
SynchroTrap-基于松散行為相似度的欺詐賬戶檢測算法
大家好,我是小伍哥,今天給大家分享一個非常牛逼的算法,叫做SynchroTrap。
一、極致對抗下的風控怎么做?
為了好理解,以淘寶刷單的風險對抗階段為例(各階段為假設,本人并未做過刷單的風控)
第1階段:同設備,同地址,大量購買
第2階段:同設備、地址部分變化,大量購買
第3階段:設備變化,IP、支付等介質(zhì)有聚集,大量購買
第3階段:設備采用模擬器,變化IP,不同收貨地址,空包等虛假物流,大量購買
··· ···
第N階段:設備真實、IP真實、地址真實、物流真實、用戶真實... ...
?
所有的都是真實的,俗稱眾包刷單,這種怎么辦?
有人說,所有東西都真實,那不就是真實的成交了么,還管啥?非也。雖然信息都真實,但是購買意愿和目的不是真實,受刷單團伙統(tǒng)一指使,嚴重破壞生態(tài)平衡,若不加管控,將導致劣幣驅(qū)逐良幣的現(xiàn)象,對平臺經(jīng)濟的持續(xù)發(fā)展產(chǎn)生毀滅性的打擊。
那遇到這種情況,我們風控人員是不是就束手無策了呢?同樣也是非也。已經(jīng)有比較成熟的方法進行挖掘。只是方法比較抽象,不是很好理解。讓我慢慢道來。
當然這種方法,不僅僅用于刷單,任何薅羊毛行為、營銷作弊、刷評論、抖音刷點贊、刷粉絲,朋友圈刷榜單等風險類型都能用,且不依賴于任何介質(zhì),只依賴行為特征。我在多個場景應用,效果非常好。
如果你是風控從業(yè)者,一定要研究該算法,做完升職加薪肯定沒問題!!
?
二、什么是SynchroTrap?
synchronized 同步的;Trap 陷阱,圈套,互聯(lián)網(wǎng)上泛濫著各種欺詐行為。特別是社交網(wǎng)絡誕生以來,許多職業(yè)黑客和黑色產(chǎn)業(yè)鏈便通過欺詐行為謀生。一個常見的欺詐行為便是大量的同時虛假點贊行為,也就是會有大量的用戶在短期內(nèi)大量地給同一個頁面點贊(Synchronized Attack)。針對這種特定的欺詐行為,學術(shù)界的研究者和工業(yè)界的工程師專門研究了一種叫做 SynchroTrap 的算法。這種算法被部署在 Facebook 和 Instagram 的系統(tǒng)中,在一個月的時間內(nèi)檢測出了 200 萬欺詐帳戶和 1156 次大規(guī)模網(wǎng)絡攻擊。
惡意賬戶在社交網(wǎng)絡、電商生態(tài)、外賣等業(yè)務上通常會有松散的同步行為進行黑產(chǎn)活動,行為上具有一定相似度。
基于攻擊者松散的同步行為和經(jīng)濟約束,構(gòu)建了惡意賬戶檢測系算法SynchroTrap,大流程如下:
基于用戶之間行為相似度構(gòu)建網(wǎng)絡
利用算法進行圖分割+連通子圖查找發(fā)現(xiàn)團伙
優(yōu)化實現(xiàn)大規(guī)模計算,對系統(tǒng)進行持續(xù)監(jiān)控
?
三、攻擊者表現(xiàn)和經(jīng)濟約束
1、 Facebook上傳圖片攻擊行為
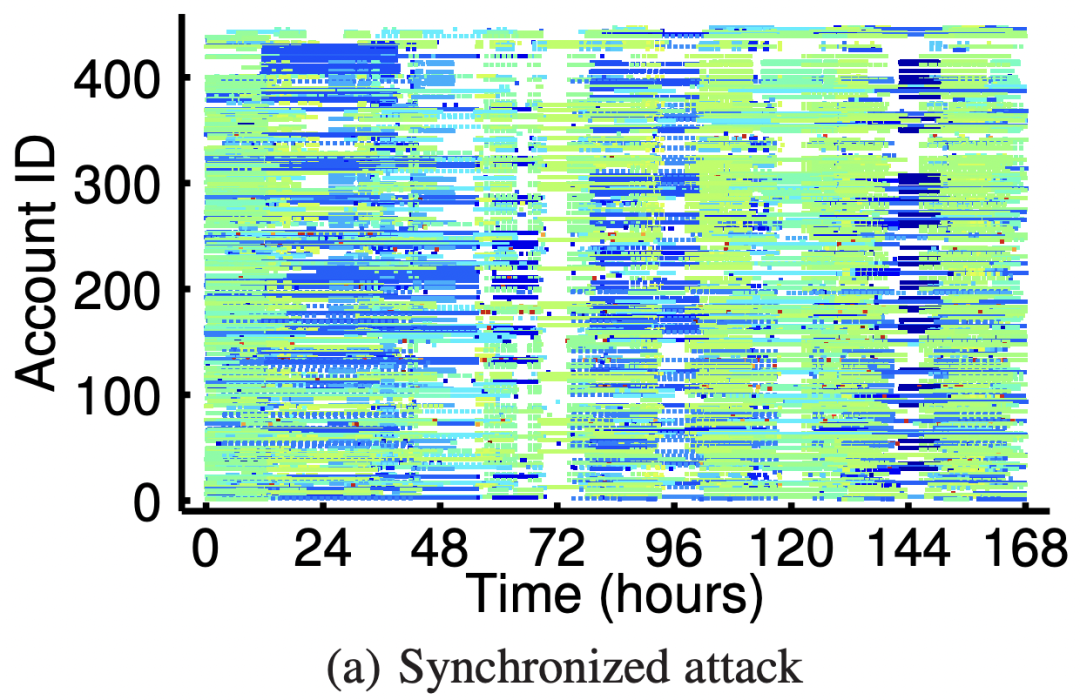
通過下圖可以看出而惡意用戶(圖a)行為較集中、持續(xù),而且使用到的IP資源較少 。正常用戶(圖b)的行為比較隨機,且使用大量不同的IP(現(xiàn)在幾乎不存在IP相同的了,論文時期還比較多)
 ? ?
