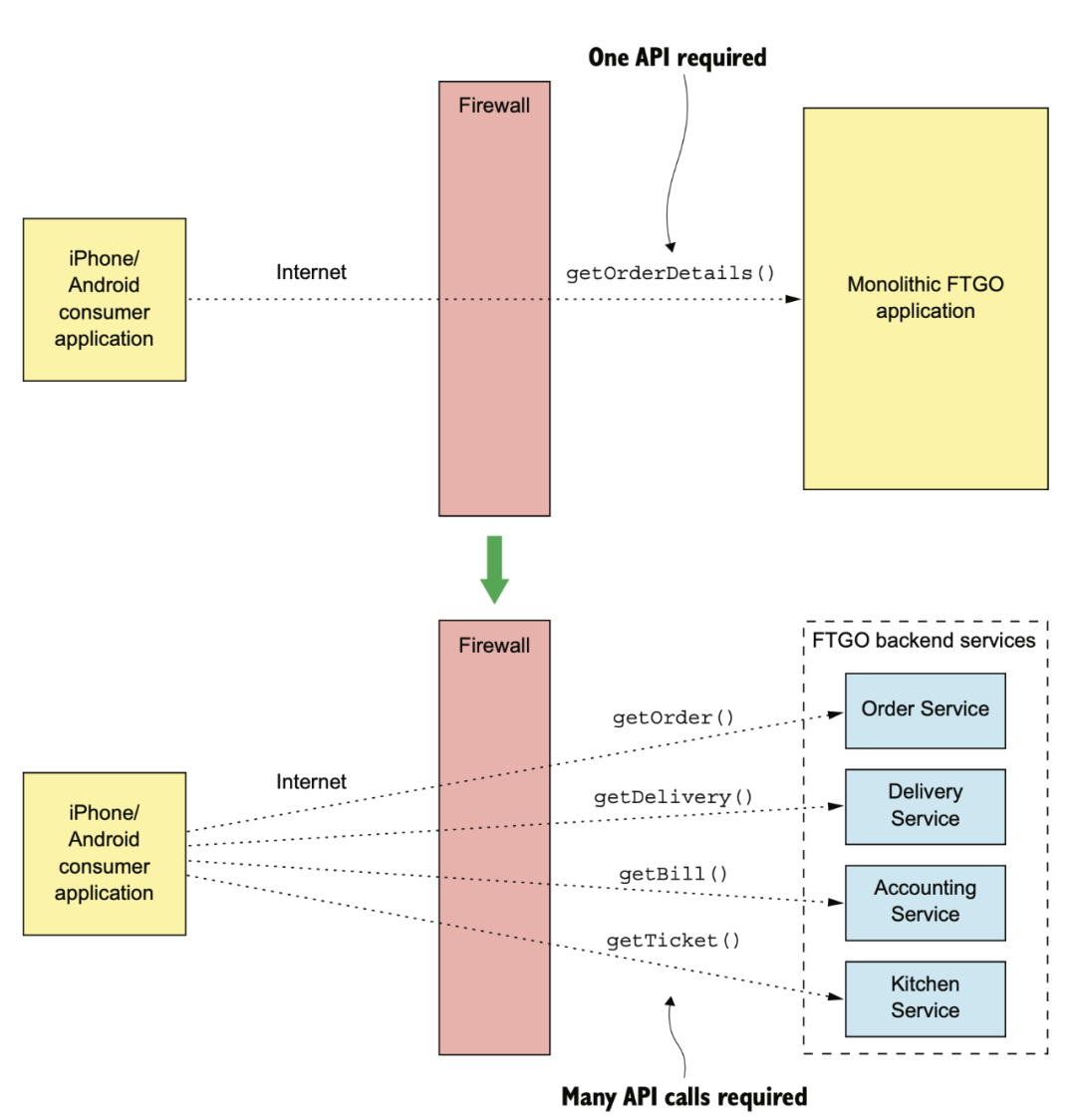
這就是我們?yōu)槭裁葱枰虚g有一個 API Gateway 的原因。
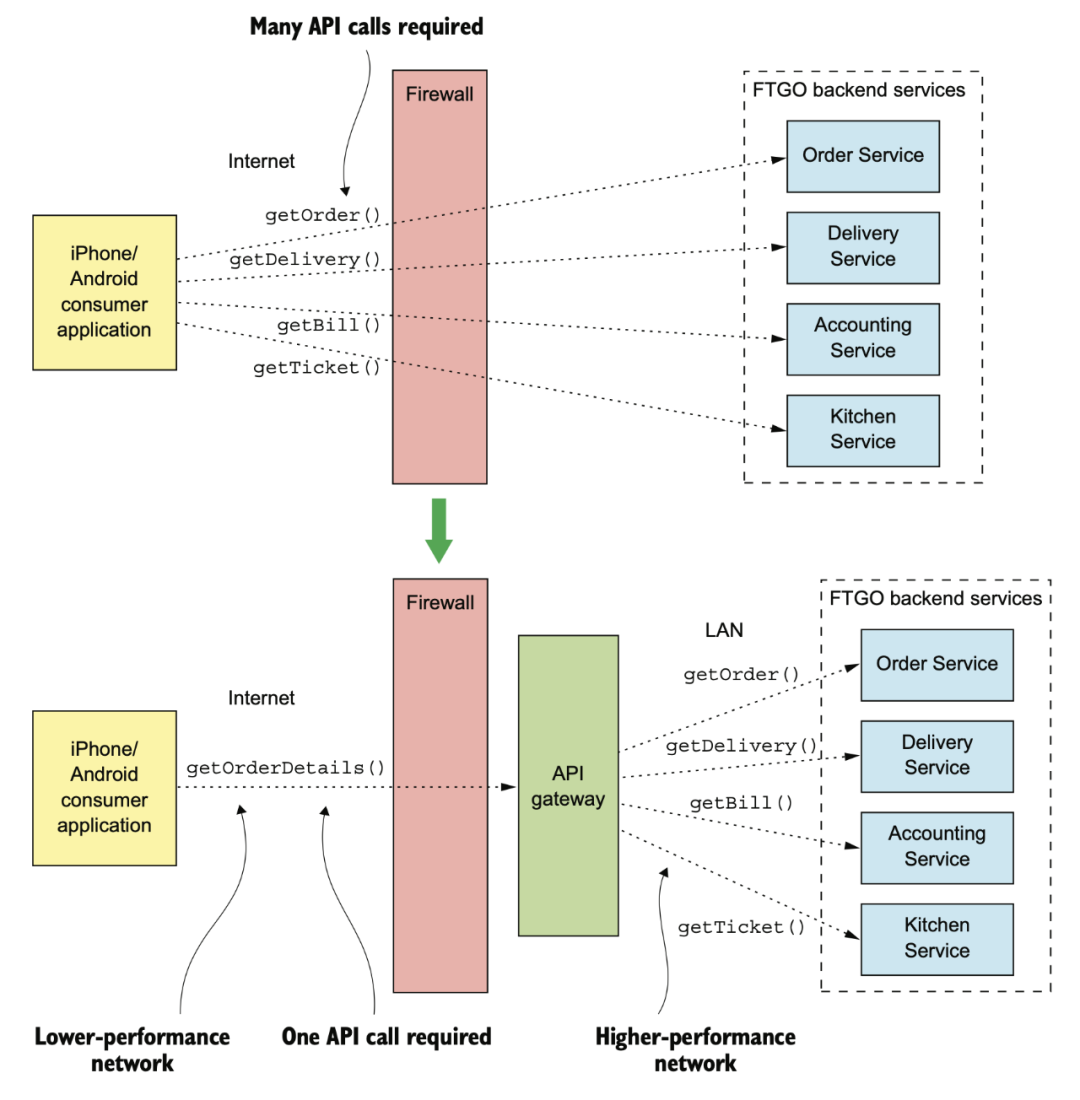
有了 Gateway 之后,在 internet 依然還是一次調(diào)用,在內(nèi)部 IDC 強網(wǎng)絡(luò)的狀態(tài)下多次網(wǎng)路調(diào)用相對沒有那么糟糕。
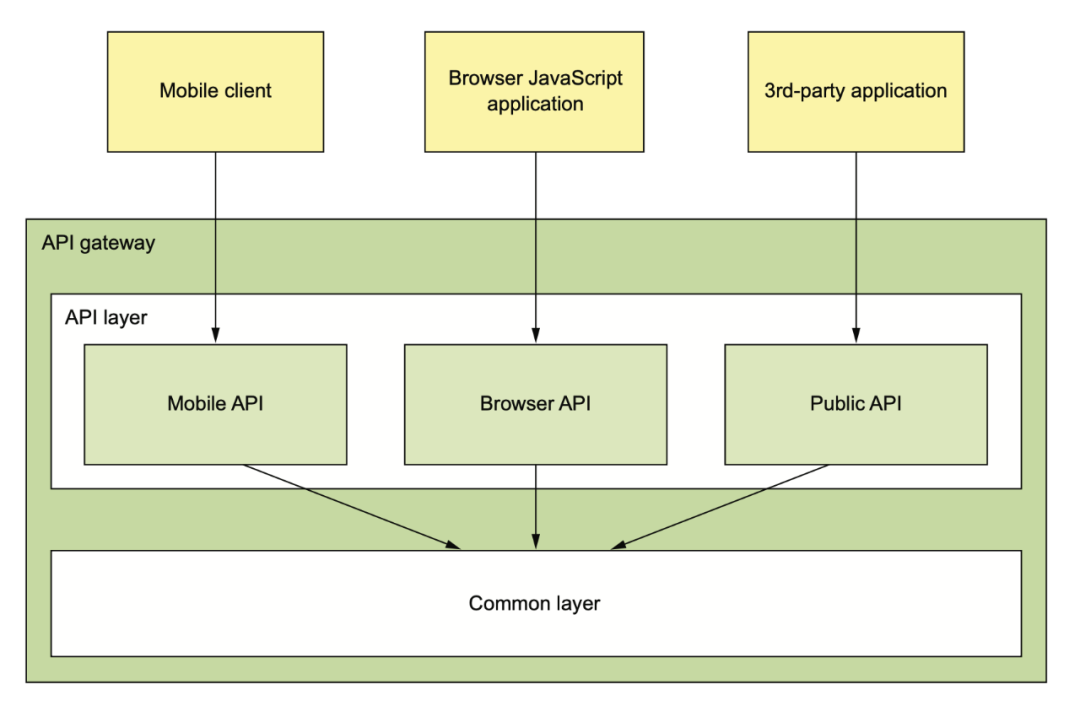
API Gateway 涉及到這些不同端的 API Gateway 應(yīng)該要誰來維護(hù)的問題。下面是一種理想的情況,Mobile 團(tuán)隊負(fù)責(zé)維護(hù)他們在 Gateway 里的 API(也可能是單獨的 Gateway),web 端團(tuán)隊維護(hù) web 的 Gateway,open API 團(tuán)隊負(fù)責(zé)維護(hù)第三方應(yīng)用的 Gateway API。
