
常見的距離算法和相似度計(jì)算方法
點(diǎn)擊下方卡片,關(guān)注“新機(jī)器視覺”公眾號
重磅干貨,第一時(shí)間送達(dá)
本文整理了常見的距離算法和相似度(系數(shù))算法,并比較了歐氏距離和余弦距離間的不同之處。
1、常見的距離算法
>>> pdist = nn.PairwiseDistance(p=2)>>> input1 = torch.randn(100, 128)>>> input2 = torch.randn(100, 128)>>> output = pdist(input1, input2)
C代碼包:emd.h, emd.c, emd.iOpenCV:實(shí)現(xiàn)了EMD api,pip install --upgrade setuptoolspip install numpy Matplotlibpip install opencv-pythonimport numpy as npimport cv#p、q是兩個(gè)矩陣,第一列表示權(quán)值,后面三列表示直方圖或數(shù)量p=np.asarray([[0.4,100,40,22],[0.3,211,20,2],[0.2,32,190,150],[0.1,2,100,100]],np.float32)q=np.array([[0.5,0,0,0],[0.3,50,100,80],[0.2,255,255,255]],np.float32)pp=cv.fromarray(p)qq=cv.fromarray(q)emd=cv.CalcEMD2(pp,qq,cv.CV_DIST_L2)
import numpy as npdef mashi_distance(x,y):print xprint y#馬氏距離要求樣本數(shù)要大于維數(shù),否則無法求協(xié)方差矩陣#此處進(jìn)行轉(zhuǎn)置,表示10個(gè)樣本,每個(gè)樣本2維X=np.vstack([x,y])print XXT=X.Tprint XT#方法一:根據(jù)公式求解S=np.cov(X) #兩個(gè)維度之間協(xié)方差矩陣SI = np.linalg.inv(S) #協(xié)方差矩陣的逆矩陣#馬氏距離計(jì)算兩個(gè)樣本之間的距離,此處共有4個(gè)樣本,兩兩組合,共有6個(gè)距離。n=XT.shape[0]d1=[]for i in range(0,n):for j in range(i+1,n):delta=XT[i]-XT[j]d=np.sqrt(np.dot(np.dot(delta,SI),delta.T))print dd1.append(d)
1、切比雪夫距離(Chebyshev Distance)
2、明可夫斯基距離(Minkowski Distance)
3、海明距離(Hamming distance)
4、馬哈拉諾比斯距離(Mahalanobis Distance)
2、常見的相似度(系數(shù))算法
>>> input1 = torch.randn(100, 128)>>> input2 = torch.randn(100, 128)>>> cos = nn.CosineSimilarity(dim=1, eps=1e-6)>>> output = cos(input1, input2)
import numpy as npx=np.random.random(8)y=np.random.random(8)#方法一:根據(jù)公式求解x_=x-np.mean(x)y_=y-np.mean(y)d1=np.dot(x_,y_)/(np.linalg.norm(x_)*np.linalg.norm(y_))#方法二:根據(jù)numpy庫求解X=np.vstack([x,y])d2=np.corrcoef(X)[0][1]
>>> torch.nn.functional.kl_div(input, target, size_average=None, reduce=None, reduction='mean')>>> F.kl_div(q.log(),p,reduction='sum')#函數(shù)中的 p q 位置相反(也就是想要計(jì)算D(p||q),要寫成kl_div(q.log(),p)的形式),而且q要先取 log#reduction 是選擇對各部分結(jié)果做什么操作,
import numpy as npfrom scipy.spatial.distance import pdistx=np.random.random(8)>0.5y=np.random.random(8)>0.5x=np.asarray(x,np.int32)y=np.asarray(y,np.int32)#方法一:根據(jù)公式求解up=np.double(np.bitwise_and((x != y),np.bitwise_or(x != 0, y != 0)).sum())down=np.double(np.bitwise_or(x != 0, y != 0).sum())d1=(up/down)#方法二:根據(jù)scipy庫求解X=np.vstack([x,y])d2=pdist(X,'jaccard')
import numpy as npdef tanimoto_coefficient(p_vec, q_vec):"""This method implements the cosine tanimoto coefficient metric:param p_vec: vector one:param q_vec: vector two:return: the tanimoto coefficient between vector one and two"""pq = np.dot(p_vec, q_vec)p_square = np.linalg.norm(p_vec)q_square = np.linalg.norm(q_vec)return pq / (p_square + q_square - pq)
#標(biāo)準(zhǔn)化互信息from sklearn import metricsif __name__ == '__main__':A = [1, 1, 1, 2, 3, 3]B = [1, 2, 3, 1, 2, 3]result_NMI=metrics.normalized_mutual_info_score(A, B)print("result_NMI:",result_NMI)
1、對數(shù)似然相似度/對數(shù)似然相似率
2、互信息/信息增益,相對熵/KL散度
3、信息檢索——詞頻-逆文檔頻率(TF-IDF)
4、詞對相似度——點(diǎn)間互信息
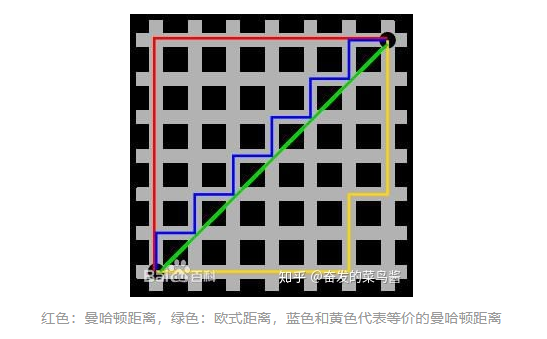
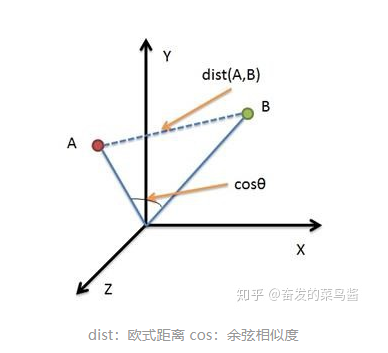
3、歐式距離vs余弦相似度
本文僅做學(xué)術(shù)分享,如有侵權(quán),請聯(lián)系刪文。
評論
圖片
表情