? ?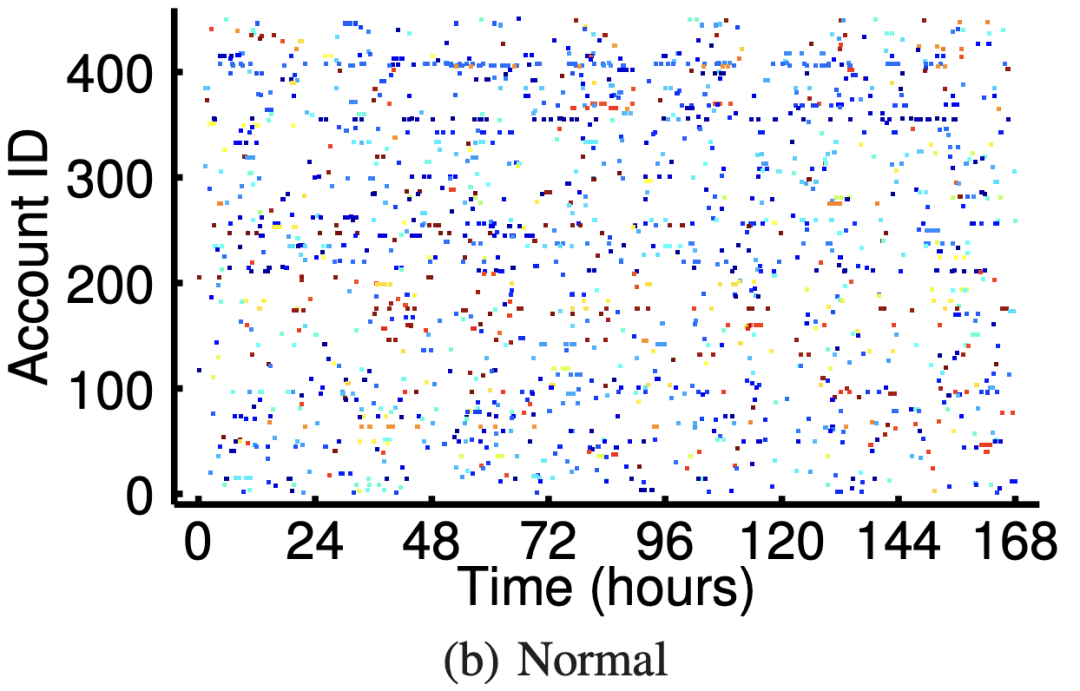
x軸是用戶上傳照片的時間,y軸代表用戶ID,點(x,y)代表某用戶在某時刻發(fā)生的上傳照片行為, 顏色代表此次行為使用的IP地址。
?
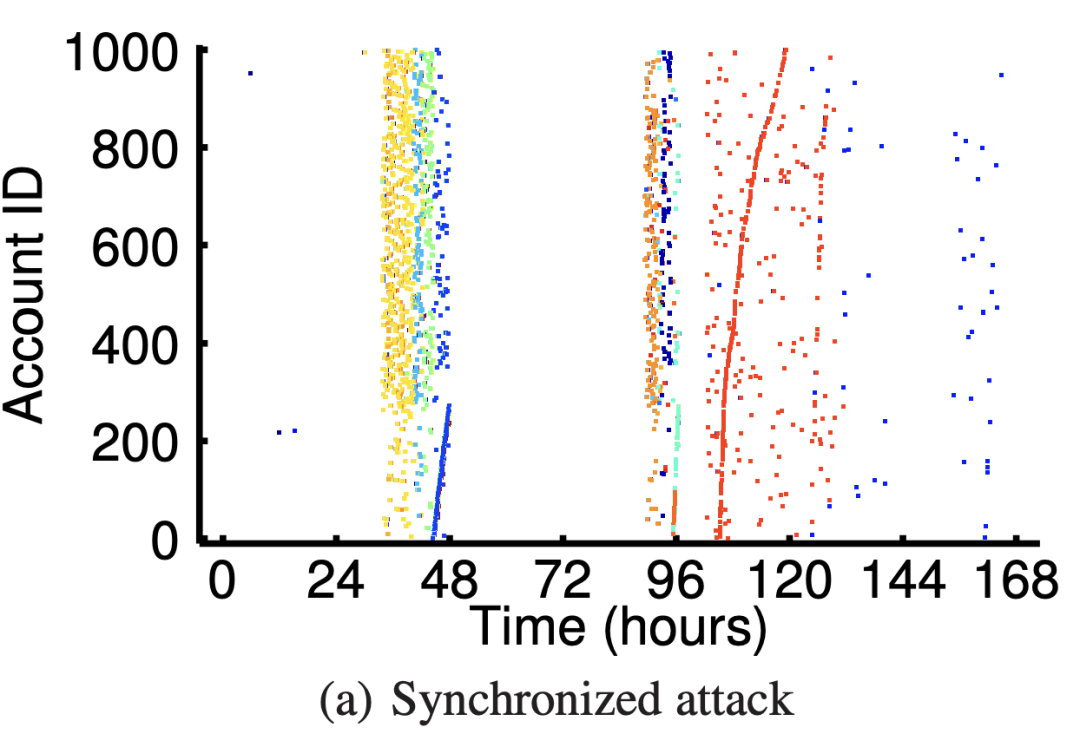
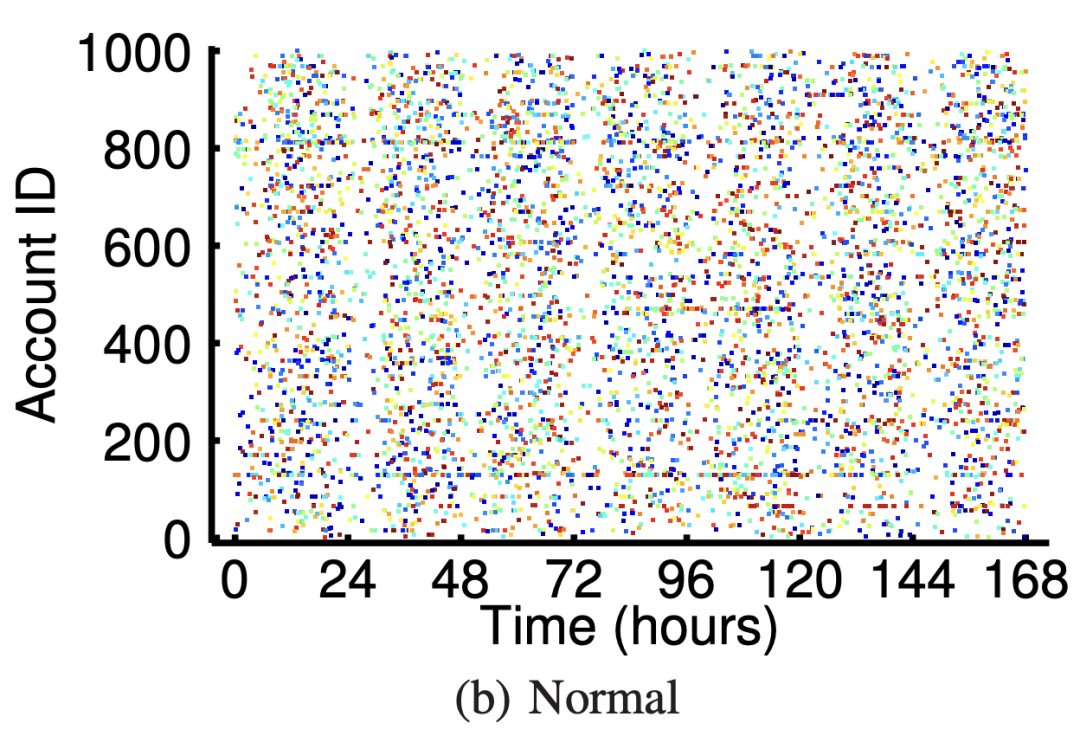
2、Instagram 用戶關(guān)注攻擊行為
下圖可以看出惡意用戶呈現(xiàn)“開關(guān)”的行為模式(只在某些時間點有行為), 并且使用的IP有限制。
 ? ?
? ?
3、經(jīng)濟約束
分析為什么社交網(wǎng)絡中攻擊者趨向“松散同步”的行為,主要原因是受到資源和任務的約束
2.3.1 資源約束
攻擊者受物理計算(服務器)、網(wǎng)絡資源(IP地址)的成本約束,甚至從云服務器租用。并且制造虛假、養(yǎng)號以及維護管理賬戶會產(chǎn)生人工和運營成本。
2.3.2 任務約束
收入來源明確需求的任務,比如在多少時間內(nèi)完成多少評論、贊、好友數(shù)。基本很多任務都需要在規(guī)定的時間內(nèi)完成,因此,黑產(chǎn)任務,時間維度的同步很難規(guī)避,如果避開時間維度,成本將不可控。
?
四、挑戰(zhàn)及解決
1、可擴展性