網(wǎng)關(guān)基礎(chǔ)設(shè)施團(tuán)隊負(fù)責(zé)提供這三方都需要的基礎(chǔ)庫。
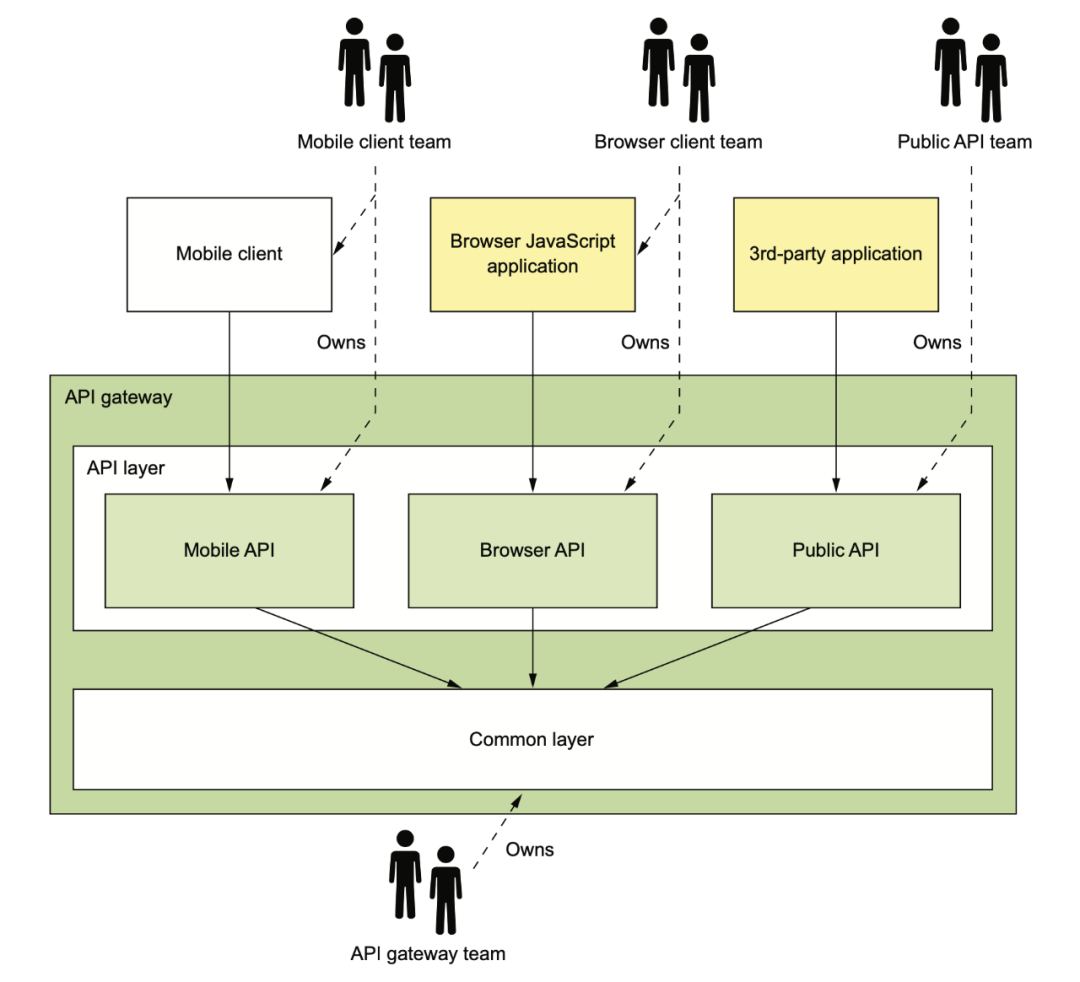
在研發(fā) API Gateway 的時候,我們有多種可選項:
直接使用開源產(chǎn)品
Kong
APISix
Traefik
自研
Zuul
Spring Cloud Gateway
RESTFul 自己做一個
GraphQL 自己做一個
開源的 API Gateway 大多不支持 API 數(shù)據(jù)組合功能,所以公司內(nèi)的 API Gateway 有時候有兩層,一層是 nginx 之類的負(fù)責(zé)簡單路由和鑒權(quán)的 gateway,后面還有一個業(yè)務(wù)的 BFF 來負(fù)責(zé)拼裝端上需要的數(shù)據(jù)。