低信噪比:Facebook上有規(guī)模較大的用戶活動數(shù)據(jù)(日活6億),惡意用戶只占其中很少的比例(每次攻擊數(shù)千用戶),會導致低信噪比,但是,難達到較高的檢測準確率。
解決方法:根據(jù)攻擊者的經(jīng)濟約束,在檢測系統(tǒng)中引入下述約束約束在每個應用級別(如FB、INS)、某個事件級別(關(guān)注、點贊)上進行檢測。通過IP地址、被關(guān)注的賬戶、被點贊的頁面 分割用戶計算相似度。
計算壓力大:兩兩用戶做相似度計算,計算復雜度O(n^2)
解決方法:分而治之,將任務基于時間維度分成較小的任務,并行執(zhí)行, 然后聚合結(jié)果多個較小的計算結(jié)果以獲得一段時間的相似度。
2、準確性
無監(jiān)督異常檢測往往容易受到準確性的制約,通過了解攻擊者經(jīng)濟約束(業(yè)務經(jīng)驗),并提煉出知識加入系統(tǒng)中提高準確性。
另外提供了一組參數(shù),針對實際場景調(diào)節(jié) 誤殺(false postive)和 召回 (false negative)
3、 適用不同場景
攻擊者會針對不同的功能(點贊、上傳照片)攻擊,對系統(tǒng)的要求是能夠擴展適用不同的場景的攻擊。
包括分離個性化操作 和 通用操作, 以及對動作進行抽象,使得系統(tǒng)可以與特定OSN(online social network)獨立。
?
五、識別策略設計
1、用戶行為(user action)
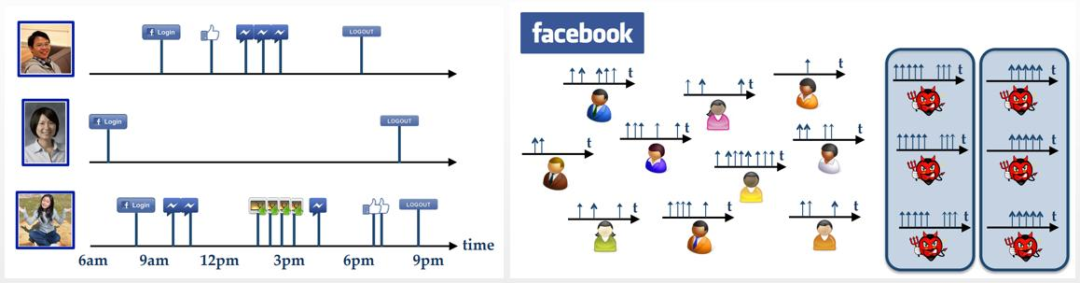
時間軸上的一個垂直箭頭表示用戶在Online Social Network上的一種操作,不同類型的箭頭表示不同類型的操作(例如,點贊,轉(zhuǎn)發(fā),評價、關(guān)注、上傳照片…)
通常每個用戶一天當中的操作是不同的,如左圖,但是Malicious Accounts組織通常是接受了某個任務,需要在規(guī)定時間內(nèi)完成指定的操作,所以會出現(xiàn)右圖矩形框中的情況,他們在時間軸上的箭頭是完全同步的。
2、按場景對行為分組
由于攻擊者的任務和操作約束,他們在特定時間只會集中針對某個功能進行攻擊,只會使用用戶行為空間中的子集行為。
故可以根據(jù)不同功能對行為分類,并在功能層次進行檢測,例如按照“上傳照片”、“頁面點贊”將用戶進行分組,每個組內(nèi)計算用戶之間相似度并進行檢測。
這樣做的好處是:
降低信噪比:如果使用用戶整體行為進行比較,可能會出現(xiàn)“維度災難”,錯過部分只針對某OSN功能的攻擊
降低計算成本:兩兩用戶計算相似度 是指數(shù)級別的開銷
?
3、數(shù)據(jù)說明及行為匹配
總結(jié)計算用戶相似度的字段:
UID:用戶ID
Timestamp:user action發(fā)生的時間戳
AppID:user action所屬功能類別,如發(fā)帖、評論、上傳照片等;
AssocID:user action作用對象ID,如某頁面、某USER、某照片;
IP address:user action發(fā)生時使用的IP地址
抽象帶時間戳的用戶行為(U為userID, T為動作時間戳, C為約束對象):

約束對象是各個屬性值的組合,例如限制在對同IP、點贊功能下、在某頁面上發(fā)生行為的用戶,進行相似度計算 。
行為匹配:若在約束下,兩個用戶的行為發(fā)生的時間都落在預定義好的匹配窗口內(nèi),那說明他們行為是匹配的:
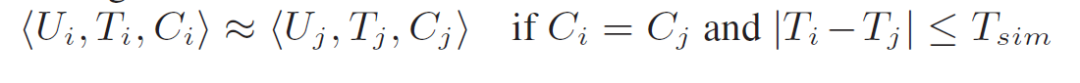
4、用戶間相似度度量
基于Jaccard測量兩個集合之間相似度,分為每個約束下的相似度和全局相似度。
4.3.1 約束下的相似度
設 Ai 為用戶Ui的行為集合:Ai = {?U, T , C ?|U =Ui } ?
設 為在約束Ck下用戶的行為集合:?