如果我們都是自研,那就可以在一個模塊上把 API Gateway 需要的功能都實現(xiàn)。這里經(jīng)常討論的一個問題是,我們是要使用 REST 還是類似 GraphQL 的圖查詢。
Netflix 的工程師在 2012 年發(fā)表過一篇文章:

《為什么 REST 讓我半夜睡不著》,老哥還挺幽默。內(nèi)容大概是講 Netflix 要面對成百上千的終端設(shè)備,Netflix 曾經(jīng)希望能給所有終端提供大一統(tǒng)的方案,大家使用統(tǒng)一的 REST API,但后來發(fā)現(xiàn)這種統(tǒng)一的方式是放棄了對任一有自己特性的設(shè)備的優(yōu)化,比如有些設(shè)備內(nèi)存小,有些設(shè)備屏幕小,這些設(shè)備上你返回的很多字段數(shù)據(jù)對他們來說根本就用不上,純粹是浪費網(wǎng)絡(luò)帶寬。有些設(shè)備用流式響應(yīng)比返回完整響應(yīng)性能更好,這也應(yīng)該是要考慮的優(yōu)化點。
所以 Netflix 做了一個叫 falcor 的方案,其實和后來 Facebook 的 GraphQL 非常類似,是用 JSON Graph 來描述內(nèi)部 API 能提供的數(shù)據(jù),然后用 JS 來定制圖上的查詢。
現(xiàn)在大多數(shù)人比較熟悉的還是 GraphQL:
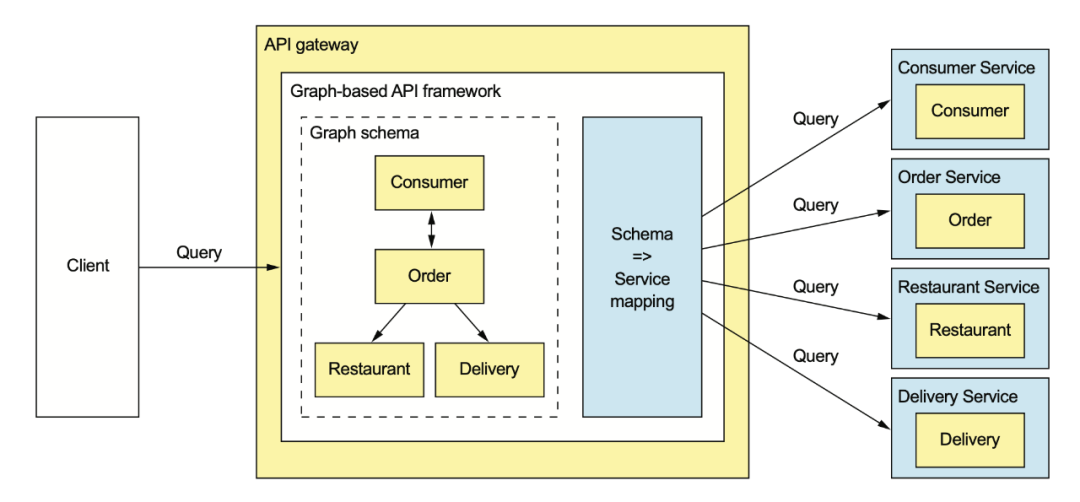
GraphQL 是個好東西,但之前我個人對使用 GraphQL 一直持懷疑態(tài)度,主要是因為:
網(wǎng)關(guān)容易被客戶端的修改直接帶崩
穩(wěn)定性非常難保障
中文互聯(lián)網(wǎng)上講 GraphQL 的基本都沒有提到限流,或者一筆帶過,這是不太負(fù)責(zé)任的
直到最近我發(fā)現(xiàn)國外某公司公開了他們的 GraphQL 限流方案,這個方案非常有意思,我會在下一篇文章進(jìn)行分享。
這本《微服務(wù)架構(gòu)模式》難能可貴的地方在于幾乎所有的技術(shù)方案,都很詳盡地給出了優(yōu)劣,這在其它書里是比較少見的。我們在某些人的文章和方案里永遠(yuǎn)只能看到優(yōu)點,但在實踐中落地技術(shù)方案的時候,其實更關(guān)注缺陷。對缺陷有心理準(zhǔn)備,才不會在新方案出問題的時候心慌。
個人覺得這本書,無論是對微服務(wù)剛?cè)腴T,或是工作幾年的人,都值得一讀。
在本文最后做個簡單的抽獎活動,本文回復(fù)的第一、第三、第十、第三十個人,都能夠得到一本《微服務(wù)架構(gòu)模式》,你需要寫寫自己對微服務(wù)的見解,或者簡短地分享一下自己在公司中碰到的微服務(wù)的坑就可以。
100 字以內(nèi)就行,不用長篇大論~
沒抽到的老哥就只能自己買了,[doge]。