為在約束Ck下用戶的行為集合:?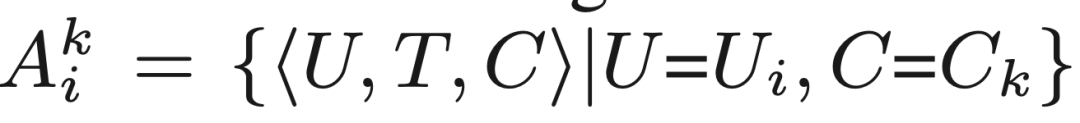 = {?U, T , C ?|U =Ui , C =Ck }
= {?U, T , C ?|U =Ui , C =Ck }
則兩用戶i、j在約束Ck下的用戶相似度:
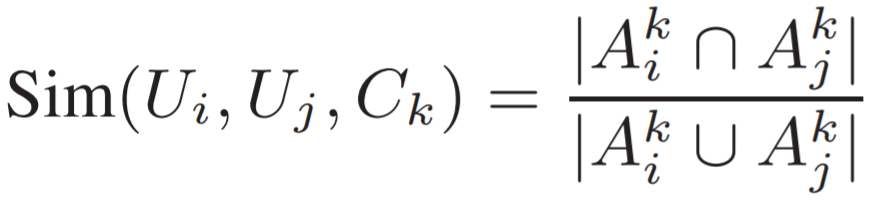
4.3.2 全局相似度
在有些約束下,用戶與操作對象的關(guān)聯(lián)可能只出現(xiàn)一次,例如安裝app,這樣jaccard相似度取值只有0/1。為了更好地表征用戶之間相似性,使用全局相似度(即綜合所有約束下的用戶間相似度):
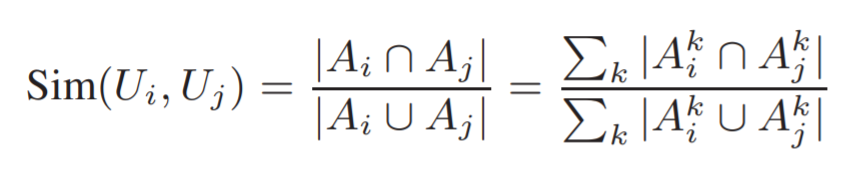
?
5、行為聚類
設定邊權(quán)重(共享的IP地址數(shù)量)閾值T,抽取G的子圖(邊權(quán)重w>=T)。對G作連通子圖聚類,得到k個連通圖。若連通圖的成員數(shù)大于M,那么對該連通圖進一步作取子圖操作,但邊權(quán)重閾值從T變成了T+1。不斷迭代上述整個過程。
單鏈層次聚類(不推薦)
現(xiàn)有的聚類方案(如k-mean)不具有擴展性,故使用單鏈層次聚類。大概的思路是:初始化:為每個節(jié)點指定一個簇逐步合并高相似度的簇,若兩個簇間用戶相似度最小值 超過某一個閾值,則合并。
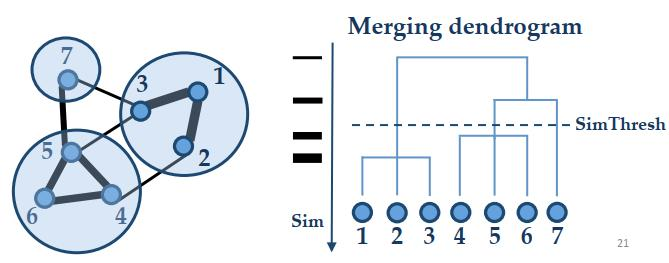
層次聚類:https://mp.weixin.qq.com/s/QD_rpJ4Iyv8gp3SFVVVamA
?
?圖分割 + 連通子圖查找
由于單鏈層次聚類依賴自下而上構(gòu)建樹,還是難以并行
采用等價的圖分割+連通子圖查找方法:過濾低于某閾值的邊,然后執(zhí)行連通子圖算法
?
圖構(gòu)建 ? - 圖分割 ?- 聯(lián)通子集查找 - 子集評分 - 節(jié)點評分
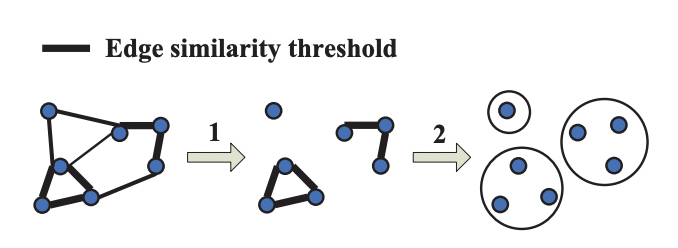
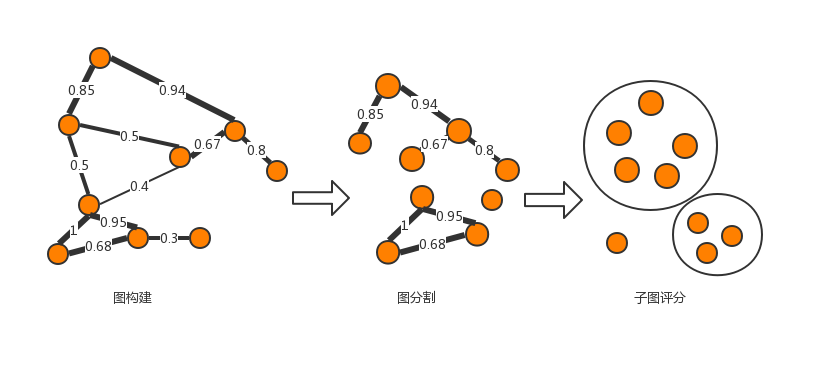
過濾邊的方法:
F1:至少存在一個約束對象,對該約束對象用戶間相似度超過某個閾值:防范在單約束下的攻擊(如同IP地址)
F2:全局相似度超過某個閾值, 防范跨多個約束對象的攻擊場景。
?
六、并行化實現(xiàn)用戶間相似度計算
對于用戶的相識度計算,計算開銷是最大的問題,算法的工程問題主要是為了解決如何計算賬號相似度,由于【賬號對(i,j)的交集次數(shù)=賬號對(i,j)的并集次數(shù)-賬號i的行為次數(shù)-賬號j的行為次數(shù)】,并且賬號的行為次數(shù)非常好計算,因此主要問題是如何計算【賬號對(i,j)的交集次數(shù)】。
一個簡單的方法是按照Constraint Object進行partition,每個分區(qū)統(tǒng)計賬號對的共現(xiàn)次數(shù),然后再進行reduce操作,但是由于一些熱點Constraint Object的存在,該方法在大數(shù)據(jù)量的情況下很難跑的出來。
論文首先提出了一個減少計算量的方法,該方法是按照天來計算,再對多天進行匯總。于是,現(xiàn)在的問題轉(zhuǎn)化為如何計算一天內(nèi)賬號對的交集次數(shù)。
1、按天為單位并行化
即按天比較用戶的日相似度,并將一定窗口內(nèi)的日相似度聚合,如下圖所示

?
用戶Ui在某天的行為:
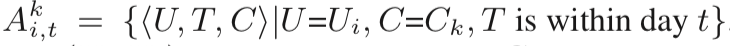
用戶Ui、Uj按天計算、聚合相似度公式:
公式中最后個等號為什么成立?因為匹配窗口是分鐘級別或者一兩個小時,跨天的用戶行為匹配相對比較少,故等號近似成立。
?
2、每時級別重疊滑動窗口的相似度計算
即使轉(zhuǎn)換成按天計算了,因為可能某些公共IP關(guān)聯(lián)的用戶量比較大(熱門IP可能每天關(guān)聯(lián)10w個用戶),可能天級別的計算也會發(fā)生數(shù)據(jù)傾斜,導致計算量異常大,所以還需要進一步優(yōu)化計算邏輯。
論文解決這個問題的思路是這樣的,以2Tsim為時間窗大小進一步對1天的時間周期進行分組,每個組之間的計算可以并行化,于是算法可以進一步提速:重疊滑動窗口大小為Tsim(行為匹配窗口)的2倍,滑動距離等于Tsim,并刪除重復計算:對在兩個連續(xù)的窗口任意一個中間部分(下圖陰影部分)禁用相似度計算。
假設Tsim=1H,那么時間段0-23可以分成(0,1)(1,2)...(22,23)這幾個組,每個組的時間跨度是2H,并且每個組與相鄰組之間有1個小時的重疊。對于每個組,統(tǒng)計賬號對發(fā)生同步行為的次數(shù),并進行聚合,得到結(jié)果A。
按照上述計算邏輯,有一種情況會重復計算,比如:一個賬號對的兩個同步行為發(fā)生在4點到5點之間,那么(3,4)和(4,5)都會對其計數(shù)一次。因此,還需要統(tǒng)計賬號對在(0)(1)...(23)這些組發(fā)生同步行為的次數(shù),進行聚合得到結(jié)果B,于是最終賬號對的交集次數(shù)為A-B。
這部分最抽象,比較難理解,理解了,直接SQL就能實現(xiàn),我就是在SQL中完成的這個部分。
?
2、提高精確度
提供一組參數(shù)根據(jù)實際場景選擇不同取值,人為調(diào)整后來權(quán)衡誤殺和召回。
Tsim:行為匹配窗口
F1:每個約束相似度過濾閾值
F2:全局相似度過濾閾值
匹配后計算額外的條件,比如行為匹配后,計算昵稱相似度
比如較大的動作匹配窗口能夠為兩個用戶找到更大的匹配動作集,從而增加他們的相似度,
較大的相似度閾值減少了召回,降低了誤殺率。根據(jù)場景不同,窗口設計差異非常巨大,如在紅包、點贊等場景,窗口盡量設計的小,活動持續(xù)時間短。商家領(lǐng)域,特別是針對養(yǎng)號類的商家,持續(xù)時間可能是月,甚至是年。
3、計算復雜度
沒約束全局相似度計算:O(rn^2),n為每個每日的活躍用戶數(shù),r為每個用戶每天的動作數(shù)
約束級別下相似度計算:O(rm^2),m為每個約束對象下每日用戶數(shù)
連通子圖查找:O(n)
總復雜度O(rm^2+n)
?
?
七、檢測系統(tǒng)使用、評價和分析
1、不同場景約束設置
如果是資源受限的同步攻擊:在用戶登陸和照片上傳場景,使用IP地址+cookie作為約束。
任務約束的同步攻擊:在安裝app、點贊和刷關(guān)注場景,用appID、pageID、被關(guān)注者ID作為約束,并在一些場景使用全局相似性。
2、減少誤殺,影響用戶體驗的設置
僅篩選出大型子圖,比如節(jié)點數(shù)超過200,這些往往都對應大型攻擊。不會使惡意子圖中所有用戶操作都無效,而是僅禁止同一子圖中每個賬戶至少出現(xiàn)過一次的操作。
3、提取攻擊簽名
約束對象如IP、UA、cookies等可能濫用的,故可以作為攻擊簽名提煉出來,構(gòu)建近實時規(guī)則。
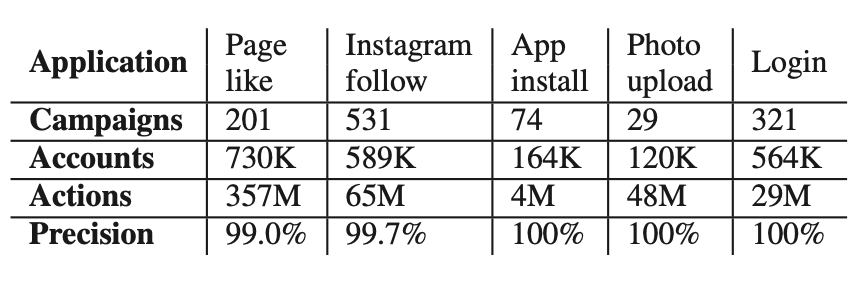
4、準確率分析(抽樣)
5、惡意賬戶類型分布

6、增量分析
每個場景檢測到的欺詐增量明顯

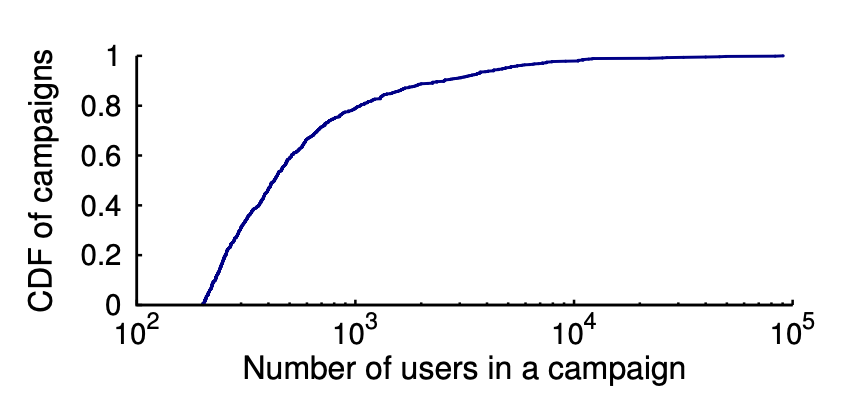
7、攻擊用戶規(guī)模分布
?
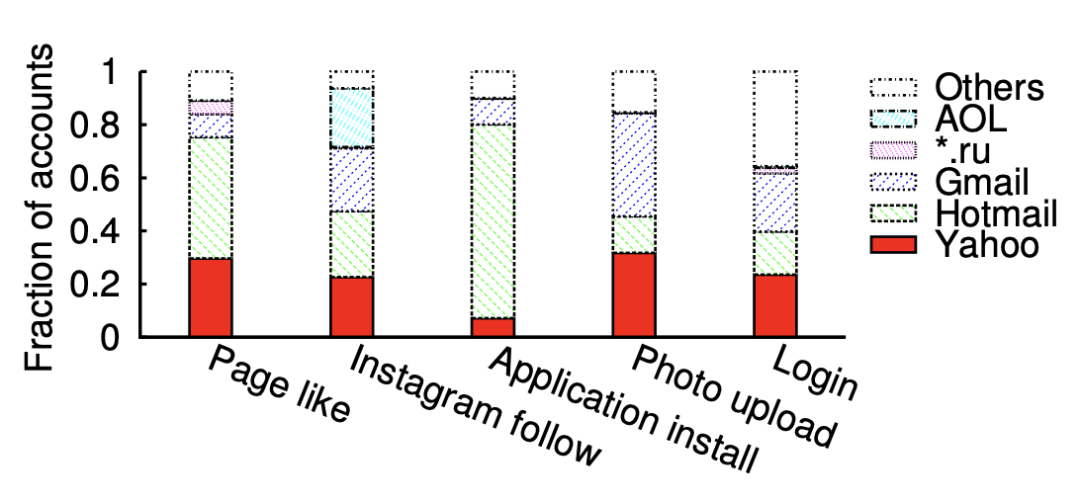
8、攻擊者郵箱來源分析
9、攻擊者IP段分析
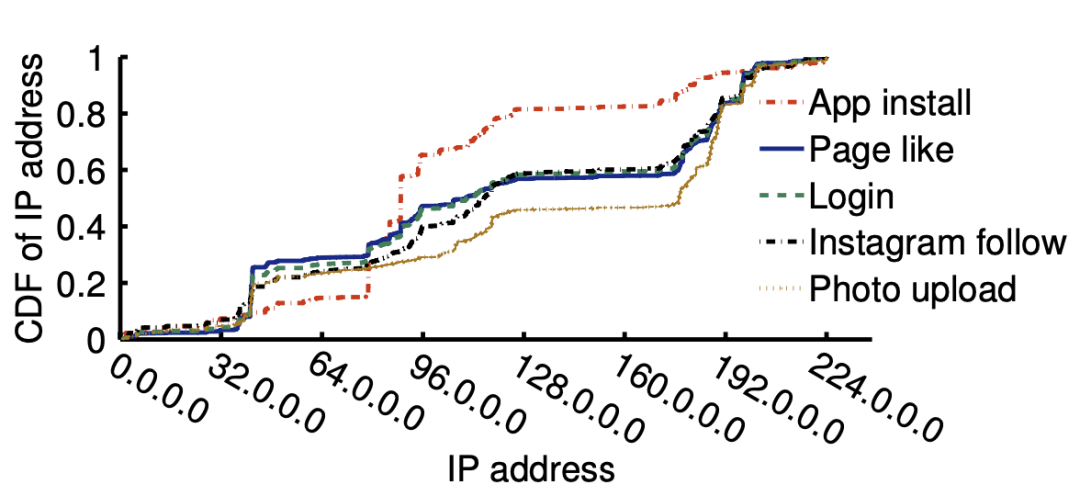
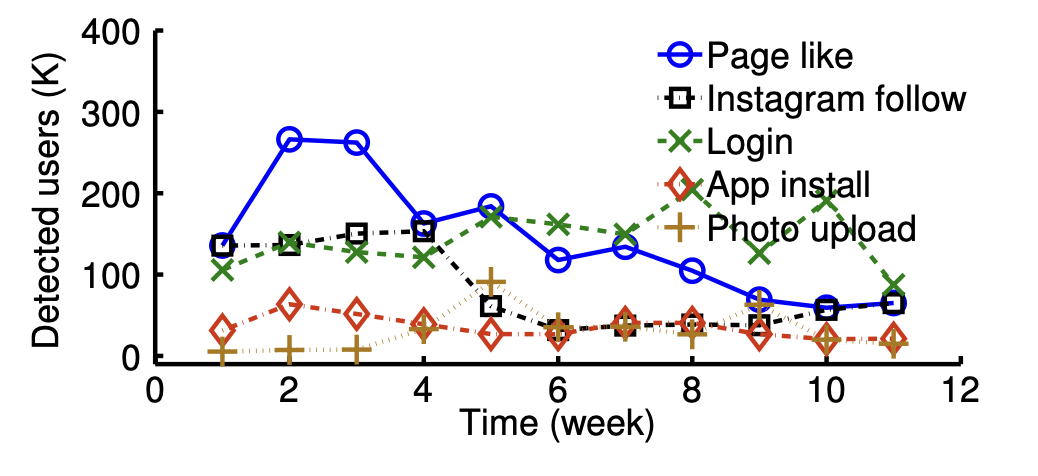
10、上線后效果
圖1:開始開始穩(wěn)定,后面下降原因可能是攻擊者發(fā)現(xiàn)無法通過這種方式攻擊,故停止了,后面一直穩(wěn)定說明有效檢測圖2是每個用戶被系統(tǒng)檢測到次數(shù),可以發(fā)現(xiàn)存在部分用戶被檢測到超過2次,這個是因為fb會對檢測到的用戶發(fā)送驗證,部分攻擊者可能會通過驗證從而發(fā)起新的攻擊
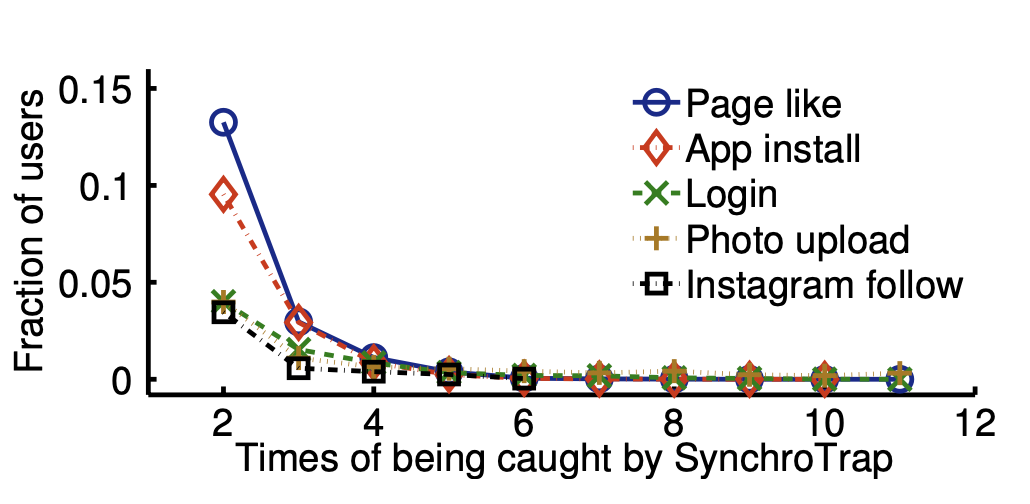
?
11、SybilRank分析
SybilRank應該是對每個用戶在社交圈的地位進行排名,通過SybilRank 對惡意用戶進行排名,描繪社交價值,發(fā)現(xiàn)登陸操作中有40%為0分,說明他們沒有社交價值(孤島),故可能為虛假帳戶。雖然sybilrank對大部分惡意用戶排名都低,但也存在部分排名高的,這個可能是也操控(盜號)了部份正常社交的用戶上傳照片傳播給他們的朋友
六、課后思考
這篇文章是具有一定啟發(fā)性的,賬號對行為具有同步特征是惡意賬號行為聚集性的必然表現(xiàn)。這種賬號之間的聯(lián)系是非常強的,并且不需要依賴一些強關(guān)聯(lián)關(guān)系(如:共用設備等)。在這里,我就這篇論文會提出一些問題供大家思考或討論:
1、Single-linkage層次聚類、DBSCAN和連通圖算法有什么聯(lián)系,什么樣的聚類算法可以轉(zhuǎn)化為圖算法。
2、與論文中的做法相比,對Similairy Graph直接采用社區(qū)發(fā)現(xiàn)算法做團體挖掘有什么優(yōu)劣。
3、對于那種行為數(shù)量異常多的Constraint Object如何處理。
4、對于LockStep欺詐行為檢測類算法,F(xiàn)RAUDAR、CopyCatch、CatchSync和SynchroTrap在適用場景上有什么不同。
大家有什么疑問,加我一起交流。
?

長按關(guān)注公眾號? ?? ? ? ??長按加作者好友 ? ? ???